

D2D2T – Disk to Disk to Tape. Backedup data from a disk source system is first written to a target disk system and then sent on to a tape library.
D2D
D2D – Disk to disk. A term used to describe backup storage systems with the backup of a disk-based source system stored in another disk-based target system and not a tape library.
CSI
CSI – Container Storage Interface. This is an industry standard interface that can be used by any storage system provider and works across various container orchestration systems, such as Kubernetes, Mesos and Cloud Foundry. Envisage a storage supplier writing a single CSI plugin so their storage could be used by containers orchestrated by any CSI-supporting orchestrator.
The specification is formally described here. With it, a container orchestrator interacts with a plugin though remote procedure calls (RPCs.) These, also known as Application Programming Interface (API) calls, are used for;
- Dynamic provisioning and deprovisioning of a volume.
- Attaching or detaching a volume from a node.
- Mounting/unmounting a volume from a node.
- Consumption of both block and mountable volumes.
- Local storage providers (e.g., device mapper, lvm).
- Creating and deleting a snapshot (source of the snapshot is a volume).
- Provisioning a new volume from a snapshot (reverting snapshot, where data in the original volume is erased and replaced with data in the snapshot, is out of scope).
CPU
CPU – Central Processing Unit – the main processor in a server, desktop or laptop computer. It executes machine-level instructions and is a general purpose processor. There can be multiple processor cores inside a CPU, and these cores can execute in parallel. The cores can have multiple threads also executing instructions in parallel. Intel makes x86 architecture CPUs, as does AMD. Other CPU architectures include Arm and Risc-V.
Container
Container – A software entity that contains application code to run microservices with a standard interface to other containers. Unlike a virtual machine a container does not contain a guest operating system and is, therefore, smaller than the equivalent application code running in a virtual machine. Containers are loaded and run – instantiated -and orchestrated by software such as Kubernetes. They were originally stateless with no state information preserved between their instantiations. Stateful containers do have data about their state stored between instantiations.
Snapshot
Snapshot – A virtual copy of a file or RAID volume or object at a point in time created in a database, hypervisor, file system or storage system that relies on the original. We’ll use volume to refer to all three here. A snapshot is a virtual copy. It has two main purposes: easy recovery of deleted or corrupted files, and a source for replication or backup. In order for the snapshot to protect against media failure, it must be transformed into a physical copy via replication or backup to another devices. If you copy this snapshot to another system it becomes a real copy.
There are two ways of writing snapshots; Copy-on-Write (COW) and Redirect-on-Write (ROW). A COW system takes place when blocks in the volume are going to be overwritten. A copy is made of the to-be-overwritten blocks and written in a separate place or snapshot area. Then the fresh data overwrites the old data in the volume. There are three I/O operations needed; a read followed by two writes.
The ROW method treats snapshots as a list of pointers. When blocks in a volume are going to be overwritten the snapshot system is updated with the pointers to the about-to-be-overwritten blocks and then the new data is written to a fresh area of the drive. Thus the existing old data blocks are added to the snapshot system without having to be read and copied. There is only one I/O operation; a write, plus the snapshot pointer updating. Consequently ROW snapshots are faster than COW snapshots.
Compression
Compression – the shrinking of a file or object’s size by replacing repeated strings of bits with fewer bits and a pointer. This is done so that files take up less storage space or needs less bandwidth when transmitted across a network link. When the file is received at the far end of the link it may be decompressed, as a stored compressed file would be when it is read. The compression-decompression processes could be carried out by a codec hardware device or performed using software.
Compression techniques can be applied to text files, audio files, images and video files, and can be done in a lossless manner or a lossy way, meaning that some information is permanently lost. Audio files may contain frequencies that the human ear cannot detect and removing them won’t affect the perceived quality of the heard audio file but will reduce its size. Applying lossy compression to images and videos can reduce the perceived quality of both.
Applying lossy compression to text files is self-defeating as losing information obscures the meaning of the text.
Compression techniques
Algorithms are used to scan files and find repeated bit sequences. They are replaced by a pointer which identifies the original bit sequence and the location in the file where it should be written when the file is decompressed. The original bit sequences can be stored in a dictionary appended to the file.
JPEG – (Joint Photographic Experts Group) is a standard format for compressed image data which is lossy in that some data is lost. This can be most effective in reducing image file sizes while still delivering acceptable image quality.
MPEG – (Moving Picture Experts Group) – A way of compressing video files that stores changes between frames in a video and not the entire frame. There are different types of MPEG compression, such as MPEG2, MPEG2 and MPEG4.
Lempel-Ziv – Abraham Lempel and Jacob Ziv published the LZ77 and LZ78 lossless compression papers in 1977 an 1978 respectively. Repeated bit sequences in a file are detected by reading a section of the file, a window. When identified the repetitive sequence is stored in the file as a length-distance pair (pointer). This says replace the next N characters with the sequence found at earlier location X in the file. Then the window is moved up the file (sliding window in LZ77) and the repetition search repeated.
The file is thus reduced in size and can be exactly rebuilt (rehydrated) when it is read.
The LZ78 algorithm stores repeated bit sequences in a dictionary and uses a pointer added to the file to identify which dictionary sequence to insert at a particular location.
The LZ78 algorithm was improved by a later LZW algorithm that pre-initializes a dictionary used with all possible characters or with an emulation of a pre-initialized dictionary.
The Lempel-Ziv algorithms are widely used.
ZIP – ZIP or archive folders are produced by losslessly compressing files and putting them inside a ZIP folder to save bandwidth and time with a network transmission or storage on a portable device. When read they are “un-zipped.”
Note. See also deduplication.
Storage News Ticker – 22 April

….
Unstructured NAS and object data migrator and manager Datadobi has signed Climb Channel Solutions to distribute its products to resellers and solution providers in the EMEA region.
…
Gartner has released historical data on the top five DBMS suppliers since 2017 and it shows the dramatic inroads made by cloud-based DBMS suppliers. Its 2017 top dog – Oracle, appears to have been overtaken by Microsoft (Azure) and AWS, and Google has leapfrogged IBM. Here are Gartner’s numbers and a chart:
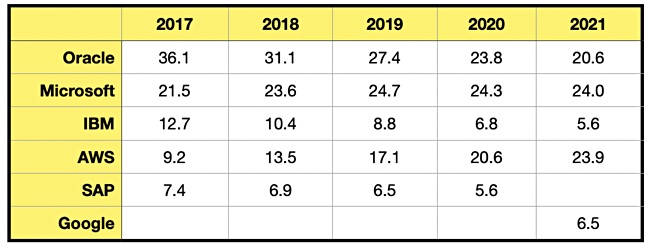
…
Hammerspace says Jellyfish Pictures has deployed its Global Data Environment to advance its virtual studio strategy and fuel its business growth. Jellyfish is using its platform on its cloud rendering projects, using Hammerspace to enable content and leverage the most cost-effective cloud compute region without concern for where the content was created. Jellyfish is an M&E/VFX company, and so has decentralized and distributed data creation, storage and talent resources across wide geographies. Hammerspace said its Global Data Environment platform gives high-performance, local read/write data access to global users and applications, of all of an organization’s data, no matter where it is stored.
…
Nexsan, a StorCentric business unit, has launched its Unity NV10000 enterprise-class, all-flash NVMe storage array. It supports file (NFS, SMB), block (iSCSI, FC) and object (S3) protocols and has up to 20GB/sec bandwidth. The array software includes, snapshots, ESXi integration, in-line compression, caching, async replication, encryption, and high-availability. It is a Veeam-certified backup target device and supports immutable block and file data and S3 object lock. This Unity array accompanies Nexsan’s E-series high-density/high-capacity and Beast high-density arrays, and the Assureon archival array.
…
AI-powered unstructured data search startup Nuclia has raised a $5.4 million seed round led by Crane Venture Partners and Ealai. Barcelona-based Nuclia says its cloud-native NucliaDB database has been open sourced. It has a publicly available API that enables developers to integrate AI-powered search into any app, service, or website in minutes. Aneel Lakhani, Venture Partner at Crane, said: “Nuclia has built something incredible. Imagine being taken to the exact time in a video or podcast, or the exact block in a PDF or presentation, that has the content you are looking for. And then go a step further, searching not only for content, but also concepts.”
…
Seagate has said it will power its global facilities with 100 per cent renewable energy by 2030, and achieve carbon neutrality by 2040. Joan Motsinger, SVP for business sustainability and transformation at Seagate, came out with a particularly cringeworthy comment in an announcement, saying: “Seagate’s value of Integrity compels us to take meaningful and measurable action on climate change.” In April 2020 it was revealed that Seagate had put slow rewrite SMR drive technology into its Barracuda disk drive products without telling customers. Public US businesses are compelled by the SEC to disclose ESG (Environmental, Social, Governance) information to customers and can look to suppliers in their supply chains to help them achieve better ESG results.
…
Sanmina’s Viking Enterprise Solutions product division has announced its Cloud Native Obsidian (CNO), an on-premises storage system with an object-and-file storage architecture. Viking says CNO’s compatibility with public cloud platforms enables businesses to deploy a hybrid cloud strategy. A diagram shows it involves NVMe SSDs, Ceph and file storage – probably disk – and hooks up to S3 in AWS.
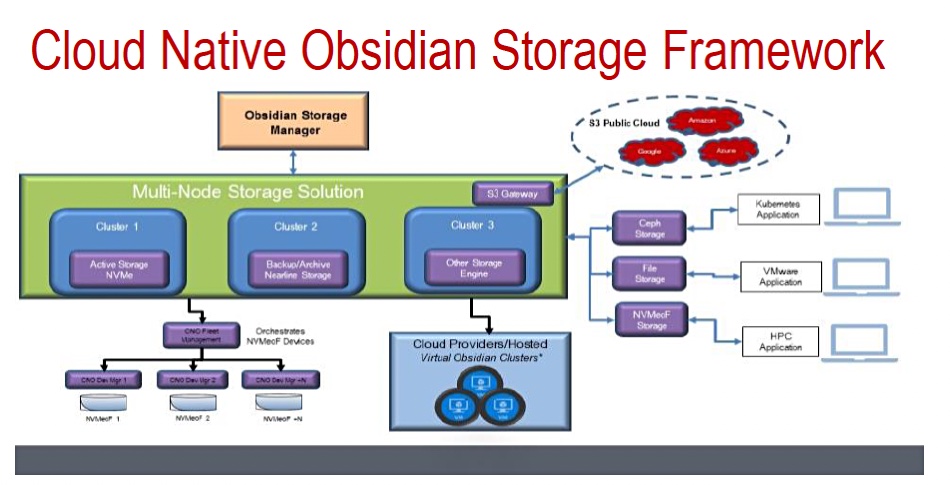
According to Viking, “when comparing to cloud-based storage, CNO removes the traditional RAID hardware constraints by simply allowing additional, qualified storage nodes to be added to the CNO cluster and providing a scalable storage lifecycle, under one storage manager.” CNO is intended for market segments including the media/entertainment, video surveillance, backup and archive, and enterprise file services sectors. It’s now available through Viking’s distribution partner Climb Channel Solutions.
WEKA moves file data at 2TB/sec on Oracle’s cloud

WEKA says it has moved file data on Oracle’s cloud at close to 2TB/sec to servers using its scale-out, parallel file system software.
The Oracle Cloud Infrastructure (OCI) public cloud provides bare-metal servers for compute shapes. A shape is a template specifying the type of CPU, number of CPU cores, RAM, and networking speed. Oracle and WEKA validated WEKA’s performance when running inside the OCI.
Oracle’s Principal Solutions Architect, Pinkesh Valdria, claimed in a blog late last week: “The performance that WEKA and OCI can provide to customer workloads is fantastic… this combination of performance and scale along with the elasticity that OCI provides, allows you to successfully host modern EDA, life sciences, financial analysis, and even more traditional enterprise workloads on OCI.”
WEKA says of Oracle’s cloud: “Oracle Cloud Infrastructure (OCI) is a top-tier Hyperscale cloud that provides XaaS compute and application services to Oracle customers, and offers a lot more than you might expect, including AI/ML and GPU workloads.”
The validation test involved runs using 80 or 373 x bare metal (BM.Optimized3.36) compute shapes with 36 cores, 512GB of RAM, 3.8TB of local NVMe SSD, 100Gbits RoCE (RDMA over Converged Ethernet), and 2 x 50Gbit/s network links. WEKA was configured to use six cores leaving 30 for running the OS and application software on the same server.
Test data was generated using Flexible IO (Fio) with 1MB blocks for large block workloads and 4KB ones for small block workloads. Here is a table of the results followed by a chart:

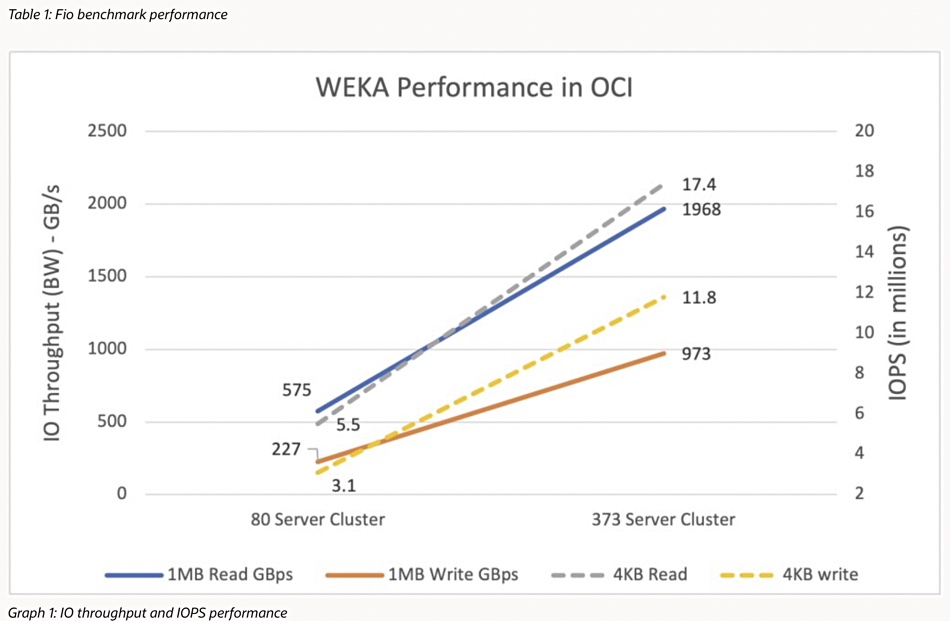
No doubt there were intermediate server number configurations, but WEKA and Oracle have highlighted the 80 and 373-server results. A near 2TB/sec throughput is certainly a hero number.
One possible comparison is with WEKA’s Nvidia GPUDirect performance of 97.9GB/s of throughput to 16 NVIDIA A100 GPUs and 113.1GB/sec to an Nvidia DGX-2 server. Presumably WEKA could deliver higher bandwidth if more Nvidia GPUs were targeted so requiring more WEKA nodes.
Analyst house ESG has validated WEKA performance on a number of benchmarks but doesn’t specifically call out IOPS and GB/sec bandwidth. Similarly the many WEKA STAC benchmarks typically don’t identify general OPS or throughput numbers.
WEKA’s own stats for its AWS performance calls out large file (1MB) read performance of over 100GB/sec and small file (4KB) read performance of 5 million-plus IOPS across 16 EC2 instances. [Conveniently for Oracle’s marketers, their lower, 80-server, 5.5 million read IOPS number exceeds the AWS 5 million-plus IOPS result. It wouldn’t look so good if the OCI result was lower than the AWS one.]
These AWS-WEKA numbers are a long way short of the 80 and 373 instances used in the OCI test runs but that’s no reason to think that WEKA’s AWS performance is less than its OCI performance.
Our thinking is that WEKA could scale to the same OCI levels of performance on AWS if it increased the number of compute instances; it is scale-out software, after all. On a linear scale it would need roughly 56 AWS compute instances, of the type used in the 16-instance test, to reach the OCI 373-server result of 17.4 million IOPS.
There aren’t equivalent data sheets for WEKA running in the Azure or GCP clouds that we could find in WEKA’s resources web page.
Pure Storage wants to work with data gravity, not against it

Pure Storage CEO Charles Giancarlo expressed two noteworthy views in an interview with Blocks & Files – that hyperconverged infrastructure doesn’t exist inside hyperscaler datacenters, and that data needs virtualizing.
He expressed many noteworthy views actually but these two were particularly impressive. Firstly, we asked him if running applications in the public cloud rendered the distinction between DAS (Direct-Attached Storage) and external storage redundant. He said: “In general the public cloud is designed with disaggregated storage in mind… with DAS used for server boot drives.”
The storage systems are connected to compute by high-speed Ethernet networks.

It’s more efficient than creating virtual SANs or filers by aggregating each server’s DAS in the HCI (hyperconverged infrastructure). HCI was a good approach generally, in the 2000 era when networking speeds were in the 1Gbit/s area, but “now with 100Gbit/s and 400Gbit/s coming, disassociated elements can be used and this is more efficient.”
HCI’s use is limited, in Giancarlo’s view, by scaling difficulties, as the larger an HCI cluster becomes, the more of its resources are applied to internal matters and not to running applications.
Faster networking is a factor in a second point he made about data virtualization: “Networking was virtualized 20 years ago. Compute was virtualized 15 years ago, but storage is still very physical. Initially networking wasn’t fast enough to share storage. That’s not so now.” He noted that applications are becoming containerized (cloud-native) and so able to run anywhere.
He mentioned that large datasets at petabyte scale have data gravity; moving them takes time. With Kubernetes and containers in mind, Pure will soon have Fusion for traditional workloads and Portworx Data Services (PDS) for cloud-native workloads. Both will become generally available in June.
What does this mean? Fusion is Pure’s way of federating all Pure devices – on-premises hardware/software arrays and off-premises, meaning software in the public cloud – with a cloud-like hyperscaler consumption model. PDS, meanwhile, brings the ability to deploy databases on demand in a Kubernetes cluster. Fusion is a self-service, autonomous, SaaS management plane, and PDS is also a SaaS offering for data services.
We should conceive of a customer’s Pure infrastructure, on and off-premises, being combined to form resource pools and presented for use in a public cloud-like way, with service classes, workload placement, and balancing.
Giancarlo said “datasets will be managed through policies” in an orchestrated way, with one benefit being the elimination of uncontrolled copying.
He said: “DMBSes and unstructured data can be replicated 10 or even 20 times for development, testing, analytics, archiving and other reasons. How do people keep track? Dataset management will be automated inside Pure.”
Suppose there was a 1PB dataset in a London datacenter and an app in New York needed it to run analysis routines? Do you move the data to New York?
Giancarlo said: “Don’t move the [petabyte-level] dataset. Move the megabytes of application code instead.”
A containerized application can run anywhere. Kubernetes (Portworx) can be used to instantiate it in the London datacenter. In effect, you accept the limits imposed by data gravity and work with them, by moving lightweight containers to heavyweight data sets and not the inverse. You snapshot the dataset in London and the moved containerized app code works against the snapshot and not the original raw data.
When the app’s work is complete, the snapshot is deleted and excess data copying avoided.
Of course data does have to be copied for disaster recovery reasons. Replication can be used for this as it is not so time-critical as an analytics app needing results in seconds rather than waiting for hours as a dataset slowly trundles its way through a 3,500-mile network pipe.
Giancarlo claimed: “With Pure Fusion you can set that up by policy – and keep track of data sovereignty requirements.”
He said that information lifecycle management ideas need updating with dataset lifecycle management. In his view, Pure needs to be applicable to the very large-scale dataset environments, the ones being addressed by Infinidat and VAST Data. Giancarlo referred to them as up-and-comers, saying they were suppliers Pure watched although he said it didn’t meet them very often in customer bids.
Referring to this high-end market, Giancarlo said: “We clearly want to touch the very large scale environment that out systems haven’t reached yet. We do intend to change that with specific strategies.” There was no more detail said about that. We asked about mainframe connectivity and he said it was relatively low on Pure’s priority list: “Maybe through M&A but we don’t want to fragment the product line.”
Pure’s main competition is from incumbent mainstream suppliers such as Dell EMC, Hitachi Vantara, HPE, IBM, and NetApp. “Our main competitive advantage,” he said, “is we believe data storage is high-technology and our competitors believe it’s a commodity… This changes the way you invest in the market.”
For example, it’s better to have a consistent product set than multiple, different products to fulfill every need. Take that, Dell EMC. It’s also necessary and worthwhile to invest in building one’s own flash drives and not using commodity SSDs.
Our takeaway is that Pure is bringing the cloud-like storage consumption and infrastructure model to the on-premises world, using the containerization movement to its advantage. It will provide data infrastructure management facilities to virtualize datasets and overcome data gravity by moving compute (apps) to data instead of the reverse. Expect announcements about progress along this route at the Pure Accelerate event in June.