


The exciting news about the HPE Cray-built Frontier supercomputer formally passing the exascale test made me curious about its storage system. I pointed my grey matter at various reports and technical documents to understand its massively parallel structure better and write a beginners’ guide to Frontier storage.
Be warned. It contains a lot of three-letter abbreviations. HPE’s exascale Frontier supercomputer has:
- An overall Orion file storage system;
- A multi-tier Lustre parallel file system-based ClusterStor E1000 storage system on which Orion is layered;
- An in-system SSD storage setup integrated into the Cray EX supercomputer, with local SSDs directly connected to compute nodes by PCIe 4.
The Lustre ClusterStor system has a massive tier of disk capacity which is front-ended by a smaller tier of NVMe SSDs. These in turn link to near-compute node SSD storage capacity which feed the Frontier cores.
Orion
The Oak Ridge Leadership Computing Facility (OLCF) has Orion as a center-wide file system. It uses Lustre and ZFS software, and is possibly the largest and fastest single Posix namespace in the world. There are three Orion tiers:
- a 480x NVMe flash drive metadata tier;
- a 5,400x NVMe SSD performance tier with 11.5PB of capacity based on E1000 SSU-F devices;
- a 47,700x HDD capacity tier with 679PB of capacity based on E1000 SSU-D devices.
There are 40 Lustre metadata server nodes and 450 Lustre object storage service (OSS) nodes.
A metadata server manages metadata operations for the file system and is set up with two nodes in an active:passive relationship. Each links to a metadata target system which contains all the actual metadata for that server and is configured as a RAID 10 array.
There are also 160 Orion nodes used for routing. Such LNET routing nodes run network fabric or address range translation between directly attached clients and remote, network-connected client compute and workstation resources. They enable compute clusters to talk to a single shared file system.
Here is a Seagate diagram of a Lustre configuration:
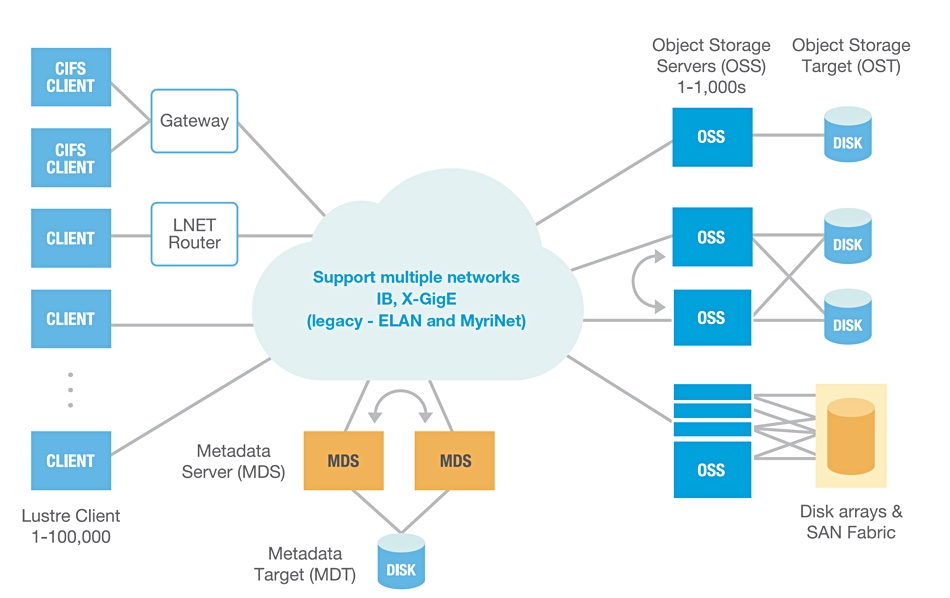
The routing and metadata server nodes exist to manage and make very fast data movement between the bulk Lustre storage devices, object storage servers (OSSs) and their object storage targets (OSTs) possible. HPE Cray’s ClusterStor arrays are used to build the OSS and OST structure.
ClusterStor
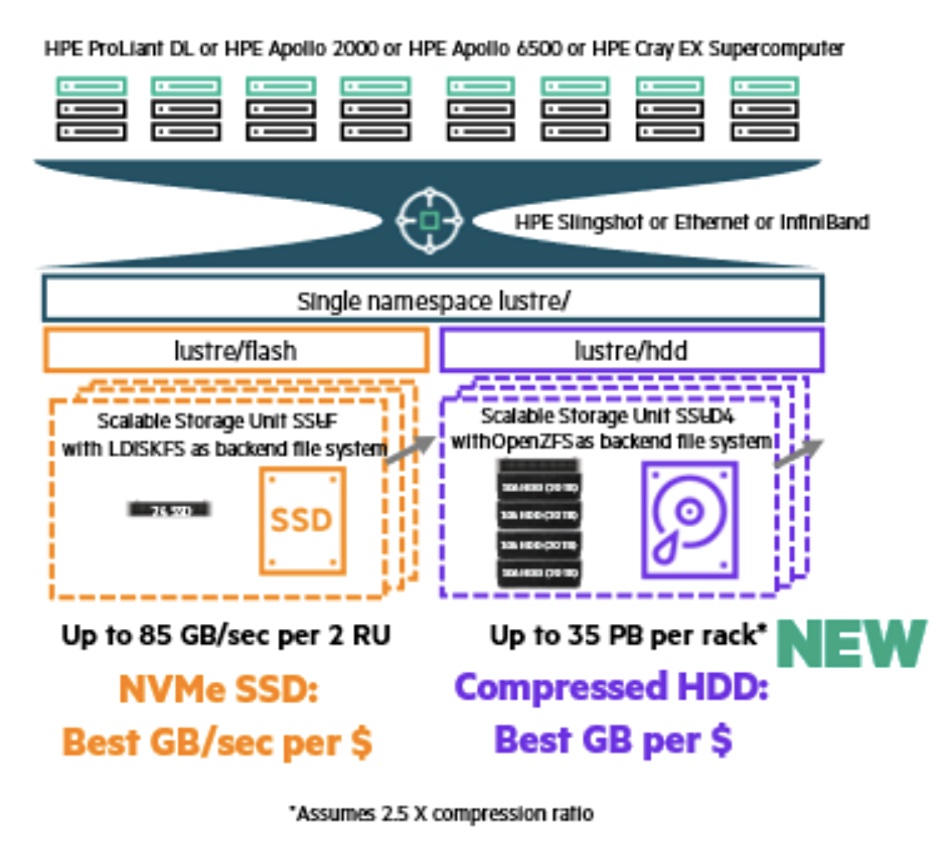
There is more than 700PB of Cray ClusterStor E1000 capacity in Frontier, with peak write speeds of >35 TB/sec, peak read speeds of >75 TB/sec, and >15 billion random read IOPS.
ClusterStor supports two backend file systems for Lustre:
- LDISKFS provides the highest performance – both in throughput and IOPS;
- OpenZFS provides a broader set of storage features like for example data compression.
The combination of both back-end file systems creates a cost-effective setup for delivering a single shared namespace for clustered high-performance compute nodes running modeling and simulation (mod/sim), AI, or high performance data analytics (HPDA) workloads.
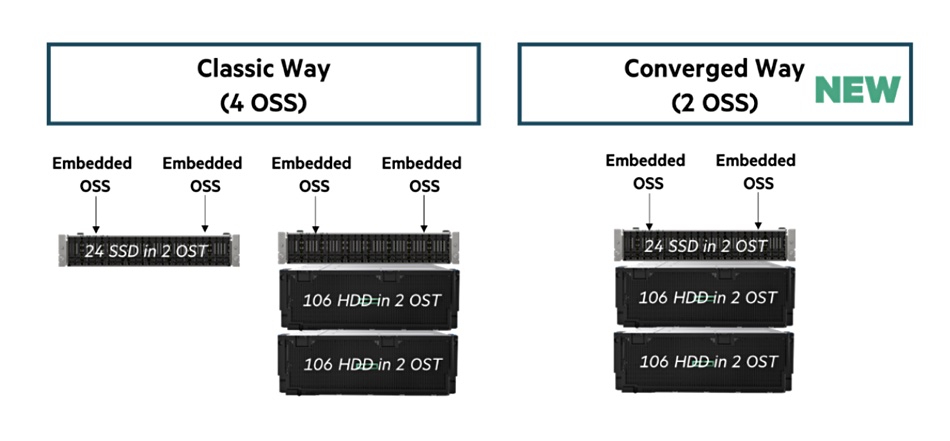
Orion is based on ClusterStor E1000 storage system hybrid Scalable Storage Units (SSU). This hybrid SSU has two Object Storage Servers (OSS) which link to one performance-optimized object storage device (OST) and two capacity-optimized OSTs; three component OSTs in total:
- 24x NVMe SSDs for performance (E1000 SSU-F for flash);
- 106x HDD for capacity (E1000 SSU-D for disk);
- 106x HDD for capacity (E1000 SSU-D).
The hybrid SSU was developed for OCLF but is now being made generally available as an E1000 configuration option. It is an alternative to original or classic four-way OSS designs. An example hybrid SSU-F and SSU-D configuration looks like this:
E1000 Scalable Storage Unit – All Flash Array (SSU-F)
A ClusterStor E1000 SSU-F provides flash-based file I/O data services and network request handling for the file system with a pair of Lustre object storage servers (OSS) each configured with one or more Lustre object storage target(s) (OSTs) to store and retrieve the portions of the file system data that are committed to it.
The SSU-F is a 2U storage enclosure with a high-availability (HA) configuration of dual PSUs, dual active:active server modules, known as embedded application controllers (EAC), and 24x PCIe 4 NVMe flash drives.
Each OSS runs on one of the server modules, forming a node, and the two OSS nodes operate as an HA pair. Under normal operation each OSS node owns and operates one of two Lustre Object Storage Targets (OST) in the SSU-F. If an OSS failover happens then the HA partner of the failed OSS operates both OSTs.
Normally both OSSs are active concurrently, each operating on its own exclusive subset of the available OSTs. Thus each OST is active:passive.
A ClusterStor E1000 SSU-F is populated with 24x SSDs. For a throughput optimized configuration, approximately two halves of the capacity are each configured with ClusterStor’s GridRAID declustered parity and sparing RAID system using LDISKFS. For an IOPs optimized SSU-F configuration, a different RAID scheme is used to improve small random I/O workloads.
Each controller can be configured with two or three high-speed network adapters configured with Multi-Rail LNet to exploit maximum throughput performance per SSU-F. A ClusterStor E1000 configuration can be scaled to many SSU-Fs and/or combined with SSU-Ds to achieve specified performance requirements.
E1000 Scalable Storage Unit – Disk (SSU-D)
The E1000 SSU-D provides HDD-based file I/O data services and network request handling for the file system with similar OSS and OST features to the SSU-F. Specifically an SSU-D is a 2U storage enclosure with an HA configuration of dual PSUs, dual server modules (EACs) and SAS HBAs for connectivity to a JBOD disk enclosure. The number of JBODs is customer-configured on order to be 1, 2, or 4.
Each JBOD is configured with 106x SAS HDDs and contains two Lustre OSTs, each configured with ClusterStor’s GridRAID declustered parity and sparing RAID system using LDISKFS or OpenZFS.
As with the SSU-F, each OSS runs on one of the server modules, forming a node, and the two OSS nodes operate as an HA pair. Normally each OSS node owns and operates one of two Lustre Object Storage Targets (OST) in the SSU-D. If an OSS failover happens then the HA partner of the failed OSS operates both OSTs. Both OSSs are concurrently active with each operating on its exclusive subset of the available active:passive OSTs.
ClusterStor E1000 can be scaled to many SSU-Ds and/or combined with SSU-Fs to achieve specified performance requirements.
Comment
Frontier’s Lustre/ClusterStor system is split, and server and target nodes for metadata storage, flash-based data storage and capacity disk-based storage – plus the router nodes so that data referencing or moving compute processes – are separated from basic data storage processing, and enable the whole distributed structure to operate in parallel and at high speed.
Such a complex multi-component system is needed by Frontier to keep its compute nodes fed with the data they need and take away (write) data they produce without bottlenecks freezing cores with IO waits. This structural split between data storage and data access managing nodes may well be needed by hyperscaler IT systems as they approach exascale. They might even be in use deep inside hyperscaler datacenters already.
Note
The ClusterStor E1000 also supports Nvidia Magnum IO GPUDirect Storage (GDS), which creates a direct data path between the E1000 storage system and GPU memory to increase I/O speed and so overall performance.





