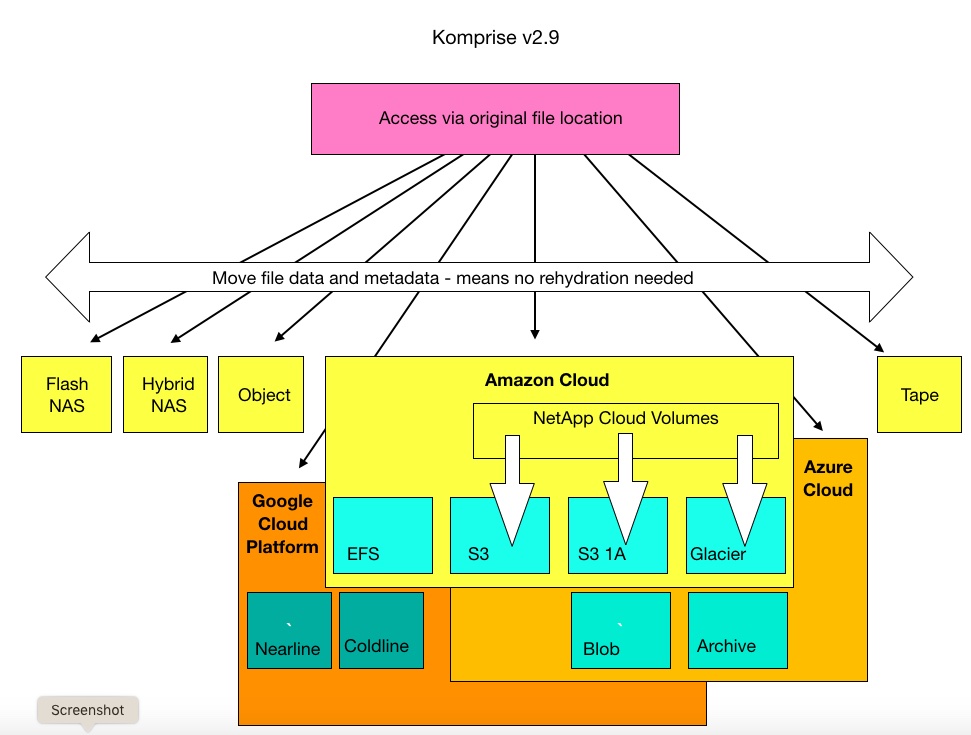
Komprise Intelligent Data Management 2.9 can transparently archive cold data from CloudVolumes to S3, S3 IA and Glacier. NetApp Cloud Volumes supports the Google Cloud Platform (GCP), as does Komprise – so we should expect Komprise to add similar support for Cloud Volumes on GCP.
Intelligent Data Management 2.9 includes multi-vendor data lifecycle management. Users set policies that define how data moves across classes of different vendors’ storage and Komprise moves the data as it ages. The outcome is reduced access rates.
The upgrade is available now at no charge for supported users.
File away
Komprise’s software is designed for organisations that need to store large volumes of infrequently accessed files. For financial reasons, that typically means the data is stored on different tiers of storage, ranging from fast access to archive class. It is difficult to manage these different storage tiers yourself, particularly with multiple vendor n the mix.
Komprise enables customers to manage the lifecycle of file data as if the files are in a single access-point virtual silo. It moves file data to where it is required.
Intelligent Data Management finds files and builds a metadata dictionary to describe them. As files age, the software can move files from the original storage tier to cheaper options.
These can include the public cloud or on-premises formats such as slower NAS, object and tape. If necessary, Komprise converts files to objects en route but preserves full file characteristics. This means there is no need to rehydrate the file data when accessed.
Also dynamic links are used so that files can be accessed from their original location, without the need to use left-behind stubs.
Schematic diagram of Komprise software functionality
Lenovo has also tag-teamed with Scale’s rivals such as Maxta, Pivot3 and DataCore.
So we took the opportunity to ask Jeff Ready, Scale Computing CEO, how he differentiates his company’s hyperconverged systems from the competition. We publish his reply in full below.
But first, let’s remind ourselves that Scale’s HyperCore software installs on bare metal and includes an operating system. By contrast, its competitors layer software onto an operating system.
Are you Ready for this?
Scale Computing CEO Jeff Ready
First (says Jeff Ready) Scale is a full infrastructure stack. HCI is just one component of that stack. Scale is managing everything that sits beneath the applications themselves, so our customers need not manage storage, virtualization, backups, disaster recovery, hardware bios, cpu microcode etc. All of that is handled by HyperCore.
Second (and tied to the first) is the self healing. Detecting, mitigating, and fixing problems anywhere in that stack, automatically, such that applications can keep running. Per the first part, this means anything in that full stack. The “secret sauce” of Scale lies in this self-healing framework, where we are monitoring thousands of different conditions in the infrastructure from the underling hardware, the intermediary software stacks, to the VMs, etc.
Finally, the biggest components of our infrastructure are homegrown and designed with this self healing framework in mind. Our SDS stack, orchestration layer, management layer, and the self-healing architecture all work together.
“On one hand, we have build the most efficient, high-performant stack out there. … we’re able to deliver native device speeds (such as 20 microsecond latency on Optane drives) all the way through our stack into the applications themselves.
While quite powerful, this was also results in a very lightweight framework, itself consuming few resources. This is very helpful when it comes to edge and retail environments, where small systems are the norm. While Scale HC3 can and does support very large data centre deployments, we also support very small deployments, where a server may only have 16GB of RAM for example.
We will only consume 2GB of RAM and a fraction of one core of CPU power, leaving the rest of the resources available for the applications themselves. Such efficiency is critical when looking at large scale deployments. Needless to say, deploying tiny servers with 16GB RAM at 3,000 locations is a whole lost less expensive than deploying large servers with 256GB RAM at 3,000 locations.
Taking all of the above into account, what the Scale HC3 solution does is provide a platform for running applications that is self-healing, lightweight, and extremely efficient. It takes care of itself. Thus, for deployments where you have perhaps zero or just 1 or 2 IT personnel on-site, this is the ideal solution.
Boston, the UK server and storage integrator, has invited its channel partners to a briefing on Micron’s 2200 SSD.
It looks like a new product line is in the offing as this does not feature in Micron’s list of SSD families: the 1100, 5100, 5200 and 9200. Micron also had a 2100 PCIe NVMe Client SSD in 2016.
OK, OK, so this is sketchy, but we’ll tell you more when we know more.
The Boston channel training session is on November 2. In the meantime, here is a copy of the invite.
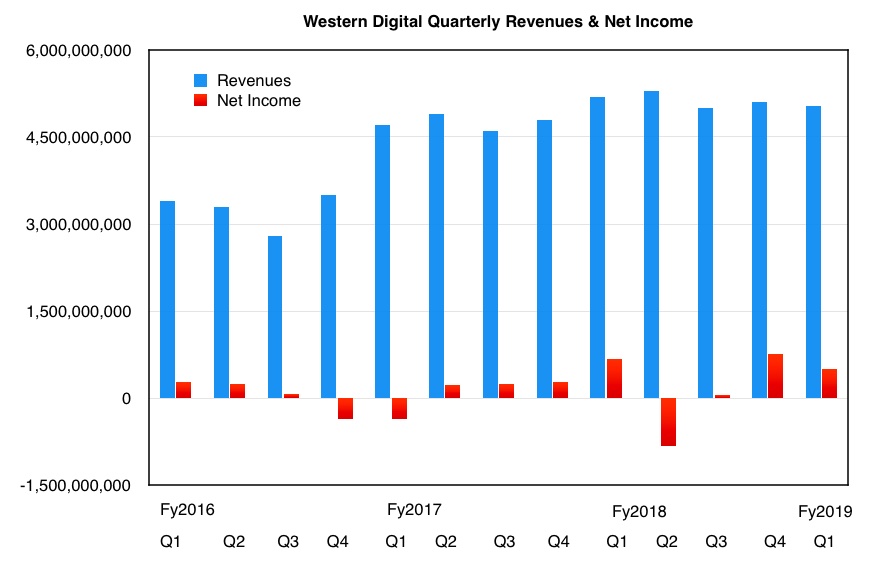
Western Digital execs blamed declining flash prices and demand for a three per cent drop in Q1 2019 revenues.
And they expect it to get much worse, forecasting a 19 per cent fall in next quarter’s revenues.
The company pulled in $5bn for Q1 ended September 28, 2018, compared with $5.2bn the same time last year. It anticipates Q2 revenues to fall to a mid-point estimate of $4.3bn, down from $5.3bn in FY2018.
WD quarterly revenue and net income history to Q1 fy2019.
We think Q3 fy2019 revenues are unlikely to be much better.
On the earnings call, CEO Steve Milligan cited trade tensions with China, changes in monetary policy, foreign exchange volatility and the corresponding economic impacts. These are causing a fall in customer demand for SSDs.
In response WD is making an immediate reduction to wafer starts and delaying deployment of capital equipment. These actions will reduce its wafer output beginning in fiscal Q3 2019; ie, mid-calendar 2019.
It also has inventory to burn off. WD aims to get its supply back in balance with demand by mid-2019, but that obviously involves an accurate estimate of likely demand.
And that implies an estimate o overall flash industry supply. If other SSD makers are similarly affected then they could reduce their output or cut prices and go for market share gains. The latter would screw with WD’s plans.
WD says it’s aiming to maintain its market share but it is unclear what Intel, Micron, Samsung, SK Hynix and Toshiba intend to do.
WD thinks the long-term demand for flash is strong and the slowdown will be temporary and relatively short-lived. We’ll see.
Virtual Instruments has released VirtualWisdom 6.0, a major release of its infrastructure performance monitoring product.
V6.0 adds cloud integrations and extended correlation of events across infrastructure elements to better visualise and fix application performance issues.
V5.4 of VirtualWisdom came out just over a year ago and V6.0 continues the work of monitoring the performance of IT infrastructure performance in the context of applications.
The whole point of an IT infrastructure is to run applications reliably and quickly. At the same time the infrastructure must observe service-level agreements and balance app demands so that is used efficiently, i.e., neither wastefully nor in a way that hobbles app performance.
So much so obvious, but an IT infrastructure is fearsomely complicated and always evolving. Virtual Instruments suggests that the scale and complexity of modern virtualized, multi-cloud environments can even be beyond human comprehension.
If a picture says a thousand words…
Here are some schematic charts that illustrate the levels of complexity involved:
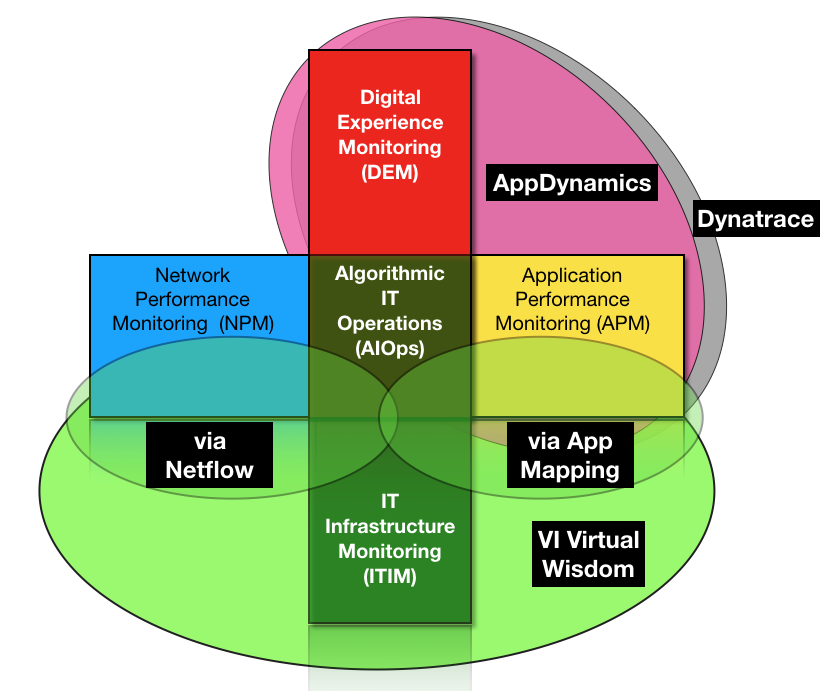
The five aspects of app-centric performance monitoring: infrastructure, network, application, digital experience and, the holy grail, algorithmic IT operations
The charts above indicate the enormous increase in the complexity of the hardware and software components as you delve deeper into the IT infrastructure.
To get a handle on this, IT admins need to visualise, the myriad compute, storage and network components in the context of the applications.
This is a necessary first step before you can dive into infrastructure elements and see how the effects of low-level events can propagate through the infrastructure and mess with app performance.
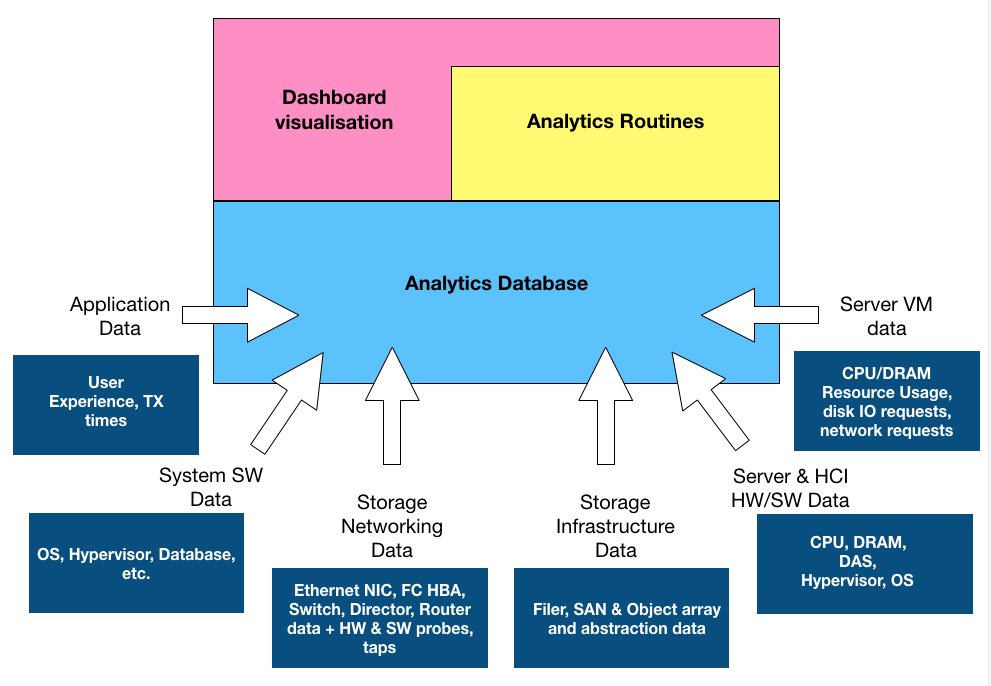
Virtual Wisdom discovers and maps applications to the infrastructure to understand where each application lives and how it behaves on top of the infrastructure, in addition to discerning the business value and SLA tier of each application.
When end-to-end visibility is established, VirtualWisdom applies real-time, AI-based analytics that include machine learning, statistical analysis, heuristics and expert systems. The software provides application service assurance, predictive capacity management, workload infrastructure balancing, and problem resolution and avoidance.
Virtual Wisdom also integrates with third-party applications for network and app-level information which it then ties to its infrastructure knowledge base:
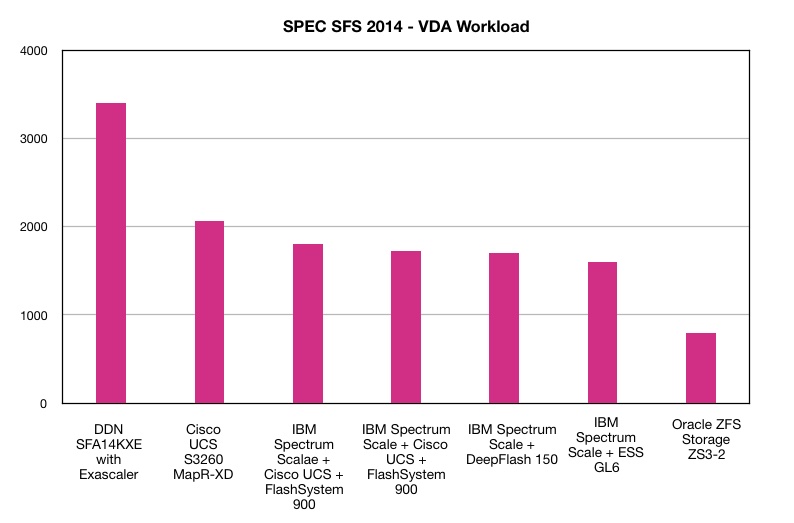
DDN has submitted a winning VDA workload benchmark in the SPEC SFS 2014 performance suite.
The SPEC SFS2014 benchmark tests filer performance. Earlier this month DDN submitted four SPEC SFS 2014 workload results:
Builds – 1,500 with an Overall Response Time (ORT) of 0.19ms
EDA – 800 with 0.29ms ORT
VDI – 800 with 2.58ms ORT
Databases – 750 with 0.61ms ORT
To date DDN is the only vendor to submit VDI, database or EDA results.
The Build result is a record – 25 per cent faster than an E8 NVMe storage system using Intel Optane 3D XPoint drives.
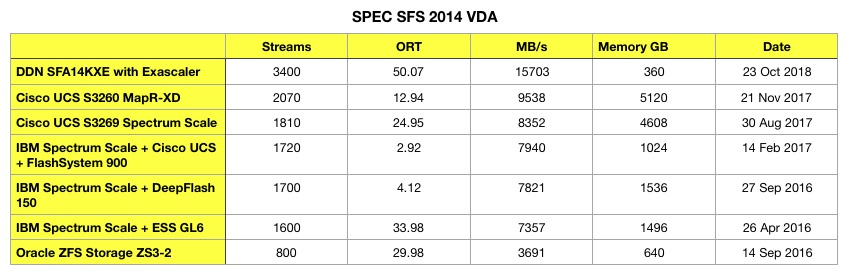
DDN’s VDA benchmark achieved 3,400 streams, 65 per cent better than its nearest competitor, a Cisco UCS S3260 system using MapR-XD.
DDN’s overall response time was 50.07 msec.
DDN’s system was its SFA 14KX array, fitted with 72 x MLC (2bits/cell) SSDs, 400GB SS200 SAS drives from Hitachi GST. The Exascaler software is IBM’s Spectrum Scale parallel file system.
Here is a table and chart showing all the VDA results:
Tabulated VDA workload results for SPEC SFS 201 benchmark
I am not a fan of the SPEC SFS 2014 benchmark, as I discuss in more detail in this article. But very briefly, the benchmark needs a price/performance element to make it useful for real world computing.
Austin McChord, the founder of backup service provider Datto, has stepped down as CEO.
It’s all rather sudden but he is staying on the board and is involved in the search for his successor. In the meantime Tom Weller, president and COO, is interim CEO.
Datto was bought by Vista Equity Partners for $1.5bn a year ago. The idea was to combine Datto with Vista’s Autotask business and build a unified managed service platform for IT management, data protection and business continuity.
At the time of the acquisition the Datto-Autotask combo had some 1,300 employees with offices in nine countries, and nearly 13,000 MSP customers servicing more than 500,000 small and medium business in 125 countries.
McChord says he will “continue to be actively involved with the company”.
Austin McChord, Datto founder and, now, ex-CEO
“This move is part of a natural evolution for the company and for me, ” he said. “Datto was my first passion, and I’m looking forward to focusing my efforts on providing strategic counsel and support now that the company is in a market-leading position.”
Time for a change
Weller said: “Austin’s legacy provides a sound foundation for Datto today and sets high ambitions for our future…I look forward to working with the board and Austin as we enter this next phase of growth and opportunity for our company.”
Nadeem Syed, operating principal at Vista Equity Partners, said: “Austin has built a truly special company that is poised for tremendous growth. While it is always difficult when a founder moves on from a company he built, we are truly grateful for what Austin has created. We look forward to working with him in his capacity as a board member and advisor as we move into this next phase.”
In a valedictory statement McChord said: “I founded Datto 11 years ago in a basement. What started out as an entrepreneurial dream, has grown into a team of 1,400 employees serving more than 14,000 Managed Service Providers with reach in 132 countries. I’m proud of the company we have built and our commitment to the MSPs we serve. Datto is positioned better than ever to continue serving partners and growing.”
He was a startup guy and Datto/Autotask is no longer a startup business.
If you use relational databases, are into business digital transformation, and think data is the new oil than climb aboard the DataOps train. Delphix and Datical will say ‘Hi’, show you to your seat, and supply tasty brochures to tempt early wallet opening.
The vendors have teamed up to make databases easier and faster for their customers who include more than half of the global Fortune 50.
Delphix is a database virtualizer and Datical is a database release automation supplier. They say they can cut the time to provision production-quality data from days or weeks to minutes. Also Delphix-Datical tag-team to eliminate manual tasks such as reviewing and validating database schema and logic changes.
They cite an unnamed top five US investment management firm which uses their products to increase the speed and quality of application releases. The outcome is:
100 per cent increase in rate of application deployments
90 per cent reduction in data provisioning times
Elimination of data-related defects
DataOps needs standards
Delphix and Datical quote Stephen O’Grady, principal analyst with RedMonk, who says: “While application development has been revolutionized by the DevOps phenomenon, database management has lagged behind. This issue is what’s created the demand for an equivalent ‘DataOps’ style movement, and is why Delphix and Datical are focusing on these needs so intently.”
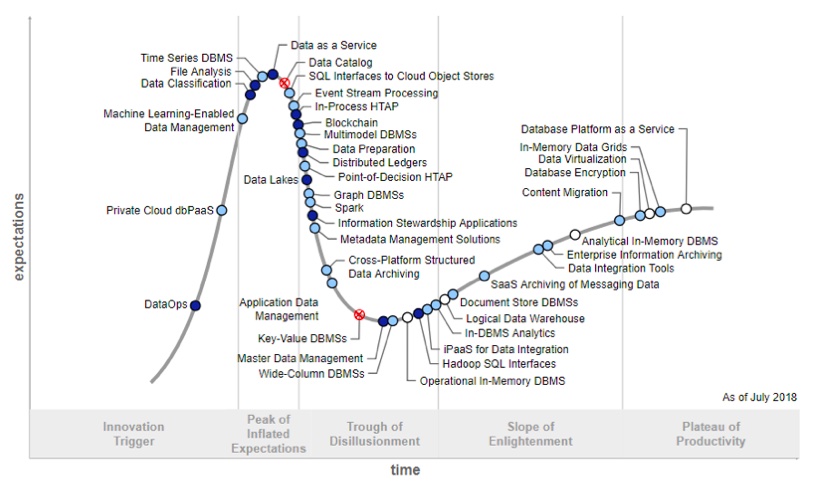
As an idea, DataOps is gaining credence, with support from Gartner. But there is a notable element of bandwagon-jumping, Nick Heudecker, a research VP at the analyst firm, warns.
He says DataOps is a “new practice without any standards or frameworks. Currently, a growing number of technology providers have started using the term when talking about their offerings and we are also seeing data and analytics teams asking about the concept. The hype is present and DataOps will quickly move up on the Hype Cycle.”
Gartner has plunked DataOps at an early stage in its Hype Cycle methodology:
DataOps is admitted hype but databases have to be updated and released and if that is completed quicker and better then what CIO is not going to be pleased?
NetApp has a new tech advisor to bend peoples’ ears about tech trends. Step forward, Greg Knieriemen who has left Hitachi Vantara to take a chief technologist slot at NetApp.
Knieriemen spent six years at Hitachi Vantara, as chief technology strategist and technical evangelist. And before that he was a Marketing VP at Chi Corporation for nearly 13 years. He is also the founder of the “Speaking inTech” podcast.
Mark Bregman resigned as a NetApp SVP and its CTO in May this year, but Knieriemen is not replacing him. Instead his role is specific to the Storage Systems and Software business unit (led by Joel Reich) and, similarly to his work at Hitachi, will be focused on product evangelism.
NetApp has no plans to replace the position previously held by Mark Bregman.
Unstructured data management is becoming a major focus for startups and supplier product development is bound to reflect competitive forces and a quest for differentiation.
IDC forecasts that by 2025, the global datasphere will grow to 163ZB (i.e., a trillion gigabytes). That’s 10 times the 16.1ZB of data generated in 2016. According to Forbes, Gartner analysts estimate around 80 per cent of enterprise data today is unstructured, meaning not held in structured databases.
It is growing fast as the machine-generated component, from online sales and other transactions for example, increases. The unstructured data market is vast. Rubrik reckons just the Copy Data Management part of it, comprising data protection and recovery, archiving, and replication, is worth $48 billion.
The best known players are Cohesity, Rubrik and Komprise. But there is still all to play for and a bunch of venture-backed “fast followers ” have emerged in their wake. These include Igneous Systems, Elastifie and WekaIO.
Igneous Systems has launched a trio of products to address the Unstructured Data Management as-a-Service (UDMaaS) market.
The Seattle-based company was founded in 2013 and has raised $41.6m to date in early stage venture funding. In the early days, it set out to build object-storing nanoservers – disk drives with attached ARM processors. From there it evolved into a hybrid cloud storage vendor and now it is pivoting again into unstructured data management.
In August 2018, the company released a set of NAS integrations with Pure Storage, Qumulo and Isilon and these underpin its new services.
So how do you pronounce ‘UDMaaS’?
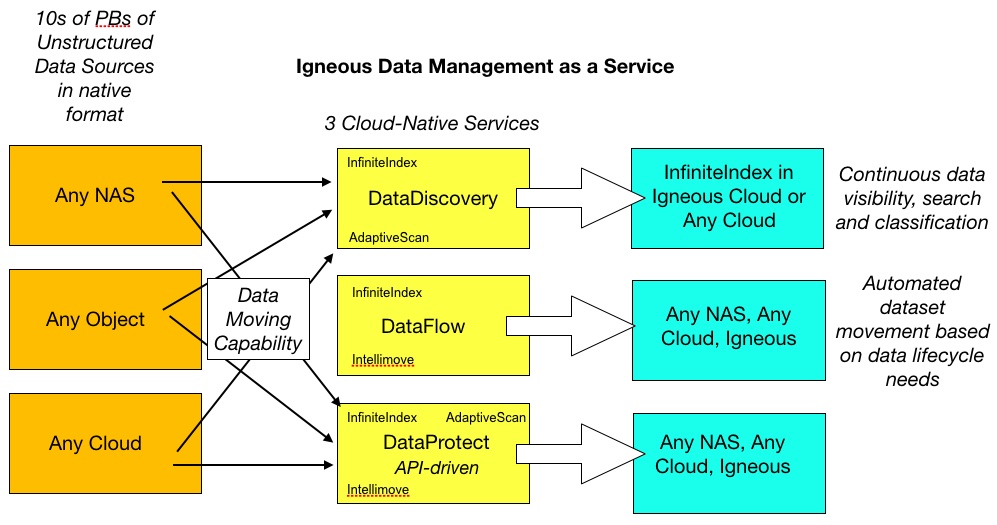
The SaaS offerings are DataDiscovery, DataFlow and DataProtect, which can use NAS and object storage systems on- and off-premises as source repositories.
Igneous’ announcement stated:
DataDiscovery is underpinned by an Igneous InfiniteIndex and provides a unified and intelligent system of record for all file and object data. It creates aggregated views of the unstructured data, utilising AdaptiveScan and InfiniteIndex to answer specific questions like “How much?,” “How old?,” “Where is it?,” and “How fast is it growing?”
DataProtect – Backup and Archive for Primary NAS, Object, and Cloud. This uses the high performance movement of Intellimove (multi-threaded, latency-aware data movement) with API integration for NetApp, Isilon, Qumulo and Pure Flashblade. Metadata stored in the InfiniteIndex. AdaptiveScan discovers change.
DataFlow provides self-service and automated dataset movement for analysis, simulations and collaboration, applicable to any operation requiring intelligent data movement at scale, including machine learning pipelines, IoT data workflows and BioInformatics pipelines. It’s driven by end-users such as scientists and engineers
Igneous says it “delivers superior data visibility, efficient data protection and automated data movement to data-centric organizations … regardless of where datasets reside.” That is “unstructured” data sets, meaning files and objects, and at scale, meaning tens of petabytes.
It provides “continuous data visibility, search and classification; backup, archive and disaster recovery of all files and objects; and automated dataset movement based on data lifecycle requirements …on a single ’as-a-Service’ solution, for all unstructured data.”
I have made a schematic diagram that shows these three services:
Christian Smith, VP of Products at Igneous, provides a canned quote; “Our customers get the benefits of visibility, classification, analysis, protection and data mobility without having to rip and replace their existing storage investments. And our unprecedented performance and support for any NAS or object interface and private or public cloud service gives agility and choice back to our customers.”
Noted that “unprecedented performance [and] support for any NAS or object interface and private or public cloud service”? We’ll take these things literally.
Igneous says its products are capable of delivering data scan-and-compare rates of over “419,000 files/second per job, data-movement rates of over 21,000 files/second per job, [and] throughput starting at 1.2GB/sec for a basic configuration.”
Our Q&A with Igneous
To find out more we asked Igneous some questions about its three UDMaaS services and spokesperson Mike Bradshaw provided the answers.
B&F: Where do these services run?
Igneous: Services run on-premises, or in the cloud.
B&F: Are agents used?
Igneous: No – this is all agentless. Data is moved and scanned through native file or object interfaces (NFS, SMB, S3, etc.) utilising API integration where available.
B&F: What will drive customers to buy these services?
Igneous: UDMaaS customers have fast growing data or a density that caused legacy data management models to break down. Igneous customers were facing the following problems:
DataProtect: The data protection in their environment used legacy technology, was cumbersome and often did not meet SLAs
DataFlow: Having built a pipeline, they got stuck trying to move data fast between different data platforms
DataDiscovery: Didn’t have a handle on the data they already had
Increasingly, unstructured data is targeted to the public cloud as part of a workflow orchestration or automating a protection/archiving solution.
B&F: Just unstructured data?
Igneous: Igneous does not protect any structured data sources or VM’s and has no plans to do so. Our future is focused on unstructured data: where it lives, where it’s going to live, and how to manage it.
B&F: Can you provide a performance example?
Igneous: A recent benchmark with Pure Flashblade delivered 226,517 files/sec in one job for an export with 1B files and a 10 per cent change rate while source side system latency stayed under 5ms.
This performance continues to scale with additional jobs.
B&F: What characterises Intellimove?
Igneous: Data movement is about keeping networks full; Igneous IntelliMove is about using concurrency and intelligent handling of all file sizes to keep networks full.
B&F: What’s your view of your competition?
Igneous: [We don’t] see many competing in our space of UDMaaS. These customers recognize best of breed in UDMaaS for performance, scale, and as-a-Service delivery. Very few comparisons on performance exist publicly.
However, a few vendors have been trying to claim file capabilities for data protection. Most recently Rubrik did a webinar where it talked about protection performance with PureFlashblade.
The best rate they talked about was 40,000 files/sec for SCAN only, no mention of compare rate to determine change. The largest fileset tested had 3.125M files in a balanced directory structure
They mentioned the impact to Pure Flashblade was 10ms – this is a huge impact for an all-flash array.
They talked about breaking up large exports with hundreds of millions of files into more exports, never gave numbers for 750 million files. Igneous does not believe data protection should drive application requirements, and all customers have that “problem” export that has hundreds of millions of files.
We believe this shows their market is one where structured data protection is the dominant priority and the customer has only “some” files.
B&F: What about Cohesity?
Igneous: They appear to be going after protecting structured data, and replacing NetApp as a primary NAS data source. If they are successful in the latter, Igneous will treat them like any other data source for Igneous DataDiscovery, Igneous DataFlow and Igneous DataProtect.
Comment
So far so very good. With the DataDiscovery metadata farming facility and its IntelliIndex metadata store, Igneous has built a foundation to add many more data services.
The rationale is that customers have so many heterogeneous data stores that no one supplier’s data management system can manage everything. Hence a separate supplier’s dedicated product is needed. This is similar to the Hammerspace view of the world .
We also think Komprise’s file lifecycle data management metadata handling capability will bring it into play in the same market, and IBM will enter it with Spectrum Discovery.
Samsung has been slow to develop QLC (4bits/cell) SSD products, compared with Intel and Micron. But it appears to be catching up, judging by a roadmap unrolled at its San Jose TechDay event last week.
Tom’s Hardware and Anandtech attended the show and their reports were the source for much of the information here as Samsung is yet to share this more widely.
The company discussed several upcoming QLC products which use 9x (90+) layer 3D NAND. Samsung did not disclose the number of layers. This, the fifth generation of its V-NAND (3D NAND) technology, is a single stack die and not a “string-stack” of, for example, 3 x 32-layer dies.
Samsung says its competitors use string-stacking in their 96-layer product.
A v6 V-NAND will have 100 or so layers and may use string-stacking. That will be followed by v7 to v10, with a route to 500 layers in which string-stacking will definitely feature.
Retail products have different naming schemes, such as PRO and EVO.
BM QLC drives
Four new QLC SSDs are on the roadmap:
BM1733 and BM9A3 enterprise NVMe SSDs,
BM1653 enterprise SAS SSD,
BM991 client NVMe SSD.
The BM1733 has both NF1 and U.2 form factors, up to 32TB of capacity, a dual-port PCIe gen 4 interface, and sequential speed of up to 10GB/sec.
Wells Fargo senior analyst Aaron Rakers said Samsung will bring out a 512Gb QLC die alongside its existing 1TB QLC chip, which operates at 1.4Gb/sec. Apparently it will have 37 per cent lower read latency and 45 per cent lower program latency relative to an unknown competitor’s 1Tb QLC NAND. Rakers thinks Samsung is comparing itself with Micron.
Z-SSD
Z-SSD is Samsung technology designed to make SSDs react more quickly and perform faster. In other words, it bridges the SSD – 3D XPoint gap.
XPoint is a phase change memory technology that has near DRAM speed and costs more than flash. So far only Intel has turned this into commercially available product, with its Optane chips. These are made at the Intel-Micron joint venture, IM Flash Technologies foundry in Lehi, Utah. But the JV is likely to be taken into sole Micron ownership and we can anticipate Micron-branded XPoint products in the second half of 2019.
Second generation Z-SSDs are coming in SLC and MLC (2bits/cell) forms. Gen 1 Z-SSD was an SLC (1 bit/cell) drive with reduced size wordlines and bitlines, making it faster in operation than ordinary SLC drives. It has a 64Gb capacity, 30us read latency and 100us write latency.
A gen 1 Z-SSD was the SZ985 which had an 800GB maximum capacity.
The Gen 2 Z-SSD, due in the second 2019 quarter, comes in both SLC and MLC (2bits/cell) form, with the SLC version coming with a 128Gb die and read/write latencies of <10-30us/70us.
Two SLC gen 2 Z-SSDs were revealed: the SZ1733 and SL1735.
The dual-port SZ1735 has 4K read latencies of ~16us, random read/write IOPS of 750,000 and 250,000, and sequential bandwidth of up to 3GB/sec. It will have a 5-year warranty, support up to 30 drive writes per day, and its capacity will run up to 4TB.
No SZ1733 details were available, but both it and the SZ1735 support PCIe gen 4.
The capacity of the MLC Z-SSD die is a logical 256Gb, and its read and write latency values are 5us/150us. This is impressively fast. Specific MLC Z-SSD products will be revealed in the future.
Future Z-SSDs will operate at up to 12GB/sec using the PCIe gen 4 interface.
QVO drives
Samsung also mentioned, without providing any details:
860 QVO SATA SSD
980 QVO NVMe SSD
The QVO moniker could indicate a 9x layer QLC consumer drive with the EVO term indicating 64-layer TLC product.
PM drives
The PM1733 follows on from the PM1723b and its capacity ranges from 1.6TB to 30.72TB. I has a dual-port PCIe gen 4 interface and runs at 8GB/sec for sequential reads and 3.8GB/sec when sequentially writing. The random read/write IOPS values are 1.5 million and 250,000 – the drive is heavily read-optimised.
Its predecessor the PM1723b operates at 3.5GB/sec – thank you, gen 4 PCIe.
Samsung also outlined new products in its 64-layer TLC (3bits/cell) portfolio, using v5 technology. A PM981a client NVMe drive will be the follow-on to the PM981, while a 970 EVO Plus will succeed the 970 EVO retail SSD. The capacity levels stay the same, running from 250GB to 2TB, but were told sequential read speeds will increase. However, Samsung says the 970 EVO Plus will run at 3GB/sec in comparison to the 970 EVO which has a 2.5GB/sec sequential write rating and a 3.5GB/sec sequential read speed, meaning the 970 EVO Plus will have a slower red speed.
We’re querying the read speed discrepancy with Samsung.
The random IO speed of the PM981a will be similar to that of the 970 EVO and 970 EVO Plus.
A PM983a TLC drive is the successor to the data centre PM983, with capacity doubled to a maximum of 16TB. These TLC drives do not use SLC caches to accelerate writes, unlike Samsung’s consumer TLC and QLC drives.
The PM971a NVMe client BGA SSD will be succeeded by a PM991 that nearly doubles random IO and sequential write speed, with sequential read speed increasing by 50 per cent.
The PM1643 enterprise SAS drive will give way to the PM1643a with a 20 per cent boost in random write performance but maximum capacity is unchanged at 30.72TB.
Samsung will move its NAND design to a Cell over Peripheral architecture, with the bit-storing cells built on top of the CMOS logic needed to operate the die. Intel and Micron have a similar CMOS-under-Array design and both schemes make scaling up 3D NAND capacity more practical.
Just three moves for you in this edition of Storage People moves.
Let’s begin with Guy Churchward, who has become executive chairman at Datera, just two months after joining the startup’s board. Datera’s software runs on x86 servers, and provides scale-out data services to applications, provisioning block or object storage and supporting containers.
Churchward also sits on the boards of Druva, a data protection vendor, and FairWarning, a SaaS supplier of data protection and governance for electronic health records, Salesforce, Office 365, and other cloud applications.
Guy Churchward, Exec Chairman for Datera
He has written a blog explaining how and why he has joined these three boards.
VMware
Former Tegile marketing head Rob Commins has jumped ship from Western Digital to take a berth at VMWare. His new job title isdirector for strategic marketing for vSAN and he reports to to Lee Caswell, VMware’s VP for storage products and availability.
Commins was senior director for commercial and enterprise brand marketing at WD, which acquired him in August 2017 along with Tegile, the flash/hybrid array startup.
Redstor
Redstor has hired Gareth Case as its chief marketing officer. The company sells backup, disaster recovery, archive, search and data management software in the UK and Africa. And it wants to treble its revenues in three years. So Case is on the case.