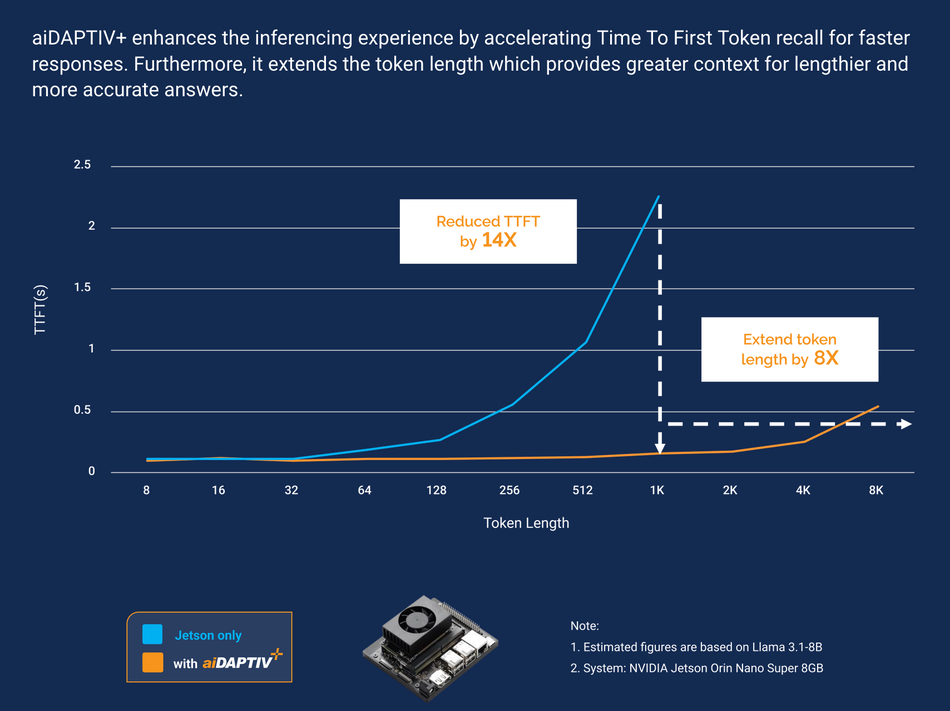
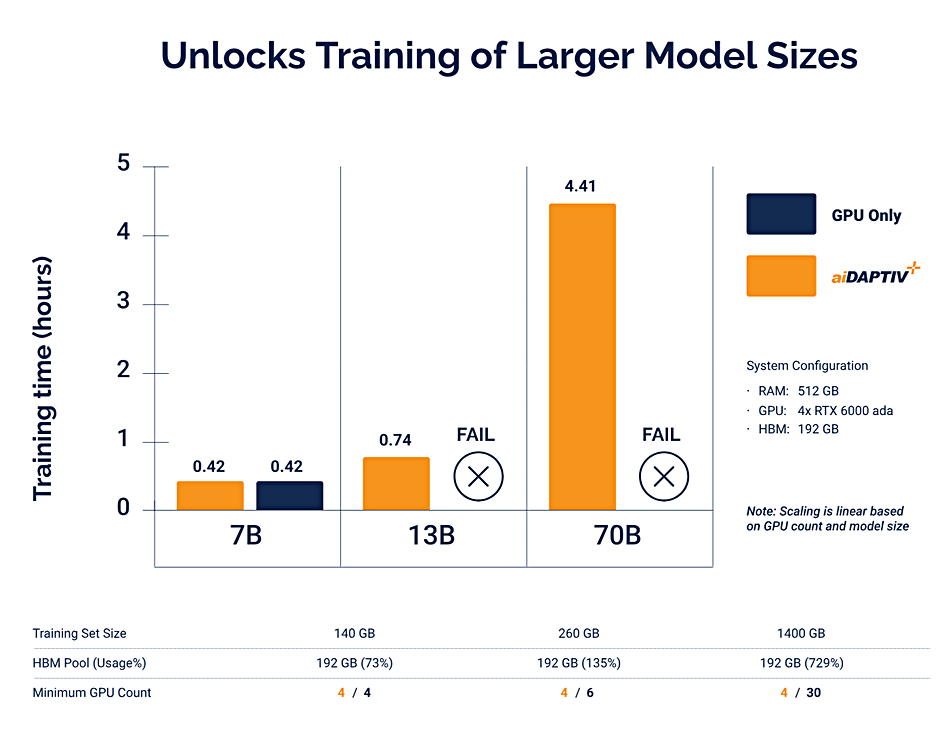
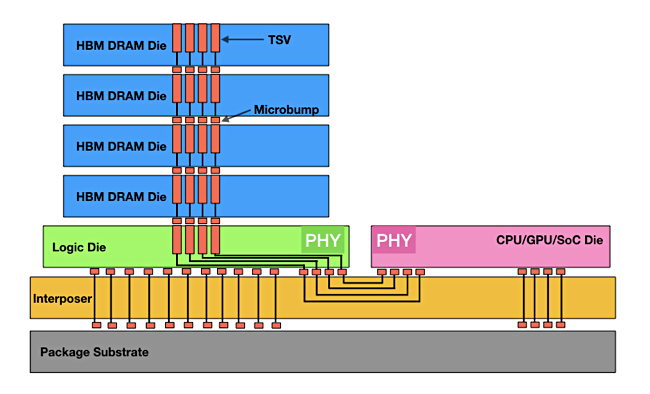
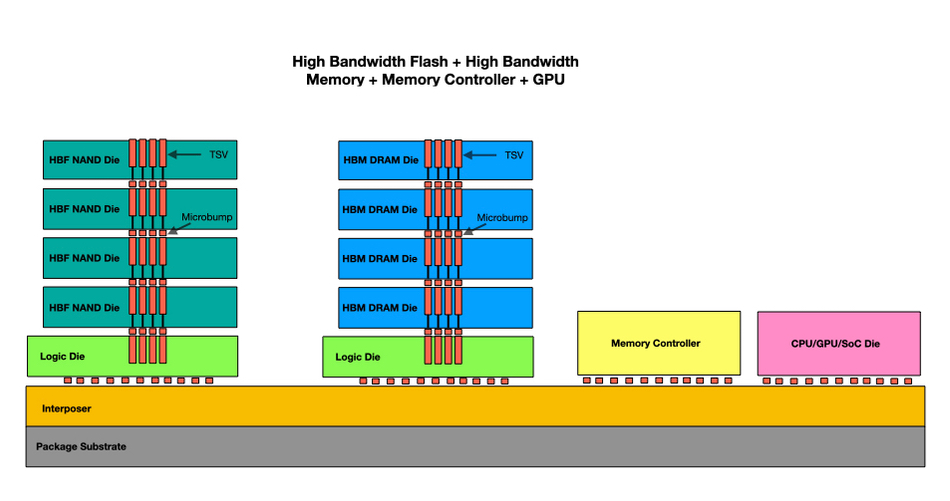
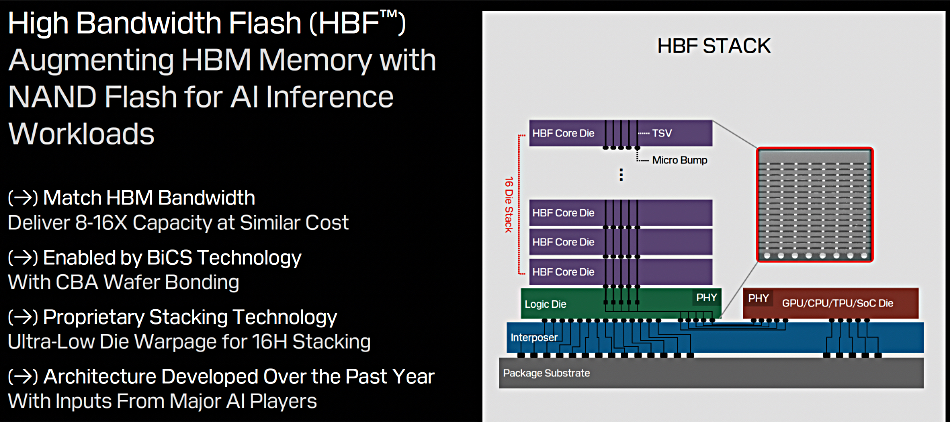
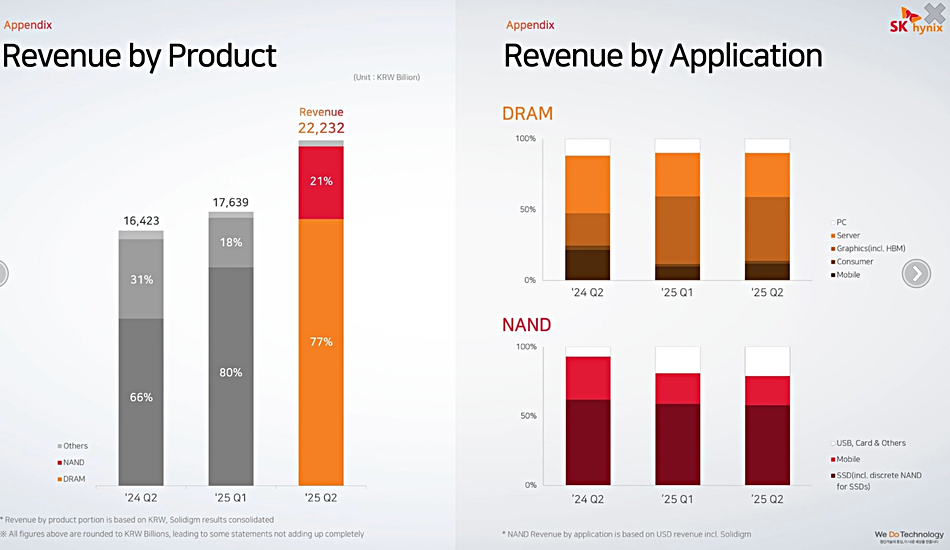
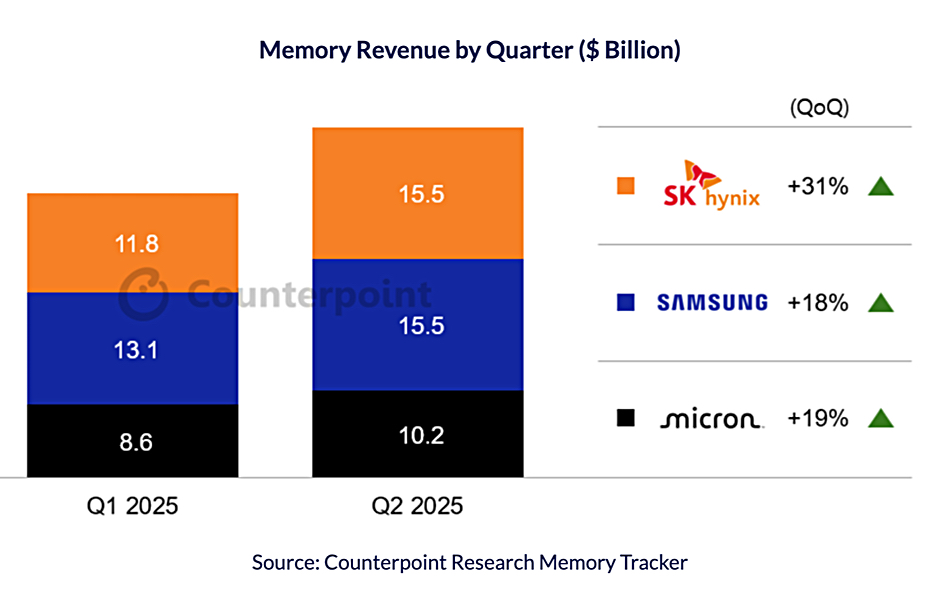
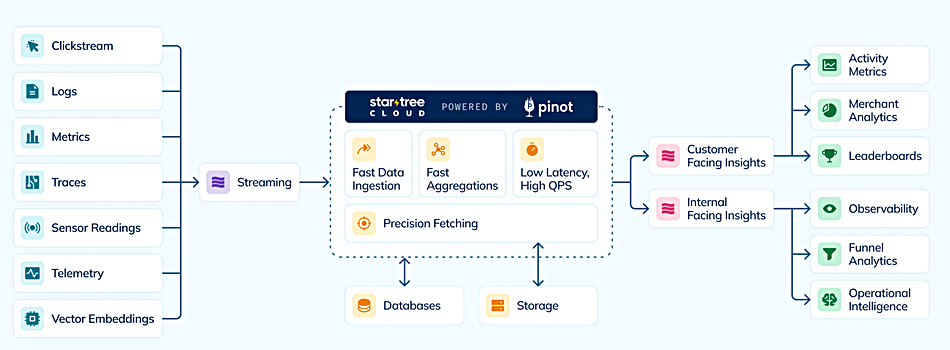
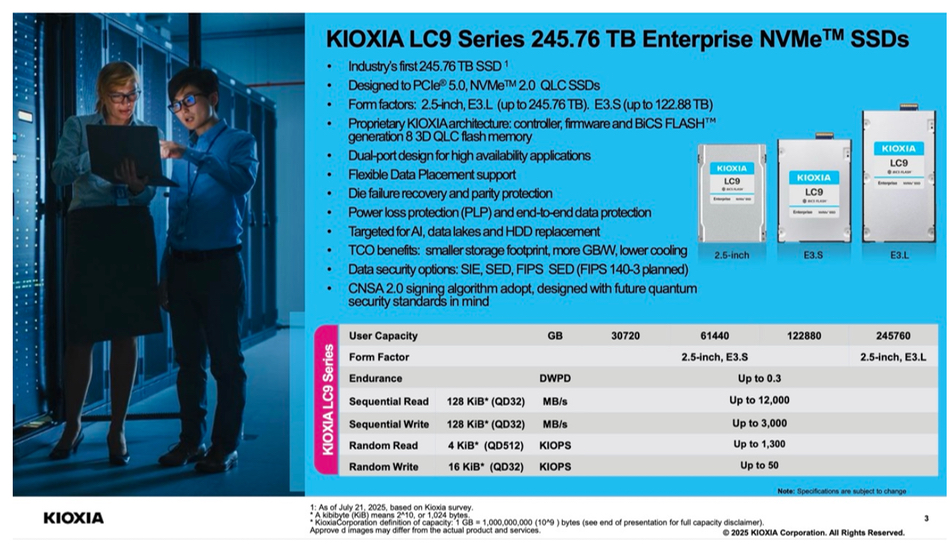
A 45Drives four-part video series, led by Chief Solutions Architect and Ceph Foundation board member Mitch Hall, documents the design, build, tuning, and real-world benchmarking of an all-NVMe Ceph cluster – powered by Stornado F16 servers. Early performance tuning results measured so far include:
- Single‑threaded sequential write: +53 percent (1.3 → 2.0 GBps)
- Single‑threaded sequential read: +183 percent (2.4 → 6.8 GBps)
- Four‑threaded sequential write: +50 percent (3.6 → 5.4 GBps)
- Four‑threaded sequential read: +113 percent (4.5 → 9.6 GBps)
- Single‑threaded random write: +98 percent (14.9 → 29.6 kIOPS)
- Single‑threaded random read: -38 percent (74.2 → 45.8 kIOPS)
A coming white paper from 45Drives will cover overall cluster specs and architecture, system‑level tuning, Ceph tuning, and which tunings map to which real‑world workloads. The first video is available now here. The others are coming.
…
Cyber-protector Acronis has named Metrofile Cloud as its premier Disaster Recovery (DR) partner in Southern Africa. Metrofile will integrate Acronis Cyber Protect Cloud into its product lines.
…
NoSQL database supplier Couchbase has announced research finding UK businesses are at serious financial risk from slow AI adoption, with over half of IT leaders estimating losses of as much as 5 percent of monthly revenue due to delays. While 79 percent of UK respondents believe AI offers a competitive edge over larger, slower-moving rivals, nearly a third (30 percent) fear the window for adoption has already closed, signalling growing anxiety about falling behind. UK businesses rank among the most pessimistic globally on this point, behind only India (35 percent) and the US (32 percent).
…
Cloud file services supplier Egnyte has achieved FedRAMP Moderate Equivalency status for engagements with U.S. DoD contractors and subcontractors, and is also listed on the FedRAMP Marketplace. This enables Egnyte to deliver EgnyteGov, its secure, AI-powered collaboration offering to U.S. federal agencies and government contractors.
…
ExaGrid software v7.3.0 updates include:
- Support of Rubrik backup software using the Rubrik Archive Tier or Rubrik Archive Tier with Instant Archive enabled
- Support of MongoDB Ops Manager
- Deduplication for encrypted Microsoft SQL Server direct dumps If encryption is enabled in the SQL application (TDE), then ExaGrid can achieve about a 4:1 data reduction with ExaGrid’s advanced Adaptive Data Deduplication technology. If a SQL database is not encrypted, ExaGrid will get between a 10:1 and 50:1 deduplication ratio
…
Cyber-threat exposure manager Flare has a commissioned Forrester Total Economic Impact (TEI) study that reveals:
- 321 percent three-year ROI – with an NPV of $699K, and payback in under six months
- 25 percent reduced risk of data breaches – avoiding $509K in costs
- 25 percent productivity gains – equal to $167K in labor savings
- 31 percent license fee reduction vs legacy solutions
The composite company under Forrester’s review generates US$10B in revenue, with 15K employees and 25 full-time employees in SecOps. The ROI analysis shows Flare not only accelerates threat response and reduces reputational risk, but also surfaces deeper intelligence on malware logs, data leaks, and supply-chain exposure.
…
HighPoint will debut the Rocket 7638D at FMS2025. It’s a multi-role PCIe Gen 5 x16 Add-In Card that consolidates external GPU connectivity and internal NVMe storage into a single low-profile MD2 adapter. The Rocket 7638D can support a full-height dual or triple-slot Gen5 x16 GPU in length while simultaneously hosting up to 16 enterprise grade NVMe SSDs, all from a single PCIe slot. The external CDFP port supports full-height, 2-slot/3-slot Gen5 GPUs (up to 370mm in length). Dual internal MCIO ports support up to 16 enterprise-grade NVMe SSDs via industry standard cabling. Read more here.
…
HighPoint has new RAID products:
- Rocket 7604A 4x M.2 PCIe Gen 5 x16 NVMe RAID AIC (FH, HL)
- Rocket 7608A 8x M.2 PCIe Gen 5 x16 NVMe RAID AIC (FH-FH)
- RocketStor 6541AW 4x U.2 PCIe Gen 4 x15 NVMe RAID Enclosure
- RocketStor 6542AW 8x U.2 PCIe Gen 4 x16 NVMe RAID Enclosure
It says its NVMe AICs can directly host up to 16 M.2 or E1.S SSDs, delivering up to 128TB of high-speed storage without the need for internal drive bays or cabling accessories. RocketStor 6500 series NVMe enclosures empower compact server and workstation platforms with up to nearly 1TB of enterprise grade U.2 storage via compact low-profile adapter that can be easily integrated into mini or tower form-factor chassis and 1U/2U rackmounts via industry-standard riser accessories.
…
IBM’s Q2 2025 results saw a big jump to $17 billion, up 17 percent from Q1 and 8 percent year-on-year, mostly due to the new Z17 mainframe starting shipping. Storage hardware products are sold through the Distributed Infrastructure part of IBM’s Infrastructure group and also in its Software group. Neither figure is made public. Infrastructure group revenues were $4.1 billion, up 14 percent. Software group revenues were $7.4 billion, up 8 percent. Re storage in the Infrastructure group, CFO James Kavanaugh said: ”While Storage was impacted by the new IBM Z cycle as clients prioritized hardware spend, our early strength in z17 and growth in installed MIPS capacity drives a long-term benefit given the 3-4x Z stack multiplier.” In other words, storage hardware appears to have shown decreased revenues.
…
IBM has updated its Storage Virtualize software to v9.1.0 with details in a blog and it adds:
- Scalability enhancements for FlashSystem grid and partitions. Up to 32 systems can now be added to a FlashSystem grid (up from 8 previously) and each system can now manage up to 32 partitions (up from four previously)
- Added support for objects and management of partitions
- Separation of duties for use specific certificates
- Security enhancements, updated inference engine and reporting of anomalies within native GUI*
- VASA5 support
- Various miscellaneous enhancements and continued GUI modernization
…
Infinidat CMO Eric Herzog presented his company’s cyber storage security features to a Gartner Security & Risk Management Summit. Download his slides here.
…
Keepit offers its own cloud storage backup capability. A blog from CISO Kim Larson describes this and says that testing is the heart of business resilience.
…
Kingston has added an M.2 2230 form factor for its NV3 PCIe Gen 4 M.2 SSD, previously only available in the 2280 size. It provides storage expansion from 500 GB to 2 TB for systems with limited space. Powered by a Gen 4×4 NVMe controller NV3 2230 delivers read/write speeds of up to 6,000/5,000 MB/s. It includes 1-year free Acronis True Image for Kingston software, alongside the Kingston SSD Manager application.
…
Kingston says its Kingston IronKey D500S hardware-encrypted USB flash drive has received NIST FIPS 140-3 Level 3 validation. It claims D500S is the world’s first and only FIPS 140-3 Level 3 validated drive with a TAA-compliant and trusted supply chain.
…
Kioxia is sample shipping 512 Gb TLC chips built from BiCS 9 (218-layer) 3D NAND with mass production in its fiscal 2025 (ending March 31, 2026). They deliver up to 4.8 Gbps under demo conditions and designed to support apps requiring high performance and power efficiency in the low- to mid-level storage capacities. They’ll be integrated into Kioxia’s enterprise SSDs, particularly in ones aim to maximize GPU efficiency in AI systems.
Kioxia will use BiCS 9 218L flash for high performance at reduced production cost and BCS 10 332L for the expected future demand for larger-capacity, high-performance product.
…
Leil Storage announces SaunaFS 5.0 supports HAMR SMR drives from Seagate. David Gerstein, CTO of Leil Storage, said: “Getting SaunaFS 5.0 to support HAMR drives in general, and HAMR SMR drives specifically, right as they’re hitting the market was a big deal for us – we wanted enterprises of any size to benefit from these massive leaps in storage capacity as soon as possible. This release is all about putting innovative, efficient storage within reach for everyone.”
…
Micron is launching a high-density, radiation-tolerant single-layer cell (SLC) NAND product with a die capacity of 256 Gb. It’s the first in a portfolio that will include space-qualified NAND, NOR and DRAM products. It’s available now.
The product has:
- Extended quality and performance testing, aligned with NASA’s PEM-INST-001 Level 2 flow, which subjects components to a yearlong screening, including extreme temperature cycling, defect inspections and 590 hours of dynamic burn-in to enable spaceflight reliability.
- Radiation characterization for total ionizing dose (TID) testing, aligned with U.S. military standard MIL-STD-883 TM1019 condition D, which measures the cumulative amount of gamma radiation that a product can absorb in a standard operating environment in orbit and remain functional, a measurement that is critical in determining mission life cycle.
- Radiation characterization for single event effects (SEE) testing, aligned with the American Society for Testing Materials flow ASTM F1192 and the Joint Electronic Device Engineering Council (JEDEC) standard JESD57. SEE testing evaluates the impact of high-energy particles on semiconductors and verifies that components can operate safely and reliably in harsh radiation environments, reducing the risk of mission failure. This profiling information enables space engineers and architects to design in a way that mitigates the risk and disruption to the mission.
Micron customer partner Mercury Systems already uses Micron memory in its solid-state data recorders (SSDRs) to capture and store mission scientific and engineering data aboard NASA’s Earth Surface Mineral Dust Source Investigation (EMIT), an imaging spectrometer built by NASA’s Jet Propulsion Laboratory and launched to the International Space Station in 2022.
…
There is a 7.3 version of ObjectiveFS which includes new features such as AssumeRole, ListObjectsV2, settable user agent header, and TLS and lease performance improvements:
- New ListObjectsV2 support (enabled by default on Amazon S3)
- ListObjects version can be selected using the LISTOBJECTS environment variable
- New AssumeRole support to get credentials using AWS STS (learn more)
- New settable user agent header using the USER_AGENT environment variable
- Added header support for buckets with S3 Object Lock enabled
- TLS prioritizes AES256 over ChaCha20 to reduce TLS overhead
- Live rekeying supports switching between manual keys, IAM role and AssumeRole
- Improved object store cache fetches during startup for very large filesystems
- Optimized lease performance for a case where multiple nodes create new files in a shared directory tree
- Added new regions for AWS and GCS
More information here.
…
Sponsored research by Odaseva reveals nearly 40 percent of organizations don’t have backup systems in place, and among those that do, more than two-thirds don’t know how often they test whether their disaster recovery plans actually work. So most enterprises don’t know if their backup data is recoverable when disaster strikes. The survey also found that more than 40 percent of organizations believe their data is more secure when stored independently from their primary cloud platforms, compared to just 23.5 percent who see no concerns with platform-dependent solutions. This survey of 600-plus enterprise architects across 47 countries was sponsored by Odaseva and conducted by Salesforce Ben.
…
Ransomware protection is built into every layer of DDN subsidiary Tintri‘s VMstore. With immutable snapshots, granular, per‑VM recovery that replaces lengthy full-environment restores, real‑time analytics to detect anomalies, and automated backups and replication, organisations can contain and rebound from attacks swiftly. To close out Ransomware Awareness Month, Tintri will host a new installment of its Geek Out! Technology Demo Series titled “Never Mind, It’s Fixed.” Taking place on Wednesday, July 30 at 10 a.m. PT / 1 p.m. ET, this grunge-themed virtual event will explore how Tintri VMstore can help IT teams automate recovery and minimise downtime. Register to join here.
…
Research consultancy ESG has produced a technical validation of Tintri’s VMstore Kubernetes Data Services. ESG analysed Tintri VMstore’s capabilities and how they apply to containerised applications in three distinct use cases: DevOps workflows, unified management and observability, and data protection and disaster recovery. ESG identified several Tintri-specific differentiators that underscore its well-established AI-enabled infrastructure, observability, and management within the container platform space. Find out more here.
…
Distributed SQL database supplier Yugabyte announced new vector search, PostgreSQL, and multi-modal functionality in YugabyteDB to meet the growing needs of AI developers:
- YugabyteDB MCP Server for seamless AI-powered experiences in applications
- Support for LangChain, OLLama, LlamaIndex, AWS Bedrock, and Google Vertex AI
- Multi-modal API support with the addition of MongoDB API support for scaling MongoDB workloads in addition to PostgreSQL (YSQL) and Cassandra (YCQL)
- Online upgrades and downgrades across major PostgreSQL versions with zero downtime
- Enhanced PostgreSQL compatibility with generated columns, foreign keys on partitioned tables, and multi-range aggregates
- Built-in Connection Pooling that can support tens of thousands of connections per node.
It says multi-modal API support across YSQL, YCQL, and MongoDB, workloads, and vector indexing and search with a YugabyteDB MCP server means organizations can now build and deploy highly resilient, “ready-to-scale” RAG, and AI-powered applications with 99.99 percent or higher uptime using familiar PostgreSQL and powerful vector search capabilities architected for 1 billion-plus vectors. More info in a blog.