Cloud and backup storage vendor Backblaze has hired Robert Fitt as Chief Human Resources Officer, its first such position. He will lead the company’s strategic advancement for all HR functions including talent management, culture, compensation and benefits, organizational design, health and wellness, diversity, equity, and inclusion efforts. Fitt’s career in HR spans more than 20 years, including leadership roles at Turntide Technologies, 360 Behavioral Health, Mobilite, Broadcom Corporation, and others.
…
Managed infrastructure provider 11:11 Systems has bought assets of bankrupt Sungard Availability Services including its Cloud and Managed Services (CMS) business. This is 11:11’s seventh acquisition including Unitas Global managed servcies and cloud infrastructure assest and iland cyber resiliency and disaster recovery unit. It is backed by Tiger Infrastructure Partners, a middle-market private equity firm that invests in growing infrastructure platforms. Learn more at 1111Systems.com.
…
We hear that Airbyte is looking to build out its list of data connectors (currently around 150) aggressively and has made available a new low code SDK (alpha version), plus financial incentives for its user community. The goal is to have a large number of new connectors at the end of the month.
…
BittWare has announced three PCIe 5.0 CXL-capable accelerator cards based on Intel Agilex M-Series and I-Series FPGAs. One is the IA-860m accelerator card using the M-Series FPGA, with high-speed HBM2e DRAM integrated into the FPGA package. It is for high throughput and memory-intensive workloads and can be programmed using Intel oneAPI and Data Parallel C++ (DPC++). The other two are the single-width IA-640i and IA-440i accelerator cards using I-Series FPGAs. The IA-640i is designed for accelerating datacenter, networking, and edge-computing workloads. The entry-level and half-height IA-440i is a mini version of the IA-640i. All three cards can be used as coherent hardware accelerators within datacenter servers, networks, and edge servers equipped with CXL-supporting CPUs. Adding CXL features to these three cards requires purchase and activation of a CXL IP license from either Intel or a third-party IP supplier. BittWare provides application reference designs for all three cards.

…
Research house DCIG has announced availability of its 2022-23 TOP 5 report on AWS Cloud Backup Solutions. It provides small and mid-sized enterprise guidance on the best backup solutions for recovering applications, data, and workloads they host in AWS. The full report may be accessed at no charge with registration on DCIG’s website here.
…
We have learned that Neridio’s CloudRAID does encryption, compression, and deduplication in addition to Reed-Solomon (RS) erasure coding. IO performance will be impacted roughly around three times of standard IO. The company told us: ”RS coding and encryption always introduces a latency tax, which is one reason why it was not adopted by primary storage by the industry.” Neridio’s software is “in the latency tolerant path, as we are not dealing with primary storage. We are only focusing on safety and security of a Gold copy, data foundation, which is Tier 2 or secondary storage tier… We are targeting those markets where security, cyber resilience, and an attack-proof data layout is more important than performance.” Neridio’s software distributes the workloads in parallel. It has Active Storage Threat response against ransomware attacks and storage security in-motion with Exclusive Path routing at content level, it said.
…
Ocient has said its Hyperscale Data Warehouse is generally available in the AWS Marketplace. Customers can deal directly with Ocient in AWS Marketplace, or with Ocient partners and resellers who offer Ocient deployed on AWS to their network of customers.
…
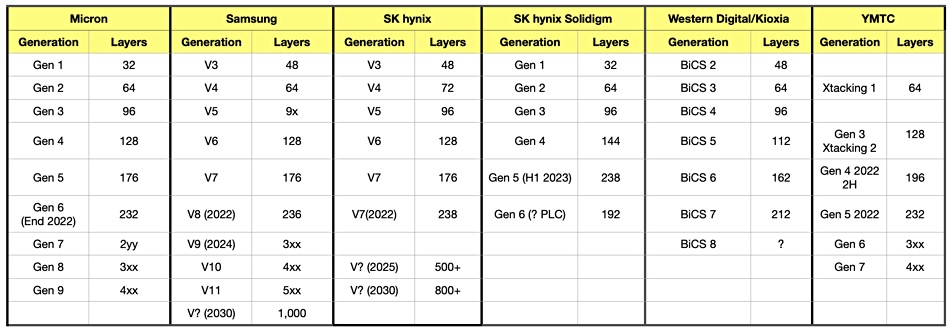
Samsung said it expects to build 1,000-plus layer 3D NAND by 2030 at its Samsung Tech Day 2022 event. Jung-bae Lee, Head of Memory Business, said: “One trillion gigabytes is the total amount of memory Samsung has made since its beginning over 40 years ago. About half of that trillion was produced in the last three years alone.” Its most recent, 512Gb eighth-generation V-NAND features a bit density improvement of 42 percent, the industry’s highest among 512Gb triple-level cell (TLC) memory products. The world’s highest capacity 1Tb TLC V-NAND will be available by the end of the year. Ninth-generation V-NAND (TLC and QLC) is under development and slated for mass production in 2024. Samsung will accelerate the transition to quad-level cell (QLC), while enhancing power efficiency.
…
Western Digital’s SanDisk has announced the Pro-G40 external SSD with a single port for either USB-C or Thunderbolt 3. It’s a rugged drive capable of withstanding dust, dirt, sand, and submersion at a depth of 1.5 meters (about five feet) for up to 30 minutes. It can withstand up to 4,000 pounds of pressure and survive a fall of up to three meters (about 9.8 feet) onto a concrete floor. It can reach speeds up to 2,700 MB/sec read and 1,900 MB/sec write speeds with Thunderbolt 3. USB 3.2 Gen 2 supports a 10Gbit/s interface, a quarter of Thunderbolt 3’s 40Gbit/s and will be slower. The Pro-G40 is available at $300 for 1TB and $450 for 2TB, with a five-year limited warranty.

…
IBM’s Spectrum Scale distributed parallel file system can now be used with the IBM Cloud. We understand that, from a tile in the IBM Cloud catalog, customers can fill out a configuration page specifying the parameters of their desired storage and compute clusters. They then click Start and a process using IBM Cloud Schematics, Terraform, and Ansible deploys and configures many IBM Cloud VPC resources that, in less than an hour, culminates in cloud-based high performance parallel filesystem storage and compute clusters that are ready to run, we are told.
…
SIOS has said its LifeKeeper for Linux clustering software has achieved SAP recertification for integration with both NetWeaver and S/4HANA. SIOS’s specialized application recovery kits (ARKs) modules come with LifeKeeper to provide application-specific intelligence and automation of configuration steps. This enables configuration of HANA clusters without the complexity or need for error-prone manual scripting. Also ARKs ensure that cluster failovers maintain SAP best practices for fast, reliable recovery of operation, SIOS said.
…
China’s TerraMaster has launched the new two-bay F2-223 NAS and 4-bay F4-223 NAS with TRAID products, with upgraded specs including the use of Intel’s Celeron N4505 dual-core processor and the latest TOS 5 operating system. This offers more than 50 new functions and 600 improvements compared with the previous generation.

TRAID offers disk space, hard disk failure redundancy protection, and automatic capacity expansion. This elastic strategy provides higher disk space utilization than traditional RAID modes, we are told. Storage space can be expanded by replacing the hard disk with a larger capacity model and/or increasing the number of hard disks. TRAID allows a maximum of one hard disk to fail. You can migrate TRAID to TRAID+, with redundant protection of two hard drives, by upping the number of hard drives.
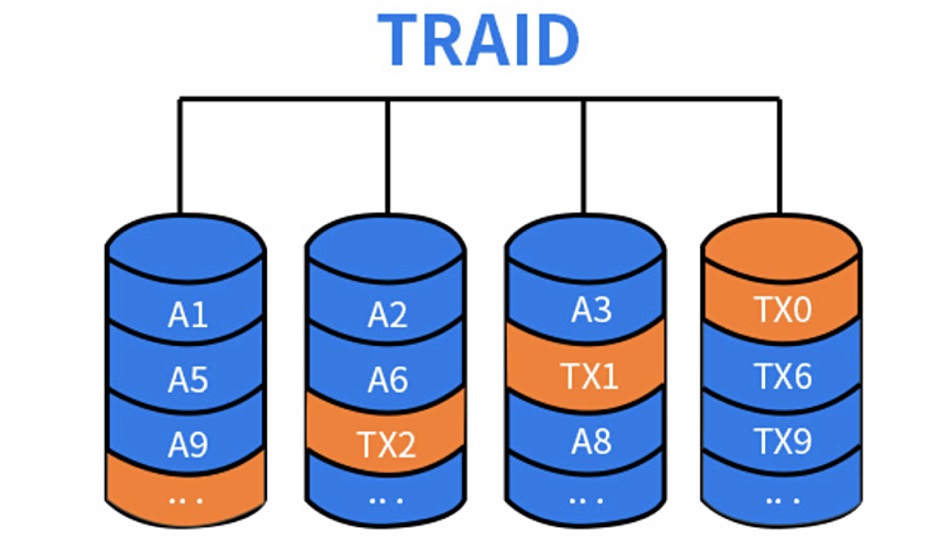
The two-bay TerraMaster F2-223 is available in the US via Amazon for $299.99 and the 4-bay F4-223 for $439.99.
…
US Commerce Department will likely deny requests by US suppliers to send equipment to Chinese firms like YMTC and ChangXin Memory Technologies if they are making advanced DRAM or flash memory chips. License requests to sell equipment to foreign companies making advanced memory chips in China will be reviewed on a case-by-case basis. US suppliers seeking to ship equipment to China-based semiconductor companies would not need a license if selling to outfits producing DRAM chips above the 18 nanometer node, NAND Flash chips below 128 layers, or logic chips above 14 nanometers. This would likely affect YMTC, which is directly competing with Micron and Western Digital.