


Startup Groq has developed an machine learning processor that it claims blows GPUs away in large language model workloads – 10x faster than an Nvidia GPU at 10 percent of the cost, and needing a tenth of the electricity.
Update: Groq model compilation time and time from access to getting it up and running clarified. 30 Jan 2024
Groq founder and CEO Jonathan Ross is an ex-Google engineer who ran the founding team for its tensor processing unit (TPU), which he designed. That chip was good for AI training, but less suited to AI inference workloads.
He started up Groq in 2016 to develop a compiler for deep learning inference tasks and a chip on which to run the compiled task models – because CPUs are not powerful enough to do the job in anything approaching real time, and because GPUs are focussed on training machine learning models not on running day-to-day inferencing tasks.
A GPU, with its massive number of parallel cores, cannot run data flow or data stream operations well. Groq developed a Tensor Stream Processor (TSP) to do this much much better than either a GPU or a CPU. A research paper abstract describes the TSU’s characteristics: “The TSP is built based on two key observations: (1) machine learning workloads exhibit abundant data parallelism, which can be readily mapped to tensors in hardware, and (2) a simple and deterministic processor with producer-consumer stream programming model enables precise reasoning and control of hardware components, achieving good performance and power efficiency.”
The paper explains: “The TSP uses a tiled microarchitecture that allows us to easily scale vector size to the underlying tensor shapes which they represent. Tensor computations are performed using a streaming processing model where computational elements are arranged spatially by function to take advantage of dataflow locality as tensors flow past.”
“It falls on the compiler to precisely schedule instructions so as to use the hardware correctly and efficiently.”
The TSP is likened to an assembly line in a factory with repetitive processing of incoming components – such as text questions – in a staged sequence of steps as the data task flows through the chip’s elements to produce a finished result – text answers – in a dependable time. These elements are memory units interleaved with vector and matrix deep learning functional units.

A GPU in this sense is roughly like the data task staying in one place, with workers coming to it to apply the processing steps. It produces the same result, but not in such an organized sequential way and therefore not as efficiently as the TSP’s assembly-line-style volume processing.
When the eruption of interest in Generative AI started a year ago, Ross realized that the TSP was ideal for running LLM inferencing tasks. Everybody knows what language is, but hardly anyone knows what a tensor is (see bootnote) so it was renamed the Language Processing Unit (LPU) to increase its recognizability. He reckons Groq’s LPU is the IT world’s best inferencing engine, because LLMs are tuned to run on it and so execute much faster than on GPUs.
LLM programming
What Groq has done is to develop a way to compile large language models (LLM), treating them almost like a written software program, and then design and build chip-level hardware – the LPU – on which to run the compiled LLM code, executing generative AI inferencing applications. This hardware is deterministic, and will deliver predictable results in terms of performance and real-time response faster than GPUs at a fraction of the cost. The compiler delivers predictable workload performance and timing.

Unlike GPUs, the LPU has a single core and what Ross called a TISC or Temporal Instruction Set Computer architecture. It doesn’t need reloading from memory as frequently as GPUs. Ross told a press briefing in Palo Alto: “We don’t use HBM (High Bandwidth Memory). We don’t need to reload processors from memory, as GPUs do from HBM, which is in short supply and more expensive than GPUs.”
A corollary of this is that the LPUs don’t need fast data delivery from storage via protocols like Nvidia’s GPUDirect, as there is no HBM in a Groq system. The LPU uses SRAM and Ross explained: “We have about 20x faster bandwidth to our memory than GPUs have to HBM.” Also, the data used in an inference run is miniscule compared to the massive size of a data set in a model training run.
Because of this, Ross argued, “We’re much more power efficient. We make fewer reads from external memory.” The LPU uses less electrical energy than an Nvidia GPU to run an inferencing task.
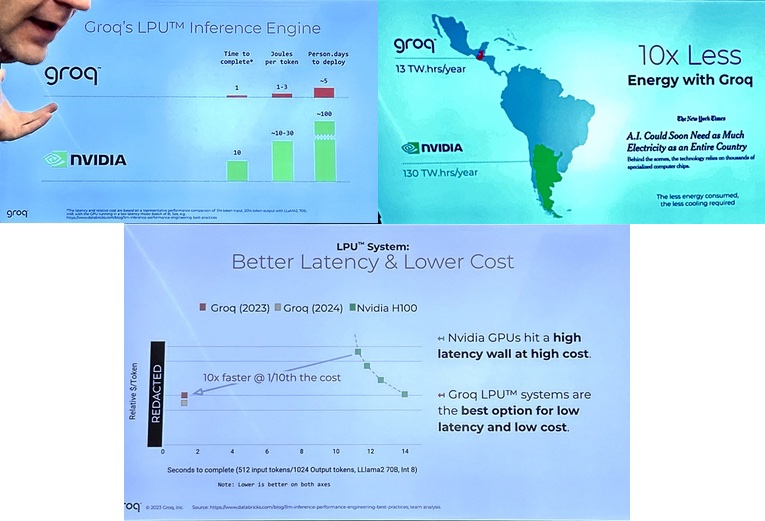
Performance is measured as latency and throughput, meaning tokens per second (TPS). A token is the text data processing unit in an LLM – a phoneme, letter or letters, word or group of words.
Groq’s LPU has a higher TPS rating than an Nvidia GPU, so taking less time to complete a request, and it also responds more quickly, having lower latency. Ross says that his LPU is dependably fast in its response, making real-time conversations reliably possible. He says that more than 80 LLMs have been compiled for Groq, and the hallucination problem will go away.
Model compilation is fast, with multiple LPU chips applied to the task, and it takes a matter of hours. The time needed to gain access to the model, compile it, and getting it up and running on Groq is 4 to 5 days:
- Llama 65 billion – five days
- Llama 7 billion – five days
- Llama 13 billion – five days
- Llama-2 70 billion – five days
- Code Llama 34 billion – four days.
Ross wants to democratize LLM inferencing, driving down the cost of LLM inferencing compute to near-zero. He reckons “2024 is the year that AI becomes real.”
There is a hierarchy of Groq products. There’s the GroqChip processor (LPU), GroqCard accelerator, GroqNode server with 2x X86 CPUs and 8x LPUs, and GroqRack compute cluster made up from 8x GroqNodes plus a Groq Software Suite.
From the storage point of view, if Groq’s LPU is accessible from or deployed at LLM inferencing sites there will be no need for Nvidia GPUDirect-class storage facilities there, as the LPU doesn’t need high-speed storage to feed a GPU’s high bandwidth memory there. The promise of Groq is that it could remove GPUs from the LLM inferencing scene with its GPU-killing inferencing chip and model compiling software.
Bootnote 1
Groq was started up in 2016 in Mountain View by CEO Jonathan Ross, originally the CTO, and has had five rounds of funding with a total of more than $362.6 million raised so far. The funding details we know are:
- April 2107: Venture round from three investors – $10.3 million
- July 2018: B-round from one investor – unknown amount
- September 2018: Venture round from five investors – $52.3 million
- August 2020: Venture round from six investors – unknown amount
- April 2021: C-round from 16 investors – $300 million.
Ross said a further funding round has completed with total funding less than $1 billion but Groq’s valuation sits at more than $1 billion. Asked how he would react to acquisition approaches, Ross replied: “If somebody makes a reasonable offer we’ll be unreasonable. If somebody makes a unreasonable offer we’ll be reasonable.”
The startup will sell its hardware and also provide private cloud Groq-as-a-service facilities.
And the name Groq? It’s a riff on the word grok invented by scifi writer Robert Heinlein, meaning to understand something.
Bootnote 2
A tensor, in mathematics, is an algebraic entity representing a multi-linear relationships between other algebraic entities involved in a so-called vector space. This is a group or set of elements – called vectors – which can be added together and/or multiplied (scaled).
A vector, in engineering-speak, is a number with magnitude or distance added to it. A number with a things or units attached to it is called a scalar. For example, three pears or three kilometers. A vector is a scalar number with a magnitude or direction added – three kilometers south for example. A NASA document discusses this in much more detail.





