Pure Storage CEO Charles Giancarlo expressed two noteworthy views in an interview with Blocks & Files – that hyperconverged infrastructure doesn’t exist inside hyperscaler datacenters, and that data needs virtualizing.
He expressed many noteworthy views actually but these two were particularly impressive. Firstly, we asked him if running applications in the public cloud rendered the distinction between DAS (Direct-Attached Storage) and external storage redundant. He said: “In general the public cloud is designed with disaggregated storage in mind… with DAS used for server boot drives.”
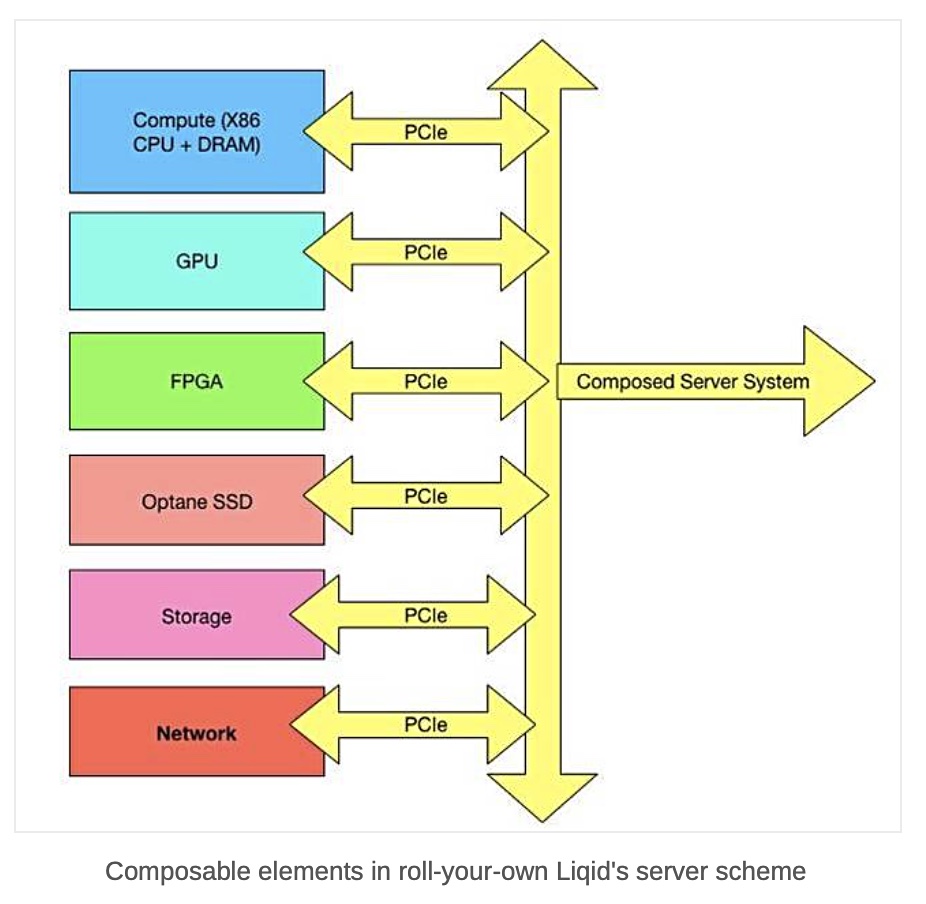
The storage systems are connected to compute by high-speed Ethernet networks.

It’s more efficient than creating virtual SANs or filers by aggregating each server’s DAS in the HCI (hyperconverged infrastructure). HCI was a good approach generally, in the 2000 era when networking speeds were in the 1Gbit/s area, but “now with 100Gbit/s and 400Gbit/s coming, disassociated elements can be used and this is more efficient.”
HCI’s use is limited, in Giancarlo’s view, by scaling difficulties, as the larger an HCI cluster becomes, the more of its resources are applied to internal matters and not to running applications.
Faster networking is a factor in a second point he made about data virtualization: “Networking was virtualized 20 years ago. Compute was virtualized 15 years ago, but storage is still very physical. Initially networking wasn’t fast enough to share storage. That’s not so now.” He noted that applications are becoming containerized (cloud-native) and so able to run anywhere.
He mentioned that large datasets at petabyte scale have data gravity; moving them takes time. With Kubernetes and containers in mind, Pure will soon have Fusion for traditional workloads and Portworx Data Services (PDS) for cloud-native workloads. Both will become generally available in June.
What does this mean? Fusion is Pure’s way of federating all Pure devices – on-premises hardware/software arrays and off-premises, meaning software in the public cloud – with a cloud-like hyperscaler consumption model. PDS, meanwhile, brings the ability to deploy databases on demand in a Kubernetes cluster. Fusion is a self-service, autonomous, SaaS management plane, and PDS is also a SaaS offering for data services.
We should conceive of a customer’s Pure infrastructure, on and off-premises, being combined to form resource pools and presented for use in a public cloud-like way, with service classes, workload placement, and balancing.
Giancarlo said “datasets will be managed through policies” in an orchestrated way, with one benefit being the elimination of uncontrolled copying.
He said: “DMBSes and unstructured data can be replicated 10 or even 20 times for development, testing, analytics, archiving and other reasons. How do people keep track? Dataset management will be automated inside Pure.”
Suppose there was a 1PB dataset in a London datacenter and an app in New York needed it to run analysis routines? Do you move the data to New York?
Giancarlo said: “Don’t move the [petabyte-level] dataset. Move the megabytes of application code instead.”
A containerized application can run anywhere. Kubernetes (Portworx) can be used to instantiate it in the London datacenter. In effect, you accept the limits imposed by data gravity and work with them, by moving lightweight containers to heavyweight data sets and not the inverse. You snapshot the dataset in London and the moved containerized app code works against the snapshot and not the original raw data.
When the app’s work is complete, the snapshot is deleted and excess data copying avoided.
Of course data does have to be copied for disaster recovery reasons. Replication can be used for this as it is not so time-critical as an analytics app needing results in seconds rather than waiting for hours as a dataset slowly trundles its way through a 3,500-mile network pipe.
Giancarlo claimed: “With Pure Fusion you can set that up by policy – and keep track of data sovereignty requirements.”
He said that information lifecycle management ideas need updating with dataset lifecycle management. In his view, Pure needs to be applicable to the very large-scale dataset environments, the ones being addressed by Infinidat and VAST Data. Giancarlo referred to them as up-and-comers, saying they were suppliers Pure watched although he said it didn’t meet them very often in customer bids.
Referring to this high-end market, Giancarlo said: “We clearly want to touch the very large scale environment that out systems haven’t reached yet. We do intend to change that with specific strategies.” There was no more detail said about that. We asked about mainframe connectivity and he said it was relatively low on Pure’s priority list: “Maybe through M&A but we don’t want to fragment the product line.”
Pure’s main competition is from incumbent mainstream suppliers such as Dell EMC, Hitachi Vantara, HPE, IBM, and NetApp. “Our main competitive advantage,” he said, “is we believe data storage is high-technology and our competitors believe it’s a commodity… This changes the way you invest in the market.”
For example, it’s better to have a consistent product set than multiple, different products to fulfill every need. Take that, Dell EMC. It’s also necessary and worthwhile to invest in building one’s own flash drives and not using commodity SSDs.
Our takeaway is that Pure is bringing the cloud-like storage consumption and infrastructure model to the on-premises world, using the containerization movement to its advantage. It will provide data infrastructure management facilities to virtualize datasets and overcome data gravity by moving compute (apps) to data instead of the reverse. Expect announcements about progress along this route at the Pure Accelerate event in June.