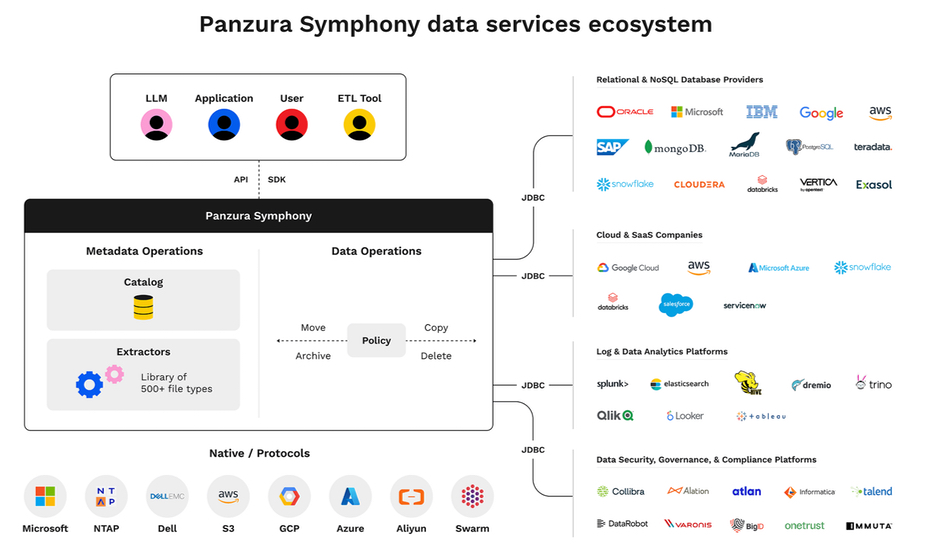
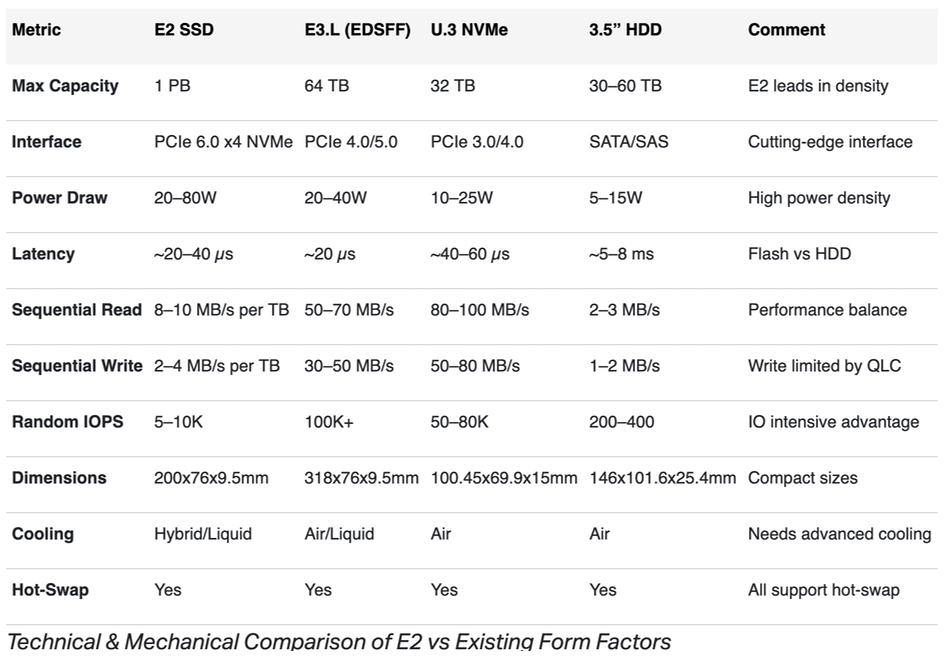
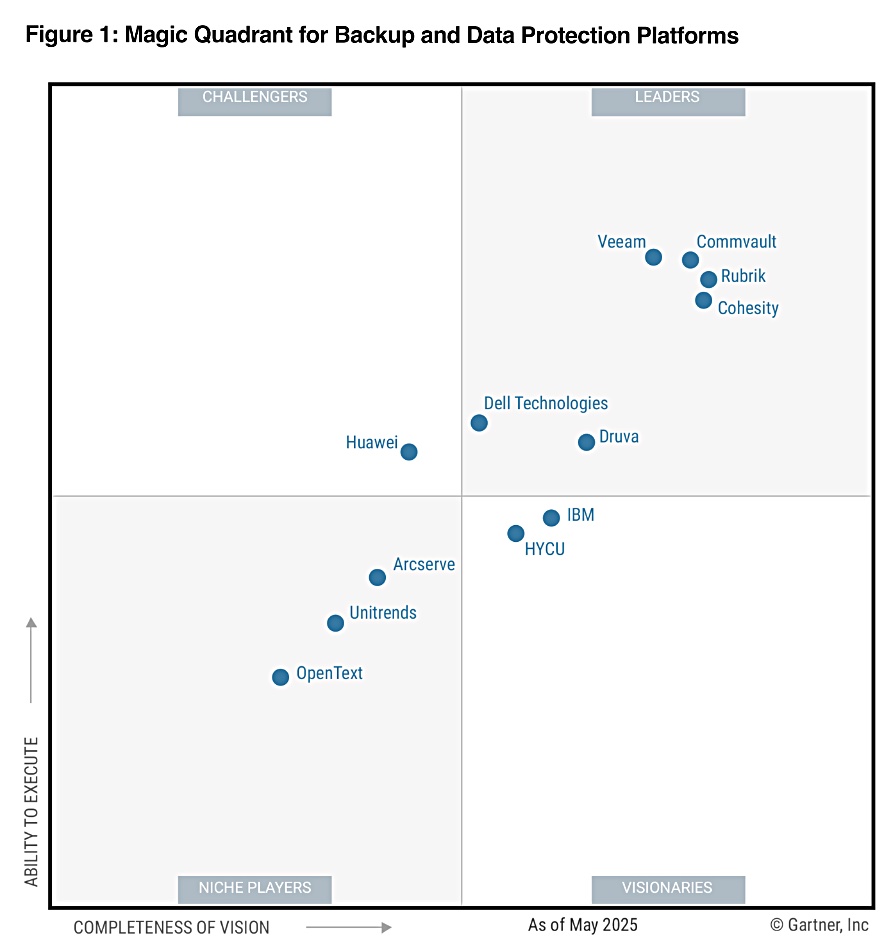
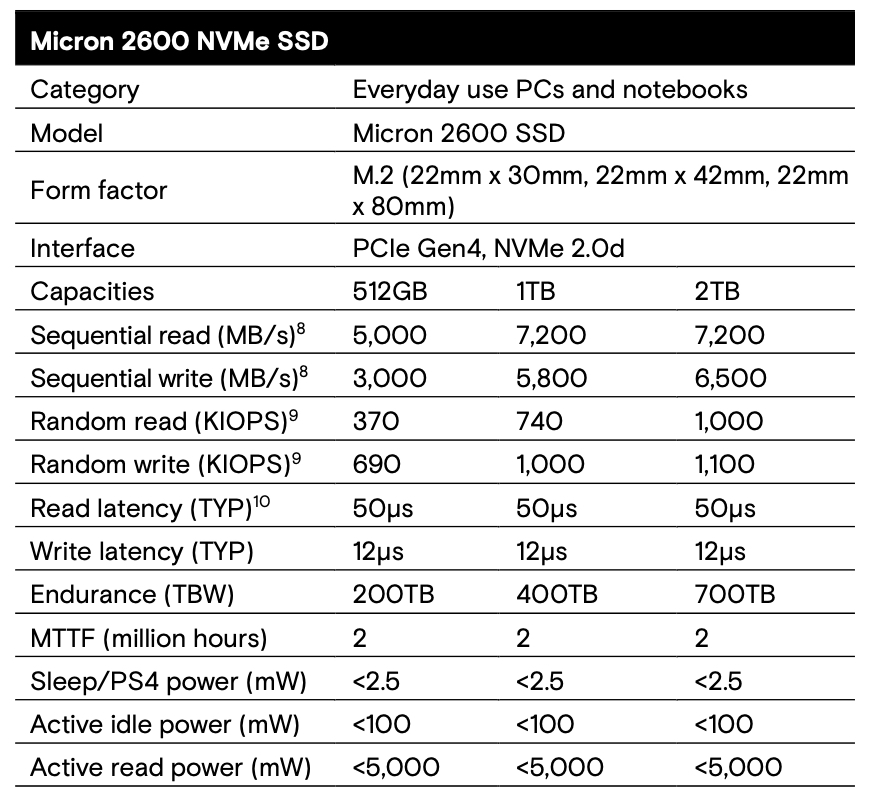
Interview: We had the opportunity to speak with Ahmed Shihab, Western Digital chief product and engineering officer, and he told us that WD’s HAMR tech is progressing well, that OptiNAND can provide a capacity advantage, and that the company has a way to increase the bandwidth per terabyte of disk drives.
Shihab joined Western Digital in March, following more than a year as a corporate VP for Microsoft Azure storage and eight years as AWS VP for Infrastructure hardware. Azure and AWS will be two of the largest hyperscaler buyers for nearline disk drive storage, which is WD’s biggest market. Shihab will have detailed knowledge of how these hyperscalers evaluate disk drive product transitions and what they look out for, invaluable to Western Digital as it follows Seagate with its own HAMR technology transition. It will not want to endure Seagate’s multi-year HAMR drive qualification saga.
Blocks & Files: Could you start by talking about the state of Western Digital and HAMR, how that’s going?
Ahmed Shihab: Actually, I was a little afraid when I first came in. It’s like, what will I find? But I was really happy with what I found because actually HAMR technology works. That’s the good news. Obviously there’s a lot of work to do to get it to the reliability levels and density levels and things like that. So there’s a lot of engineering work. So the physics, we got that done. The basics in terms of the media and the heads and all the recording technology, we got that done. There is a bunch of manufacturing stuff we have to get done to dial everything in. You know how that works. A new technology; you’ve got to do some cleanup from the initial concept.

We have a couple of customers helping us out. So that was always very gratifying. They’re looking at the drives, they’re giving us a bunch of feedback.
One of the lessons we learned is engage your customers early and being a former customer, I really appreciate that because I always wanted to know how. I don’t want to be surprised by the end of the day when somebody comes to me and says, well, here’s our technology now could you start using it? It takes a long time to qualify. So in one of my prior roles, we always engaged early. I encourage my team to engage early with technology so that we can get on the leading edge of its release and that’s what we’re doing.
Blocks & Files: Do you anticipate that the qualification period with hyperscaler customers for HAMR will be as long as the one Seagate has been enduring?
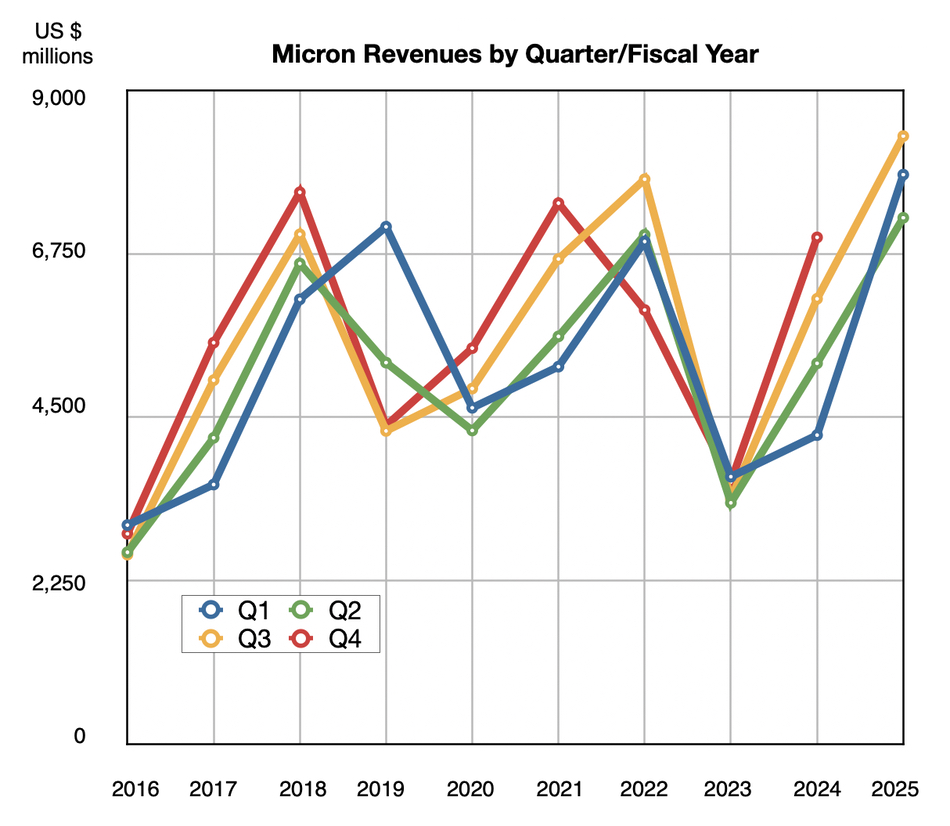
Ahmed Shihab: I hope not. The thing is there’s an advantage to being a fast follow-up because, if you think about it, AWS was always a fast follow-up for a long time and it did us well. We didn’t start leading until the 2017, 2018 sort of time frame and that is a very good philosophy in the sense a lot of the lessons were already learned. Customers will tell us what to expect and what works and what doesn’t. And we’ve certainly benefited from that experience. So that’s one of the things that’s really helping us accelerate that. And we have been working on HAMR for a long time. The ecosystems were mature. We had developed the technology. It wasn’t as much of a focus because we had the density of roadmap in ePMR, which is also unique to us. That takes us into the high thirties, early forties (TB). So we needed to accelerate it. That’s what we’re doing now.
Blocks & Files: Do you think that with an 11-platter technology you have more headroom for HAMR development? It’s less rigorous than for Seagate with its 10-platter technology to match any particular capacity point.
Ahmed Shihab: It certainly gives us more headroom to play with. We can use the extra platter to give us the overall capacity at lower density. So it gives us more headroom. It means we can go to market faster than they can. It’s not a trivial thing to do, obviously, to operate on 11 versus 10. It sounds easy, but all the tolerances, I’m sure you can appreciate, get tight. So we think that is an advantage and we’re certainly taking advantage of it.
Blocks & Files: Will you use what I understand to be the same tactic as Seagate, which is provide lower capacity drives by stripping out platters and heads and using much of the same HAMR technology and manufacturing?
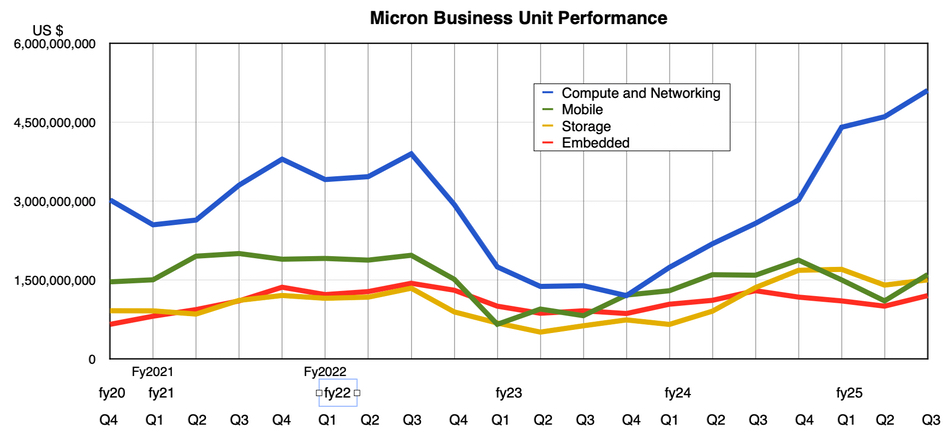
Ahmed Shihab: I think in time, maybe. Right now we don’t need to. Our ePMR technology is mature, it works, it’s high yield, it’s good margins with the OptiNAND and everything else we’re doing. We can actually continue to deliver that technology for some years.
Blocks & Files: Will OptiNAND give you particular opportunities with HAMR drives that don’t accrue to Seagate or Toshiba?
Ahmed Shihab: Let’s look at what OptiNAND does. UltraSMR (shingling) is what really is enabled by OptiNAND and UltraSMR is an algorithmic gain of capacity. Because of OptiNAND, we can actually get more capacity per platter than our competition can. So it’s an algorithmic thing that translates across the technologies. We expect it to apply equally to HAMR. We’re probably going to be a little less aggressive in the beginning, but it has the headroom, and it’s already implemented in the drives because we take technology from PMR to HAMR. It’s just the recording technology that’s different.
Blocks & Files: Does OptiNAND mean that, again, you’ve got a little bit more headroom with HAMR density than you would without it?
Ahmed Shihab: Yes. So one of the things we want to do is to be able to return that capacity to customers and in the beginning you’ll probably see us being a little conservative. We generally are more conservative. Our roots, we came from IBM and HGST and places like that where we are very, how shall I put this? We’re not flamboyant. We always deliver what we say we’ll deliver. As a customer, I’ll give you an example. We had HGST and IBM and WD drives that lasted way, way longer and with less failure rates than the competition. So we’ve always been appreciative of that and that is part of our culture.
We’re not flamboyant. We’re going to go on with it. We’re going to match and exceed Seagate’s capacity because we can win with things like OptiNAND that all our customers have qualified. They have qualified UltraSMR on ePMR. That’s already qualified in their software and we don’t have to do anything different when they come to the new drives with HAMR in them. They’ll qualify them for physical vibrations, all the usual things we help them with. But beyond that, there’s no new software they have to create.
Blocks & Files: How do you see the disk drive market developing?
Ahmed Shihab: One of the things I would say from being a customer is this: disk drives are really the bedrock of all the data economy that’s been developed. Data is constant. If you think about the cloud players’ object store, S3 and Blob stores, and all this data is constantly moving around, moving up and down the tiers, it’s moving to different regions, and moving for maintenance purposes. It’s all transparent to the user. Nobody sees it. You just apply a policy. You might have a trillion objects but it’s one policy and in the background all this data is moving around and being scrubbed and checked for bit rot and things like that.
It’s a very active environment in the background. So this is where we feel that disk drives have stood the test of time because they can deal with the read write endurance, the performance, the bandwidth – performance per terabyte is actually really more important than the IOPS in this space because it’s mostly large objects or large chunks that are moving around. So we see that as continuing. Disk drives are going to continue to be very relevant. There’s some Google papers and there’s a couple of quotes from a distinguished engineer now at Microsoft talking about how important disk drives are and continue to be important for the world. SSDs have their place, they absolutely have their place, and it’s more a question of better together than one versus the other.
Blocks & Files: How about for video surveillance, smaller network attached storage drives and that kind of thing?
Ahmed Shihab: If you think about video surveillance, it’s a very write-intensive workload. The endurance is a big deal and it’s also a very cost-sensitive world. So being 6x cheaper than QLC NAND and having practically infinite endurance, it makes a perfect sense for disk drives to be in that world. That’s definitely what we continue to see in that workload. SSDs tend to do well in very small block-based use cases and in caching use cases and high intensity read use cases.
Blocks & Files: Do you think HDDs will continue to play a role in gaming systems?
Ahmed Shihab: In some, I would say yes. It’s hard to say. The gaming market changes quite quickly. I don’t really have an opinion just yet on that one.
Blocks & Files: Disk drives are pretty much in a fixed format; it’s a 3.5-inch drive bay. And that format has a long life ahead of it because you continually are going to be able to increase capacity. And so the cost per terabyte will continue to slowly edge down and your customers will get more value from disk drives than they can get from any alternate technology, whether it be SSDs above them in the performance space or tape drives below them. Is that pretty much it?
Ahmed Shihab: We actually tried to look at five and a quarter inch drives, things like that. But the three and a half inch, one inch high form factor has really endured; mostly because you have existing infrastructure, you have people who know how to handle it. There’s a whole bunch of operational considerations to do with it. And it wasn’t lack of trying for wanting to change it, but there are practical limitations to do with the rate of spin and the size of the platters and the mechanics about the platters and the vibrations and things like that. So it’s here to stay in my opinion.
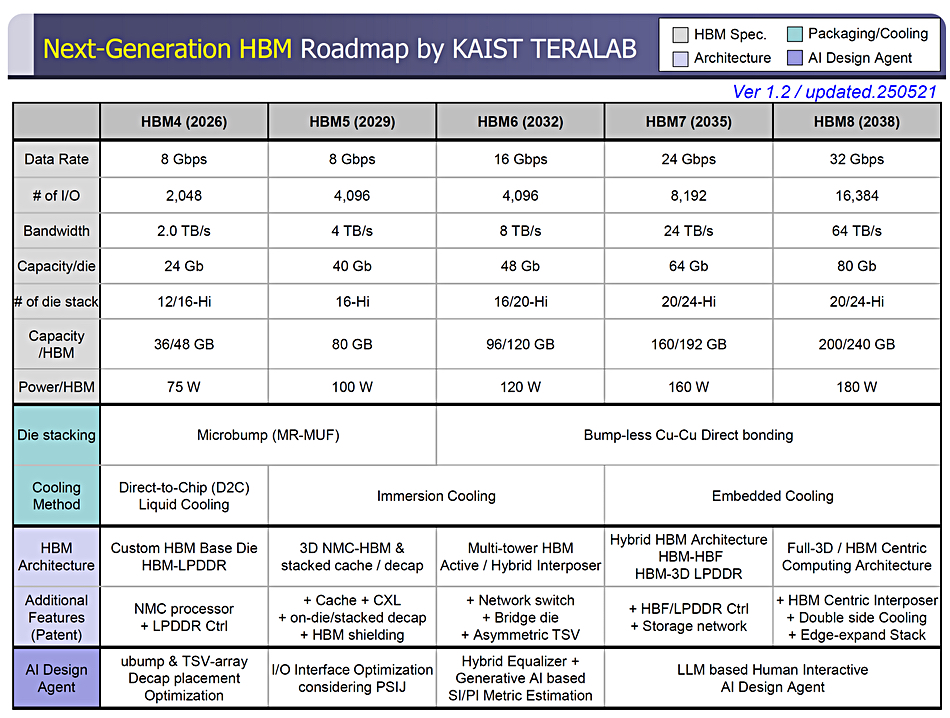
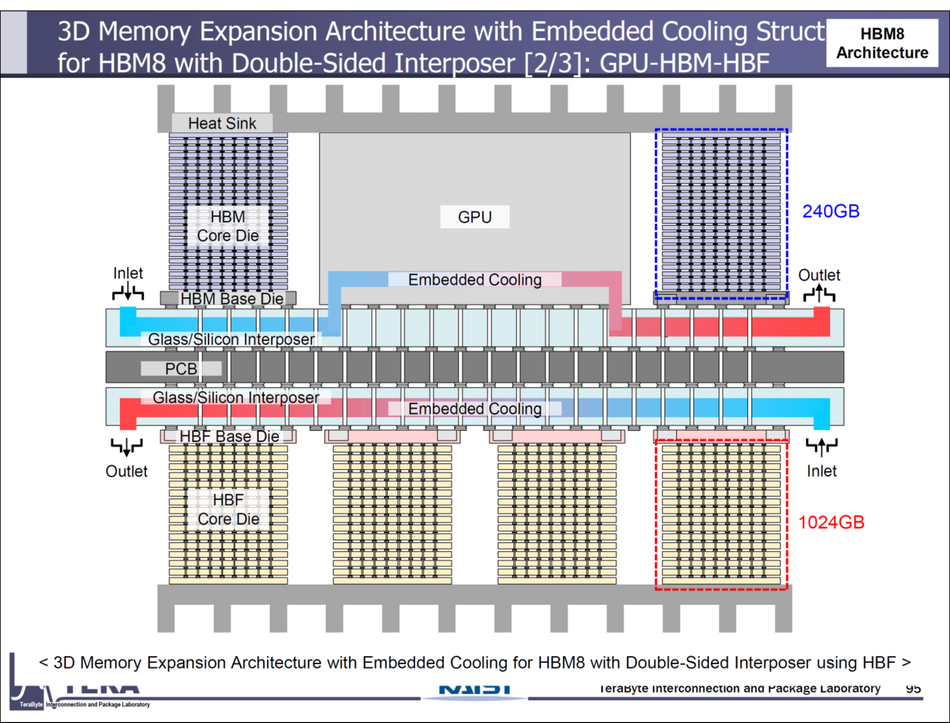
The nice thing is we actually know the physics of the recording technology of HAMR is going to take us for another at least 10, 15, 20 years. There is a whole roadmap ahead of us in that world and that’ll continue to deliver the dollars per terabyte that customers want. And there’s opportunities for us to invent new capabilities. One of the things that we’re very excited about is something new about how we managed to increase the bandwidth per terabyte. So I’m not going to say much more about it, I’m just going to tease it out there. We talked about it publicly also, but it’s something that we’re very excited about.
Blocks & Files: Do you think there’s a future for NVMe access drives?
Ahmed Shihab: The only reason I can think is NVMe will become important is when the bandwidth exceeds the capability of SATA. I think it’s going to be a practical thing that changes it. There’s a lot of ideological conversations around NVMe versus SATA versus SAS and, as a company and as a team, we’re very rooted in pragmatism. If there’s no need for it, don’t do it, because it’s disruptive to customers. And that’s something we’re very careful about, in the sense we want to reduce the friction that customers feel when they’re adopting new technology.
If you think about SMR and what we’ve done with OptiNAND and things like that, we learned a bunch of lessons from that, which is how to make it really super low-friction for customers to get into new drive technology. And we’ve been working with customers for a long time helping them write code, deliver libraries so that they can take better advantage of all the capabilities of drives. So we very much want to work in lockstep with those customers.
So just changing the interface for the sake of it; can we do it? Of course we can do it. Doing NVMe now is not really hard. It’s changing the wire and the protocol. It’s not a big deal. The question is, is the market, our customers, ready for it? Is it necessary? And customers will only do it when it’s necessary.