Veeam is adding Cobalt Iron’s SaaS data protection software to its product portfolio and has invested an unspecified amount in the company, according to a source with knowledge of the deal.
Cobalt Iron is developing a data protection abstraction layer as a SaaS service that provides backup across its existing IBM TSM (Tivoli Storage Manager) engine and soon across a Veeam engine.
The concept of separate backup engines underneath a data protection management abstraction layer is unique and holds interesting possibilities. For example, multiple backup engines could run under a single management layer, and there is the possibility to convert backup files between the different engines.
Cobalt Iron marketing VP Mary Spurlock confirmed that Veaam has a minority investment in the company but did not directly answer our questions about a technology relationship between the two. She gave us this statement instead.
“Cobalt Iron has been in market with a SaaS-based enterprise data protection solution for many years. Cobalt Iron’s analytics and data protection abstraction layer integrates with third party technologies to deliver enterprise outcomes. At this time, Cobalt Iron does not have a technology integration with Veeam nor an OEM relationship.
A Veeam spokesperson said: “This is the Veeam response as well.”
Data Dynamics is expected to announce NetApp will resell its StorageX file lifecycle management software.
The New Jersey company, founded in 2012, sells StorageX on a subscription basis. Lenovo resells its service and Data Dynamics says it has several multi-million dollar annual recurring revenue deals. It counts 26 of the Fortune 100 as customers and is profitable, Cuong Le, SVP, told us in a press briefing this week.
The company is currently buying Infintus Innovations, a small startup based in Pune, India. This will add AI-flavoured content analytics that StorageX customers can use to scan file or object content for particular types of data, for instance, personally identifiable information (PII).
Files that contain PII are recognised and can be stored more securely to meet compliance requirements and reduce the risk of exposure. The idea here is to add risk mitigation to file data management.
As with StorageX currently, old files accessed infrequently are identified through a file system scan and moved to lower-cost storage, obviating the need for primary storage or backup. This alone can save money, and competitors such as Komprise and Spectra Logic also do this. But Data Dynamics does a complete file move rather than leave a stub behind or adjusting a dynamic link. So there is no need to rehydrate the file for backup, as can be the case with stubbing.
Now is the AI of our content
StorageX is to also to add content intelligence, starting with PII scanning. The technique is to train machine learning models to recognise PII fields and then unleash them on a file estate. When a file containing PII is tagged for migration, it can be moved to more secure, cheaper storage. Data Dynamics intends to add standard templates that customers can use to specify different kinds of PII data or other sensitive data.
Enterprises increasingly recognising the necessity for basic file lifecycle management, and Data Dynamics can gain an edge by adding content intelligence. StorageX could be about to become a much more important product.
With NetApp coming on board and content intelligence slated for 2020’s second quarter, Data Dynamics sees itself at a growth inflection point.
The company is obtaining help from Mark Ward, an advisor and consultant. Data Dynamics is expanding its operating capability and geographic coverage. It is opening an office in the UK, for example. Also the company is to train the NetApp sales channel and make collateral to help sell the StorageX service.
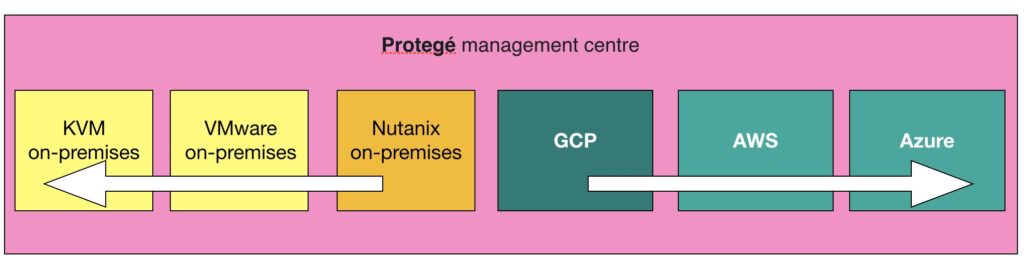
HYCU has announced general availability of its data protection-as-a-service offering called Protégé.
The data protection vendor revealed this as a project last month.
Simon Taylor, CEO, said: “It’s now become essential to provide a data management solution that complements the cloud of choice while simplifying key processes like data migration and disaster recovery.”
Protégé fully supports Google Cloud Platform with Azure and AWS coming. It provides app- and database-aware data protection, data mobility and disaster recovery. The service feature DR across across clouds; recovery of applications on a different cloud for test and dev; and lift and shift applications from on-premises to and, soon, between clouds.
The latter is said to be a 1-click operation, incorporating the automated migration of application components. The recovery of applications across clouds is defined as the delivery of consistent application copies from one cloud to another. This is also a single-click affair and migration can be on-demand or performed in a staged way.
Users access these facilities through a self-service portal. They can ensure service level objective compliance across several clouds through this portal.
Taylor told an IT Press Tour Silicon Valley briefing this week that Protégé’s cloud coverage will significantly expand in January. SaaS applications such SalesForce are also a natural focus.
Taylor said HYCU is expanding globally and Japan is a major focus in 2020. He said the company achieved 300 per cent revenue growth in 2019 and anticipates a similar revenue uplift in 2020 and HYCU becoming “very profitable”.
HYCU Protégé is available from any HYCU partner and ships at no cost with any licence of HYCU Data Protection. Data migration is available at $99 per VM and disaster recovery at $24 per VM per month.
Komprise cloud analytics can move objects between cloud object classes and the company is adding this capability to on-premises object stores.
Speaking to Blocks & Files today CEO Kumar Goswami and COO Krishna Subramanian told us Komprise will provide object store analytics that can report on an object store and say how objects are distributed by owner, size, creation date, access frequency and other filter tags. This is functionally equivalent to the company’s Deep Cloud Analytics for on-premises file stores. They did not reveal launch plans, but if they are talking to me about this service, first half of 2020 seems likely.
Object tiering is a new idea, although Goswami noted IBM already provides object tiering in its Cloud Object Store, which is available in IBM’s cloud or in an on-premises system. Subramanian told us other object storage suppliers are also developing object tiering but declined to name names. Blocks & Files thinks NetApp (StorageGRID), Cloudian and Scality are likely candidates.
Like files, objects have access frequencies and age, with lower access rates over time. It can make sense to move cold objects to cheaper storage to save money and make space in the main object store tier for more frequently accessed objects.
An object has an address based on its content. Within AWS an object has a URL and this is remapped if the object moves. Accordingly, an on-premises object store will need its object location metadata changing when objects change their location.
StorCentric looks to move ahead with QLC flash and add cross-product backup to the cloud as it integrates its four acquisitions. These were our takeaways from an interview with CEO Mihir Shah and CTO Surya Varanasi in Silicon Valley this week.
StorCentric was founded in 2018 as a private equity investment vehicle for Drobo, a consumer storage supplier. In August 2018 the venture-backed firm bought the Nexsan storage array business and this summer it acquired Retrospect, a backup company and Vexata, a struggling NVMe-oF, all-flash array startup.
This four storage properties combined have one million customers, mostly through Retrospect and Drobo, in more than 100 countries. StorCentric also claims 40,000 enterprise customers and $50m in annual revenues. The product lines inherited from the four acquisitions have separate engineering teams and are being developed under a technology roadmap.
In Retrospect
StorCentric CEO Mihir Shah
Retrospect backs up virtualized servers; the 20 year-old company has sold 500,000 licenses with 100PB of data protected and will become a cross-product backup facility covering Drobo, Nexsan and Vexata. StorCentric will add Retrospect backup to AWS and Google Cloud Platform. It can also be used to move data between StorCentric’s arrays.
Drobo has more than 400,000 customers and StorCentric will add a faster, bigger business-class iteration.
StorCentric product portfolio
There are three Nexsan array products, Unity, E-Series and Assureon, spanning medium and large enterprises. The high performance Unity file and block array will be developed with a software-only product deployable on X86 servers. Unity will be optimised for NVMe drives and quad-level cell flash. (StorCentric and Dell EMC are in dispute over the Unity brand name but, Shah says, Nexsan used it first.)
The dense E-Series can store 2.5PB of block data in a 12U enclosure. QLC flash will be supported using 2.5-inch drives in the first quarter next year. Varanasi said the E-Series software will reduce the amount of writes going to the QLC flash.
The Assureon archive object store will extend to archive data in the public cloud as a disaster recovery copy. It will be deployable as software on any x86 server and also in the cloud.
Vexata sits at the high end of StorCentric’s line-up. Varanasi said the company ran into problems because the sales cycle for its array took up to 18 months. Few sales resulted as Vexata burned through its cash.
According to Varanasi, the 4-node Vexata system can match the performance of the 4-node Oracle RAC and is 30 per cent cheaper. Its roadmap includes an entry-level dense system with 1PB in 6U using QLC NAND. This will have 50 per cent of the current TLC flash system performance at less than half the price, Varanesi said.
As with the Nexsan arrays, Retrospect will provide Vexata backup to and disaster recovery in the public cloud.
Shah said StorCentric had a strong focus on customer satisfaction, a land and expand customer account strategy and a focus on acquisitions and partnerships.
Our impression? This company knows where it’s going, has great channel up-sell and customer cross-sell opportunities, and has to show it can take advantage of these opportunities.
Western Digital will introduce MAMR technology with coming 18 and 20TB drives. Seagate is developing HAMR technology for similar capacity drives.
CFO Robert Eulau and Siva Sivaram, President, technology and strategy, told attendees at a Wells Fargo TMT Summit 2019 this month that HAMR technology adoption remains a possibility. WD expects rising production of 18TB and 20TB drives in 2020, especially for 18TB drives.
The company said it could adopt HAMR as capacities rise to 25TB and beyond. It remains agnostic about which technology will be its long term choice, out to 50TB disk capacities. WD has HAMR expertise, possessing more than 500 patents relating to HAMR tech, so could go either way.
Hard disk drive (HDD) capacities rise in two main ways. One is by adding platters to an enclosure – as with helium-filled nearline drives moving from 6 to 8 and 9 platters. The second is to reduce the size of the recorded bits and so cram more into a disk drive track.
Current perpendicular magnetic recording technology is producing 14 and 16TB drives but this is reaching its limit in terms of reducing bit size. The recording medium becomes increasingly unreliable and causes bit values to flip. Reformulated media requires energy to be beamed at a bit area before writing the data, which then becomes stable when the so-called energy assist – microvaves or heat – is removed.
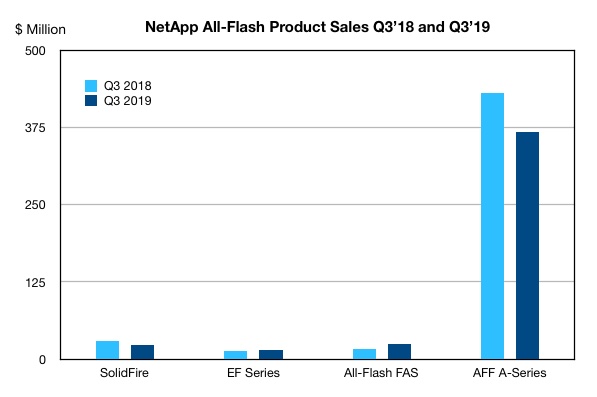
NetApp’s AFF A-Series, the world’s best selling all flash array, is less best selling than it used to be. In the third quarter ended September the product line generated $360.9m revenues, a massive fall from last year’s $430.9m.
And market conditions do not appear to be to blame, with global market Q3 all-flash array (AFA) revenues climbing 12 per cent year on year to $2.58bn.
The numbers were revealed in a mail to subscribers by Wells Fargo senior analyst Aaron Rakers and include IDC Storage Tracker numbers.
Rakers examines AFA product sales by Dell EMC, HPE, Pure Storage, IBM , Hitachi, Huawei and others. Dell EMC dominates with 33.4 per cent share – up from 31.8 per cent a year ago – and about twice that of second-placed NetApp.
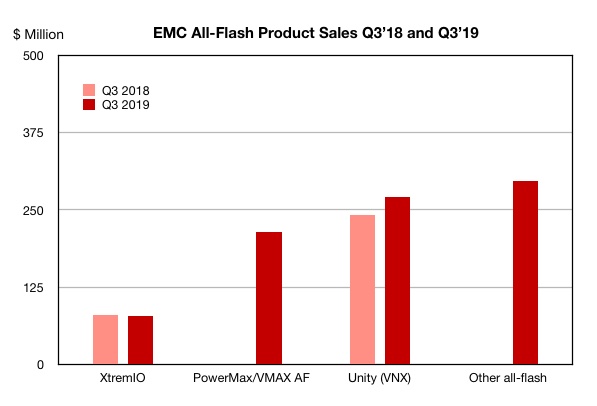
Dell EMC’s overall AFA sales rose 17.2 per cent from $735m to $861.2m on the back of good growth for all its products, especially PowerMax/VMAX AF and Unity.
NetApp’s market share declined from 21.3 per cent to 16.6 per cent. The EF-Series and all-flash FAS recorded small gains but these were not enough to offset the big AFF A-Series revenue fall and a small decline in SolidFire revenues.
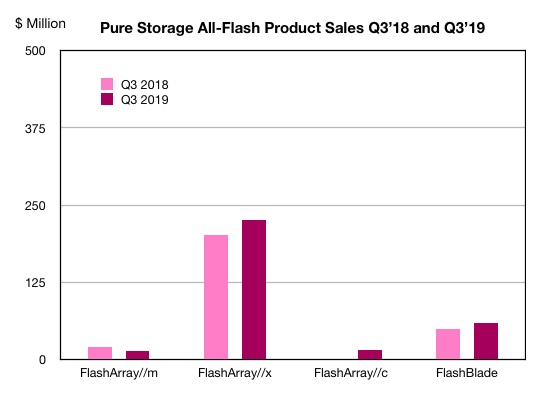
Pure Storage revenues grew 15.4 per cent from $188.7m to $221.6m and market share rose from 11.7 per cent to 12.1 per cent, to overtake HPE. Pure Storage demonstrated strength through product breadth – but to a lesser extent than Dell EMC.
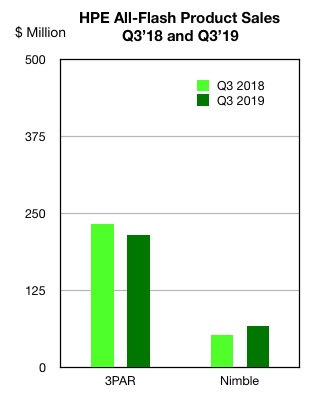
HPE has two AFA ranges and sales for the bigger line – 3PAR – fell over the year. The small rise in Nimble sales didn’t prevent an overall 1 per cent sales decline from $285.5m to $282.6m. Market share fell from 12.4 per cent to 11 per cent.
Rakers didn’t provide per-product numbers for IBM, Hitachi and Huawei. But Huawei AFA sales rose 122.9 per cent, doubling market share from 4.2 per cent in Q3 2018 to 8.4 per cent this year. This is almost equal to IBM’s 8.6 per cent share (up from last year’s 8.2 per cent). Hitachi also grew its share from last year’s 3.8 per cent to 4 per cent.
According to IDC total flash capacity shipped was about 3.2EB during 3Q19, up 40 per cent. All-flash capacity shipped accounted for about 13 per cent of total external storage capacity shipped in 3Q19, up from 9 per cent a year ago.
To conclude, this a mixed bag for vendors, with NetApp and HPE looking lacklustre in comparison to Dell EMC. Pure, Hitachi, Huawei, and IBM had the satisfaction of growing their minor shares. Huawei’s success is particularly noteworthy, considering the Chinese company is locked out of the US market. It is becoming a formidable competitor in markets where it is active.
Version 7 of MemSQL’s relational database, out today, does space-saving in memory and adds hash indexing on disk to speed access.
This is phase 1 of MemSQL’s single row+column concept, called SingleStore. MemSQL 7.0 also adds accelerated synchronous replication and incremental backup, making it better suited to be a system of record for critical workloads. The upgrade is generally available for on-premises use or via the company’s Helios managed service on AWS.
MemSQL Co-CEO Nikita Shamgunov said in a statement today: “Having MemSQL 7.0 available on AWS gives our customers – which include global enterprises that are leaders in their industries – easy access to a fast, scalable data platform for operational analytics, ML, and AI.
“Upgrading MemSQL Helios with the 7.0’s new SingleStore and system of record functionality continues our relentless focus on eliminating the speed and scale limits that organisations have long struggled with in their operational workloads.”
MemSQL Rowstores and Columnstores
Relational databases (RDBMS) are tables which store data in rows and columns. They can be queried using Structured Query Language (SQL) and accessed in row or column mode. Rows are identified by keys and can be directly accessed by these keys. This makes them suitable for latency-sensitive applications like online transaction processing (OLTP)
The MemSQL database operates in two formats. The rowstore format executes entirely in memory, making it much faster than the columnstore format which is stored on disk. Slower columnstore access makes it applicable to less latency-sensitive work such as analysis. It is also the choice if you have more data than will fit in DRAM.
MemSQL 7.0 remedies two problems. First, more memory is needed as row format data grows, making it expensive and thereby limiting its applicability.
Secondly, accessing columnstore data means scanning all the columns to find the data record needed, as there is no key access to an individual column.
Therefore columnstore data in MemSQL is inherently slower to access. It is mostly stored on slow external storage with only a small cache in memory. Also, the RDBMS access method provides no direct access to a column, so millions of columns may have to be scanned to find the one of interest.
Version 7 of the MemSQL database has remedies for both the row memory capacity and columnar disk access time problems.
Sparse compression
Rowstore data tables now get compression of records containing null data. Every record has a fixed-width section containing ordinary data and index keys and a variable width section that can be slimmed if it contains fields with null data. The variable width portion contains sparse data and a bitmap is used to indicate which fields containing null data.
This sparse data compression preserves fast access to rows while shrinking them if they have null data fields. MemSQL rowstore users can now store more data in memory than before, with the extra effective capacity varying with the amount of compressed null data. For instance, if half the values are null you can double the effective memory capacity.
In the future MemSQL intends to compress fields containing blanks and zeros, and store small integers in less than the current 8 bytes. The bitmap is wide enough at 4 bits to handle nulls, blanks, zeros and small integers, according to the company.
Columnar hash indexing
MemSQL columnstore tables are divided into 1 million-row segments. Columns are stored independently within each segment, in contiguous parts of a file or in a file by themselves. Accessing a field in a single row in a segment entails scanning the entire million-row segment, with many many file accesses.
MemSQL 7.0 introduces subsegment access. The software calculates the location of data within a columnstore for a row, and then reads only the part of a column segment that is needed to locate and access that row. This reduces the task from reading a million rows to reading a few thousand.
V7 also introduces hash indexes on columnstores, with users able to specify hash indexing of individual columns. Selection operations can be executed using the index without any scanning. Using hash indexes to enable filters can be orders of magnitude faster than full or partial-segment scanning.
The speed increase in columstore SQL is so large that MemSQL floats the idea that it could be used for some, less latency-sensitive OLTP applications.
This new version also introduces row-level locking of a columnstore, which is much less access-limiting than the existing segment-level locking.
AWS Outposts is a converged infrastructure rack, announced at re:Invent in Las Vegas this week. In effect this is Amazon’s public cloud in a box, delivering an all-AWS hybrid computing environment within the customer’s data centre.
By coupling Outposts so tightly to AWS, Amazon is taking a different approach than other converged infrastructure rack vendors such as Dell EMC.
AWS Outposts is a fully-managed compute, networking and storage rack built with AWS-designed hardware that allow customers to run AWS services on-premises or in co-location sites and is connected to the AWS public cloud.
AWS Outposts rack
An Outpost rack is conceptually equivalent to a converged infrastructure (CI) rack such as Dell EMC’s PowerONE and VxBlock systems.
The Outposts rack contains servers, storage, AWS software, redundant power supplies and built-in top-of-rack network switches. The switch supports 1/10/40/100 Gbit/s uplinks. There are Outposts compute and storage capacity options. Customers can also work with Amazon to create a custom combination with their desired EC2 and EBS capacity. This combo is pre-tested and validated by Amazon before delivery.
An AWS Outposts FAQ states: “AWS Outposts leverages AWS designed infrastructure, and is only supported on AWS-designed hardware.” For example, EBS snapshots created on an Outposts rack are stored in the connected region’s S3 vault.
The Outposts rack must be connected across the public internet to a parent AWS region with a high-availability link. AWS uploads and executes software upgrades and patches across this link.
Configurations
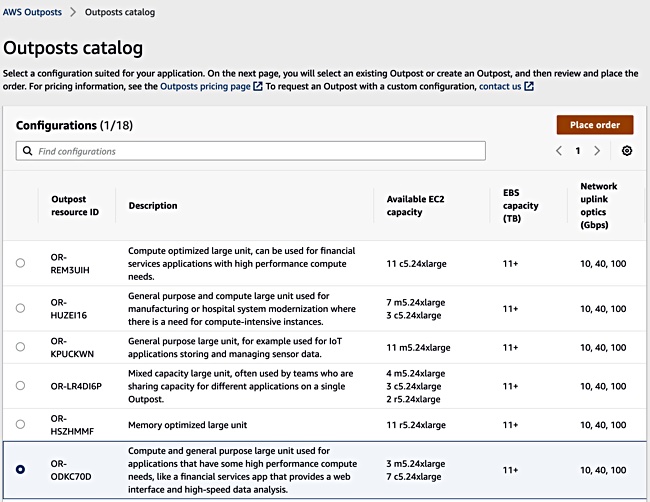
Outposts racks are configured by available EC2 and EBS capacities. For example: Compute optimised – 11 c5.24xlarge EC2 capacity and 11+ TB of EBS capacity. There are options for memory optimised, graphics large units, general purpose units. Here is a sample from a trial configuration process.
Outposts configuration presents a near ‘black box’ defined by its deliverable ECS and EBS resources
There is no option to select specific server CPU models with their cores and clock rating. You cannot specify the amount of memory nor the amount and type of storage media. We saw no option to specify particular software or Amazon services.
Prices lists EBS storage tiers – 2.7TB, 11TB, 33TB and 55TB – with per GB/month prices ranging from $0.25 to $0.55.
Customers can pay all upfront, make a partial upfront payment or pay through monthly subscription. For example, an OR-FWTFFXJ compute-optimised unit with a three-year term costs $239,761.41 upfront, $123.650.18 partial upfront payment and $3,434.73 monthly or $7,148.67 monthly.
The most costly Outposts rack, an OR-HSZHMMF memory-optimised large unit, costs $1,079,998.31 upfront or $33,869.12 per month.
These prices do not include operating system usage, which is charged by the second per instance.
AWS Services on Outposts are priced based on usage by the hour per instance and excludes underlying EC2 instance and EBS storage charges. Available AWS services include RDS, ECS, EKS, EMR and App Mesh and their prices are explained in their service web pages. For example, this is the EKS pricing page.
VMware intends to launch VMware Cloud on AWS Outposts next year so users can have VMware on their own in-premises gear, in the AWS public cloud and on the Outposts rack.
Cohesity, Druva and Veritas have each announced that their protection products support AWS Outposts.
Let’s now explore how AWS Outposts differs from Dell EMC’s PowerOne and VxBlock CI systems.
Dell EMC PowerOne and VxBlock
PowerOne is a converged infrastructure system comprising compute, storage, networking, VMware virtualization software, and data protection in a single rack. All components come from Dell Technologies. The technical specifications list the components in each category:
PowerOne configuration
The customer has to understand their workload and what it needs in terms of compute, storage, networking and protection capacity. On delivery it has to be set up and an automation engine helps with this and with provisioning resources for application workloads.
The PowerOne selection language is different from that of AWS Outposts which is specified in terms of EC2 instance types and EBS capacity.
Dell EMC’s VxBlocks are also specified by components and use Dell EMC storage, VMware virtualization software and Cisco servers and networking.
Customers can run a VMware environment in Amazon but there is no easy way to port VxBlock applications to run in AWS. Typically, VxBlock hybrid cloud entails backing up VxBlock data to AWS, not application portability.
When – or if – VMware Cloud Foundation runs on VxBlock and PowerOne we can look forward to an all-VMware hybrid cloud that embraces CI systems from Dell EMC and AWS Outposts.
Pricing for PowerOne and VxBlocks is not publicly available.
This way to the hybrid cloud
Ideally a hybrid on-premises public cloud environment would have a simpler management plane and application portability between the on-premises and public cloud systems.
AWS Outposts enables customers to run an all-Amazon hybrid cloud with Outposts on-premises linking to the AWS public cloud under a single AWS management facility.
Amazon sees hybrid cloud as the AWS public cloud connected to AWS Outposts.
Dell EMC envisages the hybrid cloud as its on-premises infrastructure extended out and linked to multiple clouds, for backup or storage tiering, for example. Customers should be able to run virtual machines that run on-premises in the public cloud and also containers.
With this model, the on-premises supplier calls the shots and helps itself and its customers to avoid cloud lock-in.
By contrast, AWS Outposts shows Amazon constructing the hybrid cloud as an entirely in-house affair with a unified on-premises and public cloud AWS environment managed from AWS. With the notable exception of VMware Cloud Foundation, this vision does not accommodate third party vendors or integrate with non-Amazon environments. At least, not at the moment.
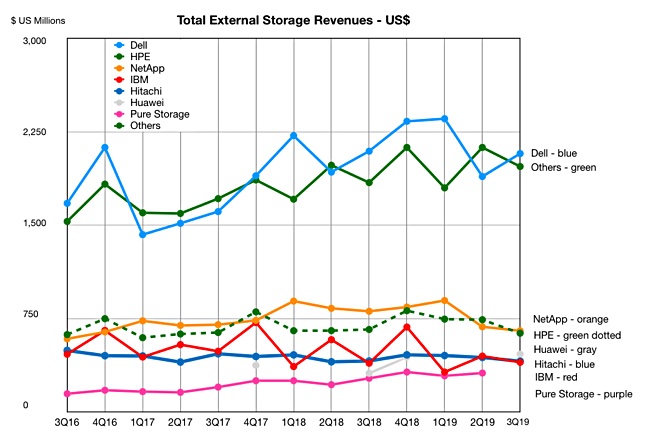
Dell Technologies pulled in external storage revenues of $2,075.8m in the third quarter, accounting for 31.5 per cent of an anaemic global market, up 1.3 per cent to $6.6bn.
Dell revenues fell 0.9 per cent year on year but the runaway market leader did rather better than NetApp in joint second place, which experienced a 19.4 per cent decline in revenues to $651.7m, taking 9.9 per cent share.
The figures, recorded by IDC’s Worldwide Quarterly Enterprise Storage Systems Tracker, show HPE in joint second place with $632.2m revenues, down 4.6 per cent and taking 9.6 per cent share of market.
Three suppliers share fourth place. Huawei’s revenues grew 49.6 per cent to $463.5m, for seven per cent share. Hitachi’s $407.1m revenues were down 0.4 per cent, to take 6.2 per cent share. IBM grew revenues 1.8 per cent,to $398.4m, for 6 per cent market share.
NetApp and HPE have hovered around $750m quarterly revenues for several quarters. IBM matched that number in 2017’s fourth quarter but is now dipping below $400m and playing tag with Hitachi, while Huawei overtook both in Q3. Pure and Lenovo showed strong revenue growth, according to IDC, but are not at top-table levels.
IDC’s storage tracker show capacity shipments grew 6.8 per cent to 17.3EB. But total market capacity shipments, meaning external storage plus server-based storage, fell 13.9 per cent to 98.8EB. IDC has not released a revenue number for server-based storage. So we do not know if server-based storage revenues are rising, falling or flat.
However, the technology research firm reports strong double-digit growth of all-flash array sales with declines in disk-only and hybrid flash+disk external storage sales.
Quarterly trend of IDC’s external storage tracker.
We have charted vendor growth rates to show how Huawei tops the growth rate table with NetApp underpinning it.
We can deduce that NetApp did not sell a lot of all-flash arrays, as revenues declined 19.6 per cent while all-flash array revenues showed strong double-digit growth.
DDN separately announced that it has entered lDC’s rankings of major all-flash array vendors, but it did not reveal numbers apart from Q3 2018 to Q3 2019 revenue growth of 78.7 per cent. According to DDN, this outstripped Dell, NetApp, Pure and IBM. IDC has not publicly revealed all-flash array vendor revenue numbers.
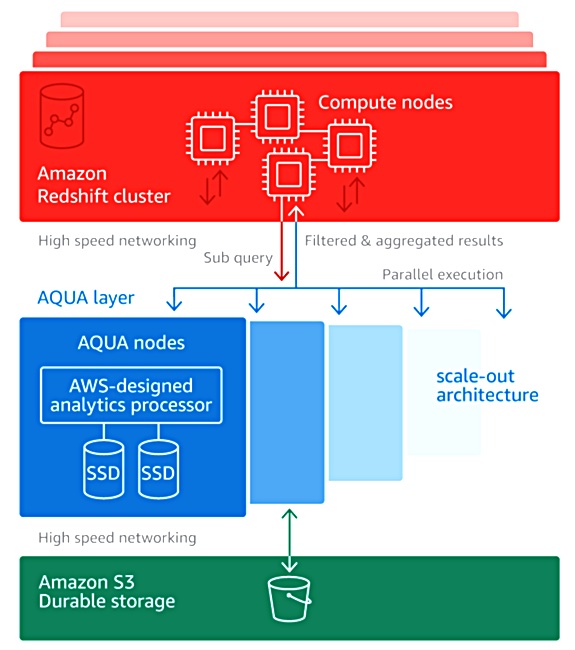
Amazon Web Services AQUA (the Advanced Query Accelerator) is a scale-out set of hardware nodes that provides parallel processing of data sets moving from S3 buckets to the Redshift data warehouse.
Let’s take a closer look to see why AWS chose the custom home-grown route with AQUA, announced this week, instead of relying on commodity hardware.
The AQUA hardware sits inline in the network between the S3 storage and Redshift cluster, acting as a caching bump in the wire and also as a sub-query offload processing system. AQUA offloads certain repetitive tasks to dedicated hardware, enabling a cluster of Redshift processors to do their work quicker. It pre-processes the dataset being moved to the Redshift cluster so that less data hits this cluster and the cluster can run its application routines without having to do so much system-level work.
The claimed result is up to 10-times better query performance than other cloud data warehouse providers. How does AQUA do this?
AQUA in-line processing layer
The AQUA module hardware consists of FPGAs to run customised analytics routines and AWS Nitro chips. AQUA modules scale out as needed and operate simultaneously. Data is stored in SSDs.
The FPGA hardware does dataset filtering and aggregation. Filtering removes unwanted information from a data set to create a sub-set. Aggregating provides summing, counts, average values and so forth of records in a data set. The result is that less data is sent to the Redshift cluster. The cluster has to do less work on it because of the pre-processing, and can offload certain sub-query processing to the AQUA nodes.
The Nitro hardware deserves a closer look and its origin needs putting in context.
AWS Nitro
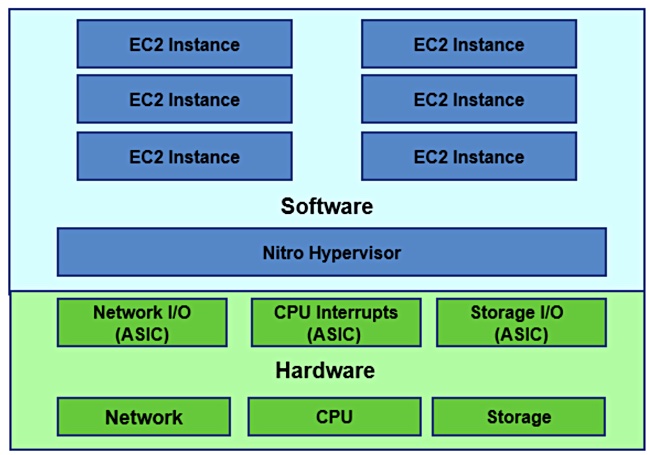
Nitro is both a hypervisor and hardware. AWS EC2 compute users have their applications run as Amazon Machine Instances (AMIs) in virtual machines (VM) on a server. As Metricly blogger Mike Mackrory said;”EC2 is a Service of Virtual Machines.”
When the EC2 service launched in 2006 AWS used Xen Paravirtualization for its physical servers to enable and support its VMs. A VMM (Virtual Machine Manager) function receives calls from the VM for network and storage IO and similar system-level requests.
The VMM dealt with many of these requests by passing them to software routines called device models (DMs) to handle tasks such as sending data across a network to a different server or accessing storage.
The Xen hypervisor uses the server CPUs to run the VMM and DM software, taking up CPU cycles. AWS developed ASIC (Application-Specific Interface Card) hardware, Nitro ‘cards’, to replace these DMs and run their functions faster.
They handle networking, storage (via NVMe to EBS), security, management and monitoring functions as hardware invocations from the VMM, via a Nitro hypervisor, and replace the software DMs. The Nitro hypervisor replaces the Xen hypervisor on Nitro-based systems.
Nitro hypervisor and hardwire diagram.
Other Nitro cards provide handling PCIe network interfacing, local NVMe storage, Remote Direct Memory Access (RDMA), and EBS storage, where it handles encryption and flash drive monitoring. Think of Nitro as a family of cards and ASICs, some of which are used by AQUA.
Redshift-only?
The AQUA nodes contain unspecified Nitro ASICs which handle compression and encryption. Together with the FPGAs they provide a Redshift data warehouse acceleration engine which is denied to on-premises data warehouse hardware buyers.
AQUA is slated for delivery in the middle of next year. It will be interesting to see how AWS Redshift compares in query speed and cost with Snowflake and Yellowbrick Data cloud data warehouses. These Redshift competitors can run Nitro-enabled EC2 instances.
AWS exposes services based on its hardware and software infrastructure. These services abstract the details of its infrastructure. Will it expose the specific AQUA Nitro cards and chips and FPGAs as services to customer-competitors Snowflake and Yellowbrick? We ask this because AWS has AQUA ‘secret sauce’ to accelerate Redshift. It has no incentive to provide this to Redshift competitors.
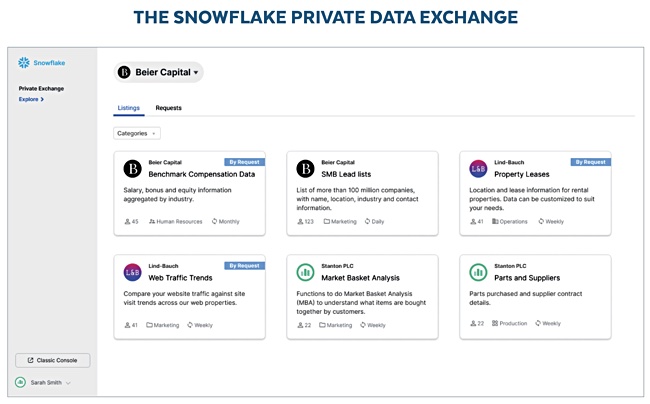
Snowflake, the cloud data warehouse power house, has opened a Private Data Exchange for listing Snowflake data sets and secure sharing within a business and its ecosystem.
CEO Frank Slootman said in an announcement yesterday: “The Snowflake Private Data Exchange represents the future of managing and sharing data broadly and securely inside enterprise and institutional boundaries. The data exchange model will become the deployment standard for exploring, discovering and sharing data enterprise-wide.”
Currently, a business unit has to set up a special arrangement to share data warehouse data sets with other departments or affiliates in a supply chain. This can be cumbersome and time-consuming, perhaps involving APIs, FTP transfers or Extract-Transform-Load (ETL) procedures to move data copies from the warehouse to the other parties.
Snowflake’s Private Data Exchange (PDX) acts as a central hub in which data sets can be listed and specific third-parties given access. Once validated they go straight to the data.
Snowflake PDC interface and data set listing.
Snowflake said a PDX can be used share data sets with authorised third parties in a business eco-system, for bi-directional data exchanges, or even to sell data set access for a fee to customers. We could think of manufacturing chain or financial institution partnerships using it to share sensitive data.
Snowflake made the announcement shortly before AWS unleashed marketing war today with its latest Redshift data warehouse acceleration developments.