

Apache Spark – an open-source, distributed computing framework intended for fast, large-scale data processing and analytics. It’s used for big data workloads involving batch processing, real-time streaming, machine learning, and SQL queries.
Nyriad releases SAN arrays with CPU+GPU controllers

Newcomer Nyriad has launched two SAN array systems with combined CPU+GPU controllers to provide fast recovery from drive failures and a maximum sustained IO rate of 18GB/sec for writes and reads.
The company uses 18TB disk drives with erasure coding and the IO workload is spread across all the drives to achieve the high IO rate. Nyriad says the arrays are good for data-intensive use cases such as HPC, media and entertainment, and backup and archive. Users will get consistent high performance without the long rebuild times and associated performance degradation that are common with today’s RAID-based storage systems, it says.
Nyriad CEO Derek Dicker said: “RAID has been the de facto standard for storage for more than three decades, but the demands of today’s data-intensive applications now far exceed its capabilities. With the UltraIO system, Nyriad built a new foundation for storage that addresses current problems and creates new opportunities for the future – without requiring organizations to make disruptive changes to their storage infrastructure.”
There are two H series systems, both with dual active-passive controllers, the H1000 and H2000, with 99.999 per cent data availability. They both use dual Intel Xeon CPUs in each of their two controllers (head nodes) and Nyriad plans to move to a single-processor design in both head nodes. On the GPU front they use dual Nvidia RTX A6000 GPUs in each of their two head nodes, again with a plan to move to a single GPU in each node.
The dual controllers feature dual HBAs, which are attached to drive enclosures via SAS4 cabling. The H1000 supports up to 102 disk drives and the H2000 supports up to 204 disk drives. The detailed specs are below:
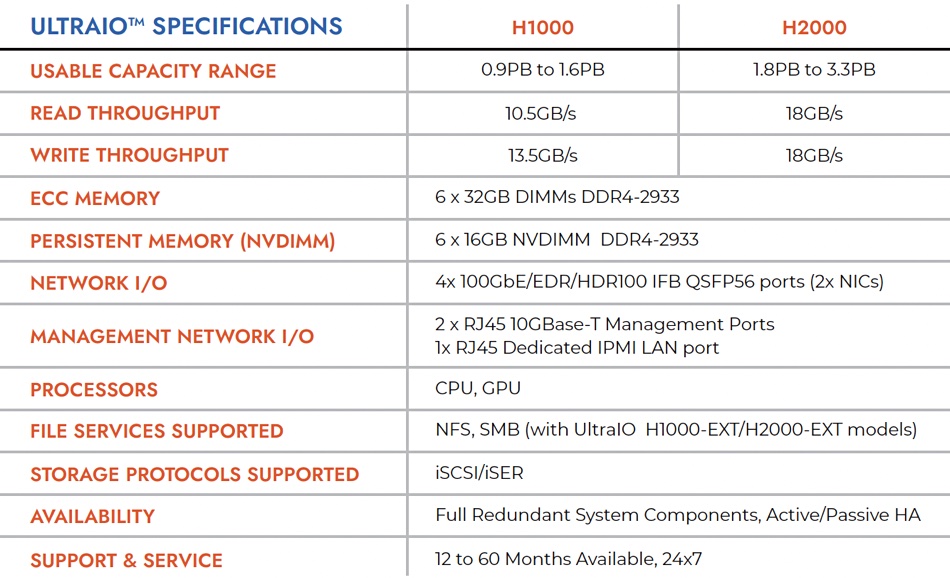
The H Series are classified as block storage systems and customers can non-disruptively connect UltraIO as a POSIX Compliant Block Target into their existing infrastructure. File and object protocol support will be added in the future – the table above mentions SMB support with H1000-EXT and H2000-EXT models.
Customers can specify a number of parity drives, up to 20. An example was given of an H2000 system with 200 18TB drives configured at 20 parity. It can continuously write at 18GB/sec and also continuously read at 18GB/sec. If 20 of the 200 drives were to fail concurrently, it would continue to operate with just 5 per cent performance degradation.
When a drive fails, the system’s performance doesn’t decline noticeably and the failed drive doesn’t need urgent replacing, according to the company. Nyriad says the UltraIO OS utilizes all the drives for all the work all the time with intelligent data block placement mechanisms and use of a large persistent cache. It can utilize the entire drive array to provide write operations concurrently, placing data to optimize both writing and subsequent concurrent reading performance. It also does write deduplication when high-frequency block updates take place.
In general, though, the UltraIO systems do not do data reduction. A Nyriad spokesperson told us: “Our initial target market segments are HPC, media and entertainment, and backup, restore, and archive. These segments seem to value absolute performance first. In addition, their data tends not to benefit from data reduction techniques. If we discover that there is a demand for these techniques, the computational power we have will allow us to address it.”
The OS stores an erasure coding integrity hash with every block written. It then integrity checks each block as it is read and ensures it is correct. If not, it recreates it. We think that GPU processing power is used to do the hashing and integrity checks, which would overburden a dual-x86 controller design.
H Series systems can scale up within configuration limits and then scale out by adding more H Series arrays. Nyriad said the UltraIO system is designed to support multiple media types, including SSDs. It will make decisions about which media types it will support, and when, based on market demands.
There is an administration GUI, a RESTFul API, and a Secure Shell for operating storage and other services securely over a network.
Check out the H Series datasheet here. The system is sold exclusively through Nyriad’s channel and you can contact Nyriad to find out more.
StorONE
Nyriad competitor StorONE does fast RAID rebuilds. Its vRAID protection feature uses erasure coding and has data and parity metadata striped across drives. Its S1 software uses multiple disks for reading and writing data in parallel, and writes sequentially to the target drives. In a 48-drive system, if a drive fails, vRAID reads data from the surviving 47 drives simultaneously, calculating parity and then writing simultaneously to those remaining 47 drives. A failed 14TB disk was rebuilt in 1 hour and 45 minutes, and failed SSDs are rebuilt in single-digit minutes.
VAST Data launches Ceres storage drive enclosure

VAST Data has announced its next-generation Ceres storage drive enclosure using long ruler format drives and Nvidia BlueField-1 DPUs to deliver 50 percent more bandwidth. It is developing a turnkey AI system with Nvidia’s DGX SuperPod hooked up to Ceres.
Nvidia BlueField DPUs (Data Processing Units or SmartNICs) are programmable co-processors that run non-application tasks from a host application server CPU or replace storage controllers and NICs in an array, as they do in the VAST Ceres instance. E1.L long format ruler drives are an example of EDSFF (Enterprise and Datacenter SSD Form Factor), which is set to replace the M.2 and U.2 formats with higher-capacity drives supporting better thermal management in denser enclosures.
VAST CMO Jeff Denworth said: “While explosive data growth continues to overwhelm organizations who are increasingly challenged to find value in vast reserves of data, Ceres enables customers to realize a future of at-scale AI and analytics on all of their data as they build to SuperPOD scale and beyond.”
The aim is to enable faster processing of huge datasets while saving power as the DPUs use less than existing IO modules. The long ruler format opens the door to higher capacity enclosures in the future, possibly double or even more than what is initially available with Ceres.
VAST’s hardware architecture relies on front-end stateless IO servers (Cnodes) communicating with requesting application servers using NFS or S3 protocols. These IO servers link to NMVe drives in back-end data enclosures across an NVMe-oF link. The current VAST data enclosure has two active-active IO modules, each with two Intel CPUs, in a 2RU chassis holding 44 x 15.36TB or 30.72TB U.2 format Intel SSDs, totaling 675TB or 1,350TB of raw capacity. These drives use QLC (4 bits/cell) NAND. The chassis also contains 12 x 1.5TB Optane or other storage-class memory (SCM) drives for caching and consolidating write data before striping it across the SSDs. The data enclosure delivers up to 40GB/sec of bandwidth across 4 x 100GbitE or 4 x EDR (100Gbit) IB connections.
Ceres
Ceres is half the size of the existing data chassis, being 1RU in thickness, and contains up to 22 x E1.L 9.5mm drives in the same 15.36 or 30.72TB capacities, again using QLC NAND, totaling 675.84TB of maximum raw capacity. The starting capacity is 338TB. We understand these are Solidigm D5-P5316 drives using 144-layer 3D NAND with a PCIe Gen 4.0 interface. VAST says its data reduction algorithms can provide an effective 2PB of capacity per Ceres box.

There are four ARM-powered BlueField-1 BF1600 DPUs, which replace the two existing Intel-driven IO modules and provide more than 60GB/sec of network capacity. VAST tells us: “There’s some VAST code for authentication and connection setup running on the Bluefield ARM cores but it’s limited.”
Also: “Under normal conditions each Bluefield connects 1/4th of the Ceres SSDs (both SCM and QLC) to the fabric in a 4 way active-active config.” Each BF1600 has PCIe gen 4 x 16 connectivity.
VAST will eventually move to using BlueField-3 DPUs.
The number of U.2 format SCM drives is reduced from 12 in the 2U chassis to 8 in Ceres, with a total 6.4TB of SCM capacity. These are 800GB Kioxia FL6 drives.
VAST says that ruler-based flash drives will over time pack more flash capacity compared to traditional U.2 format NVMe drives because they have a much larger surface area. Solidigm is also developing penta-level cell (PLC) drives with 5 bits/cell capacity, providing for a 25 percent capacity boost over QLC drives.
Ceres data enclosures can scale out to hundreds of petabytes and be mixed and matched with VAST’s existing data enclosures in its Universal Storage clusters. The Ceres chassis are fully front and rear serviceable, and VAST’s system supports full enclosure failover. Ceres will be built by VAST design partners such as AIC and Mercury Computer.
Nvidia and AI
VAST and Nvidia are working to make Ceres a data platform foundation for a turnkey AI datacenter with Nvidia’s DGX SuperPOD. Ceres is in the process of being certified for the GPU server. The DGX system itself has BlueField client-side DPUs. VAST and Nvidia are collaborating on new storage services to enable zero-trust security and offload functionality by using these client-side DPUs with Ceres.

VAST Data Universal Storage certification for DGX SuperPOD is slated for availability by mid-2022. The company says that, to date, it has received software orders to support over 170PBs of data capacity to be deployed on Ceres platforms.
HPE adds block storage to GreenLake

HPE is adding block storage to its GreenLake cloud-style IT subscription service along with backup and recovery, an existing parallel file system in a new GreenLake for High Performance Computing service, and supplying GreenLake through Digital Realty’s worldwide colocation sites.
Update: HPE added details about underlying Block Storage hardware and the backup and Recovery Service. 23 March 2022.
GreenLake is HPE’s branded services and subscription business model – hardware and software products supplied as public cloud-style services in on-premises and hybrid cloud data centres, colocation centres, remote offices, and other edge locations. HPE is bringing its Aruba networking products into GreenLake and making GreenLake available in the online marketplaces of ALSO Group, Arrow Electronics, Ingram Micro, and TD Synnex to reach over 100,000 partners. Getting partners to sign up has been a chore.
Antonio Neri, HPE president and CEO, said: “In the hybrid cloud market, HPE GreenLake is unique in its simplicity, unification, depth of cloud services, and partner network. Today, we are furthering our differentiation, boldly setting HPE GreenLake even further apart as the ideal platform for customers to drive data-first modernization.”
GreenLake for Block Storage features self-service provisioning and comes with a 100 percent data availability guarantee. HPE claims it is the industry’s first block-storage-as-a-service product with self-service provisioning on a cloud operational mode with such a guarantee. As is usual with such service announcements, the company did not explicitly say which of its storage array products were used to provide the service but it did say that IT resources are freed to work on strategic, higher-value initiatives with 98 percent operational time savings using intent-based provisioning.
This percentage saving is based on a comparison of infrastructure lifecycle management of HPE’s Alletra arrays by ESG Market Research in April 2021. That implies the GreenLake Block Storage is based on Alletra arrays and is not available as software running in public clouds. We have asked if this is actually the case and if both the Alletra 9000 and 6000 arrays are included.
An HPE spokesperson told us: “When customers provision HPE GreenLake for Block Storage, the underlying hardware is determined based on the SLA and specific customer requirements. HPE GreenLake for Block Storage abstracts the underlying infrastructure for the customer who now only needs to select their desired outcome- SLA, performance, capacity, term, and HPE delivers these outcomes through the period of the contract by matching the best suited backend storage array. In the backend, the Mission Critical tier is delivered through HPE Alletra 9000 and the Business Critical tier is delivered through HPE Alletra 6000.”
There is no public cloud or software-only version of GreenLake for Block Storage.
IBM offers a block storage service with flash drive speed and various performance level pricing tiers.
Pure Storage has a Pure-as-a-Service offering, a single pay-per-use subscription supporting block, file, and object storage both on-premises and in the public cloud. It is actually based on Pure’s Cloud Block Store running in AWS and Azure, and on-premises FlashArray (block) and FlashBlade (file + object) elements. The service comes with the Pure1 management facility for managing this hybrid-cloud environment from a single dashboard.
Zadara also has a block storage service with its managed virtual private arrays. Neither Zadara, Pure nor IBM offer a 100 percent data availability guarantee.
However, Hitachi Vantara’s VSP E990 does and also has its EverFlex consumption-based options ranging from basic utility pricing through custom outcome-based services to storage-as-a-service. It also has a self-service feature. That makes it a fairly close competitor to GreenLake Block Storage.
Dell’s APEX project includes Storage-as-a-Service and is a work in progress. It includes Multi-Cloud Data Services delivering storage and data protection as-a-service and inside this is Project Alpine, which offers Dell’s block and file storage software on the main public cloud. There is no 100 percent Dell availability guarantee. Dell also has APEX Backup Services for SaaS applications, endpoints, and hybrid workloads in the public cloud.
The HPE Backup and Recovery Service is a backup-as-a-service offering for hybrid cloud use, protecting virtual machines deployed on heterogeneous infrastructure. Backups are stored on-premises for rapid recovery and in the cloud for long-term retention. The Backup and Recovery Service is getting immutable data copies both on-premises and in AWS to aid ransomware attack recovery.
We asked if this Backup and Recovery Service was based on Zerto. The spokesperson said: “HPE Backup and Recovery Service is separate from Zerto. This service is focused on data backup and recovery, while Zerto offer application level disaster recovery and cloud mobility.
“HPE Backup and Recovery Service enables users to protect VMware workloads with the simplicity and flexibility of the software delivered as a service. Policy-based orchestration and automation lets users set up the protection of their virtual machines (VMs) in a few simple steps, in less than 5 minutes. Managed through the single cloud native console, it automatically retains local snapshots for instant data restores, performs local on-premises backups for rapid data recovery, and utilizes cloud backups for cost-effective, long term data retention.
GreenLake for High Performance Computing (HPC) includes HPE Parallel File System Storage, which is actually IBM’s Spectrum Scale Erasure Code Edition running on HPE’s Apollo and ProLiant DL servers with InfiniBand HDR/Ethernet 100/200 Gbit/s adapters. The Spectrum Scale licensing is included in the product. It ships as a fully integrated system from HPE’s factory with support from HPE’s PointNext operation. The system is meant for use in general HPC environments, artificial intelligence, and high-end data analytics.
Arcserve StorageCraft platform woes continue

The Arcserve StorageCraft data protection platform is going through an extended episode of “cloud degradation” with no end in sight.
According to Arcserve’s status page, since March 12, StorageCraft Cloud Services (DRaaS) in Australia; Ireland; and Utah, US have been unavailable. The page isn’t entirely clear but the outage may go as far back as March 9. Meanwhile, one part of the status page shows DRaaS has suffered degradation in Canada since roughly March 7.
Yes, DRaaS, as in, disaster recovery as a service. This means cloud backups stored by Arcserve may be unavailable.
The latest explanation to customers reads: “Our engineers continue to actively work on the resolution for this issue. If you have questions or concerns, please refer to the email that was sent to all affected customers. ShadowXafe customers were sent a separate email with specific instructions. Please refer to that email for more details.”
A Redditor going by the handle dartdou claims to have been a customer and said they got a call from a StorageCraft representative saying their “cloud data is permanently lost.”
The netizen went on to quote an email they claim they received from Arcserve: “During a recent planned maintenance window, a redundant array of servers containing critical metadata was decommissioned prematurely. As a result, some metadata was compromised, and critical links between the storage environment and our DRaaS cloud (Cloud Services) were disconnected.
“Engineers could not re-establish the required links between the metadata and the storage system, rendering the data unusable. This means partners cannot replicate or failover machines in our datacenter.”
The Redditor continued that they had a conversation with an Arcserve representative, who, it is claimed, said the business had hoped to recover the data but stopped when it became clear that would not be possible. The netizen also said there was no offer of compensation; instead, customers must ask to be put on a list to be considered for a rebate, it was claimed.
Private equity-owned Arcserve merged with StorageCraft in March last year. The intention was to create a single entity providing workload protection and supporting SaaS applications. Arcserve brought its UDP appliances that integrate backup, disaster recovery, and backend cloud storage to the table plus its partnership with Sophos for security, cloud, and SaaS offerings. The smaller StorageCraft has backup for Office365, G Suite, and other SaaS options as well as OneXafe, a converged, scale-out storage product. StorageCraft bought SMB object storage startup Exablox in January 2017.
We have asked Arcserve to comment on the outage and compensation options available to users. We’ll update this story if we receive a reply.
VergeIO – an HCI curiosity shop survivor

Verge.io’s technology creates nested, multi-tenant, virtual datacenters for enterprises and MSPs from hyperconverged infrastructure servers. Back in the HCI glory days before 2018, it was known as Yottabyte and lauded as a potential giant killer. Now this minnow survives as Verge.io, still fighting the software-defined datacenter (SDDC) fight but making less of a wave.

Yottabyte was founded in 2010 by VP of technology Greg Campbell, along with President and CEO Paul E Hodges III, and principal Duane Tursi, all based in Michigan. Campbell drove the vCenter software research and development to create an SDDC layer that sat atop commodity servers fitted out for compute, storage, and software-defined networking, formed them into resource pools, and composed them into an SDDC. The systems could scale out, with storage scaling up as well for archive capacity.
Around that time commentators became enthused about its prospects, not least Trevor Pott in The Register who talked about Infrastructure Endgame machines in 2015, saying: “The end of IT as we know it is upon us. Decades of hype, incremental evolution and bitter disappointment are about to come to an end as the provisioning of IT infrastructure is finally commoditised.”
Pott said of Yottabyte: “The result of years of this R&D is yCenter. It can be a public cloud, a private cloud or a hybrid cloud. Yottabyte has gone through and solved almost all the tough problems first – erasure coded storage, built-in layer 2 and 3 networking extensibility, management UI that doesn’t suck – and is only now thinking about solving the easy ones.”
Alas, HCI didn’t kill off conventional IT infrastructure and its proponents were bought by larger suppliers such as HPE, or crashed and burned. Just Dell, Nutanix, and VMware dominate the field these days, followed at some distance by HPE, Cisco and Scale Computing.
Yottabyte formed a partnership with the University of Michigan in late 2016 to build the Yottabyte Research Cloud for use by academic researchers.
A video talks about the university’s Advanced Computing Research Division using Yottabyte “to provide thousands of secure, compliant virtual data centers that house some of the world’s most advanced medical research data.”

The beauty of the SDDC software was that entire datacenters could be moved with button clicks from one platform to another, or cloned for another bunch of tenants or a department or an MSP customer.
Exec churn and name change

A period of exec churn ensued. Between 2017-2018, Yottabyte was renamed Verge.io with Campbell becoming CTO. Tursi changed from a principal to an advisor in February 2018 and quit that role in March 2019. Michael Aloe was SVP sales and operations from April 2017, becoming COO in 2018, but he’d left by October 2019. Matt Wenzler became CEO in January 2020 but exited September 2021, when Yan Ness took over. Kathy Fox became CFO in July last year and Chris Lehman SVP of sales in December 2021.
Verge.io does not have a history of VC funding. This means it has not had that fierce boardroom presence of investors driving it to refine its product and market positioning. And now the HCI market boom is over. The SDDC concept is dominated by VMware, also Nutanix, and is less x86 centric with GPU servers for AI and large-scale analytics, specific AI processor developments, and DPU/SmartNIC technology for composability.
Verge.io software
Against this background, Verge.io now has software that is clean and elegant and easy to use but possibly too capable, in its niche, and too restricted to be of widespread use.
The Verge.io software is a datacenter OS based on a QEMU/KVM hypervisor which can have Linux and Windows guests. This OS can create multiple virtual datacenters, with multi-tenancy, which can be nested, using compute, storage, and network servers from the resource pools. The storage is a vSAN (block) and a NAS (files) using blockchain technology. It is encrypted, supports global deduplication, and has built in snapshotting and recovery.
The storage software supports silent data corruption detection and recovery, multi-site synchronisation, and disaster recovery through site failover. It supports storage tiers for different workloads – NVMe SSDs, SAS and SATA SSDs, and hard disk drives. System management has ML and AI features, and it’s claimed a sysadmin generalist can manage Verge.io virtual datacenters.
The pitch is that “Verge.io is one single, powerful, thin piece of software that replaces many disparate vendors and orchestration challenges. It’s just one SKU, one bill, one dashboard, one API managed by generalist IT staff.” It has pay-per-use consumption billing.
Customers get much reduced capex, more operational efficiencies, and rapid scalability.
Datto looking for takeover or private equity sale

Datto could be going private again with equity investors understood to be circling the cloud backup and security supplier just 18 months after it listed on the NYSE, with its share price currently languishing below the IPO offer price.
The company sells its cloud services to small and medium businesses through more than 18,500 managed service providers (MSPs). Revenues, including subscription, have grown steadily and Datto has been profitable for all but two quarters since its IPO in October 2020.
Bloomberge reported that Datto has received a takeover approach and was examining strategic options.
William Blair financial analyst Jason Ader told subscribers: “Takeover interest from potential buyers only provides us with greater confidence that the company is positioned as one of the clear leaders in the MSP software space – which is being driven by accelerating secular tailwinds (e.g. shift to remote work, digital transformation, labor shortages).”
A look at Datto’s history shows that it was bought by Vista Equity Partners in October 2020 and that firm still holds 69 per cent of the shares. In calendar Q4 2020, Datto brought in $164.3m and made a $5.7m profit. It has a stated goal of reaching a $1bn run rate in 2024, up from its current $657m, and expects to grow 20 percent annually.
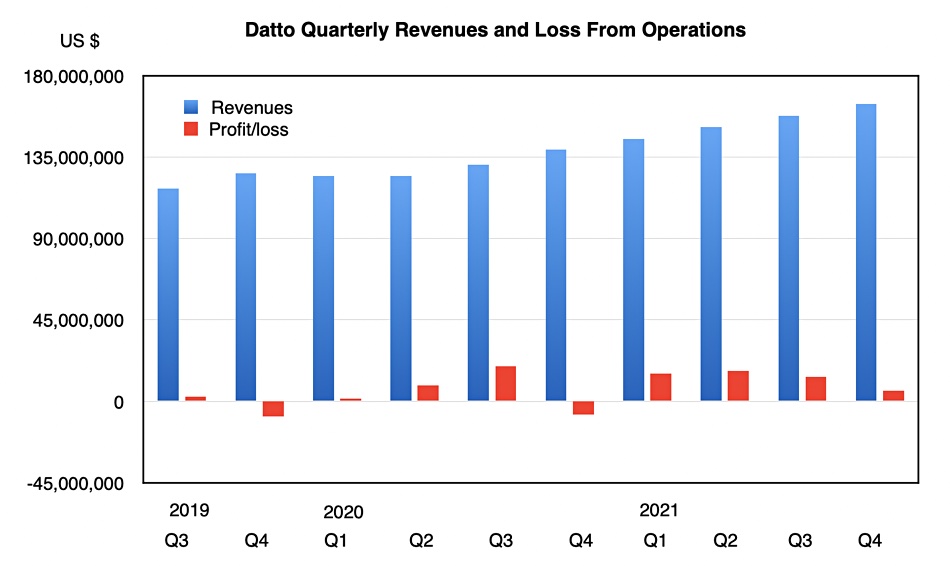
Despite this consistent revenue growth and its profitability, the stock market has not valued the company highly, as its share price history shows:
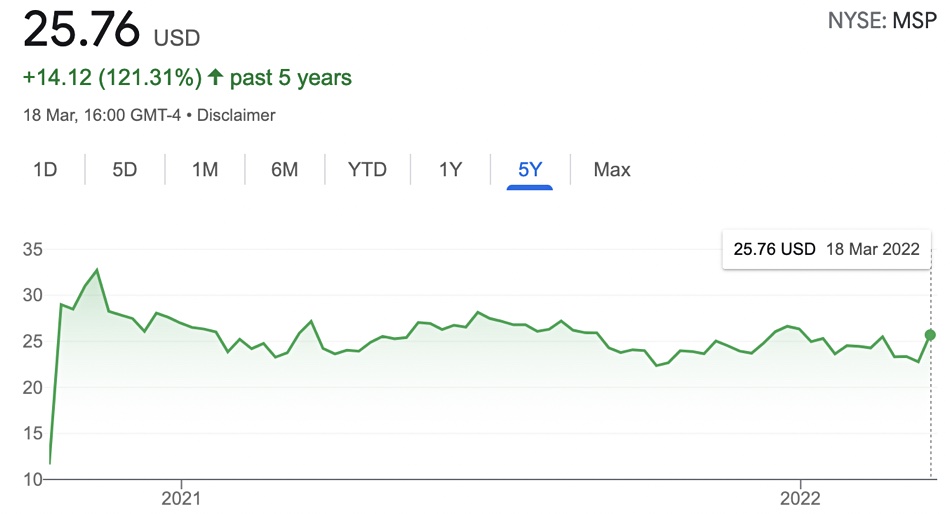
Datto’s competitors include ConnectWise, Kaseya, N-able, Barracuda, Acronis, and Veeam. Ader suggested that a risk for Datto is that the prolonged COVID-19 pandemic could restrict Datto’s SMB end customers, while another is that the MSP market could consolidate.
Ader reckoned: ”Ultimately, given our view that the MSP market is entering a golden age, we see scarcity value in the story as the top publicly traded, pure-play software vendor leveraged to MSP market trends.”
Datto has a wide, growing, and profitable cloud backup and security services MSP channel to SMB customers. A larger on-premises supplier could see an opportunity here to make a move into the cloud market and add its own services on top of Datto’s to grow its business. Hypothetically, Carlyle-owned Veritas could fit this notion.
Datto history
- 2007 – Started up
- 2013 – $25m A-round
- 2014 – Bought Backupify
- 2015 – $75m B-round
- 2017 – Bought Open Mesh
- Oct 2017 – Bought by Vista private equity and merged with Autotask
- 2020 – Bought Gluh and its real-time procurement platform
- Oct 2020 – IPO at $27.50/share
- March 2021 – Bought BitDam for cyber threat protection tech
- January 2022 – Bought cybersecurity supplier Infocyte
- 21 March 2022 – stock price $25.76 below IPO price
Datto has more than 1,600 employees.
SOCAMM
SOCAMM – Small Outline Compression Attached Memory Module. SOCAMMs provide over 2.5 times higher bandwidth at the same capacity when compared to RDIMMs, according to Micron. The SOCAMM form factor of 14x90mm occupies one-third of the size of the industry-standard RDIMM form factor. When using LPDDR5X memory, SOCAMM products consume one-third the power compared to standard DDR5 RDIMMs. SOCAMM implementations use four placements of 16-die stacks of LPDDR5X memory to enable a 128GB memory module.

We understand that SOCAMM is an AI server-specific memory and Nvidia is pushing for its standardization. Nvidia may use SOCAMM in its Grace Blackwell Ultra (GB300) GPU, which could increase demand markedly.
Facebook investigates silent data corruption

Facebook has flagged up the problem of silent data corruption by CPUs, which can cause application failures and undermine data management systems in its super dense datacenters.
An academic paper detailing the research says: “It is our observation that computations are not always accurate. In some cases, the CPU can perform computations incorrectly.” Unlike soft errors due to radiation or other interference, “silent data corruptions can occur due to device characteristics and are repeatable at scale. We observe that these failures are reproducible and not transient.”
Moreover, the researchers say: “CPU SDCs are evaluated to be a one in a million occurrence within fault injection studies.” Scale that up by the number of processors and computations Facebook’s infrastructure accommodates and the implications are obvious. The researchers state it “can result in data loss and can require months of debug engineering time.”
The researchers wrote: “It is our observation that increased density and wider datapaths increase the probability of silent errors. This is not limited to CPUs and is applicable to special function accelerators and other devices with wide datapaths.”
This can have effects at application level, including on Facebook’s data compression technology to reduce the footprint of its datastores, leading to the possibility of files being missed from databases, ultimately leading to application failure. “Eventually the querying infrastructure reports critical data loss after decompression,” said the researchers.
The answer is testing to uncover errors. But servers are tested for a few hours by the vendor then by an integrator for at best a couple of days. After they go into production, Facebook said “it becomes really challenging to implement testing at scale.”
Testing times
The giant’s answer is to combine two types of testing regimes. Opportunistic testing means piggy backing on other routine maintenance events such as reboots, kernel or firmware upgrades, or device reimages, host provisioning, and namespace reprovisioning. “We implement this mechanism using Fleetscanner, an internal facilitator tool for testing SDCs opportunistically,” said Facebook.
But this alone is not enough. Facebook also committed to ripple testing, essentially running SDC detection in conjunction with production workloads. “Ripple tests are typically in the order of hundreds of milliseconds within the fleet,” the researchers wrote. This results in “a footprint tax” but this is negligible in comparison with other management activities.
The result is faster time to detecting errors that “can have a cascading effect on applications… As a result, detecting these at scale as quickly as possible is an infrastructure priority toward enabling a safer, reliable fleet.”
Could Russia plug the cloud gap with abandoned Western tech?

What happens to a country when it runs out of cloud? We might just be about to find out as Russia has apparently realized it’ll be out of compute capacity in less than three months and is planning a grab for resources left by Western companies who have exited the country after Vladimir Putin’s invasion of Ukraine.
A report in Russian newspaper Kommersant says the Kremlin is “preparing for a shortage of computing power, which in the coming months may lead to problems in the operation of state information systems.” Initial translations of the report referred to a shortage of storage.
The Russian Ministry of Digital Transformation reportedly called in local operators earlier this month to discuss the possibility of buying up commercial capacity, scaling back gaming and streaming services, and taking control “of the IT resources of companies that have announced their withdrawal from the Russian Federation.”
Apparently, authorities are “conducting an inventory of datacenter computing equipment that ensures the uninterrupted operation of systems critical to the authorities.” The ministry told the paper it did not envisage critical shortages, but was looking at “mechanisms aimed at improving efficiency.”
The report cited rising public-sector demand for computing services of 20 percent. It added that one major impact is from the use of “smart cities” and surveillance systems. Apparently, its source “explains that due to the departure of foreign cloud services, which were also used by some departments, the demand for server capacities instantly increased.”
Meanwhile, the report continues, Russia’s datacenter operators are struggling, swept up in sanctions, economic turmoil and facing the challenge of sourcing kit when the ruble is collapsing. And they are effectively left with just one key supplier – China.
Russia stretched thin
It’s not like Russia was awash with datacenter and cloud capacity in the first place. According to Cloudscene, there are 170 datacenters, eight network fabrics, and 267 providers in Russia, which has a population of 144 million.
Neither AWS, Google nor Azure maintain datacenters in Russia, and while there may be some question as to what services they provide to existing customers, it seems unlikely they’ll be offering signups to the Russian authorities. AliBaba cloud doesn’t apparently have any datacenters in Russia either.
By comparison, the UK, with 68 million citizens, has 458 data centers, 27 network fabrics, and 906 service providers, while the US’s 333 million citizens enjoy 2,762 datacenters, 80 network fabrics, and 2,534 providers.
It’s also debatable how much raw tin there is available in the territory. In the fourth quarter, external storage systems shipped in Russia totaled $211.5m, up 34.2 percent. Volumes slipped 12.3 percent on the third quarter, while in the fourth quarter 50,199 servers were delivered, up 4.1 percent, though total value was up 28.8 percent at $530.29m.
Server sales were dominated by Dell and HP. Storage sales were dominated by Huawei at 39.5 percent, with Russian vendor YADRO on 14.5 percent, and Dell on 11.2 percent by value, though YADRO dominated on capacity.
Now, presumably, Dell and HP kit will not be available. Neither will kit from Fujitsu, Apple, Nokia or Ericsson, and cloud services from AWS, Google or Azure.
Could China step in?
Chinese brands might be an option, but they’ll still want to be paid, and the ruble doesn’t go very far these days. Chinese suppliers will have to weigh the prospect of doing business in Russia against the possibility of becoming persona non grata in far more lucrative markets like Europe, and perhaps more scarily being cut off from US-controlled components. Kommersant reported that Chinese suppliers have put deliveries on hold, in part because of sanctions.
So there are plenty of reasons for Russia to eke out its cloud compute and storage capacity. According to the Kommersant: “The idea was discussed at the meeting to take control of the server capacities of companies that announced their withdrawal from the Russian market.”
Could this fill the gap? One datacenter analyst told us that, in terms of feasibility, two to three months is doable as “what normally holds up delivery of services is permits and government red tape, construction. If they are taking over existing datacenter space with connectivity and everything in place, they could stand up services pretty fast.”
But it really depends on the nature of the infrastructure being left behind. This is not a question of annexing Western hyperscalers’ estates, given they are not operating there. Which presumably leaves corporate infrastructure as the most likely target.
Andrew Sinclair, head of product at UK service provider iomart, said co-opting dedicated capacity that’s already within a managed service provider or cloud provider might be fairly straightforward.
Things would be far more complicated when it came to “leveraging dedicated private cloud infrastructure that’s been aligned to these companies that are exiting. These are well-recognized Fortune 500 businesses we’ve seen exiting. These businesses have really competent IT leaders. They’re not just going to be leaving these assets in a state that people are going to be be able to pick them up and repurpose them.”
‘Extreme challenge’
From the Russian authorities’ point of view, “they would be going out and taking those servers, and then reintegrating them into some of these larger cloud service providers more than likely. Even from a security perspective, a supply chain perspective, from Russia’s perspective, would that be a sensible idea? I don’t know,” Sinclair added.
The exiting companies would presumably have focused on making sure their data was safe, he said, which would have meant eradicating all the data and zeroing all the SAN infrastructure.
“Following that, there’s a question about whether they just actually brick all the devices that are left, whether they do that themselves, or whether the vendors are supporting them to release patches to brick them.
“Connecting Fiber Channel storage arrays that have been left behind to a Fiber Channel network? Reasonable. But to be able to do that in two to three months, and to be able to validate that the infrastructures are free of security exploits, all the drives have been zeroed, and it’s all nice and safe? I think that’s an extreme challenge.”
But he added: “When you’re backed into a corner, and there’s not many choices available…”
Of course, it’s unwise to discount raw ingenuity, or the persuasive powers the Kremlin can bring to bear. It’s hard not to recall the story of how NASA spent a million dollars developing a pen that could write in space, while the Soviets opted to give its cosmonauts pencils. Except that this is largely a myth. The Fisher Space Pen was developed privately. And Russia used it too.
Tokens
Tokens – In the context of artificial intelligence (AI), particularly in natural language processing (NLP) tokens are an intermediate representation of words, images, audio and video between the origini=al item and vectors. A token is typically a unit of text—like a word, subword, or character—that an AI Large Language Model (LLM) processes. For example, in the sentence “I love AI,” the tokens might be “I,” “love,” and “AI.” These tokens start as raw text or symbols.
To work with tokens mathematically, AI models (like those based on transformers) convert them into vectors—numerical representations in a high-dimensional space. This conversion happens through a process called embedding. Each token is mapped to a vector using an embedding layer, which is trained to capture semantic meaning, context, or relationships between tokens. For instance, “love” might become something like [0.23, -1.54, 0.89, …], a list of numbers that encodes its meaning relative to other words.
Therefore:
- Tokens are the discrete units (e.g., words or subwords).
- Vectors are the numerical representations of those tokens after embedding.
In practice, when people talk about “tokens” in AI models, they often mean these vector representations implicitly, especially when discussing how the model processes input.
Note that a token is the smallest unit of text that the LLM processes at a time. It’s typically a word, part of a word, or a punctuation mark, depending on the tokenization method used by the model. Tokenization is the process of breaking down input text into these smaller units so the model can understand and generate text.
However, a chunk is a larger segment of text, typically consisting of multiple tokens, that is grouped together for processing or analysis. Chunking often happens when dealing with long documents or inputs that exceed the model’s token limit, requiring the text to be split into manageable pieces.
Snowflake unveils medical data cloud

Snowflake has lifted the sheets on a dedicated Healthcare and Life Sciences Data Cloud that it claims will fast track the exchange of critical and sensitive health data and speed research.
Few data types spark as much concern around privacy and confidentiality as health data, while health organizations, pharma and medical companies, and public bodies, are all desperate to get their hands on this information for research or planning.
Snowflake says its Healthcare and Life Sciences Data Cloud gives all these stakeholders a single, integrated cross cloud data platform, that will allow them to share and analyze data more productively, while ensuring compliance.
Todd Crosslin, global head of healthcare and life sciences at Snowflake, said one of the biggest challenges when it came to healthcare and life sciences is siloed data – both within and between organizations.
For example, a pharma organization might have teams working on sensitive clinical trial data who need to collaborate with colleagues across the world. Relying on traditional tools like FTP to copy data is unwieldy and problematic when live data is being constantly updated, but also starts raising compliance flags.
“We can really accelerate these things,” said Crosslin. “We know everyone bent over backwards for Operation Warp Speed here in the US and, and around the world for COVID vaccines, but they almost killed themselves doing that.”
Snowflake’s Healthcare and Life Sciences Data Cloud allows the data to be processed into a single set of tables, which researchers can then analyze or share with partners – subject to data residency and other regulations.
Life sciences research is covered by the GxP standards that cover sensitive industries like pharmaceuticals and food. “We cannot be GXP compliant,” said Crosslin. “We can only be compatible. And it’s the global pharma firm that has to say, we have done X, Y and Z, right on Snowflake to be compliant.”
Crosslin was at pains to say Snowflake’s platform wouldn’t replace the high-end storage systems used in, for example, gene sequencing or for AI work. “What we typically find is, then you take the results of that, and you put that back in Snowflake, right to analyze… we appreciate our cousins in different areas that use those types of super high performance storage solutions”