IBM has updated Spectrum Discover, object storage and Spectrum Protect Plus products and added the FlashSystem 9100 array to its VersaStack converged infrastructure.
The company made the announcement in a webcast by by Eric Herzog, CMO at IBM Storage. He said the updates help customers better handle data in the petabyte-to-exabyte range. Forget data lakes – they are moving to data oceans.
Spectrum Discover
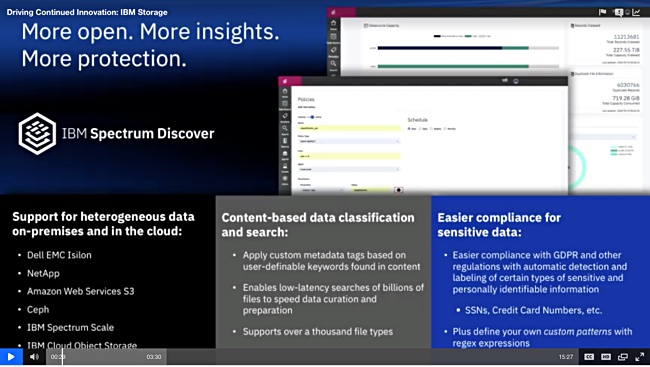
Spectrum Discover, a file cataloguing and indexing product, gets support for heterogeneous environments – Dell EMC Isilon and NetApp filers, Amazon Web Services S3, Ceph, IBM Spectrum Scale and IBM Cloud Object Storage.
It can detect personally identifiable information, such as credit card and social security numbers, and is said to be compatible with GDPR and the California Consumer Privacy Act which is expected to be enforced starting in 2020.
An un-named beta test customer said Spectrum Discover catalogued 254 million files across three file systems. Some 45 per cent of the data was flagged as inactive and transferable to cheaper archive storage. The software identified 84 users with wholly inactive data.
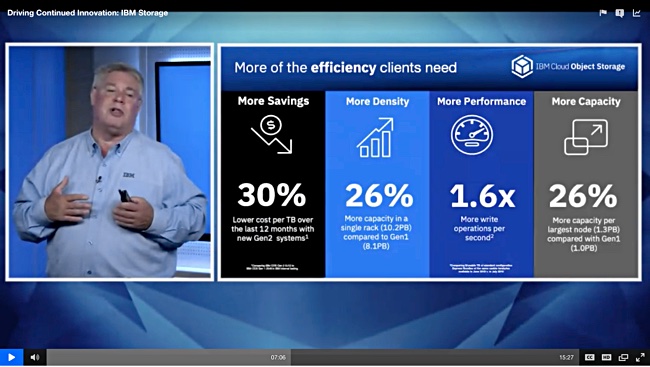
There is a second-generation COS appliance featuring:
Drop of up to 37 per cent in terms of cost per terabyte,
A 26 per cent increase in capacity in a single rack to 10.2 petabytes.
Up to a 25 per cent increase in throughput.
Herzog presenting on IBM COS.
Herzog said these are all versus the company’s original appliance. IBM is not telling us the enclosure sizes, the disk sizes or the prices or the availability. There is no way of comparing IBM on-premises COS systems to other vendor’s systems as all the comparisons IBM makes are self-referential.
Spectrum Protect Plus
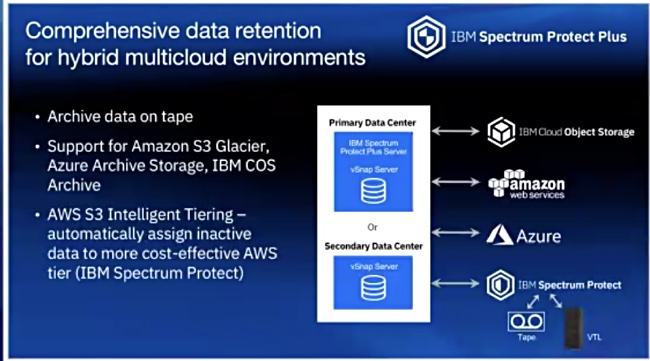
IBM Spectrum Protect Plus, in v10.1.4, can now protect IBM Db2, Oracle, Microsoft SQL Server, and MongoDB databases hosted on AWS. It can also run disaster recovery from backup repositories stored in AWS.
Data on AWS-hosted repositories can be archived to tape, or to S3 Glacier, Azure Archive Storage, or IBM Cloud Object Storage Archive, and it supports AWS S3 Intelligent Tiering
Spectrum Protect Plus is available via the AWS Marketplace.
VersaStack
The VersaStack CI portfolio now includes a FlashSystem 9100 offering. It includes Spectrum Virtualize and can federate up to 450 non-IBM storage arrays with the FlashSystem, as well as move data to and from public clouds.
Herzog said a 4-node 9100 system could pump out 15m IOPS.
Comment
There is much here to please IBM’s customers. The announcement was big on hero numbers and features but light on product details. IBM is maintaining a good quarterly cadence of storage news announcements but the announcements tend to be self-referential and lack the details needed for comparison with competing vendors’ products.
The Evaluator Group has published an evaluation guide to composable infrastructure and its suppliers.
The guide defines composable infrastructure as a “comprehensive, rack-scale compute environment that uses software-defined networking techniques to connect independent servers, storage and switch chassis or modules by PCIe or Ethernet.”
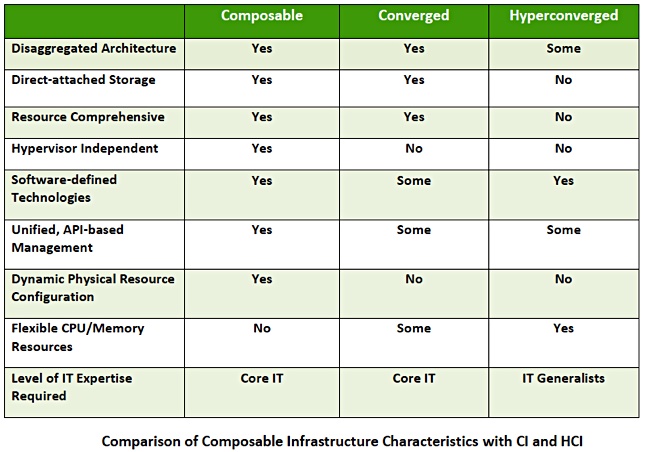
According to the Evaluator Group, composable infrastructure incorporates elements of both converged infrastructure (CI) and hyperconverged infrastructure (HCI).
Composable systems disaggregate physical resources, in common with CI – putting storage, networking and compute into dedicated modules. By contrast, HCI systems combine physical resources. This allows the composable system to create compute configurations with more storage, more networking connectivity and special resources like GPUs and FPGAs.
The guide provides a table comparing composable, converged and hyperconverged infrastructures:
The inclusion of UCS is a surprise. Here is what the Evaluator Group has to says about this: “Cisco’s Universal Computing System, with software-controlled compute and software-defined networking, was an early example of composable infrastructure, although not promoted or sold as a composable solution, per se.”
The guide suggests that composable infrastructure will “embrace the eventual disaggregation of the CPU-memory complex, improving flexibility and resource efficiency. This would also enable the sharing of DRAM/NVM resources and support putting data closer to the CPU, a long-time goal of distributed computing architectures.”
Also composable Infrastructure is not designed to replace converged or hyperconverged infrastructures, the guide argues. The technology is suitable for “companies seeking the scale and power of CI with the “infrastructure-as-code” aspects of HCI,.”
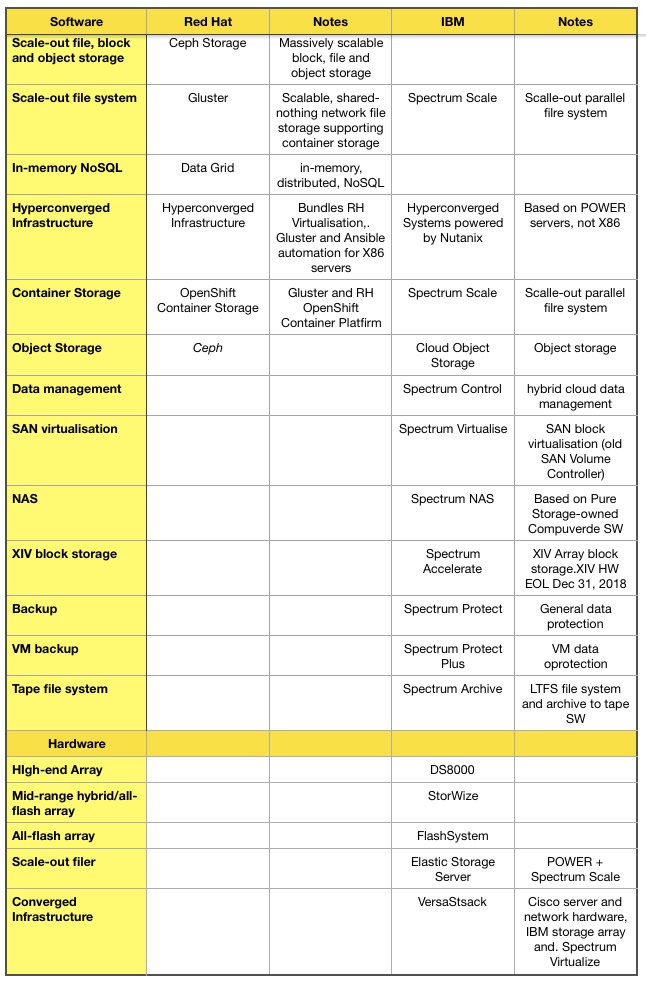
IBM closed its massive $34bn Red Hat acquisition yesterday. The Red Hat portfolio includes five open source storage software products. Let’s take a closer look.
For starters, there is little crossover with IBM’s own storage offerings.
We tabulated each company’s storage products and came up with four or five partial overlaps.
Red Hat has Ceph-based storage software, which provides scalable file, block and object storage. IBM has nothing exactly like this but its Spectrum Scale delivers massively scalable and parallel access file storage. IBM also has its Cloud Object Store for object storage, so there is partial overlap with Ceph on the file and object side.
Red Hat’s Gluster scalable network file system software overlaps with Spectrum Scale and to an extent with Red Hat’s own Ceph.
IBM’s hyperconverged infrastructure product is based on Nutanix software and POWER servers. The Red Hat hyperconverged infrastructure software is for X86 servers so the effective overlap is minimal.
The Red Hat OpenShift Container Storage has an overlap with Spectrum Scale which can also provide container storage.
Otherwise the two product sets largely complement each other.O
How deep is IBM’s love for open source software?
Could IBM conceivably transfer one or more storage products to Red Hat and provide them as open source software?
For example, XIV grid array software could be transitioned to open source as the XIV array system is no longer supported.
IBM might ask itself why it should have two ways of providing software, its own proprietary products and the Red Hat open source product set. Perhaps it will consider expanding the open source storage software product set as a way of having a more consistent storage software marketing position.
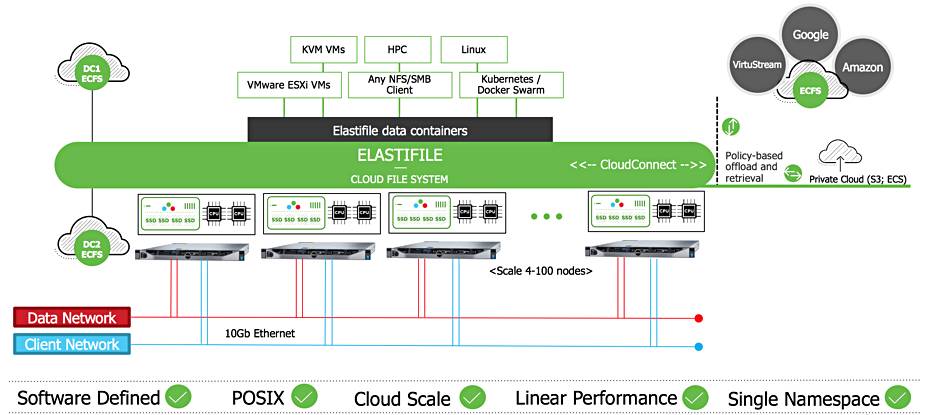
Elastifile’s software runs on-premises and in the Google and AWS clouds.
Elastifile product schematic
Petabyte era
In its acquisition announcement Google said: “The combination of Elastifile and Google Cloud will support bringing traditional workloads into GCP faster and simplify the management and scaling of data and compute intensive workloads. Furthermore, we believe this combination will empower businesses to build industry-specific, high performance applications that need petabyte-scale file storage more quickly and easily.”
Elastifile was founded in Israel in 2014 It has accumulated up to $71m in funding, including $16m in 2017.One report in Israel suggested Google paid $200m, which would be a goodish exit for Elastifile’s VCs.
The Elastifile acquisition is expected to close later this year. Google is making the acquisition through its Google Cloud business, run by CEO Thomas Kurian.
Google bought Looker for its analytics technology business June for $2.6bn and Kurian is moving fast to strengthen the GCP Offering.
Research scientists have demonstrated kilobyte-scale data storage in synthetic metabolitic molecules, smaller than DNA, with data read by mass spectrometry. This could lead to dense offline storage that may be denser than tape reels or flash memory.
Metabolites are intermediate chemical compounds created during metabolism, the chemical reactions inside organisms that sustain life, such as sugars, amino acids, nucleotides, vitamins and anti-oxidants. A metabolome is the set of such metabolites found within a biological sample.
Their presence or absence in an organic chemistry sample can be detected by mass spectrometry.
A recent demonstration of DNA-based data storage by researchers at Washington State and Microsoft inspired scientists at Brown University to explore the potential of the metabolome as a biomolecular information system.
Metabolite molecules that are smaller than DNA and thus denser than DNA storage.
Biomechanical storage medium
A team led by Jacob Rosenstein has published a paper demonstrating the writing and reading of kilobyte-scale images using synthetic metabolomes containing a set of 36 metabolites.
The metabolitic storage process.
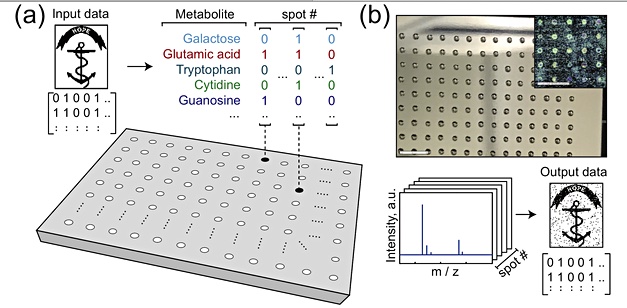
The presence or absence of a specific metabolite in a sample signals a binary one or zero and they can be grouped to provide, for example, 4-bit quartet, such as 1010. Each metabolite would be viewed as a bit position in this quarter and signify 1 or 0 in that position.
The samples were created as nanoliter-sized volumes or spots deposited in their thousands in a grid pattern on 76 x120 mm² steel plates, with spots deposited on a 48 x 32 grid; 1,536 spots in total.
An acoustic liquid handler was used for the deposition. Each spot contains a mixture of metabolites, obtained from a chemical library of purified metabolites. This library represents a synthetic metabolome.
The total number of bits stored in a single spot is given by the number of metabolites in the library. Four were used in the experiments described in the paper but 36 is the upper bound in this particular work.
The metabolites were carried in a solvent mixture, deposited on the plate and the solvent then evaporates. The plates were left to dry and the spot compounds to crystallise overnight.
The researchers used mass spectrometry to analyse the spots and determine the presence or absence of metabolites in each spot, thus building up the values of a 4-bit quartet at each spot. Each spot’s binary values were read in parallel, with the spots on the plate read serially. This took under two hours.
Statistical analyses were used to determine if a specific metabolite was present or absent at a spot and the accuracy reached was about 99.6 per cent.
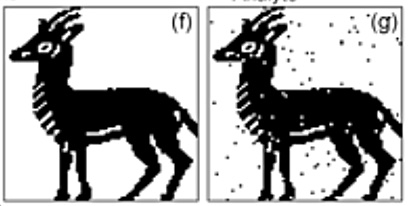
Several experimental results were reported. One involved 1,024 spots containing 6 metabolites (sorbitol, glutamic acid, trypotophan, cytidine, guanosine and 2-deoxyguanosine hydrate) used to encode a 6,142 pixel image of an ibex. In effect, 6-bit words were used for the encoding.
Before and afterimages of ibex.
The ibex before (f) and after (g) images above show that the process is not that accurate, with random values dotting the image. The researchers observed a two per cent cumulative read/write error. Also repeated spot reading caused data loss, with a <1 per cent error added by each successive read.
A further experiment used a 17,424 pixel image of a cat, (i) below, which was encoded into 1,452 spots using 12 metabolites per spot, 12-bit words in effect.
Source cat image (i), with initial read image (ii) and improved image (ii) using stronger statistical analysis.
Once again random errors were apparent in the read image (ii above) with better statistical analyses (multi-peak logistic regression) improving the read accuracy (iii).
Comment
The researchers successfully explored their stated aim to explore the proof of principle of the metabolome as a storage medium. But any practical application could be decades away.
The Brown researchers concluded that “the metabolome is a viable and robust medium for representing digital information.”
The medium is certainly viable but “robust” is a bit of stretch. Accuracy will need to improve.
The Brown researchers think they can improve on the density of DNA storage, currently 2.4PB/gram.
In their experimental demonstration they wrote data at 5bits/sec and had aggregate read speeds of 11 bits/sec.
Let’s be blunt: these read and write speeds are appallingly slow by disk drive and NAND flash standards.
According to the researchers, read speed improvements are possible through increased metabolite library size; meaning more bits per spot. They think hundreds of bits per spot could be achievable.
Write speed and density improvements would come from reducing the spot size. They wrote: “Scaling the mixture spots down to diffraction-limited laser spot scales could improve data storage density by six orders of magnitude. Theoretically, this could facilitate extension from kilobyte- to gigabyte-data sets per plate.”
Blocks & Files notes that M.2 2280 flash drives are 22mm x 80mm in size and already store up to 1TB (Optane H10 using QLC (4bits/cell) flash) with read and write rates of 2.4/1.8GB/sec.
Metabolomitic-based data storage would require a lot of development to match this.
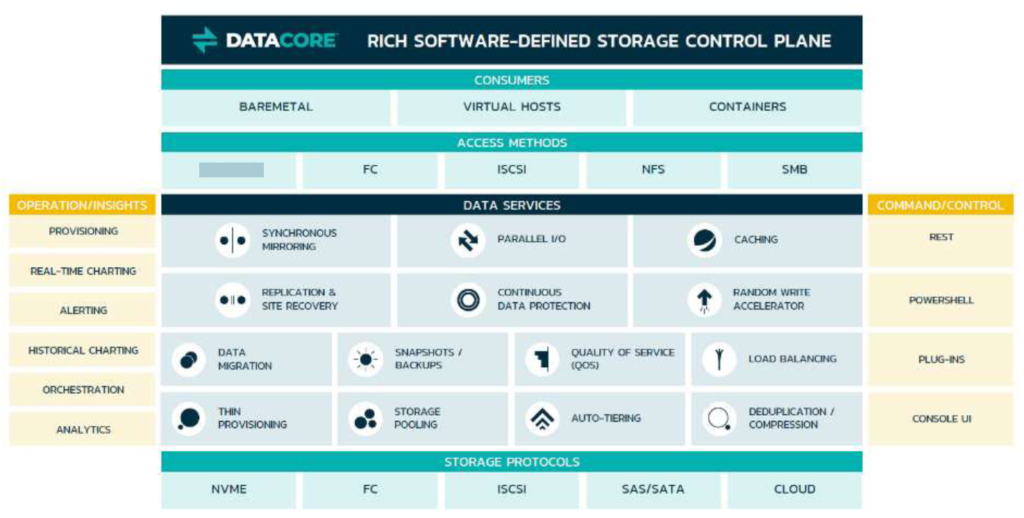
DataCore, the SANsymphony supplier, has gone supersonic, launching a hyperconverged appliance, cloud-based predictive insights and a subscription licensing scheme.
The company, founded in 1998, has developed its SAN Symphony virtual SAN product over many years and the software comes in two flavours, either as a shared external storage facility or configured as a hyper-converged infrastructure (HCI) product, called a Hyperconverged Virtual SAN (HvSAN) for vSphere or Windows Hyper-V.
More than 10,000 customers use SANsymphony products and recent developments include a parallel IO facility in 2016 – which led to industry standard benchmark successes.
The company is now releasing DataCore SDS – technically speaking SANsymphony 10 PSP 9. This is available in HvSAN packages for both VMware vCenter and Microsoft Hyper-V.
DataCore SDS
CMO Gerado Dada told us by mail: “SANsymphony and Hyperconverged Virtual SAN (HvSAN) are really the same codebase. They are on the same version and have the same capabilities. The only difference between them is that the HvSAN is delivered in an installation package that is optimised for deployment in a HCI configuration.“
Dada said: “Over time, HvSAN and SANsymphony will go away. Part of the difficulty in renaming a product is that when a vendor does that that, they lose all the certifications, in or case we would have to re-start the certification process for SAP, VMware, Veeam, etc. – even if the product is exactly the same, just a different name.”
PSP 9 update
SDS (SANsymphony 10) PSP 9 adds:
UI modernisation and a new web-based console that is more intuitive and task-oriented
REST API library
AES-256 bit encryption at rest
Improved VVOL integration with a few enhancements and re-certification with newer versions of ESX
DataCore Installation Manager one-click installers for Hyper-V and vCenter
Resiliency improvement for ESX Metro-cluster configurations
Monitoring and metering for our CSP customers supporting the PayG licensing model
Various other improvements and bug fixes
HCI-Flex appliances
The latest iteration of the hyperconverged line is the HCI-Flex appliance and there are 1U and 2U configurations with vSphere or Hyper-V pre-installed and a deployment wizard to get the software installed and operational in a few minutes.
It can use external shared storage and scale compute and storage capacities independently, and a high-availability option needs a minimum of two appliances. So too can Dell EMC’s VxRail, using an arbiter or witness host in a virtual appliance, and HPE’s SimpliVity HCI product.
HCI-Flex is available as software to run on partner’s X86 server hardware, such as Dell, Lenovo, Supermicro and others, or as a hardware appliance.
DataCore HCI-Flex summary
We suggested t DataCore’s Dada that company was giving out a mixed software-defined-storage -but-we-sell-hardware-too message.
He replied: “The reason for the appliance is simplicity, mainly for our some of our resellers who don’t want to spend time configuring an appliance and installing software, they prefer a turnkey solution that requires less effort on their part. These resellers are also attracted to a system that has a single point of contact and accountability for support for both hardware and software.”
DataCore isn’t supplying the hardware. Dada said. “DataCore is and will continue to be a software company. We chose to partner with Unicom, a global company with very deep expertise in building hardware appliances. Unicom is a Dell partner, they procure the hardware, configure it, install our software, test the appliance, and Unicom sells and ships the finished appliance to our distributors. We are not really building a competence in hardware, and we don’t ever see hardware revenue.”
Dada declared: “Announcing our own appliance is helpful from a market awareness perspective, it calls attention to DataCore’s value for customers who are interested in HCI yet they may not be aware SDS provides a very attractive option. Some of the larger analyst firms won’t consider DataCore a real player in the space without an appliance.”
DataCore Insight Services
DataCore has introduced DIS (DataCore Insight Services), a cloud-based analytics platform service to improve the operational efficiency of its installed systems.
This is based on telemetry data from customers’ systems, existing knowledge, machine learning (ML)and AI. According to Datacore, the ML/AI combo detects current or foreseeable anomalies in installed systems. A built-in recommendation engine directs designated individuals to carry out corrective actions.
Prescribed steps are highly-automated and can be run remotely or on-premises, Datacore said. The aim is to achieve reduced downtime, faster response, higher efficiencies and cost savings.
Users can model workload or virtual machine additions in advance for smoother deployments.
DIS is available with subscription licensing only.
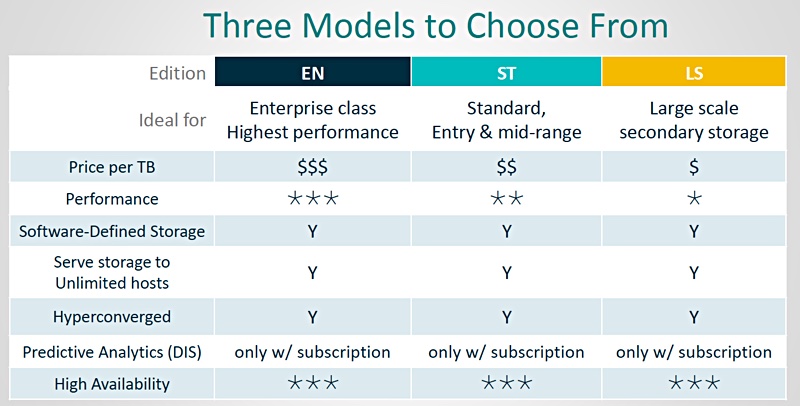
Subscriptions
DataCore customers can choose either perpetual or subscription licenses. The subscription licenses are based on terabytes of capacity over one or many nodes. Terms run for one, three or five years with upfront payments. Subscription and perpetual licenses cannot be mixed in a DataCore server group.
There are enterprise (EN), standard (ST) and large scale (LS) schemes available as the diagram above shows. A 1-year 50 – 99TB LS license will cost $245/TB while a 5-year 1 – 9TB EN license will cost $1,924/TB. Prices include DataCore Insight Services.
A perpetual to subscription license trade-in program is likely to be announced later this year.
Update May 5, 2020. Dell EMC today launched the PowerStore (formerly called Midrange.NEXT) data storage array line. Check out our PowerStore explainer. Our editor thinks this is “most important development in data storage hardware for many years”.
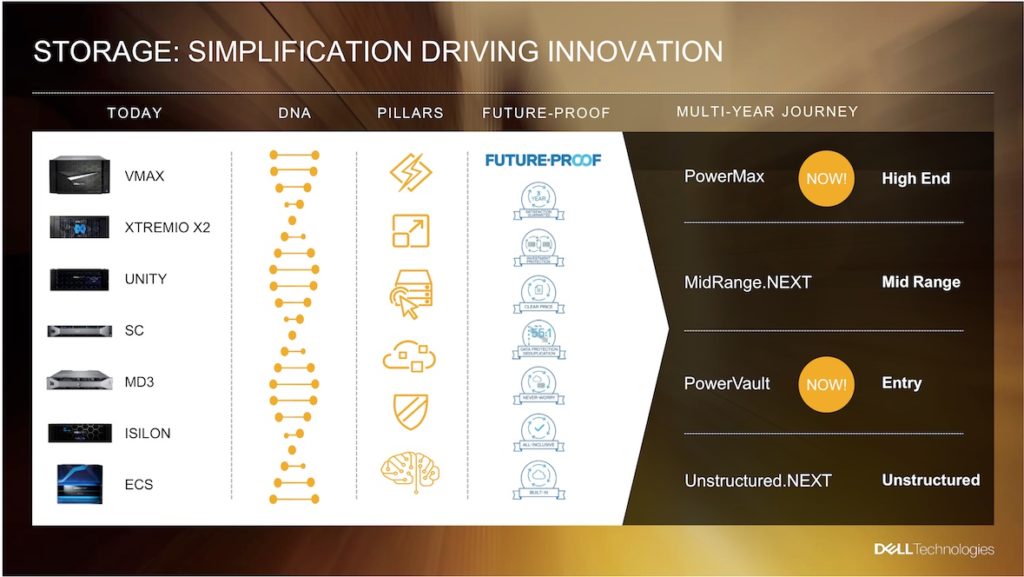
MidRange.NEXT is Dell EMC’s upcoming replacement for the SC, Unity and XIO mid-range arrays.
The three array lines came into being when Dell and EMC were independent. Dell acquired Compellent and its SC array products in 2010. EMC developed Unity from its existing VNX line, based on Clarion technology acquired from Data General in 1999.
EMC acquired XtremIO in 2012 as a way of producing an all-flash array. Subsequently Unity and the SC both gained an all-flash array model. When Dell bought EMC it determined that operating three mid-range array products was expensive and wasteful. It decided to meld the three ranges into one: MidRange.NEXT.
Dell EMC has made its intentions to simplify and update the mid-range portfolio abundantly clear, for instance at Dell World, Las Vegas in April 2019.
But the company has been far less forthcoming on product details. Based on our conversations with several sources this is what we know so far.
This shares the “Power” brand identity with PowerEdge servers, the PowerMAX high-end array, PowerVault low-end arrays and PowerSwitch networking gear.
MidRange.NEXT launch date
Dell EMC is currently targeting the V1.0 release date for March- May 2020, according to our sources. There is a Dell Technologies World event in Las Vegas, May 4-11. We think that Midrange.next aka PowerStore will be announced then.
In early February 2020, Dell EMC emailed us this statement: “Customers have taken part in Midrange.next’s early access program since Q4FY20 and feedback to date has been very positive.”
Dell EMC originally pencilled September 2019 for V1 launch and provisionally scheduled V2.0 and v3.0 for 2020 and 2021, with the federating ability getting stronger, release by release.
What MidRange.NEXT is
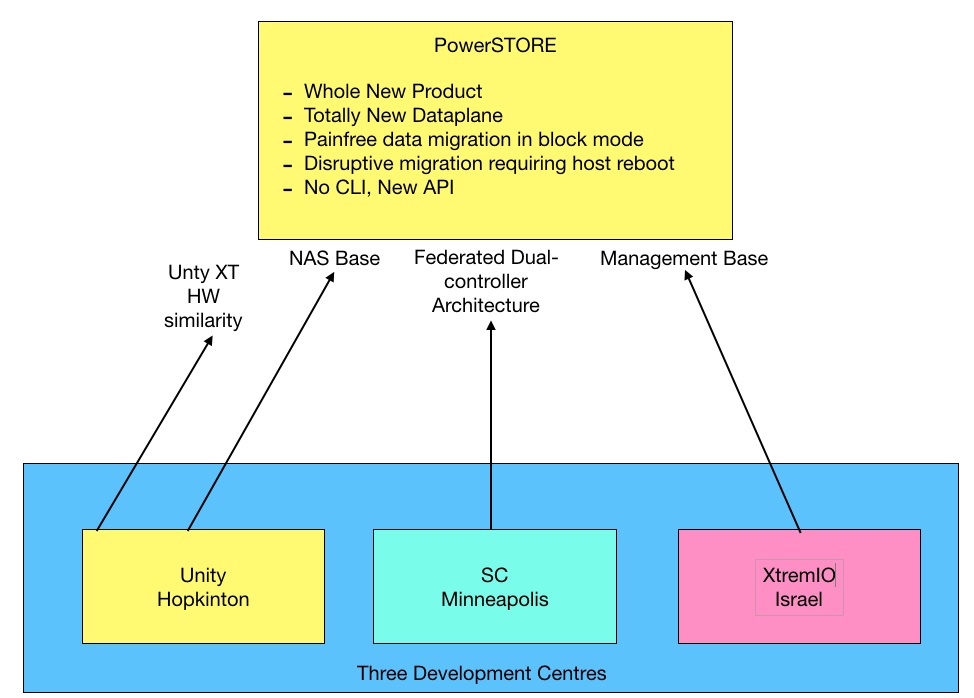
In essence Midrange.NEXT is an almost ground-up new software design with smallish pieces from Unity (NAS), SC and XIO (management). The dataplane is all new and there is a new API and no CLI.
Blocks & Files diagram
The overall architecture involves federated dual-controller nodes and is similar to the SC. The hardware is a development based onUnity XT, which was announced in April 2019.
Our sources say MidRange.NEXT features:
25 NVMe slots in the base 2U Drive Array Enclosure (DAE) with 4 used by NVRAM modules,
2U Expansion DAE is SAS-only with 25 slots, with 3 DAEs supported,
Entire array can be configured with flash or Storage-Class Memory (SCM) but media cannot be mixed,
Up to 21 SCM drives with 750GB capacity and NVMe only,
Or up to 96 flash drives, up to 16TB in capacity, and a mix of NVMe (21) and SAS (75).
No tiering,
No NVMe-oF (possibly in v3),
32Bit/s FC or 25Gbit/s iSCSI.
At time of publication Dell has not corroborated any of these details.
From September 2019 onwards Unity will have some new features added but SC and XtremIO are effectively in maintenance mode.
Midrange.NEXT development is taking place in three locations: Hopkinton, Mass, (Unity base), Minneapolis (SC base) and Israel (XtremIO base). Some engineers in each location are working on the existing Unity, SC and XtremIO products but most are working on MidRange.NEXT.
According to our sources, engineer retention is an issue and many senior people have left.
What we don’t know yet
We assume that MidRange.NEXT will be a unified file and block access array with support for public cloud back-end storage, but don’t know this for certain.
A Dell EMC spokesperson said about all this: “We are going to decline comment on anything specific related to our future product roadmap.”
Data migration
The existing Dell EMC midrange arrays will co-exist with the new mid-range system, possibly for many years. There will be no speedy end-of-life moves.
Data migration from SC, Unity and XIO will be simple in block mode. It will be more complicated in other modes. When either SC, Unity or XIO are migrated to Midrange.NEXT a host reboot or two will be needed.
Chris Evans, author of the Architecting IT blog, suggests: “Forcing customers to rewrite scripts and change processes is probably necessary. Finding a way to do this without incurring risk and cost will be the challenge. For data itself, customers will need some kind of migration tools and even interfaces between existing platforms and MidRange.NEXT.
“Where systems are already virtualised, the migration process is relatively simple – create new datastores and vMotion. File shares are harder and physical servers require some more thought. These migrations can get really complex when there are many dependencies like snapshots and replication – or even public cloud.”
The mid-range array market
A mid-range storage array is typically a dual-controller design with expansion shelves and a capacity range of 20TB to 2PB. Such arrays can be clustered or federated tother to provide large capacities and a higher number of IOPS.
The array operating system (controller software) provides management and protection of the storage drives, and typically includes functionality such as thin-provisioning, data reduction, replication and tiering to the public cloud.
A high-end array, such as an IBM DS8000 or Dell EMC PowerMAX, generally has a multiple controller design and high capacities, heading up to multiple petabytes and beyond. They may support mainframe connectivity.
Low-end arrays, such as Dell EMC’s PowerVault, will have generally lower capacities, from single-digit terabytes to, say, 100TB, and less software functionality.
Mid-range array costs can span from $15,000 to $1m-plus.
Why a new Dell EMC mid-range array?
The mid-range combined block and file array market is hugely important for Dell EMC; its Unity array is probably the most popular storage array in history,
In November 2017 Dell EMC told a Tech Field Day event that it had accumulated more than $2.3bn revenues from 20,000-plus Unity customers and more than 35,000 arrays installed.
We have been unable to ascertain SC and XTremIO revenues but can safely assume that their contributions make storage arrays even more significant to Dell EMC.
However, as previously mentioned, Dell sees three competing products as wasteful of resources, from engineering through marketing to sales channels and support.
Mid-range market size
IDC sized the enterprise storage market at $13bn in Q1 2018, growing 34.4 per cent on the previous year. The all-flash array category was $2.1bn, growing 55 per cent year-on-year, and the hybrid flash/disk category was $2.5bn, growing 24 per cent y-o-y.
Combining the two gives a mid-range array market size of $4.6bn in 2018’s Q1 or $18.4bn – roughly – for the whole year.
The competition
Because of Dell EMC’s number one position in the storage array market Midrange.NEXT will be a hugely important product, and the response of the SC, Unity and XIO customer bases is crucial to its success.
IBM, HPE, NetApp, Pure Storage and others will circle like hungry predators, alert for any opening that could let their sales channels into the Dell EMC customer base.
Competing products for PowerSTORE are:
Mainstream vendors:
Fujitsu ETERNUS Arrays
Hitachi Vantara VSP array
Huawei OceanStore
HPE Primera, 3PAR and Nimble arrays,
IBM Storwize and FlashSystem
NetApp all-flash AFF and hybrid flash/disk FAS arrays running ONTAP software; also SolidFire all-flash arrays
Pure Storage FlashArray
Startups, private equity firms and expansion-minded suppliers:
Apeiron NVMe-oF array
DDN Tintri arrays
E8 NVMe-oF array
Excelero NVMe-oF array
Infinidat InfiniBox arrays
Kaminario composable NVMe-oF array
Pavilion Data Systems NVMe-oF array
Reduxio array
StorCentric Nexsan and Vexata NVMe-oF array
StorOne array
VAST Data array
Violin Systems all-flash array
Western Digital’s IntelliFlash array, based on acquired Tegile technology
Midrange.NEXT will be the second all-new or substantially new storage array design announced this year. HPE’s Primera, a re-architecting of the company’s 3Par line, was first out of the block in June 2019.
It’s a moot point whether Primera and MidRange.NEXT will push vendors with established mid-range array product lines, such as Fujitsu and IBM, to re-architect their products.
IntelliFlash all-flash arrays have been certified for use by SAP’s HANA in-memory database system.
IntelliFlash was the main product portfolio Western Digital Corp. acquired when it bought Tegile in August 2017. The range consists of hybrid flash+ disk T4000 systems and all-flash IntelliFlash arrays; the N5000 NVMe drive series and the HD2000 SAS products.
IntelliFlash NVMe array
The HANA (High-Performance Analytic Appliance) certification applies to both the NVMe and SAS all-flash arrays.
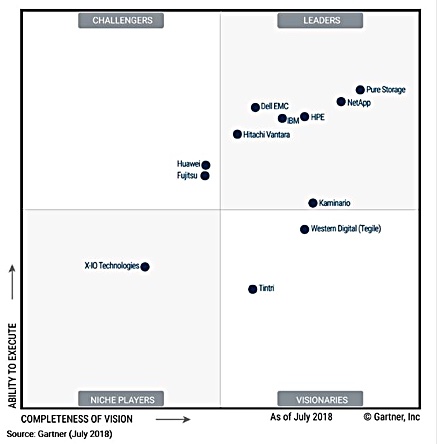
WD said it has thousands of deployed IntelliFlash arrays worldwide. IntelliFlash arrays have been located in the Visionaries box of Gartner’s all-flash array (SSA) magic quadrant in July 2017 and also July 2018.
We might expect an updated Gartner SSA MQ some time this month, and it will be interesting to see if the IntelliFlash arrays move into a different quadrant.
Our round up starts with an on-premises tape backup replacement, meanders through storage in the cloud, and returns to tape with a new LTFS indexing scheme that saves space and time.
We finish with DataCore’s exec roster revamp and InfiniteIO and Nasuni hires
Cohesity backsup a fire service
On-premises tape backup systems are still being replaced with disk-based ones. Cohesity customer West Midlands Fire Service has replaced tape backup and an 11-mile weekly tape trip to an offsite DR centre with Cohesity’s backup.
A server backup now takes five minutes, saving the service over 360 hours a year – the equivalent of almost 2.5 months of time for a full-time engineer. Critical data is backed up hourly and global variable length deduplication provided on-premises and cloud storage savings.
HYCU goes in for cloud lifting and shifting
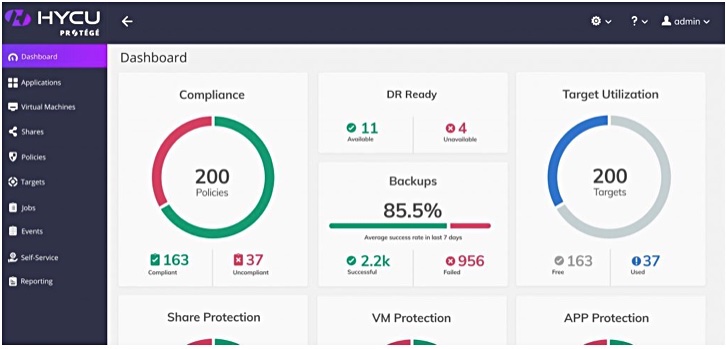
HYCU offers backup and recovery of Virtual Machines in Nutanix environments. Protégé is a new HYCU data protection offering for hybrid and public clouds.
It provides a mechanism to “lift and shift” customer applications from one cloud to another, making sure the data is protected throughout. A single-click feature enables customers to recover specific applications onto a different cloud for test and dev, and a disaster recovery option across clouds is available
HYCU wrote in a blog that “what customers want us to do here is to automate the entire process and make it a one-click operation to migrate an entire application from on-prem or Cloud to another Cloud.” HYCU Protégé will simplify the process to become a one-click migration.
Protégé dashboard.
Protégé should be generally available in the third 2019 quarter.
SaaS will be the largest revenue category, followed by PaaS and then IaaS.
IaaS spending, comprised of servers and storage devices, will be the fastest growing category of cloud spending with a five-year CAGR of 32 per cent, compared to the PaaS CAGR of 29.9 per cent. IDC has not publicly revealed the SaaS CAGR.
IaaS spending will represent more than 40 per cent of public cloud services spending by the professional services industry in 2023, compared to less than 30 per cent for most other industries. Professional services will also see the fastest growth in public cloud spending with a five-year CAGR of 25.6 per cent
LTFS gets indexing taped
The Linear Tape File System, which presents a file:folder interface to LTO tapes, has a new, more efficient file indexing scheme. It comes from the SNIA Linear Tape File System (LTFS) Technical Work Group (TWG.)
LTFS stores files and their metadata on the same tape and makes the data accessible through the file system interface. The LTFS standard defines the data recording structure on the tape and the metadata format in XML. It creates a full index when new files are added.
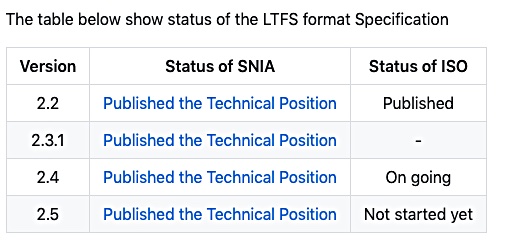
V2.5 of the LTFS format specification uses a new and incremental indexing method with a journal-like capability where only changes to the index need to be recorded frequently. A complete index is required to be written at unmount time.
Incremental indexing reduces the tape space needed for the index data so more data can be written to the tape, and also reduces the index writing time. Both are particularly helpful when small files are written to the tape. The LTFS people have IOT sensors generating small files of data which can now be written more efficiently to tape.
A reference implementation of LTFS format version 2.4 is available as open source at GitHub project here. Presumably v2.5’s ISO base media file format will appear on Github shortly; its current status is: ”not started yet.”
GitHub LTFS format version specifications status.
People
DataCore, which supplies the SW-designed SANsymphony products, has refreshed its executive team following co-founder and CEO George Teixeira’s elevation to executive chairman. The roster includes;
Dave Zabrowski – CEO
Martin Clancy – CFO
Gerardo Dada – CMO
Roni Putra – co-founder and CTO
Rizwan Pirani – Chief Product Officer
Robert Bassett – VP Engineering
Christian Marczinke – VP Global Alliances
Amanda Bedborough – SVP EMEA Field Operations
Startup InfiniteIO, which supplies NAS file access acceleration technology, has appointed Michael Croll as its first VP for worldwide sales. He joins from IBM Cloud Object Storage (the acquired Cleversafe), where he was VP of sales and operations for the North America public market. He has also worked at Data Domain and EMC.
Nasuni has hired David Grant as its CMO. He joins Nasuni from Veeam Software, where he was the SVP of global marketing. Before that he was at VMware.
The world of hyperconverged (HCI) and converged infrastructure has become utterly confusing with marketing droids causing hyperactive uncontrolled growth of marketing terminology.
For instance: HCI, Disaggregated HCI, Distributed HCI, Composable Infrastructure, Composable / Disaggregated Infrastructure, Converged Infrastructure, Open Convergence, Hybrid HCI, HCI 2.0, Hybrid Converged Infrastructure and Hybrid Cloud Infrastructure.
Let’s see if we can make sense of it all. But first, a brief discussion of life before converged infrastructure.
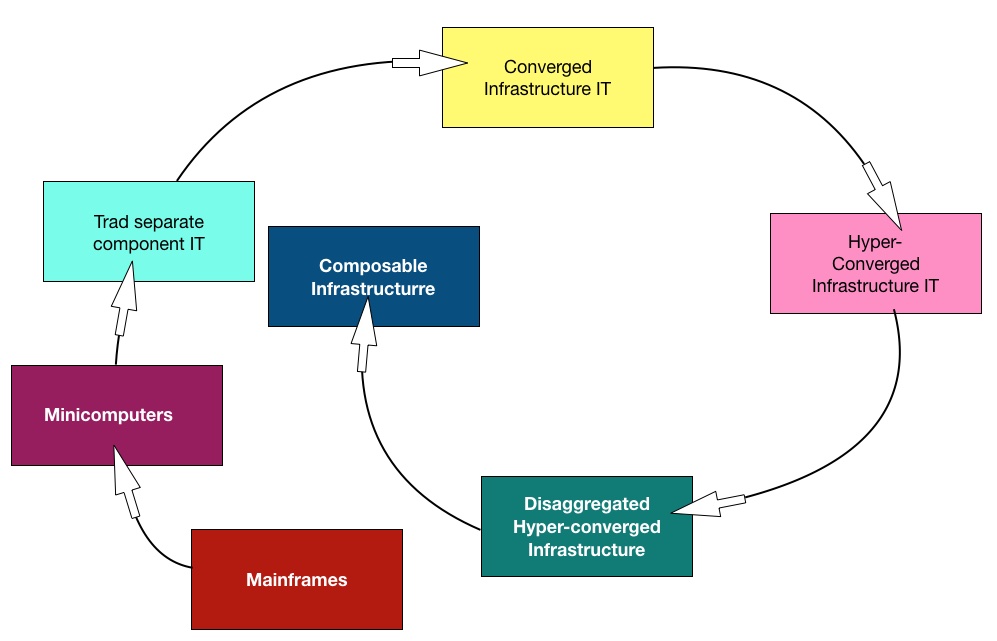
We can see a progression, starting with mainframes and passing through minicomputers, (decomposed) component-buying IT, converged infrastructure (CI), hyperconverged infrastructure (HCI), disaggregated HCI (dHCI) to composable systems.
The mainframe-to-composabke systems cycle.
It was the mainframe wot started it
In the 1950s IBM created mainframe systems, made from tightly integrated processors and memory (which became servers), network connecting devices, storage units and system software. These were complex and expensive.
Savvy engineers like Ken Olsen at Digital Equipment and other companies got to work in the 1960s and created minicomputers. These smaller and much cheaper versions of mainframes used newer semiconductor technology, Ethernet, tape and then disk storage, and system software.
IBM launched its first personal computer on August 12, 1981, following pioneering work in the 1970s by Altair, Apple, Commodore and Tandy. PCs used newer semiconductor technology, commodity disk drives and network connectivity and third-party system software such as CPM and DOS.
In due course, the technology evolved into workstations and servers. These servers ran Windows or Unix and displaced minicomputers. The server market grew rampantly, pushing mainframes into a niche.
Three-tier architecture came along from the mid-90s onwards, with presentation, application and data tiers of computing. The enterprise purchase of systems became complex, involving racks filled with separately bought servers, system software, storage arrays, and networking gear. It required the customer or, more likely, a services business to install and integrate this intricately connected set or blocks of components.
Customers buying direct from suppliers certainly did not enjoy having support contracts with each supplier and no one throat to choke when things went wrong.
Converged infrastructure
Cisco entered the server market in 2009and teamed up with EMC to develop virtual blocks, racks of pre-configured and integrated server, system software, networking and external storage array (SAN) components. It was called a converged infrastructure approach.
EMC manufactured virtual blocks – branded vBlocks – through its VCE division. These were simpler to buy than traditional IT systems and simpler to install, operate and manage, and support, with VCE acting as the support agency.
NetApp had no wish to start building this stuff but joined in the act with Cisco in late 2010. Together they developed the FlexPod CI reference architecture,to enable their respective channel partners to build and sell CI systems.
CI systems multiplied with application-specific configurations. Other suppliers soon produced reference architectures, for example, IBM with VersaStack and Pure Storage with FlashStack, both in 2014.
All these CI systems are rack-level designs, coming in industry standard 42-inch racks.
Hyperconverged infrastructure
Around 2010 a new set of suppliers, such as Nutanix, SimpliVity and Springpath, saw that equivalent systems could be built from smaller IT building blocks, by combining server, virtualization system software, directly-attached storage into a single 2U or 4U rack enclosure or box, with no external shared storage array.
The system’s power could be scaled out by adding more of these pre-configured, easy-to-install boxes or nodes, and pooling each server’s directly-attached storage into a virtual SAN.
To distinguish them from CI systems these were called hyperconverged infrastructure (HCI) systems.
EMC got into the act in 2016 with VxRAIL, using VMware vSAN software. It became the dominant supplier after its acquisition by Dell that year, followed by Nutanix, which remains in strong second place. The chasing pack – or perhaps also-rans – include Cisco-Springpath, Maxta, Pivot3 and Scale Computing.
Hybrid or disaggregated HCI
A feature of HCI is that the systems scale by adding pre-configured boxes combining compute, storage and networking connectivity. You add another box if there is too little compute or too little storage. This means that compute-intensive workloads could get too much storage and storage-intensive workloads could get too much compute. This wastes resources and strands unused storage or compute resource in the HCI system. It can’t be used anywhere else.
In response to the stranded resource problem, ways of separately scaling compute and storage within an HCI environment were developed around 2015-16. In effect the HCI virtual SAN was re-invented as a physical SAN, by using separate compute-optimised and storage-optimised nodes or by making the HCI nodes share access to a separate storage resource.
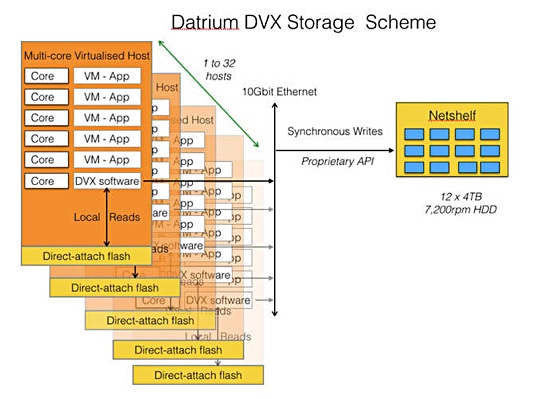
Datrium was a prime mover of this solution to the HCI stranded resource problem. Founded in 2012, the company brought product to market in 2016. It argued hyperconverged was over-converged, and said its system featured an open convergence design.
Datrium converged system scheme
Near HCI
Fast forward to June 2017 and NetApp introduced its HCI product, called NetApp HCI. Servers in the HCI nodes accessed a SolidFire all-flash array, and the system could scale compute and storage independently.
And now, in 2019, HPE has introduced the Nimble dHCI, combining ProLiant servers with Nimble storage arrays. The ‘d’ in dHCI stands for disaggregated.
Logically these second-generation HCI systems, called disaggregated or distributed HCI, are less converged than HCI systems but more converged than CI systems. They are more complicated to order, buy and configure than gen 1 HCI systems but are claimed by their suppliers to offer a gen 1 HCI-like experience. A more accurate term for these products might be “near-HCI”.
Enrico Signoretti, GigaOm consultant, said HCI is about how a system looks from the outside to users. In a July 2, 2019 tweet he wrote: “HCI is about infrastructure simplification, a box that gives you the entire stack. We can discuss about what’s in the box, but first of all you want it to look integrated from the outside.”
He developed this thought in a follow-up tweet: “What is HCI after all? SW + simplified installation/deployment process + integrated management. Many CI and HCI solutions lack the proper integration to manage the infra as a whole, this is the real issue IMO. Do we really care how HW is physically configured? And why?”
That may be so but it is best to avoid confusing and misleading IT product category terms.
Disaggregated HCI
Saying a disaggregated hyperconverged system is a hyperconverged system is an oxymoron.
Trouble is, there is no definitive definition of HCI. Confusion reigns. For instance, NetApp, in a recent blog, stated: “One of the challenges of putting out an innovative product like NetApp HCI is that it differs from existing market definitions.”
The NetApp blogger, HCI product specialist Dean Steadman, said a new category has landed. “To that end, IDC has announced a new “disaggregated” subcategory of the HCI market in its most recent Worldwide Quarterly Converged Systems Tracker. IDC is expanding the definition of HCI to include a disaggregated category with products that allow customers to scale in a non-linear fashion, unlike traditional systems that require nodes running a hypervisor.”
Steadman wrote “NetApp HCI is a hybrid cloud infrastructure”, which means containers running in it can be moved to the public cloud and data stored in it can be moved to and from the public cloud.
As a term ‘dHCI’ is useful – to some extent. It separates less hyperconverged systems – Datrium, DataCore, HPE dHCI and NetApp Elements HCI – from the original classic HCI systems – Dell EMC VxRail, Cisco HyperFlex, HPE SimpliVity, Maxta, Nutanix, Pivot3 and Scale Computing.
Where do we go from here?
CI, HCI and dHCI systems are static. Applications can use their physical resources but the systems cannot be dynamically partitioned and reconfigured to fit specific application workloads better.
This is the realm of composable systems, pioneered by HPE with Synergy in 2015, where a set of processors, memory, hardware accelerators, system software, storage-class memory, storage and networking is pooled into resource groups.
When an application workload is scheduled to run in a data centre the resources it needs are selected and composed into a dynamic system that suits the needs of that workload. There is no wasted storage, compute or network bandwidth.
The remaining resources in the pools can be used to dynamically compose virtual systems for other workloads. When workloads finish, the physical resources are returned to their pools for re-use in freshly-composed virtual systems.
The idea is that if you have a sufficiently large number of variable resource-need workloads, composable systems optimise your resources best with the least amount of wasted capacity in any one resource type.
Suppliers such as HPE, Dell EMC (MX700), DriveScale, Kaminario, Liqid and Western Digital are all developing composable systems.
Composability injections
Blocks & Files thinks CI, HCI, dHCI and composable systems will co-exist for some years. In due course composable systems will make inroads in to the CI category, with CI systems becoming composable. HCI and dHCI systems could also get a composability implant. It’s just another way of virtualizing systems, after all.
Imagine a supplier punting a software-defined, composable HCI product. This seems to be a logical proposition and HPE has probably started along this road by making SimpliVity HCI a composable element in its Synergy composable scheme.
Get ready for a new acronym blizzard. CCI – Composable CI, HCCI – Hyper-Composable Converged Systems or Hybrid Converged Composable infrastructure, Even Hybrid Ultra Marketed Block Uber Generated Systems – HUMBUGS.
MapR, the struggling Hadoop data analytics firm, has missed its July 3 deadline to sell out or shut up shop. Today is Independence Day, July 4, so an update is unlikely until tomorrow at the earliest.
On May 31, MapR revealed in a WARN notice in California that it was two weeks away from closure. In the WARN letter MapR CEO John Schroeder wrote the board was considering two letters of intent to buy the company. But extremely poor – and unexpected – results in the first three months of the year had torpedoed negotiations to secure debt financing.
The June 14 deadline was extended to July 3 according to a Datanami report on June 18, which revealed MapR had signed a letter of intent to sell the company. The unknown potential acquirer was performing due diligence to see if it could consummate the acquisition.
If this process didn’t complete successfully MapR anticipated it would start layoffs and close down from July 3 onwards. That date has now passed with no announcement of an acquisition or a third deadline. The company has about 120 employees based in California.
MapR’s total funding is $280m from six investing firms, including Google’s capitalG, Qualcomm Ventures and LIghtspeed.
Cisco and NetApp are adding MAX Data to their FlexPod reference design to make applications run faster.
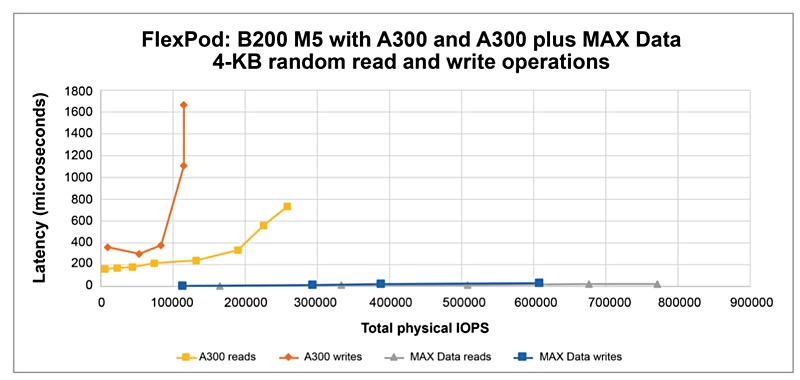
In a white paper published last week Cisco showed MAX Data on FlexPod is capable of delivering five times more I/O operations with 25 times less latency than the same system without MAX Data installed.
FlexPod is a converged infrastructure (CI) reference platform for compute, storage and networking. It incorporates Cisco validated designs for Cisco UCS servers and Nexus and MDS switches with NetApp’s validated architecture for all-flash and hybrid flash/disk storage arrays running ONTAP software.
MAX Data is NetApp’s Memory Accelerated Data software which uses Optane DIMM caching in servers backed by an all-flash NetApp array. MAX Data presents a POSIX file system interface to applications, which don’t need to change. The software tiers data from the ONTAP all-flash array (treated as an underlying block device) into the Optane persistent memory.
The hottest, most frequently accessed data is kept in the Optane memory space, and cooler, less frequently used, data is tiered to the ONTAP storage array. Most data requests are serviced from Optane with misses serviced from the array.
The array is connected to the Optane DIMMs by an NVMe-oF link. Applications in the server get their data IO requests serviced from the Optane cache/tier instead of the remote NetApp array.
This greatly reduces data access latency times, down to about 10 microseconds from a millisecond or so. Databases can support more transactions with fewer computing resources and complete user queries more quickly.
Design of the times
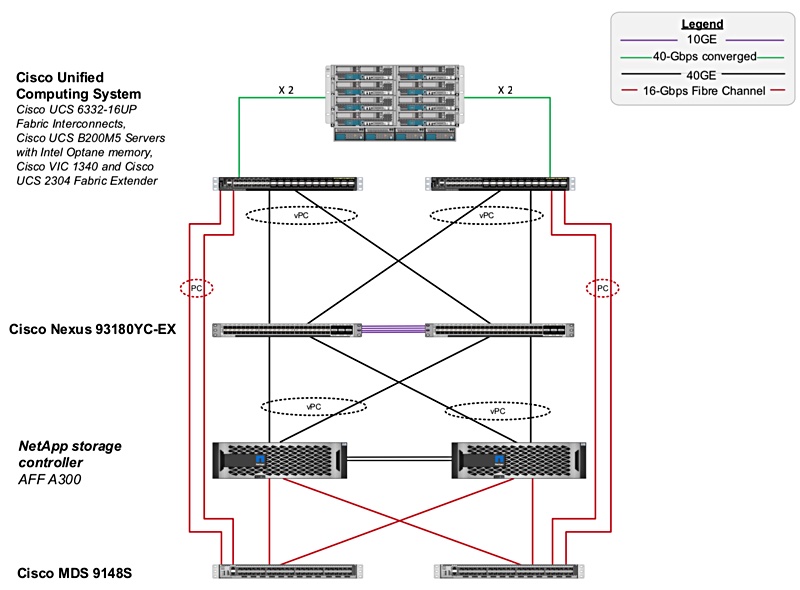
The FlexPod MAX Data design uses third-generation Cisco UCS 6332-16UP Fabric Interconnects and the UCS virtual interface card with 40Gbit/s Ethernet links to a NetApp AFF A300 storage cluster using vPCs (Virtual Port Channels.)
It supports 16-Gbit/s Fibre Channel, for Fibre Channel Protocol (FCP) between the storage cluster and UCS servers.
NetApp Cisco topology diagram of FlexPod MAX Data system. (vPC is a Virtual Port Channel.)
Optane DIMMS with 128GB, 256GB and 512GB can be used.
The Optane DIMMs must be paired with DRAM DIMMs in each memory channel and can be used in various access modes:
Memory mode, which provides additional volatile memory capacity.
App Direct mode, which provides persistence and can be accessed through traditional memory load and store operations.
Mixed mode where a percentage of the DIMM is used in memory mode and the rest in App Direct mode.
MAX Data uses App Direct mode. For application vendors themselves to use this Optane mode they must rewrite their applications. With MAX Data, applications can use Optane DIMMs without any re-writing of code.