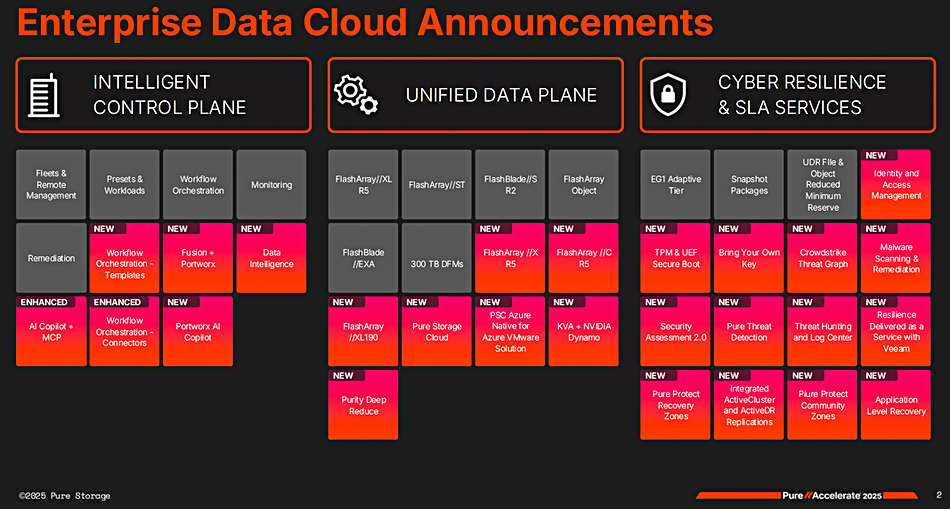
Control plane enhancements for Pure Storage arrays and software stack are enabling customer admins to manage and secure fleets of Pure arrays and cloud instances, and their workloads more effectively.
Pure Storage has gained the top position in Gartner’s latest Enterprise Storage Platform Magic Quadrant and, with its Accelerate event announcements intends to stay there. It reckons that, Wedbush analyst Matt Bryson says: “AI is forcing enterprises to rethink data architectures, creating a window for Pure to take share from incumbents.” The announcements cover virtually the entirety of its offerings, from hardware up through the SW stack to AI-enhanced array and fleet management. We covered the HW and data plane announcements here and now look at the control plane news.

Pure CTO Rob Lee stated: “In today’s AI era, access to data is everything. Managing your data, not just storing it, is the new foundation for AI-readiness from cloud to core to edge. Success depends on having your data secure everywhere, and easily accessible anywhere, with a unified and consistent experience – in real time, at scale, across any workload.”
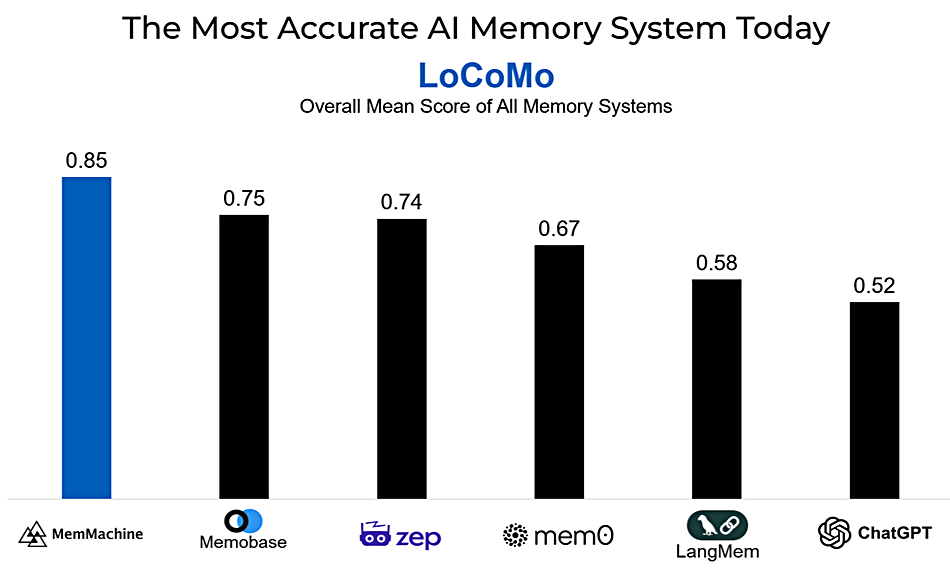
Pure says its Intelligent Control Plane (ICP) has activities covering fleet and remote management enforced by policies with presets for workloads. Workflows can be orchestrated and managed with an AI Copilot. The ICP now has real-time awareness of applications and workloads across a customer’s entire fleet of Pure Storage arrays on-premises and its instantiations in the public cloud. It can discover over-burdened arrays and move workloads to relieve the stress.
The cloud-based Pure1 management feature now has an AI Copilot with MCP (Model Context protocol) integration, enabling natural language-using AI agents to connect to it and open the door to admin staff using natural language to manage workloads across a Pure fleet. Pure Storage AI Copilot operates as both an MCP server and client, enabling integration with internal systems for hardware performance, subscriptions, and security data, as well as external tools like analytics engines and application monitors.

There is a Portworx AI Copilot to help manage Portworx deployments, providing answers to natural language queries about, for example, Portworx cluster health, license states and offline nodes. Users can query Portworx clusters in the same way they interact with FlashArray systems, monitoring their Kubernetes and Portworx clusters at scale via instant interaction with an AI agent on the Pure1 Copilot user interface.

Pure’s fleet-managing Fusion can now manage a customer’s Portworx instantiations, handling Portworx containerized apps. Fusion can be used to discover and migrate VMware workloads to KubeVirt.
ICP gets workflow orchestration templates through which, it says, production-ready workflows can be deployed in minutes. Connectors bring in other Pure products as well as third-party offerings from, for example, Google, Microsoft, PagerDuty, SAP, ServiceNow and Slack.

Cyber Resilience
Pure says the standard approach to cyber defense—bolting on multi-vendor solutions that don’t cover the storage platform—does not work. We need native threat detection capabilities at the storage layer and that is what it’s providing; built-in capabilities.
Across-the-board advancements here provide better threat detection, security assessments and a cyber-recovery SLA. Pure’s AI Copilot – think conversing with a dashboard – provides visibility of anomalies, threat detection and can take proactive action. Customers can use Pure’s Log Center to investigate insider threats and anomalous user access and there is real-time malware scanning with ICAP (Internet Content Adaptation Protocol) and a file workload anti-virus capability.

Pure has partnered with CrowdStrike for Threat Graph and Falcon SIEM (Security Information and Event Management) integration to get real-time Threat Graph intelligence to automatically detect and combat malicious activity and attacks. The integration with CrowdStrike Falcon next generation SIEM automates and accelerates incident response, with immediate action to automatically update policies, replicate, and isolate critical systems to contain threats. Alerts sent to security teams mean they can hopefully respond proactively before damage occurs.
It is also partnering with Superna to get automated, real-time tile and user monitoring for threat detection and response at the data layer. This is integrated with both FlashArray and FlashBlade, and specifically targets attacks like data exfiltration or double-extortion ransomware. Compromised accounts are instantly locked when malicious activity is detected, and security policies are enforced automatically.
Pure Protect Recovery Zones – clean rooms – provide automatically-provisioned isolated recovery environments. This means customers can non-disruptively test and validate applications and data, or to remediate and recover from malicious attacks without affecting production environments.
A Veeam partnership provides Cyber-Resilience-as-a-Service with centralized, automated protection and recovery through a SaaS scheme that is enterprise- and fleet-wide, and has SLAs.
Availability
- Pure Protect Recovery Zones are also some way off, expected to GA in Pure’s 1st fiscal 2027 quarter (February to April 2026.)
- The Portworx Pure1 AI Copilot is generally available (GA).
- Pure1 AI Copilot Integration with Model Context Protocol (MCP) Servers will be GA in Pure’s fourth fiscal 2026 quarter (November 2025 to January 2026)
- Portworx integration with Fusion is slated to be GA in the first half of Pure’s fiscal 2027 (January to July 2026 period).
- Real-time threat evaluation and response with CrowdStrike Threat-Graph and Falcon Next-Gen SIEM Integration should be GA in Pure’s 3rd fiscal 2026 quarter (August – October 2025).