Microsoft has added Azure NetApp Files to US government region data centres, making it available to federal, state and local agencies.
Azure NetApp Files is a fully-managed Microsoft Azure cloud service based on NetApp ONTAP systems located in its regional data centres. It is currently available in Canada and the USA, in seven of Azure’s 60+ regions, with North Central US region availability expected by the end of 2020;.
Deployment of Azure NetApp Files to government data centre regions started in Virginia, followed by Arizona and Texas deployments. That adds three more regions to the seven listed by Microsoft.
Anthony Lye.
Anthony Lye, NetApp’s SVP and GM for the Cloud Data Services business unit, provided a quote. “Azure NetApp Files is a significant Azure differentiator, and a game changer for all organisations that want to fully harness the value of cloud.”
Lye said in a February NetApp blog: “Microsoft and NetApp co-created Azure NetApp Files … NetApp has an inside track at Microsoft. We are, for all intents and purposes, an engineering team within Microsoft.”
Azure NetApp Files is delivered as an Azure first-party service, which allows customers to provision workloads through their existing Azure agreement. No additional NetApp ONTAP licensing is required.
Azure also has its own basic Azure Files service with SMB file shares. There are no listed Azure partnerships with other filesystem suppliers such as Qumulo, or WekaIO. Scality is developing scale-out like system for Azure’s Blob object storage service.
Azure Government has US Federal Risk and Authorization Management Program (FedRAMP) High Baseline level authorisation, meaning it meets security requirements for high-impact unclassified data in the cloud.
Percona’s open source MySQL database runs faster with ScaleFlux computational storage SSDs. And they have the benchmarks to prove it.
The companies compared the ScaleFlux CSD 2000 with an Intel DC P4610 SSD and found that the CSD 2000 was up to three times faster in certain workloads such as compression
In their test results document, published today, Percona and Scaleflux state “Our testing verifies ScalesFlux’s claims that if a customer has a Write heavy or mixed Read/Write workload the ScaleFlux drive can improve their performance.”
This sounds attractive, but will customers bite?
The basic idea of computational storage is this: dedicated hardware in storage drives perform operations such as compression and decompression and video transcoding faster than a drive’s host server.
For it to succeed, any computational storage device needs to be faster than using the same host server with ordinary (non-computational) SSDs. So ScaleFlux passes this table stakes test. But is this enough to overcome any reluctance by customers to rely on single-sourcing computational storage drives to get the performance they want?Traditionally, customers prefer multiple sources for components such as disk drives and SSDs, to avoid supplier lock-in,
And then there’s the price performance angle. The extra queries per second delivered by the CSD 2000 have to be affordable and worth the money. Expect a spreadsheet blizzard from computational storage suppliers trying to prove their case.
The CSD 2000 benchmarks
The CSD 2000 includes hardware GZIP compression that effectively doubles capacity and delivers 40 to 70 per cent more IOPS than similar NVMe SSDs on mixed read and write OLTP workloads, according to Scaleflux.
For its benchmarks, Percona and ScaleFlux compared a TB CSD 2000 to an Intel DC P4610 SSD with 3.2TB capacity. This is a 64-layer, TLC, 3D NAND SSD with an NVMe interface running across a PCIe gen 3.1 x 4 lane connection.
The CSD 2000 is also an NVMe/PCIe gen 3 x 4 device, using 4TB ofTLC 3D NAND and with an FPGA doing storage computations, like compression, in the drive’s enclosure. As well as compression it has a customisable database engine accelerator. There are more details in its datasheet.
Percona’s database has a DoubleWrite Buffer to protect against data loss and corruption, in which a set of data pages are pulled from a buffer pool and held in the DW buffer until they are correctly written to the final database tablespace. The CSD 2000 has an Atomic Write feature which renders the Double Write Buffer redundant and it can be turned off, speeding database writes. Intel’s P4610 has no atomic write feature.
Read-only, write-only and mixed read/write workloads were tested with Percona v8.0.19 with a Sysbench data schema. The Intel drive used Percona with the DoubleWrite feature and, separately, server-based compression. The ScaleFlux drive was tested with and without the DoubleWrite feature being turned on.
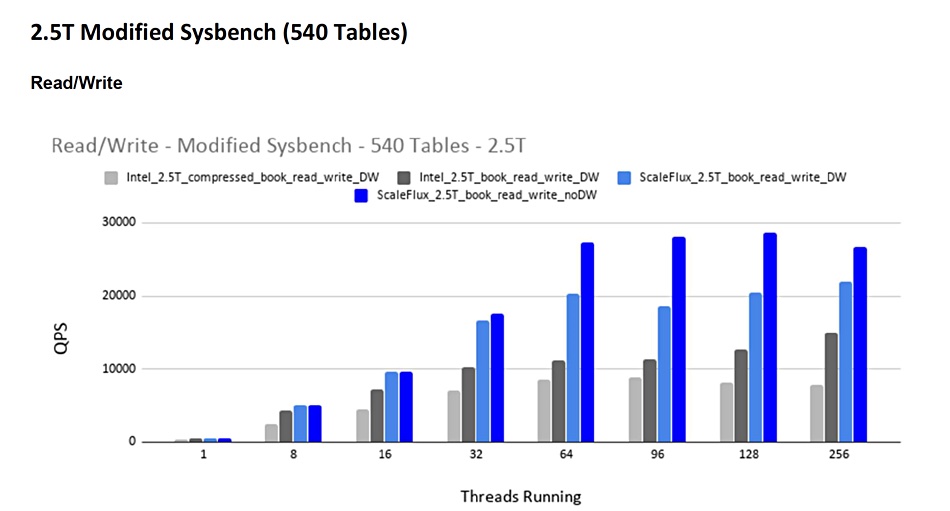
In general, the ScaleFlux drive was faster than the Intel SSD, especially with DoubleWrites turned off. Here is a chart of mixed read/write results to show this, with a 2.5TB, 540 table, data set:
As the number of threads increases beyond 8 up to 256 the ScaleFlux advantage grows, with the Atomic Write becoming significant at 64 threads and up (bright blue bars). Turning off Percona’s DoubleWrite allowed the CSD 2000 to boost its performance from just over 2,000 queries per second at 64 threads to more than 2,700.
At the 64 to 128 thread level, the ScaleFlux Drive is up to three times faster than the Intel drive (light grey bars) when the host server is doing the compression in software.
HPC workloads vary from using very large files, through medium-sized ones to myriad small files and mixed workloads. An HPC storage system must be tuned to match the IO patterns of its main workloads – unless, of course it is bought for one specific type of file IO,
Panasas, the HPC file storage supplier, has devised a workaround with a PanFS update that auto tunes to speed file access with different IO types.In its announcement today, Panasas claims all other parallel file systems require clumsy tiering and-or manual tuning to compensate for specific workload characteristics and changes. That leads to inconsistent performance and higher admin costs.
Panasas’s new feature, called Dynamic Data Acceleration (DDA), does this automatically using the same tiering and caching ideas and does it consistently faster with no need for manual tuning.
Panasas ActiveStor Ultra.
With DDA, NVMe SSDs store metadata, lower-latency SATA SSDs store small files, and large files are stored on low-cost, high-bandwidth disk drives. Storage-class memory NVDIMM holed transaction logs and internal metadata, and the most recently read or written data and metadata are cached on DRAM.
Small file IO has more metadata accesses – such as file and folder lookup – as a proportion of an overall file IO than large file IO, where the data portion off the IO can be many times larger than the metadata portion.
PanFS dynamically manages the movement of files between SSD and HDD, and uses fast NVMe SSDs, NVDIMM and DRAM to accelerate file metadata processing. That speeds small file IO much more than it would large file IO, where the metadata processing occupies a much smaller percentage of the overall file IO time.
DDA is included in the latest version of PanFS, which is now generally available to supported customers.
IBM has improved performance and functionality for the mainframe focused storage array and virtual tape library (VTL) products.
The DS8900F flash array gets a 70 per cent increase in memory cache size from 2TB to 3.4TB, enabling the consolidation of workloads into a single DS8900F system. For example, IBM cites 8 x DS8870 arrays being consolidated into a single DS8950F.
David Hill, a senior analyst at Mesabi Group, provided a prepared quote for IBM: “IBM has done a good job in providing a comprehensive portfolio of storage for IBM Z solutions to address every enterprise data storage requirement and meet the demands of a modern, agile and secure to the core infrastructure.”
The DS8910F can be integrated with the latest z15 model T02 mainframe and LinuxONE III model LT2 product, which were announced on April 14.
The DS8900F now integrates more closely with the TS7770 VTL, a disk array with a tape library interface;
The DS8900F can compress data before sending it across a TCP/IP link to the TS7770, which is configured as an object target and can store up to 3 times more data.
SP 800-131A compliant In-flight encryption is added to the DS8990F for sending data to TS7770s.
Transparent Cloud Tiering (TCT) is introduced to the DS8900F and TS7770, automating data movement to and from the cloud, and reducing mainframe utilisation by 50 per cent for this work.
The DS8900F’s Data Facility Storage Management Subsystem (DFSMS ) uses TCT to create full volume backups to the cloud which can be restored to any DS8900F system.
A disaster recovery feature involves data sets copied from a grid of TS7770s and sent to cloud pools where they are managed by DFSMS. These pools can reside in IBM’s Cloud, AWS S3, IBM Cloud Object Storage on-premises, and RStor. Version retention time is enabled within each cloud pool. The data sets can be restored to an empty TS7770 outside the original grid.
Minor storage news from IBM has SAS interfaces being added to TS1160 tape drives and the TS4500 tape library getting support for the TS1160 drives.
You can read an IBM blog about these announcements and a wider scope blog for additional mainframe-related news.
Four of the most important domesticated silk moths. Top to bottom: Bombyx mori, Hyalophora cecropia, Antheraea pernyi, Samia cynthia. From Meyers Konversations-Lexikon (1885–1892)
Silk is the new name for Kaminario, an on-premises all-flash array startup, that has transformed itself over the last three years into a cloud block storage software company.
Derek Swanson.
Blocks & Files took the opportunity to interview Derek Swanson, Silk CTO, about the company’s transition.
Blocks & Files: Why did Kaminario change its name to Silk?
Swanson: Lots of reasons. Flash and the public cloud are revolutions. … DevOps and the public cloud are forming a new paradigm … More and more enterprises are looking at putting storage in the cloud. Everyone wants to be cloudy, with a legacy footprint. We wanted to acknowledge what’s going on as we are now a cutting edge cloud storage company and not just a legacy, on-premises storage supplier.
Also we’re not a startup anymore. We have a 10-year old software stack that’s been fully ported to the public cloud. It runs with a consistent 300-400 microsecs latency and it’s not using a caching engine. … That contrasts with NetApp and its 10 to 30 millisecs performance in the cloud. … Everything is done in DRAM. … The user experience should be the same on-premises and in the public cloud.
We do all our development on GCP and have done for many years now. Our GCP deployment happened in August 2019. Now we have AWS as well with Azure following in the next few months.
Our controllers are active:active and storage performance scales by adding another compute engine.
Blocks & Files: What about high-availability in the public cloud?
Swanson: Tier one apps running in the public cloud need 100 per cent availability across zones and regions. We do snapshots but we need synchronous writes to multiple zones and regions. That requires write-many snapshots and synchronous replication. We have a robust solution coming later this year.
Blocks & Files: Does VisionOS have predictive analytics? What do they do?
Swanson: VisionOS sends telemetry to Clarity in GCP and we do predictive analytics for performance, capacity, hardware and software failures. We push out patches and firmware upgrades. A minor hardware event pattern can help predict a failure. We initiate pro-active support tickets and up to 92 per cent of all tickets are initiated by us, not customers. In fact we tell the customers.
Blocks & Files: Does Silk think there is a need for a unified file and object storage resource?
We provide a dedicated block store and frontend it with a unified file/object head today. For us to develop a unified file and object offering would be cost-prohibitive. We use other people’s front ends; Ceph, Gluster and Windows Storage Server, for example.
Blocks & Files: Will all storage suppliers have to go to a homogenous, unified on-premises and public cloud offering like Kaminario?
Swanson: The problem is that the big boys sell hardware. Nutanix took a huge hit by exiting the hardware business. The big storage guys couldn’t do it; there would be too big a revenue hit. Co-locating hardware in the public cloud is a short-term fix.
Blocks & Files: What do you think of Pure Storage’s Cloud Block Store public cloud implementation?
Swanson: It’s not a scalable architecture, using active:passive controllers. To provide scalable performance you must have dedicated processing power and memory.
Pure uses NVRAM as a write cache with NVMe SSDs to commit writes. It’s very fast but it’s not DRAM – and you can’t do it in the cloud. Pure’s storage performance is slower in the cloud than what they get on-premises. It’s a limitation of their architecture. Fixing this would need a rewrite of its Purity OS.
Blocks & Files: How is Kaminario’s move to the hybrid, multi-cloud doing?
Swanson: Customers like it, particularly the on-premises migration element. We’re in a lot of proof-of-values (concepts). A surprising number of cloud-native customers are finding their public cloud storage performance is limited. They have no shared storage and can only get more performance by buying excess compute and networking in the cloud, meaning extra costs.
So we now have interest from cloud customers and Google as we solve storage performance problems in the cloud. Customers don’t need to rewrite their apps. We are partnering and co-selling with Google and hope to do the same with AWS.
Net:Net
The metamorphosis into Silk has taken Kaminario two and half years. In January 2018, the company made its Vision array OS and Clarity analytics software available on a pay-as-you-go basis to cloud service providers. It exited the hardware business at the same time, supplying its software to run on certified hardware built by Tech Data. This hardware and Kaminario’s software became available on subscription in June 2019.
Kaminario started talking about a single storage data plane spanning multiple clouds at the end of last year. And in April, the company announced the Vision OS roadmap, with porting to AWS, Azure and the Google Cloud Platform (GCP).
Google is becoming an important partner. If Swanson is right about Silk’s scalable and consistent performance advantage in the cloud then Silk could grow at the expense of all-flash array vendors, such as NetApp and Pure, with cloudy ambitions.
Toshiba disk drive shipments fell by half in the second 2020 quarter – an outage at its Philippines disk manufacturing plant is thought to be to blame.
Wells Fargo senior analyst Aaron Rakers pointed to the “severe decline” in a note to his subscribers. “Toshiba shipped ~9.55 million total HDDs during the June quarter, which represents a 51 per cent y/y decline and down 32 per cent q/q.”
Toshiba Information Equipment (Philippines) Inc., Binan.
Rakers doesn’t say what kind of outage affected the plant. And there is no mention of Covid-19 factors, such as lockdown, that may have affected Toshiba’s HDD ship numbers.
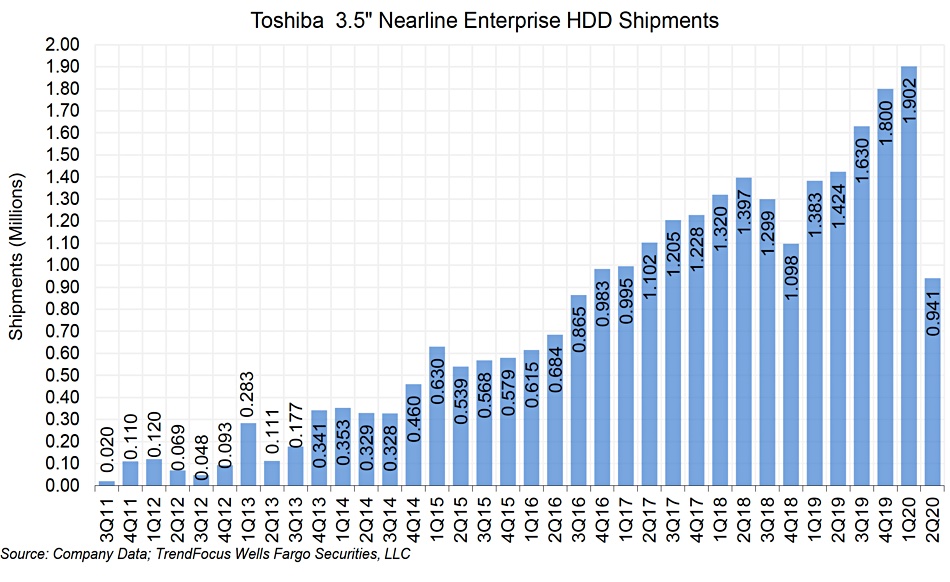
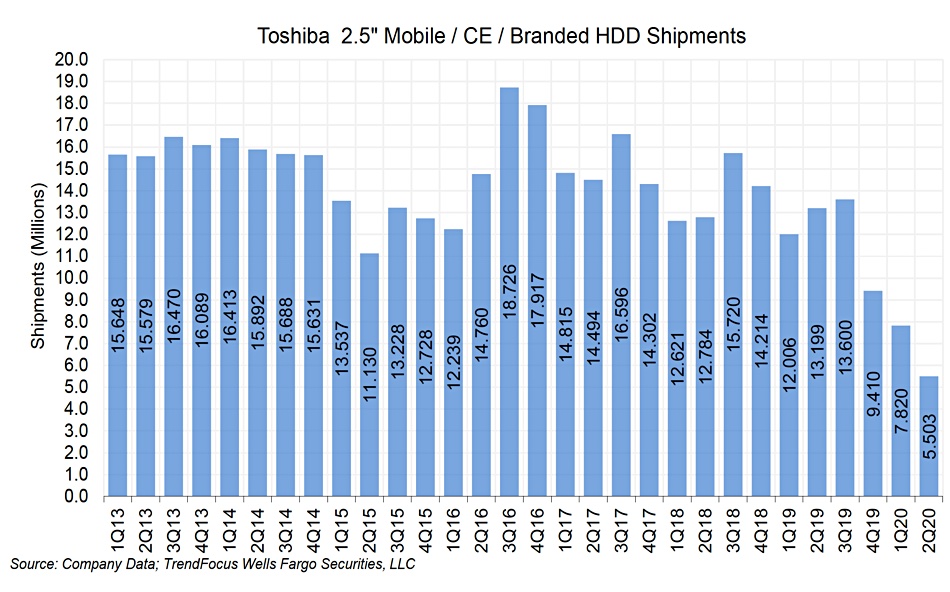
Toshiba’s Philippines plant produces nearline, 2.5-inch and 3.5-inch surveillance drives. Raker’s unit ship numbers for each in the quarter are:
Nearline – c941,000 – down 50 per cent y/y and down 32 per cent q/q
2.5-inch – c5.5 million – down 58 per cent y/y and down 30 per cent q/q
3.5-inch desktop – c1.82 million – down 35 per cent y/y and up 23 per cent q/q
Within the 3.5-inch desktop category Toshiba shipped 380,000 surveillance drives; down 71 per cent q/q from the prior 1.33 million drives with no y/y comparison.
Two of Rakers’ charts show these declines:
Toshiba’s shipments measured in exabytes reflect the same changes. For example, the company shipped c8.38 EB of nearline capacity, down from the c16.8 EB shipped in the first quarter. Seagate’s nearline capacity shipped in the second quarter was almost five times bigger at 79.5 EB.
Backblaze has launched an S3 compatible APIS for its B2 cloud storage, which it claims is 75 per cent cheaper than AWS. Not convinced? The company is offering to pay AWS S3 egress fees for customers that migrate more than 50TB of data and keep it in Backblaze’s B2 Cloud Storage for at least 12 months.
Backblaze added S3 API support in May this year and started a 90-day beta test in which, it says, thousands of customers migrated petabytes of data. During the trial, Backblaze recorded interactions with more than 1000 unique S3-compatible tools from multiple companies. The results show “customers can point their existing workflows and tools at Backblaze B2 and not miss a beat”.
Gavin Wade, CEO of CloudSpot, a Backblaze customer, provided a prepared quote: “With Backblaze, we have a system for scaling infinitely. It lowers our breakeven customer volume while increasing our margins, so we can reinvest back into the business. My investors are happy. I’m happy. It feels incredible.”
Backblaze storage pods; the red-coloured enclosures.
Cloudspot faced paying 9 cents/GB to move 700TB of data from AWS S3 to Backblaze. The company moved that data across in less than six days because AWS storage costs were eating into profits as business, and the amount of stored data, grew.
Backblaze’s B2 Cloud Storage is already popular, with the amount of data in its vaults growing at 25 per cent month on month. It costs $0.005/GB per month for data storage and $0.01/GB to download data. There are no costs to upload data.
A final thought. AWS, with its enormous scale must be making money hand over fist from S3, when Backblaze can offer this service at one quarter of the price. This shows the cloud giant has plenty of scope for cost-cutting. But in the meantime cloud storage backup suppliers such as Datto and OVHcloud may be encouraged to follow Backblaze’s suit.
Criminals need two things to make a ransomware attack work for them; a penetrated IT security system, and inadequate or non-existent backup and disaster recovery.
Sadly, this is an all too common state of affairs, as illustrated by Garmin, the latest high-profile victim of ransomware. At time of writing, the company is slowly restoring its GPS tracker and navigation services. But it is thought to have paid up to $10m to the ransomware attackers to gain access to the decryption key, according to The Times and other reports. The company will have also suffered substantial downtime costs and possibly a hit to its reputation. No-one should blame the victim of crime. But this is a hot mess.
Ransomware is a multi-billion dollar operation in 2020 and IT security vendors are engaged in an arms race with the perpetrators. However, no IT system is 100 per cent secure. This is which is why backup and DR are required as the last line of defence.
In the event of an attack, this line of data protection should not fail. Ransomware victims need readily available backup and disaster recovery files that are uncorrupted by malware. The recovery process should enable victims to quickly rebuild clean systems.
So when it comes to ransomware, backup and recovery is last but not least. Blocks & Files has polled a group of backup and recovery suppliers for their take on ransomware defences. Our contributors are Acronis, Cohesity, Databarracks, Datto, Druva, Rubrik, Unitrends, Veeam, Veritas and Zerto. Commvault, Iland, Pure Storage, Radware and TechData also contributed. We publish their replies below.
How does a supplier protect its customers against ransomware attacks?
Candid Wüest
Acronis Candid Wüest, VP Cyber Protection Research, said: “Relying on separate backup, vulnerability assessment, patch management, remote management, anti-virus, and anti-ransomware [heuristic] requires an MSP technician to learn and maintain all of those applications. Besides, … Acronis Cyber Protect combines all of these tools into one single product with one single agent, one single management console, and one single license.”
This sounds like an excellent idea.
Pascal Geenens.
Pascal Geenens, director of threat intelligence at Radware, tells us: “The most effective way to mitigate the impact of ransomware is offline backup systems, with emphasis on ‘offline’. Any online backup system is at risk of corruption or destruction by the ransomware, keeping backups offline and disconnected from the corporate network will ensure they stay tamper proof.”
He says: “Once the infection vector is identified, it is important to first close the security gap before recovering the systems. Missing this step leaves the door open to re-infection by the same or other ransomware.”
This is a good point to recognise.
Gijsbert Janssen van Doorn, Director of Technical Marketing, Zerto, told us: “The Zerto IT Resilience Platform uses Continuous Data Protection to keep data protected in real time. If – and when – a cyberattack makes it past your defences, your data can be recovered in seconds with just a few clicks.
“Zerto enables organizations to use network, journal, and IOPS statistics to determine the precise moment the ransomware became active and recover to the point within seconds before it happened. Zerto also allows you to quickly perform a failover test to see if you have the right point in time. If not, you can easily failover to a different point, and Zerto’s journal-based recovery lets you recover anything from just a few files to an entire application stack.”
Bob Petrocelli, Datto CTO, tells us: “Local backups are … traditionally the least secure. This is because they are only as strong as the home network, which is inherently vulnerable to attacks and disaster. The same event that may require a backup will likely impact any local protection.” If backups are local then use physically air-gapped ones as part of your ransomware DR strategy.
Ezat Dayeh, SE Manager, Cohesity UK, said: “Cohesity delivers a unique combination of an immutable file system with DataLock capabilities, plus policy-based air-gap and multi-factor authentication to prevent backup data from becoming part of a ransomware attack. Its CCyberScan gives deep visibility into the health and recoverability status of protected snapshots. CyberScan shows each snapshot’s vulnerability index and actionable recommendation to address any software vulnerabilities. This helps you to cleanly and predictably recover from a ransomware attack.
A Pure Storage FlashBade has has immutable snapshots of backup data and associated metadata catalogs created after full backup is performed. They provide a copy of data that a ransomware attacker cannot compromise, alter, or affect.
Rubrik’s Robert Rhame, Director of Market Intelligence, tells us: “Rubrik has an immutable file system and hardened native architecture that attackers can’t flatten. Determining the scope of the damage, point in time, and rebuilding the application dependency chains is automated by Rubrik Polaris Radar. This eliminates guess work during a very stressful event. Rubrik can also live mount for forensic analysis purposes, and then instantly recover workloads to get the organisation back in business.
Michael Cade, senior global technologist at Veeam, said: “There are five functions to help protect customer environments from ransomware, as modelled out by NIST (National Institute of Standards & Technology): identify, protect, detect, respond; and recover. Veeam is able to support each of these areas.”
Veeam stresses the need for immutable and air-gapped backups.
Cade said: ”Veeam has simple, flexible and reliable capabilities built into the recovery process that will securely recover data in the event of ransomware. With as little as checking a box, a service or application will be analysed prior to being brought online for any traces of malicious content. Additionally, there is a default capability to create a “sandbox” of a compromised system to better understand why a compromise occurred and to learn from an event to prevent a future cybersecurity incident.”
Doug Matthews, Veritas VP, Product Management said: “A major enemy of successful disaster recovery from large events is complexity. Veritas helps IT teams counter complexity by delivering a single platform that services all their disaster recovery requirements. Our platform delivers recovery technologies to meet every service level objective in the recovery spectrum via orchestrated, tested recovery for physical, virtual or cloud based workloads. In that regard, Veritas is ready to help by protecting data with a single solution for over 800 date sources, writing to over 1,400 storage targets either on-premises or across over 60 cloud providers.”
Yes, this is marketing but it also says Veritas takes an all-in-one approach (see Acronis above) and is ready for ransomware attack recovery action. Its systems are designed to enable fast recovery at enterprise scale, for any granularity (file, instance, application, data centre etc.) with an instant access capability.
Justin Augat, VP Product Marketing at iland, emphasises air-gapping: “All customers get iland Secure Cloud Backup as a Service to enable remote copies of all data (defeating ransomware leverage) and optional “Insider Protection” which is an air-gapped repository accessible only by iland. In the case the customer requires the solution of last resort, iland Secure Disaster Recovery as a Service is a ready, remote environment (protected by security/defence strategies).
Defeated ransomware attacks and lessons
Every supplier we talked to said some of their customers had defeated or recovered from ransomware attacks with their products.
“We cannot name individual customers, but we had many customers that were saved by the Acronis DR solution after a ransomware attack knocked them offline.”
Commvault said ransomware attackers struck the City of Sparks, Nevada. The infection locked police department shared files and left crucial GIS data – think fire and EMS dispatching – unavailable. The Sparks IT team completed data recovery in just 12 hours, not weeks, using Commvault data protection.“ Watch a video about the incident.
An un-named mid-western US City, which was a Datrium DVX customer, suffered a Ryuk ransomware attack in January 2020. An Azure shares was compromised and led to a startup script automatically executing, which began to encrypt all the system files. The entire city was shut down, and the Governor contemplated declaring a state of emergency. Datrium’s support team located a clean DVX snapshot before the attack, which created enlarged snapshots due to its encryption work. This became a golden master and the city’s VMS were restored one by one and verified from this copy. This work took two days and no ransom was paid.
This was an ad hoc recovery, made simpler because a single data centre and a single storage supplier with immutable snapshots were involved.
Rubrik customer the North Carolina City of Durham detected a ransomware attack on Friday, March 6, and recovered over the weekend. They were able to restore critical city services, including access to 911, from the Rubrik backups. Core business systems, including payroll, were back online by the start of the business week. The cleanup involved rebuilding 80 contaminated servers and re-imaging around 1,000 PCs and notebooks.
A second Rubrik customer, Kern Medical Center, discovered a ransomware attack in June 2019. Users reported they couldn’t access their systems. They were able to recover all of the impacted systems protected by Rubrik within minutes, including recovering their business-critical electronic medical record system. Other systems took up to 16 days to be recovered. The customer has now added Rubrik protection to some of its legacy IT systems.
Veeam’s Cade tells us: “A Canadian engineering firm had 100 per cent recovery from a ransomware attack thanks to Veeam and backup data stored in the cloud. Veeam has a dedicated Support SWAT team to handle any cyber security related incidents and assisting in getting customer data back up and running as soon as possible.
Zerto’s Van Doorn said: “TenCate, a multinational textiles company based in the Netherlands, has experienced ransomware twice. The first [CryptoLocker] attack occurred prior to implementing Zerto, and the second occurred after implementing Zerto.
“When the first attack hit, TenCate’s only recovery method was restoring to backup disks, which required a lengthy, multi-step data restore process. Using that method, TenCate experienced 12 hours of data loss and didn’t recover for two weeks.“
Zerto – First TenCate attack.
“After implementing Zerto, TenCate experienced a second ransomware attack, but this time Zerto’s journaling capabilities allowed the IT team to select a recovery checkpoint a few minutes prior to the ransomware attack. TenCate only experienced 10 seconds of data loss and was able to recover in under 10 minutes.” That’s what we call a decent ransomware attack recovery process.
Veritas’ West said: “We helped a large European energy company who were hit hard during the NotPetya incident. They had a diversified portfolio of solutions protecting their infrastructure at their headquarters but relied on NetBackup appliances as a key element of their data protection strategy.
“When they were attacked with NotPetya, they discovered that, not only was their primary data encrypted, the operating systems of the other backup tools, which were running on a Windows Server architecture, had been encrypted too. The hardened infrastructure of the Veritas appliances meant that this data, however, could be restored efficiently. And, since the customer had chosen to include their Windows Server data in their backup set, the other backup environments could be restored as well. As a result, none of the data in the Head Office estate was lost.”
This, the ransomware encryption of the operating systems of the other backup tools, was a gigantic fail of backup technology. Veritas said its backup appliances are protected (hardened) against malware and have intrusion detection.
According to West, organisations need offsite copies of all valuable data that are complete, current, air gapped and immutable.
Should customers regularly test DR readiness and ability to recover from ransomware attacks?
All the suppliers, without exception, said yes, customers should regularly, and even rigorously, check their ransomware attack recovery plans, with simulated attack recovery events and processes. The aim is to find missing process steps and unprotected devices and applications.
For example, Petrocelli said: ‘Scheduled and frequent testing – and allowing adequate time to resolve any problems that the tests might highlight – is the only way to guarantee that business operations can be restored quickly and smoothly in an emergency.”
The test should simulate a successful ransomware attack with a large and random group of compromised apps and systems; it has to be serious and realistic.
Veritas includes the capability to automate ransomware attack recovery rehearsals in its data protection platform to validate readiness to recover.
Tech Data’s Bart van Moorsel, Security Solutions Architect, EMEA, said: “You must test disaster recovery to make sure everything works. Disaster recovery is your card of last resort. It is a bit like having a life jacket or a fire extinguisher. You hope you never need it, but when you do, it is nearly always critical that it works as intended.”
Ian Schenkel, VP EMEA at FlashPoint, a threat intelligence platform, says: “When it comes to ransomware, the ideal state is to not only be ready to respond in emergency situations but already be prepared so that your team can act quickly. Things like ransomware workshops, tabletop exercises, stimulated scenarios, and engaging with an experienced partner who has dealt with various ransomware incidents are all things that can help prepare an organisation to swiftly mitigate risk associated with ransomware.”
Marc Laliberte, senior security analyst at WatchGuard Technologies, sings off the same hymn sheet: “At a minimum though, you should be testing your backup restoration process quarterly or, preferably monthly, to ensure your systems and procedures are all in working order.”
Does this require different test parameters and methods from a normal DR test?
Zerto’s van Doorn said: “The challenge with ransomware is that it requires both fast and granular recovery, not only from a recovery point perspective, but also from an object perspective, as ransomware can attack only certain components of the infrastructure.”
You should be able to “choose from many recovery points from seconds to days in the past and one that gives you the ability to test the recovery of any type of object (from a single file to an entire datacenter) without impacting the production systems is crucial. Having such a non-intrusive solution in place also allows for easy automation of these recovery tests which results in more frequent tests than just once or twice a year.”
Rubrik’s Rhame stressed a tabletop testing concept: “Most organisations have playbooks for many different Business Continuity Management (BCM) scenarios, but up until a few years ago few had updated them to take all the encrypted non-functioning pieces of a ransomware attack into account. This gap must be closed… Tabletop [DR] testing can expose gaps like lack of out of band communications, uncover insufficient recovery bench strength, and introduce all the organisational stakeholders before they meet during a crisis.”
Augat from iland says an untested ransomware DR plan will likely fail, and asks: “Does your backup solution use AI to automatically detect and alert you to ransomware early on so you can restore quickly? If not, you should look for a solution that can identify if ransomware resides in your backups and select the best backup to use for restores. Lastly, does your backup solution offer testing and verification? Recovery assurance will give you the flexibility to regularly perform testing and verification of your backups.”
Veaam’sCade reminds us: “Businesses have to be sure that when they are restoring from older backup sets, they have the capability of being able to scan the contents of those backup files with the latest virus definitions and ensure that you are not restoring compromised data into a live environment.”
Net: Net
Veritas’s West says: “Every business should assume that it will be the target of a ransomware attack and plan from there.”
Blocks & Files recommends every business to protect all its data with physically air-gapped, immutable backups. They require analysis facilities to detect clean backups before the attack and rehearsed playbook automation to recover systems.
Organisations with distributed data centres, hybrid cloud operations, and multiple storage and data protection suppliers should realise that they have the most difficult ransomware attack recovery procedure of all. So, they must pay particular and regular attention to rehearsing attacks and attack recovery.
If your executives don’t believe this is necessary, just show them what happened to Garmin.
This week the International Space Station’s NAS gives vent, Nebulon pumps out a survey, Pliops talks about its storage processor, we see how Pivot3’s video HCI is getting better system management, and take a look at Veeam’s quarterly boast.
ISS payload NAS
The International Space Station summary report for July 27 includes this gem; “Payloads Network Attached Storage (NAS) Cleaning:The crew cleaned inlet/outlet vents of the NAS to prevent the NAS from automatically powering off due to inadequate processor or Hard Drive cooling that can be caused by blocked vents.“ Memo to self: we should all clean our vents.
NASA International Space Station
Nebulon survey
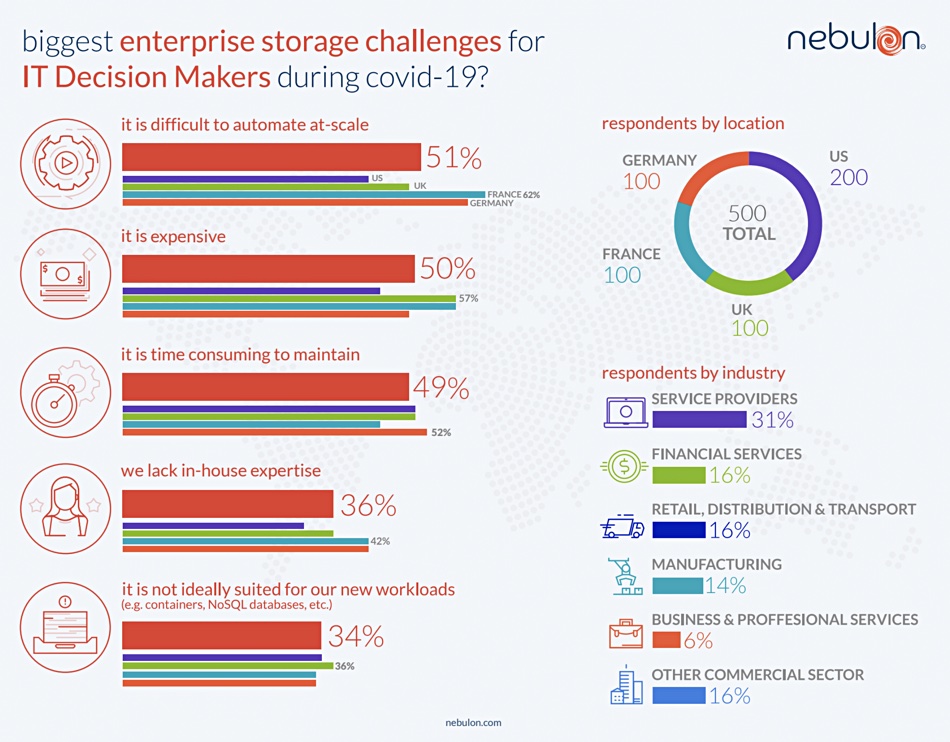
Nebulon has commissioned an independent survey that exposes the biggest challenges that enterprises face in transforming their on-premises application storage environments.
Nebulon survey info chart.
Siamak Nazari, co-founder and CEO of Nebulon, issued a canned quote: “The impact of the pandemic is forcing CIOs worldwide to reconsider their operations. Reducing costs through server-based storage alternatives without the restrictions of hyperconverged infrastructure, and reducing operating cost pressure through cloud-based management of the application storage infrastructure are crucial initiatives for IT organisations looking to survive this new normal.”
The survey was completed by IT decision makers at 500 companies in the IT, financial services, manufacturing, retail, distribution and transport industries across the UK, US, Germany and France. This seems like a supplier polling potential customers and finding out, and telling them, they need its product.
Nebulon makes an on-premises, server SAN, bolstered with storage processing offload cards, which is managed through a cloud service.
‘More than 10″ tier-one cloud and enterprise companies, including the database supplier Percona, have tested and evaluated the GPU-like, PCIe card storage processor device from Pliops.
Pliops Storage Processor
The startup says the devices boost performance by more than 10x, reduces five 9s latency by up to 1000x, and increase flash price performance by more than 90 per cent. These results were indicated for almost all workloads using flash. Pliops is planning general availability of its Storage Processor later this year.
Steve Fingerhut, president and chief business officer, issued a canned quote: “The Pliops approach accelerates compute-intensive functions and eliminates bottlenecks – solving the dilemma of choosing cost at the expense of performance – and vice versa.”
Shorter items
Veeam doesn’t talk revenue figures, preferring instead to talk percentage growth in regular press releases. The latest this week announced annual recurring revenue (ARR) increase of 20 per cent year-over-year for Q2’20 – the biggest second quarter in the company’s 14-year history. Veaam reported its biggest quarter for total bookings of its fastest growing product, Veeam Backup for Microsoft Office 365, with an 89 per cent YoY increase and a 75 per cent YoY gain in overall subscription bookings.
AWS has announced new EC2 Instances based on Graviton2 processors with local NVMe-based SSDs. The “d” variant of the three instance types— M6gd, C6gd, and R6g – have up to 2 x 1.9 TB NVMe SSDs. They offer 50 per cent more storage GB/vCPU compared to M5d, C5d, and R5d instances and are designed for apps needing high-speed, low latency local storage, such as scratch space, temporary files, and caches. Details can be found on the AWS News Blog and What’s New at AWS posts.
A Minioblog says: “the ARM architecture, with the introduction of the Graviton2 processor by AWS, has closed the performance gap to Intel and even surpassed it for multi-core performance.” There are AWS Graviton performance testing details in the blog.
TechRadar is teasing a feature about a potential 1PB SSD from Nimbus Data, possibly using compression to ramp its 400TB raw capacity up to 1PB “usable” with availability in 2023.
HCI supplier Pivot3 has added intelligent system health and best practices analysis features to its Acuity software.
SANBlaze announced its SBExpress v 8.1 software release to provides NVMe SSD manufacturers the ability to test native NVMe PCIe devices as well as NVMe-oF (NVMe over Fabrics) devices. V8.1 builds on the Industry Standard SBCert (Certified by SANBlaze) NVMe qualification platform adding advanced automated testing features. The SW works in conjunction with the SANBlaze SBExpress-RM4 PCIe NVMe Gen4 test system hardware to test PCIe Gen4 NVMe devices.
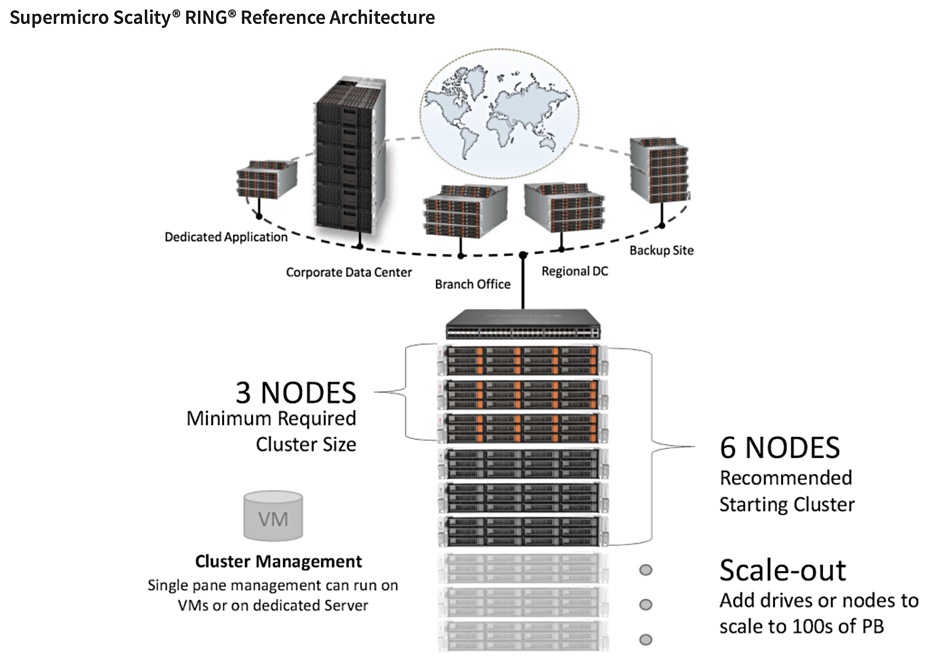
Supermicro and Scality are selling Scality RING object storage on Supermicro server and storage hardware with a reference architecture design. It comes in performance-optimised and capacity-optimised versions. The two say they deliver a petabyte-scale storage framework offering cost-effective scaling, performance, and resiliency paired with Supermicro’s predefined hardware configurations that offer users an appliance-like deployment and service levels to meet enterprise requirements. You can download basic datasheet-type details.
Supermicro has unveiled a new generation of its top-loading storage systems (60-bay and 90-bay), which are optimised for enterprise environments. They support scale-up and scale-out architectures and are available in single-node and dual-node configurations, with the drives evenly split between each node.
The NAND market is weakening, according to TrendFocus. The market research firm says demand from the retail end has been recovering in June and July, but demand for PC and server SSDs has softened. as a result of decelerating demand for cloud and remote access services. A.
TrendForce forecasts the quarterly decline in NAND flash ASPs will likely reach 10 per cent under the impact of the pandemic, due to excess inventory. This is despite the traditional peak season for electronics sales and the release of Apple’s new iPhones in 3Q20. TrendForce forecasts the oversupply in the NAND Flash market will intensify in 4Q20, further exacerbating the decline in NAND Flash ASP. YMTC’s capacity expansion this year is expected to continue in 2021.
Verbatim has announced the Store’n’Go ALU Slim – a compact, lightweight portable hard drive in a metal enclosure with USB 3.2 Gen 1 connection for data transfer speeds of up to 5Gbit/s. It has 1TB and 2TB capacities, weighs 150g, is 0.9cm thick, and includes a Micro-B to USB-A cable and a USB-A to USB-C adapter. The drive is FAT32 formatted. For content with files sizes larger than 4GB, software is supplied on the drive to reformat to HFS+ for Macs and NTFS for PCs. Suggested retail price is £62.99 for 1TB and £82.99 for 2TB.
HCI is a fairly mature market and we think it should be simple enough for tech analysts to agree on what vendors to classify as HCI vendors. Not so fast.
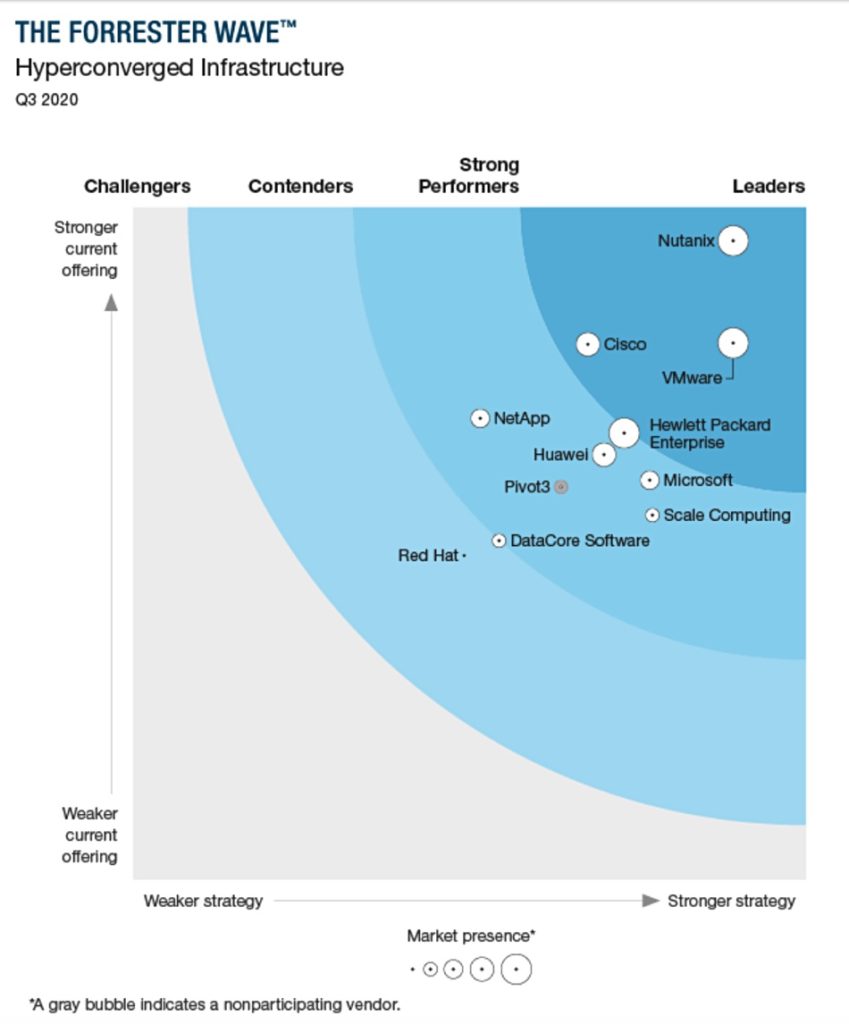
Forrester has published a Wave report looking at hyperconverged infrastructure (HCI) systems, with Nutanix top of the HCI pops, VMware second and Cisco in third place. However, it disagrees with Gartner and Omdia on who the HCI suppliers are.
Forrester defines HCI vendors as Challengers, Contenders, Strong Performers, and Leaders. Here is its HCI Wave chart, in which the size of vendor circle represents market presence.
Nutanix, VMware and Cisco occupy the Leader’s quadrant. HPE leads the Strong Performer groups, with Huawei next, followed by Microsoft (Azure Stack), Scale Computing, and Pivot 3.
DataCore is a Contender, close to the boundary with Strong Performers, followed by Red Hat.
Analyst HCI confusion
There are big differences between the Forrester HCI and the recent Omdia Decision Matrix for HCI. Omdia left out Nutanix and Huawei, which were asked to – but didn’t – contribute data, and Microsoft. Omdia includes Fujitsu, Hitachi Vantara, and Lenovo.
Gartner’s HCI Magic Quadrant is at odds with both Forester and Omdia. The analyst firm omits NetApp, while including Huayun Data Corp, Sangfor Technologies, StarWind and StorMagic as ‘Niche Players’ (which is the Forrester equivalent of ‘Challengers’).
A blast from the recent past
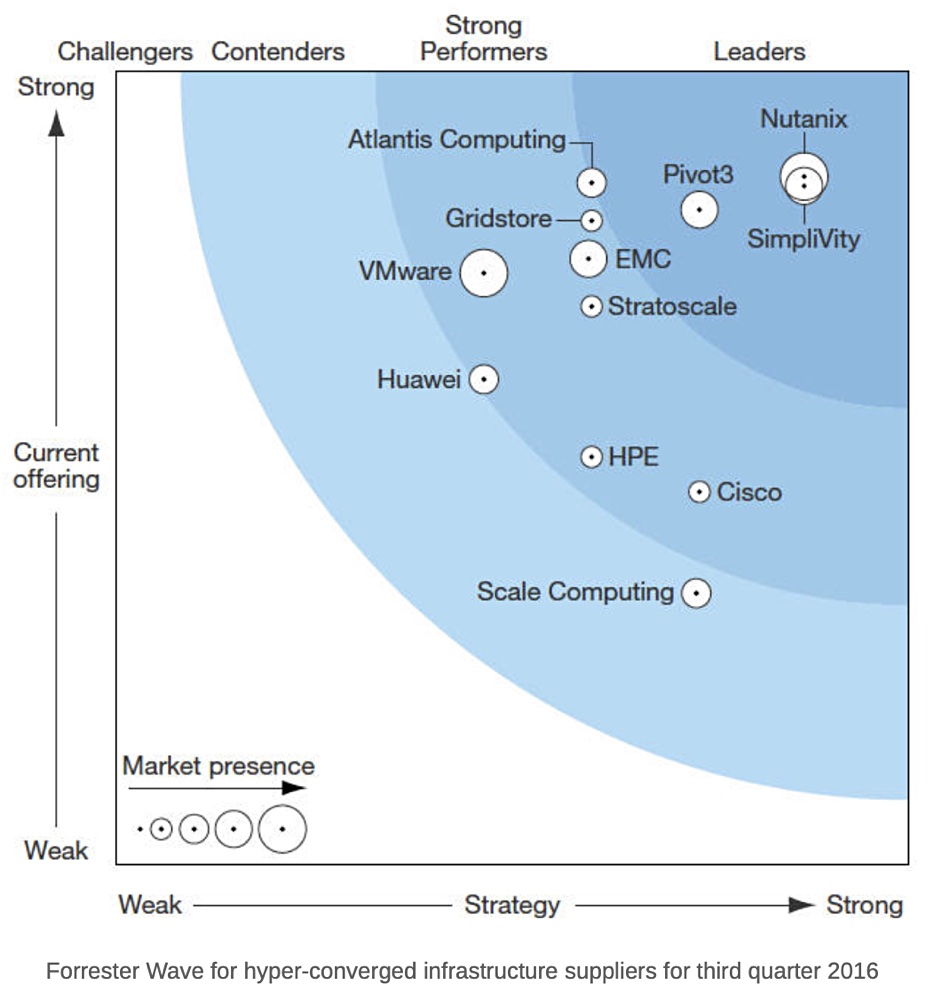
We have unearthed a 2016 Forrester HCI Wave for IT history buffs.
It shows EMC and VMware separately, and also SimpliVity and HPE as separate vendors. Atlantis Computing, GridStore and Stratoscale have exited the market since then and NetApp had no HCI presence in 2016.
SimpliVity was almost up with Nutanix but now, in the arms of HPE, has fallen back. The EMC-VMware-Dell combo has progressed to second place, with Cisco rising to third. Buying Springpath was a good move for the networking giant.
In addition, we emailed the company some questions about its storage strategy and here are the answers provided by Tom Black’s staff. The Q&A is lightly edited for brevity and is also available as a PDF. (The document also contain’s HPE’s summary of its storage product line-up, which comrpises the Intelligent Data Platform, InfoSight, Primera, Nimble Storage, XP, MSA SAN Storage, Nimble Storage hHCI, SimpliVity, Cloud Volumes and Apollo 4000.)
Blocks & Files: Does Tom Black look after HPC storage? I’m thinking of the ClusterStor arrays and DataWarp Accelerator that were acquired when HPE bought Cray. If not will there be separate development or some sort of cross-pollination?
HPE: No, HPC and HPC storage are part of an integrated group in a separate business unit. HPC is run as a segment with integrated R&D and GTM.
Blocks & Files:IBM and Dell are converging their mid-range storage products. Does HPE think such convergence is needed by its customers and why or why not? Will we see, for example, a converged Primera/3PAR offering and even a converged Primera/3PAR/ Nimble offering?
HPE: We believe that businesses need workload-optimized systems to support mid-range and high-end requirements. Systems that are designed to deliver the right performance, resiliency, efficiency, and scale for the SLA and use case.
HPE Primera.
With the introduction of HPE Primera last year, HPE consolidated its primary storage portfolio with one lead-with mid-range storage platform – HPE Nimble Storage, and one lead-with high-end storage platform – HPE Primera. Our HPE 3PAR installed base has a seamless upgrade path to HPE Nimble Storage and HPE Primera. (Comment: We didn’t know that 3PAR arrays could be upgraded to Nimble arrays.)
Blocks & Files:Will the XP systems remain a key aspect of HPE’s storage portfolio and, if so, how are they distinguished from the Primera line?
HPE: Yes, HPE XP Storage is a key aspect of HPE’s storage portfolio. It is our high-end platform for mission-critical workloads with extreme scale requirements, traditional use cases like Mainframe, NonStop, OPVMS and Cobol-based environments, and XP install base customers. HPE Primera is our lead-with high-end platform for mission-critical applications to support virtualized, bare metal, and containerized applications.
Blocks & Files: I believe HPE is the only supplier with both HCI and dHCI systems in its range. How does HP position its SAN storage, its HCI systems and its dHCI systems?
HPE: In the last several years, HCI has offered small and medium businesses a new value proposition, delivering infrastructure simplicity with VM-centric operations and automation – and therefore HCI (and HPE SimpliVity) is performing very well in that segment.
We’re hearing from our enterprise and mid-market customers that they want the simplicity of HCI but are unable to adopt it as they’re giving up too much to gain the agility and simplicity. This is where we position HPE Nimble Storage dHCI – a disaggregated HCI platform that uniquely delivers the HCI experience but with better performance, availability, and scaling flexibility than HCI for business-critical applications and mixed-workloads at scale.
Nimble dHCI.
In addition, in the enterprise core data center and service provider market, organizations here have the largest scale requirements and strictest SLA for performance and availability for their mission-critical applications. The right solution for them is high-end storage/SAN, so we position HPE Primera with HPE Synergy here as the core consolidation platform for mixed-workloads at scale.
Blocks & Files: What is the role of storage in HPE’s composable systems? Will all the SAN, HCI and dHCI systems evolve towards composability?
HPE: HPE has been a pioneer in delivering composability. Companies once forced into overprovisioning infrastructure are now able to create fluid pools of compute, storage, and network resources. Composability is designed for any application, at any SLA, and at any scale because all it takes is a single line of code to gather and deploy the IT assets needed to run any application, anywhere, at any scale.
From a storage perspective, our focus is to continue to deliver infrastructure that is fully automated, optimized and integrated with intelligence and composability. We drive a cloud experience on-premises with a strong foundation of composability on intelligent infrastructure for any workload. Bringing together the intelligence from an intelligent data platform with the composability of HPE Synergy, IT organizations have the absolute flexibility to support any application with the agility of the cloud in their on-premises data center—delivered as a service to scale to meet ever-changing business needs.
We fundamentally believe in flexibility and the need for workload-optimized systems designed for the use case. Composability – with the ability to support any applications across bare metal, virtualization, and containers – makes the most sense in large scale, enterprise core data center environments. For organizations who don’t need this level of resource composition and flexibility, and perhaps are exclusively needing to support virtual machines, HCI – with a software-defined framework specifically for virtual machines – will make the most sense for them.
Blocks & Files: HPE is not perceived as a mainstream supplier of its own file storage technology. It partners widely with suppliers such as Qumulo, WekaIO and others. Long term should HPE have its own file storage technology or continue to set as a reseller/system integrator of other supplier’s technology?
HPE: With unstructured data, use cases are continuing to evolve. Here’s the breakdown of our view of use cases and how we address them with our owned IP and partner solutions:
AI/ML – HPE Ezmeral Container Platform, which is inclusive of HPE Ezmeral Data Fabric (MapR), enables data scientists and data analysts to build and deploy AI/ML pipelines to unlock insights with data.
Distributed, scale-out enterprise-wide data fabric for edge to cloud – HPE Ezmeral Data Fabric (MapR) is a leading scale-out filesystem with enterprise reliability and data services, and one of the only file systems that offers batch processing, file processing, and streams processing.
Analytics, Medical Imaging, Video Surveillance, etc – HPE Apollo 4000 in partnership with scale-out software partners such as Qumulo (file) and Scality (object) provides a great foundation for these use cases.
HPC – We have market-leading HPC solutions (i.e. ClusterStor) from our acquisition of Cray
Like any market, we will continue to monitor the evolution of customer use cases and ensure we can help them address the use cases with differentiated solutions.
Blocks & Files:HPE is not perceived as a mainstream supplier of its own object storage technology. It partners with suppliers such as Cloudian and Scality. Long term should HPE have its own object storage technology or continue to set as a reseller/system integrator of these other supplier’s technology?
HPE: HPE will continue to monitor the market for object storage. Scality is the strategic HPE partner for massively scalable multi-cloud unstructured data stores – including S3 compatible object storage. The HPE partnership with Scality is global and backed by joint go-to-market. This is all in addition to a global reseller agreement through which HPE offers Scality on our mainstream HPE price list.
With unstructured data, use cases are continuing to evolve. Here’s the breakdown of our view of use cases and how we address them with our owned IP and partner solutions:
AI/ML – HPE Ezmeral Container Platform, which is inclusive of HPE Ezmeral Data Fabric (MapR), enables data scientists and data analysts to build and deploy AI/ML pipelines to unlock insights with data.
Analytics, Medical Imaging, Video Surveillance, etc – HPE Apollo 4000 in partnership with scale-out software partners such as Qumulo (file) and Scality (object) provides a great foundation for these use cases.
HPC – We have market-leading HPC solutions (i.e. ClusterStor) from our acquisition of Cray
Like any market, we will continue to monitor the evolution of customer use cases and ensure we can help them address the use cases with differentiated solutions.
Blocks & Files:How will HPE evolve its storage offer at Internet Edge sites with a need, perhaps, for local data analytics?
HPE: Enterprise edge, as we refer to the edge, is becoming more and more strategic for customers and an opportunity for infrastructure modernization. It can be a small site in a hospital or oil rig, or a distributed enterprise with remote offices/branch offices e.g. for banks or retail. Key characteristic is often no on-site resident IT staff and therefore the ability to remotely deploy, manage, operate, upgrade is really important.
We are seeing a growing market opportunity to leverage HCI at the enterprise edge. The simplified experience of a hyperconverged appliance addresses edge-specific requirements, including the need to power edge applications in a highly available, small footprint, protect data across sites, and facilitate entire lifecycle management remotely without local IT presence. HPE SimpliVity is our strategic platform to address this need with customers with numerous use cases and wins.
We also provide our customers the end-to-end lifecycle with HPE Aruba and our HPE EdgeLine servers to service all customer needs at the edge.
Blocks & Files: How is HPE building a hybrid cloud storage portfolio with data movement between and across the on-premises and public cloud environments?
HPE’s approach hinges on providing a true, distributed cloud model and cloud experience for all apps and data, no matter where they exist – at the edge, in a colocation, in the public cloud, and in the data center. Our approach helps customers modernize and transform their applications and unlock value across all stages of their lifecycle where it makes the most sense.
Our hybrid cloud storage portfolio: 1) on-premises private cloud, 2) enterprise data services across both on-premises private cloud and public cloud, and 3) seamless data mobility between on-premises private cloud and public cloud.
HPE delivers a seamless experience by extending our storage platforms to the public cloud with HPE Cloud Volumes. HPE Cloud Volumes is a suite of enterprise cloud data services that enables customers, in minutes, to provision storage on-demand and bridges the divide and breaks down the silos that exist between on-premises and public cloud.
Unlike other cloud approaches, we’re uniquely bringing customers a fresh approach to backup, with the ability to put backup data to work in any cloud with no lock-ins or egress charges when recovering that backup data from HPE Cloud Volumes Backup.
Blocks & Files: How does HPE see the market need for SCM, NVMe-oF, and Kubernetes and container storage developing. Will these three technologies become table stakes for each product in its storage portfolio?
HPE – SCM
HPE 3PAR Storage pioneered the use of SCM, showcasing its performance benefits as early as 2016. Next, in 2019, we were the first vendor to introduce SCM as a caching tier on the 3PAR high-end platforms for extreme low latency requirements.
While other storage vendors have since caught up, SCM remains a niche use case because it is cost prohibitive to deploy as a persistent storage tier.
Our focus has been to democratize SCM and delivering it more widely through broader use cases. This is why this past June we introduced SCM for HPE Nimble Storage to deliver SCM-like performance for read-heavy workloads with 2X faster response times with an average of sub 250 microseconds latency at near the price of an all-flash array (~10-15% price premium depending on the HPE Nimble Storage all-flash array model).
Over time, we believe SCM will do the job of what SSD did 10 years ago, by providing a latency differentiation performance tier within AFAs.
HPE -NVMe-oF
We believe this is the next disruption in the datacenter fabrics. As with all fabric changes, this transition will happen gradually. It will take time for host ecosystems readiness, as well as customers’ willingness to make substantial changes in their fabric infrastructure.
We are at the early stages of host ecosystem readiness. For example, Linux distributions are ready. VMware 7.0 has brought some level of fabric support (with the next release scheduled to go further).
For us, we know this disruption is coming, and are working hard with our partners to develop an end to end NVMeoF solution. We are committed to being ready once the market (partners and customers) is as well.
HPE – Kubernetes and Container Storage
As customers continue to modernize their apps, they need to modernize the underlying infrastructure and we see a clear shift toward container based applications. Kubernetes is the defacto open source standard.
HPE CSI Driver for Kubernetes for HPE Primera and HPE Nimble Storage enables persistent storage tier for stateful container-based apps, and for deploying VMs and containers on shared storage infrastructure. HPE CSI Driver for Kubernetes includes automated provisioning and snapshot management. Over time, we will extend CSI (which is an open specification) to deliver additional value-added capabilities for customers.
In addition to HPE Storage platforms for container support, HPE offers its Ezmeral Container Platform, to help customers modernise and deploy non-cloud native and cloud native applications. (See answers above.)
IBM Research and Radian Memory Systems have found SSD zoning can deliver three times more throughput, 65 per cent more transactions per second and greatly extend an SSD’s working life.
SSD zoning involves setting up areas or zones on an SSD and using them for specific types of IO workloads, such as read-intensive, write-intensive and mixed read/write IO. The aim is to better manage an SSD’s array of cells in order to optimise throughput and endurance. A host to which the SSD is attached manages the operation of the zones and relieves the SSD’s Flash Translation Layer (FTL) software of that task.
For its benchmarks, IBM Research used SALSA (SoftwAre Log Structured Array), a host-resident translation layer, to present the SSD storage to applications on the server as a Linux block device. Radian supplies SSD management software to suppliers and OEMs. The test SSD was an RMS-350, a commercially available U.2 NVMe SSD with Radian Memory Systems’ zoned namespace capability and configurable zones.
SALSA controls data placement while the SSD abstracts lower level media management, including geometry and vendor-specific NAND attributes. SALSA also controls garbage collection, including selecting which zones to reclaim and where to relocate valid data, while the SSD carries out other NAND management processes such as wear-levelling in zones.
By residing on the host instead of the device, SALSA enables a global translation layer that can span multiple devices and optimise across them. The FTL of an individual SSD does not have this capability.
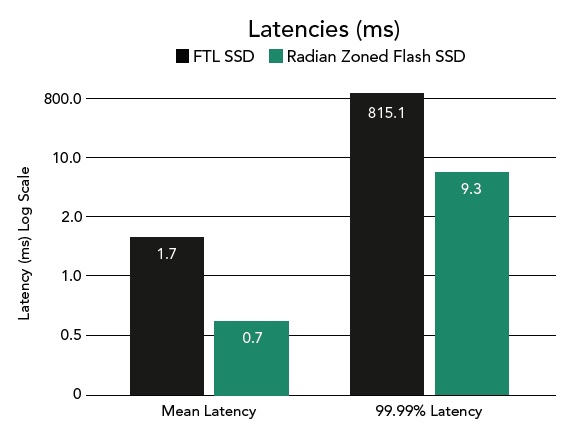
IBM and Radian ran fio block-level benchmarks and recorded throughput rising to 301MB/sec from 127MB/sec compared to the same SSD relying solely on its own FTL with no SALSA software. There was a 50-fold improvement in tail latencies (latencies outside 99.99 per cent of IOs) and an estimated 3xvimprovement in flash wear.
A MySQL/SysBench system-level benchmark showed 65 per cent improvement in transactions per sec, 22x improvement in tail latencies and, again, an estimated 3x Flash wear-out improvement.
This is just one demonstration and used a single SSD. A problem with host-managed zoned SSDs is that software on the host has to manage them. This software is not included in server operating systems, and so application code needs modifying to realise the benefits of the zoned SSD. Without a standard and widespread zoned SSD specification, there is no incentive for application suppliers to add zoned SSD management code to their applications.
IBM’s SALSA interposes a zoned SSD abstracting management layer between the zoned SSDs and applications that use them. That means little or no application code has to be changed. You can read the IBM/Radian case study to find out more.
Ideally, SALSA or equivalent functionality should be open-sourced and added to Linux. This would make it easier for applications to use zoned SSDs. A 3x improvement in throughput and wear, together with tail latency and transactions/sec improvements are worthwhile gains. But without easy implementation, the technology will remain niche.