


Intel revealed more Sapphire Rapids memory information at Supercomputing ’21 with capacity, bandwidth and tiering data. Datacentre servers will become much faster and capable of running more containers and virtual machines — but at the expense of SKU complexity.
Update. Diagram corrected to show Optane PMem 300 series connectivity doesn’t use PCIe bus. 2 Dec 2021.
Sapphire Rapids is the fourth generation of Intel’s Xeon Scalable Processor brand datacentre server CPU, following on from Ice Lake. According to Intel it will offer the largest leap in datacentre CPU capabilities for a decade or more.
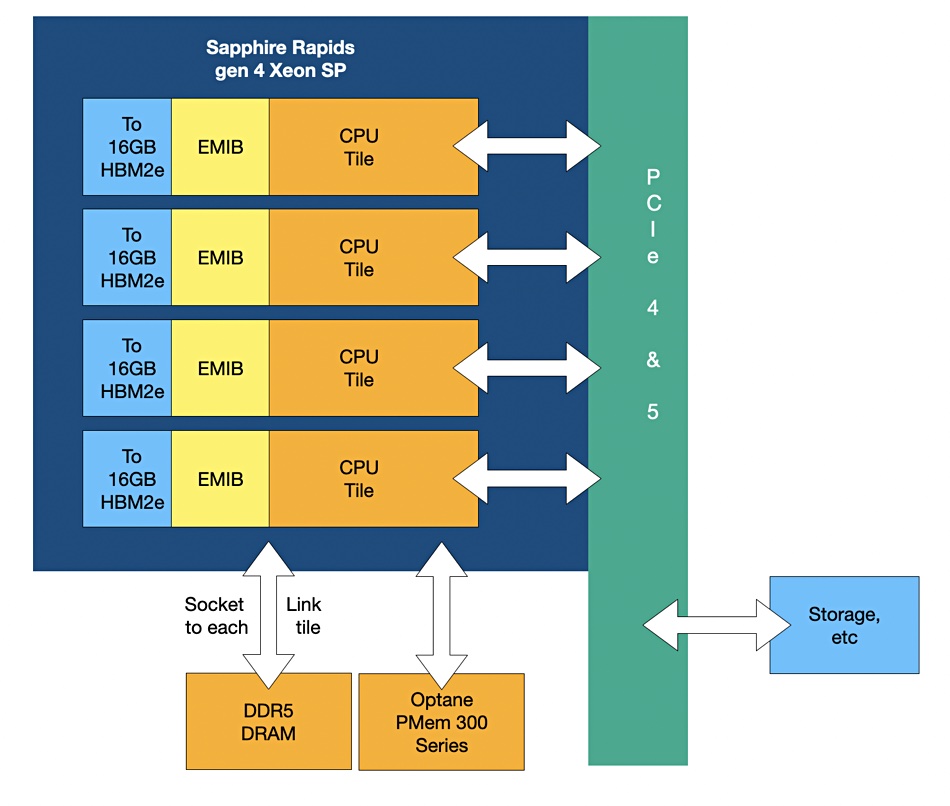
It has a 4-tile design, using an EMIB (Embedded Multi-die Interconnect Bridge) link to unify them into what appears to be a monolithic die. The processor, with up to 56 cores — 14 per tile — supports:
- DDR5 DRAM — up to eight channels/controllers,
- HBM2e — up to 64GB of in-package memory with up to 410GB/sec bandwidth per stack, 1.64TB/sec in total;
- Optane Persistent Memory 300 series;
- PCIe 4.0 and 5.0;
- CXL v1.1.
The EMIB functions also as an interposer, linking each CPU tile to its HBM2e stack. There is a three-level memory hierarchy, with HBM2e at the top, then socket-linked DRAM and Optane PMEM 300 series. HMBe2 will bring “orders of magnitude more memory bandwidth” according to Jeff McVeigh, VP and GM for the Super Compute Group at Intel. He said: “The performance implications for memory-bound applications I[are] truly astonishing.”

The processor has a coherent shared memory space, across CPU cores and DSA and QAT acceleration engines. DSA accelerates input data streaming while Quick Assist Technology (QAT) speeds encryption/decryption and compression/decompression.
The coherent memory space applies to processes, containers and virtual machines.
There can be up to 64GB of HBM2e memory, divided into four units of 16GB, one per tile, each built from 8x 16Gbit dies.
The Sapphire Rapids CPU can operate in four NUMA (Non-Universal Memory Architecture) modes with a sub-NUMA Clustering feature
Sapphire Rapids options include HBM2e with no DRAM, or DRAM with HBM2e — in which case we have flat mode and caching mode. Flat mode has a flat memory design embracing both DDR5 DRAM and HBM2e, but with the DRAM and HBM2e each having its own NUMA mode.
In caching mode the HBM2e memory is used as direct-mapped cache from DRAM and is invisible to application software. With the alternative flat mode application software has to use specific code to access the HBM2e memory space.
As Optane also has its different modes, such as application direct (DAX), the use of non-persistent (HBM2e and DRAM) and persistent (Optane PMem 300) memory by applications will become more complicated. Intervening system software, such as MemVerge’s Big Memory Computing offering, will become more useful because they promise to hide this complexity.
It’s obvious that server configuration variations will become more complex as well, with servers coming with Sapphire Rapids CPU variations (how many cores did you want?), HBM2e-only and no DRAM, HBM2e and DRAM, PCIe 4.0 and/or 5.0, CXL1.1 or not, Optane PMem 300 and no Optane. This could be a SKU nightmare.
Intel’s Ponte Vecchio GPU will also support HBM2e and PCIe 5, and Intel considers Sapphire Rapids and Ponte Vecchio as natural partners — the one for general workloads and the other for GPU-intensive work. Will there be a GPUDirect-type link between Sapphire Rapids servers and Ponte Vecchio GPUs, echoing Nvidia’s software to bypass server CPUs and get stored data into its GPUs faster than otherwise? We don’t know but the idea seems to make sense.





