


The world of composable systems is divided between PCIe/CXL-supporting suppliers, such as Liqid, and networking suppliers such as Fungible. And then there is Nvidia, which has depended upon its networking for composability – either Ethernet or InfiniBand – but is preparing to support CXL. An interview with Kevin Deierling, its VP for Networking, cleared things up.
His basic concern with PCIe-based systems is tail latency – the occasional (98th to 99th percentile) high-latency data accesses that could occur and delay app completion time – and link robustness, as we shall see.
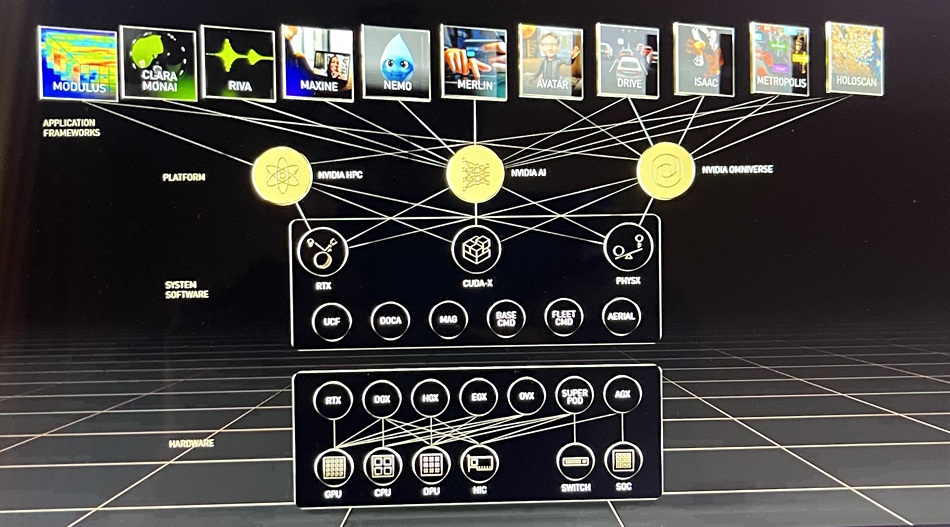
Deierling said Nvidia starts from a three-layer stack point of view, with workloads at the top. They interface with a system hardware layer through platform elements such as Nvidia Omniverse, AI and HPC. These talk system software – Nvidia RTX, CUDA-X and PHYSX – through underlying software constructs such as DOCA, Base Command and Fleet Command to hardware elements such as GPUs, CPUs, DPUs (Bluefield), NICs (ConnectX), switches and SoCs (System on Chip).

Deierling said: “This is relevant because each of these different workloads on the top, some of them are incredibly compute-intensive, and need a tonne of GPUs. Others are incredibly data-intensive and need, you know, NICs and CPUs to access storage. And so that notion of composability is critical to everything we do. And it’s really fundamental to everything we do so that we can take a set of resources and offer this as being built in the cloud. Therefore, you have a set of resources that needs to run every one of these applications. … Composability is really being driven by this. It’s just all sorts of different workloads at the top that all need really different elements.”
He said: “Our customers will leverage our technology to build a composable datacenter. So we’re not trying to compete with somebody that’s doing something over PCI Express – that’s just not how we view the world.”
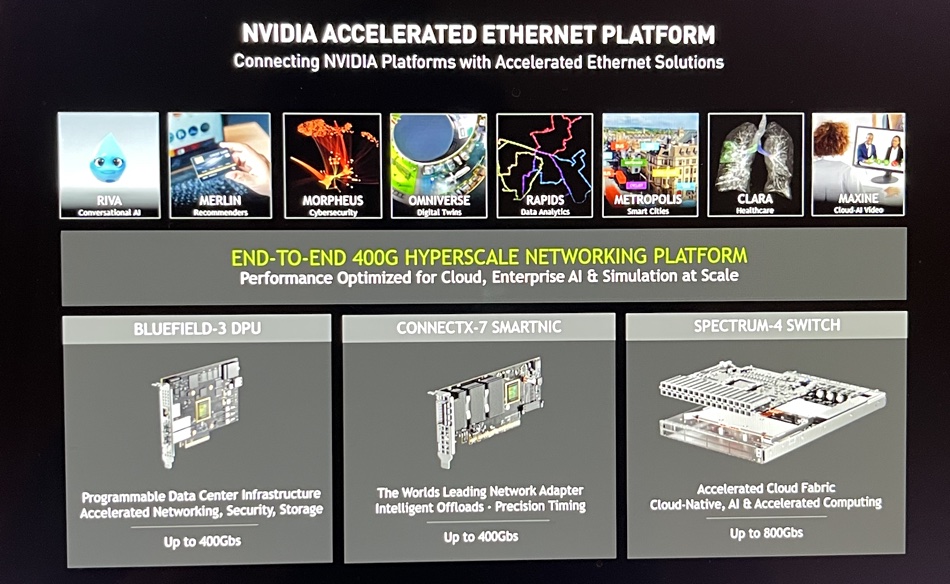
Deierling talked about Nvidia’s accelerated Ethernet platform and three embodiments: the BlueField 3 DPU (Data Processing Unit), ConnectX-7 Smart NIC and Spectrum-4 switch.
He said: “Underlying it is this vision of the datacenter as the new unit of computing. And then we can scale the three elements – GPUs, CPUs, and DPUs – independently. And then, of course, storage is another really a fourth element here so that, for storage-intensive applications, we can assign different storage elements to these boxes.”

A datacenter can be equipped with a number of GPUs of different kinds, CPUs and DPUs – but not all workloads need all of these, and what they do need varies. By virtualizing the hardware and being able to compose the hardware elements and form them into dynamic configurations for workloads you can increase the system’s utilization and reduce the amount of stranded and temporarily useless resource capacity in systems such as Nvidia’s OVX SuperPod.
BlueField, he said, “can actually go take what was local storage and make it remote, but have it still appear as if it was local. This is a classic composability workload, and others are doing that by literally extending the PCIe interface.”
The trouble with PCIe is that it is unsophisticated and was never designed for networking. “We do it in a much more sophisticated way. The problem with PCIe is that if you disconnect a PCIe switch cable from a storage box, then your system says: ‘Oh, something broke, I’m going to reboot.’ Everyone’s trying to work around that fundamental nature – that PCIe was designed to work in a box, and it doesn’t fail. And if it fails, your whole system has failed.”
“We use networking, and we make the composability interface at the software layer. So when you do … NVMe, you actually say, ‘Hey, I’m a local NVMe drive.’ The reality is we’re not an NVMe drive – the storage is somewhere else. It’s in a box from one of our partners – a Pure or a DDN or NetApp or EMC or just a bunch of flash. We present it as if it was local. We do the same thing with networking. We can have IO interfaces that are really composed and then we can go off and run firewalls and load balancers and all of those different applications.”
In his view, “We’re really taking all of … hardware appliances, and we moved them to this software-defined world and now we’re virtualizing everything which makes it composable in a software-defined hardware system.”
Blocks & Files: I can see that you’re dynamically composing storage attached to Bluefield and the GPUs and CPUs, but I can’t see you composing DRAM or storage-class memory. So are you at a disadvantage there?
Deierling: “Our NVLink technology is an even lower-level technology than networking. That starts to address some of these issues … We’re using our NVLink technology to connect GPUs to GPUs. But Jensen [Huang, Nvidia president and CEO] showed the roadmap where that really starts to extend into other things. And those other things are certainly capable of supporting memory devices. Today, we’re actually doing GPU to GPU and the memory between those devices. We can connect across an NVLink interface and share that.”
Blocks & Files: And CXL?
Deierling: “One of the things we’re looking at is CXL. NVLink is very much like CXL. And I think we won’t be disadvantaged. You know, we’ll support CXL when it’s available. We look at CXL as just the next generation of PCIe. Certainly today with PCIe, it’s one of the areas where we connect. And, you know, frankly, it slows us down.”
“When we make networking connections between devices, we’re typically limited by PCIe to go to the host memory. This is precisely, for example, why we have converged cards that we can connect directly from our GPUs: because we have a very, very fast local interconnect, faster than we’re able to get through the host system bus to the CPU.”
He said that CXL will speed things up and “as it starts to provide new semantics, we will absolutely take advantage of those.”
Tail latencies
A PCIe problem is tail latencies, as he explained. “RDMA, the remote direct memory access capability, needs really low latency hardware offload congestion management. [That’s] because one of the challenges here is that if you have memory, you simply can’t live with long tail latencies, where every once in a while, your access takes many, many hundreds of microseconds versus on average, microseconds.
“This is one of the things that we address with all of our adaptive routing and congestion control capabilities that we built into our networking technologies, the same sort of technologies will need to be built into anything that has the potential to compose memory.”
You may get 99 percent hit rates on local caches (server socket-accessed DRAM or GPU high-bandwidth memory) and only one percent of the time have to go fetch data across the composable interface. “So you figure that you’re in great shape. Well, if your access times is 1000 times longer – if instead of being 50 nanoseconds, it’s 50 microseconds – [then] that one percent of the time … that you have to go fetch from remote memory completely dominates your performance.”
PCIe can’t solve the tail latency problem. “Today we’re doing a tonne of things with RDMA over networks. We partner with others that use PCI Express, but frankly, we’ve never seen that technology be able to deliver the kinds of performance with composability that we’re able to deliver over a network.”
“CXL has some headwinds that it needs to overcome to become something that really supports the composable network. We’ll adopt and embrace that as needed. And when things aren’t there, and they’re not available, then we build our own technologies.” Like NVLink.
Deierling said: “There was a great paper that that actually Google published nine years ago called The Tail at Scale. Even if something happens only one out of 1000 times, in our datacenters with our workloads fragmented into thousands of microservices, you’ll see it all the time. So that’s what we really think about not average latencies, but tail latency.”
Blocks & Files: What do think of CXL big memory pools?
Deierling: “As CXL evolves, and we see a potential that gives us performance. It has to be deterministic performance. It’s that long tail latency that kills you. … If that becomes something that is reliable, cost effective, can scale out and addresses that long tail latency, then absolutely we will take advantage of those connections. You know, it’s not there yet.”
Comment
Nvidia is a member of the CXL Consortium and has, we could say, a watching brief. It does not have a need for large CXL-accessed memory pools because its GPUs have local high-bandwidth memory and are not memory-limited in the same way as an x86 server, with its limited DRAM socket numbers. As CXL memory pooling is not here yet we can’t tell if long tail latency will be a real problem or whether software such as that from MemVerge could sort it out. We are suffering from, you could say, new technology’s long arrival latency.





