


Using a data warehouse in the cloud is a Band-Aid to make existing data preparation methods for analytics last longer. But this method is plain wrong – so says Dremio, a data warehouse startup that argues analytics should work directly on source data in the cloud.
It thinks the extract, transform and load (ETL) mechanism for populating data warehouses is time-consuming and wasteful. With ETL, source data in a data lake is selected, copied, processed and then loaded into a second silo, the data warehouse, for analytics work, costing time and money.
More processing is required, as data scientists reformat it into data cubes, business intelligence (BI) extracts and aggregation tables for their own purposes.
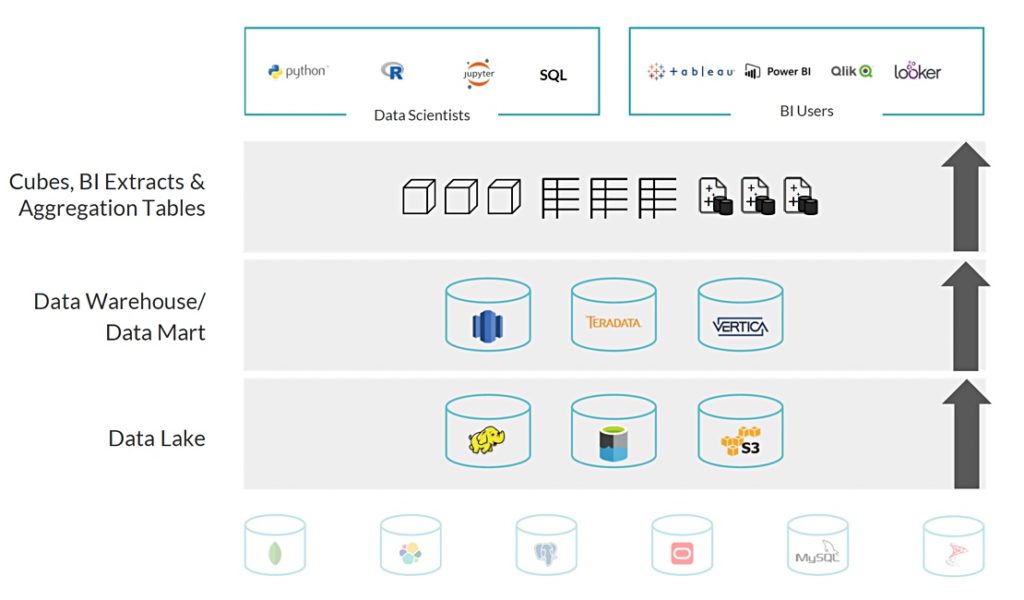
It would be better to run the analytics directly on source data in the data lake, according to Dremio, which has built a Data Lake Engine running on AWS and Azure to do this. Users can execute queries faster by going straight to the S3/ADSL data lake data. The software uses open file formats and source code so there is no vendor lock-in, as there can be with existing data warehouses.
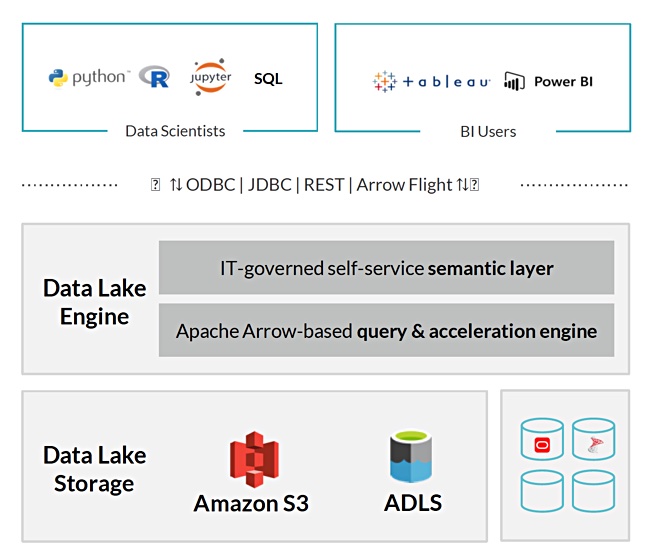
Dremio says that its direct access software means there’s no need to create cubes, BI extracts and aggregation tables. Data scientists use a self-service semantic layer that’s more like Google Docs than an OLAP cube builder or ETL tool.
Dremio features
To speed data access the software provides a columnar cloud cache which automatically stores commonly accessed data on NVMe drive storage close to the clustered compute engines, called Executor nodes. Predictive pipelining pre-loads the cache and helps eliminate waits on high-latency storage.
The software has an Apache Arrow-based engine for queries. This has been co-created by Dremio and provides the columnar, in-memory data representation and sharing. Dremio claims Arrow is now the de-facto standard for in-memory analytics, with more than one million downloads per month.
Apache Arrow Flight software extends the performance benefits of Arrow to distributed applications, It uses the Remote Procedure Call (RPC) layer to increase data interoperability by providing a massively parallel protocol for big data transfer across different applications and platforms.
Flight operates on record batches without having to access individual columns, records or cells. For comparison, an ODBC interface involves asking for each cell individually. Assuming 1.5 million records, each with 10 columns, that’s 15 million function calls to get this data for analytics processing.
An open source Gandiva vectorised processing compiler is used to accelerate the handling of SQL queries on Arrow data. It reduces the time to compile most queries to less than 10ms. Gandiva supports Xeon multi-core CPUs with GPUs and FPGAs on Dremio’s roadmap. Dremio claims Gandiva makes processing 5 to 80 times faster again, on top of Arrow’s acceleration.
The software also integrates with identity management systems like Azure Active Directory to ease its use by enterprises validating data access that way. It also supports AWS security utilities.
A Dremio Hub software entity has Snowflake, Salesforce, Vertica and SQLite connectors that joins data with existing databases and data warehouses. The hub supports any data source with a JDBC driver, and includes relational databases, REST API endpoints, and other data sources. More connectors are being added, with 50+ targeted for the end of the year.
The Dremio software can also run on-premises as well as in the AWS and Azure public clouds.
Company background
Dremio was started in 2015 by former MapR employees Tomer Shiran (CEO) and Jacques Nadeau (CTO). Total funding is $45m. It is headquartered in Santa Clara, CA and the v1.0 product was delivered in 2017. Customers include Diageo, Microsoft, UBS, Nutanix, and Royal Caribbean Cruises.
Shiran predicts 75 per cent of the global 2000 will be in production or in pilot with a cloud data lake in 2020. That sounds good but the claim is hard to validate.
Dremio will need a major funding round this year or next to participate fully in this predicted upswing. This would help it compete with Snowflake and its massive $923m funding.





