


HPE-owned Cray claims the new ClusterStor E1000 parallel storage system delivers up to 1.6 terabytes per second and 50 million IOPS/rack. According to supercomputer maker this is more than double that of other unnamed competitors.
The ClusterStor E1000 starts at 60TB and scale to multiple tens of petabytes across hundreds of racks. What makes it so fast and able to hold such high capacity? Our guess is that the E1000’s PCIe gen 4 links to SSDs and use of disks as capacious as 16TB contributes to its speed and the 6,784TB/chassis maximum capacity.
And Cray has some marquee customers lined up already with the E1000 selected as external storage for the first three US exascale supercomputing systems: Aurora for US Department of Energy (DOE) for use at the Argonne Leadership Computing Facility, Frontier at the Oak Ridge National Laboratory and El Capitan at the Lawrence Livermore National Laboratory.
Lustre with added lustre
ClusterStor is a scale-out parallel filesystem array for high performance computing installations. It uses Cray-enhanced Lustre 2.12 software. The system features GridRAID with LDISKFS or ZFS (dRAID).
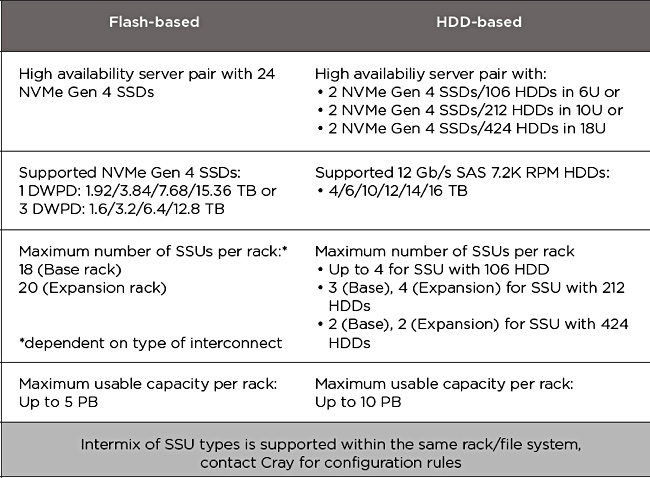
This E1000, presented as exascale storage, comes with three components: Scalable Storage units (SSUs) which are either flash-based or SAS disk-based with SSD caching, a Meta Data Unit and a System Management Unit.
The system uses NVMe/PCIe gen 4-accessed SSDs that are either capacity-optimised (1DWPD) or set for a longer life (3DWPD).
It has faster than usual host interconnect options; 200 Gbit/s Cray Slingshot interconnect, InfiniBand EDR/HDR or 100/200 Gbit/E. The usual top speed are 100GBit/s. The E1000 can connect to Cray supercomputers across Slingshot and to any other computer system using InfiniBand or Ethernet.
There is a management network utilising 10/1GbitE.
The ClusterStor E1000 filesystem can support two two storage tiers in a filesystem – SSD and disk drives. There are three ways to move data between these tiers or pools:
- Scripted data movement – user directs data movement via Lustre commands. Best for manual migration and pool data management.
- Scheduled data movement – data movement is automated via the workload manager and job script. Best for time critical jobs and I/O acceleration of disk pool data.
- Transparent data movement – read-through/write-back model supporting multiple file layouts of file. Best for general purpose pre/post processing.
ClusterStore Data Services uses a relatively thin layer of SSDs (for cacheing) above a large disk pool to present the system as a mostly all-flash system.
As yet there is no HPE InfoSight support – that may be something for the future as HPE only completed the acquisition of Cray in September 2019. Instead the E1000 offers HPC storage analytics on a job level with Cray View for ClusterStor via an optional software subscription.
The E1000 is a larger and faster array than Cray’s three existing ClusterStor systems; the L300F (flash), L300N hybrid flash/disk and L300 disk drive systems.
Competition
Cray identifies several competing arrays:
- DDN EXAScaler – DDN ES400NV all-flash, DDN ES18K and ES7990 disk-based systems, and hybrid systems.
- IBM Elastic Storage Server (ESS) GSxS all-flash and GLxC disk models.
- Lenovo Distributed Storage Solution for GPFS (DSS-G) with all-flash DSS-G20x and disk-based DSS-G2x0 arrays.
Cray says the E1000 has more throughput than all of these DDN, IBM and Lenovo systems and there is no automated scheduler-based data movement between their flash and disk pools. The IBM system requires Spectrum Scale software support while the E1000 includes its Lustre software.
Cray’s ClusterStor E1000 are available starting in Q1 2020.





