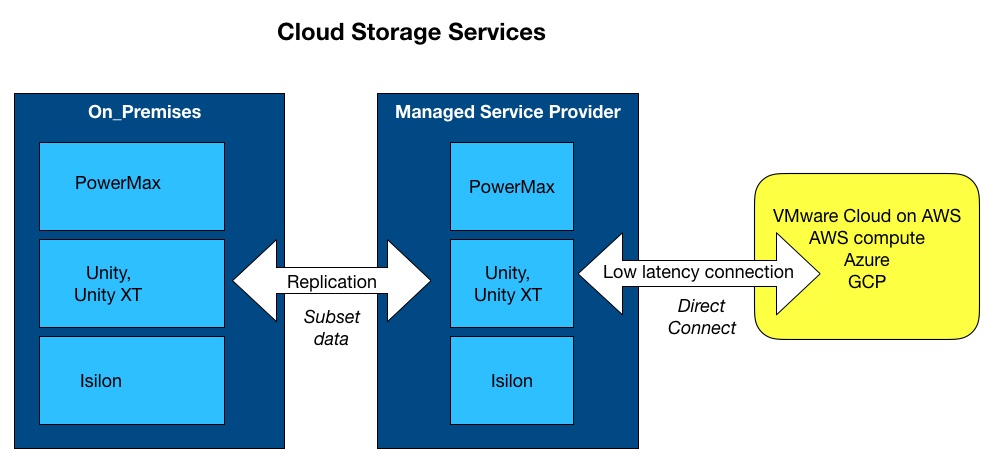
Dell Technologies World Dell EMC has announced Cloud Storage Services, a disaster recovery option that removes the need for a separate storage DR site and so cuts costs. The service uses the public cloud and an MSP intermediary instead.
The service is a two-stage affair where customers replicate data to an MSP (managed service provider) facility, which has a Direct Connect link to a public cloud.
When disaster strikes at the on-premises site the compute switches to the public cloud and the stored compute instances access data on the arrays using a Direct Connect link. Claimed speed is 3msec or faster.
Cloud Storage Services supports PowerMax, Unity and Isilon on-premises arrays. The SC arrays are not supported.
Arrays without a Direct Connect link could take up to a second or more to replicate data to the public cloud, depending on network bandwidth.
Dell envisages customers will typically replicate a subset of data to the MSP site, so the arrays there would be smaller than their on-premises relatives.
This is similar to NetApp’s 2012 vintage NetApp Private Storage which “allows one to place a NetApp FAS appliance in a data centre – specifically one where Amazon’s Direct Connect is operating – from where it will be available for “immediate use via iSCSI to and from their EC2 environment.”
Cloud Storage Services supports four public cloud targets: VMware Cloud on AWS, AWS, Azure and GCP. Dell EMC said the multi-cloud approach enables compute instances in each cloud to access the MSP arrays. There is no need to move data to these clouds or to pay for storage. Users pay only for the compute in the cloud when it has to be used.
Customers running VMware environments can implement a DR system using VMware Cloud on AWS as the secondary site. VMware Site Recovery Manager, along with native replication of the Dell EMC storage arrays, enables automation of DR operations.
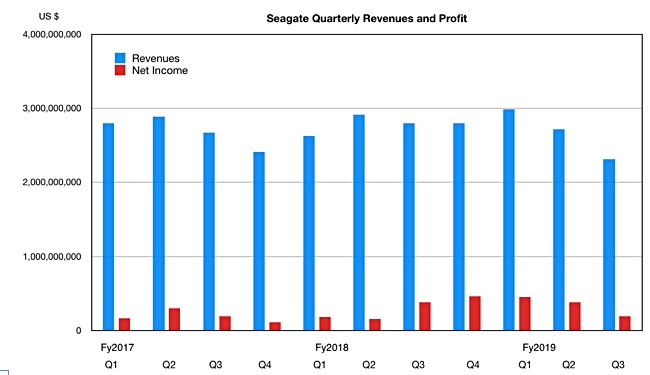
Seagate’s third fiscal 2019 quarter was hit by falling disk drive demand.
Revenues of $2.3bn ($2.8bn Q3, 2018) were 17.5 per cent lower and net income fell 488 per cent to $195m ($381m).
Seagate’s fourth quarter outlook is continued decline, with mid-point revenues of approximately $2.32bn, down 17.1 per cent ($2.8bn).
Nonetheless the relative performance was better than arch-rival Western Digital accomplished with its latest quarter’s revenues of $3.7bn – 26 per cent down on a year ago. Last year’s $61m net income turned into a thumping $581m loss for WD.
Seagate CEO Dave Mosley talked of successfully navigating “near-term demand head-winds.” And he expects “broader demand recovery starting in the second half of the calendar year.”
Seagate’s recent revenues and profits history, showing the Q3 fy’19 slump.
In the earnings call Mosley said: “In the edge compute market, revenue was impacted by the expected transition to SSDs, ongoing CPU shortages, and seasonal demand slowdown for Notebooks and desktop PCs. In the surveillance market, revenue remained suppressed by economic and geopolitical uncertainties…In the enterprise market, both seasonal and macroeconomic challenges weighed on revenue for our Nearline drives.”
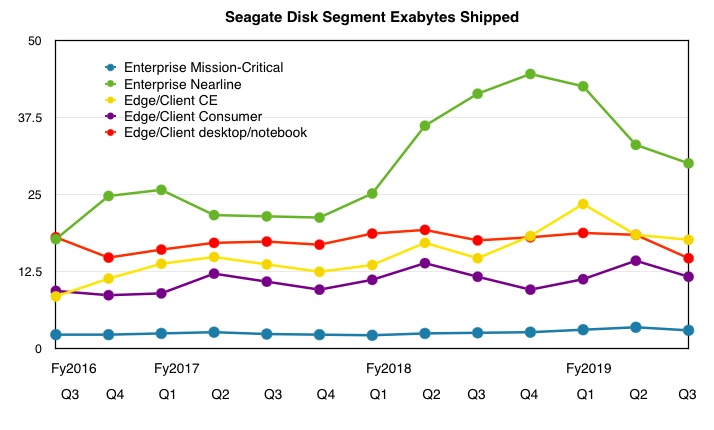
Shipments
The company shipped 76.7EB of capacity, which was divided between five categories of drive.
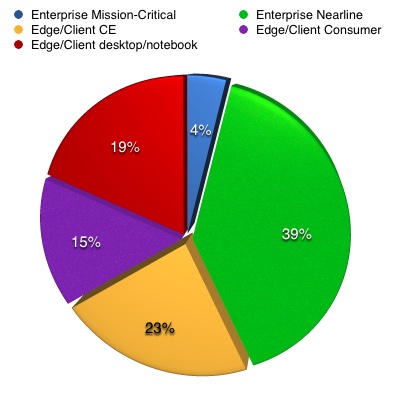
All segments were down Q-on-Q for Q3 fy19 but Edge/Client CE and consumer and Enterprise Mission-Critical were up y-on-y. The other segments were down, led by Enterprise Nearline
A pie chart shows the segment split for the latest quarter:
HAMR time
Mosley also dropped a surprise into the results release: “We began shipping the industry’s first 16-terabyte high capacity drives in the fiscal third quarter and expect to ramp high volume production in the second half calendar 2019.” Deliveries started in March and “qualifications are underway at many major cloud and enterprise customers.”
Seagate expects to “begin ramping to high volume later in calendar 2019 and expect 16 terabyte drives will be our highest revenue SKU by this time next year”.
Seagate’s 16TB monster is a 9-platter/18 head drive. Western Digital is prepping an 8-platter/16 head MAMR drive for launch in late 2019. It hopes the lower platter and head component count will give it a cost advantage.
Mosley expects to ‘introduce drives with over 20 terabytes of capacity in calendar year 2020.” These will use its Heat-Assisted Magnetic Recording (HAMR) technology.
He added: “We believe HAMR high density drives combined with our multi-actuator technology will not only address the heavy workloads and high utilisation rates required by large cloud data centres, but also new use cases that are emerging at the edge.”
The Snowflake board has dumped chairman and CEO Bob Muglia and brought in former ServiceNow boss Frank Slootman to replace him.
Founded in 2012 venture-backed Snowflake provides a data warehouse in the cloud, atop AWS or Azure.
Muglia has been Snowflake’s Chaiman and CEO since July 2014, and has raised an astonishing $923m in funding in that time, with the latest round for $450m completed in October 2018.
At the time Muglia said: “Our post-money valuation is now $3.9bn making Snowflake amongst the top 25 most highly valued private US tech companies. This funding is also the fifth ever largest private company financing in enterprise software.”
Muglia is now history. Mike Speiser, venture capitalist and board director at Snowflake, said in a statement: “Snowflake is one of the most significant new companies in Silicon Valley and we believe Frank is the right leader at this juncture to fully realize that potential. The best time to make a change is when things are going well. We’re thrilled to have Frank take the helm at Snowflake. We also wish to recognise the incredible role Bob Muglia has played over the past five years to get us to this point.”
Bob Muglia.
Frank Slootman
New broom Frank Slootman was the chairman and CEO at ServiceNow from April 2011 to March 2017. Before that he was president and CEO of Data Domain, which was bought by EMC in June 2009 for $2.4bn.
ServiceNow IPOed in June 2012, raising $210m.
Blocks & Files thinks Slootman’s track record of acquisition and successful IPO-based growth must have been attractive to Snowflake’s investors, looking for a great exit.
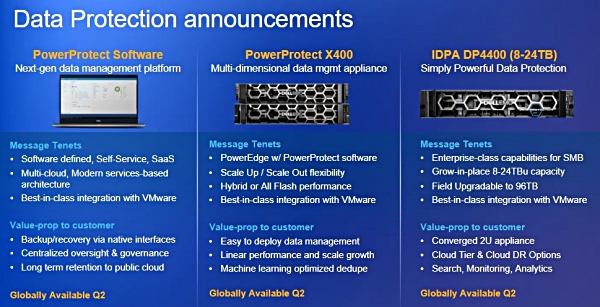
Dell Technologies World Dell EMC today announced new PowerProtect data protection hardware and software, along with an entry-level DP440 integrated data protection appliance.
In our opinion, PowerProtect has emerged as Dell EMC’s main integrated data protection appliance range. The PowerProtect software is an alternative to backup software products such as BackupExec and NetBackup, and the X400 appliance competes against target purpose-built back appliance such as a Data Domain system.
The PowerProtect hardware system has direct backup to component capacity nodes to avoid a central controller bottleneck slowing operational speed as the system scales up.
PowerProtect software
The Dell EMC PowerProtect Software is called a platform and provides data protection, replication and re-use. It supports long-term retention in the public cloud and is described as a multi-cloud product.
Dell EMC slide.
Backed up data and virtual machines data are live mounted by VMs in client servers. The data is used, for example, for database patch testing or some other test and dev requirement.
PowerProtect software can run stand-alone on a server and send protection data to a target backup array, such as Data Domain. Alternatively it can run in the X400 appliance.
Agents
The appliance supports Oracle, Microsoft SQL, VMware, Windows and Linux file systems workloads and users can perform backup and recovery operations from their native applications. Agents are used with the data sources.
These agents run Data Domain Boost source deduplication software, which part-deduplicates the data stream and the target PowerProtect system (Or X400 capacity node) completes the work. This increases the data ingest speed.
The agents also send workload type data to the PowerProtect software which can use this for data placement in the X400 appliance.
The software has SaaS-based management and self-service capabilities that give individual data owners the ability to control backup and recovery operations.
VMware vSphere customers get automated policy-based backup and recovery and integration with vRealize Automation.
There’s a PowerProtect software roadmap and this includes Cloud DR, Office 365 support, multi-tenancy and RST API availability. An in-built deduplication engine could be added to the software.
NAS is not supported, neither is NDMP, or other target devices apart from Data Domain. However, these could be items on the roadmap.
Update: There is a large set of Data Domain Boost agents, larger than the comparatively few that PowerProtect supports in its first release. For example, there are Data Domain Boost agents for Cassandra, MongoDB and Hadoop. It seems readily apparent that PowerProtect could expand ts source application support list by using existing Data Domain Boost agents.
PowerProtect software could also run on the VxRAIL hyper-converged system. The software can run on any VMware-certified server.
PowerProtect X400
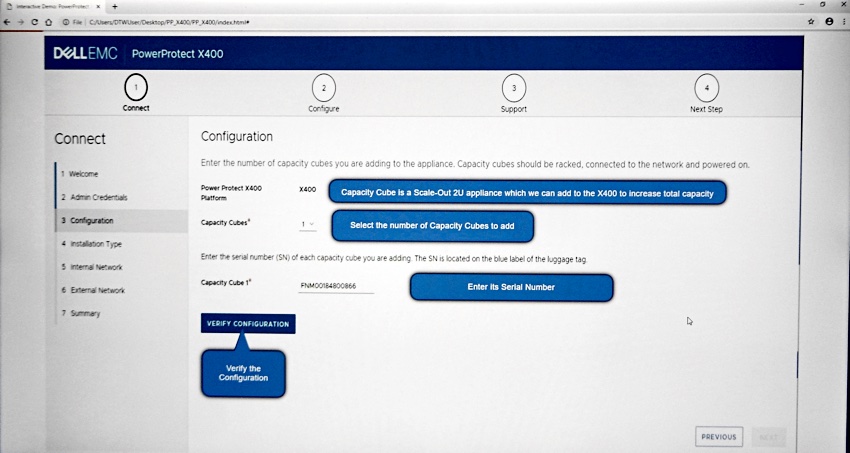
The X400 PowerProtect hardware combines PowerEdge servers, with local flash (X400F) or hybrid flash+disk storage (X400H), and PowerProtect software. It can scale-up with capacity expansion and scale-out compute power, capacity and network bandwidth by adding X400 nodes, called cubes in Dell EMC’s vernacular, although as 2U rack enclosures they are not cubic in shape.
Dell EMC PowerProtect X400 slide.
The base appliance configuration is an X400 platform cube (2U) and one to four X400H or X400F scale-out cubes (2U) for capacity. Currently you cannot mix X400F and X400H capacity cubes in a single X400 appliance.
X400H cubes have from 64TB to 96TB of usable capacity, while an X400F cube has from 64TB to 112TB. We don’t know what kind of SSDs are being used.
In-cube capacity expansion is accomplished through a license upgrade as cubes are shipped fully populated.
X400 expansion desktop.
Data is sent directly to the capacity cubes across 10 or 25GbitE links; it not being routed through the base platform cube. The core cube is a management system, a control plane, and not in the data plane.
Data placement in an appliance and its capacity cubes is driven through a machine learning-based load balancing scheme. As scale-out cubes are added the system will rebalance, with data migrated to an appropriate scale-out cube with available resources.
The data placement uses workload characterisation to move data to the appropriate cubes to maximise overall deduplication. Exactly how it decides on data location placement is proprietary information.
If a workload is moved from one cube to another as part of a rebalancing exercise it does not lose its deduplicated state, and the control plane software remaps the incoming source data stream to the new cube without any change being needed on the source system.
Effectively it’s a hyperconverged data protection system that, Dell EMC says, enables users to protect, manage and recover data at scale.
The roadmap includes increasing the number of capacity cubes from 4 to 8 and on to 12.
We might consider the idea of having two fully populated X400s, with 12 capacity cubes each, co-ordinated in some way by a super-controller.
Limited deduplication
The system has built-in deduplication but the scope is limited to single capacity cubes in this first release of the PowerProtect software. It does not have a global scope across the cubes in an X400 appliance or, indeed, across X400 appliances.
Dell EMC said such global deduplication could slow the data ingest speed and that this is undesirable.
Dell EMC logical capacity tables use a 10X to 50X deduplication ratio. For example, Dell EMC suggests an X400 scale-out cube with its 64TB to 112TB of usable capacity, can have a 640TB to 5.6PB logical (deduplicated) capacity. The range is very wide so customers should run proof of concepts at their own sites to find the deduplication ratio they actually experience.
Blocks & Files’ understanding is that global deduplication across the capacity cubes may make it to a a future roadmap.
But the PowerProtect group needs to find out first if this delivers appreciable improvements in the overall deduplication ratio. Also any extra work in co-ordinating deduplication tables between capacity modes should not place too much demand on the system.
Data management
PowerProtect software has some data management, data reuse features, but there is nothing in this first release to cause concern to specialist data management, data analysis, and copy data re-user companied. However this is a possible development direction for Dell EMC if it wants to tackle the likes of Actifio, Cohesity, Delphix, and Rubrik head-on
The X400 has SaaS-based management, compliance and predictive analytics.
The all-flash PowerProtect X400F differs from the Pure Storage FlashBlade product which, although used as an all-flash backup target, is not positioned as a data protection appliance.
IDPA DP4400 low capacity version
Dell EMC has announced the availability of an 8-24TB version of its Integrated Data Protection Appliance (IDPA) DP4400. This is intended for smaller organisations and remote offices and can grow in place up to 96TB with the purchase of license keys and an upgrade kit.
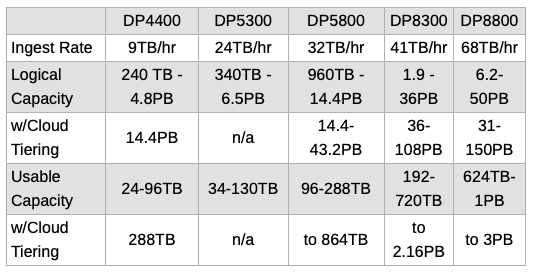
The IDPA systems run Avamar software and are hybrid, flash and disk-based. They overlap the PowerProtect X400H in capabilities, as this IDPA product table shows:
A DP4400 is roughly similar to an X400H chassis. The X400 core platform can scale out to four X400H chassis and 384TB of usable capacity – the same usable capacity range as the DP4400, DO5300 and DP5800. It doesn’t reach the DP8300 and DP8800 capacity levels .
Dell is not positioning PowerProtect as competitor to more complex Avamar/Networker products.
Feel the Power
Dell EMC is consolidating storage, servers and networking brands to single product lines, all with Power branding. The company has already released PowerSwitch networking, PowerEdge servers, PowerMax high-and arrays and PowerVault entry-level arrays.
Blocks & Files thinks that the PowerProtect line will be Dell’s main data protection appliance line going forward and the IDPA product set may diminish in importance over time.
Availability
The PowerProtect Software platform and PowerProtect X400 appliance is generally available in July 2019. The 8-24TB DP4400 is generally available in May 2019.
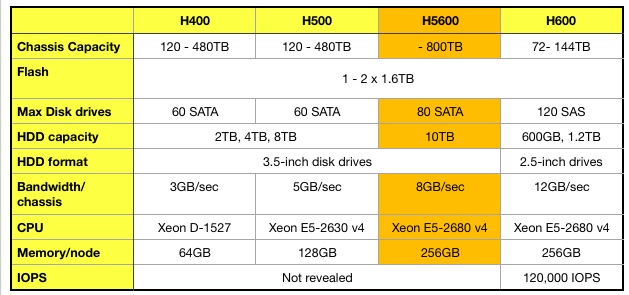
Dell Technologies World Dell EMC has added an Isilon H5600 general scale-out file storage cluster node, using a mix of SSDs and disk drives. It comes with a new version of the OneFS operating system, v8.2, which enables Isilon clusters to grow to 252 nodes, storing up to 58PB.
This is the first cluster node count jump for many years – Isilon clusters traditionally have a 144 node limit. The upgrade equips Isilon to cope with much bigger data sets.
An Isilon cluster can now offer up to 945 GB/sec aggregate throughput, darn close to 1TB/sec The OS refresh also increases cluster performance by up to 75 per cent to 15.8m IOPS.
The H5600 offers more capacity and performance than the current entry and mid-range hybrid models but is slower than the high-end hybrid Isilon system.
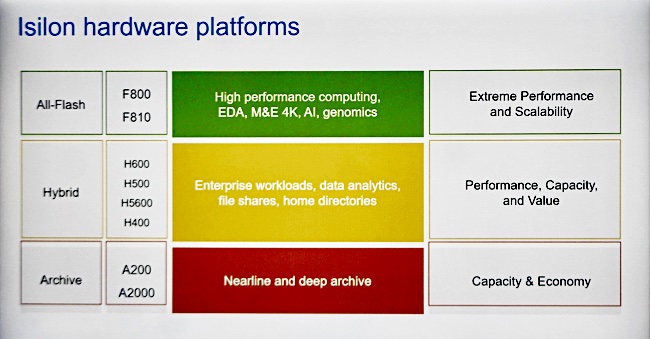
Isilon hardware range
There are three Isilon hardware product groups:
H5600 chassis.
F800 and F810 all-flash nodes for the highest performance,
H600, H500, H5600, and H400 hybrid flash/disk general nodes
A200 and A2000 nearline and archive nodes
By tabulating the main hybrid range’s hardware characteristics we can see that the H5600 essentially uses the high-end H600’s CPU and memory while retaining the 3.5-inch capacity disk drives from the H400 and H500. It has 20 extra drive bays compared to these systems, and a drive capacity jump from 8TB to 10TB.
This takes the H5600 chassis capacity up to 800TB, almost doubling the 480TB limit of the H400 and H500.
OneFS 8.2 software is available now and the H5600 will be generally available in June 2019.
Dell Technologies World Dell EMC’s new Unity XT arrays add drives, memory and CPU power, with the hybrid models getting a stronger upgrade punch than their all flash cousins.
Unity arrays are unified midrange file and block arrays, positioned between entry-level PowerVaults and high-end PowerMax arrays.
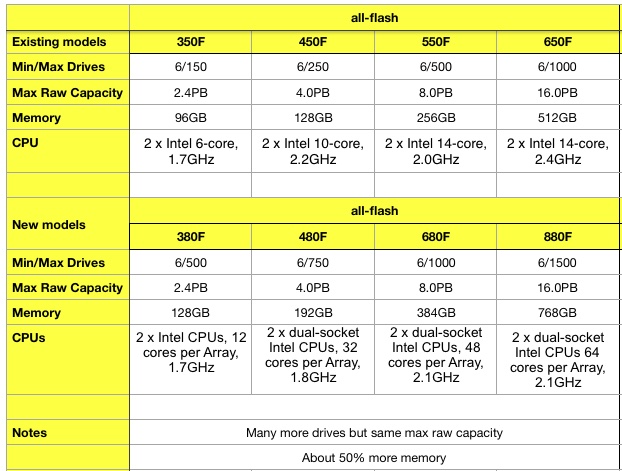
They are available as all-flash and hybrid SSD/disk drive systems, with four products in each category. The current all-flash models are the 350F, 450F, 550F and 650F and the hybrid models are the 300, 400, 500 and 600.
The new all-flash Unity XT models are the 380F, 480F, 680F and 880F, and Dell EMC said the 880F is twice as fast as its predecessor, the 650F. They are also 67 per cent faster than their closest un-named competitor.
A table gives a snapshot of how they differ from the old Unity all-flash arrays:
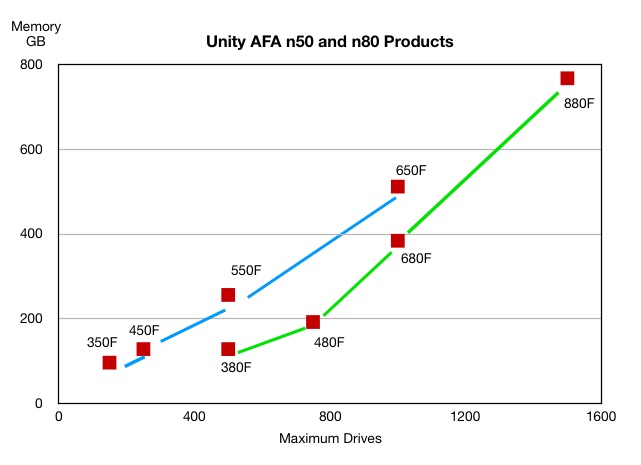
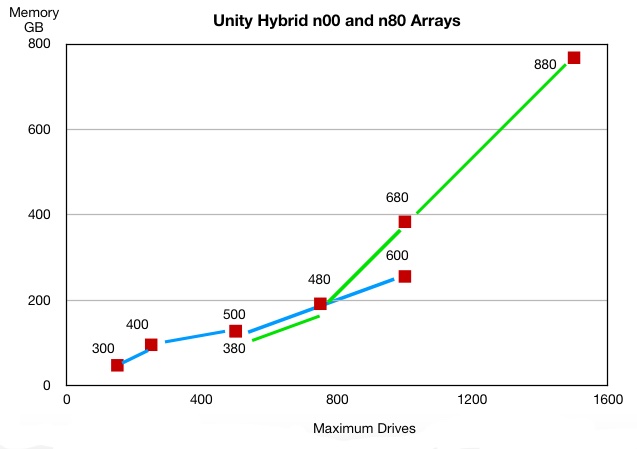
Sticking the memory and maximum drive numbers in a chart makes the differences between old and new readily apparent:
The blue line connects the old old Unity AFAs which are positioned in a 2D space defined by memory capacity and the maximum number of drives.
The green line connects the new models and it is obvious that they have more drives and more memory.
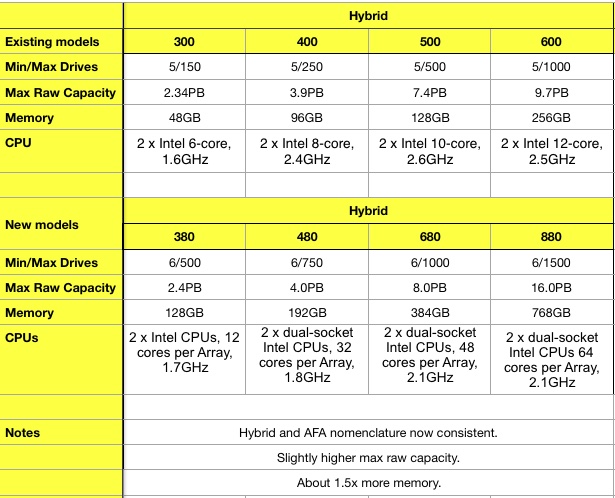
We can do the same for the hybrid models, with a table first:
A second 2D scatter chart shows a larger difference between the old and new hybrid arrays than between the flash Unity arrays:
The blue line connects the old systems, with the green line connecting the new systems. In terms of maximum drives and memory, one configuration is common between old and new. The old 500 has the same memory and maximum drive count as the new 380. This is now the entry-model instead of upper mid-point in the range.
The new hybrids have the same max drive count and memory capacity as the new Unity AFAs.
The new Unity arrays are SAS-based but are said to be ready for NVMe adoption. NVMe support had been expected…but not yet.
Unity arrays are validated as building blocks for the Dell Technologies Cloud. Unity XT Series arrays will be generally available in July 2019.
Western Digital was hit by weak disk drive demand and over-supply-induced flash price cuts in its third fiscal 2019 quarter. When will things improve for the flash, SSD and disk drive manufacturer?
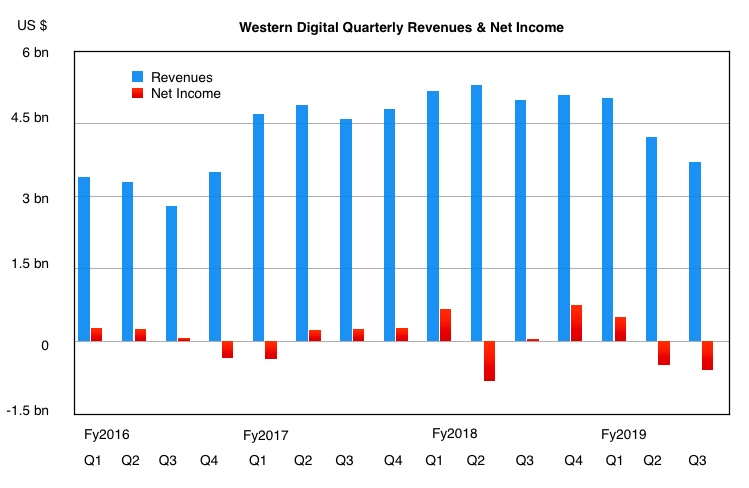
Revenues of $3.7bn were 26 per cent down on a year ago. Last year’s $61m net income turned into a thumping $581m loss.
Discussing the results Steve Milligan, Western Digital CEO, saw “initial indications of improving trends…our expectation is for the demand environment to further improve for both flash and hard drive products for the balance of calendar 2019.”
Revenues and profits go up – and revenues and profits go down.
Q3 2019 revenue fell in all three business divisions: Data Centre Devices and Solutions, Client Solutions, and Client Devices.
Data Centre devices revenues were $1.25bn ($1.66bn a year ago)
Client Devices revenues were $1.63bn ($2.3bn)
Client Solutions revenues were $0.8bn ($1.04bn)
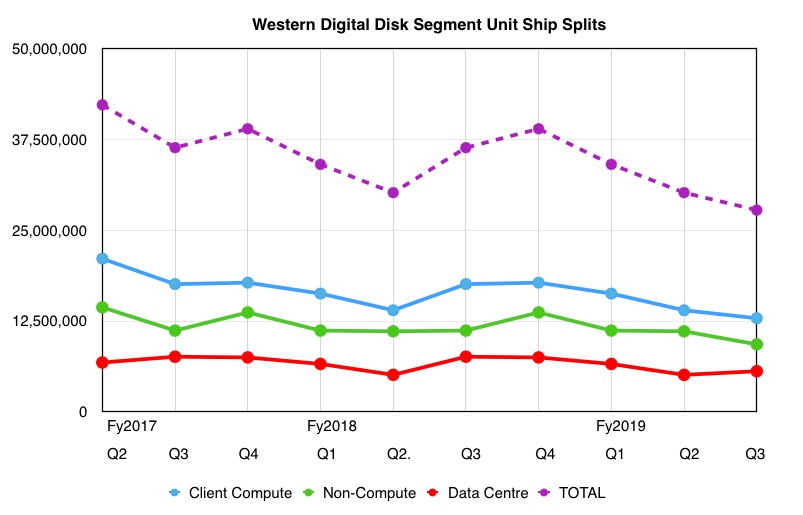
We charted the recent disk drive unit ship historical trends:
A pattern of disk drive unit shipments decline.
There is a discernible recent quarter-on-quarter pickup in data centre disk drive units.
WD attributed the fall in mobile embedded revenues to weak handset demand. Notebook and desktop revenue declined due to seasonality and flash price declines.
In the data centre devices unit, demand for capacity enterprise drives was better than expected.
WD was hit by a double whammy in the quarter. Total HDD revenues were $2.64bn a year ago and $2.1bn in the latest quarter. The equivalent flash revenues were $2.4bn a year ago and $1.6bn in Q3 fy’19. Wells Fargo senior analyst Aaron Rakers said flash capacity shipped was down 5 per cent year on year.
It’s not all bad. Rakers noted “client SSD Exabyte shipments more than doubled year-on-year,”
And WD’s OEMs are qualifying new NVMe eSSDs, with shipments expected to start in three months or so.
The Intel Optane DC SSD D4800X (NVMe) offers a “24x7” available data path and super-fast storage, breaking through bottlenecks to increase the value of stored data. Intel Corporation on April 2, 2019, introduced a portfolio of data-centric tools to help its customers extract more value from their data. (Credit: Intel Corporation)
Dell Technologies World Dell EMC’s PowerMax arrays will incorporate Intel’s dual-port Optane SSD memory.
The technology is intended for applications that require 24×7 access to the data on the drive. Dual port redundancy means data can still be accessed through the second controller and NVMe port in the event of a single failure or controller upgrade.
The Optane DC D4800X has an NVMe interface with two PCIe gen 3 lanes per port. The single port P4800X uses all 4 lanes and has more performance. Intel has not yet revealed the performance of the D4800X. It will have the same 30DWPD endurance as the P4800X, according to Rob Crooke, Intel’s general manager of the non-volatile memory solutions group.
Intel Optane SSD DC D4800X
The D4800X comes in a U.2 (2.5-inch drive) format with 375GB, 750GB and 1.5TB capacities.
Intel said the D4800X is “the result of a three-year collaboration between Intel and Dell to improve the performance, management, quality, reliability, and scalability of storage.”
Dell’s high-end PowerMax array is the first to use this dual-port Optane SSD. Other storage array suppliers will probably announce similar support.
According to Amazon, customers want to process locally created or ingested data in real-time for in-field analysis and automated decision making, using the same resources and methods as in in the cloud. Hence the addition of block storage volumes used by Amazon EC2 instances running in the Snowball Edge appliance.
Snowball users fill up the ruggedised system with data for local processing, and then transport it to an Amazon data centre for AWS cloud upload.
The appliance can use Performance-Optimized NVMe SSD volumes, while capacity and throughput-oriented workloads store data on Capacity Optimized Hard Disk Drive (HDD) volumes. Applications with capacity and long-term storage needs can use the Amazon S3 object storage API.
Amazon Snowball Edge device
To provide block storage to EC2 Amazon Machine Image-based applications on the Edge box, customers dynamically create and attach block storage volumes to the AMIs. Such volumes do not have to be pre-provisioned and they grow elastically to their defined size.
Find out more from an Amazon blog by Wayne Duso, AWS general manager for Hybrid and Edge.
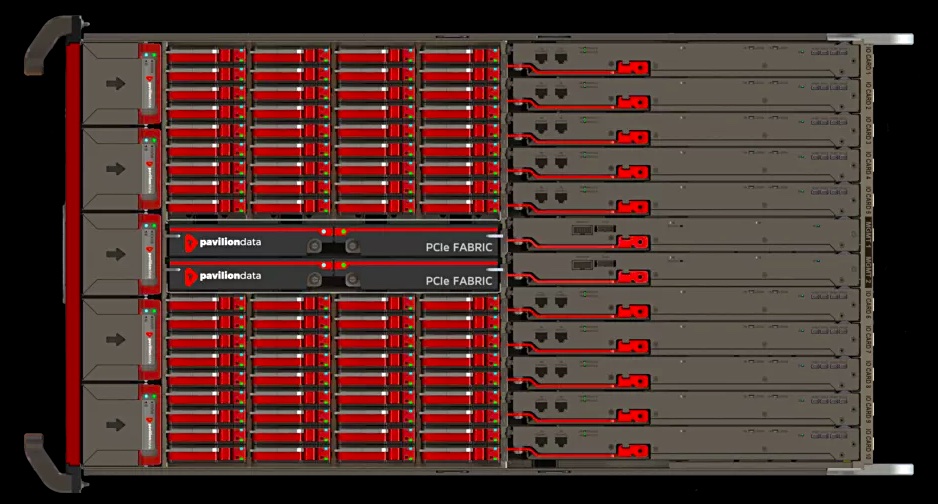
Pavilion Data Systems, the NVMe-over-Fabrics array maker, has tweaked its software to pump performance to fresh heights.
Taking an untraditional approach, The RF100 series appliance incorporates a bank of controllers talking PCIe to NVMe SSDs.
Pavilion Data array.
In November 2018, the company recorded RF10 performance at up to 120GB/sec read bandwidth, 60GB/sec write bandwidth and average read latency of 117μs.
V2.2 of Pavilion software improves write performance by 50 per cent to up to 90 GB/second. Other features in the upgrade include:
Write latency as low as 40μs
RAID-6 protection which allows for two disk failures within a RAID set before any data is lost
SWARM recovery for RAID rebuilds which can rebuild a single 2TB SSD drive in under ten minutes, a task that can often take several hours
Consistency groups for snapshots
Competition in the NVMe-oF market is sparking continuous product development. Pavilion claims its multi-controller architecture arrays deliver more scale and performance than dual-controller arrays.
It also has a bring-your-own-drive attribute, as customers can populate Pavilion’s array with their existing 25-inch NVME drives or buy from the suppler of their choice. This should help reduce cost/GB compared with competitors who supply bundled and high-priced drives.
Today’s storage briefs include Violin arrays adopting NVMe, NEC using Scale Computing to build a hyperconverged offering, Formulus Black getting its software added to HPE servers but not by HPE, and Hitachi Vantara bigging up object storage.
It is pre-configured in three levels – base, mid-range and power – and can be customised if pre-packed models don’t meet the needs of a customer.
The software, with in-built hypervisor, is pre-installed, and the customer just needs to add networking information to deploy the appliance.
New appliances can be added into a running cluster seamlessly and within minutes. Different models and capacities can be used together in various combinations to scale out resources as needed.
NEC’s HCI product is available in calendar Q2 2019 through its channel partners.
Hitachi Vantara’s IDC object survey
Hitachi Vantarra has sponsored an IDC InfoBrief, titled “Object Storage: Foundational Technology for Top IT Initiatives.” In the survey, 80 per cent of respondents believe object storage can support their top three IT initiatives related to data storage – which include security, Internet of Things and analytics for unstructured data.
To date, object storage has been used predominately for archival, according to Hitachi Vantara. That’s about to change, with object storage also used as a production data store for analytics routines, the company argues.
It quotes Amita Potnis, IDC research manager, file and object-based storage systems: “As we continue to see adoption across all environments – both on-and off-premises – features like All-flash will help usher in new, more performant use cases beyond archiving that drive additional value for organisations.”
All-flash object stores will provide much faster data access than disk-based stores and the latest 96-layer QLC (4bits/cell) 3D NAND SSDs will provide more affordable flash storage than the current TLC (3bits/cell) 64-layer 3D NAND.
The company supplies its HCP object storage platform and Pentaho analytics software. The all-flash HCP G10 configuration is the fastest performer. But Hitachi V said it has also sped up disk-based models with Skylake processors, and added capacity with 14TB disk drives and more drive bays in the product chassis.
Violin and NVMe
Violin Systems is adding NVMe SSDs to its XVS 8 all-flash array, lowering data access latency and also doubling usable capacity to 151TB.
According to IDC, by 2021 NVMe-based storage systems will drive over 50 per cent of all primary external storage system revenues. After that NVMe will be table stakesin all-flash arrays, meaning customers won’t buy all-flash arrays that don’t have NVMe drive support.
The software in the 3U XVS 8 provides deduplication and compression and effective capacity is up to six times greater than the usable capacity.
Formulus Black and HPE Proliants
Formulus Black has signed a reseller deal with Nth Generation, a US IT consulting and engineering firm, to provide its ForsaOS software integrated with HPE ProLiant servers.
Wayne Rickard, Formulus Black’s chief marketing officer, said: “Nth Generation…will be able to deliver tailor-made solutions that satisfy the needs of customers requiring exceptional performance, even when utilising more-affordable, mid-tier Xeon processors.”
ForsaOS uses bit-marker technology to run applications in memory much faster than if they were run with working sets partially in memory and partially in storage. To accomplish this, CPUs have to do extra work in decoding and encoding bit markers.
Testing on an HPE ProLiant DL380 Gen10 server, featuring mid-range Intel Xeon Gold 6126 processors and 24 x 32GB HPE DDR4-2666 MT/s DIMMs, yielded performance from 4.5 to 7.8 million random 4K IOPs. Average latencies for writes were 2.8µs and reads were 1.8µs per IOP with CPU utilisation below 50 per cent.
The results were achieved running VDBENCH on ForsaOS in host mode (non-virtualized). Formulus Black claims this performance is unmatchable by any SSD or other I/O-bound technology.
ForsaOS screenshot
ForsaOS treats memory as storage and completes in-memory system backup and restoration in minutes instead of hours or days, according to Forumulus Black. By identifying and encoding data patterns using algorithms, the software enables more data to be securely persisted in memory, using powerfail protection to write DRAM contents to storage if power is lost.
The software stack can run any workload in memory without modification on any server.
Liqid, the composable systems maker, is extending connectivity fabric support to enable customers to dynamically compose servers from pools of CPU, GPU, FPGA, NVMe, and NICs regardless of underlying fabric type.
Liqid’s soon-to-be-released Command Center 2.2 software will support PCIe Gens 3 and 4, Ethernet (10/25/100 Gbit/s (10/25/100 Gbit/s), and Infiniband, and lays the foundation for supporting Gen-Z specifications.
Liqid is a member of the Gen-Z consortium and will actively support Gen Z in future releases of Liqid Command Center Software.
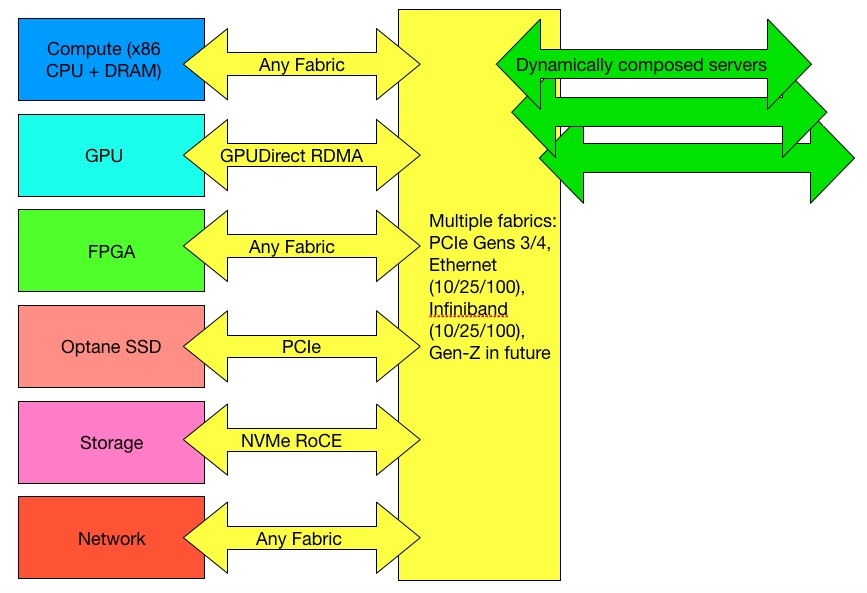
Customers will be able to simultaneously compose infrastructure across multiple fabric types. Resources such as NVMe (RoCE) storage, GPUs (with GPU-oF meaning GPUDirect RDMA) and FPGAs are deployed as needed via multiple fabrics, and monitored through a single GUI.
Liqid multi-fabric scheme.
Sumit Puri, Liqid CEO, gave out a quote: “Providing Ethernet and Infiniband composability in addition to PCIe is a natural extension of our expertise in fabric management.”
Removing the defacto requirement for a single composable systems fabric is a good thing. It will be interesting to see if other compassable systems suppliers such as DriveScale,HPE (Synergy) and Dell EMC follow suit.
General availability of Liqid Command Center 2.2 is expected in the second half of 2019.