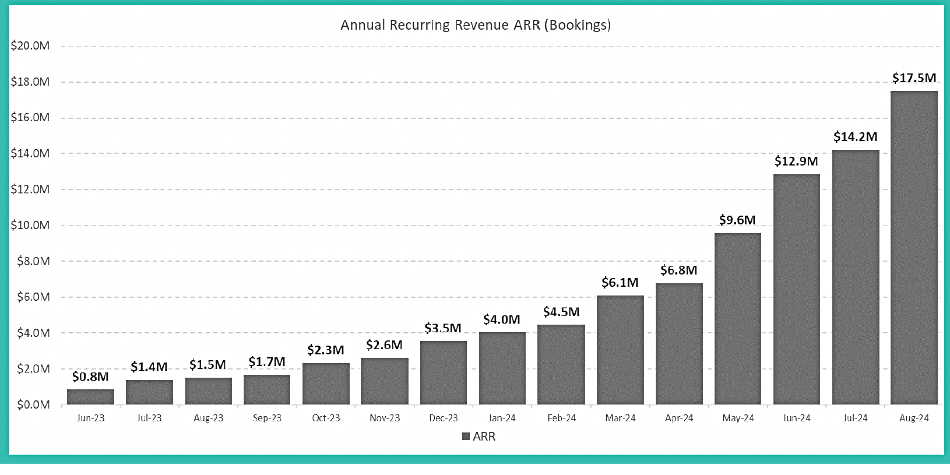
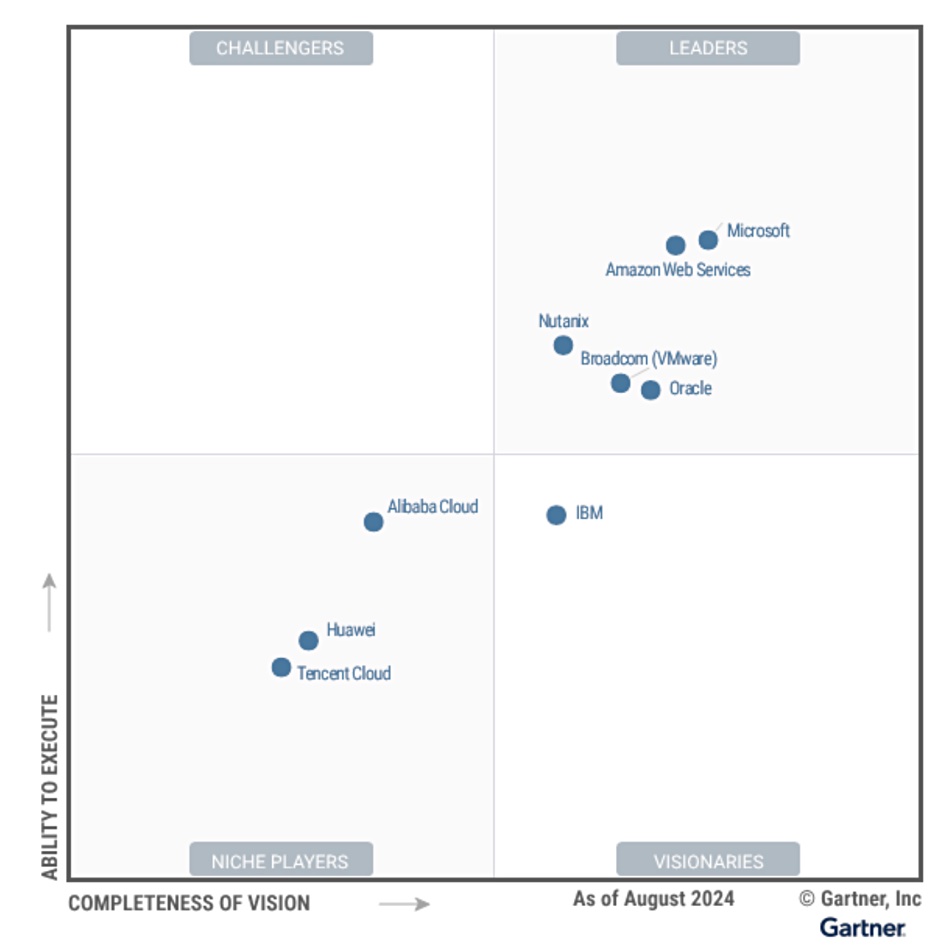
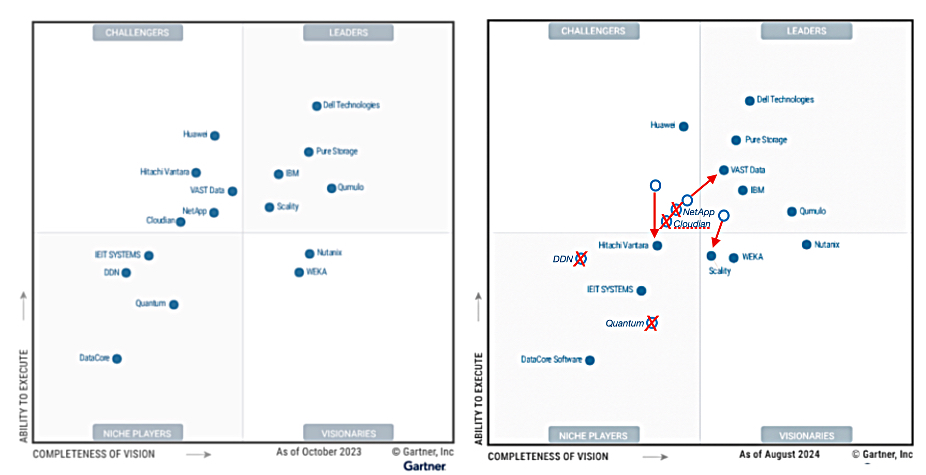
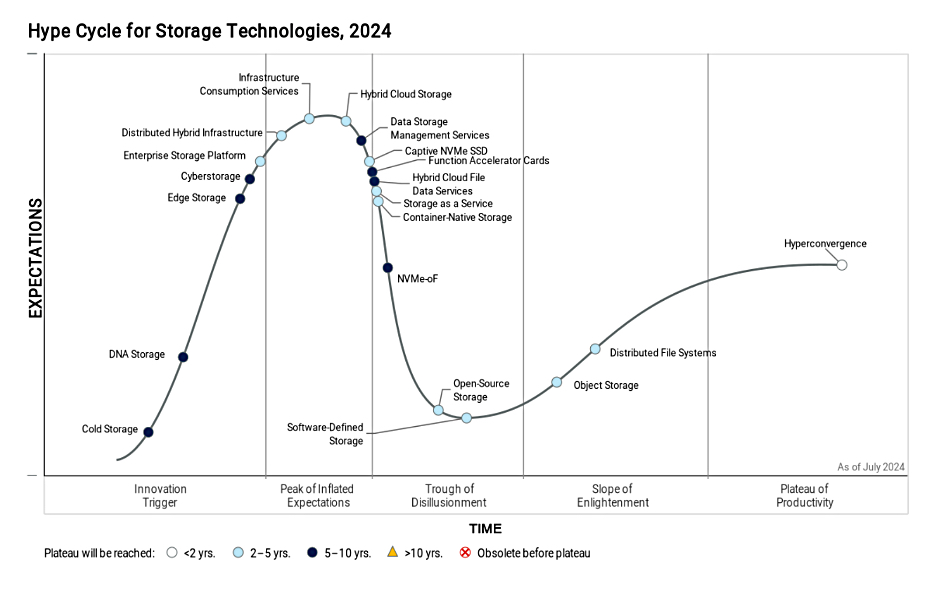
COMMISSIONED: As the world becomes more data-driven, the landscape of safety and security is evolving in remarkable ways. Artificial Intelligence (AI) technology is transforming how organizations manage mission-critical infrastructure, from video surveillance systems to real-time data analysis. At the heart of this transformation lies an important shift: a growing emphasis on the sheer volume of data being collected, how it’s processed, and the insights that can be derived from it. In this evolving ecosystem, edge AI and advanced storage systems are reshaping how security teams work and the role of data in decision-making.
Dell Technologies stands at the forefront of this shift, driving innovation through cutting-edge storage solutions like Dell PowerScale and collaborating with software technology partners to provide smarter, more efficient tools for data management and AI-powered analysis. The opportunities presented by AI in the safety and security space are immense, and the organizations that embrace these advancements will unlock new levels of efficiency, insight, and protection.
The data age in safety and security
Today, security is no longer just about physical safeguards or outdated surveillance systems. It’s about managing vast amounts of data to enhance decision-making, improve response times, and streamline operations. Mission-critical infrastructure now revolves around data volumes and data hygiene – how well that data is stored, maintained, and accessed. In this new paradigm, we see a shift in who’s attending security meetings: Chief Data Officers (CDOs), data scientists, and IT experts are playing pivotal roles in shaping security strategies. They’re not only ensuring systems run smoothly but also leveraging video data and AI-driven insights to drive broader business outcomes.
The introduction of AI into security systems has brought new stakeholders with unique needs, from managing complex datasets to developing real-time analytics tools that improve efficiency. For instance, consider the rise of body cameras equipped with edge AI capabilities. These cameras are no longer just passive recording devices – they’re active data processors, analyzing video footage in real time and even assisting officers in the field by automatically annotating scenes and generating reports. This reduces the time officers spend writing reports at the station, improving productivity and allowing for faster, more efficient operations.
Technologies transforming the security ecosystem
One of the most exciting aspects of AI technology in the security space is the way it is enabling new players to emerge. Independent Software Vendors (ISVs) are stepping into the fold, introducing a range of applications aimed at enhancing organizational efficiency and transforming the traditional security landscape. These new ISVs are bringing innovative solutions to the table, such as edge AI applications that run directly on video surveillance cameras and other security devices.
These advancements have revolutionized how data is collected and processed at the edge. Cameras can now run sophisticated AI models and Video Management Systems (VMS) onboard, transforming them into intelligent, autonomous devices capable of making decisions in real-time. This shift toward edge computing is powered by the increasing presence of Graphics Processing Units (GPUs) at the edge, enabling high-performance AI computing on-site.
For security integrators, this evolution has been transformative. The emergence of edge AI has introduced a new skill set into the industry – data scientists. Traditionally, security teams focused on camera placement, network design, and video storage. Now, they must also manage complex AI models and large datasets, often requiring the expertise of data scientists to oversee and fine-tune these systems. This shift is opening the door for new ISVs and dealers, changing the service landscape for security integrators.
The changing role of storage in AI-powered security
One of the most critical aspects of this AI-driven revolution in security is the need for robust, scalable storage solutions. Traditional storage systems, such as RAID-based architectures, are simply not up to the task of handling the demands of modern AI applications. AI models rely on massive datasets for training and operation, and any gaps in data can have a detrimental impact on model accuracy. This is where advanced storage solutions, like Dell PowerScale, come into play.
Dell PowerScale is designed specifically to meet the needs of AI workloads, offering extreme scalability, high performance, and superior data management. As video footage and other forms of security data become more complex and voluminous, traditional storage systems with Logical Unit Numbers (LUNs) struggle to keep pace. LUNs can complicate data mapping for data scientists, making it difficult to efficiently analyze and retrieve the vast amounts of data generated by AI-driven security systems.
In contrast, PowerScale provides seamless, flexible storage that can grow as security systems expand. This is crucial for AI models that require consistent, high-quality data to function effectively. By offering a scalable solution that adapts to the changing needs of AI-powered security applications, PowerScale ensures that organizations can maintain data hygiene and prevent the bottlenecks that would otherwise impede AI-driven insights.
Edge AI and the future of security
The advent of edge AI is arguably one of the most transformative developments in the security industry. By processing data closer to where it’s collected, edge AI enables real-time decision-making without the need for constant communication with centralized cloud servers. This shift is already being seen in body cameras, security drones, and other surveillance tools that are equipped with onboard AI capabilities.
As GPUs become more prevalent at the edge, the compute and storage requirements of these devices are evolving as well. Cameras and other edge devices can now run custom AI models and scripts directly onboard, reducing latency and improving response times. However, this also means that security teams must manage not only the hardware but also the datasets and AI models running on these devices. Data scientists, once peripheral to the security industry, are now becoming essential players in managing the AI models that power edge-based security systems.
This evolution is also changing the nature of cloud services in the security space. Edge computing reduces the reliance on cloud-based storage and processing, but it doesn’t eliminate it entirely. Instead, we are seeing a more hybrid approach, where edge devices process data locally and send only critical information to the cloud for further analysis and long-term storage. This hybrid approach requires a new level of agility and flexibility in both storage and compute infrastructure, underscoring the need for scalable solutions like PowerScale.
Embracing AI and data-driven security
Despite the clear advantages of AI and edge computing, the security industry has been slow to adopt these technologies. For over six years, IP convergence in security stalled as organizations hesitated to move away from traditional methods. A lack of investment in the necessary skills and infrastructure further delayed progress. However, the time for change is now.
As other industries move swiftly to embrace AI-driven solutions, the security sector must follow suit or risk falling behind. The convergence of AI, data science, and advanced storage solutions like Dell PowerScale represents a tremendous opportunity for growth and innovation in safety and security. Network value-added resellers (VARs) are well-positioned to capitalize on this shift, offering modern mission-critical architectures that support AI-driven security applications.
The future of security lies in data – how it’s collected, processed, and stored. With the right infrastructure in place, organizations can unlock the full potential of AI, driving greater efficiency, faster response times, and more effective security outcomes. Dell Technologies is committed to leading the charge in this transformation, providing the tools and expertise needed to support the AI-powered security systems of tomorrow.
The security industry is at a pivotal moment. The rise of AI and edge computing is transforming how organizations approach safety and security, but these advancements require a shift in both mindset and infrastructure. Dell Technologies, with its industry-leading storage solutions like PowerScale, is helping organizations navigate this new landscape, ensuring they have the scalable, high-performance infrastructure needed to unlock AI’s full potential.
As we move deeper into the data age, embracing these emerging technologies will be critical for staying ahead of the curve. The future of security is bright, but only for those prepared to invest in the right infrastructure to support the AI-driven innovations that will define the next era of safety and security.
For more information, visit Dell PowerScale.
Brought to you by Dell Technologies.