


Analysis: DDN says storage for generative AI and other AI work needs a balance of read and write speed, claiming its own storage provides the best balance because of its write speed superiority over competing systems.
Update. Dell PowerScale F600 write bandwidth performance added. 31 July 2023.
The company supplies its Exascaler AI400X2 array with Magnum I/O GPUDirect certification for use with Nvidia’s DGX SuperPod AI processing system. It uses 60TB QLC (4bits/cell) SSDs and has a compression facility to boost effective capacity. Some 48 AI400X2 arrays are in use with Nvidia’s largest SuperPODs according to DDN, which said it shipped more AI storage in the first quarter of this year than in all of 2022.
SVP for Products at DDN, James Coomer, has written a blog, Exascale? Let’s Talk, in which he says that an AI storage system has to support all stages of the AI workload cycle. “That means ingest, preparation, deep learning, checkpointing, post-processing, etc, etc, and needs the full spectrum of IO patterns to be served well.”
AI processing read-write mix
What IO patterns? Coomer cites an OSTI.GOV whitepaper, Characterizing Machine Learning I/O Workloads on Leadership Scale HPC Systems, which studied: ”the darshan logs of more than 23,000 HPC ML I/O jobs over a time period of one year running on Summit – the second-fastest supercomputer in the world”. Darshan is an HPC IO characterization tool. Summit’s storage was the GPFS (Storage Scale) parallel filesystem.
The whitepaper says: “It has been typically seen that ML workloads have small read and write access patterns,” and “Most ML jobs are perceived to be read-intensive with a lot of small reads while a few ML jobs also perform small writes.”
But, “from our study, we observe that ML workloads generate a large number of small file reads and writes.”
The paper says ~99% of the read and write calls “are less than 10MB calls. … ML workloads from all science domains generate a large number of small file reads and writes.”
A chart shows their finding with GPFS-using workloads:
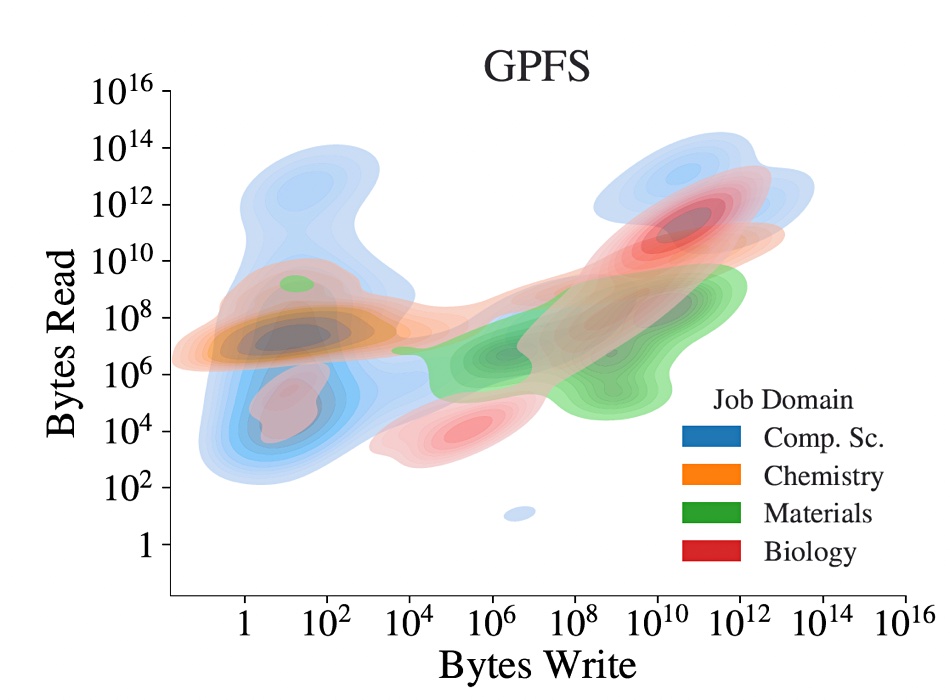
There is a roughly even balance between read and write IO. Coomer’s blog has a chart showing the balance between read and write IO calls with small calls (less than 1MB) dominating the scene:
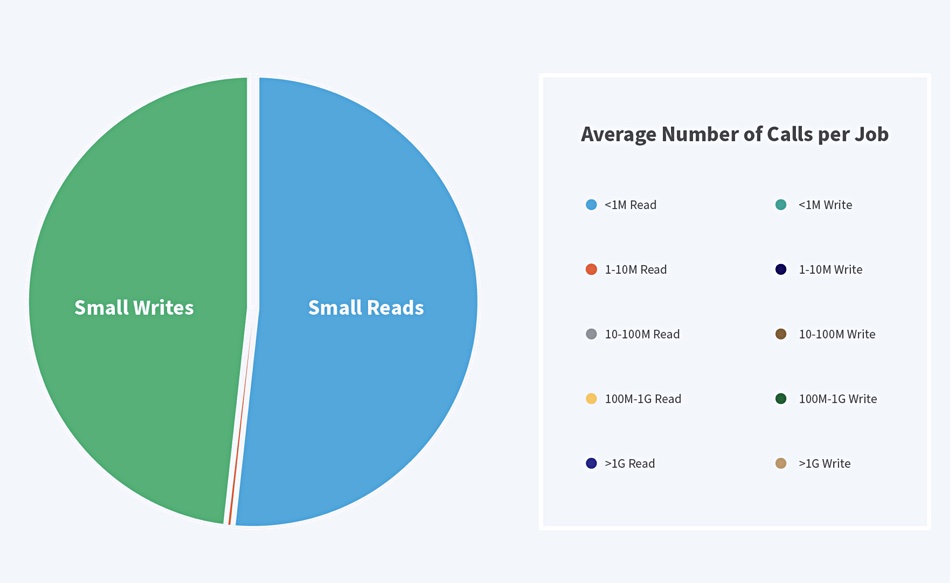
The paper’s authors say: “The temporal trend of ML workloads shows that there is an exponential increase in the I/O activity from ML workloads which is indicative of the future which will be dominated by ML. Therefore better storage solutions need to be designed that can handle the diverse I/O patterns from future HPC ML I/O workloads.”
Armed with this balanced and small read/write preponderance finding Coomer looks at the IO capabilities of different QLC flash systems using NFS compared to the DDN AI400X2 storage.
He contrasts a part-rack DDN AI400X2 system that can provide 800GBps of write bandwidth with a competing but un-named system needing 20 racks to do the same.
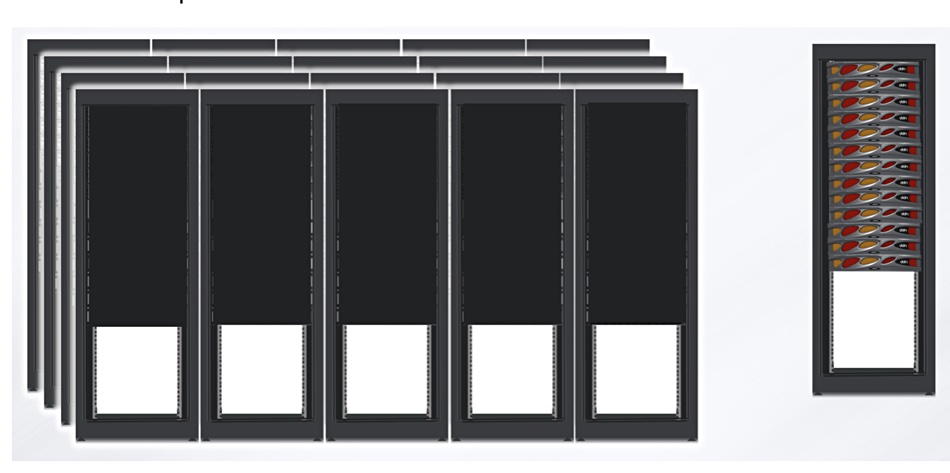
Coomer told us: “The servers and storage are all there (embedded inside the AI400NVX2) and no switches are needed for the back end. We plug directly into the customer IB or Ethernet network. The DDN write performance number is a measured one by a customer not just datasheet.”
What competing system?
We looked at various QLC flash/NFS systems to try and find out more. For reference, an AI400X2 system can deliver 90 GBps of read bandwidth and 65 GBps write bandwidth from its 2RU chassis. Twelve of them hit 1.08 TBps read and 780 GBps write. Thirteen would reach 1.17 TBps read and 845 GBps write bandwidth from 26 RU of rack space.
It’s necessary to include the servers and switches in the alternative systems to make a direct comparison with the DDN system.
VAST Data Lightspeed storage nodes provides 50 GBps from a 44RU configuration. We would need 16 of these to achieve 800 GBps write speed, plus the associated compute nodes and switches. Say ~20 racks roughly; it depends upon the storage node-compute node balance.
A newer VAST Data Ceres system provides 680 GBps from 14 racks, 48.6 GBps per rack, meaning 17 racks would be needed to reach the 800 GBps write speed level:

A Pure Storage FlashArray//C60 has up to 8 GBps throughput from its 6RU chassis. If we assume that is write bandwidth and we have 1.3 GBps per RU and will need 14 or so racks to reach 800 GBps write speed.
Update. Forty eight Dell PowerScale F600s demonstrated 56.4GiBps sending data to 48 Nvidia GPUs, 1.175GiB/node (1.26GB/node). A node is 1RU in size and, therefore, to achieve 800GBps write bandwidth there would need to be 635 nodes; about 15 fully populated racks.
Scale-out NFS inefficiency
In Coomer’s view scale-out NFS system architectures are inefficient because they are complex:
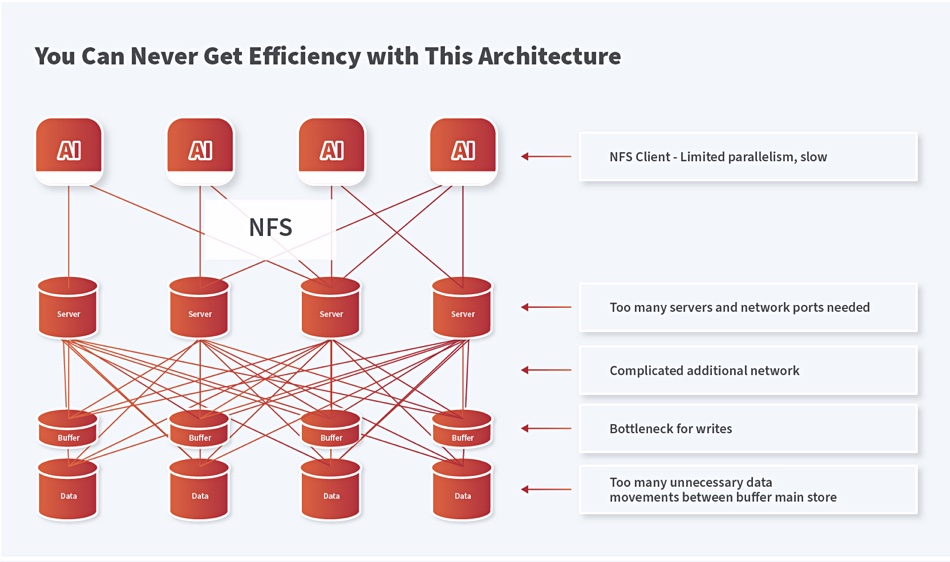
DDN’s Exascaler AI400X2 system does away with the server-interconnect-buffer complexity because its client nodes know where the data is located:
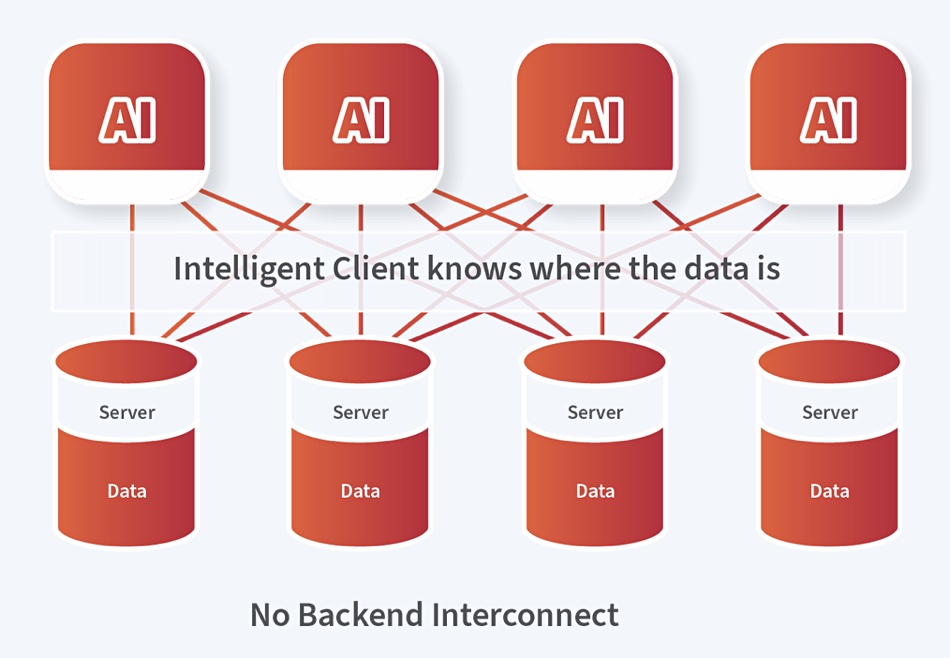
It can provide, Coomer argues, the balanced small read and write IO performance that ML workloads, like generative AI, need, according to the OSTI.GOV research. It can do this from significantly less rackspace than alternative QLC flash/NFS systems. And that means less power and cooling is needed in AI data centers using the DDN kit.




