Sponsored Hyperconverged infrastructure (HCI) has been around for at least a decade, but adoption continues to grow apace, as shown by figures from research firm IDC which indicate that revenue from hyperconverged systems grew 17.2 per cent year on year for the fourth quarter of 2019, compared to 5.1 per cent for the overall server market.
Although it has become common for HCI to run general purpose workloads, some IT departments are still wary of using this architecture for the mission-critical enterprise applications on which their organisation depends for day to day business. Now, with technologies available as part of the Second Generation Intel® Xeon® Scalable processor platform, HCI can deliver the performance and reliability to operate these workloads, while providing the benefits of flexibility and scalability.
HCI is based on the concept of an appliance-like node that can serve as an infrastructure building block, enabling the operator to scale by adding more nodes or adding more disks. Each node integrates compute, storage and networking into a single enclosure, as opposed to separate components that have to be sourced and configured separately.
The real value of HCI is in the software layer, which virtualizes everything and creates a pool of software-defined storage using the collective storage resources across a cluster of nodes. This software layer facilitates centralised management and provides a high degree of automation to make HCI simpler for IT professionals to deploy and manage.
But that software-defined storage layer may be one reason why some organisations have been wary of committing to HCI for those mission-critical roles.
Doing it the traditional way: SANs
Enterprise applications, whether customer relationship management (CRM), enterprise resource planning (ERP) or applications designed for online transaction processing (OLTP), rely on a database backend for information storage and retrieval. This requirement will typically be met by a database system such as Oracle or SQL Server.
Traditionally, the database would run on a dedicated server, or a cluster of servers in order to cope with a high volume of transactions and to provide failover should one server develop a fault. Storage would be provided by a dedicated storage array, connected to the server cluster via SAN links. This architecture was designed so that the storage can deliver enough performance in terms of I/O operations per second (IOPS) to meet the requirements of the database and the applications using it.
But it means the database, and possibly the application, is effectively locked into its own infrastructure silo, managed and updated separately from the rest of the IT estate. If an organisation has multiple application silos such as this, it can easily complicate data centre management and hinder moves towards more flexible and adaptable IT infrastructure.
It also pre-dates the introduction of solid state drives (SSDs), which have a much higher I/O capacity – and much lower latency – than spinning disks. For example, a single Intel® 8TB SSD DC P4510 Series device is capable of delivering 641,800 read IOPS.
Partly, this is because of the inherent advantages of solid-state media, but also because newer SSDs use NVMe as the protocol between the drive and host. The NVMe communications protocol was created specifically for solid state media and uses the high-speed PCIe bus to deliver greater bandwidth than a legacy interface such as SAS while supporting multiple I/O queues. The NVMe protocol also ensures performance is not compromised by delays in the software stack.
Software-defined
With HCI, the database can run on a virtual machine, and the software-defined storage layer means that storage is distributed across an entire cluster of nodes. Every node in the cluster serves I/O and this means that as the number of hosts grows, so does the total I/O capacity of the infrastructure.
This distributed model also means that if a node goes down, performance and availability do not suffer too much. Most HCI platforms also now feature many of the capabilities of enterprise storage arrays as standard, such as snapshots and data deduplication, while built-in data protection features make disaster recovery efforts much easier.
With advances in technology, such as the Second Generation Intel® Xeon® Scalable processors, tends to feature more CPU cores per chip than earlier generations. This presents organisations with the opportunity to reduce the number of nodes required for a cluster to run a particular workload, and thus make cost savings.
But as the total I/O capacity depends on the number of hosts, such consolidation threatens to reduce the overall IOPS of the cluster. Fortunately, SSDs boast enough IOPS to counteract this, especially Intel® Optane™ DC SSDs, which are architected to deliver enough IOPS for the most demanding workloads. In tests conducted by Evaluator Group, a storage analyst firm, a four-node HCI cluster with Optane™ DC SSDs outperformed a six-node cluster using NAND flash SSDs under the IOmark-VM workload benchmark, with both configurations having a target of 1,000 IOmark-VMs.
Optimise the cache layer
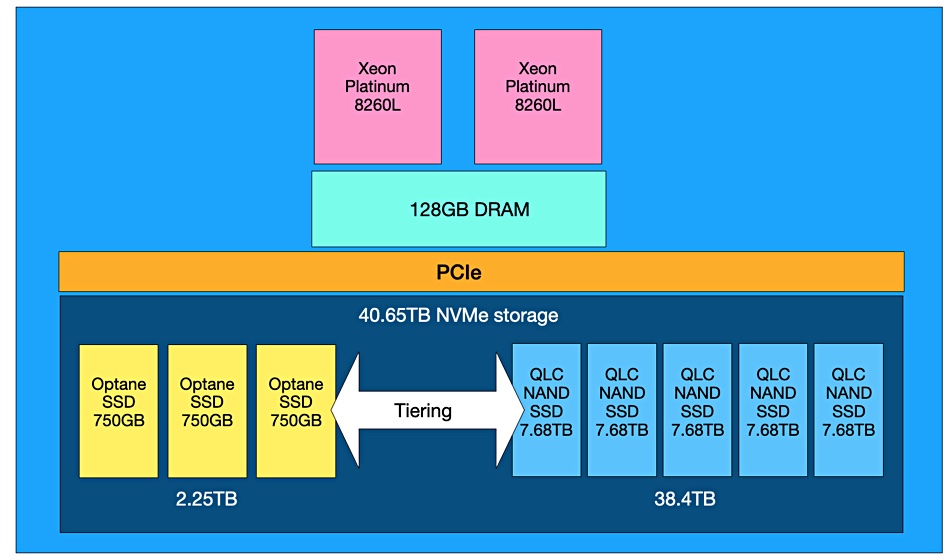
It is common practice to implement tiered storage in HCI platforms. Inside each node in a cluster, one drive is treated as a cache device – typically an SSD – and the other drives are allocated as a capacity tier. In the past, capacity drives have been rotating hard drives, but these days the capacity tier is also likely to be SSD.
In this configuration, the cache tier effectively absorbs all the writes coming from every virtual machine running on the host system, which means it is critical to specify a device with very low latency and very high endurance for this role. In other words, you need a device that would not ‘bog down’ as those extra CPU cores are put to work.
Intel® Optane™ SSDs fit the bill here, because Intel® Optane™ is based on different technology to the NAND flash found in most other SSDs. Current products such as the Intel® Optane™ SSD DC P4800X series have a read and write latency of 10 microseconds, compared with a read/write latency of 77/18 microseconds for a typical NAND flash SSD.
In terms of endurance, Intel claims that a half terabyte flash SSD with an endurance of three Drive Writes Per Day (DWPD) over five years provides three petabytes of total writes. A 375GB Optane™ SSD has an endurance of 60 DWPD for the same period, equating to 41 petabytes of total writes, representing around a14x endurance gain over traditional NAND.
The capacity tier of the storage serves up most of the read accesses and can therefore consist of SSDs that have greater capacity but at lower cost and endurance. Intel’s second generation of 3D NAND SSDs based on QLC technology is optimised for read-intensive workloads, making them a good choice for this role.
Furthermore, IT departments can use the greater efficiency of Intel® Optane™ SSDs to make cost savings by reducing the size of the cache tier required. Intel claims that the cache previously had to be at least 10 per cent of the size of the capacity tier. But with the performance and low latency of Intel® Optane™, 2.5 to 4 per cent is sufficient. This means a 16TB capacity tier used to require a 1.6TB SSD for caching but now customers can meet that requirement with a 375GB Intel® Optane™ SSD.
Boosting memory capacity
Another feature of Intel® Optane™ is that the technology is byte-addressable, so it can be accessed like memory instead of block storage. This means that it can expand the memory capacity of systems, boosting the performance of workloads that involve large datasets such as databases, and at a lower cost compared to DRAM.
To this end, Intel offers Optane™ DC Persistent Memory modules, which fit into the DIMM sockets in systems based on Second Generation Intel® Xeon® Scalable processors. The modules are used alongside standard DDR4 DIMMs but have higher capacities – currently up to 512GB. The latency of the modules is higher than DRAM, but a tiny fraction of the latency of flash.
These Optane™ memory modules can be used in two main ways; in App Direct Mode, they appear as an area of persistent memory alongside the DRAM and need applications to be aware there are two different types of memory. In Memory Mode, the CPU memory controller uses the DRAM to cache the Optane™ memory modules, which means it is transparent to applications as they just see a larger memory space.
In other words, App Direct Mode provides a persistent local store for placing often accessed information such as metadata, while Memory Mode simply treats Optane™ as a larger memory space.
VMware, whose platform accounts for a large share of HCI deployments, added support for Optane™ DC Persistent Memory in vSphere 6.7 Express Patch 10. In tests using Memory Mode, VMware found it could configure a node with 33 per cent more memory than using DRAM alone. With the VMmark virtual machine benchmark suite [PDF], VMware said this allowed it to achieve 25 per cent higher virtual machine density and 18 per cent higher throughput.
In conclusion, HCI might have started out as a simpler way to build infrastructure to support virtual machines, but advances in technology now mean it is able to operate even mission critical workloads. With Second Generation Intel® Xeon® Scalable processors and Intel® Optane™ DC SSDs, HCI can deliver the I/O, low latency and reliability needed to support enterprise applications and their database back-ends.
It can also potentially deliver cost savings, as the greater efficiency of Intel® Optane™ storage means that fewer drives or nodes may be required to meet the necessary level of performance.
Sponsored by Intel®