


How do you evaluate Kubernetes data protection vendors? According to the GigaOm, there is currently no framework to do this. So the tech research firm is developing a set of key criteria, which it will publish shortly.
Arrikto, Commvault, Dell Technologies, Druva, NetApp, Pure Storage (Portworx) and Veeam (Kasten) all have – or are developing – data protection for cloud-native environments. However, protecting Kubernetes-orchestrated containers is hard.
The basic problem is that a container is an element of an application. But the protection unit of focus is the cloud-native application, and not the potentially hundreds of individual containers that make up the application. Therefore, backing up at the container level makes little sense.
Virtual machines (VMs) by contrast can run applications and act the unit of focus for backup services. “Typically a VM will contain both the data and the application, “Chris Evans, an independent storage architect told us. “The data might be on a separate volume, which would be a separate VMDK file. With the container ecosystem there is no logical connection we can use, because the container and the data are not tightly coupled as they are in a VM.”
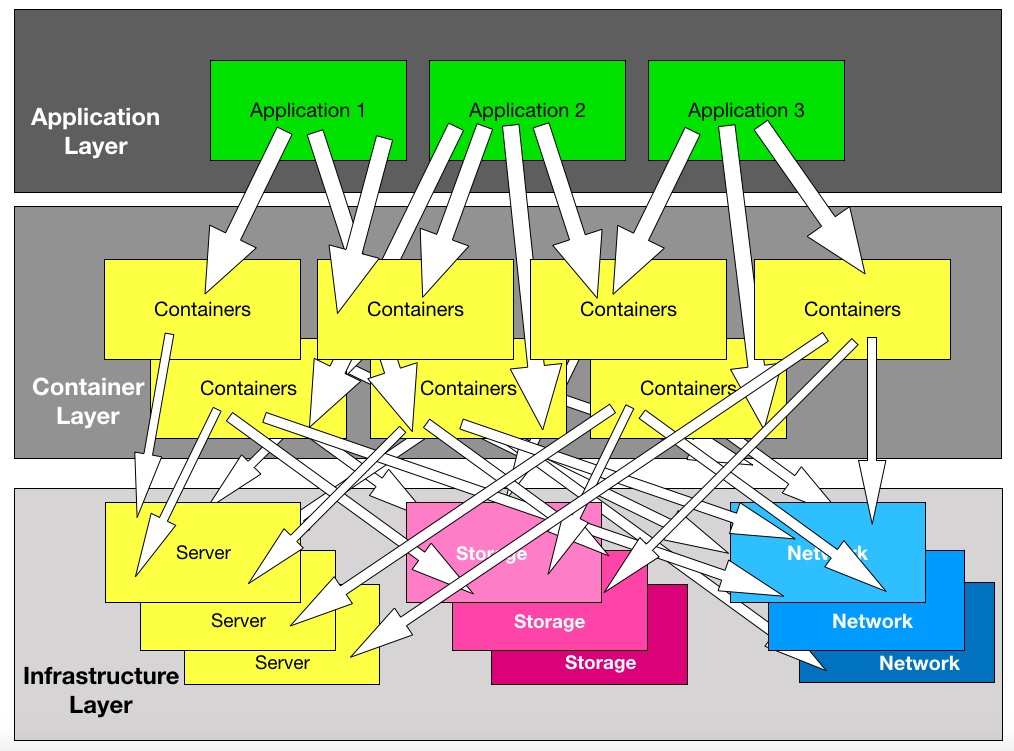
The Kubernetes container storage interface (CSI) provides a persistent volume abstraction but “there is no backup interface built into the platform,” Evans, says. “VMware eventually introduced the Backup API into vSphere that provided a stream of changed data per VM. There is no equivalent in K8s. So you have to back data up from the underlying backing storage platform. As soon as you do this, you risk breaking the relationship between the application and the data.”
GigaOm K8s checklist
GigaOm is developing a Key Criteria for Evaluating Kubernetes Data Protection. We have seen a draft copy.
GigaOm analyst Enrico Signoretti writes: “Traditional backup paradigms and processes don’t work with Kubernetes applications. The speed of change and the diversity of components involved require a new approach, especially when the data protection solution is also a mechanism for enabling data mobility and advanced data services.”
He organises the criteria to be used to judge suppliers’ offerings into three categories: existing table stakes shared by all suppliers, key criteria to differentiate suppliers; and the emerging technologies of which they need to be aware.
Signoretti notes that today’s table stakes are yesterday’s key criteria, and some of the emerging technologies will become key criteria in the future.
The table stakes include native Kubernetes integration, software consumption models, APIs and automation, CSI (container storage interface) integration and security. Every offering should have these.
Concerning security, he notes; “There is no history of ransomware attacks on Kubernetes clusters, and there are no best practices or remediation activities that have been tested in real-world deployments regarding this threat.” This is something that needs to be addressed.
The key criteria list includes multi-cloud support, application environmental awareness, disaster recovery, applications and data migration, and system management.
Signoretti makes this point about disaster recovery: “CSI does not have the necessary level of sophistication to replicate data volumes, applications, or Kubernetes objects to a remote location.” Suppliers will have to build this, using Kubernetes’ snapshots and replication facilities.





