With just three times longer latency Samsung’s 983 ZET Z-NAND SSD is a fair spec sheet competitor to Optane SSDs, beating it on most IO measures.
The 983 ZET uses 48-layer 3D NAND organised in SLC (1 bit/cell) mode and Samsung says it has optimised it for higher performance. It comes in 480GB and 960GB capacities.
Product briefs for the 983 ZET (Z-NAND Enterprise Technology) SSD show less than 0.03ms latency. That’s <30 µs, compared to less than 10 µs latency for the Optane DC P4800X. They show it as faster than Optane at all IOs except random writes but suffering on the endurance front.
Samsung 983 ZET SSD with heat sink removed
The ‘up to’ performance numbers (with Optane DC P4800X numbers in brackets) are;
Random read/write IOPS – 750,000/75,000 (550,000/500,000)
Optane’s random read/write numbers are similar whereas the 983 ZET drive is ten times slower at random reads than writes. At random reads and all sequential IO the 983 ZET is faster than Intel’s Optane SSD.
The 480GB 983 lasts for 8.5 DWPD (7.44PB written) for 5 years, with the 960GB version enduring 10 DWPD (17.52 PB written.) But Intel’s P4800X can sustain up to 60 DWPD; far more.
Samsung’s 983 supports AES 256-bit encryption, has capacitor-backed power loss protection for its DRAM cache, and comes as a HHHL add-in card (AIC.)
Both drives use the NVMe interface operating across PCIe gen 3 x 4 lane and have 5 year warranties.
A 480GB version will cost $999.99 with $1,999.99 needed for the 960GB version. A 750GB DC P4800X Optane costs $3,223.42 on Span.com making the 983ZET substantially less expensive.
Blocks & Files wonders if Samsung is considering producing a Z-NAND NVDIMM.
Dateline: April 1, 2019. Researchers at a secret Google facility have implemented multi-level cell DRAM, demonstrating 2 bits/cell (MLC) with a roadmap to 3 and 4 bits/cell, equivalent to MLC, TLC and QLC NAND.
MLC DRAM has double the density of single bit DRAM, enabling a doubling of DIMM density to 512GB from the current 256GB. There is an increase in access latency, from DDR4 DRAM’s 15ns to 45ns but no decrease in endurance.
As soon as an application with a working set in excess of 3TB can fit in memory then the longer MLC DRAM access time becomes moot as IOs to storage are avoided, saving much more time than that needed for extended MLC DRAM latency.
A single Optane SSD access can take 10,000ns, 220 times longer than MLC DRAM access. An NAND SSD accessed with NVMe can take 30,000ns per access, 660 times longer than MLC DRAM. A 6TB working set application running in a 3TB DRAM system and needing 20,000 storage IOs executed in 300,000,000ns. When run in a 6TB MLC DRAM system with the same Xeon SP CPU it took just 50,000ns; 6,000 times faster.
The impact of this on machine learning model training and Big Data analytics runs will be incalculable, according to Alibaba Rahamabahini, AI Scientist Emeritus at Google’s Area 51 Moonshot facility; “With this kind of moonshot thinking around AI and machine learning, I believe we can improve millions of lives. It’s impossible to understate the positive effects of this game-changing development on science and technology, with the benefit of improving human life. This outsized improvement has inspired me, and I’m tremendously excited about what’s coming, such as actually delivering fully autonomous vehicles and real time cancer diagnoses.”
The technology borrows word and bit line technology from NAND without affecting the byte addressability of DRAM.
Four different voltage levels are needed to enable 2 bits per cell. Although there is more complex sensing and refresh circuitry, the fabrication process requires no extra steps so the DRAM foundries see a doubling of density with no manufacturing cost increase. DRAM controllers need extra firmware and a few extra fabrication steps. System builders should expect to see an at least effective 50 per cut in their DRAM prices, possibly more.
Arvinograda Mylevsky, lead researcher at Google’s Area 51 Moonshot facility, said: “For far too long DRAM expense has limited application working set sizes and blighted the industry with its need to use external storage. MLC DRAM, combined with Persistent Memory, will relegate SSD and disk drive storage to archive store status, freeing modern AI, machine learning and analytics from the shackles of out-dated, decades-old technology.”
Google is contributing the technology to the Open Compute project, and making it available on an open source basis to all DRAM semi-conductor foundry operators.
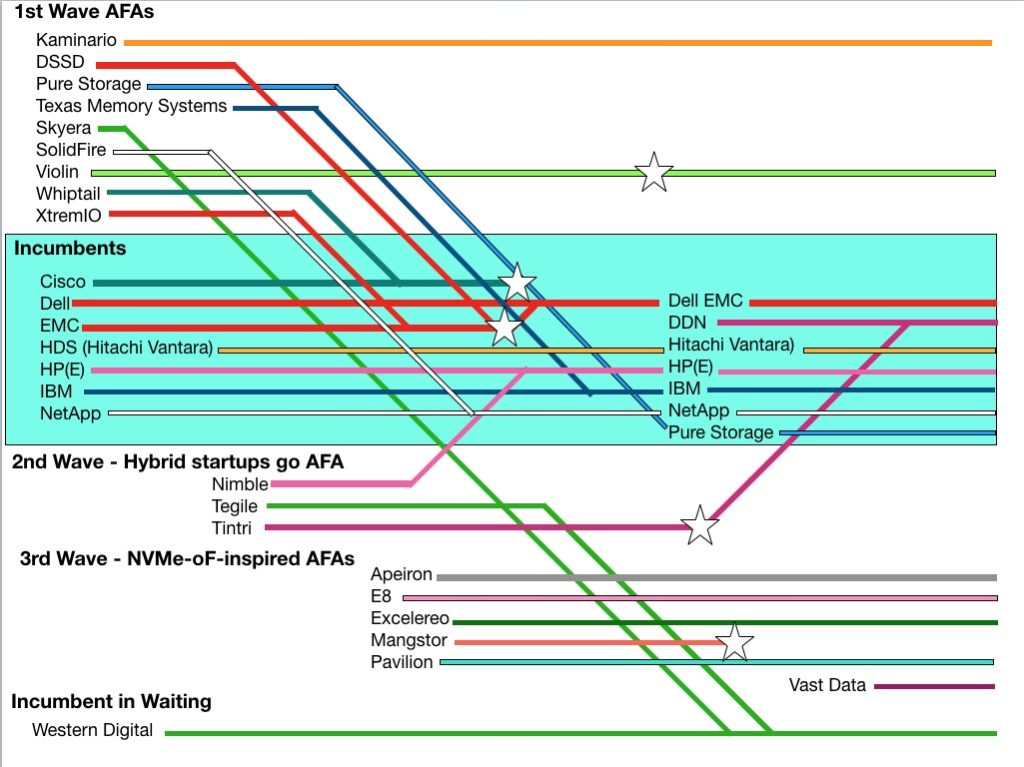
Fourteen years ago Violin Memory began life as an all-flash array vendor, aiming to kick slower-performing disk drive arrays up their laggardly disk latency butt. Since then 18 startups have come, been acquired, survived or gone in a Game of Flash Thrones saga.
Only one startup – Pure Storage – has achieved IPO take-off speed and it is still in a debt-fuelled and loss-making growth phase. Two other original pioneers have survived but the rest are all history. A terrific blog by Flashdba suggested it was time to tell this story.
Blocks & Files has looked at this turbulent near decade and a half and sees five waves of all-flash array (AFA) innovation.
We’re looking strictly at SSD arrays, not SSDs or add-in cards, and that excludes Fusion IO, STEC, SanDisk – mostly – and all its acquisitions, and others like Virident.
A schematic chart sets the scene. It is generally time-based, with the past on the left and present time on the right hand side. Coloured lines show what’s happened to the suppliers, with joins representing acquisitions. Stars show firms crashing or product lines being cancelled. Study it for a moment and then we’ll dive into the first wave of AFA happenings.
First Wave
The first group of AFA startups comprised DSSD, Kaminario, Pure Storage, Skyera, SolidFire, Violin Memory, Whiptail, X-IO and XtremIO. Pure and XtremIO achieved major success and XtremIO post-acquisition by EMC, became the biggest-selling AFA of its era, achieving $3bn in revenues after three years availability.
XtremIO bricks
EMC was convinced of AFA goodness and spent $1bn buying DSSD, an early NVMe-oF array tech – but it bought a dud. After Dell bought EMC it canned the product in March 2017. This was possibly the biggest write-off in AFA history.
Pure Storage grew strongly, IPOed and has now joined the incumbents, boasting a $1.6bn annual revenue run rate.
Kaminario survives and is growing. Violin has survived a Chapter 11 bankruptcy and is recovering from walking wounded status.
Texas Memory Systems was bought by IBM and its tech survives as IBM’s FlashSystem arrays. Skyera stumbled and was scooped up by Western Digital in 2014.
SanDisk had a short life as an AFA vendor with its 2014-era IntelliFlash big data array, before it was bought by Western Digital in 2015 for an eye-watering $19bn. That was the price WD was willing to pay to get into the enterprise and consumer flash drive business.
Whiptail was bought by Cisco in September 2013 for $415m. It found it had bought an array tech that needed lots of development work. In the end itcanned the Invicta product in June 2015.
Second wave – hybrid starts go all-flash
The next round of AFA development came from Nimble, Tegile and VM-focused Tintri. These three prominent hybrid array startups quickly went all-flash and formed a second AFA wave;.
All have been acquired. HPE bought Nimble with its pioneering InfoSight cloud management facility for its customers arrays. Nearly every other array supplier has followed Nimble’s lead and HPE is extending the tech to 3PAR arrays and into the data centre generally.
Poor Tintri crashed, entered Chapter 11 and its assets were bought for $60m by HPC storage supplier DDN in September last year. Tintri gives it a route into the mainstream enterprise array business.
X-IO was another hybrid startup that went all-flash. It stumbled, went through multiple CEOs and then, under Bill Miller, sold off its ISE line to Violin. It continues as Axellio, a maker of all-flash IOT edge boxes.
Incumbents retrofit and acquire
The seven mainstream incumbent suppliers all bought startups or /and retrofitted their own arrays with AFA tech and in two cases tried to develop their own AFA technology. One, NetApp’s FlashRay, was killed off on the verge of launch in favour of AFA retrofitted ONTAP.
The other, HDS’s in-house tech, survives but is not a significant player. In other words, no incumbent developed an AFA tech from the start that became a great product.
Dell EMC retrofitted flash to VMAX and VNX arrays on the EMC side of the house, and SC arrays on the Dell side. IBM flashified its DS8000 and Storwize arrays. HPE put a flash transplant into its 3PAR product line.
And Cisco? Cisco gave up after killing Invicta.
Invicta appliance
Interfaces
Initially, SSDs were given SATA and SAS interfaces. Then much faster multi-queue NVMe interfaces were used with direct access to a server or drive array controller’s PCIe bus, instead of indirect access through a SATA or SAS adapter.
This process is ongoing and SATA is on the way out as an SSD interface. NAND tech avoided the planar (single layer) development trap looming from every smaller cells becoming unstable, by reverting to large process sizes and layering decks of flash one above the other in 3D NAND.
It started with 16, then 32, 48, 64, and is now moving to 96-layers with 128 coming. At roughly the same planar-to-3D NAND transition time, single-bit cells gave way to double capacity MLC (2bits/cell) flash, then TLC (3bits/cell) and now we are seeing QLC (4 bits/cell) coming.
The net:net is that SSD capacities rose and rose to equal disk drive capacities – 10 and 12 and 14TB – and then surpass them with 16TB drives.
This process accelerated the cannibalisation of disk drive arrays by flash arrays. All the incumbents are busy helping their customers replace old disk drive arrays with newer AFA products. It’s a gold mine for them.
Third wave of NVME-oF inspired startups
We have also seen the rise of remote NVMe access, extending the NVMe protocol across networking links such as Ethernet and InfiniBand initially and lCP/IP and Fibre Channel latterly, to speed up array data access.
This technology prompted a third wave of AFA startups: Apeiron, E8, Excelero, Mangstor and Pavilion Data. Interestingly, DSSD was a pioneer of NVMeoF access but, among other things, was too early with its technology.
Mangstor crashed and fizzled out, becoming EXTEN Technologies, but the others are pushing ahead, trying to grow their businesses before the incumbents adopt the same technology and crowd them out.
However, the incumbents, having learnt the expensive lesson of buying in AFA tech, are adopting NVME-oF en masse.
The upshot is that 15 companies are pushing NVME-oF arrays at the market.
The storage-class memory era arrives
Storage-class memory (SCM), also called persistent memory, as exemplified by Intel’s Optane memory products using 3D XPoint non-volatile media, promises to greatly increase data access speed. Nearly all the vendors have adoption programs. For instance:
HPE has added Optane to 3PAR array controllers.
Dell EMC is adding Optane to its VMAX and mid-range array line.
NetApp is feeding Optane caches in servers from its arrays.
Optane SSD
The third wave of startups need to adopt SCM fast or face the prospect of getting frozen out of the NVMe-oF array market they were specifically set up to develop.
Fast-reacting incumbents are moving so quickly that large sections of the SCM-influenced array market, the incumbent customer bases, will be closed off to the third wave startups and that will result in supplier consolidation.
It has always been that way with tech innovation and business. Succeed and you win big. Fail and your fall can be long and miserable. But we salute the pioneers- the healthy like Pure and Kaminario, and the ones with arrows in their back – DSSD, Mangstor, Tintri, Violin, Whiptail, X-IO.
You folks helped blaze a trail that revolutionised storage arrays for the better. and there is still a ways to go. How great is that.
Vexata, the extreme high-performance storage array startup, has laid off several staff and imposed pay cuts, according to industry sources. The company declined to comment on pay or confirm the number of job losses.
Founded in 2013, Vexata has raised $54m in four funding rounds, of which the most recent was a $5m top-up in 2017.
The company’s scale-out VX-Cloud software and VX-100 software/hardware system comprises intelligent front-end servers talking to intelligent back-end NVMe storage nodes. Performance is claimed at 20 million IOPS.
In an interview, Vexata said a recent reorganisation saw the company move from direct sales to channel partnerships and had resulted in some departures. We can confirm at time of writing four job losses, but our sources say several more are in the market looking for new roles.
Blocks & Files understands Farad Haghighi, VP worldwide support and services, and Stephen King, director of sales and business development, left in January. Jack Dyke, senior solutions engineer, was laid off recently and Mithun Jose, staff engineer in India, left this month.
Vexata’s view
Rick Walsworth, VP product and solution marketing, told us in an email interview, that Vexata had “made some strategic shifts and subsequent adjustments in staffing and expenses to align to the new strategies. Specifically, we have adjusted focus on two areas; Go to Market motion and Product Development.
He explained: “As of Q4 of last year we made a strategic shift towards partner-driven sales motion vs a direct sales motion. While we retain a handful of strategic sales executives for large accounts, we are driving most of our sales growth through this new partner motion.
“The Fujitsu announcement in November last year was the first of many anticipated announcements. Since that partnership announcement, Fujitsu has been able to nearly double our pipeline in the last quarter. We expect this to ramp even further as we engage with Fujitsu on a global scale.”
Walsworth said the company had “also ramped work on our cloud and cloud-scale focused offering, which you saw as part of the VX-Cloud announcement a few weeks back. This shift meant an alignment on engineering talent around this new market and appropriate adjustments to ensure we can deliver to the unique product and market needs.”
Pivotal changes
The all-flash array market is a tough business environment for startups. Judging from its actions Vexata is seeking to reduce cash burn as it fights to gain traction in a market dominated by established storage vendors.
This explains the pivot to partner sales to expand sales coverage and also to cloud software to reduce engineering costs and capitalise on customer movement to the cloud.
SoftIron has announced three Ceph-based storage systems – an upgraded performance storage node, an enhanced management system and a front-end access or storage router box
Ceph is free source storage software that supports block, file and object access and SoftIron builds scale-out HyperDrive (HD) storage nodes for Ceph. These can outperform dual-Xeon commodity hardware (see below) and are 1U enclosures, with an Arm64 CPU controlling a set of disk drives or SSDs. There are Value, Density and Performance versions.
The Value system (HD11048) has 48TB of disk-based storage using 8 drives. The Density system (HD11120) has 120TB of disk capacity while the Performance variant has 56TB of SSD capacity (HD31056), using 14 x 4TB SSDs.
SoftIron’s existing Performance node is a single processor system. The new HD32112 Performance Multi-Processor node has two CPUs and 28 x 4TB SSDs, totalling 112TB. This is twice the capacity of the first Performance system.
SoftIron Performance Multi-Processor system board showing two CPUs
Tabular comparison of the two SoftIron Performance products
The new HD Storage Manager appliance simplifies the complex Ceph environment for sysadmins. The GUI enables:
Centralised management of HyperDrive and Ceph
Update, monitor, maintain and upgrade HyperDrive nodes
Manage file shares SMB (CIFS) and NFS, object stores (S3 and Swift), and block devices (iSCSI and RBD – RADOS block devices)
Single HD product management facility
Insight into Ceph storage health, utilisation and predicted storage growth
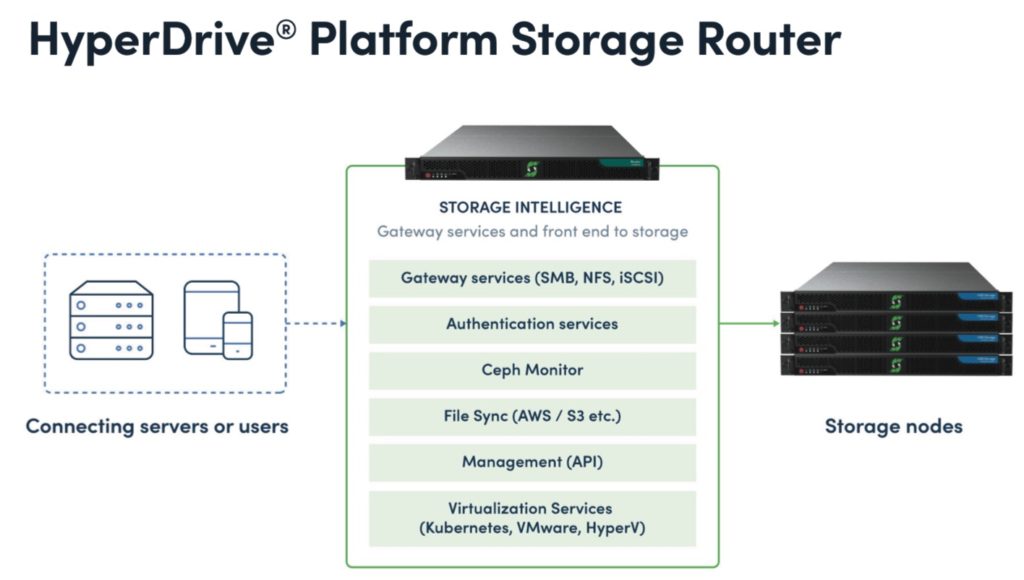
The HD Storage Router centralises front-end client access protocols to the storage nodes. It is a 1U system which provides Ceph’s native block (RBD), file (Ceph-FS) and object (S3) access, adding iSCSI block and NFS and SMB/CIFS. The iSCSI block and file protocols can operate simultaneously.
The NFS facility enables support of Linux file shares and virtual machine storage. SMB and CIFS enable support of Windows file shares.
Performance
SoftIron’s products have skinny ARM processors compared to commodity storage boxes with beefier Xeon CPUs. However SoftIron claims its integrated hardware and software systems outperform Ceph running on commodity dual-Xeon hardware.
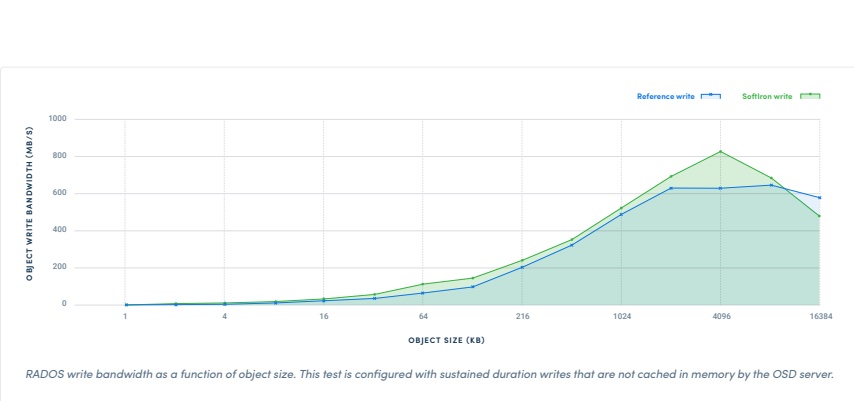
With sequential reads and writes a SoftIron entry-level system (8-core ARM CPU, 10 x 6TB 7,200rpm disk drives, 256GB SSD for write journalling) achieved 817MB/sec peak bandwidth, with SoftIron’s HyperDrive being 26 per cent faster.
A cluster of three systems achieved 650MB/sec. Each node used 2 x 8-core Xeon E5-2630 v3 processors, 12 x 1.8TB SAS disk drives and 4 x 372GB SSDs.
Sequential object write performance comparison
With cached random object write performance the SoftIron system peaked at 606MB/sec with the dual Xeon box going faster at 740MB/sec.
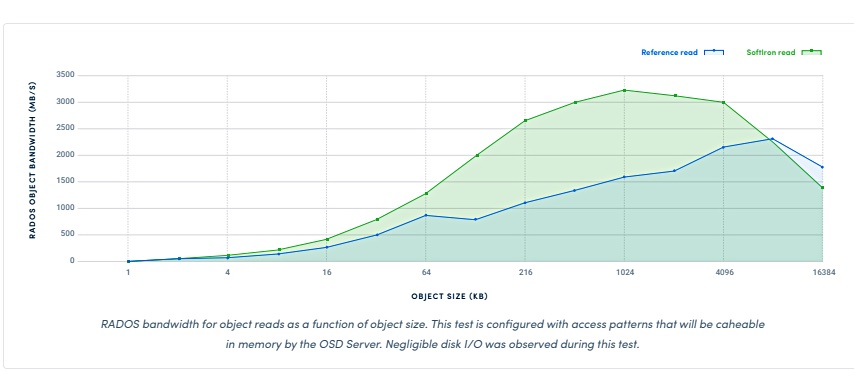
But supremacy was regained with cached random object read performance. The Xeon system reached 2,294MB/sec while SoftIron’s box went 44 per cent faster at 3,300MB/sec.
Cached random object read performance comparison
The term ‘OSD’ on the charts stands for Object Storage Device, a storage node in Ceph terms.
Summary
The three new SoftIron products bring flash capacity almost up to disk-based capacity (112TB NAND vs 120TB disk), add improved and simplified management and extend Ceph usage by adding iSCSI and NFS gateway functionality. This means that an enterprise lacking Ceph-skilled admin staff can envisage using it for the first time with a variety of potential storage use cases.
However, the SoftIron system performs poorly on Ceph object writes compared to a dual-Xeon CPU system. On object reads it’s faster.
We have no information about the performance of SoftIron Ceph systems on block or file access by the way.
Amazon Web Services has announced its Glacier Deep Archive is available at about $1/TB/month, the lowest data storage cost in the cloud.
AWS claims this is significantly cheaper than storing and maintaining data in on-premises magnetic tape libraries or archiving data off-site. Of course data retrieval is faster from an on-site tape.
Glacier Deep Archive was previewed in November last year. The service has eleven ’nines’ data durability – 99.999999999 per cent. Ordinary data can be retrieved within 12 hours or less while bulk data at the PB level can take up to 48 hours. The data thaw time is s-l-o-w.
Retrieval costs a standard $0.02/GB or $0.0025/GB for bulk data.
Bulk data is a retrieval speed option. The AWS S3 FAQ says: “There are three ways to restore data from Amazon S3 Glacier – Expedited, Standard, and Bulk Retrievals – and each has a different per-GB retrieval fee and per-archive request fee (i.e. requesting one archive counts as one request).“
In AWS’s US East (Ohio) region standard retrievals cost $0.01/GB, expedited retrievals $0.03/GB and bulk retrievals $0.0025/GB. Expedited retrievals typically complete in five minutes, standard in five hours and bulk in 12 hours
Amazon says GDA is suitable for data that is accessed once or twice a year with either 12 or 48 hour latencies to the first byte.
The Restore (Retrieval) request, effected by an API call through the S3 management console, makes a temporary copy of the data, leaving the GDA-held data intact. The thawed out GDA data is not streamed direct to you on-premises or inside AWS for use as it comes in. You have to wait for the copy to be made.
The copy is accessed through an S3 GET request and you can set a limit for the retention of this temporary copy.
GDA data upload is done through an S3 PUT request or via the AWS management console, or AWS Direct Connect, Storage Gateway, Command Line Interface or SDK.
Tape Gateway
AWS’s Storage Gateway is a virtual tape library (VTL) in the AWS cloud Glacier Deep Archive, with virtual tapes despatched to GDA from your on-premises system. The Tape Gateway code is deployed as a virtual or hardware appliance. No changes are needed to existing backup workflows. The backup application is connected to the VTL on the Tape Gateway and streams backup data to this target device.
The Tape Gateway compresses and encrypts the data and sends it off to a VTL in Glacier or the Glacier Deep Archive.
A cache on the Tape Gateway ensures recent backups remain local, reducing restore times.
S3 storage classes
As a reminder AWS offers;
Simple Storage Service (S3) Standard
S3 Intelligent Tiering
S3 Standard Infrequent Access (IA)
S3 One Zone IA
S3 Glacier for archive
S3 Glacier Deep Archive
You can use S3 Lifecycle policies to transfer data between any of the S3 Storage Classes for active data (S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA, and S3 One Zone-IA) and S3 Glacier.
Net:net
Should you give up your on-site tape library? Blocks & Files thinks this needs careful analysis of the costs of tape library storage and retrieval, with retrieval speed taken into account.
SpectraLogic TFinity ExaScale library
There is a crossover at a certain level of data stored and data retrieval frequency and size. And calculating that crossover point for your tape installation is key. Although your on-site tape library costs may be predictable into the future, AWS’s GDA costs are driven by marketing needs. They may dip a little over the next year or three and then rise again if AWS grabs enough tape library market share.
Monopolists see little need to lower prices. Of course, GDA is a good idea if you don’t have an on-site tape library and need to store data long-term with one or two accesses a year.
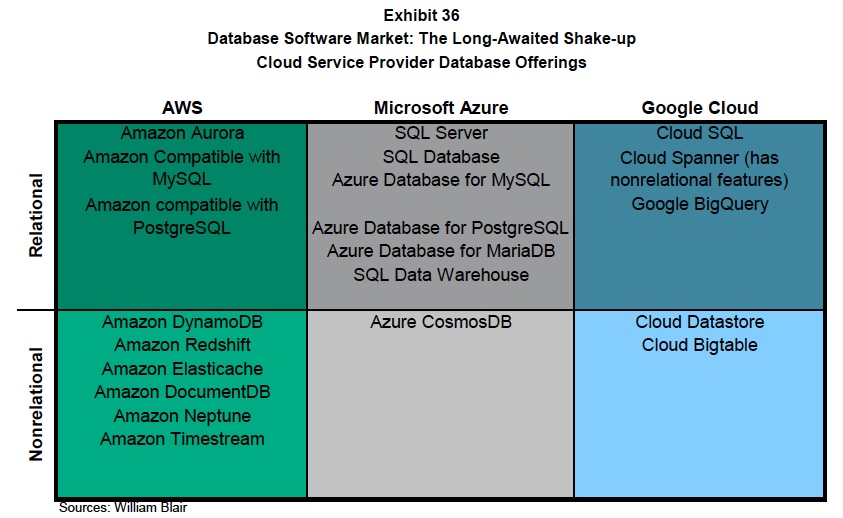
I’ am bewildered by all the changes in the database market. It used to be so simple with relational databases but then along came NoSQL and the confusion started.
Today there are multiple types of non-relational databases, public cloud databases, business analytics databases and unified relational-NoSQL databases and graph databases and ….
William Blair database report diagram
It has become too much for generalists to easily comprehend what’s going on.
And so my thanks goes to Jason Ader, an analyst at William Blair, who has written a comprehensive report on the database market report, in which he details technology development trends, classifies products, sizes the market and profiles the main players.
William Blair kindly says we can distribute it to our readers and here it is;
Western Digital is developing zoned SSDs that can be managed by host systems to speed data access and prolong the life of the drives.
This could make short-life QLC (4bits/cell) flash drives usable for fast-access archive. Applications that currently use shingled disk drives for this purpose could instead use zoned SSDs with few code changes to increase data access speed.
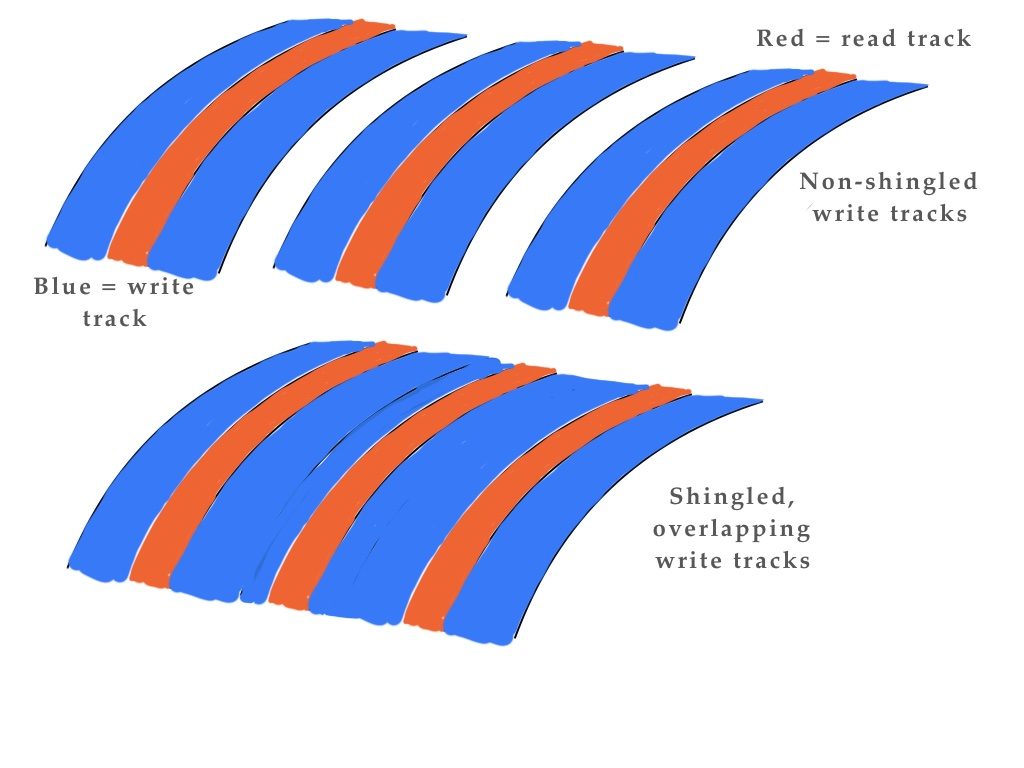
Shingled disk drives
Shingling exploits the difference in width between larger disk drive write tracks and read tracks. The tracks are shuffled closer, keeping read tracks separate while overlapping write tracks at their edges.
Disk shingling concept
This means the drive can hold roughly 20 per cent more data.
But data can no longer be directly rewritten as that would also alter an underlying write track.
Instead whole blocks of write tracks are rewritten when any data in the block needs rewriting. This necessitates reading the data in the block, adding the new data and then writing the data back to the block of tracks.
Three points to note: first, this is similar to the read-program-erase (PE) cycle used when blocks of written data are recovered for re-use in SSDs. Second, in Western Digital’s scheme the host manages the shingled drive re-write process and not the drive itself. Third, a block of tracks is also a zone of tracks.
Shingled drives are finding favour with hyperscale customers who need to store PBs of read-centric bulk data as cost effectively as possible, and relish turning a raw 14TB disk drive into, say, a 16TB shingled disk drive.
Zoning NAND
In some cases, these customers need faster access to read-intensive reference data than disk storage can provide. Step forward QLC (4bit/cell) flash. However it wears out faster than TLC (3bits/cell) flash. QLC has a low PE cycle number – possibly 1,000 to 1,500.
Data is written anywhere there is free space in an SSD, without reference to usage patterns or access frequency. Each SSD looks after its own data deletion, in a process called garbage collection that recovers blocks for re-use.
This involves reading any valid data in the blocks and writing it elsewhere in the SSD so the contents of a whole block can be erased and recovered.
The additional writes are called write amplification and this can prolong the life of an SSD if the write amplification factor is as low as practicable. Western Digital thinks zoning can achieve this and that applications that host-manage shingled drives can managed zoned SSDs equally well – the interface is basically the same.
Zoned NameSpace SSDs
Matias Bjørling Western Digital’ director for solid-state system software ,gave a presentation on this topic at the Vault’19 Linux Storage and Filesystems conference in February 2019. He said a NVMe working group developing industry standards for Zoned Namespaces (ZNS) has a technical proposal for the technology.
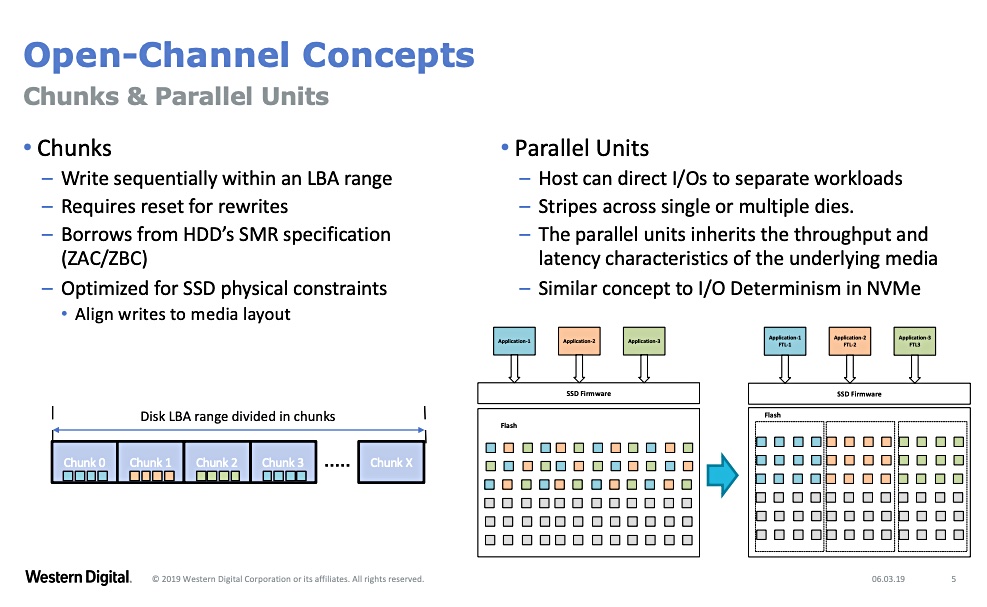
NVMe-access SSDs have parallel IO queues and these can be used to direct different data types to different zones of an SSD in WD’s Open-Channel concepts scheme. The zones can span multiple dies their size is based on the SSD’s block size.
Bite-sized chunks
The drive’s address space is known as its Logical Block Address (LBA) range and this is divided conceptually into chunks, which are multiples of the SSD’s block size.
Chunks are grouped together into zones and these zones are aligned to the NMAND block size and zone capacity is aligned to the SSD’s capacity.
Different zones can be dedicated to different types of data – music, video, images, etc. – so that the usage pattern for data within any one zone is constant and predictable.
Each zone is written sequentially. Incoming data of any one type is divided into chunk-sized pieces and written to a specific zone in sequential format. Zones can be read randomly and are deleted as a whole, which reduces consequent write amplification to near zero and prolong’s the SSD’s life.
The SSD controller’s own workload is reduced and it needs less DRAM to do it, which lowers its cost. As well as reduction in the write amplification factor, the SSD needs less over-provisioning of capacity to replace worn-out cells during its working life., IO performance is more consistent, as there is little or no interruption from device-side garbage collection or wear-levelling.
SK Hynix and Microsoft
SK Hynix is developing a zoned SSD and has blogged about it. It suggests zoned SSDs could be 30 per cent faster than their traditional counterparts and last four times longer.
SK Hynix zoned M.2 format SSD
Microsoft is also keen on the idea, with principal hardware program manager Lee Prewitt speaking on the subject at the Open Compute Project summit this month. A video of his pitch can be seen here and his thoughts on ZNS begin at 8min 50sec.
Lee Prewitt’s Microsoft ZNS pitch at the OCP Summit
Blocks & Files thinks zoned SSDs will find a role as storage devices for bulk, fast-access reference data and help make both TLC and QLC flash usable as a near-archive data store. Get Matias Bjørling’s slide deck here.
Vcinity, a San Jose networking startup, has transferred 1PB of file data across a 4,350 mile, 100 Gbit/s WAN, with 70 ms latency in 23 hours and 16 minutes.
It says it can use up to 97 per cent of the available network bandwidth in the link.
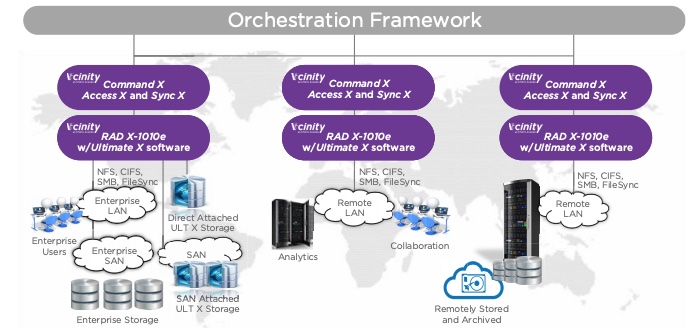
The company’s Ultimate X (ULT X) products use a fabric extension technology, and support InfiniBand and also RDMA over Converged Ethernet (RoCE).
Vcinity says it can make a remote filer seem as if it were local. Chief Technology Officer Russel Davis said: “Our technology has shattered the mould of data-access – we extend RDMA over global distances, so users can remotely access, manage and manipulate large datasets.”
Vcinity networking concept scheme
This PB-transferred-in-under-24-hours claim rang a distant memory bell. Surely … yes, Bay Microsystems did just that in May 2018, moving a petabyte of data across a 2,800 mile network link in a little over 23 hours. It said it took the distance out of data at the time.
How do these two companies and their technologies relate to one another?
Bay Microsystems
Bay Microsystems was founded in 1998 and went through six funding rounds, taking in $34.4m publicly and possibly more privately. Its CEO from November 2015 to October 2018 was Henry Carr and its COO and EVP for emerging solutions was Russ Davis from January 2014 to October 2018.
Vcinity came out of stealth mode in October 2018 and its CEO is Henry Carr. Russ Davis is also its CTO and COO. The SVP for Engineering is Bob Smedley and he was SVP Engineering at Bay Microsystems too. The CFO is Mike McDonald and his LinkedIn entry says he has been in that position since 2004, which is nonsense as the firm was only founded in 2018.
Vcinity says it acquired Bay Microsystems assets in July 2018. There was no fanfare and no reason was given for Bay Microsystems going out of business.
Steve Wallo, VP for Sales Engineering at Vcinity, held the same role at Bay Microsystems. Mark Rodriguez, VP Product Management at Vcinity, was in the same position at Bay Microsystems.
There are no recorded funding rounds for Vcinity, but the board includes James Hunt, a professional investor, and Scott Macomber, a private investor.
Vcinity is Bay Microsystems reborn
It’s obvious that Vcinity is actually Bay Microsystems reborn, probably re-financed, and the technology is re-worked Bay Microsystems technology.
Vcinity sells its technology as RAD X-1010e and RAD X-1100 PCIe cards and ULT X software running in off-the-shelf Linux servers or in virtual machines. This presents a NAS (NFS and SMB) interface to accessing application servers.
Ultimate X server
The products can be used to move data fast across long distances for migration purposes, or to carry out real-time actions on far-away files.
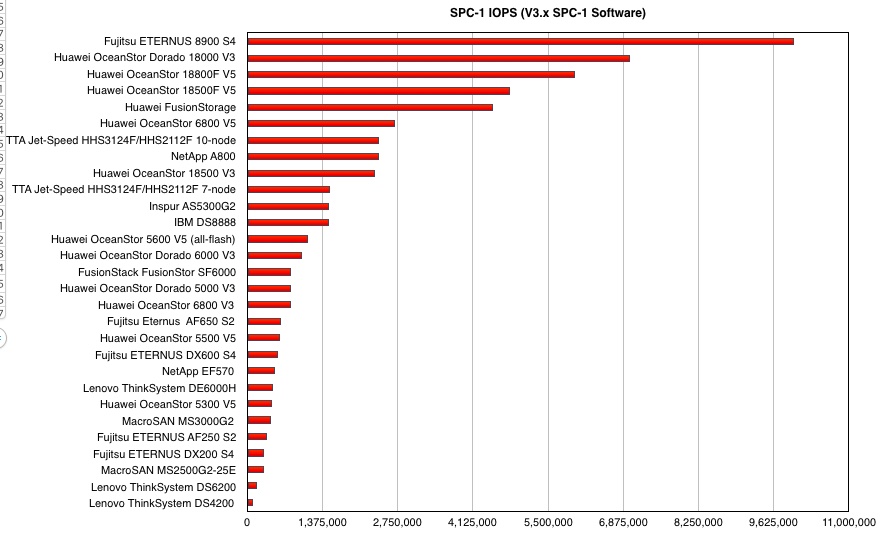
Fujitsu has set the new top score for the Storage Performance Council SPC-1 benchmark, scoring 10,001,522 IOPS with its ETERNUS DX8900 S4 array.
In SPC-1 benchmark terms this is the fastest storage array in the industry.
The SPC-1 v3 benchmark tests a storage array with a single business critical-type workload and supports deduplication and compression. Fujitsu’s ETERNUS DX8900 S4 is a high end and hybrid disk and flash array with six ‘nines availability and a compression engine.
It supports NVMe drives and 32Gbit/s Fibre Channel links. The test configuration was all-flash with 230,400GB of storage capacity using 576 x 400GB SAS SSDs, and linked to 44 servers.
SPIC-1 results summary table for ETERNUS DX8900 S4
The next highest-scoring system is a Huawei OceanStor 18000nV3, which achieved 7,000,565 IOPS. Another Huawei system, an OceanStor 18800F V5, is third with 6,000,572 IOPS.
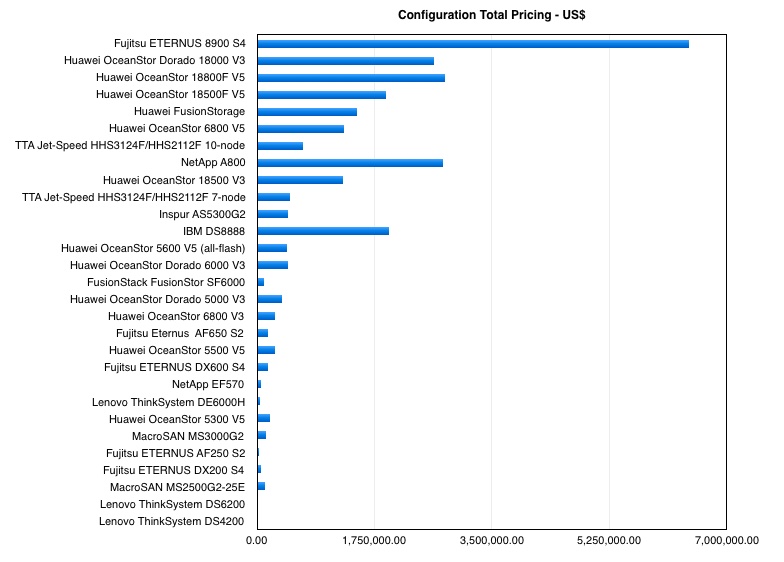
As well as the fastest system tested the Fujitsu array is also the most expensive at $6,442,522.88. The second-placed Huawei system’s total price was $2,638,917.96.
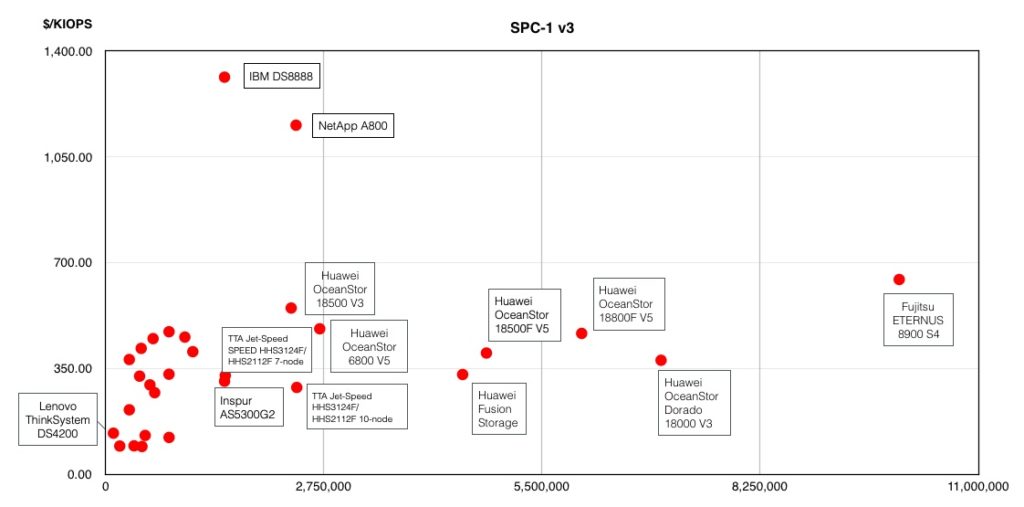
By charting IOPS performance against cost per thousand IOPS we can get a better picture of how the DX8900 stacks up against other systems.
Fujitsu’s array is way out to the right in a category all of its own, leaving Huawei’s arrays behind in the dust.
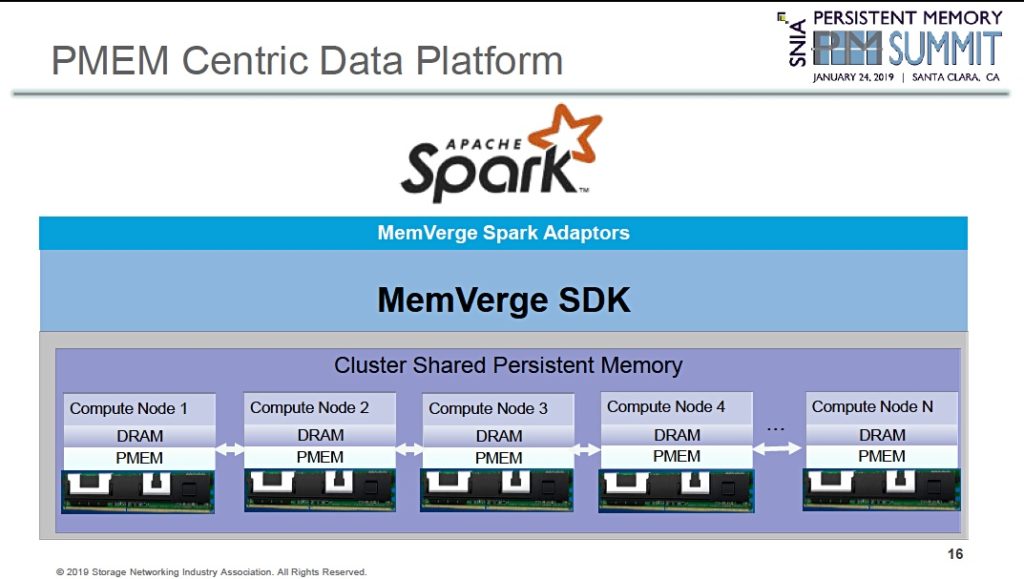
MemVerge a stealth-mode startup, based in Silicon Valley, is developing shared pools of external Optane DIMM memory to make Spark and similar applications run faster than servers with local drives.
The company outlined the technology at the SNIA’s Persistent Memory Summit in January2019 and you can download the slides and watch the video.
The presentation shows how storage and memory can be converged using Optane DIMMs to reduce data-intensive application run times. Of course it is a sneak preview, and MemVerge gives no clue when it could become a shippable product.
MemVerge presentation at SNIA Persistent Memory Summit
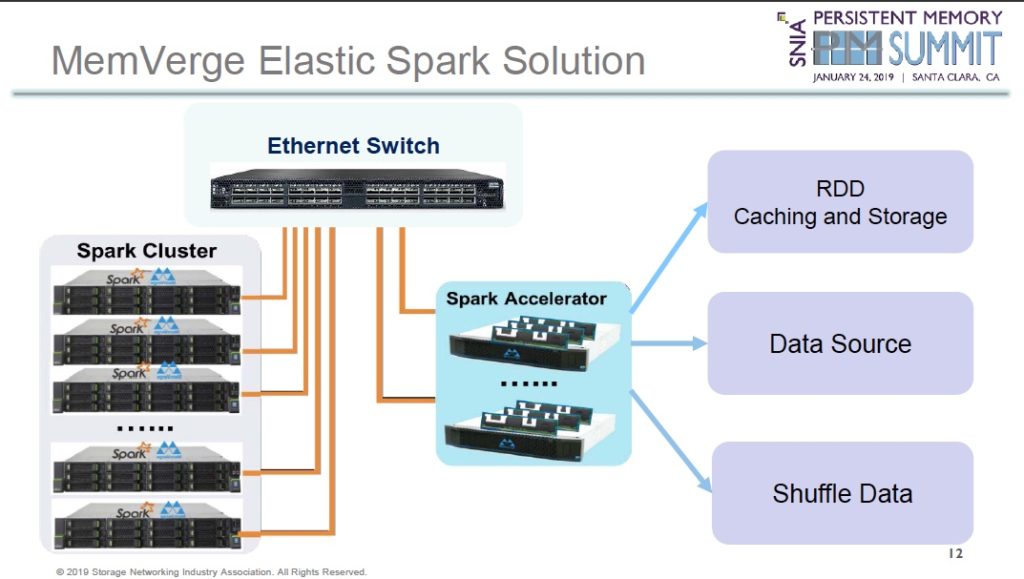
The idea is to cluster Spark Accelerators – servers containing a CPU, some DRAM and Optane DIMMs – to form a single virtual pool of memory which is accessed by application compute nodes (servers) in a Spark Cluster using an Ethernet switch.
Data is analysed by the Apache Spark engine using MemVerge’s PMEM Centric Elastic Spark data storage system (PMEM is Optane persistent memory).
Spark cluster nodes run the Tencent Spark application and MemVerge software. Spark accelerators store source data for the Spark Cluster nodes and also intermediate calculation results called Resilient Distributed Dataset (RDD) and Shuffle data.
Shuffle dance
Shuffling is a process of redistributing data needed by the Spark application cluster nodes. It can mean data has to move between different Spark application servers.
If the shuffle data is held in a single and external virtual pool it doesn’t have to actually move. It just gets remapped to a different server, which is much quicker than a data movement.
A Spark Accelerator cluster looks like this architecturally:
Individual accelerator nodes – called compute nodes in the diagram – use Optane DC Persistent Memory and standard DRAM. They present a pool of persistent memory through Spark adapters to the Spark accelerator nodes.
In response to an audience question at the Summit, the MemVerge presenter, co-founder Yue Li, declined to say if the Spark cluster nodes accessed the accelerator nodes using RDMA. Blocks & Files thinks the company uses an RDMA-class access method to enable the accelerator to out-speed local drives in the cluster nodes.
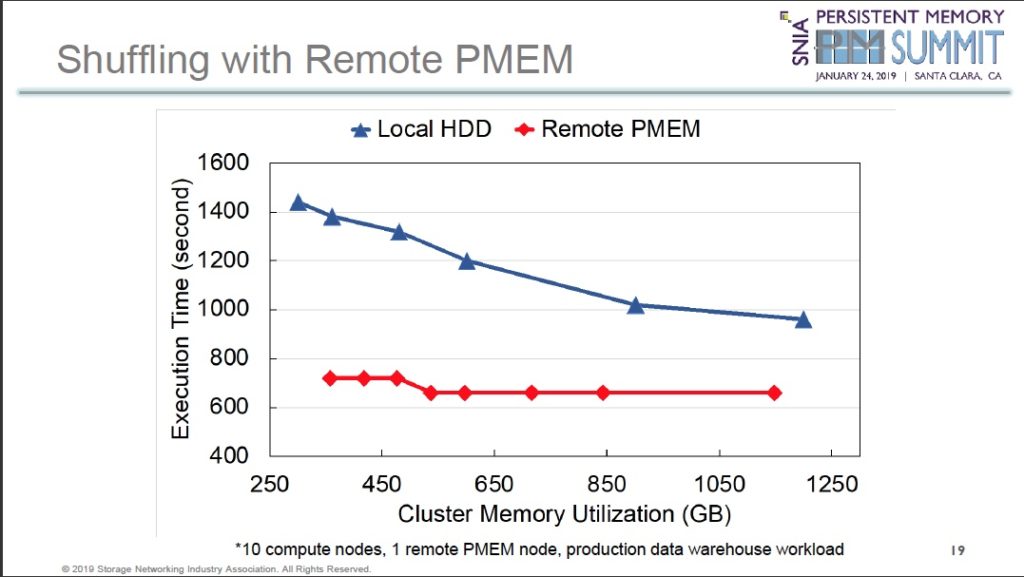
Yue Li gave three performance examples in his presentation. First, a HiBench wordcount time run, with a 610GB data set, took 10 minutes using a 5-node Spark cluster with local SSDs while the PMEM-based Spark accelerator node took 2.2 minutes.
Second, persisting RDD data to a local hard drive took roughly a third longer than putting it in the remote PMEM pool formed by the Spark accelerators.
Third, shuffling data was also faster with the remote PMEM than local disk drives.
Asked why not simply put Optane drives in the Spark Cluster nodes, Yue Li said there could be a 1,000 or more such nodes, which makes it expensive and challenging. It is simpler and less expensive to build a single shared external PMEM resource, he said.
MemVerge is developing its technology with Intel’s help and in partnership with ecommerce powerhouse Tencent which has a Cloud Data Warehouse.
This piqued our curiosity about the relationship between the two companies and so who better to ask than CTERA CEO Liran Eshel?
The Q and A
Blocks & Files: Are the local and cloud dedupe processes separate with, for example, HPE SimpliVIty doing the local dedupe, and CTERA doing the cloud dedupe? If they are separate processes do the local dedupe files have to be rehydrated so they can then be deduped again by the cloud dedupe process?
Liran Eshel: True. The processes are separate. However, the local dedupe is hardware accelerated, so the rehydration and dehydration takes place in real-time without creating disk I/O or consuming any temporary disk space.
The files are never stored in a dehydrated form. The dedupe algorithms are also different, the local one is tuned for high IOPS, primary storage use case, and to do so, relies on low latency directly connected flash.
In contrast, the cloud deduplication is optimized for WAN at high-latency, as well as providing the ability to perform global deduplication between multiple sites.
Blocks & Files: Is the CTERA Edge X Series only available on an HPE SimpliVity hardware/software base?
Liran Eshel: The Edge X is only based on HPE SimpliVity. The Edge V is a virtual edition that can run on any other server or HCI platform, and is certificated for the likes of Dell, Cisco and Nutanix.
Blocks & Files: What is the relationship between CTERA and HPE? Is CTERA reselling HPE SimpliVity systems? Do customers only buy Edge X Series systems from CTERA?
Liran Eshel: CTERA is reselling SimpliVity in the case of the X Series. In addition to that, HPE is selling the CTERA software portfolio as part of HPE Complete program on top of HPE HW and in combination with 3Par and Scality.
Blocks & Files: Did CTERA consider partnering other HCI vendors, such as Dell EMC with VxRail, or Nutanix with either vSphere or Acropolis?
Liran Eshel: CTERA is already partnering with Cisco HyperFlex and Nutanix (both vSphere and Acropolis), in a meet in the channel mode.
Blocks & Files: Where does support come from; CTERA and/or HPE? Does the customer have 1 or 2 throats to choke?
Liran Eshel: 1 throat to choke. CTERA takes front line for the X Series, with back-line support from HPE for all HW and HCI related matters.
Blocks & Files: How is data protection (backup) provided?
Liran Eshel: CTERA has built-in backup capabilities with customer defined interval, retention and choice of cloud.
The CTERA relationship is based in SimpliVity hyperconverged kit which is ProLiant server-based. Nutanix doesn’t need to do this because it has its own File product. Ditto NetApp which has ONTAP filers available for its HCI products if needed.
HPE’s deal with CTERA could spark other HCI suppliers to addfile services from external suppliers. For example, Cisco, Pivot3 and Scale Computing might look to do something here.