The Flash Memory Summit is renaming itself to the Future of Memory and Storage, conveniently keeping the FMS acronym.
FMS 2023 was held in August at the Santa Clara conference center in Silicon Valley, showcased 95 exhibitors, and drew in more than 3,000 visitors. It was the eighteenth occurrence of this annual and near-iconic conference in the memory and flash memory world, and attracts world-class technology expert presenters and panelists, and leading-edge exhibitors. In fact, the show has become the world’s largest such conference and exhibition.
Kat Pate.
Kat Pate, FMS CEO, said: “Over the past few years, we have welcomed storage and related applications to FMS and the event has grown. We are pleased to make it official by rebranding the event. We know this change will bring continued growth for FMS, and we look forward to welcoming new companies.”
The show organizers say the intention is to encompass all volatile and persistent memory and storage applications. This is because, they say, the memory and storage industry is undergoing rapid technology advancements in the artificial intelligence and machine learning, data analytics, high performance computing, cloud computing services, automotive and even outer-space application areas. FMS organizers want the event to bridge the gap between cutting-edge memory and storage solutions, and the demands of emerging use cases and applications.
FMS 2024 is set to feature dedicated sessions and discussions on the symbiotic relationship between memory-storage technologies and AI applications. Experts in their field will deliver keynote addresses and participate in panel discussions, providing insights into the evolving memory and storage technology landscape.
The conference and exhibition will put the spotlight on the latest products and systems in memory and storage, giving attendees insights into future trends and technological breakthroughs in the industry. Attendees can also expect decent networking opportunities with fellow professionals as well as analysts, media, and industry leaders from diverse storage-related fields, encouraging collaboration and innovation.
Mark your calendars; the next FMS event will take place at the Santa Clara convention center from August 6 to 8 this year. Find out more about at the FutureMemoryStorage.com website.
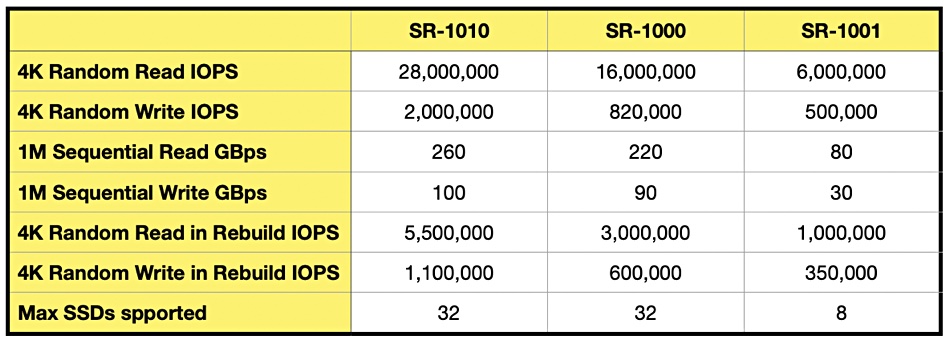
GPU-powered RAID card provider Graid has developed an entry-level card: the SR-1001.
Graid until now has had two products: the SR-1000, and the SR-1010. Both support up to 32 SSDs but the SR-1000, Graid’s first card, has a PCIe gen 3 interface while the SR-1010 uses PCIe gen 4 and is therefore faster. They are for use in enterprise datacenters. Unlike traditional RAID cards that connect directly to storage drives, Graid’s SR, or SupremeRAID, products are PCIe-connected peers on the host’s motherboard and are not in the data path.
Leander Yu, President and CEO of Graid Technology, has this to say about the launch on Thursday: ”As NVMe SSDs play a crucial role in cloud, core, and edge infrastructure, the demand for enhanced data protection without compromising performance is evident. SupremeRAID SR-1001 addresses this need by delivering best-in-class performance and airtight data protection while optimizing throughput, parallelism, and latency, ensuring seamless performance at the edge.”
The SR-1001 is a limited version of the SR-1000 in that it supports just 8 SSDs and has lower performance than the other two cards, as the table below summarizes:
The SR-1001 has the same code base as its siblings. It is intended for use by tower and edge servers, professional workstations, and gaming desktops, running apps such as CAD, video editing, IoT workloads, and games.
Thomas Paquette, senior veep and GM at Graid, said the biz has plans to increase the number of SSDs supported by its cards later this year and will also add PCIe 5 support. That will send performance higher as well, we’re promised. He said Graid has no plans to add deduplication or compression or other data services to the hardware. Its products are intended to be NVMe SSD failure protection cards and not computational storage devices.
Graid believes its performance numbers versus legacy RAID cards, such as Broadcom’s 9600 and 9500 offerings, are superior. That said, the SR-1001 is said to be slightly less performant than Broadcom’s 9600 gear on the rebuild IOPS front but apparently convincingly better at sequential throughput.
The SupremeRAID cards also beat software RAID products, which use host server CPU cycles for RAID parity calculations and can limit overall server application performance.
The SR-1001 extends Graid’s market coverage. It has also developed a UEFI card product to protect server boot SSDs, and a fan-less product to reduce card thickness. Its market prospects look good, with Paquette telling IT journalists touring Silicon Valley this month that its AI/ML, edge computing, speed-dependent big data analytics, cloud service provider, and telecom & 5G infrastructure market segments are all growing.
He said the company had completed an A+ VC round last year, raising less than half the $15 million it pulled in from a 2022 A-round. We believe its total funding is around $20 million. It will probably run a B-round later this year to pay for business infrastructure expansion, such as hiring more sales and marketing people. Paquette said: “When we get to that point as a company, we would have additional investors and would naturally cede some control which is typical as venture backed companies progress through different phases of growth.”
Check out a datasheet-class SR-1001 brochure here.
Our view:
No competitors to Graid have emerged, meaning other GPU-powered RAID cards, since it launched its product family in 2021. The SupremeRAID series is said to have a substantial performance advantage over leading RAID card supplier Broadcom’s products, and leaves software RAID behind as well. It has a substantial performance runway ahead as PCIe gen 5 servers with a gen 5 SupremeRAID card will go even faster than PCIe gen 4 server/card combinations. Unless Broadcom and other hardware RAID card suppliers adopt the same GPU-powered technology, or an equivalent whatever that might be, they will stay in the relative low performance area.
Graid has taken in around $20 million in funding and a B-round would almost inevitably increase its valuation from the A-rounds. We here at B&F think an IPO is unlikely, the technology being quite niche, but an acquisition looks a likelier prospect. This is just our gut feeling to be clear. We have no inside knowledge. The place we get to with this is a RAID card supplier, such as Broadcom, feeling the competitive heat and buying Graid. What would it cost? We’re in string length estimation territory at this point. Suppose a 5x multiple on the VC funding was taken as a starting point; that’s $100 million. But a B-round valuation could put a higher price on the company; say $500 million or more. It’s going to be an interesting year.
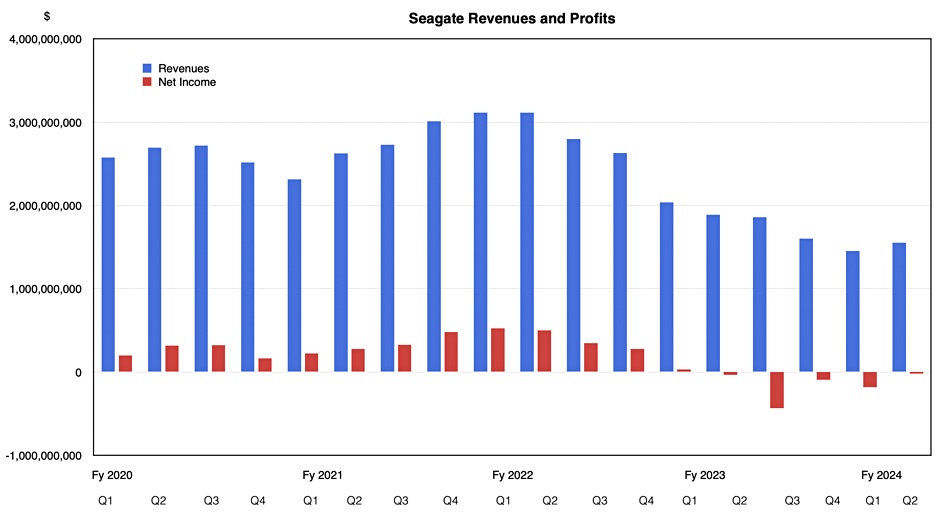
Spinning-disk slinger Seagate this week signaled its revenue recovery has begun with a sequential revenue upturn in its second fiscal 2024 quarter.
It reported [PDF] revenues of $1.56 billion, down 17 percent year-on-year but up seven percent from the previous quarter and its first such Q-to-Q upturn after seven Q-to-Q declines in a row. The biz recorded an overall loss of $19 million, much reduced from the year-ago $33 million loss and especially from last quarter’s $184 million loss.
CEO Dave Mosley on an earnings call with analysts said: “Revenue of $1.56 billion was led by sequentially improving cloud nearline demand and a seasonal uptick in consumer drives, offset partially by the decline in VIA sales that we anticipated. … These performance and demand trends affirm our expectation for the September quarter to be the bottom of this prolonged down cycle.”
VIA refers to the video surveillance market.
Financial summary:
Operating cash flow: $169 million
Free cash flow: $99 million
Gross margin: 23.3% vs 23.6% a year ago
Diluted EPS: -$0.09/share vs $10.132/share a year ago
Cash and cash equivalents: $787 million
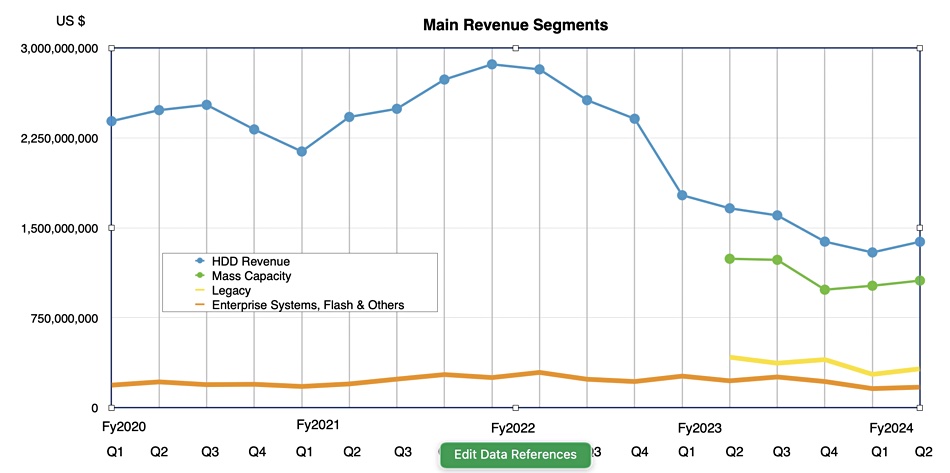
Seagate made $1.38 billion from disk drives and $171 million from enterprise systems and flash drives in the three months to December 29. It said it shipped 95 EB of capacity compared to 89.6 EB last quarter and 112.5 EB a year ago. The average capacity per drive was 8.2 TB, up from 7.3 TB a year ago and 7.5 TB last quarter.
Snapshot of Seagate’s past financial performance: Mass capacity and legacy drive numbers are only available from Q2 fiscal 2023.
Mosley talked about demand trends on the earnings call, saying: “From a demand standpoint, gradual recovery within the US cloud market has started to take shape, reflecting solid progress in consuming excess inventory, along with more stable end-market behavior.
“Enterprise OEM demand trends have also stabilized within the US markets. Customer feedback still points to macro-related concerns, although IT hardware budgets are projected to modestly improve in calendar 2024, and traditional server growth is expected to resume trends that support incremental HDD demand growth in the calendar year.”
China is lagging a bit, we’re told: “Across the broader China markets, we project a relatively slower pace of recovery given the ongoing economic challenges within the region. However, some local governments announced further steps to support the region’s economy, which our customers believe will bolster local demand across mass capacity markets in China in the second half of the calendar year.”
Seagate introduced its higher capacity HAMR drives this quarter and expects volume shipments to start ramping up. It can use HAMR tech to reduce the platter count in today’s mid-to-low capacity drives and so improve its cost structure. This should lead to increased profitability as the drive recovery gets under way and it ships more drives overall.
Mosley continued: “We are rapidly nearing qualification completion with our initial hyperscale launch partner. The qualification has gone very well, and we are working with this customer at their request to fully transition future Seagate demand to the three-plus terabyte per disk platform.”
This means that other hyperscale drive users have not yet qualified the HAMR drives.
He talked about the manufacturing ramp and getting more hyperscale wins: “Volume ramp is starting in the March quarter according to plan with a goal to ship about 1 million units in the first half of this calendar year. We then expect to continue to ramp through the balance of the calendar year, and we are currently broadening our customer engagements. Based on their planned timelines, we expect to complete qualifications with a majority of US hyperscalers and a couple of global cloud customers during calendar 2024.”
Mosley explained how HAMR will improve Seagate’s drive manufacturing costs: “As we scale areal density to four terabytes per disk, this enables extremely cost-effective product offerings in the low to midrange capacity points used by a majority of our enterprise … customers. With four terabytes per disk, we used half the number of heads and disks to produce a 20-terabyte drive. Prototypes are already working in our labs with revenue planned for the second half of calendar 2025.”
The manufacturer confirmed it expects its second generation Mozaic 3+ 4TB/platter HAMR drives, with 40TB or more capacities, to ship in the second half of next year.
Seagate has just launched a 24TB IronWolf Pro NAS drive using its perpendicular magnetic recording (PMR) technology, not HAMR. This will be one of its last PMR drives as HAMR technology will be used across the board.
The revenue outlook for the next quarter is $1.65 billion+/- $150 million which is 11.3 percent down year-on-year. Seagate’s year-on-year quarterly revenue decline is easing as its recovery gets underway. CFO Gianluca Romano said: “We expect incremental improvements in mass capacity demand from both cloud and enterprise customers to more than offset seasonal-related decline in VIA and the legacy markets.”
Jill Stelfox has departed as CEO and executive chairwoman at cloud file services collaborator Panzura, with former CRO and Chief Transformation Officer Dan Waldschmidt moving into the top spot in her stead.
Panzura started out as a file sync and share business, but didn’t grow enough. It evolved into a cloud-based file data services supplier after the company was refounded by Jill Stelfox who led a private equity buyout by Profile Capital Management in May 2020. The firm was restructured and then grew its business in competition with CTERA and Nasuni.
Dan Waldschmidt
Waldschmidt said in a statement: “I am incredibly proud of the impressive growth that this team has achieved to date. However, our ambitions are higher and the impact we plan to deliver for the enterprise is much greater. We are confident we can move even faster to provide customers with unrivaled value, security, visibility, and control of their stored data.”
Panzura chairman and Profile Capital Management president Ben Chereskin said: “Dan is well positioned to progress Panzura into a leading enterprise-grade business platform, and it is a natural transition given his deep industry experience and intimate knowledge of the company.”
Waldschmidt joined Panzura in 2020 as part of Stelfox’s team, where Panzura says he played a key role of crafting the strategy for revenue generation and moving Panzura into the enterprise market. As CRO, he led a 150 percent year-over-year increase in the customer base. Waldschmidt also guided 288 percent revenue growth over three years, 125 percent net retention, and maintained 98 percent brand loyalty. He negotiated agreements with 84 partners, and successfully developed and deployed an international revenue expansion plan.
Jill Stelfox
He became the Chief Transformation Officer in April last year. In a LinkedIn post he said: “With Panzura revenue established at record levels, I turned my focus to combining strategic foresight with effective implementation to lead significant improvements in operational efficiency and accelerated service delivery. We are successfully navigating a comprehensive digital transformation, strengthening Panzura’s standing in the market and elevating our customer experience.”
And Stelfox? A Panzura spokesperson said: “Jill has moved on from the firm and we wish her the best in her future endeavors.” Waldschmidt said: “I want to thank my co-refounder, Jill Stelfox, for her service to the company as CEO. Jill and I came into the company together and we achieved significant progress.”
Bootnote
Waldschmidt is an author and elite ultra-marathon runner, holding a record for running the equivalent elevation of Mount Everest in a single attempt.
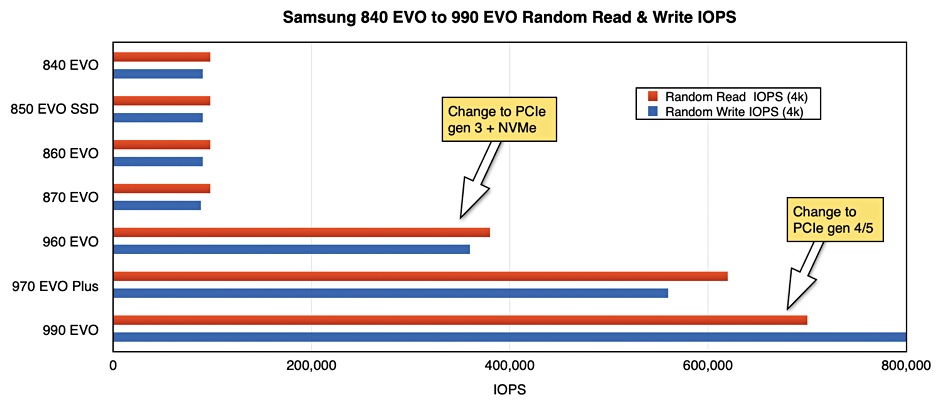
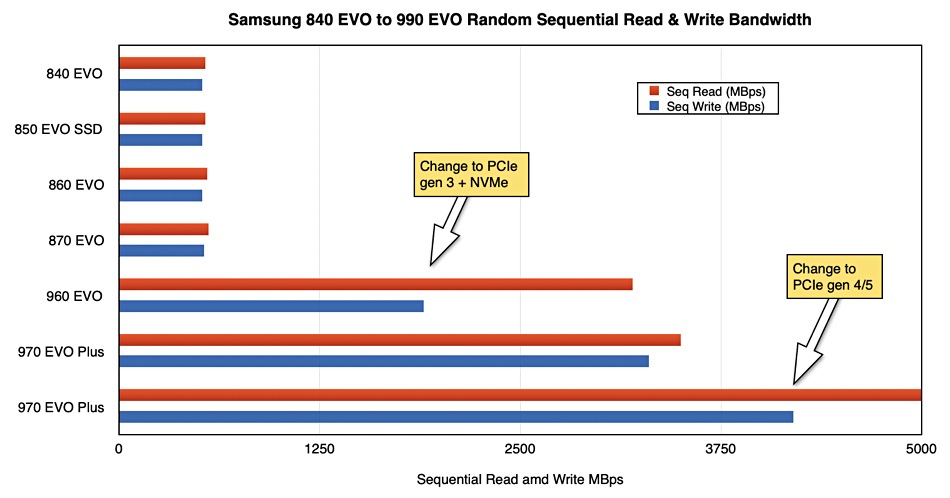
Samsung has launched a hybrid gumstick SSD, the 990 EVO, which supports both PCIe gen 4 and 5.
The consumer-grade SSD EVO line started with the 840 EVO in 2013, with its SATA interface, 2.5-inch format, and TLC NAND, and progressed through 860 and 870 generations to the M.2 gumstick format. The 860 used 32-layer 3D V-NAND and then 64-layer, while the 870 EVO jumped to 128-layer NAND. After that it stepped up to the PCIe gen 3 interface with the 960 EVO in 2016. This provided a performance boost and was followed by the 970 EVO Plus.
Now Samsung has adopted a combined PCIe gen 4/5 design but with restrictions affecting its PCIe gen 5 performance.
Chart showing how random read and write IOPS change across Samsung EVO drive generations
The drive comes with 1 or 2 TB capacities on a single sided M.2 2280 card. In its PCIe gen 4 guise it has four lanes and supports NVMe v2.0. The performance maxes out at 700,000/800,000 random read/write IOPS with a 5,000 MBps sequential read top speed and 4,200 sequential write top speed.
And how sequential read and write bandwidth changes across Samsung EVO drive generations
The IOPS is nothing special with plenty of other PCIe gen 4 M.2 card drives exceeding 1 million IOPS. Ditto the sequential bandwidth.
The oddity is that these performance figures don’t change when using the PCIe gen 5 interface. That’s because there are only two gen 5 lanes. Although each gen 5 lane should have twice the bandwidth of a PCIe gen 4 lane, the halving of the lane count means the overall performance doesn’t change at all.
This does mean the drive could be used in a gen 4 PCIe laptop now and in a gen 5 model later. That may be convenient for some but the drive’s performance is lackluster compared with other PCIe gen 5 M.2 SSDs. For example, Seagate’s FireCuda 540, with the same capacity levels, offers 1.5 million random read and write IOPS, and 10,000 MBps for both sequential reads and writes. Crucially, it has four gen 5 PCIe lanes, not just two.
Moving away from raw performance, we note that the 990 EVO uses its host’s DRAM as a buffer and has an onboard SLC cache for faster data IO – just as well as without that its performance would be even worse. Samsung says the 990 EVO has faster performance than the 970 EVO and, considering the PCIe bus level jump, so it should. However, view this 990 EVO as a PCIe gen 4-class drive that masquerades as a gen 5 PCIe drive because, in our opinion, it doesn’t deliver on the standard’s potential.
Samsung says it uses TLC flash but doesn’t reveal the drive’s layer count. Tech PowerUp reckons it’s a boosted gen 6 V-NAND with 133 layers instead of the standard 128.
The 990 EVO has a Samsung controller and a 0.3 drive writes per day endurance for its five-year warranty, meaning 600 total terabytes written for the 1 TB model and 1,200 total terabytes written for the 2 TB version. It supports 256-bit AES and TCG/Opal v2.0 encryption. The drive costs $124.99 for 1 TB and $209.99 for 2 TB.
Apple’s Vision Pro virtual reality headset can be fitted with up to a terabyte of flash storage to store the content its wearers will no doubt want to engage with.
Tech specs were revealed by Apple on its website and the $3,499 base priced pair of extremely fancy glasses come with 256 GB of NAND – the same as the MacBook Air on which I’m typing this article. They can be upgraded to 512 GB for another $200 and 1 TB for $400.
David Ngo
…
Cloud and backup storage provider Backblaze has hired David Ngo as chief product officer (CPO). He was previously global CTO for Metallic, Commvault’s SaaS-based backup service. Ngo will guide overall product direction for existing customers as well as emerging needs as the firm continues moving upmarket. Backblaze has more than 500,000 customers and 3 EB of data storage under management.
…
Victoria Grey.
Falconstor has announced the availability of StorSafe v11.13 including StorSight – FalconStor’s hybrid cloud data protection management console – tailored for IBM Power environments that span on-premises to multi-cloud instances. It says StorSafe v11.13 brings significant enhancements, solidifying its position as the de facto standard for IBM Power data protection and recovery optimization, including expanded support for Power10. Furthermore, marketing expert Victoria Grey has left the CMO role at Nexsan and joined FalconStor as its head of marketing. Grey says she is a fractional CMO. It’s promising news for Falconstor and rewarding for the efforts of CEO Todd Brooks and his team.
…
NAKIVO Backup & Replication v10.11 has expanded backup, recovery, and monitoring capabilities:
Enhanced IT monitoring with alarms and reporting for VMware host, VM, and datastore for suspicious activity
Backup for Oracle RMAN on Linux
File System Indexing feature to search for and recover individual files or folders from VMware and Hyper-V VM backups
Backup from HPE Alletra and Primera Storage Snapshots – customers can directly back up their VMware VMs stored on these devices from storage snapshots, eliminating the need for regular VM snapshots
Microsoft 365 backup functionality – adding support for additional types of mailbox items in Exchange Online:
In-Place Archive mailboxes
Litigation Hold items
In-Place Hold items
Universal Transporter (not a data mover) – customers can discover and protect multiple workloads (Hyper-V VMs, physical servers, Oracle databases, and tape devices) located on the same host, from the NAKIVO Backup & Replication interface. v10.11 is available for download.
…
Nexsan has downsized its NV10000 unified array with an entry-level NV6000 for small and medium business customers and added immutable snapshots to its Unity OS. The NV10000 was launched in April 2022 and is a 2RU x 24-slot chassis extensible with up to eight JBODS with a maximum of 480 drives. It supports both disk and SSD, with a FASTier SSD caching facility, and can be deployed in an all-flash configuration. Nexsan also supplies E-series high-density/high-capacity and Beast high-density arrays, and the Assureon archival array.
Andy Hill, Nexsan’s EVP, said in a statement: “If data is the new oil, it is more imperative than ever to make sure you protect your organization’s data from being siphoned off by the unscrupulous.” The latest release of the Unity OS, v7.0, adds an immutable snapshot feature. It already had S3 object-locking support and disk-to-disk-backup-capabilities via Assureon integration.
Unity NV6000
The NV6000 chassis is twice the size of the NV10000 enclosure at 4RU with 60 drive bays. There can be two 4RU JBOD expansion chassis, taking the drive count total to 180. The base chassis holds a maximum of 1.12PB raw capacity while adding in the two expansion JBODs takes that to 3.36PB. The bigger NV10000 goes up to 9.6PB with disk drives and 368PB with NVMe SSDs.
Data access protocols consist of SAN (Fiber Channel, iSCSI), NAS (NFS, CIFS, SMB 1.0 to 3.0, FTP) and S3 object. Connectivity support includes 16/32GB FC, and 10/25/40/100GbE. There is up 20GB/sec bandwidth and two redundant controllers, redundant power supplies and RAID.
Andy Hill tells us: “The Unity NV6000, designed as a mid-tier unit, caters to the needs of small to mid-market end-users. This decision aligns with our commitment to providing cost-effective solutions without compromising quality. Our NV10000 model, equipped with NVMe SSDs, is ideal for users with higher performance requirements. Notably, the NV10000 remains competitively priced, typically about 30% less than similar offerings from Pure, NetApp, and Isilon. By differentiating the NV6000 and NV10000 in this manner, we ensure that our product lineup meets a diverse range of customer needs while maintaining exceptional value in both segments.”
…
AI and Nvidia distribution specialist PNY and PEAK:AIO have signed a distribution agreement, aiming to provide AI infrastructure systems to professionals in EMEA, with details in a PNY blog. It says: “This partnership will allow them to harness the full potential of AI to benefit from a complete solution keeping GPUs fast, priced for AI and simple to use.”
…
Seagate issued its fifth annual Diversity, Equity, and Inclusion (DEI) report. It outlines Seagate’s continued progress in the areas of Representation, Inclusion, Social impact, and Equity (RISE).
Representation – Increased representation of women across all levels of leadership (33.6 percent global women in leadership, up more than 3 percent since FY21).
Inclusion – Added new employee-led resource groups tallying 29 chapters in seven countries with more than 3,700 participants worldwide. New chapters include Seagate Women’s Leadership Network in India and the Military Employee Resource Group in Fremont, CA.
Social – Engaged in community outreach with a focus on STEM awareness across global footprint.
Equity – Enhanced equitable and inclusive hiring practices resulting in 325 global interns onboarded including students from the National Society for Black Engineers and focused efforts to recruit and engage a veteran workforce more effectively.
Seagate, with about 30,000 employees in fiscal 2023 = spanning 41 locations across the globe and countless cultures – says it holds an unwavering commitment to fostering a diverse, equitable, and inclusive workplace. It says it is dedicated to championing a core value of inclusion in every facet of its operations.
…
Veritas Technologies says the Veritas Application Mobility Service makes it easier for enterprises to migrate or deploy new applications in the public cloud by automating the process, claiming this reduces the time needed from months to as little as 15 minutes. The service is now available to all customers and includes support for Azure. There is a 60-day trial at no cost and participants gain access to best-practice application configuration templates generated by the service to automatically instantiate their applications in the cloud. As the service is based on Veritas Alta Enterprise Resiliency, they will get built-in application resiliency as part of their trial license. The trial can be converted into a paid subscription.
…
TD SYNNEX has a new distribution agreement with cloud storage provider Wasabi covering the EMEA region. The portfolio is now live for TD SYNNEX partners in the UK, Ireland, Germany, Austria, France, and Benelux, with remaining countries in the distributor’s European footprint to follow in the coming weeks. This partnership expands upon the existing Wasabi and TD SYNNEX agreement in the United States.
…
Western Digital stock rose 5.2 percent in value after Morgan Stanley raised its price target from $52 to $73, stating: “The valuation disparity between Western Digital and peers is extremely compelling, particularly in light of the second-half separation of the memory business, which should unlock the sum of the parts values. Business is getting better at a rapid rate, and there are pluses and minuses to the NAND cycle.”
…
Software RAID supplier Xinnor has a strategic partnership with European HPC integrator MEGWARE, which can use Xinnor’s xiRAID engine, designed to handle the high level of parallelism of NVMe SSDs. André Singer, CEO at MEGWARE, said: “We invested time in qualifying Xinnor’s xiRAID, as demand for faster storage has never been higher and we can satisfy it with a very elegant solution like xiRAID.” Customers interested in evaluating the system based on xiRAID can physically and remotely access MEGWARE’s demo lab in Germany.
…
A3 Communications, the storage PR specialist, has created a storage technology milestone infographic covering the last 20 years:
S3 cloud storage provider Wasabi is buying Curio for its AI-powered video content indexing technology, and will offer a focussed entertainment and media industry storage tier.
Wasabi has styled itself as a hyper-focussed cloud storage provider, offering a single tier of S3 storage with no extra tiers – such as deep archive or fast access offerings. That is about to change with the addition of a smart video content storage tier based on acquired Curio AI technology, IP and brand from GrayMeta.
David Friend, Wasabi.
Wasabi CEO David Friend provided a statement: “A video archive without detailed metadata is like a library without a card catalog. This is where AI comes in. AI can find faces, logos, objects, and even specific voices. Without it, finding exactly the segments you are looking for requires tedious and time-consuming manual effort. The acquisition of Curio AI will allow us to revolutionize media storage.”
Up until now, videos stored in cloud object storage could have content metadata tags added manually – such as “3 minutes 10 seconds: foot fault” in a tennis match. With literally hundreds of thousands of stored videos, amounting to hundreds of exabytes of video archives, the problem of adding content metadata tags has been immense. Without such tags, the ability to find and re-use video content has been excessively difficult.
Curio’s AI technology scans videos and generates metadata about segments containing people, places, events, emotions, logos, landmarks, background audio and speech – which it can transcribe in more than 50 languages. It will change the status of effectively stranded segments to being online and searchable.
Aaron Edell.
GrayMeta CEO Aaron Edell will join Wasabi and become SVP for AI and Machine Learning. He boasted: “AI-powered storage will allow Wasabi customers to instantly find exactly what they need amongst millions of hours of footage and unleash the value in their archives. We believe this will be the most significant advance in the storage industry since the invention of object storage.”
Edell was GrayMeta’s first employee, returning as CEO and president in February last year after stints at AWS and Veritone. Eleven months later he’s off and taking Curio with him. Curio-skilled GrayMeta employees Jesse Graham, Scott Sharp and Piotr Rojek will also move to Wasabi.
This Wasabi acquisition will prompt a flurry of similar initiatives to add AI-powered content metadata generation by other entertainment and media asset management suppliers, covering both video and still images.
Wasabi did not reveal the terms of the Curio AI acquisition deal. Wasabi expects to unveil its Curio-powered service in the spring. GrayMeta will now be lead by ex-president and CEO Mark Gray, who is returning from retirement to take on the roles.
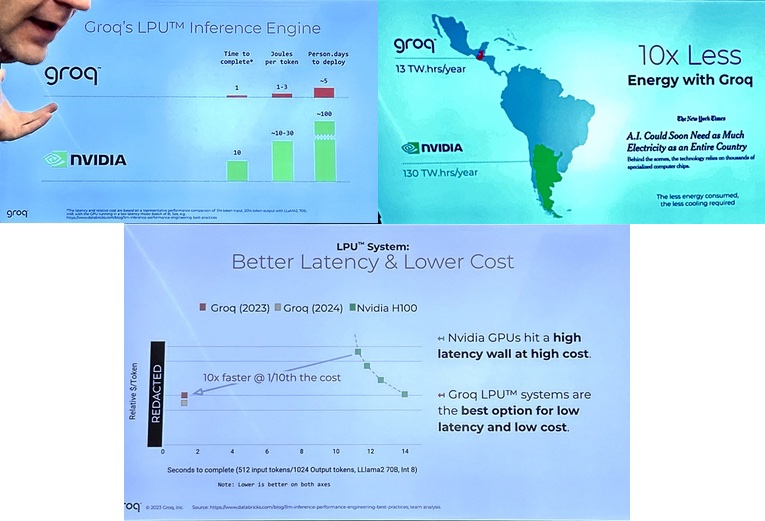
Startup Groq has developed an machine learning processor that it claims blows GPUs away in large language model workloads – 10x faster than an Nvidia GPU at 10 percent of the cost, and needing a tenth of the electricity.
Update: Groq model compilation time and time from access to getting it up and running clarified. 30 Jan 2024
Groq founder and CEO Jonathan Ross is an ex-Google engineer who ran the founding team for its tensor processing unit (TPU), which he designed. That chip was good for AI training, but less suited to AI inference workloads.
Jonathan Ross.
He started up Groq in 2016 to develop a compiler for deep learning inference tasks and a chip on which to run the compiled task models – because CPUs are not powerful enough to do the job in anything approaching real time, and because GPUs are focussed on training machine learning models not on running day-to-day inferencing tasks.
A GPU, with its massive number of parallel cores, cannot run data flow or data stream operations well. Groq developed a Tensor Stream Processor (TSP) to do this much much better than either a GPU or a CPU. A research paper abstract describes the TSU’s characteristics: “The TSP is built based on two key observations: (1) machine learning workloads exhibit abundant data parallelism, which can be readily mapped to tensors in hardware, and (2) a simple and deterministic processor with producer-consumer stream programming model enables precise reasoning and control of hardware components, achieving good performance and power efficiency.”
The paper explains: “The TSP uses a tiled microarchitecture that allows us to easily scale vector size to the underlying tensor shapes which they represent. Tensor computations are performed using a streaming processing model where computational elements are arranged spatially by function to take advantage of dataflow locality as tensors flow past.”
“It falls on the compiler to precisely schedule instructions so as to use the hardware correctly and efficiently.”
The TSP is likened to an assembly line in a factory with repetitive processing of incoming components – such as text questions – in a staged sequence of steps as the data task flows through the chip’s elements to produce a finished result – text answers – in a dependable time. These elements are memory units interleaved with vector and matrix deep learning functional units.
Groc LPU.
A GPU in this sense is roughly like the data task staying in one place, with workers coming to it to apply the processing steps. It produces the same result, but not in such an organized sequential way and therefore not as efficiently as the TSP’s assembly-line-style volume processing.
When the eruption of interest in Generative AI started a year ago, Ross realized that the TSP was ideal for running LLM inferencing tasks. Everybody knows what language is, but hardly anyone knows what a tensor is (see bootnote) so it was renamed the Language Processing Unit (LPU) to increase its recognizability. He reckons Groq’s LPU is the IT world’s best inferencing engine, because LLMs are tuned to run on it and so execute much faster than on GPUs.
LLM programming
What Groq has done is to develop a way to compile large language models (LLM), treating them almost like a written software program, and then design and build chip-level hardware – the LPU – on which to run the compiled LLM code, executing generative AI inferencing applications. This hardware is deterministic, and will deliver predictable results in terms of performance and real-time response faster than GPUs at a fraction of the cost. The compiler delivers predictable workload performance and timing.
GroqCard.
Unlike GPUs, the LPU has a single core and what Ross called a TISC or Temporal Instruction Set Computer architecture. It doesn’t need reloading from memory as frequently as GPUs. Ross told a press briefing in Palo Alto: “We don’t use HBM (High Bandwidth Memory). We don’t need to reload processors from memory, as GPUs do from HBM, which is in short supply and more expensive than GPUs.”
A corollary of this is that the LPUs don’t need fast data delivery from storage via protocols like Nvidia’s GPUDirect, as there is no HBM in a Groq system. The LPU uses SRAM and Ross explained: “We have about 20x faster bandwidth to our memory than GPUs have to HBM.” Also, the data used in an inference run is miniscule compared to the massive size of a data set in a model training run.
Because of this, Ross argued, “We’re much more power efficient. We make fewer reads from external memory.” The LPU uses less electrical energy than an Nvidia GPU to run an inferencing task.
Three iPhone screen shots as the distributed presentation slides had “Nvidia” text removed.
Performance is measured as latency and throughput, meaning tokens per second (TPS). A token is the text data processing unit in an LLM – a phoneme, letter or letters, word or group of words.
Groq’s LPU has a higher TPS rating than an Nvidia GPU, so taking less time to complete a request, and it also responds more quickly, having lower latency. Ross says that his LPU is dependably fast in its response, making real-time conversations reliably possible. He says that more than 80 LLMs have been compiled for Groq, and the hallucination problem will go away.
Model compilation is fast, with multiple LPU chips applied to the task, and it takes a matter of hours. The time needed to gain access to the model, compile it, and getting it up and running on Groq is 4 to 5 days:
Llama 65 billion – five days
Llama 7 billion – five days
Llama 13 billion – five days
Llama-2 70 billion – five days
Code Llama 34 billion – four days.
Ross wants to democratize LLM inferencing, driving down the cost of LLM inferencing compute to near-zero. He reckons “2024 is the year that AI becomes real.”
There is a hierarchy of Groq products. There’s the GroqChip processor (LPU), GroqCard accelerator, GroqNode server with 2x X86 CPUs and 8x LPUs, and GroqRack compute cluster made up from 8x GroqNodes plus a Groq Software Suite.
From the storage point of view, if Groq’s LPU is accessible from or deployed at LLM inferencing sites there will be no need for Nvidia GPUDirect-class storage facilities there, as the LPU doesn’t need high-speed storage to feed a GPU’s high bandwidth memory there. The promise of Groq is that it could remove GPUs from the LLM inferencing scene with its GPU-killing inferencing chip and model compiling software.
Bootnote 1
Groq was started up in 2016 in Mountain View by CEO Jonathan Ross, originally the CTO, and has had five rounds of funding with a total of more than $362.6 million raised so far. The funding details we know are:
April 2107: Venture round from three investors – $10.3 million
July 2018: B-round from one investor – unknown amount
September 2018: Venture round from five investors – $52.3 million
August 2020: Venture round from six investors – unknown amount
April 2021: C-round from 16 investors – $300 million.
Ross said a further funding round has completed with total funding less than $1 billion but Groq’s valuation sits at more than $1 billion. Asked how he would react to acquisition approaches, Ross replied: “If somebody makes a reasonable offer we’ll be unreasonable. If somebody makes a unreasonable offer we’ll be reasonable.”
The startup will sell its hardware and also provide private cloud Groq-as-a-service facilities.
And the name Groq? It’s a riff on the word grok invented by scifi writer Robert Heinlein, meaning to understand something.
Bootnote 2
A tensor, in mathematics, is an algebraic entity representing a multi-linear relationships between other algebraic entities involved in a so-called vector space. This is a group or set of elements – called vectors – which can be added together and/or multiplied (scaled).
A vector, in engineering-speak, is a number with magnitude or distance added to it. A number with a things or units attached to it is called a scalar. For example, three pears or three kilometers. A vector is a scalar number with a magnitude or direction added – three kilometers south for example. A NASA document discusses this in much more detail.
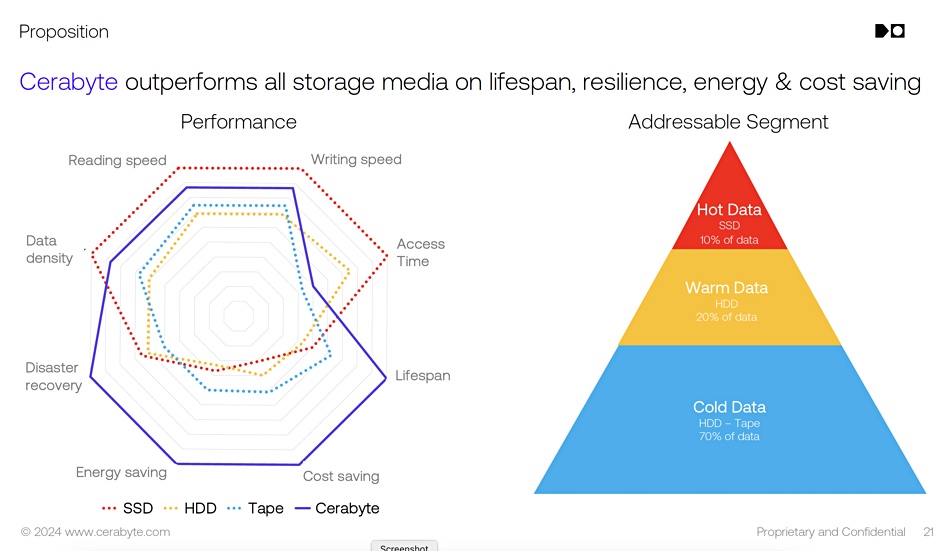
Cerabyte requires venture capital funding, partnership with a tape library system vendor, or joint development with a large-scale user to bring its glass archival storage system to market.
The company is developing technology in which a femtosecond laser punches nanoscale holes in a ceramic layer to indicate a binary number which can be read by a scanning microscope. The data is organized into QR-code squares with 2 million bits written in one laser pulse and 1 GB of data on each surface of the glass. The ceramic-coated glass slab is held inside an LTO tape-sized cartridge holding around ten slabs and stored in a robotic library system. These write-once-read-many platters can hold data for a thousand years or more, with no need for periodic refreshes. A prototype system has been built using readily available technology components and the next step is getting a commercial product funded and built.
Steffen Hellmold
CEO Christian Pflaum told an IT Press Tour audience in Palo Alto about the component ecosystem and Cerabyte’s scaling plans. He has set up Cerabyte Inc. in the US, run by director Steffen Hellmold, to help with commercialization. Hellmold said: “It was previously thought only DNA storage could develop to store exabytes per rack. But Cerabyte can scale there as well.” And its tech is more practical and closer to productization.
Blocks and Files discussed three productization routes with Cerabyte: VC funding to pay for product manufacturing and go-to-market business arrangements, partnering with an existing tape library systems vendor, or, as Pflaum and Hellmold suggested, partnering with an end user.
Such an exabyte-scale user would be facing the prospect of ongoing expensse due to tape’s need for periodic content refreshes (resilvering). Tape libraries also occupy appreciably more floorspace than a Cerabyte system for a given amount of data.
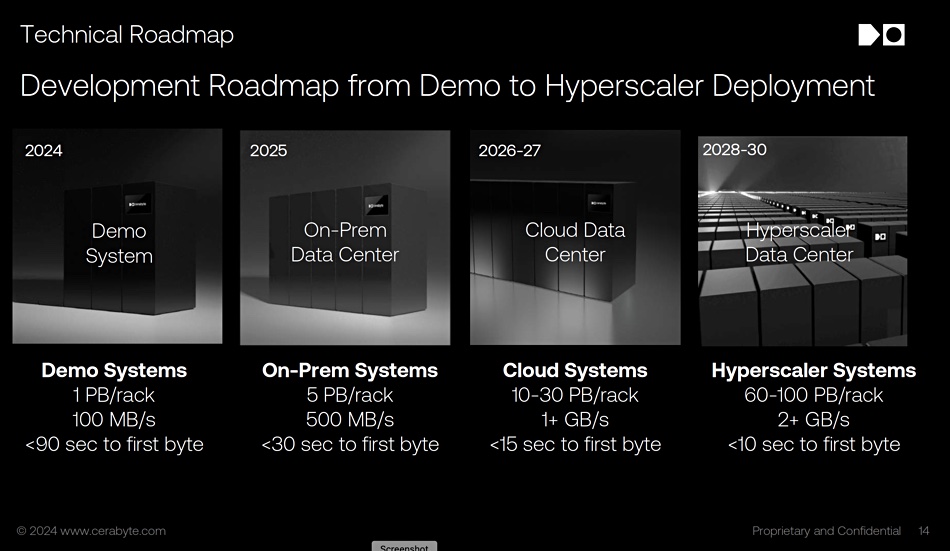
A large archive customer could make significant savings in the running costs of an archive by selecting Cerabyte technology instead of tape. Cerabyte could be productized in around a year, whereas DNA storage is years away from commercialization.
Cerabyte technology roadmap
Pflaum and Hellmold said Microsoft’s Project Silica, which stores data as nanoscale voxels in a silica glass slab, is much more complex than Cerabyte’s technology, requiring higher precision instruments. Cerabyte considers that its technology represents the nearest and most practical improvement on tape archiving – which is far from ideal for exabyte-level archives.
As for disk drive archives, they are impractical as the disk drives would need replacing every five years, according to Pflaum. They would last longer if spin-down archiving is used, but Cerabyte would have a significant edge on density and hence datacenter floorspace needs.
Hellmold said large scientific research institutions like CERN could be prospects for joint development with Cerabyte, and government institutions a second possibility. They could help fund productization then receive a cut of ongoing sales.
Pflaum said the initial response from component and other potential partners had been positive. This could presage ceramic-coated glass archiving becoming a reality.
Commissioned: The adage that you can’t manage what you can’t measure remains polarizing. Some leaders lean on analytics to improve business processes and outcomes. For such folks, aping Moneyball is the preferred path for execution.
Others trust their gut, relying on good old-fashioned human judgement to make decisions.
Regardless of which camp you IT leaders fall into – planting a foot in both is fashionable today – it’s becoming increasingly clear that analyzing the wealth of data generated by your IT estate is critical for maintaining healthy operations.
Analytics in a multicloud world
Analyzing sounds easy enough, given the wealth of tools designed to do just that, except that there is no one tool to measure everything happening in your datacenter. Moreover, more data is increasingly generated outside your datacenter.
The growing sprawl of multicloud environments, with applications running across public and private clouds, on-premises, colocation facilities and edge locations, has complicated efforts to measure system health. Data is generated in multiple clouds and regions and multiple sources, including servers, storage and networking appliances.
Add to that the data created by hundreds or thousands of apps running within corporate datacenters, as well as those of third-party hosts, and you can understand why data volumes are not only soaring but becoming more unwieldy. Data is poised to surpass more than 221,000 exabytes and hit a compound annual growth clip of 21 percent by 2026, according to IDC research.
Mind you those lofty stats were released before generative AI (GenAI) rocked the world last year, with text, video, audio and software code expanding the pools of unstructured data across organizations worldwide. Unstructured data will account for more than 90 percent of the data created each year, the IDC report found. Again – that’s before GenAI became The Thing in 2023.
One approach to measure everything
If only there were an app for measuring the health of such disparate systems and their data. The next best thing? Observability, or a method of inferring internal states of infrastructure and applications based on their outputs. Observability absorbs and extends classic monitoring systems to help IT pinpoint the root cause of issues by pushing intelligence to surface anomalies down to the endpoint.
When it comes to knowing what’s going on in your IT estate, observability is more critical now than ever thanks to the proliferation of AI technologies – GenAI in particular. Like many AI tools, GenAI learns from the data it’s fed, which means trusting that data is crucial.
Companies implementing LLMs or SLMs may use proprietary data to improve the efficacy of their solutions. They also want to prevent data loss and exfiltration. This puts a premium on observability, which provides a sort of God’s Eye View of IT system health.
Observability stacks typically include monitoring tools that continuously track system metrics, logs, traces and events, sniffing out bottlenecks across infrastructure and applications. Data collection tools, such as sensors, software agents and other instruments track telemetry data.
Modern observability stacks leverage AIOps, in which organizations use AI and machine learning techniques to analyze and interpret system data. For example, advanced ML algorithms can detect anomalies and automatically remediate issues or escalate them to human IT staff as necessary.
Moreover, observability and AIOps are taking on growing importance amid the rise of GenAI services, which are black boxes. That is, no one knows what’s happening inside them or how they arrive at their outputs.
Ideally, your AIOps tools will safeguard your GenAI and other AI technologies, offering greater peace of mind.
Observability must be observed
Automation often suggests a certain set it and forget-it approach to IT systems, but you must disabuse yourself of that notion. Even the monitoring must be monitored by humans. For example, organizations that fail to capture data across all layers of their infrastructure or applications can succumb to blind spots that make them susceptible to system failures and downtime.
Moreover, failing to contextualize or correlate data across different systems can lead to mistaken interpretations and makes it harder for IT staff to pinpoint root causes of incidents, which can impact system reliability.
Finally, it is not unusual for thousands of incidents to be buried in billions of datapoints that an enterprise produces daily. IT departments should prioritize alerts based on their business impact. Even so, without the ability to analyze this data in real-time, generating actionable insights is impossible.
In today’s digital era, organizations can ill afford to suffer downtime. Gauging system health and resolving issues before they can denigrate the performance of IT infrastructure and applications is key.
You can’t watch everything. A partner can.
With so many business initiatives requiring IT resources, it can be hard for IT teams to monitor their own systems. Trusted partners can help you observe IT health.
Dell Technologies CloudIQ portfolio proactively monitors Dell hardware, including server, storage, hyperconverged infrastructure and networking technologies, as well as Dell APEX multicloud systems. Moreover, with its acquisition of Moogsoft Dell is rounding out its AIOps capabilities, supporting a multicloud-by-design strategy for running systems on premises, across clouds and on edge devices.
Sure, going with your gut works for certain things, but would you want to take that tack when it comes to your IT systems? For such a critical undertaking, holistic measurement is the key to managing your IT systems.
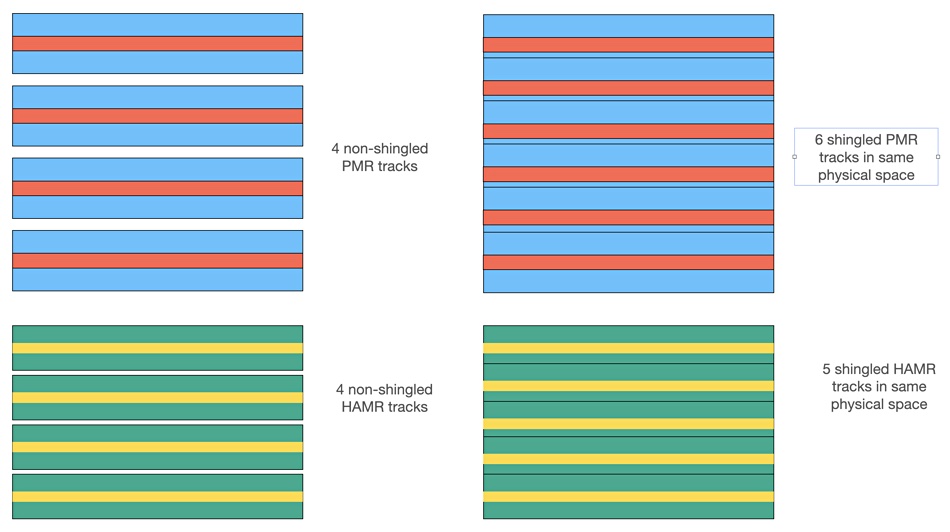
Shingled HAMR disk drives get a lower capacity increase than existing conventional drives. Is this due to HAMR technology itself or higher capacity drive tracks being narrower with less scope for shingling?
SMR (shingled magnetic recording), with its overlapped write tracks, delivers a capacity increase over PMR (perpendicular magnetic recording), also known as conventional magnetic recording (CMR), because a read track is narrower than the write track. A read head, which senses bit area magnetic direction, is narrower than a write head, which writes bit area magnetic direction. If you partially overlap write tracks but preserve the read tracks, you can add 17 to 20 percent or more capacity to the disk drive. You basically get more free physical space on the drive and can add extra tracks to the disk platters.
A Dropbox document says: “When shingled, track width is no longer limited by the size of the write head, but the size of the read head, which can read a much narrower track. Shingling increases the capacity of SMR drives by about 20 percent over conventional perpendicular magnetic recording (PMR) drives.”
Bear in mind that the write and read tracks on an SMR drive are closer together than on a non-shingled drive so the overall gap between the read tracks is less. There still needs to be a gap between the read tracks to prevent cross-track interference.
The larger the difference between write track width and read track width, the bigger the capacity advantage delivered by shingling. The implication is that there is less scope for shingled capacity addition on HAMR or higher capacity drives because the write tracks are not that much wider than the read tracks.
Diagram showing hypothetical SMR differences between PMR and HAMR disks. The wide blue and green bands are write tracks while the narrower red and yellow bands are read tracks. A shingled PMR drive gets 6 tracks in the same space as 4 non-shingled PMR tracks. A shingled HAMR drive only gets 5 tracks in the same space as 4 non-shingled tracks
A 24TB Seagate or Western Digital PMR drive becomes a 28 TB SMR drive, gaining 4 TB, meaning 16.66 percent more capacity.
But Seagate’s Exos 30 TB HAMR drive only becomes a 32TB drive in its SMR version – 2TB more. That’s only a 6.66 percent capacity increase. Why is this proportionally smaller than the PMR drive’s shingling increase?
HAMR drive tracks are closer together and narrower than PMR tracks, which means shingling can only increase capacity by around 7 percent instead of about 17 percent with PMR technology.
A conventional PMR drive, for example, may have a 2:1 ratio between write track width and read track width, meaning the read track is half the width of the write track. A HAMR or other higher capacity drive may only have a 1.3:1 ratio, with the write track a third wider than the read track. This provides much less scope for overlapping the write tracks while leaving the read tracks undisturbed. These are hypothetical numbers of course.
The Dropbox document discusses the company’s experience with HAMR drives, saying “HDD data tracks become smaller and spaced more closely together” with HAMR technology. It also talks about the need for better control of vibration. Narrower tracks could mean less tolerance for vibration. Putting limits on the width reduction of write and read tracks and the gap between them could be one result of this.
We asked Seagate for the reasons that its HAMR drive shingling adds a proportionally lower capacity increase than conventional drive shingling. Jason Zimmerman, Sr. Director of Product Line Management, told us: “The Mozaic 3+ product offerings are not necessarily completely indicative of the overall SMR vs CMR gains at a fundamental technology level. Generally, with Mozaic 3+, we are observing approximately ~10 percent additional capacity gains with SMR over CMR. So, I would not quote the 6 percent as completely indicative of the technology capability.
“The observation is generally correct that with higher TPI (narrower tracks) on any CMR will result in less SMR gains…however, this relationship is independent of recording technology (this is true whether it is HAMR or standard PMR). I would not “label” the higher track density in your figure as “HAMR Tracks”…as it will be true for any recording technology that increased “Conventional” CMR TPI. The label “HAMR lowers shingling capacity addition” does not seem fundamentally true.” It’s Zimmerman’s emboldening in this paragraph..
Broadcom is damaging the VMware channel and creating opportunities for channel partners pushed to the quitting point. That’s the view of hyperconverged infrastructure systems vendor Scale Computing’s founder and CEO, Jeff Ready, whose outfit is positioning itself to pick up these resellers and service providers.
Blocks & Files: What is your general view of the effect of Broadcom’s acquisition of VMware on the hyperconverged infrastructure market’s users, both large and small?
Jeff Ready
Jeff Ready: Overall we’re seeing Broadcom do exactly what was expected. Wasn’t it you who, early on, reported Broadcom’s stated focus as being on their top 600 customers?
Blocks & Files: How do you think this will affect the edge market for HCI products and systems?
Jeff Ready: The edge was not VMware’s strong suit before, and we’ve seen edge as an area where customers were open to change and were actively seeking new innovation. That is still the case, and it’s even stronger now. But post-acquisition, I’m seeing this same rekindled desire for innovation span the whole spectrum, from edge to datacenter to cloud, at a level I’ve not seen there previously.
Blocks & Files: How will the Broadcom channel changes affect partners?
Jeff Ready: Broadcom has effectively blown up its channel program and stated they were taking the most profitable customers direct. I think their wording was something like “strategic customers are no longer available for opportunity registration,” which is a convoluted way of saying, “We’re stealing your customers.”
The channel is what built VMware, so for any partner in that ecosystem, it must feel like a knife in the back. The small and medium-sized partners are treated like yesterday’s trash, and the big partners are robbed at gunpoint. That’s far beyond just being channel-unfriendly; it’s downright channel-hostile. This is another private equity-style move. A profit-driving one, perhaps. But it’s not what a company focused on future growth and innovation would do, and it feels downright cringy to me. It’s a Wolf of Wall Street approach, not a Jobs-and-Wozniack one.
Blocks & Files: What could disaffected partners do in response?
Jeff Ready: There’s an opportunity for partners to build an entire practice around migrations off of VMware – I’m certainly seeing customer demand for it all across the spectrum. Some customers will stay where they are, of course, but there are ample numbers of customers who are looking for a return of innovation that was already languishing with VMware even before the deal, and is now likely dead entirely.
And all this is happening at a time when we are seeing a return of on-premises computing, whether in the form of edge computing, or even basic datacenter/server room-type computing. Some workloads just run better and/or cheaper outside the cloud. With the right tools, customers can manage their entire environment as one, regardless of where the workloads are. Once you can manage the whole thing as one, you just run the apps wherever they make the most sense.
So for partners, this return of on-premises computing along with the rise of applications using AI, GPU, and computer vision – these are areas where traditional value-added partners can help customers. When you add the Broadcom-VMware deal on top of that backdrop, it’s fuel to an already burning fire of opportunity. Partners can help customers benefit from these new technologies and trends, while also rekindling their own businesses.
Blocks & Files: How would you describe the HCI market and its suppliers now that Broadcom has acquired VMware and Cisco is partnering with Nutanix?
Jeff Ready: VMware alternatives like us at Scale Computing, and like Nutanix, all benefit from the Broadcom deal. As I said, we’ve seen a huge increase in interest from both customers and partners. I’m talking about an order-of-magnitude change in just a few weeks’ time. It’s hard to overstate that tectonic shift. The Cisco-Nutanix partnership doesn’t change the overall industry much. Cisco Hyperflex stalled out some time ago, and now there’s an opportunity to replace Hyperflex as well as VMware. We’re seeing some benefit from Cisco’s retirement of Hyperflex ourselves, and of course Nutanix sees it, but the Cisco-retiring-Hyperflex impact on the industry is dwarfed by the Broadcom-acquires-VMware impact.
Blocks & Files: Is HPE a presence in your part of the HCI market?
Jeff Ready: For us, HPE is now more of a partner than a competitor. We will rarely still see a SimpliVity deal that is competitive, but not nearly as often as it used to be. What we do see are customers who want to run Scale Computing software on HPE hardware or who want to use other Scale Computing systems with HPE networking, for example. Those are now more cooperative opportunities than they are competitive.
Blocks & Files: Has Quantum buying Pivot3’s assets been a factor in Scale’s deals with customers and prospects?
Jeff Ready: No, not at all. I assume Quantum has moved that technology in a completely different direction. We’ve picked up some Pivot3 customers for sure, but I don’t know if there are any Pivot3 infrastructure customers left now.
Blocks & Files: Do you think generative AI will influence your market and product strategy and in what way?
Jeff Ready: For sure. And AI broadly even more so – computer vision and so forth. All of this typically uses GPU and sometimes CPU, both of which are quite expensive in the cloud, not to mention the requirements for collecting and moving massive amounts of data. We’re seeing these kinds of applications being deployed on-premises – on the factory floor where robots produce data about parts, or in the retailer where cameras can optimize employee productivity or enhance the customer experience.
These are great use cases for edge computing, which we’ve embraced and have been innovating in for years – and we’re only at the very beginning of that trend. We’re helping customers put in place an edge infrastructure that can be managed at scale when and how future needs dictate.




























{kind=link}