NAND and SSD supplier Kioxia is reporting a rise in revenues and underlying profitability as market demand strengthens, but there is no news on either a resumed IPO or an acquisition.
The company filed for an IPO in August last year but the US-China trade dispute derailed it. Market speculation about Western Digital and Micron acquisition bids for Kioxia surfaced in April.
In Kioxia’s fourth quarter fy21, ended 31 March, showed a 10.2 per cent Y/Y revenue rise to ¥294.7bn ($2.7bn), with a loss of ¥21bn ($190m), contrasting with the year-ago ¥9.8bn ($90m) profit. Kioxia sold more SSDs into data centres and for use as desktop/notebook drives, which drove a topline rise. This was despite a seasonal decrease in smartphone NAND sales.
Full year revenues rose 19 per cent, in line with the market, for fiscal 2021 ended 31 March, hitting ¥1,178.5bn (c $10.79bn) as the NAND glut eased throughout the year.
Full year net income was a loss of ¥24.5bn ($22m), a great improvement on the ¥166.7 bn ($1.53 bn) prior year loss. A company statement said profitability improved significantly, with a return to positive operating income due to cost reductions from OPEX management. There was also a move to 96-layer 3D NAND (BiCS 4) production with a lower cost/TB than the previous 64-layer product.
Shipments and builds
It has seen high single-digit per cent average selling price (ASP) declines in both Q3 and Q4 fy20. Quarter-on-quarter bit shipments gave grown from a low single-digit increase in Q34 to a mid single-digit increase in Q4, however. If the ASP decline can be lowered further, or halted, and bit shipments rise at the same or a higher rate Kioxia can move into profit.
The company is expanding its NAND manufacturing capacity by building a seventh fab at its Yokkaichi facility.
Kioxia is developing its sixth generation (BiCS 6) 162-layer 3D NAND products to lower manufacturing cost further. It sees data centre and client SSD demand staying strong. It predicts smartphone NAND demand will rise as 5G models become popular. Kioxia will be hoping this means more NAND and SSD sales with stronger pricing, enabling the firm to make a profit.
IPO, acquisition and amalgamation
A report in Japanese biz daily the Asahi Shimbun said Kioxia’s majority shareholder, Bain Capital Private Equity, had no plans to sell its holding. Yuji Sugimoto, who heads Bain ops in Japan, said Kioxia’s IPO will be brought forward ASAP.
He believes there will be an amalgamation of NAND producers. He also said governments will have to be involved to help make it happen.
There are are six major NAND producers: Intel, Kioxia, Micron (the industry leader), Samsung, SK Hynix, and Western Digital. SK Hynix is buying Intel’s NAND foundry and and SSD operations, which will bring the number down to five.
Kioxia and Western Digital have a joint flash foundry venture. Potential Kioxia buyers appear to be Micron and Western Digital, and Samsung, as SK Hynix already has Intel NAND and SSD interests in its grasp. It may be easier for Japan, where Kioxia is based, to agree an acquisition by a US company than a Korean one. This is patly due to historical enmity between Japan and Korea based in events in the Second World War.
Bain Capital may be thinking that a bidding for Kioxia could generate a better price in the open market following an IPO than private sale bids before any IPO takes place.
It’s time to visit with old friends this week as Fibre Channel lives on at higher speeds, DRAM demand increases, and backup revenues rise nicely. That’s true for both data protection in the cloud and on-premises. The constant increase in data generation and movement is providing a constant positive headwind for the storage business.
For once AI, machine learning and Kubernetes take a back seat.
Broadcom’s 64gig HBA
It has only taken 8 months. Broadcom, which launched its 64Gbit/s (gen 7) Fibre Channel switch last September, has made available its matching 64Gbit/s HBA: the Emulex Gen 7 LPe36000-series Host Bus Adapters.
Emulex LPe36000.
Broadcom claims it’s the world’s first 64G Fibre Channel HBA and enables an end-to-end 64G data path. Its speed in Tolly Group testing:
Reduced Oracle data warehousing runtime by 87 per cent compared to 32G FC,
PCIe 4.0 demonstrated up to a 63 per cent improvement in application performance for dual-port 64G HBAs compared to running in a PCIe 3.0 server,
Cuts storage migration times by up to 38 per cent,
Reduces VM boot storm times by up to a half.
Kevin Tolly, founder of The Tolly Group, said: “The combination of new PCIe 4.0 servers and all-flash arrays demonstrate such high performance margins that they are now capable of consuming all the bandwidth that current storage networks can deliver.”
That’s why, he says, “all-flash storage arrays should be paired with 64G technology such as Emulex Gen 7 HBAs and Brocade Gen 7 switching.”
DRAM shipments and prices rose in Q1
Research house TrendForce says all DRAM suppliers posted revenue growth in 1Q21, and overall DRAM revenue for the quarter reached $19.2bn, 8.7 per cent growth QoQ.
This was mostly due to higher demand for notebook memory resulting from remote working and working from home during the pandemic. The researchers also cite increased demand from Chinese smartphone manufacturers – OPPO, Vivo and Xiaomi, competing for marketshare after Huawei was included on the US Entity list.
These two things led to higher-than-expected shipments from various DRAM suppliers while DRAM prices rose as TrendForce had predicted.
It says some server manufacturers have started a new round of procurement as they expect a persistent increase in DRAM prices.
Datto drives revenues higher
Cloud backup service provider Datto saw Q1 revenues rise to $144.9m, up 16 per cent on last year’s $116m and beating estimates. There was a $15.3m profit (GAAP net income), up a massive 1,030 per cent from the year-ago $1.4m.
Subscription revenues rose 17 per cent Y/Y to $135.6m and ARR (Annual Run-rate Revenue) rose 15 per cent to $572.5m.
It increased its MSP partner count by 300 in the quarter, to 17,300. Guidance for next quarter is $147m +/- $1m in revenues.
William Blair analyst Jason Ader told subscribers: “The beat was driven by rebounding demand for the firm’s core continuity (backup/disaster recovery) solutions, which management attributed to the combination of economic reopening tailwinds (though still early and uneven) and SMB focus on ransomware protection.”
He said: “Net new ARR, which after adjusting for currency was $26m, a significant acceleration from the prior three quarters and the second-highest net new ARR in company history.”
Ader thinks Datto will achieve mid-to-high teens growth after facing increased customer churn during the pandemic.
Veeam announces yet another double-digit quarter
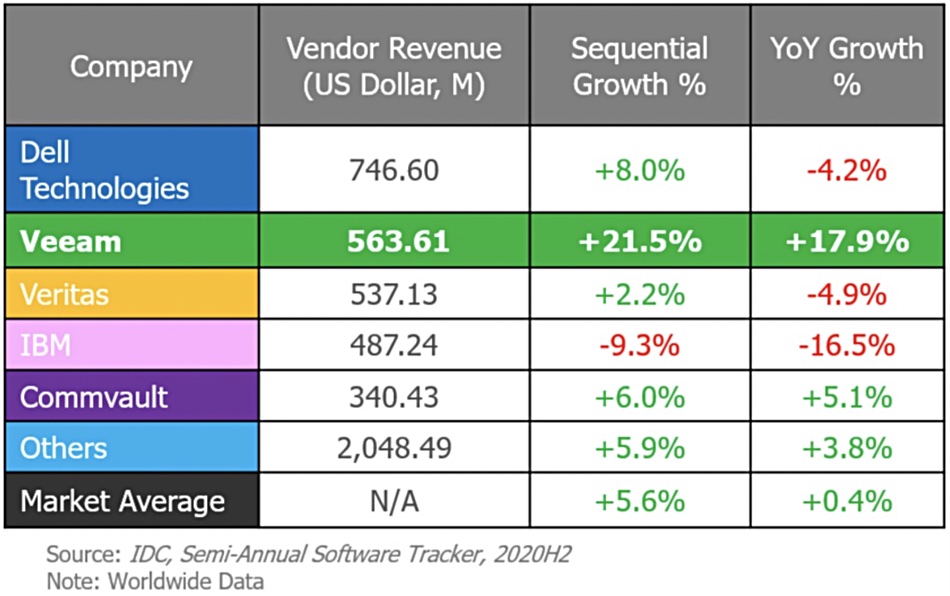
Data protector Veeam has announced an annual recurring revenue (ARR) increase of 25 per cent Y/Y for Q1’21.
CEO and Board Chairman William Largent talked of double-digit YoY growth across all geos and said: “To see such increases globally is a tremendous achievement in such a challenging environment.”
Veeam has now recorded 13 consecutive quarters of growth greater than 10 per cent and the customer count has gone past 400,000.
It overtook Veritas in revenue terms in the quarter and IDC says it’s the second largest software vendor worldwide after Dell EMC.
Danny Allan, CTO and SVP of Product Strategy at Veeam, said: “Our product roadmap for 2021 will further expand our offerings with the top cloud providers – AWS, Microsoft Azure and Google – and Kubernetes.”
Shorts
Aunalytics is partnering Stonebridge Consulting. The combination of Aunalytics Aunsight Golden Record as a Service and Stonebridge’s EnerHub data management product provides customers in the oil and gas market with Universal Data Access and dynamic data cleansing and governance.
ChaosSearch’s multi-model and multi-cloud Data Lake Platform product now supports SQL on the AWS and GCP clouds. It indexes data as-is within cloud environments, recognising native schemas, rendering it fully searchable and uses open APIs. That enables log and BI analytics with existing tools in use, such as Tableau, Looker, Kibana, Grafana or Elastic API.
Cisco is end-of-lifing its UCS-E VSAN ready node. The last day to order the product is November 5, 2021.
The ClearDATA Healthcare Security and Compliance Platform can automatically detect protected health information (PHI) in multi-cloud storage buckets. It ensures compliance with applicable privacy regulations that include HIPAA and GDPR.
Commvault’s Metallic SaaS data protection is out in 20 countries in the EMEA region after having been available for 6 months. Shai Nuni has been appointed as the new Vice President of Metallic in EMEA. Customer wins include Aliscargo Airlines (Italy), Evolutio Cloud Provider (Spain), Sithabile Technology Group (South Africa), and Keshet Broadcasting (Israel)
The Japan Aerospace Exploration Agency (JAXA) has selected DDN‘s SFA200NVXE and SFA7990XE modular storage systems as infrastructure components for its new 19.4 TFLOPS FX1000 ARM-based supercomputer system TOKI-SORA, which went into operation in December 2020. The DDN systems will provide over 50 PBs of usable SSD and HDD storage capacity at a combined peak throughput of up to 1TB/sec.
UK-based data protector Databarracks has bought 4sl for an undisclosed sum to create a combined company with 75 staff, including 50 data protection experts.
Barnaby Mote, CEO and founder of 4sl, said: “Databarracks is now the UK’s largest Commvault Managed Service Provider.”
Delphix has announced new data compliance capabilities for Salesforce customers, protecting personally identifiable information.
Flash chip fabber and SSD maker Kioxia announced a 20 billion yen ($18m) investment to expand its Technology Development Building at its Yokohama Technology Campus and to establish its new Shin-Koyasu Advanced Research Center. The new facilities are expected to be operational by 2023.
Pavilion Data is supplying its HyperParallel Data Platform array to the Cyber Bytes Foundation (CBF), which showcases technologies in its Research and Innovation Labs located at the Quantico Cyber Hub (QCH). These labs support a Cooperative Research and Development Agreement (CRADA) with Marine Corps System Command and Marine Corps Forces Cyberspace Command.
Open source database software and services supplier Percona announced a preview of its fully open source Database as a Service (DBaaS), which eliminates vendor lock-in and supports Percona open source versions of MySQL, MongoDB and PostgreSQL. By using Percona Kubernetes Operators it’s possible to configure a database once, and deploy it anywhere – on-premises, in the cloud, or in a hybrid environment.
Korean flash and memory foundry business SK hynixsaid it is considering a plan to double its foundry capacity. Co-CEO and Vice Chairman Park Jung-ho said it will look into several options such as equipment expansion at domestic sites and M&A.
BeeGFS parallel file system company ThinkParQ has promoted channel partner Advanced Clustering Technologies from Gold to Platinum status, meaning it can provide 1st and 2nd level support.
DDN’s Tintri operation paid for an ESG study that said VDI customers got value from their Tintri VMstore storage with cost savings and easier VDI admin.
Cloud storage provider Wasabi has announced support for S3 Object Lock, meaning stored objects can be made immutable for a specific period of time and so protected against ransomware. Of course you needs backup apps that support it too, like Veeam Backup & Replication.
Analysis: We have more HPE Alletra‘s features and performance details, after analysing a post by Dimitris Krekoukias. The Nimble exec provided a more informed comparison with the competition, Primera arrays, and a view of the 9000’s branding.
The new Alletra 9000 details we now have are:
Active Peer Persistence allow “a LUN to be simultaneously read from and written to from two sites synchronously replicating”;
Multiple parallelised ASICs per controller help out the CPUs with various aspects of I/O handling for the all-NVMe SSDs;
Vast majority of I/O happens well within 250 microsecond latency;
Array OS determines what workloads to auto-prioritise
Alletra 9000 and competing arrays
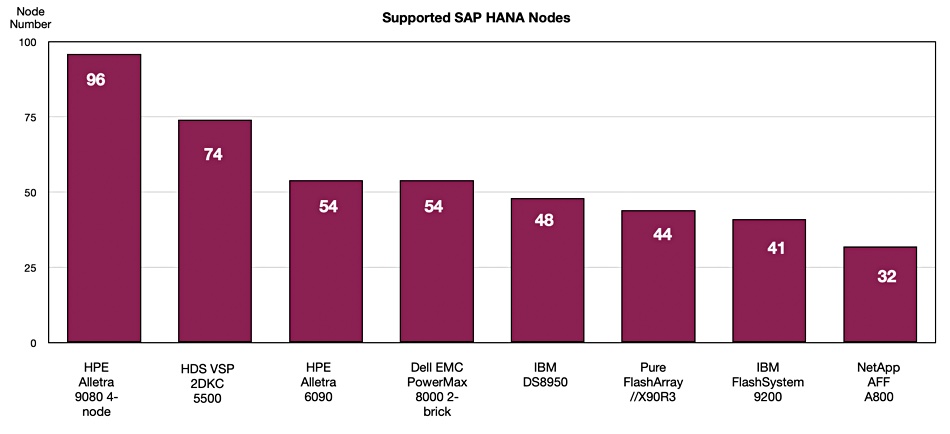
Krekoukias charts the 9000 (and 6000) on a SAP HANA Nodes supported basis, against competing arrays from Hitachi (VSP), Dell EMC (PowerMax), IBM (DS8950, FlashSystem 9200), Pure Storage (FlashArray//X90), and NetApp (AFF A800).
Krekoukias makes much of the 9000’s ability to deliver this performance from its single 4U enclosure. He believes it “makes it the most performance-dense full-feature Tier 0 system in the world (by far).”
He says of the HDS VSP 5500: “The physically smallest possible HDS 5500 shown for comparison would need 18U to achieve 74 nodes. So, the Alletra 9000 can do 30 per cent more speed in 4.5 times less rack space.”
That means it beats HPE’s own XP8, which is an OEM’d HDS VSP 5100/5500 array.
As for Dell EMC’s PowerMax: “A PowerMax 8000 2-Brick (4 controllers) needs 22U and only does 54 nodes. A 3-brick system (6 controllers) can do 80 nodes and takes almost a whole rack (32U). So even with more controllers, a PowerMax needs 8x more rack space to provide less performance than an Alletra 9000!”
There’s more of the same regarding Pure Storage and NetApp.
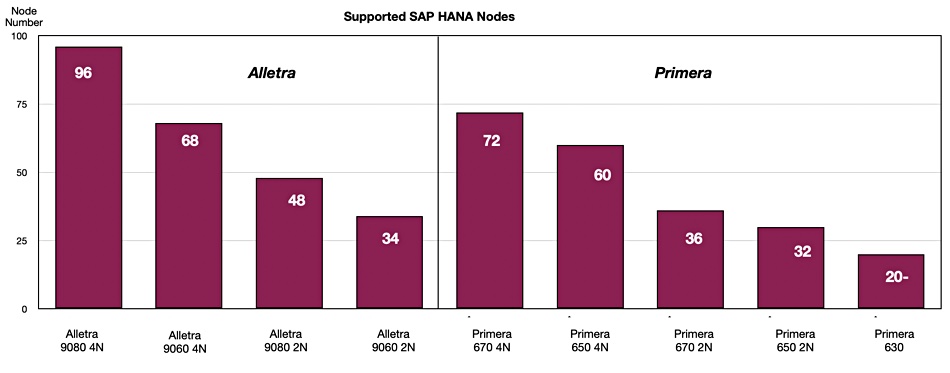
We were interested in using the data to compare HPE’s Primera arrays with the Alletra 9000. The Primera’s architecture and OS are the basis of the 9000.
Alletra 9000 and Primera
A quick Primera range recap: the current Primera arrays are three all flash models – the 24-slot x 2U x 2-node A630, the 48-slot x 4U x 2-4-node A650, and the A670 – and three hybrid ones: the C630, C650 and C670, all with the same slot, chassis and node details. A node means a controller. The A630 and C630 have a single ASIC per node while the A and C 650 and 670 systems have 4 ASICs per node.
The Alletra 9000 has a 4U chassis like the Primera A and C 650 and 670 arrays.
The ASICs handle zero detect, SHA-256, X/OR, cluster communications, and data movement functions.
Krekoukias writes: “The main difference is how the internal PCI architecture is laid out, and how PCI switches are used. In addition, all media is now using the NVMe protocol. These optimisations have enabled a sizeable performance increase in real-world workloads.”
The blog reveals the number of SAP HANA nodes it supports. We can chart the Alletra 900 and Primera array performance on that basis:
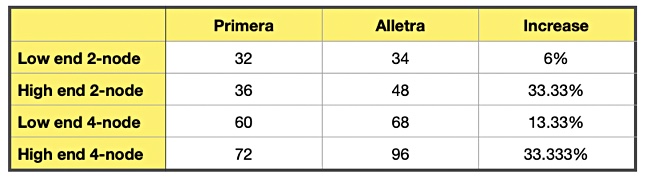
This allows us to directly compare the 9000 models to the equivalent Primera models and work out the performance increase:
The 4-node (controller) models gain a 33.33 per cent speed boost; there were smaller increases for the 2-node models.
Alletra 9000 performance characteristics
As we understand it, an Alletra 9000 system, like a Primera multi-node system, is a cluster in a box. You cannot cluster separate Alletra 9000s together, unlike the Nimble-based Alletra 6000s.
In theory, the only way to scale up Alletra 9000 performance further would be to add more controllers inside a chassis, or to provide some form of interconnect to link separate Alletra 9000s together. Both cases would require hardware and software engineering by HPE.
Without this, having only 4 controllers in its chassis limits the Alletra 9000’s top-end performance, as with Primera. Somewhat embarrassingly, it also uses PCIe gen 3 instead of the twice-as-fast PCIe gen 4 bus (like the Alletra 6000s).
The Alletra 9000s get more performance, per chassis, than the 6000s, even with the slower PCIe Gen 3 bus, as their ASIC hardware accelerates their performance. But cluster the slower 6000 boxes together and they outrun the 9000, reaching 216 SAP HANA nodes supported.
Speeds and feeds
It is a bit of a mystery why the Alletra 9000 didn’t move to AMD processors and the PCIe 4 bus, like the 6000, and gain a greater performance boost over the Primera arrays. That said, the engineering burden would have been greater and taken longer to complete. They would have needed to tune and tweak the ASICs for the new CPUs, and re-engineer the passive backplane to support PCIe Gen 4.
In our view there is an implicit roadmap to a second generation Alletra 9000, using AMD processors and PCIe gen 4. Whether that roadmap contains a larger 9000 chassis to accommodate more nodes, six or eight, is a moot point. So is the addition of a clustering capability, like that of the Alletra 6000.
Without these, faster Dell EMC PowerMax and clustered NetApp AFF systems, as well as clustered 6000s, will be able to outgun the top-end Alletra 9000.
Branding conundrum
It’s clear that, underneath the umbrella Alletra brand, the 9000 and 6000 arrays are different hardware systems with different OS software as well. They are unified by the branding and by the shared management console and ownership/usage experience.
As we understand it, a migration from the 6000 to the 9000 would be a fork-lift upgrade. We have asked if there is an HPE strategy to move to a common hardware/software architecture for the Alletra products.
From a public cloud point of view, where we order storage with particular service levels and characteristics – think S3 variations – the Alletra, like S3, would be an umbrella brand signifying different storage service types available through a unified and consistent front end. The actual hardware/software product details are abstracted away and underneath the AWS customer experience infrastructure.
Seen through this lens, the Alletra branding makes good sense.
The Chief Revenue Officer of high-speed file system startup WekaIO has resigned.
Ken Grohe
Ken Grohe became Weka’s president and CRO in June 2020, and lasted 11 months at his post. Carol Platz, a senior director in Weka’s Global Corporate Marketing organisation, also resigned this month.
Grohe’s LinkedIn entry states he joined Commvault’s software-as-a-service advisory board in a part-time role in April.
We asked Weka about Grohe and Carol Platz’s departures. CEO and cofounder Liran Zvibel told us: ”Ken Grohe has decided to spend time pursuing his passion, which is advising startup companies, especially those in the SaaS space. He will remain an advisor to WekaIO as he uses his years of experience to help companies reach their goals. Ken remains a true believer in Weka’s mission, its ability to grow, and its Limitless Data Platform’s ability to dominate the market.
Carol Platz
“Regarding Carol Platz, after helping to launch and scale Weka, Carol was offered a leadership position in marketing at another company which has been her personal goal, and we are very happy for her.“
She has in fact joined NVMe-over-TCP outfit Lightbits Labs as its global marketing veep.
Zvibel said this of Grohe and Platz: “While we will miss them both, they remain friends of Weka.”
Opinion: The golden age of storage hardware startups is over and storage software rules the world.
B&F is including hyper-converged infrastructure appliance vendors amongst the storage startups and we recognise that storage hardware startups always had a software component as well.
There are storage array startup technology eras, such as the all-flash array era, the deduplicating appliance area, the NVMe array era and the HCI era. Generally speaking, deduplicating arrays solved a backup disk capacity problem, all-flash arrays fixed the slow disk access problem, NVMe SSDs fixed a slow SSD issue, NVMe over Fabrics sorted out the slow storage networking problem and HCI was a response to SAN complexity difficulties.
Here is a rough, ready list of HCI and storage array startups recorded in our files since 1999:
2019 – 2021: None
2018: Nebulon
2017: None
2016: VAST Data
2015: Fungible
2014: E8, Excelero, Pavilion Data
2013: Apeiron, Stratoscale, Vexata
2012: Datrium, Qumulo, SoftIron, Symbolic IO
2011: Cloudian, Coho Data, Mangstor, StorONE
2010: Exablox, Infinidat, SolidFire, Tegile
2009: Gridstore, Maxta, Nutanix, Pure Storage, Scality, SimpliVity
It’s immediately obvious that the seven years between 2007 and 2014 were the golden years. Since then, only VAST Data has been started up and even it has recently moved away from hardware; it knows which way the wind is blowing.
What big storage issues are left that can be fixed with better array system hardware?
The single largest problem is data movement, making it quicker or avoiding it altogether. There are clever software tricks to make it quicker, such as Nvidia’s GPUDirect and its CPU/storage IO software stack bypass technology. There is also a hardware dimension to this with compute on storage drives from NGD and Pliops – but these are examples of drive-level technology not system or array-level.
Another hardware angle to the data movement problem is to keep the majority of data in memory and reduce storage IO that way. It appears to need the CXL bus and and storage-class memory. These are technologies that will be adopted by the mainstream server vendors in two to three years when they mature, and probably won’t provide scope for HW/SW startups.
How things have moved on
In general the big incumbents – Dell, HPE, and NetApp – have become faster at adopting new technology; that is why, in my view, no NVMe-over Fabrics startup has made it to an IPO event. They have also adopted Optane quite quickly and that has closed off opportunities for most storage startups using Optane, except ones that twinned it with clever software, such as VAST Data.
Another factor lowering interest in hardware-focused storage startups is the public cloud, which can throw enormous capacity and compute scale at storage-related problems.
There’s plenty of scope for storage innovation though. New resistive RAM technologies are being developed and penta-level cell flash may have promise. Software abstraction layers are needed in the hybrid cloud world to unite the on-premises and hybrid environments. Kubernetes storage is a hotbed of development. The data management area has enormous scope as does the whole analytics and AI field.
But for now it appears that a hardware-based approach to storage system-level problems has come to an end. So, alas, a golden age of storage HW/SW startups is coming to a close.
All-flash array supplier Pure Storage is becoming a public cloud-like business, offering its products and capabilities as services in a hybrid multi-cloud world. In the background is its cloud-native Portworx software, which is deeply integrated into its FlashArray and FlashBlade products.
Pure will also add automated monitoring and so-called “AI-driven” recommendation capabilities with self-service management and digital procurement to its Pure1 console. The changes were announced at its Pure//Accelerate virtual event today. They are generally in line with the thrust of recent announcements on APEX by Dell Technologies and HPE, which recently rolled out Alletra hardware and Digital Services Platform as its as-a-service proposition.
Prakash Darji, Pure’s VP and GM for Digital Experience, said in a canned statement: “By giving our customers more control over their environments and active recommendations for solving problems before they happen, we’re delivering on our Digital Experience vision and transforming the IT management experience yet again.”
Murli Thirumale, Pure’s VP and GM of its Cloud Native Business Unit, said the firm was “delivering storage that can be orchestrated entirely through Kubernetes”…. along with “a seamless hybrid cloud experience.”
Pure1 Digital Experience
The Pure1 Digital Experience builds on Pure-as-a-Service by adding self-service management and online procurement to its catalogue. Customers can buy new systems and services – including Pure-as-a-Service, Portworx, and Pure Cloud Block Store – or expand their as-a-service footprint on demand.
Users can quote, order and track new system additions from anywhere as well as schedule upgrades. Customers can also use the Meta AI engine in Pure1 to get predictive fault analysis and resolution using telemetry from FlashArray, FlashBlade, Portworx, and Pure Cloud Block Store for AWS and Microsoft Azure. This includes both virtual machines and containers on these products, with real-time troubleshooting.
The vendor says the AI engine can provide forecasts of how these products will respond if customers add or move workloads, with recommendations on workload capacity and performance scaling.
Meta can also provide assessments for ransomware protection, with suggestions such as SafeMode snapshots.
Portworx
At the array end of the digital experience stack, so to speak, Pure has integrated its cloud-native Portworx storage and data protection software into FlashArray and FlashBlade provisioning for Kubernetes.
V2.8 of Portworx Enterprise enables the automatic creation of storage volumes or file systems on FlashArray and FlashBlade when users provision container-native volumes through Portworx. The provisioning is done using Kubernetes without the need to directly interface with the backing storage arrays.
CTO International, Alex McMullan told us: “Pure has taken a unique approach. For example, instead of just running a CSI plugin in front of a FlashArray, where provisioned LUNs are mapped to volumes on a 1:1 basis, Portworx uses the CSI spec to provision and manage the underlying storage, but then virtualizes that storage to enable an order of magnitude more volumes as well as more administrative actions (create, delete, attach, detach), thanks to the distributed Portworx control plane.
“Additionally, with Portworx, these virtual volumes can be managed at the container-granular and application-granular level, enabling true app-aware data management. For instance, a Portworx backup of a Kubernetes application captures the distributed container volumes, as well as all the Kubernetes application configuration and can be moved to any S3-compatible objects, like Amazon S3 or FlashBlade.”
The new release sends Kubernetes cluster and volume usage metrics collected by Portworx to Pure1. McMullan said: “We do not believe any competitor has this level of ability with K8s monitoring and observability, though we are aware of competitors talking about AI ops and insights into cloud infrastructure etc.”
V2.8 also adds VMWare Tanzu (TKG) support via the native Tanzu CSI driver. Portworx continues its general third-party array support and can provide a consistent, Kubernetes-native experience for applications running on any enterprise storage that supports CSI.
Pure’s first generation Kubernetes offering, Pure Service Orchestrator (PSO) will become a part of Portworx Essentials, Portworx’s freemium offering, to provide unified storage orchestration for Kubernetes. Portworx Essentials is included and fully supported in a customer’s Evergreen or Pure-as-a-Service subscriptions with more functionality than the current PSO.
Portworx Enterprise 2.8 will be available in June.
Comment
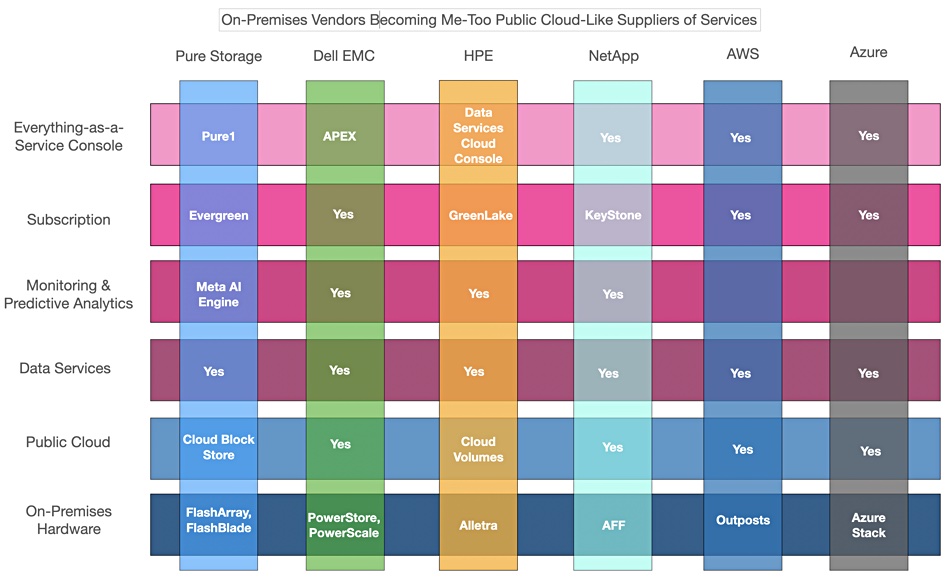
In a hotly competitive market, the on-premises storage and system suppliers are becoming public cloud-like and the public cloud suppliers are building on-premise offerings – such as AWS’ Outposts, Microsoft’s Azure Stack and GCP on-prem.
In a sense all the main storage and server/storage system suppliers are adopting public cloud characteristics:
General diagram showing suppliers and public cloud operators adopting each other’s’ clothes.
Pure’s emphasis on the digital experience might seem insubstantial to people concerned with storage array speeds and feeds, but the firm seems deadly serious about this stuff. CEO Charlie Giancarlo has said that 95 per cent of Pure’s engineers are software engineers; that’s an indication of hardware’s relative importance to Pure these days.
An, ahem, purist might say that customers are not concerned with the hardware speeds and feeds of Amazon’s cloud storage facilities, they just buy/consume storage services with a totally online experience. And the online digital experience is all software.
Startup Ionir has said its latest software release adds Kubernetes app ransomware protection with a 1-second RPO.
It’s part of a package of added data services which include multi-cloud instant copy of persistent volumes between private, AWS and GCP clouds, hot rebalancing across storage media, and faster recovery, rebuilds and upgrades.
Jacob Cherian.
Ionir CEO Jacob Cherian said in a canned statement: “Everything that Kubernetes supports, we support. And we have additional, exclusive functionality that Kubernetes doesn’t support yet, such as instant copy of volumes across clusters and over distance.”
The 1-sec RPO comes from Ionir’s clone to time technology, which puts the timestamps of all storage writes in a metadata database. Ionir claims this gives customers the ability to access data volumes as they existed at any previous point in time with one-second RPOs. This is supposed to provide a way of defeating ransomware and other malicious and accidental activities that can corrupt and delete data.
Standard Kubernetes management functions can manage the process of bookmarking specific points in time, and accessing point-in-time data copies. This enables the Kubernetes container storage interface (CSI) to request a volume from a specified time. A fully read/write-capable volume containing data as it existed at that exact requested moment is then made available to Kubernetes applications in seconds.
Ionir claims this can help streamline the AppDev pipeline with consistent test data applied across all of its stages. Its Kubernetes-native data services platform software also supplies persistence, protection, replication, global deduplication, and compression.
The company has achieved full operator certification for Red Hat OpenShift and its software is supported and validated to run on the Google Cloud Platform.
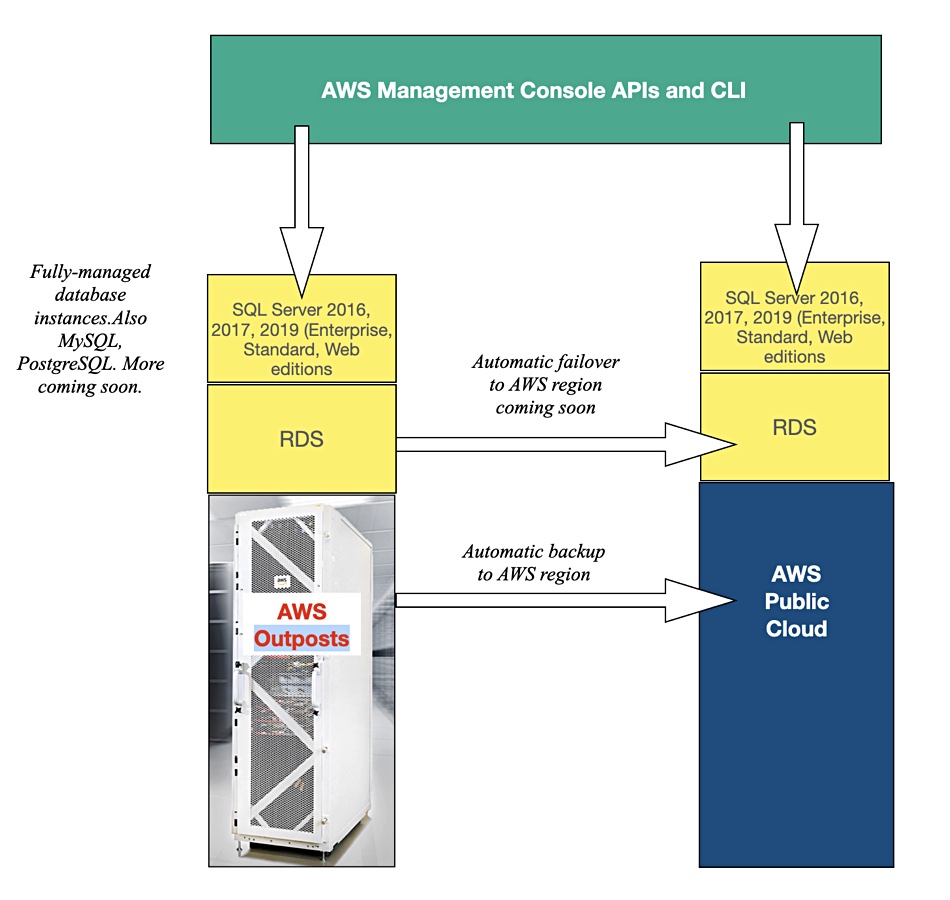
AWS has made SQL Server running on its Outposts Relational Database Service (RDS) generally available, extending its hybrid cloud database coverage, with more supported databases to come.
The news was revealed in an AWS blog that said Outposts RDS specifically supports Microsoft SQL Server 2016, 2017, and 2019 in Enterprise, Standard and Web Editions.
Outposts is the Amazon Web Services cloud hosted in a fully managed on-premises or co-location hardware box. The converged system encompasses compute, storage, networking, database and includes the same AWS infrastructure, services, APIs, and tools you’d find in the AWS public cloud. It is intended for workloads needing low-latency access for local data processing and data residency and to support application migration to AWS over a prolonged time period.
Blocks & Files diagram.
Outposts RDS is ordered and managed through the AWS cloud management console. The RDS instance can be automatically backed up to a nearby AWS region. Automatic RDS failover to an RDS instance in the region will be coming soon. Amazon says it will support more databases, presumably relational ones, in the future.
Outposts also supports Amazon’s ElastiCache memory database and its ALB application load balancer.
The Outposts hardware is currently a 42U rack that can scale out to 96 racks. Later this year it will be available at a much smaller scale; 1U and 2U servers.
Specs
The 1U Outposts provides 64 vCPUs, 128 GiB memory, and 4TB of local NVMe storage. The 2U Outposts provides up to 128 vCPUs, 512 GiB memory, and 8TB of local NVMe storage, with configurations that support accelerators like AWS Inferentia or GPUs. Each will allow customers to run Amazon Elastic Compute Cloud (EC2), Elastic Container Service (ECS), Elastic Kubernetes Services (EKS), and Virtual Private Cloud (VPC) on-premises.
A VMware variant running a fully managed VMware Software-Defined Data Center (SDDC) will also become available this year.
AWS added S3 Outposts support to the existing Elastic Block Store (EBS) support in October last year. Third-party filesystems and data protection services are available from Clumio, Cohesity, Commvault, CTERA, NetApp, Pure Storage, Qumulo and WekaIO.
Comment
AWS is extending its own hybrid cloud to more of the on-premises data processing environment. Existing SQL Server customers will be able to use Outposts RDS/SQL server as an on-ramp to the AWS cloud. AWS will be able to say that its AWS hybrid cloud offers a more consistent hybrid cloud experience than, for example, Dell, HPE, Pure and NetApp because its hybrid cloud is made up from AWS native software through and through whereas its on-premises competitors’ hybrid cloud is not.
VMware appears to be escaping this trap with the coming Outposts version of its SDDC.
Our understanding is that AWS’s coming mini-Outposts servers will be, in effect, hyperconverged systems. Once they are available, AWS should be regarded as an on-premises server systems supplier, competing with Dell, HPE, Lenovo, Supermicro and other server suppliers, and also hyper-converged infrastructure vendors, for the edge processing market.
Because AWS will be using its own hardware, it could add in its Nitro acceleration and also Graviton (Arm) CPUs. Nothing yet has been said about making its RedShift data warehouse available on Outposts.
Promo Moving to the cloud is so exciting isn’t it? New tools, unlimited infrastructure, a whole new world of analytics and machine learning. Why didn’t we do this years ago, they’ll ask?
The answer, as with so many questions, is data. And if your organisation’s cloud to do list doesn’t have “data migration” somewhere near the top, the excitement will be short lived, as you face the challenges of pouring your data lake from one place to another, while ensuring updates are replicated, and fretting about when to make that final cut over.
Oh, and we’re totally comfortable that the data is secure both in transit and at rest, aren’t we?
The fact is data is a strategic lever in the cloud migration plan as a whole and failing to appreciate this from the start will only lead to disruption, delays and dodgy data. And that’s if you’re lucky.
Which is why you should join our webcast on June 3 at 9:00 PDT / 12:00 EDT / 17:00 BST, when we’ll be looking at Zero Disruption Cloud Data Migration.
Your host will be Tim Phillips, who’s only every disruptive in a good way, and he’ll be joined by Blocks and Files’ storage guru Chris Mellor and WANdisco’s CTO Paul Scott-Murphy.
This tech triumverate be talking through the realities of on-prem to cloud migration, and how to make this process as efficient and risk free as possible.
They’ll also highlight the most pressing technical challenges around cloud data migration, and how you should tackle them.
And they’ll lay out a proven framework for planning and executing a data-first migration.
So, if the cloud is on your agenda – and let’s face it, it probably is whether you know it or not – you should really join us. All you need is to migrate a few details of your own into the registration page here and we’ll update your calendar and give you a nudge on the day.
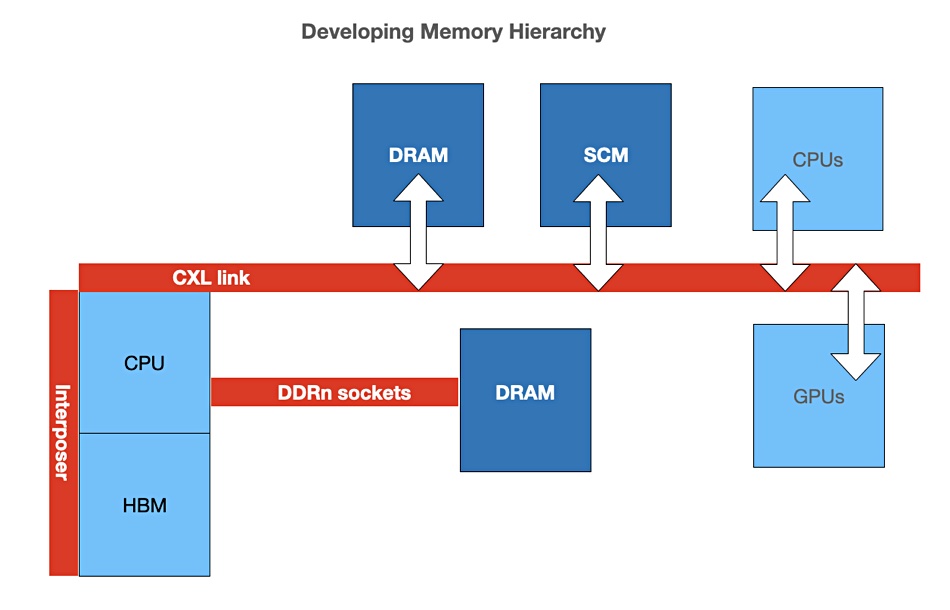
The OMI serial bus gets more memory near to the CPU than either parallel DDR memory channels or High-Bandwidth Memory (HBM) at HBM speed levels, faster than DDR channels.
That’s the position espoused by a white paper: The Future of Low-Latency Memory, co-authored by Objective Analysis (Jim Handy) and Coughlan Associates (Tom Coughlan) for the OpenCAPI consortium.
The OpenCAPI (Open Coherent Accelerator Processor Interface) was established in 2016 by AMD, Google, IBM, Mellanox and Micron to develop a better way than the DDR channel to connect memory to CPUs. There are several other members, such as Xilinx and Samsung. Intel, notably, is still not a member.
OpenCAPI has developed its OMI subset standard to focus on near memory, that memory which is connected directly by pins to CPUs.
Other CPU-memory interconnect technology developers such as CXL and Gen-Z are banding together around the CXL serial bus, which connects so-called far memory to CPUs, GPU and other accelerators.
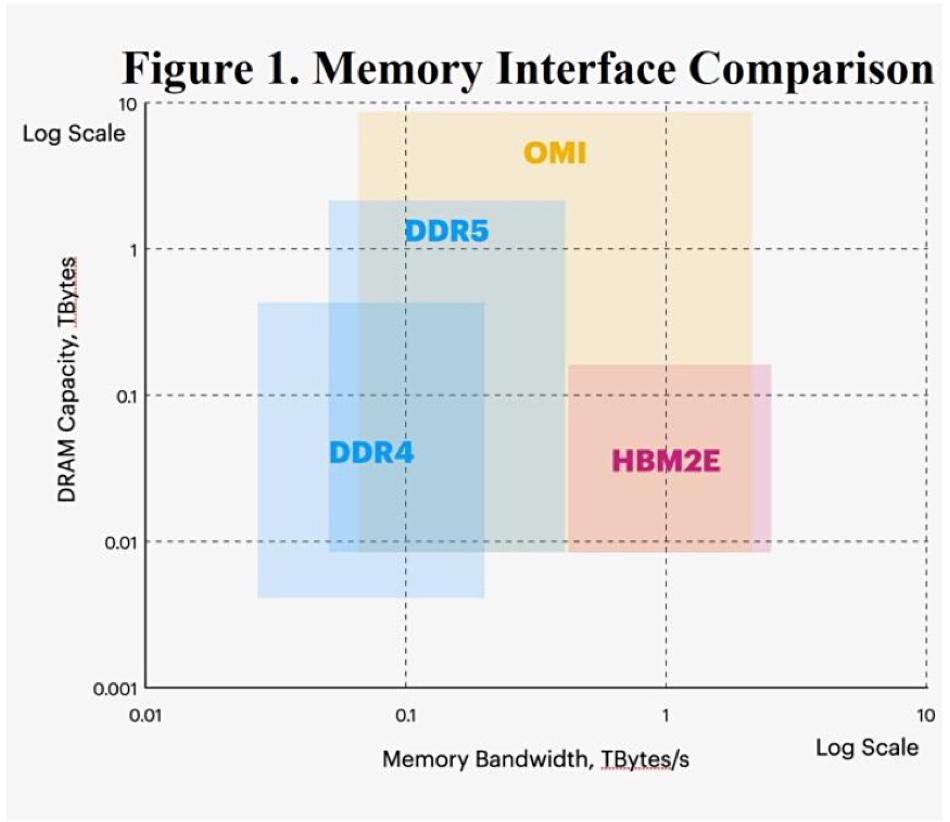
That paper’s authors say the OMI alternatives are DDR4, DDR5, and HBM in its current HBM2E guise.
The white paper puts forward the view that the Open Memory Interface (OMI) is superior to DDR4, DDR5 and High-Bandwidth Memory (HBM). Its reasoning is it doesn’t suffer from their limitations, basically lack of bandwidth and capacity with DDR4 and 5, and lack of capacity by HBM. It plots the four technologies in a 2D space defined by bandwidth and capacity, both set in log scales:
The authors say HBM is faster than DDR memory because it has 1,000 to 2,000 parallel paths to the host CPU. But HBM is more expensive than commodity DRAM. It also has a limit of stacks of 12 chips, restricting the capacity it supports. HBM is also, unlike DDR4 and DDR5 DRAM, not field-upgradable.
OMI connects standard DDR DRAMs to a host CPU using high-speed serial signalling and “provides near-HBM bandwidth at larger capacities than are supported by DDR.”
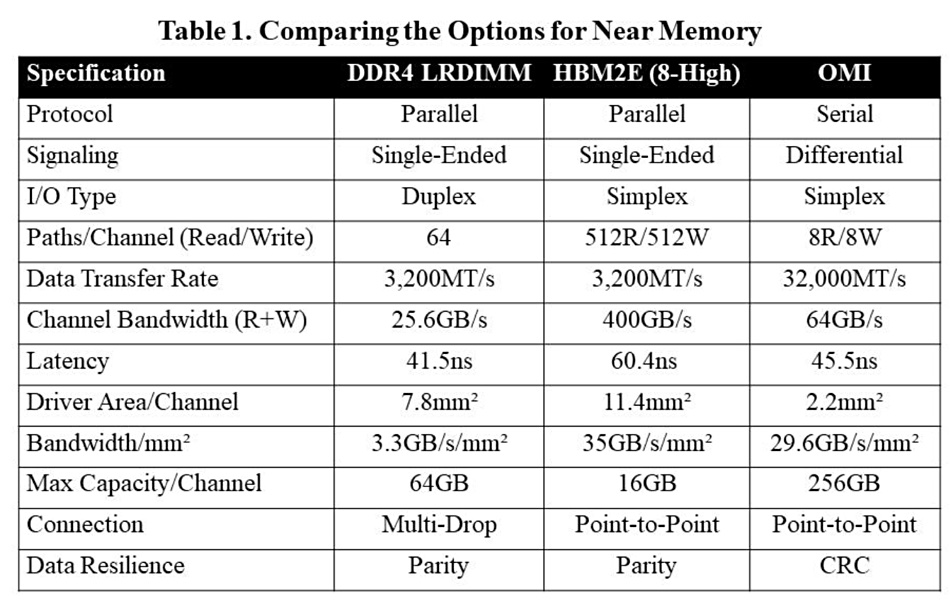
The authors compare and contrast three different CPU-memory interfaces in terms of the die area they consume and bandwidth they deliver, looking at AMD’s EPYC processor with DDR4 DRAM, Nvidia’s Ampere GPU with HBM2E, and IBM POWER10 with OMI. They tabulate their findings and conclude OMI offers the most bandwidth per square millimetre of die area and the highest capacity per channel:
They write: “Each HBM2E channel can support only a single stack of up to 12 chips, or 24GB of capacity using today’s highest-density DRAMs, while each DDR4 bus can go up to 64GB and an OMI channel can support 256GB, over 10 times as much as HBM.”
You can fit “a very large number of OMI ports to a processor chip at a small expense in processor die area.” they write. They add: “OMI does requires a DRAM die to have a transceiver, such as a Microchip Smart Memory Controller, but this is small (30 square millimetres) and doesn’t add much cost to the DRAM.”
They conclude that “OMI stands a good chance of finding adoption in those systems that require high bandwidth, low latencies and large capacity memories. “
However, “DDR should remain in good favour for widespread use at computing’s low end where only one or two DDR memory channels are required. HBM will see growing adoption, but will continue to remain an expensive niche technology for high-end computing.”
Dell EMC has launched a faster all-flash PowerScale system with 65 per cent more NVMe capacity per node. It has added a general speed boost with an OS upgrade, and claims to have made PowerScale quicker in the Google cloud as well.
The scale-out filer PowerScale product line, previously branded Isilon, has all-flash, hybrid and archive nodes. Its OneFS operating system provides inline compression and deduplication. We understand it supports mixed system clusters of up to 252 nodes.
Dell EMC’s John Shirley, VP of Product Management, Unstructured Data Solutions, called the F900 a “workhorse” for “modern high performance data lakes.” He added that users could “add in new F900 nodes or replace old nodes with new PowerScale nodes.” These have “compatibility with existing Isilon clusters, thanks to the PowerScale OneFS operating system.”
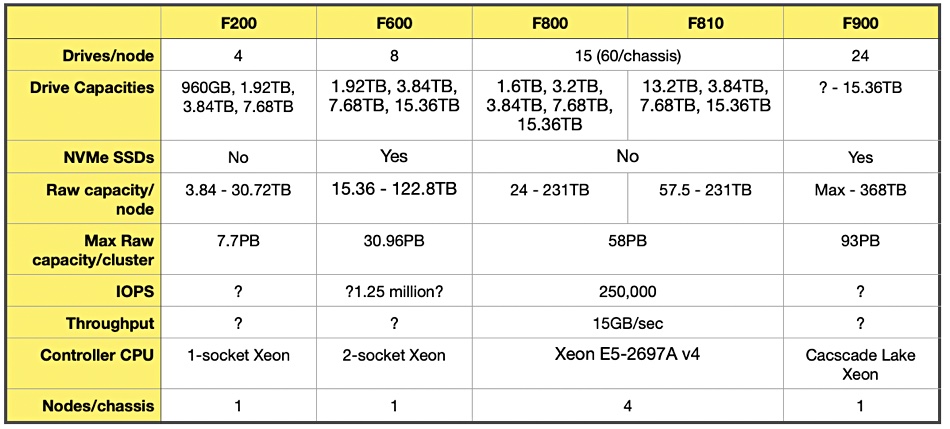
The F900 uses a 24-slot, 2U chassis, which has a 368TB maximum raw capacity using 15.36TB SSDs. It is controlled by dual-socket Cascade Lake generation Xeon processors. It supports Nvidia’s GPUDirect server CPU-bypass IO technology to feed data faster to GPUs.
F900 front showing the 24 drive bays behind the bezel
The existing F800 and F810 have more capacity in their 4U chassis, at 924TB, than the F900. However, there are four nodes in the F800/810 chassis, meaning 231TB/node. That is why the F800 and F810 maximum raw cluster capacity is 58PB while the new F900 goes up to 93PB, 60 per cent more.
We tabulated the different F-series PowerScale systems, although there is missing performance information for some:
Dell competitor Qumulo has a P368T all-flash filer also using a 2U by 24-slot chassis, also with 368TB of raw capacity. It uses 2 x Intel Gold 6126 CPUs rated at 2.6GHz, with 12 cores. Potentially the F900’s Cascade Lake processors may be faster but your mileage may vary.
OneFS
Dell EMC has also upgraded the PowerScale OneFS OS to v9.2, increasing performance for the F200 and F600 systems. Shirley claims it “speeds up PowerScale F200 (edge/entry nodes ) by 25 per cent and F600 (all-NVMe compact performance nodes) systems by 70 per cent for sequential reads.” Since we don’t know the starting numbers for these increases, we can’t speculate about what that means in deliverable performance terms.
V9.2 OneFS has remote direct memory access (RDMA) support for applications. Shirley said users with network file systems (NFS) benefit from accelerated GPU-powered applications, significantly higher throughput performance and low latency communication, especially for single connection and read intensive workloads.
PowerScale for Google Cloud is now available with all-flash Tier 1 Agile configurations. Shirley said these deployment options “offer a lower entry point with reduced minimum capacities and shorter commitment terms.”
We will be interested to see how PowerScale systems using GPUDirect compare to DDN, Pavilion Data, VAST Data and WekaIO systems in throughput terms.
Interview: MemVerge co-founder and CEO Charles Fan believes we are transitioning to an era of very big, petabyte-level CXL-connected memory pools. CPUs, GPUs and other accelerators will access vast in-memory datasets, minimising data movement and speeding computation.
MemVerge provides Memory Machine software, an abstraction layer that pools DRAM and Storage-Class Memory such as Optane to enable applications to run completely in memory and avoid most storage IO. Fan thinks hugely larger memory pools are coming and briefed Blocks & Files on his views last month.
He said the main driver for very big memory pool concept is the memory-CPU bottleneck. The restriction on CPU-memory socket count and resultant memory capacity limitations per CPU is what causes this. There is a follow-on problem in that, when data is processed, it has to be sent to the GPU – as with GPUDirect. If CPUs and GPUs could share a memory pool, then the data could stay in place with no time wasted in sending it to the GPUs and then returning it.
Such big memory pooling is made possible by the Compute Express Link, a bus based on the PCIe Gen 5 standard. Fan said of this: ”The Availability of CXL will be an inflexion point and bring in the era of big memory.”
He picked up on something Intel director of Technology Initiatives Jim Pappas said at the April SNIA Persistent Memory and Storage Summit. According to Fan, Pappas said Optane (3D XPoint storage-class memory) and CXL are a match made in heaven. Over the next two to three years, Intel will add a CXL interconnect to Optane. This thus making its capacity accessible to any processing resource with a CXL link – non-Intel X86, Arm, FPGAs and GPUs for example.
Fan said: “In 2 – 3 years we’ll see two to three CXL-interfaced SCM (Storage-Class Memory) products made at higher capacity and lower cost than DRAM.”
He cited Resistive RAM (RERAM) as a potential technology for this.
Big name vendors
Who is making them? Fan said: “We’re under NDA and they have not publicly announced anything. They are major established players of Intel and Micron class.”
This is hinting at Samsung, SK Hynix and maybe Kioxia/Western Digital. Whoever they are, MemVerge plans to support their CXL-connected technology out of the gate.
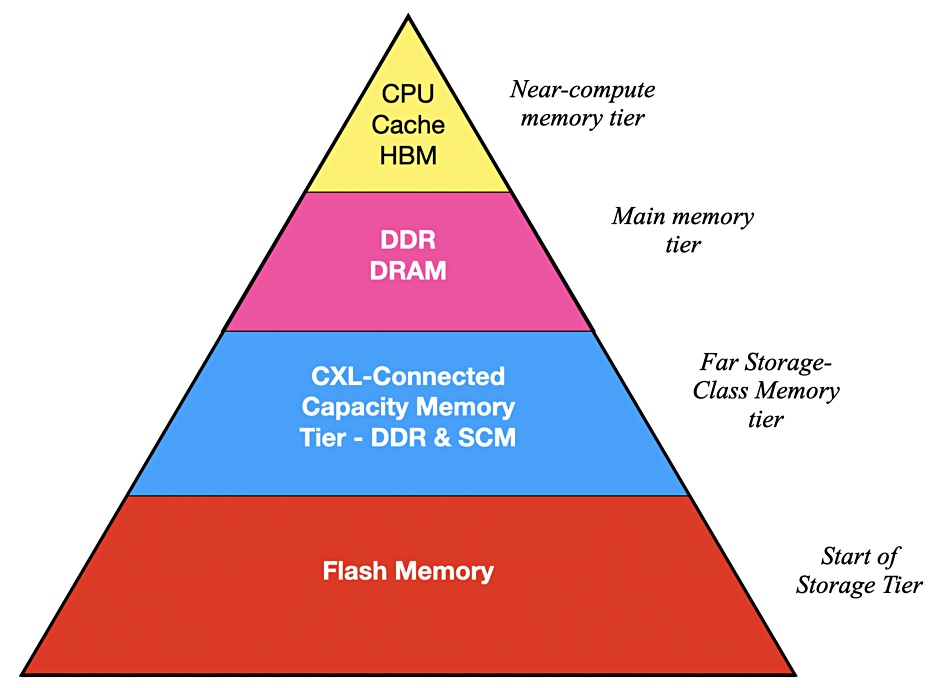
Fan said he thinks memory technology will diverge into three classes: near-CPU memory, main memory, and far memory:
Another way of looking at the top three layers in this hierarchy is by connect technology:
3-layer memory scheme
In Fan’s view near-memory will use HBM with its fast and high-bandwidth interposer link to the CPU. DDR socket links will be too slow for this role. He says increased core counts in CPUs will need increased CPU-memory bandwidth and HBM is a good fit: “HBM will turn into a caching layer.”
He also says DDR DRAM memory channels have 300 pins in their connectors. This results in very complicated wiring on the motherboard: “Moving to a serial [CXL] bus gives you the same bandwidth but at 80 pins per channel.” That makes connections simpler.
The CXL bus enables interconnects between servers. The existing DDR memory channel does not. This could: “allow many petabytes of memory pooling – really big memory. … The compute-to-memory Von Neumann bottleneck gets fixed.”
It also fixes the memory-to-storage bottleneck as you: “keep most of the data in memory rather than in the storage layer. It doesn’t need to move. Really big memory will fundamentally change things over the next three to five years.”
Main memory will be DDR4 and DDR5 socket-linked memory. Far memory will be CXL-connected SCM predominantly with some DRAM. His reasoning? CXL, with its few hundred microsecs latency, is too slow for DDR DRAM but OK for SCM. He sees servers accessing 100TB or more of CXL memory in two to three years time.
CXL is already here
Samsung has just demonstrated a CXL-connected DDR5 memory module that could provide up to a terabyte of capacity. The module has memory mapping, interface converting and error management technologies to enable CPUs and GPUs to use this CXL memory module as main memory.
Samsung CXL-connected DDR5 memory module
Naturally there needs to be a software layer between applications and the three memory tiers. Software will compensate for the DRAM and CXL memory access speed differences and also use the non-volatile nature of CXL-connected SCM to protect data. This could use snapshotting (aka checkpointing) of DRAM contents to SCM, with periodic writes to storage for longer-term protection. That would enable fast rollbacks from SCM to previous points in time if there were problems.
This software layer will enable existing applications, whether they are bare-metal, virtualised or containerised, to run in a server combined DDR DRAM + CXL memory environment.
Fan sees MemVerge’s Memory Machine software as being such a layer. The idea is it would enable applications to deal with DRAM main memory and CXL far memory as a single resource. He told us data services, such as snapshotting, will be offered for CXL memory pools. Another could be metro-distance disaster recovery between two very big memory installations. This would use an asynchronous background replication process to move snapshot data to the second system.
A third option would be to move the snapshot data to a storage system or S3 bucket: “You could then retrieve state and relaunch the app anywhere. It’s instance management with state. [Data] movement, which might take 15 minutes, happens in the background and doesn’t impact the primary system.”
He said: “We capture the entire app state and not just the data state. It’s a snap-mirror-like process,” with layers of snapshots, up to 256 today for example.
Comment
MemVerge is flying the flag for its own technology of course, but what FAN says about the need for an abstraction layer is interesting. Presenting disjoint memory/SCM pools as a single, logical memory resource makes sense. If what he says about major semi-conductor memory/SCM players developing their own SCM products for the 2023/2024 period and CXL-connected Optane comes to pass, our current server-based app environment is going to change substantially.