


Data analytics startup ChaosSearch is growing like crazy as its analytics software enables more needles to be found in haystacks faster.
The company, which recruited IBMer Ed Walsh as its CEO a year ago, started out as a log data analytics business but is now expanding its remit to include more general, multi-modal analyses of data lakes stored in cloud object storage repositories.
It increased revenues 611 per cent year-on-year — a growth rate indicative of a low starting point — and has doubled its headcount this year and should double again by the end of the year. The headcount increases come off the back of a $40 million B-round fund raise in December 2020.
ChaosSearch also tripled its customer base, which now includes organisations like Equifax, Blackboard, Klarna, Armor, Hubspot, and BAI Communications.
Andreessen Horowitz paper
There is a paper produced by Andreessen Horowitz entitled Emerging Architectures for Modern Data Infrastructure. This nicely, if in a somewhat complicated way, positions data sources, ingests, lakes, warehouses, and analytical operations for newer data infrastructures concerned with data/workflow pipelines for analysing historical and operational data.
Here is the authors’ unified architecture diagram:
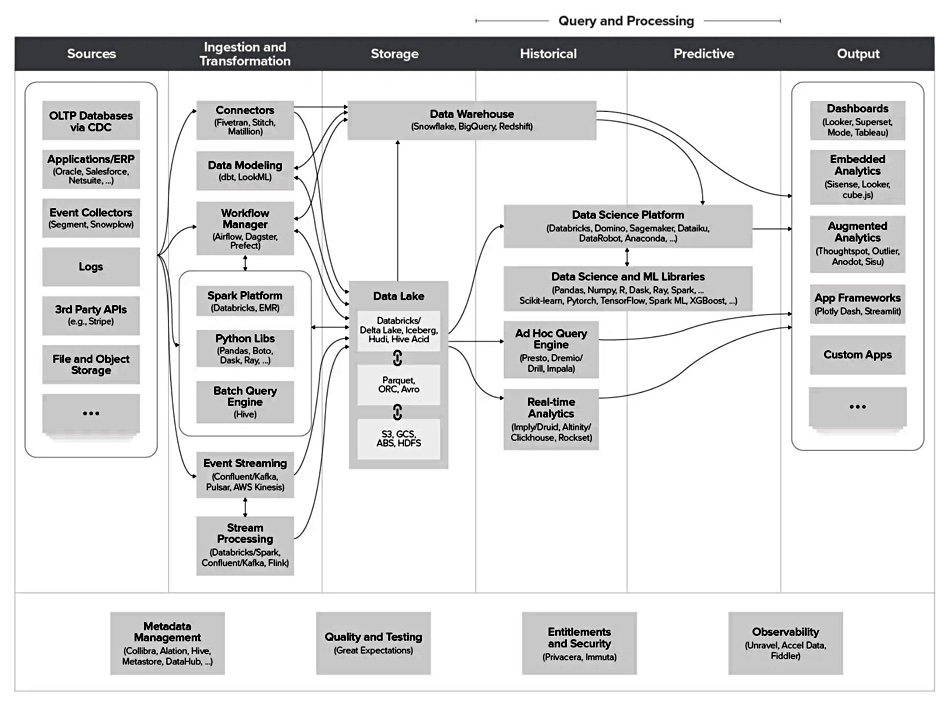
This diagram excludes transactional systems (OLTP), log processing, and SaaS analytics apps.
ChaosSearch would be positioned in the Historical and Predictive columns of this diagram and combine ad hoc queries and real-time analytics.
The paper’s authors point out that the data warehouse is the backbone of the analytics ecosystem, and it needs loading from sources with Extract/Transform/Load (ETL) procedures. Data lakes are the foundation of the operational ecosystem and take in raw data.
There is a trend of developing combined data lake/data warehouse functionality with a unified data representation. If analytics and search runs can take place on raw data, then ETL procedures can be sidestepped.
Indexing background

ChaosSearch CTO Thomas Hazel briefed us about its technology, which is built on a new way of indexing content. For content to be searched it has to be indexed, and an index supporting full text search is large. Hazel found a way of combining compression and indexing that is much more space-efficient than existing methods.
His method takes a source file and compresses and indexes it by separating out what is being compressed — data elements or symbols — from its position in a file.
Imagine a text file which looks like this: “The cat had black hair. The dog had brown hair, unlike the cat.”
We have two occurrences of “cat” — one starting at the fifth byte from the start of the file, and the other starting at the sixtieth byte from the start of the file, if my counting is correct. A single entry for cat would be found in the symbol file and there would be another entry in the position file looking something like this: <5><60>.
The overall space taken up by these two files can be up to 50 per cent less than with existing compression methods such as ZIP. That means that, when the files are loaded into memory for processing, less DRAM is needed.
The data file deliberately loses locality — but the index is lossless. Hazell says this make data reduction — compression and deduplication — much more effective.
The position file is composed of integers and mathematical operations, such as Join and Order, can be applied to them. He says: “By doing this, because locality is [now] so manipulable, the shape or schema can be altered easily. We can apply schemas on the fly. I can do transformations at petabyte scale.”
Hazel says that separate silos are no longer needed, such as ones having extracted, transformed and loaded (structured) data and others for raw, log data. “There are no separate silos. We have it all in ChaosSearch.”
He talked about the Snowflake data warehouse, saying: “it is great at searching relational data but it can’t do things very well with log data; it has no search … You can do Find operations in particular columns but you can’t do full text search.” You can do both with ChaosSearch.
Unified representation
He says ChaosSearch technology can search both operational log data and business intelligence (structured) data “and correlate log data to the BI database.” It’s a unified representation, as described in the Andreessen Horowitz paper.
ChaosSearch is adding relational data search to its product this year along with SQL access to log data.
It stores all its data in cloud object storage, meaning AWS S3, Azure blob and Google Cloud Storage. Hazel suggests a query run via ChaosSearch on a 9TB COS store could complete in seconds. “We’re highly optimised, index-optimised, for COS.”
Check out a detailed look at a white paper describing ChaosSearch’s technology here.
Comment
The notion of combining real-time analytics with historical analyses and methods has also been adopted by Kyligence, also by Ahana.
Dremio also has relevant technology. The whole area is a hotbed of development. We wonder if secondary data management companies like Cohesity and Rubrik will be forging links with analytics companies so that their Cohesity and Rubrik customers can look deeper into all the petabytes of backup data they are amassing.





