


Korean technology firm Panmnesia has a CXL 3.0-enabled accelerator chip which provides sharable memory to speed AI applications.
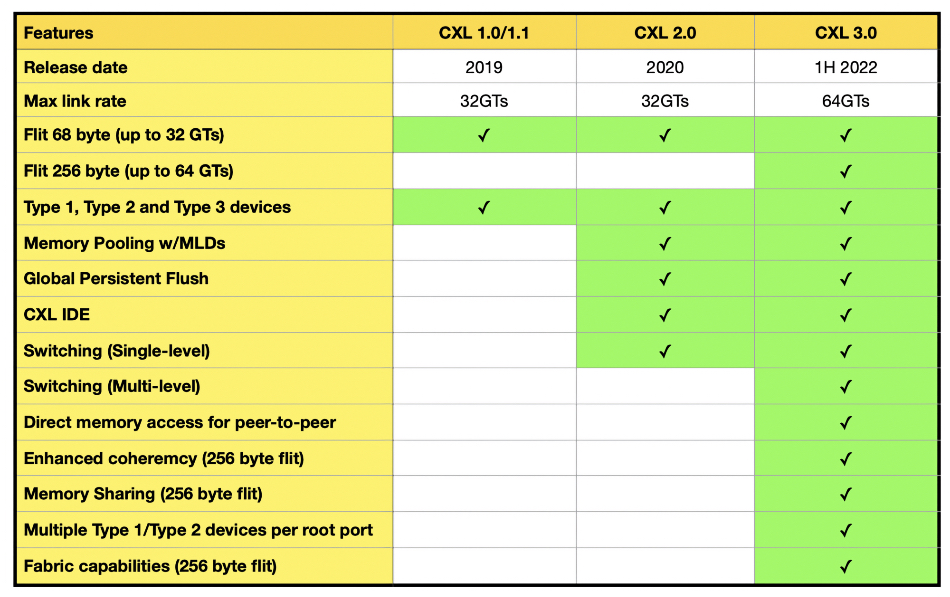
CXL (Computer eXpress Link) 3.0 enables a pool of external memory, accessed through CXL switches, to be shared between host computers with coherent caches in the hosts and the CXL memory endpoints or expanders. The earlier CXL 2.0 standard enabled hosts to access their part of an external memory pool via a CXL switch but not share it. The initial CXL 1.0/1.1 standards supported a host having direct access to external memory without going through a switch.
The forthcoming CES 2024 show has given Panmnesia an Innovation Award for its accelerator chip.
Panmnesia founder and CEO Myoungsoo Jung said in a statement: “We believe that our CXL technology will be a cornerstone for next-generation AI acceleration system. We remain committed to our endeavor revolutionizing not only for AI acceleration system, but also other general-purpose environments such as data centers, cloud computing, and high-performance computing.”
The company contrasts its ability to provide up to a theoretical 4PB of shared memory with clustered servers accessing external SSDs for data. It says that individual servers generally work in parallel on AI and other HPC-style applications and need to access more data than can be held in their memory. That means they have to use SSDs to store the excess data and access them by SAS, NVMe or RDMA protocols across a network.
It is better – faster – to load all the data into an external memory pool and have all the servers access it using memory load and store instructions with data crossing a PCIe 6 bus instead of a slower network link.
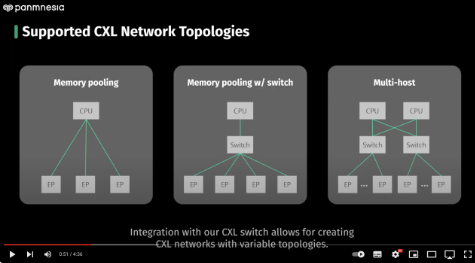
The accelerator chip is part of a Panmnesia All-in-One Framework to help developers build proof-of-concept CXL 3.0 system software, user-level applications and custom hardware. It includes the accelerator chip which has a built-in CXL 3.0 controller, CXL switching and end-points. These are are fully compatible with all CXL protocols, such as CXL.io, CXL.cache, and CXL.mem.

The switch has a software fabric manager function to manage internal routing rules within the switch, and can connect to other CXL switches and external devices,
The framework justifies its All-In-One name by having a software stack featuring a Linux-based OS with CXL device drivers and a CXL-aware virtual memory system. This means applications can use the shared CXL external memory with no code change
Panmnesia’s memory sharing uses back invalidation to enable endpoints, the memory expander modules, to manage the cache coherency between hosts. There is register-to-register transfer between a host and its accelerator chip.
A You Tube demo video shows 8TB of CXL-attached memory being made available to the host and 8KB of the memory space set shareable. Another host could then access the sharable memory and the two hosts share data via the shared memory space.
Panmnesia says that some HPC plasma simulation applications speed up 1.8x by using its shared memory instead of accessing SSDs to get data. It also claims that AI applications can achieve an up to 101x speed up through the accelerator chip, because it is tailored to AI search with frequent parallelized vector processing.
CES 2024 will take place in Las Vegas from January 9 to January 12.
Panmnesia raised a $12.5 million seed round in September, giving the company an $81.4 million valuation. The round was led by Daekyo Investment, with participation from SL Investment, Smilegate Investment, GNTech Venture Capital, Time Works Investment, Yuanta Investment and Quantum Ventures Korea.

Israeli startup UnifabriX is also working in the CXL 3.0 shared memory area with its MAX memory and storage machine. It has an Early Access Program (EAP), with agreements with High-Performance Computing (HPC) entities for MAX testing and validation. This has been expanded to include companies with on-prem/cloud data centers needing to handle AI workloads.





