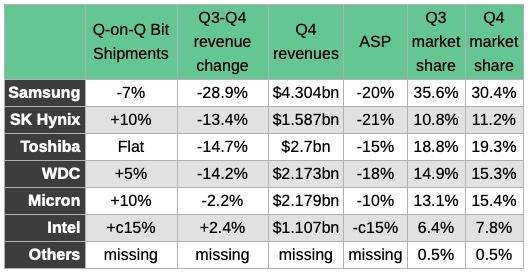
An abrupt quarter-on-quarter revenue cliff drop affected all the main flash vendors, except Intel, which saw revenues rise despite falling prices.
DRAMeXchange highlighted the sudden revenue reversals everywhere but Intel, supplying these numbers:
Everyone except Samsung increased bit shipments in the fourth 2018 quarter compared to the one before, and Intel pushed them up 15 per cent.
Samsung revenues dropped dramatically from the third to the fourth quarter – down 28.9 per cent to $4.304bn – and its market share fell 5.2 per cent to 30.4 per cent.
All the major suppliers took share from Samsung, except the Others category.
Both SK Hynix and Samsung had to cut average selling prices (ASPs) by more than 20 per cent, but SK Hynix gained market share as a result and its revenues only fell 13.4 per cent, less than half of Samsung’s percentage drop.
The DRAMeXchange researchers reckoned the first quarter of 2019 will be worse, with seasonality deepening the demand slump, resulting in a projected decline in NAND bit shipments over 2018’s final quarter.
The research outfit predicted the main NAND suppliers would lower prices further to retain their respective market shares. If you’re in the flash game, consider yourself warned.
Yesterday’s ObjectEngine launch is notable for what it brings to Pure’s future data management table. This is Pure’s third hardware platform, joining FlashArray for primary data and FlashBlade for secondary, unstructured data.
ObjectEngine positions Pure Storage for a multi-cloud, data copy serving and Data-as-a-Service future, taking on Actifio, Cohesity and Delphix.
The company says the technology is suitable for machine learning, data lakes, analytics, and data warehouses – “helping you warm up your cold data.”
ObjectEngine//A270 with four nodes (2 enclosures) above a single FlashBlade box
ObjectEngine is a scale-out, clustered inline deduping system. It accepts incoming backup files via an S3 interface, squashing them, and sends them along to an S3-compliant back-end – either on-premises Pure FlashBlade arrays or AWS S3 object storage. For restoration, ObjectEngine fetches the back-end S3 files and rehydrating them.
A Pure Storage Gorilla Guide mentions this point: “It’s conceivable that more public and private cloud services will be supported to help reduce the complexity and cost of F2F2C (flash to flash to cloud) backup strategies.”
The Pure Storage vision extends beyond data storage and data protection to data management.
Flash dedupe metadata
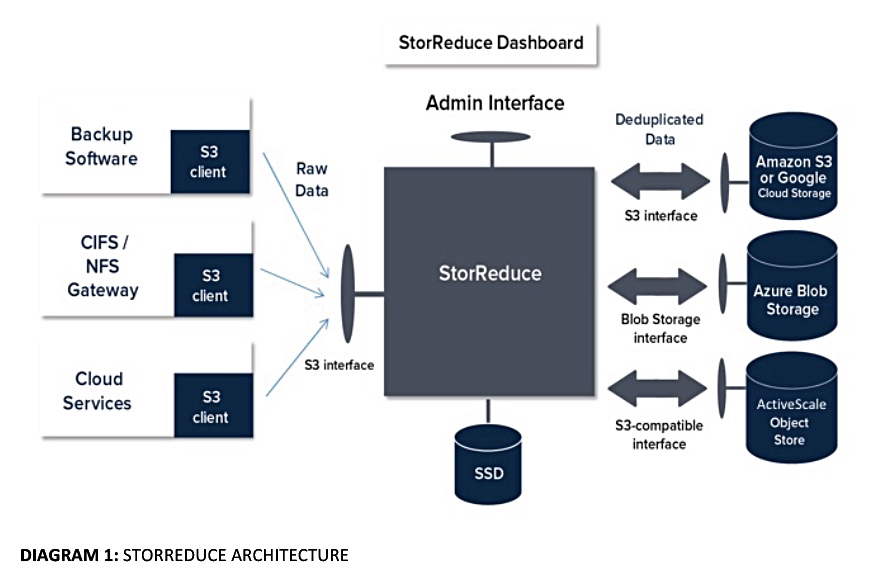
A StorReduce server uses x86 processors and stores dedupe metadata on SSDs:
StorReduce Architecture
The Gorilla Guide doc says each StorReduce server keeps its own independent index on local SSD storage.
As I note here, Pure has not published deduplication ratios, but it gives big clue in the Gorilla Guide: “The amount of raw data a StorReduce server can handle depends on the amount of fast local storage available and the deduplication ratio achieved for the data. … Typically, the amount of SSD storage required is less than 0.2 per cent of the amount of data put through StorReduce, for a standalone server.”
StorReduce servers use backend object storage for:
Deduplicated and compressed user data. Typically, this requires as little as 3 per cent of the object storage space that the raw data would have required, depending on the type of data stored.
System Data: Information about buckets, users, access control policies, and access keys, making it available to all StorReduce servers in a given deployment.
Index snapshots: Data for rapidly reconstructing index information on local storage.
Note this point, which is counter-intuitive considering SSDS are non-volatile: “The StorReduce server treats local SSD storage as ephemeral. All information stored in local storage is also sent to object storage and can be recovered later if required.”
A server failure means that another server can pick up its load using the failed server’s back-end stored information.
With the metadata held in local flash, “StorReduce can create writable “virtual clones” of all the data in a storage bucket, without using additional storage space.”
It can “create unlimited virtual clones for testing or distribution of data to different teams in an organisation. Copy-on-write semantics allow each individual clone of the data to diverge as new versions of individual objects are written.”
Multiple clouds
StorReduce software could store its deduped data on on-premises S3-accessed arrays, Amazon S3 or S3IA, Microsoft Azure Blob Storage, or Google Cloud Storage. ObjectEngine only supports FlashBlade and AWS S3 – for now.
We have no insider knowledge but it seems a logical next step to enlarge the addressable market for ObjectEngine by extending support for Azure Blob storage and Google Cloud Platform (GCP).
Furthermore ObjectEngine could migrate data between these clouds by converting S3 buckets into Azure blobs or the GCP equivalent. The StorReduce doc says: “StorReduce can replicate data between regions, between cloud vendors, or between public and private cloud to increase data resiliency.”
The system transfers unique data only to reduce network bandwidth needs and transmission time.
Data copy services
StorReduce had the facility of having StorReduce instances taking a freshly deduped object set, rehydrating it and pumping it out for re-use. This fits perfectly with Pure’s DataHub ideas, as mapped out below.
Pure’s Data Hub idea for data distribution for re-use
Here we see the likelihood of Pure taking direct aim at Activity, Cohesity and Delphix in the copy data management market.
ObjectEngine opens several data management doors for Pure Storage. Expect these doors to start being delineated over the next few quarters as Pure builds out its third hardware platform.
Veeam’s backup Cloud Tier can use Western Digital’s object-storing ActiveScale box as a target data store.
The idea is to make longer-term backup storage cheaper by moving it away from more expensive direct backup-to-disk targets to ActiveScale.
Cloud Tier is Veeam’s term for older backup data moved to AWS S3, Azure Blob or on-premises object storage. It is not separate archiving as the backups are still accessible via metadata references in the local backup store.
ActiveScale is an S3-compatible object storage array. It scales from 500TB to 49PB in one namespace and offers a claimed 19 nines data durability – 99.99999999999999999 per cent. Blocks & Files thinks this equates to a 1 in 9 quintillion chance that a data object will be lost, but our eyes glazed over as we counted the 9s.
ActiveScale P100.
Western Digital has joined the Veeam Alliance Partner Program as part of its arrangement with Veeam.
Three more points:
A Unified Data Access feature offers file access protocols as well as object access.
ActiveScale use by Cloud Tier requires Veeam Availability Suite v9.5 Update 4.
Cloud Tier also supports Western Digital’s IntelliFlash all-flash arrays, the acquired Tegile technology.
The amount of data to be stored, processed and protected grows incessantly. That’s fuelling product growth and partnerships between suppliers as they jostle to taker advantage of the benign storage weather climate.
Cisco HyperFlex and Nexenta target VDI
Cisco is using Nexenta’s Virtual Storage Appliance (VSA) to provide NFS and SMB file services to its HyperFlex hyper-converged system. This SW-based NAS features inline data reduction, snapshots, data integrity, security, and domain control, with management through VMware’s vCenter plugin.
The two say HyperFlex plus Nexentastor VSA is good for VDI with support for home directories, user profiles, and home shares.
It obviates the need for HyperFlex customers to add a separate NAS filer to support VDI.
The two suggest the combined system is suited for remote office/branch office (ROBO) and backup/disaster recovery (BDR), supporting legacy enterprise, new cloud-native, and 5G-driven telco cloud apps, in part as it eliminates the need for separate file servers.
Cray meets good weather in South Africa
A Cray XC30-AC supercomputer, with a Lustre file system, used by the South African Weather Service’s (SAWS) since 2014, has been upgraded.
SAWS has doubled its compute capacity, tripled storage capacity and mire than doubled bandwidth.
The upgrade involved;
Growing from 88 to 172 Ivy Bridge compute nodes
Upgrading processors from Ivy Bridge 2695v2 to Ivy Bridge 2697v2
The system went from 1.5 cabinets to 3 cabinets (48 blades)
Storage was upgraded from Sonexion 1600 arrays with 0.52 PB capacity and 12 GB/sec bandwidth to ClusterStor L300 storage with 1.8PB capacity and 27 GB/sec.
Ilene Carpenter, earth sciences segment director at Cray, said: “With the Cray system upgrades in place, SAWS has the storage and compute resources needed to handle an increasing number of hydro-meteorological observations and to run higher fidelity weather and climate models.”
IDC’s Global StorageSphere
IDC’s inaugural Global StorageSphere forecast; a variation on the old Digital Universe reports, predicts the amount of stored data is going to grow; there’s a thing.
The installed base of storage capacity worldwide will more than double to 11.7 zettabytes (ZB) over the 2018-2023 forecast period. IDC says it measures the size of the worldwide installed base of storage capacity across six types of storage media, but doesn’t publicly identify the six media types.
We asked IDC and spokesperson Mike Shirer tells us: “The six types of storage media in the report are: HDD, Tape, Optical, SSD, and NVM-NAND / NVM-other. Share is dominated by HDD, as you might expect.” Indeed.
The three main findings, according to IDC, are;
Only 1-2 per cent of the data created or replicated each year is stored for any period of time; the rest is either immediately analysed or delivered for consumption and is never saved to be accessed again. Suppliers added more than 700 EB of capacity across all media types to the worldwide installed base in 2018, generating over $88 billion in revenue,
The installed base of enterprise storage capacity is outpacing consumer storage capacity, largely because consumers increasingly rely on enterprises, especially cloud offerings, to manage their data. By 2023, IDC estimates that enterprises will be responsible for managing more than three quarters of the installed base of storage capacity.
The installed base of storage capacity is expanding across all regions, but faster in regions where cloud datacentres exist. The installed base of storage capacity is largest in the Asia/Pacific region and will expand to 39.5 per cent of the Global StorageSphere in 2023.
Mimecast’s textbook example of business growth
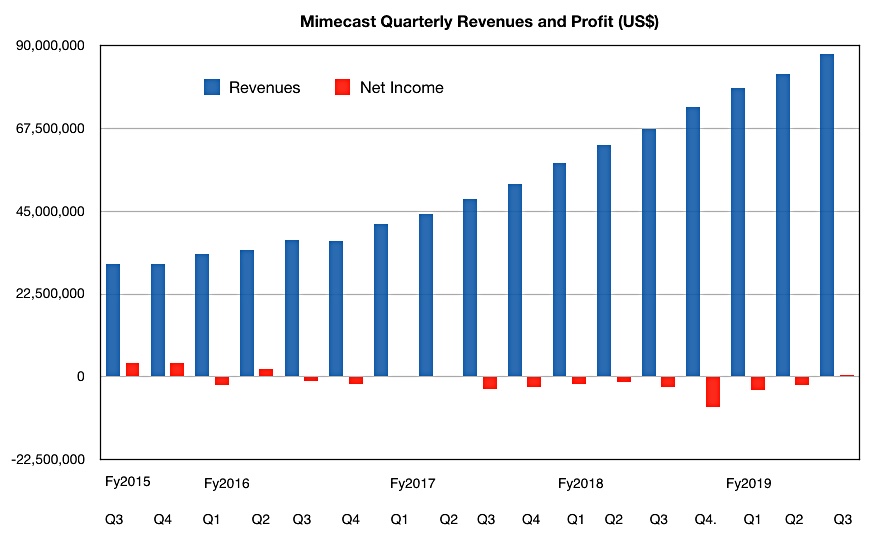
Mail archiver and protector Mimecast delivered yet another quarter of record growth.
Revenues for its third fiscal 2019 quarter were $87.6m, providing a $350m annual run rate, and an increase of 30 per cent on last year.
THere’s not a trace of seasonality in this revenue growth curve.
There was a $500K profit; unusual as Mimecast generally runs with a regular quarterly loss to fuel its growth.
Mimecast closed a record number of six figure transactions and a seven figure deal that was the largest ever for the company. It was with a financial services customer working across the Middle East and Africa.
A thousand new customers were recruited in the quarter, more than last quarter’s 900 but less than the year-ago’s 1,200. The total customer count is 33,000.
The outlook for the fourth quarter of 2019 revenue is a range of $90.6m to $91.5m. Full year 2019 revenue is expected to be in the range of $338.7m to $339.7m. Full-year 2020 revenue is expected to be in the range of $413m to $427m.
Mimecast bought Simply Migrate last month, with software technology to migrate mail archives into Mimecast’s Cloud Archive vaults. The price was not disclosed.
Seagate and the EMEA Datasphere
Another IDC report, commissioned by Seagate, looks at the data produced (not necessarily stored) in the EMEA region. It predicts the EMEA Datasphere will grow from 9.5ZB to 48.3ZB from 2018 to 2025, a growth rate slightly lower than the global average (CAGR of 26.1 per cent vs 27.2 per cent.)
The main findings;
AI, IoT and entertainment streaming services rank among the key drivers of data growth,
Streaming data is expected to grow by 7.1 times from 2015 to 2025; think YouTube, Netflix and Spotify,
AI data is growing at a 68 per cent CAGR, while IoT-produced data will grow from 2 per cent to a 19 per cent share of the EMEA datasphere by 2025,
The percentage of data created at the edge will nearly double, from 11 per cent to 21 per cent of the region’s datasphere,
China’s Datasphere is currently smaller than the EMEA Datasphere (7.6ZB vs 9.5ZB in 2018), but by 2025 it will have overtaken Europe to emerge as the largest Datasphere in the world, with 48.6ZB.
Prissily Seagate and IDC advise that businesses need to see themselves as responsible stewards of data, taking proactive steps to protect consumer data while reaping the benefits of a global, cloud-based approach to data capitalisation, whatever data capitalisation means. Yeah, yeah.
Veeam did well – again
Backup and recovery supplier Veeam, which has a succession of record-breaking quarters has had another one leading to a near $billion year. Total global bookings in 2018 were $963m were, 16 per cent higher than 2017’s $827m.
The global customer count is over 330,000. At the end of 2017 it was 282,000, and Veeam says it has been acquiring new customers at a 4,000/month rate. More than 9,900 new EMEA customers in EMEA were acquired in the fourth 2018 quarter; mind-boggling numbers.
Cloudhas been the fastest growing segment of Veeam’s business for the past 8 quarters. Veeam reported 46 per cent y-o-y growth in its overall cloud business for 2018. The Veeam Cloud & Service Provider (VCSP) segment grew 23 per cent y-o-y, and there are 21,700 Cloud Service Providers, 3,800 licensed to provide Cloud Backup & DRaaS using Veeam Cloud Connect.
Ratmir Timashev, co-founder and EVP of Sales & Marketing at Veeam, said: “We have solidified our position as the dominant leader in Intelligent Data Management and one of the largest private software companies in the world.”
Veeam recently took in a $500m investment to help drive its growth. Timashev said: “We are leading the industry by empowering businesses to do more with their data backups, providing new ways for organisations to generate value from their data, while solving other business opportunities.”
Blocks & Files thinks acquisitions are coming as Veeam strengthens its data management capabilities to compete more with Actifio, Cohesity and Rubrik. We reckon it will hit the $1bn by the mid-year point.
WANdisco gets cash and stronger AWS partnership
Replicator WANdisco has raised $17.5m through a share issue taken up by existing shareholders;
Merrill Lynch International
Ross Creek Capital Management, LLC
Global Frontier Partners, LP
Davis Partnership, LP
Acacia Institutional Partners LP, Conservation Fund LP and Conservation Master Fund (Offshore), LP
CEO and chairman Dave Richards said the cash will be used to: “to leverage a number of significant opportunities to expand our existing partner relationships.”
WANdisco has received Advanced Technology Partner status with Amazon Web Services, the highest tier for AWS Technology Partners. Richards said this new partner status: “significantly expands our sales channel opportunities.”
Shorts
Amazon Elastic File System Infrequent Access (EFS IA) is now generally available. It is a new storage class for Amazon EFS designed for files accessed less frequently, enabling customers to reduce storage costs by up to 85 per cent compared to EFS Standard storage class. With EFS IA, Amazon EFS customers simply enable Lifecycle Management, and any file not accessed after 30 days gets automatically moved to the EFS IA storage class.
A major US defence contractor is implementing an Axellio FabricXpress system using Napatech’s FPGA-based SmartNIC software and hardware. The Axellio/Napatech 100G capture and playback appliance will be used as a test and measurement system to capture and store 100 gigabits per second data-to-disk to allow precise replay. Napatech provides high-speed lossless data capture and replay.
Cisco’s second fiscal 2019 quarter results earnings call revealed this HyperFlex HCI snippet; CFO Kelly Kramer said; “We had a great Q2, we executed well with strong top-line growth and profitability.
“Total product revenue was up 9 per cent to $9.3bn, Infrastructure platform grew 6 per cent. Switching saw double-digit growth in the campus. … Wireless also had double-digit growth … Routing declined due to weakness in service provider. We also saw decline in data centre servers partially offset by strength in hyperconverged.” So HyperFlex revenues grew though UCS servers generally did not.
Intel will build a new semiconductor fab in Hillsboro Oregon, but hasn’t said what kind of chips it will make; CPUs, NAND or Optane. The new fab will be a a third phase of the existing D1X manufacturing complex and its exact size and timing haven’t been specified.
Mail manager and archiver Mimecast’s third fiscal 2019 quarter revenues were up 30 per cent y-o-y to $87.6m. It added 1,000 new customers in the quarter to reach a total of 33,300; impressive. A total of 41 per cent of Mimecast customers used it in conjunction with Microsoft Office 365 during the quarter compared to 29 per cent a year ago.
Scale-out filer start up Qumulo said that, in FY19;
Its partner ecosystem, including HPE, was responsible for 100 per cent of bookings and the source of about 40 per cent of its deals.
More than 65 per cent of new business was partner-initiated
It saw year-over-year triple-digit growth with HPE, with new customers across enterprise, commercial, State/Local government and Education (SLED), Federal government and small/medium business (SMB).
People
Rafe Brown has been appointed as Mimecast’s CFO. He was previously CFO of SevOne, being CFO of Pegasystems before that.
Leonard Iventosch has joined scale-out filer Qumulo as its Chief Channel Evangelist, coming from HPE’s Nimble unit, where he was VP for world-wide channels.
“We love mainframe and we want to make it better,” says Model9 co-founder and CEO Gil Peleg.
He wants to demonstrate his love by killing off mainframe Virtual Tape Libraries (VTLs) with a software explosive to blow them up.
The mainframe market includes the largest companies in the world. It is a worthwhile market niche.
Mainframes have traditionally used tape drives and libraries for backup and longer term storage. These have largely been supplanted by disk arrays controlled by software presenting a virtual tape library interface to mainframe applications. These VTLs are much faster than tape drives and libraries at both writing and retrieving data.
However, in the x86 server world VTLs have in their turn been supplanted by deduplicating to-disk arrays acting as backup targets, by object storage arrays and by the public cloud offering backup and archival storage based on object technology, such as Amazon’s S3 and Glacier.
Model9 saw this and reckons it can bring object storage goodness, on-premises and in the cloud, to mainframes making their backup and allied operations less expensive, more scalable and convenient and with no vendor lock-in.
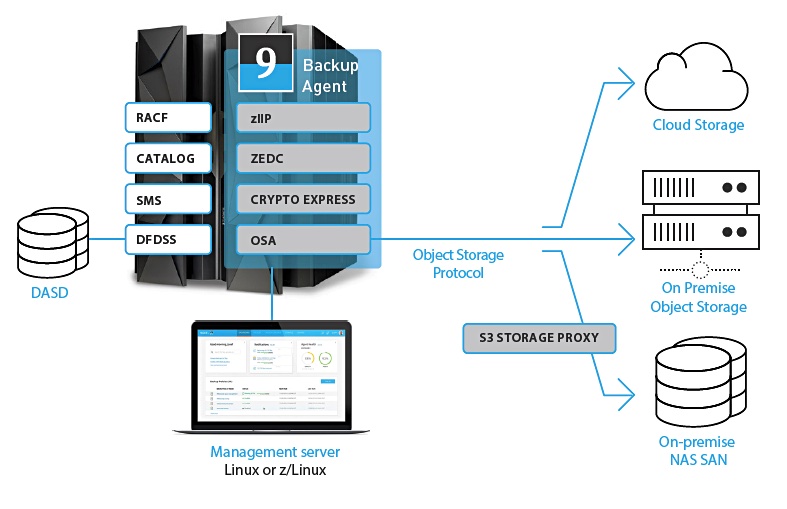
Its technology connects the mainframe directly over TCP/IP to any network-attached storage and enables the supplementing or complete elimination of the need for virtual tape libraries and physical tapes.
Gil Peleg
The product is called Model9 Backup and Recovery for z/OS.
Since then it has developed its software. Peleg tells us; “Model9 is a shipping product, with customers running in production and customers who have totally eliminated IBM tape hardware and replaced IBM and CA backup software with our solution.”
It supports the following targets:
Cloud: Amazon S3, Glacier, Azure, Google Cloud and IBM Cloud,
Object: Hitachi Content Platform (HCP), IBM Cloud Object Storage, EMC Elastic Cloud Storage, NetApp StorageGRID and Microsoft Azure Stack,
Tape Management: IBM RMM, CA-1, CA-TLMS, BMC Control-M/Tape
Virtual Tape Software: IBM VTFM, CA-VTape
Security Software: RACF, CA-TSS, CA-ACF2
This is a heck of a lot of software functionality to develop in two years or so, Particularly in the assembler-driven world of mainframe software development.
The software consists of a Backup Agent on z/OS and a Management Server on Linux or z/Linux as shown in the diagram below;
Java vs. Assembler
The Israeli company was started in 2016 by four mainframe people: CEO Gil Peleg, CMO Motti Tal, VP Busness development Adi Pundak-Mintz, and departed CTO Yuval Kashtan.
It has had two smallish funding rounds; a pre-seed one and a seed round, both in 2017, and with the amounts undisclosed.
How come Model9 has been able to do all this in a comparatively short time?
Peleg points to three key differentiators over other Mainframe vendors that “allow us to move very fast.”
“The mainframe side of the product is developed in Java, unlike any other infrastructure solution in the mainframe world that are developed in Assembler. Our patented technology is all about how to perform low-level mainframe I/O operations and invoke system services from Java. So developing the majority of the product in Java instead of Assembler allows us to use standard tools and practices and develop high quality software much faster than the norm in this market.”
Secondly: “We support S3 directly from z/OS which enables us to quickly develop and make adjustments between the different cloud storage player offerings and provide support for AWS, Azure, Google Cloud and IBM Cloud. In 2016 we also participated in IBM’s cloud accelerator called IBM AlphaZone and were the first company to connect the IBM mainframe to the IBM Cloud. We also certified with the major NAS/SAN players such as NetApp and Infinidat.”
And the third factor is this; “Our R&D team is composed of highly skilled mainframe software engineers, all under 40 with 15 years of experience in mainframe, storage, cyber security and enterprise software development. All of our R&D team are guys who started their professional career as mainframe engineers in the Israeli Army’s computer centre, at one of its elite computing units. This young and agile team with startup mentality enables us to develop very fast in compare to other companies our market.”
Intel’s new Cascade Lake AP processor supports Optane memory but the company is not revealing details about endurance. This raises doubts about its real world use.
The AP (Advanced Processor) version of Intel’s Cascade Lake CPU adds Optane support to the x86 lineup. One reason for having direct support in the processor is that a server with both DRAM and Optane has two tiers of memory: fast DRAM memory and slower Optane memory; more formally Optane persistent memory.
DDR4 DRAM latency is in the 14ns area while Optane DC Persistent Memory averages 350ns for reads. This is the classic NUMA (non-universal memory access) issue seen in multi-processor servers with near and far memory having different response times but present inside a single processor server with two types of memory.
Cascade Lake AP differs from the SP (Standard Procecessor) version by having an integrated memory controller which supports running both DRAM and Optane memory in the same memory structure.
Cascade Lake AP is a multi-chip package combining two 24-core processors connected by a UPI link, into a single 48-core CPU.
A Cascade Lake AP has 12 memory channels, each capable of supporting two DDR4 DIMMs. These can be DRAM DIMMs, Optane DIMMs or one of each.
Optane DIMMS come in 128GB, 256GB or 512GB capacity points. There can be a maximum of up to 3TiB of DRAM or 6TiB of Optane in a Cascade Lake AP system, or, more likely, a mix of DRAM and Optane with the DRAM acting as a cache.
Cascade Lake AP servers can be 2-socket systems, in which case they will support up to 12TiB of Optane memory.
An Optane SSD has over-provisioning (extra cells) to prolong its endurance (active life). With this the 750GB P4800X has a 5-year warranty and a listed 41PB written endurance rating. This is equivalent to 30DWPD (drive writes per day.) That has gone up from the initial 20DWPD number.
Intel has not revealed the endurance of its Optane DIMMs. If they are used in direct access memory mode; treated as memory by applications in other words and not as storage we can reasonably expect a large amount of writes to take place.
We are all waiting for Intel to release its Optane DC Persistent Memory endurance numbers and then we can get a good idea of real world performance. Hopefully they will be good.
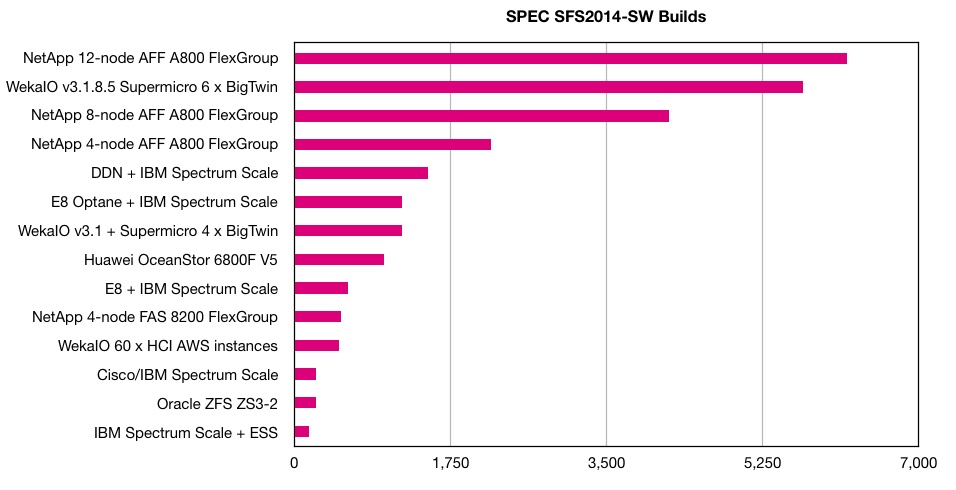
Well, this fun Two can play at the node addition game. NetApp beat WekaIO in the SPEC SFS 20i4 software build benchmark.
WekaIO had cleanly swept the SPEC SFS 2014 results and continually topped the popular SW build test part by adding nodes to its Matrix scale-out parallel file system.
NetApp is using the same tactic, and adding nodes to its all-flash A800 array, with a 12-node system scoring 6,200 SW builds at an overall response time of 0.83 msecs. That beats WekaIO’s 5,700 and its 0.26 msecs ORT, which had beat an 8-node A800’s 4,200 SW builds at an 0.78 mess ORT.
Blocks & Files would suggest that, in price/performance terms, WekaIO with its Supermicro BigTwin server hardware, is much more cost-effective than NetApp. But NetApp has its mature software environment to offer in turn.
SPEC SFSing is turning into a duopoly, game dominated by NetApp and WekaIO. Both can keep on adding nodes to leapfrog each other.
NetApp says flash and cloud integration enables it to build a moat around its core ONTAP business base, despite revenues becoming temporarily becalmed.
Its third quarter revenues of $1.56bn were up just 2 per cent annually, missing Wall Street estimates. The company forecasts no annual growth at the mid-point of its next quarter’s revenue guidance: $1.64bn.
CEO George Kurian told analysts in NetApp’s Q3 fy19 earnings call that he is confident NetApp will see growth resuming in 2020 because it has a three-way growth strategy based on flash arrays, HCI and multi (private + public) cloud offerings.
He said that the customer “requirement for hybrid multi-cloud capabilities is creating three significant market transitions: disk to flash, traditional IT to private cloud, and on-premises infrastructure to hybrid clouds.” NetApp has and is responding to each of these transitions.
All-flash arrays
First the good news, NetApp is doing well in the fast-growing all-flash market, growing 19 per cent year-over-year to an annualised net revenue run rate of $2.4 billion. Kurian said: “Wit only 15 per cent of our installed base currently running all-flash arrays, the runway for this secular transition remains in the early innings.”
He noted a” lot of weak large players in disk-based system that we will take share from; IBM, Hitachi, Fujitsu, Oracle, HPE, there’s a lot of them. And even Dell has a challenged mid-range portfolio and [high-end] portfolio. So, we feel good about our opportunities.”
Private cloud
Kurian stated: “The second major market transition we’re exploiting is the shift from traditional IT to private cloud. SolidFire and NetApp HCI are the building blocks for private cloud deployments, enabling customers to bring public cloud like experience and economics into their data centres.”
Kurian was asked by a call analyst: ”Are you prepared at this point to provide kind of a [SolidFire stand-alone and HCI] run rate that you think is reasonable or a percentage of product revenue?”
In the earnings call he declined a request by an analyst to name the [SolidFire stand-alone and HCI] run rate he thought “is reasonable or a percentage of product revenue?”
In response, he said the” momentum in our private cloud business that began in the October quarter [Q2] accelerated in Q3” and “We’ll tell you more as we head into fiscal ’20.”
NetApp is late to the hyperconverged market and has a mountain to climb here. Dell EMC and Nutanix appear to have sewn it up with dominating market shares.
Hybrid or multi-cloud
Kurian said the shift from on-premises infrastructure to hybrid clouds is “the third key market transition that we are taking advantage of to expand our business.”
He claimed: “Only NetApp is building a comprehensive set of cloud data services available across multiple clouds,” and: “Our cloud data services annualised recurring revenue is approximately $33m, up 22 per cent from Q2.”
“Roughly two-thirds of early Cloud Volumes Service customers are new to NetApp,” which means they could be sold other NetApp offerings.
The CEO said: “We are seeing accelerating momentum with our private cloud solutions, and our public cloud solutions are positioned to deliver strong growth in FY ’20.”
Isn’t this a little late?
“I would say we’re a bit behind where we expected to be in terms of the operational readiness of our service offerings with our cloud providers. We are, as we said, generally available with AWS. We are, you know, in controlled pilot production projects with both Azure and Google, and we expect them to be available imminently.”
New growth angles
Kurian believes: ”Our private and public cloud solutions enable us to reach new buyers. Our flash hybrid cloud infrastructure and AI solutions are serving as pillars of customers’ new architectures and we are seeing adoption of our cloud offerings as part of our customers’ foundation for moving applications and data to the cloud.”
Business might be lacklustre now because of worries in larger enterprises about tensions with China and the US public sector but, hopefully, these are short-term and will get resolved. Then NetApp will surge ahead.
It’s the end of an era; NetApp co-founder and EVP Dave Hitz is retiring.
The news came in a blog and signals the end of a near 27-year remarkable career showing that nice guys can get to the top.
He writes: “I think of NetApp as my child. In any parent’s life, there comes a time when you are proud of your kid, you love your kid—but you don’t want to see them every day! If you’ve done a good job as a parent, they will do well on their own.”
He becomes a Founder Emeritus with CEO George Kurian’s co-operation and so will retain a connection with he company he founded with self-effacing James Lau and Michael Malcolm, although a much less active one.
Lau retired in late 2015. Malcolm had resigned earlier, in 1994, after a disagreement.
Left to right: James Lau, Dave Hitz, Byron Rakitzis (one of the founders at Igneous in Seattle), unknown, Michael Malcolm.
Hitz memorably co-wrote a book; “How to Castrate a Bull,” and has served as an evangelising EVP and a sort of keeper of the company’s conscience.
Now he is separating himself almost completely from NetApp and this link to NetApp’s past is stretched wafer thin. Anyone who j-has watched Hitz present or seen him draw diagrams on his iPad will remember an effervescent character brimming with ideas and the way to express them.
Dave Hitz is a legendary engineer and will be sorely missed.
Radian Memory Systems can make SSDS last longer and perform more predictably and consistently.
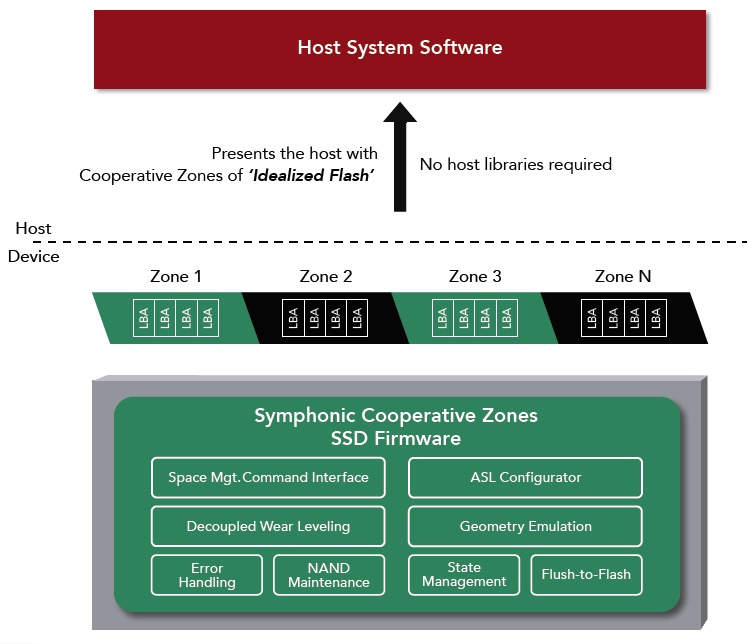
The company has released its branded Symphonic Cooperative Zones technology on its RMS-350 U.2 and RMS-325 edge card SSDs. This is how it works.
Radian sub-divides SSDs into zones that can be operated and managed together with the host. The outcome is a reduction in unexpected latency delays, increased parallelism – equals more performance – and endurance.
Lost in Flash Translation
Currently SSDs have a Flash Translation Layer and carry out garbage collection and wear-levelling themselves, with no reference to the host (asynchronously). These operations can interfere with and delay host-initiated read and write requests; the host sees an unexpected latency spike.
They can also cause more writes than anticipated, in a process known as write amplification. This reduces the working life, or endurance, of the SSD.
The newly-arrived QLC (4bits/cell) SSDs have intrinsically lower endurance than TLC (3bits/cell) SSDs and so write amplification is more undesirable. In turn TLC flash has lower endurance than MLC (2bits/cell) flash.
Radian sets up so-called co-operative zones that can be accessed in parallel. These consist of NAND blocks – or NAND Erase Units in Radian terminology. They are subsets of a physically separate region of the SSD, based upon NAND dies and channels, and called an iso-box.
Zones are configurable in size and the host sees sequential write zones of idealised flash, mini virtual SSDs. The co-operative zones appear as a range of contiguous logical block addresses (LBAs) accessible via conventional addressing through the NVMe command set.
Symphonic Cooperative Zones
Cooperative zones can be factory-configured to support different types of memory, ranging from NVRAM to SLC (1bit/cell) and TLC today, and for SCM (Storage-Class Memory) and QLC in the future. Radian also says the technology supports specialised ultra low latency SLC variations in the future as well. Blocks & Files understand this refers to Samsung’s Z-SSD and other possible products.
This feature can be used to tier data within an SSD to maximise performance, capacity and cost efficiencies.
Routine wear levelling and NAND maintenance (data retention, scrubbing, error handling) are performed internally by the SSD. The device initiates co-operative requests to the host if required data movement could conflict with other (host-initiated) I/O access.
If additional wear levelling or other NAND maintenance is required that could conflict with host I/O access latencies, the host is also alerted. That means the host can respond by rescheduling IO requests.
As part of garbage collection, hosts are responsible for selecting valid data and a relocation destination on a different zone, either performing a copy/write operation directly or using Radian’s optional Delegated Move command (NVMe vendor extension) that delegates the data transfer to the SSD.
Zones are erased through the use of a ‘Zone Reset’ command (NVMe vendor extension) that is issued by the host to the SSD, or via a zone aligned NVMe deallocate command.
Radian emphasises no host library support is needed. The functionality is carried out entirely by SSD device firmware.
Write amplification can also be caused by mismatches between the host file system’s segment size and the ones used by the SSD. Radian has an Address Space Layout (ASL) configurator which enables users to configure the SSD zones to match the host file system’s segment size. This eliminates the write amplification that would otherwise occur if the host segments and SSD zones were not aligned.
Further FTLs, if log-structured, can have their own internal garbage cleaning operations, and these can can conflict with regular garbage collection, causing more wrote amplification and latency spiking. Because Radian’s technology eliminates the FTL this additional write amplification and latency spiking are both eliminated.
Radian supplies its SSD technology and products to system OEMs, cloud providers, and for licensing to device manufacturers. The company says thousands of its NVMe storage devices have been deployed in data centre applications by some of the industry’s largest OEMs.
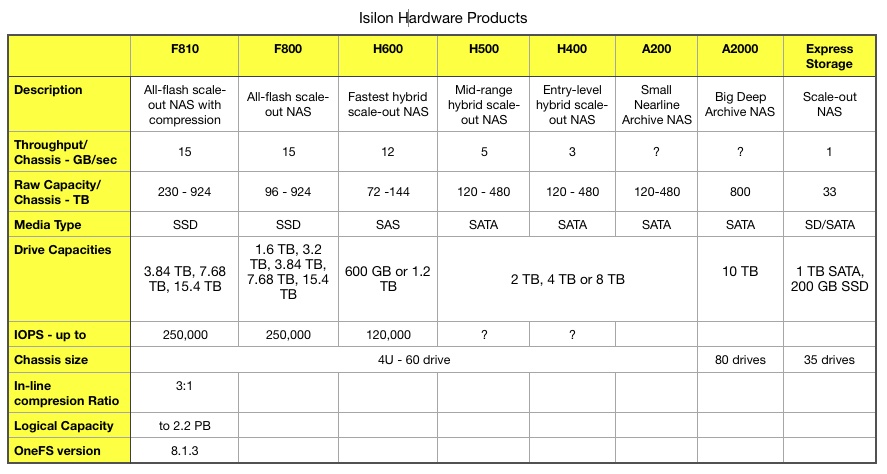
Dell EMC’s Isilon group has added compression to the F810 all-flash filer, guaranteeing logical capacity at twice raw capacity.
There is also ClarityNow software to locate, access and manage data across file and object storage on-premises and in the cloud.
in common with other systems in the range, the F810 can scale out to a 144-node cluster. The table below provides a snapshot of the range.
The F810 is roughly equivalent to an F800 with added in-line compression. Dell EMC says this can compress data up to 3x but guarantees at least 2x for one year, giving it a 2.2PB logical capacity per 4U – 60 drive chassis. A 144-node cluster of F810s would have up to 79.6PB of logical capacity.
The IOPS and throughput rating of the F810 are identical to those of the F800 but the raw capacity range is different – 230TB to 924TB. This compares to the F800’s 96TB to 924TB. The F810 can be added to existing Isilon clusters.
More Clarity
ClarityNow provides a foundation on which Dell EMC can build secondary file data management facilities to compete with Cohesity and Rubrik.
The unstructured data management package provides a unified global file system view across heterogeneous distributed storage and the public cloud. Users have self-service capabilities to index, find, use and move files anywhere within this file system.
The software can cope with billions of files, according to Dell EMC, and the heterogeneity appears to be a useful attribute.
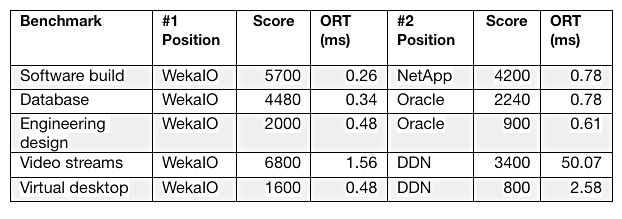
WekaIO has made a clean sweep of all five SPEC SFS 2014 benchmark categories.
SPEC SFS 2014 is a file serving benchmark with five different workloads: software builds, video streaming (VDA), electronic design automation, virtual desktop infrastructure and database. Each category test results in a numerical score and an overall response time (ORT.)
WekaIO’s Matrix software is a scale-out, parallel file system. It topped the software build category in January 2019 and has now achieved the top rank in outright performance and in response time, for the other categories
Here is a table it published:
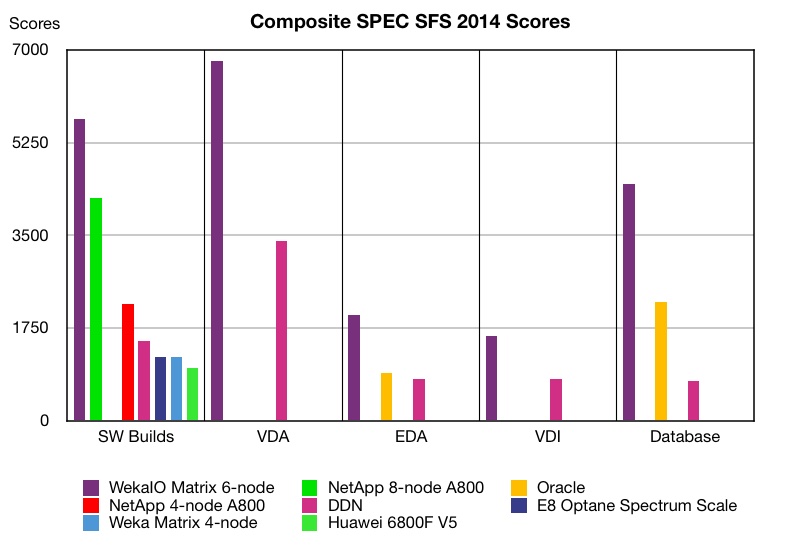
A composite chart shows WekaIO’s overall position:
The missing columns in the chart are there because not all vendors enter test results in each of the five categories.
According to this benchmark WekaIO Matrix is the fastest file serving system available.
Our understanding is that WekaIO’s performance grows linearly as nodes are added. If a competing vendor beats WekaIO in any category then it can just add nodes and beat them in turn.
Such is the nature of scale-out file storage.
Its two software build results, with a score of 1,200 from a 4-node system and 5,700 from a 6-node system, bear this out.
Comment
If WekaIO can beat any other competitor via node addition, then it can be argued that it has effectively killed the SPEC SFS 2014 benchmark.
Blocks & Files contends that you can’t have a benchmark in which there is only ever one winner. This benchmark needs a price/performance aspect or some other attribute so that there is another way of ranking suppliers rather than sheer performance modified by overall response time.