How much life there is left in your storage? ProphetStor can tell you that. Also, academic researchers working on AI can avoid costly hardware purchases by using OpenExpress from a Korean university.
OpenExpress for NVMe
The Korea Advanced Institute of Science and Technology (KAIST) has developed Open Express, an easy-to-access open NVMe controller hardware IP modules and firmware for future fast storage class memory research. Associate Professor Dr. Myoungsoo Jung from the Computer Architecture and Memory systems Laboratory (CAMELab), tells us: “OpenExpress fully automates NVMe data processing as hardware, which is a word-first open hardware NVMe controller to the best of my knowledge.”
Jung said: “The cost of third party’s IP cores (maybe similar to OpenExpress) is around $100K (USD) per single-use source code, but OpenExpress is free to download for academic research purposes. Our real storage card prototype using OpenExpress exhibits the world’s fastest performance without a silicon fabrication (better than an Intel Optane SSD).”
All the OpenExpress sources are ready to share online.
Artificially intelligent ProphetStor
ProphetStor’s Federator.ai 4.2 predicts how long a storage system will last before it fails and the software can help schedule workloads away from storage nodes that are predicted to fail. Federator.ai works continuously on collected operation data, including the health of the disks and storage systems and application workloads. Data collected includes metrics from application logs, virtualization platforms, cloud service providers, and infrastructure.
Acronis has added Sale Sharks, the English Premiership Rugby team, to its roster of sports sponsorships. Acronis will provides Sale Sharks with backup and security software and will help the team to analyse on-pitch performance data.
Caringo has announced Swarm Cloud, a disaster recovery managed service powered by Wasabi Hot Cloud Storage. Users can instantly add a remote DR site at a Wasabi facility.
The DDR5 memory spec supports memory DIMMs of up to 2TB capacity through the maximum die capacity rising to 64Gbits, 4x higher than DDR4’s 16Gbits, and stacking of 8 dies on a memory chip. The standard DDR5 data rate is 6.4Gbit/sec, which is double DDR4’s 3.2Gbit/sec maximum speed. DDR5 will offer 2 x 32-bit data channels per DIMM with pairs of DIMMs mandatory.
FileCloud’s latest version of its enterprise file sharing and sync platform has an improved notification system with more granular controls. The release adds Automatic Team Folder Permission Updates, ServerLink Enhancements, SMS Integration & Gateways and integration with Multiple Identity Providers (IdP) plus more than 500 minor product improvement fixes.
Fujitsu is the the first vendor to offer Nutanix hyperconverged infrastructure software with certified application performance for analytics and general purpose workloads on Intel-based servers. The Intel certification applies to Fujitsu’s PRIMEFLEX for Nutanix Enterprise Cloud.
NAND bit-growth and higher average selling prices helped Intel Non-Volatile Solutions Group (NAND Flash and Optane) boost revenue 76 per cent higher year over year to $1.66bn in Q2 2020 .
Kingston Digital Europe has added 128GB capacity options to three encrypted USB flash drives: DataTraveler Locker+ G3,, DataTraveler Vault Privacy 3.0 and DataTraveler 4000G2.
Kioxia said its lineup of NVMe, SAS and SATA SSDs have successfully tested for compatibility and interoperability with Broadcom’s 9400 series of host bus adapters (HBAs) and MegaRAID adapters.
Fast object storage software supplier MinIO has gained Veeam Ready qualification for Object and Object with Immutability. This provides customers with an end-to-end, software-defined, solution for deploying MinIO as a backup, archive, and disaster recovery storage target for Veeam.
Nakivo v10 is out. Updates include backup and replication to Wasabi, vSphere 7 Support, full physical to virtual recovery and Linux Workstation backup.
Quantum has added multi-factor authentication software to the Scalar i3 and i6 tape libraries, in order to help secure off-line data against ransomware attacks.
Sixty-eight per cent of available enterprise data is unused, according to an IDC survey of 1500 execs, commissioned by Seagate The disk drive vendor has published the findings in a report: Rethink Data: Put More of Your Data to Work—From Edge to Cloud.
StorMagic has announced encryption Key Management as a Service (KMaaS), its first cloud service.
Yellowbrick Data has teamed up with Nexia, a SaaS data operations platform that helps teams collaborate by creating scalable, repeatable, and predictable data flows for any data use case. Nexia SaaS can deliver data from internal systems, ecosystem partners, and SaaS services into the Yellowbrick data warehouse.
Avinash Lakshman and Ediz Ertekin (credit:Ertekin)
Sponsored During his time working at Amazon and then Facebook, Avinash Lakshman played a starring role in taming the complex and voracious data management needs of these hyperscale cloud giants.
At Amazon, where he worked between 2004 and 2007, Lakshman co-invented Dynamo, a key-value storage system designed to deliver a reliable, ‘always-on’ experience for customers at massive scale. At Facebook (from 2007 to 2011), he developed Cassandra, to power high-performance search across messages sent by the social media platform’s millions of users worldwide.
The ideas he developed along the way around scalability, performance and resilience fed directly into his own start-up, Hedvig, which he founded in 2012 – but this time, Lakshman applied them instead to the data storage layer.
By the time Hedvig was acquired by Commvault for $225 million in October 2019, it had attracted some $52 million in venture capital funding and a stellar line-up of corporate customers including Scania, Pitt State and LKAB. As Commvault CEO Sanjay Mirchandani said on completing the deal: “Hedvig’s technology is in its prime. It has been market tested and proven.”
Tackling fragmentation
Avinash Lakshman and Ediz Ertekin
What sets Hedvig apart is its unique approach to software-defined storage (SDS), which helps companies to better manage data that is becoming increasingly fragmented across multiple siloes, held in public and private clouds and in on-premise data centres, says Ediz Ertekin, previously Hedvig’s senior vice president of worldwide sales and now vice president of global sales for emerging technologies at Commvault.
“What companies are looking for in this multi-cloud world is a unified experience of managing data storage that simplifies what is fundamentally very complex, and becoming more complex with every day that passes,” he says.
The premise for SDS is pretty straightforward: by abstracting, or decoupling, software from the underlying hardware used to store their data, organisations can unify storage management and services across the diverse assets contained in their hybrid IT environments.
It’s an idea many IT decision-makers find attractive, because it gives mainstream corporate IT access to the kind of automated, agile and cost-effective storage approaches that power hyperscale pioneers like Amazon, Facebook and Google.
According to estimates from IT market research company Gartner, around 50 per cent of global storage capacity will be deployed as SDS by 2024. That’s up from around 15 per cent in mid-2019.
As Ertekin explains, the Hedvig Distributed Storage Platform transforms commodity x86 or ARM servers into a storage cluster that can scale from just a few nodes to thousands of nodes, covering both primary and secondary storage. Its patented Universal Data Plane architecture, meanwhile, is capable of storing, protecting and replicating block, file and object data across any number of private and/or public cloud data centres. In short, Hedvig’s technology enables customers to consolidate their storage workloads and manage them as a single solution, using low-cost, industry-standard hardware.
An urgent requirement
At many organisations, a new approach isn’t just attractive, it’s an urgent requirement, says Ertekin. That’s because IT leaders are quickly discovering that established storage management approaches simply don’t sit well with the multi-cloud and modern application strategies that their organisations are adopting in order to fulfill their digital transformation ambitions.
Hybrid and multi-cloud deployments are increasing rapidly, Ertekin points out. And while the cloud-native and containerised applications that frequently underpin new, business-critical digital services may speed up innovation by supporting faster, more agile DevOps approaches, they also add to storage complexity.
“These trends are leading to more fragmentation, and with more fragmentation comes less visibility and more friction,” he says. “Traditional storage management simply can’t keep pace with new requirements.”
It leaves IT teams having to manage a vast range of disparate storage assets, unable to ‘talk’ to each other because they’re not interoperable, he says. They’re also wrestling with multiple management tools to oversee that patchwork of storage systems. On top of that, older ways of working make it extremely difficult to migrate data back and forth between on-premise systems and cloud environments, and between different public clouds. “There’s a distinct lack of portability that IT teams know they must address, but if they can’t see what data resides where, that’s going to be a big struggle,” he says.
By contrast, SDS provides companies with a virtual delivery model for storage that is hardware-agnostic and provides greater automation and more flexible provisioning. As Ertekin explains it, application programming interfaces (APIs) enable Hedvig’s Distributed Storage Platform to connect to any operating system, hypervisor, container or cloud, enabling faster, more proactive orchestration by IT admins and automating many tasks, such as provisioning, that they may have previously needed to carry out manually.
“In this way, organisations using Hedvig don’t just experience the simplification that they need, but also better resource optimisation and substantial cost reductions, too,” he says.
All this has important implications for resilience, Ertekin adds: “When you have that visibility into where data is stored and the ability to move it around as necessary, you’re better equipped to deal with the potential impact of downtime.”
“Our customers can define their data protection policies to deal with everything from a single node failure to downtime across an entire site,” he continues. “For example, in the case of a production workload, where business continuity is critical, you might decide to keep multiple copies of the data, written across multiple nodes, multiple sites or multiple geographies, so it’s never necessary to physically move data if you run into problems.”
Future challenges
At a time when it’s never felt more difficult for IT decision-makers to understand what the future might hold, a big selling point for SDS is the predictability it can bring, according to Ertekin. “With SDS, there’s more flexibility and agility to adapt to changing business and IT requirements with confidence and without having to worry about the implications for performance, scale and cost,” he says.
For a start, the issue of remote working is currently high on CIO agendas, driven by Covid-related stay-at-home orders. SDS can provide the portability to ensure that data remains accessible to employees who need it and can easily be moved or replicated to where it is needed most, while still applying strict policies to it, in order to ensure compliance with corporate governance guidelines, not to mention wider legal and regulatory obligations.
On the cost front, says Ertekin, abstracting storage management from the hardware layer using software relieves organisations of many of the time and cost burdens associated with regular infrastructure refreshes. SDS enables them to rely on commodity hardware, rather than proprietary storage appliances, and to pick and choose between public cloud providers based on pricing. It offers a scale-out solution that allows them to take a more ‘pay as you go’ approach, where matching capacity to performance and costs needs becomes easier to estimate ahead of time.
Some developments, of course, are easier to predict. The burgeoning multi-cloud and containerisation trends show no signs of slowing as companies scramble to deliver new and compelling digital experiences to their customers. In fact, more than four out of five enterprises (81%) are already working with two or more public cloud providers, according to a 2019 Gartner survey, while another study from the firm suggests that three-quarters of global enterprises will be running containerised applications in production by 2022.
As companies increasingly rely on different application delivery models, their storage capabilities will need to be just as diverse, says Ertekin. For example, there will more frequently be a need to add persistent volumes to container environments. SDS delivers the integration with container orchestrators (COs) such as Kubernetes and Docker, for example, to quickly provision the storage that containerised apps need, along with data management and protection for them.
Nor does the volume and variety of data that needs to be managed and protected look set to demonstrate anything other than continued prolific growth.
“The sources might be bare-metal, virtual servers, or containerised servers or IoT edge devices. Their locations might be centralised data centres, remote and branch offices, edge locations or multiple public clouds – or any combination of these,” says Ertekin. “And the data may be file, block or object-based. It might be streaming data, metadata, primary or secondary data. It will need to be managed for legacy applications, as well as for big data analytics, for AI and machine learning.”
This all points to a world where the ability to impose some kind of simplification will be a must-have for many firms, he says. After all, every organisation is now under pressure to achieve the same kind of standardisation, elasticity, scaling and predictability that enables the hyperscale cloud giants to cater to the needs of often millions of users, in the face of huge spikes and troughs in traffic and without missing a beat.
“But to do that,” he warns, “mainstream organisations also need to be able to take advantage of the same technology underpinnings and strategic thinking that got those hyperscale companies to where they are today. And at the heart of that is the process of making a complex task much simpler, less resource-intensive, less costly. That’s what has guided everything we do at Hedvig and continues to guide us.”
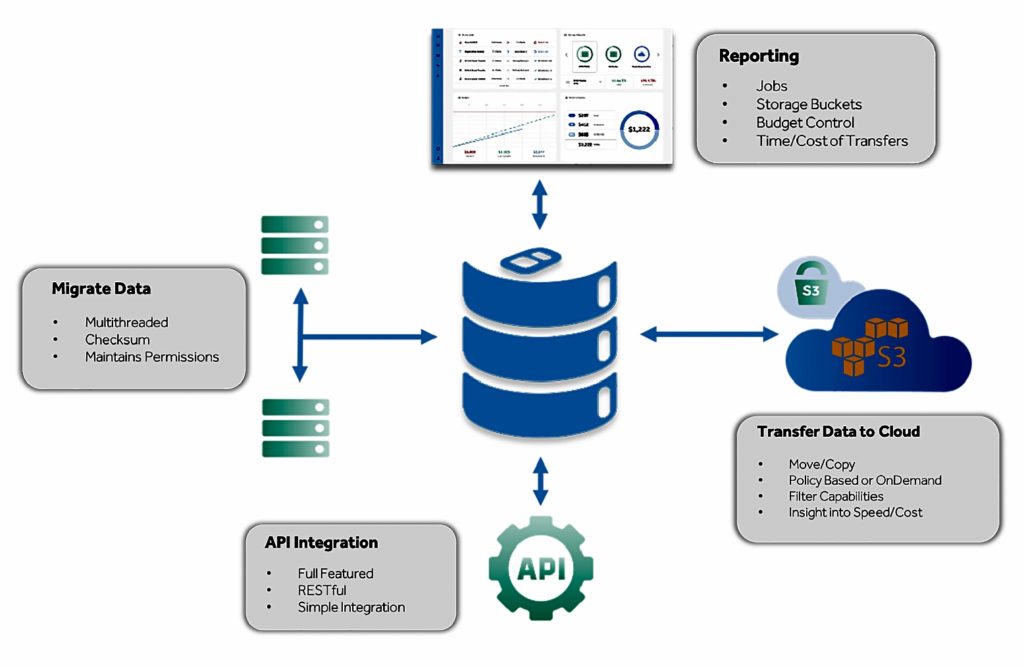
Integrated Media Technology (IMT), a tech systems integrator based in Hollywood CA, has launched its first software product. Called SoDA, the enterprise app can be thought of as data moving logistics service for AWS.
Update: GCP and Azure support plans added. On-premises cost comparison to be added at future date. 27 July 2020.
SoDA manages cost and data migration time visibility. You can use it to decide where best to move data, including comparing on-premises and public cloud tiers. A dry-run, predictive analytics feature allows customers to model the cost and duration of proposed data migrations to and from AWS. Data can be moved automatically according to policies or via manual transfer.
Greg Holick, VP of Product Management at IMT, said in prepared remarks: “SoDA predicts the cost and speed of data movement between on-premises and cloud solutions, giving customers the tools they need to control their spend and understand the time it takes for data movement.”
We asked IMT how SoDA gets and uses on-premises storage costs to make its comparisons with AWS public cloud S3 costs. A spokesperson said “Customers are typically aware of their on premises CAPEX purchases. We are looking at adding a pricebook feature, similar to how we do AWS, for each on premises storage later this year to make that comparison and we will do a cost/month basis based on a period of time.”
SoDA is delivered as a subscription service, with software running in a local virtual machine. It contains a policy engine with cost and ingress and egress transmission rates for different kinds of AWS S3 storage: Standard, Glacier and Deep Archive. SMB, NFS and S3 protocols are supported.
IMT SoDA diagram
Users set up a cloud transfer budget and monitor how individual file transfers affect this with a real-time dashboard. A budget limit can be set to prevent excess costs. Data transfer jobs are tracked and itemised so chargeback routines can be implemented.
SoDA’s subscription pricing model has unlimited data movement with no capacity limits. It has RESTful API integration with third-party media asset management packages. IMT’s datasheet and video marketing material do not say how on-premises storage costs are calculated.
IMT plans to add Azure support by the end of the year and GCP support after that.
Competition
SoDA appears to be an everyday data transfer tool – as opposed to a Datadobi-esque one-off migration project data mover. Other competing offerings include DataDynamics StorageX and Komprise’s KEDM. KEDM moves file data between NFS or SMB/CIFS sources and transfers it to a target NAS system or via S3 or NFS/SMB to object storage systems or the public cloud.
By the way SoDA is not an acronym. IMT chose the name because it’s a refreshing approach.
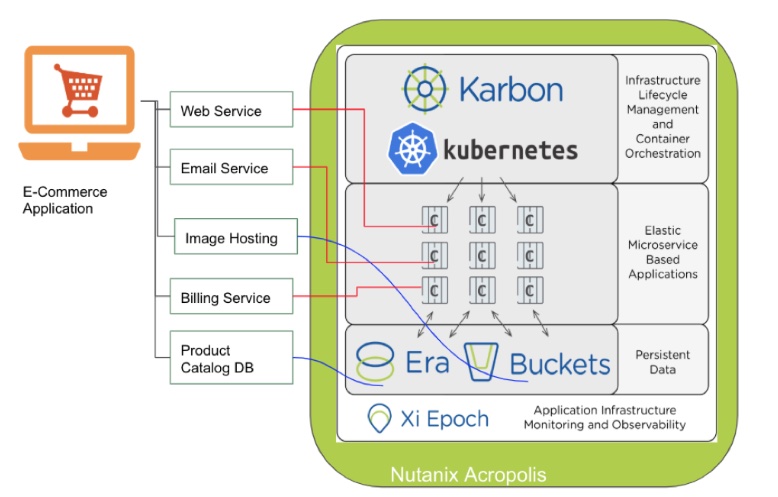
Nutanix’s goal for Karbon, a management app for Kubernetes, is to provide an integrated all-in-one framework to build and run containerised apps. That way, customers can go cloud-native with their Nutanix platform.
The company this week updated Karbon with networking, storage and API enhancements to further that goal. Version 2.1 adds storage volume cloning and expansion, to aid data protection. API hooks enable Karbon to work with Nutanix Calm and ServiceNow (or other apps that can use API calls). This helps automation and the more granular provisioning of Kubernetes clusters.
Nutanix Karbon diagram.
Calico networking
Nutanix has chosen Calico as the standard Kubernetes CNI (Container Network Interface) for Karbon 2.1, which will simplify network and security administration, according to the company.
Open source Calico is effectively a de facto standard for adding networking to containers, Nutanix says.
The code was invented and largely maintained by a company called Tigera. “By bringing Calico’s run-anywhere security enforcement to Karbon customers, developers and cluster operators enjoy a consistent experience and set of capabilities accelerating their Kubernetes journey, ” said Amit Gupta, Tigera VP of product management.
Karbon 2.1 follows Karbon 2.0 in short order. The predecessor came out in February and introduced Prism Pro management integration, network isolation for ransomware protection, plus 1-click Kubernetes upgrades.
European cloud service provider OVHcloud has bought OpenIO, a French provider of fast object storage.
OpenIO was started up in 2015 and has bagged about $5m or so of funding There were eight founders, led by CEO Laurent Denel. Its highly-scalable and open source object storage software is hardware supplier-agnostic. Today the company has 30-plus employees and more than 40 customers.
Laurent Denel.
Denel said in prepared remarks: “All of the technologies used to build our Object Storage solution are and will continue to be open-sourced, which is an essential common value for both OVHcloud and OpenIO. More than that, it will be extended and enriched by our combined talents.”
He told Blocks & Files: “OVHcloud’s acquisition of OpenIO comes at a time when performance has become a key consideration for a storage solution. Companies today want the benefits of trusted cloud storage, to regain control of their data and streamline costs – which are rising due the unpredictable pricing models offered by hyperscalers.”
Denel said: “The OpenIO brand will disappear, but the project continues. And it will grow, taking advantage of OVHcloud’s know-how to industrialise it.”
OVHcloud was founded in Roubaix, France, in 1999 by chairman Octave Klaba The hosting firm operates 400,000 servers in its own 30 data centres across four continents, and claims in excess of 1.5 million customers in more than 130 countries.
Michel Paulin, OVHcloud cloud CEO, issued a quote: “With the global volume of data doubling every 18 months, we are aware that storage issues are at the heart of the concerns of our 1.5 million customers. With the acquisition of OpenIO, we aim to create a highly scalable offering, benefiting from the best infrastructure and one of the most attractive prices in the market.”
OVH aims to build a European alternative to US public cloud offerings, with European data sovereignty rules respected.
OVH says that the combination of OpenIO software with its industrial and cloud infrastructure expertise will enable the design of a very large-scale object storage offering at the best price performance ratio. Both companies are European and open source in approach. Both have contributed to development of the Swift open source project which offers object storage as part of the Openstack foundation.
OpenIO’s workforce will join with the OVHcloud teams in Roubaix, Paris and internationally. The financial terms of the acquisition were not revealed.
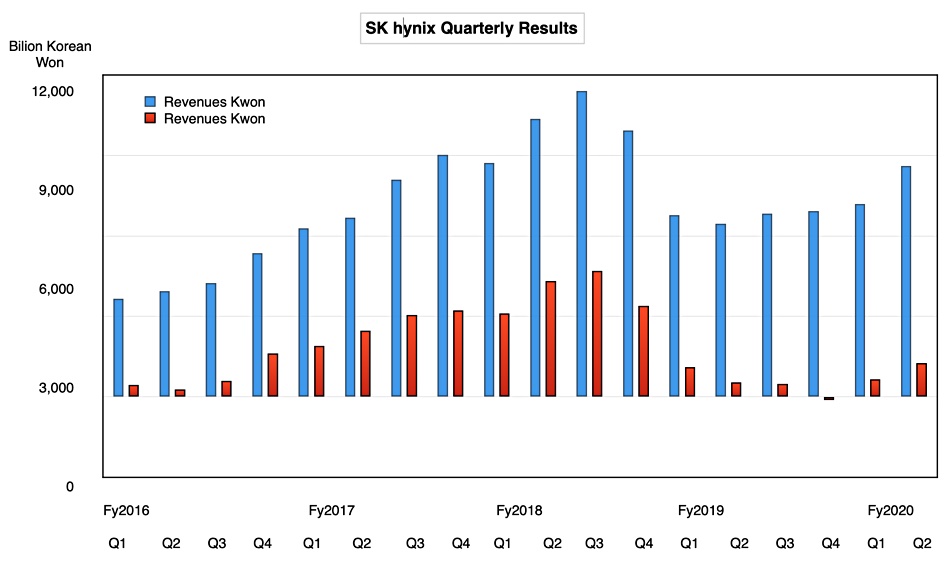
The second 2020 quarter marked a revenue and profits uptick for SK hynix, which sold more server memory and lowered costs by increasing process yield.
Revenues of ₩8.6tn ($7.15bn) were 33.4 per cent higher than a year ago and there was 135.4 per cent profit lift to ₩1.26tn ($1.1bn).
Sk hynix experienced weak mobile demand for DRAM in the quarter but demand for server and graphics DRAM increased. So much so that DRAM bit shipment and average selling price increased by two per cent and 15 per cent QoQ respectively.
NAND bit shipment and average selling price increased five per cent and eight per cent QoQ respectively. As well as making NAND chips, SK hynix is pumping out a lot more SSDs. This quarter, SSD sales for the first time accounted for almost half of its NAND flash revenues.
In the next quarter or two the company thinks the pandemic will continue to cause economic uncertainties. But it anticipates 5G smartphones and next-generation gaming consoles will stimulate DRAM, NAND and SSD growth.
To accompany the earnings release, sk Hynix teased out some roadmap details to accompany the earnings. It will focus on 1Ynm mobile DRAM, LPDDR5 DRAM and 64GB server DRAM product sales, while embarking on mass production of the next, 1Zmm memory node.
The company will also focus on more customer qualifications for its 128-layer 3D NAND product to drive sales upwards. It is also aiming to increase enterprise SSD sales.
Glad all over
The Korean memory chip maker’s recovery from the recent worldwide DRAM and NAND glut is gaining pace. A chart of revenues and profit by quarter shows the upturn:
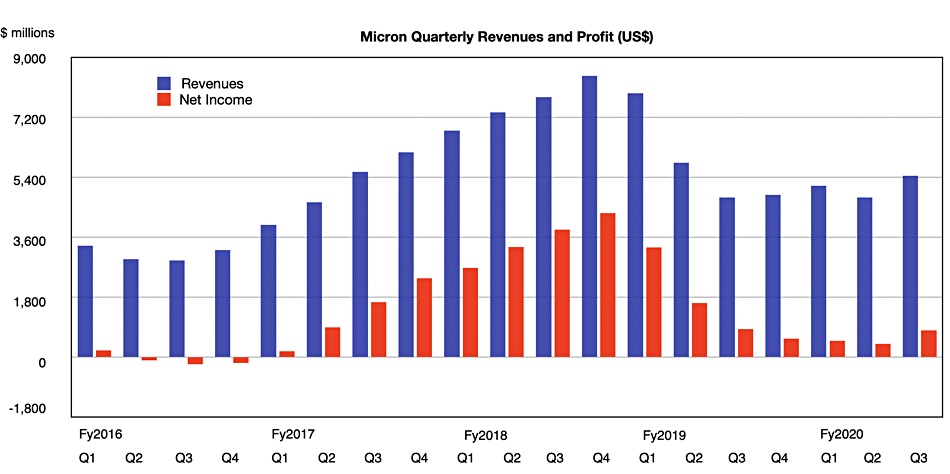
Competitor Micron saw a sales uplift in its most recent quarter which ended on May 28; 13.6 per cent to $5.44bn. It also exhibited four glut-trough quarters before this one, as the chart shows:
Western Digital revenues climbed 14 per cent on the back of record flash memory performance to $4.18bn in its third fiscal 2020 quarter ended April 3.
It certainly looks as if the DRAM and NAND glut is over.
The datasets used in big data analytics and AI model training can be hundreds of terabytes, involving millions of files and file accesses. Conventional X86 processors are poorly suited for this task and so, GPUs are typically used to crunch the data. Their instruction sets can process millions of repetitive operations many times faster than CPUs.
However, there is a performance bottleneck to overcome when transferring data to GPUs via server-mediated storage.
Typically, data transfers are controlled by the server’s CPU. Data flows from storage that is attached to a host server into the server’s DRAM and then out via the PCIe bus to the GPU. Nvidia says this process becomes IO bound as data transfers increase in number and size. GPU utilisation falls as it waits for data it can crunch.
For example, an IO-bound GPU system used in fraud detection might not respond in realtime to a suspect transaction, resulting in lost money, whereas one not getting access to data faster could detect and prevent the suspect transaction, and alert the account-holder.
Normally data is bounced into host server’s memory and bounced out of it on its way to the GPU. This bounce buffer is required – because that’s the way server CPUs run IO processes. However, it is a performance bottleneck.
If the IO process can be accelerated, with higher speed and lower latency, application run times are shortened and GPU utilisation is increased.
Modern architecture
Nvidia, the dominant GPU supplier, has worked away at this problem in stages. In 2017, it introduced GPUDirect RDMA (remote direct memory access), which enabled network interface cards to bypass CPU host memory and directly access GPU memory.
The company’s GPUDirect Storage (GDS) software, currently in beta, goes beyond the NICs to get drives talking direct to the GPUs. API hooks will enable the storage array vendors to feed more data faster to Nvidia’s GPUs, such as its DGX-2.
GDS enables DMA (direct memory access) between GPU memory and NVMe storage drives. The drives may be direct-attached or external and accessed by NVMe-over-Fabrics. With this architecture, the host server CPU and DRAM are no longer involved, and the IO path between storage and the GPU is shorter and faster.
Blocks & Files GPUDirect diagram. Red arrows show normal data flow. Green arrows show shorter, more direct, GPUDirect Storage data path.
GDS extends the Linux virtual file system to accomplish this – according to Nvidia, Linux cannot currently enable DMA into GPU memory.
The GDS control path uses the file system on the CPU but the data path no longer needs the host CPU and memory. GDS is accessed via new CUDA cuFile APIs on the CPU.
Performance gains
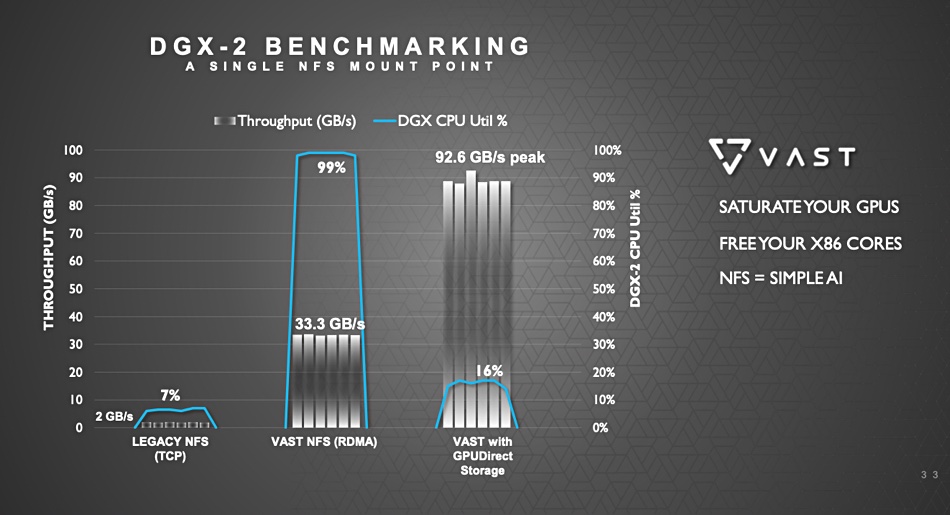
Bandwidth from CPU and system memory to GPUs in an DGX-2 is limited to 50GB/s, Nvidia says, and this can rise to 100GB/sec or more with GDS. The software combines various data sources such as internal and external NVMe drives, adding their bandwidth together.
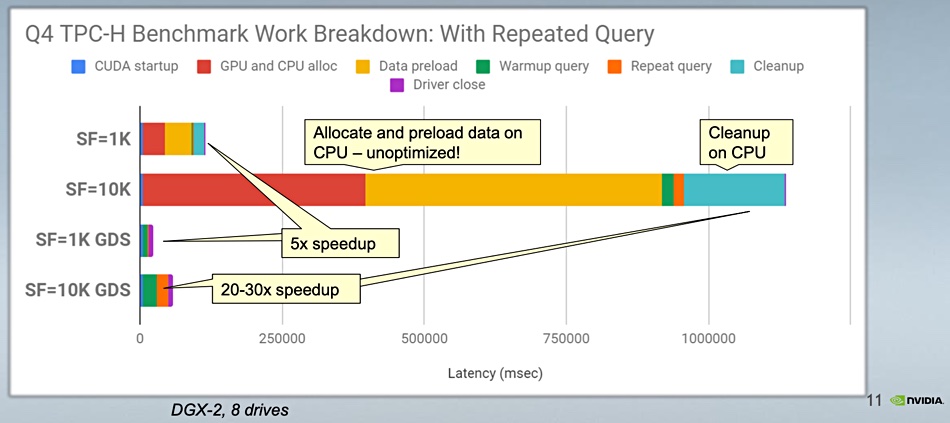
Nvidia cites a TPC-H decision support benchmark with scale factors (database sizes) of 1K and 10K. Using a DGX-2 with eight drives, the 1K scale factor test latency was 20 per cent of the non-GDS run. This is a fivefold speedup. At the 10K scale factor, latency was 3.33 to five per cent when GDS was used compared to the non-GDS case. This is a 20x-30x speed up.
Nvidia GDS TPC-H benchmark slide.
Four flying GDS partners
DDN, Excelero, VAST Data and WekaIO are working with Nvidia to ensure their storage supports GPUDirect Storage.
DDN is supplying full GDS integration with its A3i systems: A1200, A1400X and A17990X.
Excelero will have a generally available GDS support in the fourth quarter for disaggregated, converged and hybrid environments. It has a roadmap to develop a GDS-optimised stack for shared file systems.
A Nvidia GDS slide deck provides detailed charts showing VAST Data and WekaIO performance supporting GDS storage access.
VAST Data achieved 92.6GB/sec from its Universal Storage array with GDS while Weka recorded 82GB/sec read bandwidth between its file system and a single DGX-2 across 8 EDR links using two Supermicro BigTwin servers.
Blocks & Files envisages other mainstream storage array suppliers will soon announce support for GDS. Also, a GPUDirect Storage compatibility mode allows the same APIs to be used when non-GPUDirect software components are not in place. At time of writing, Nvidia has not declared Amazon S3 support for GDS.
Nvidia GDS is due for release in the fourth quarter. You can watch an GDS webinar for more detailed information.
Spin Memory, a developer of Magnetic RAM, has raised $8.5m in addition series B funding. This is valued at “the same terms as the last closing in April 2019”, lead investor Allied Minds said in a statement. Spin Memory will use the capital to support its research on MRAM to bring its technology to the market.
Founded in 2007, Spin Memory bagged $52m in B-round funding in 2018, taking total funding before the recent top-up to $158m.
The company announced the funding – but not the amount or terms -earlier this month. CEO Tom Sparkman said: “The additional investment validates the work we’re doing here at Spin Memory and demonstrates the value of our unique MRAM IP offerings – especially during such challenging times. We are proud to be part of the growing MRAM eco-system in both the embedded and stand-alone implementations.”
Tom Sparkman
Allied Minds, which owns 43 % of Spin Memory capital, contributed $4m to this capital raise. Arm, Applied Ventures and Abies Ventures jointly contributed $4.25m.
Allied Minds CEO Joe Pignato issued his own quote: “The additional funding announced today endorses the business’ development and provides additional resources to support its rapid growth.”
He suggests markets such as artificial intelligence, autonomous vehicles, 5G communication and edge computing could use Spin Memory’s technology.
Magnetic RAM
Magnetic RAM is positioned as a replacement for SRAM (Static RAM) used in CPU cache memory.
SRAM is volatile, faster than DRAM and also more expensive. Spin Memory claims SRAM technology is growing its capacity at a falling rate and techniques to reduce SRAM current leakage at transistor and chip level are near exhaustion. As CPUs get more powerful the SRAM caches will be unable to keep pace.
Hence the need for replacement technology. Spin Memory says its Spin Transfer Torque (STT) MRAM, which can be non-volatile, is that replacement.
The company is developing embedded and stand-alone MRAM devices. The embedded product, built with Applied Materials, was meant to be commercially available last year. This background suggests new top-up funding was needed to complete the development and bring the embedded product to market.
Spin Memory’s technology uses less energy than DRAM. It has more than 250 patents, a commercial agreement with Applied Materials, and a licensing agreement with Arm. The company is in the R&D phase for multi-layer and multi-bit cell MRAM. 3D MLC MRAM, which would increase MRAM chip capacity and could function as storage-class memory.
Spin Memory 3D MLC diagram shows a 2-layer crosspoint design
A 2-layer structure could double the existing STT MRAM capacity and a 2-bit MLC cell would double it again. Spin Memory suggests this would have the same density as today’s DRAM.
Commvault has rejigged its product lines to better match market needs. The company has separated components for data protection, disaster recovery and data management tasks, and has integrated Hedvig software into HyperScale backup appliances.
Commvault announced the portfolio reshuffle yesterday at its Future Ready customer conference. The company has also rolled out subscription pricing to more products, while confirming ongoing support for perpetual licensing options.
Rajiv Kottomtharayil
Commvault chief product officer Rajiv Kottomtharayil provided an announcement quote: “Customers need to be increasingly agile, flexible, and scalable. This new portfolio addresses data management risks that exist today and that may exist tomorrow, intelligently. From a natural disaster, to human error, to ransomware, our customers are covered.”
Coming out of 2019, Commvault had six product lines: Commvault Complete Backup & Recovery, Commvault HyperScale, Commvault Orchestrate, Commvault Activate, Hedvig’s Distributed Storage Platform (DSP) and Metallic (SaaS backup and recovery service).
The new line-up is:
HyperScale X with Hedvig technology
Commvault Backup & Recovery
Commvault Disaster Recovery
Commvault Complete Data Protection
Commvault Activate disaggregation into separate Data Governance, eDiscovery & Compliance and File Storage Optimization products
Enhanced Container Support for Hedvig’s DSP
Commvault launched HyperScale appliances in 2017 to provide scale-out backup and recovery for containers, virtual and database workloads. The appliances supports on-premises deployments and multiple public clouds, with data movement between these locations.
HyperScale provides up to 5PB of capacity, automatic load balancing across nodes, data caching, cataloguing, automatic rebalancing of stored data across nodes, and integrated copy data management.
The new HyperScale X, available today, brings Hedvig’s DSP file system software to the appliance for the first time, adding higher performance backup and recovery as the system scales. Concurrent hardware failures are managed to maintain availability.
Commvault’s standalone Backup & Recovery protects containers, cloud-native, and virtual server workloads across cloud and on-premises environments. A separate Disaster Recovery product supports on-premises and cloud environments with automated DR orchestration, replication, and verified recovery readiness.
A Complete Data Protection offering combines Backup & Recovery and Disaster Recovery.
Not so simple
Commvault announced Activate in July 2018, in a product simplification exercise prompted by prodding from activist investor Elliott Management. The software is now disaggregated into separate data Governance, eDiscovery and compliance, and file storage optimisation products.
Hedvig’s DSP software, acquired last year, gets more container support. Hedvig introduced Kubernetes Container Storage Interface (CSI) support in October 2019 and with Hedvig for Containers has added:
Native API Kubernetes enhancements to offer encryption and third-party key management (KMIP) support,
Container snapshots for point-in-time protection of stateful workloads,
Container migration to move data across Hedvig clusters on-premises or in the public cloud,
High-availability and disaster recovery for containerised workloads,
Automated policies for snapshot frequency and migrations.
Avinash Lakshman, chief storage strategist for Commvault, said in a statement: “Cloud native applications are critical to the enterprise, and Hedvig for Containers hits that sweet spot of software-defined storage coupled with protection for containerised applications.”
Hedvig for Containers is available today.
Comment
Commvault is in a data protection and storage marathon. The company competes intensely with Actifio, Cohesity, Dell, IBM, Rubrik, Veeam and Veritas for enterprise data protection and management accounts. Also, ambitious backup-as-a-service startups such as Clumio and Druva are muscling in to this territory.
Commvault has rearranged its shop window to better show its wares. It’s also moved to take advantage of its Hedvig software-defined software by adding it to the HyperScale appliance line. Hedvig’s latest updates should enhance the software’s appeal to enterprise DevOps cloud native users.
Commvault is claiming a stake in the general storage market with Hedvig Distributed Storage Platform providing file, block and object storage at cloud scale. This general storage market also features intense competition from new and established suppliers and the idea of a combined file, block and object storage product is not universally adopted.
Commvault can use Hedvig software in its own appliances, but it will be quite the challenge to gain wide traction in the general storage market. There are good growth prospects for the emerging stateful container market and Commvault is building a strong story here. However, the mainstream storage suppliers are not so far behind.
IBM executive Arvind Krishna. 5/30/19 Photo by John O’Boyle
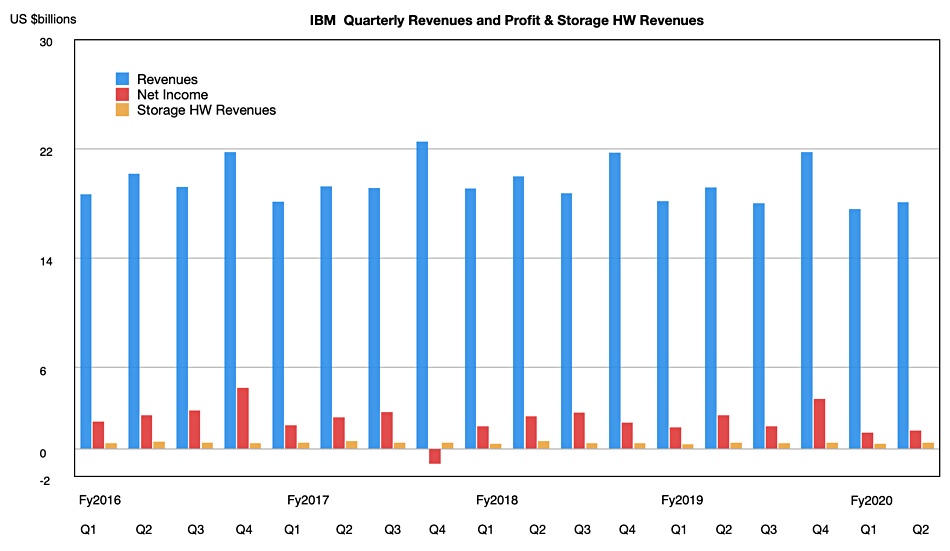
IBM’s latest quarterly revenues dropped a few per cent but mainframe revenues rose strongly and its storage business grew for the third quarter in a row, albeit at 2 per cent.
Q2 revenues declined 5.4 per cent y/y to $18.1bn and net income slumped 45.5 per cent to $1.36bn as the pandemic discouraged customer spending. That said, Big Blue sees green shoots ahead as enterprise customers adopt more AI and head for hybrid multi-cloud IT.
Arvind Krishna.
CEO Arvind Krishna said in prepared remarks: “Our clients see the value of IBM’s hybrid cloud platform, based on open technologies, at a time of unprecedented business disruption.”
He added: “What’s most important to me and to IBM is that we emerge stronger from this environment with a business positioned for growth. And I am confident we can do that.”
The “open technologies” phrase include’s IBM’s acquired Red Hat business which saw revenue rise 17 per cent.
No great pandemic depressing effect visible in IBM’s latest results.
IBM’s business units results were mixed;
Cloud & Cognitive Software — revenues of $5.7bn y/y, up 3 per cent.
Global Business Services — revenues of $3.9bn, down 7 per cent.
Global Technology Services — revenues of $6.3bn, down 8 per cent.
Systems — revenues of $1.852bn, up 6 per cent. This was made up from Systems hardware rising 13 per cent, with Z mainframes contributing a massive 69 per cent revenue rise, storage systems growing slightly by 2 per cent and poor Power server systems down 28 per cent. Operating system software declined 13 per cent while cloud-based revenues in the systems business grew 22 per cent.
Global Financing — revenues of $265m, down 25 per cent.
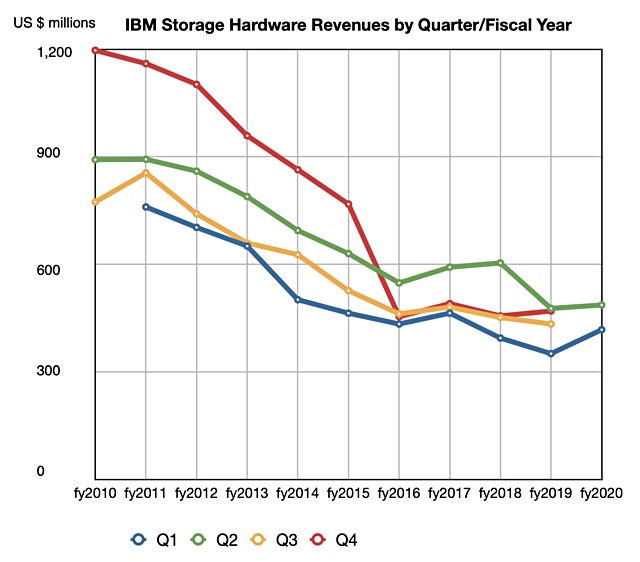
Storage division CMO and VP Eric Herzog told us: “IBM Storage Systems grows for the third quarter in a row with growth of 2 per cent for Q2 2020, following growth of 18 per cent in Q1 2020 and 3 per cent in Q4 2019.”
We added the latest storage revenue number to our chart of IBM’s quarterly storage revenues by calendar year and the third-in-a-row uptick (green line) is clearly seen:
These numbers do not include some IBM storage software sales nor its Cloud Object Storage business as IBM doesn’t reveal these aspects of its overall storage business.
IBM’s second quarter storage results contrast with HPE’s second fiscal 2020 quarter ended April 30. HPE’s storage revenues slumped 18 per cent to $1bn due to “component shortages and supply chain disruptions related to the COVID-19 pandemic”.
They also contrast to NetApp’s fourth fiscal 2020 quarter ended April 24, when revenues dropped 11.9 per cent to $1.4bn as the pandemic struck and exacerbated product and cloud sales weaknesses.
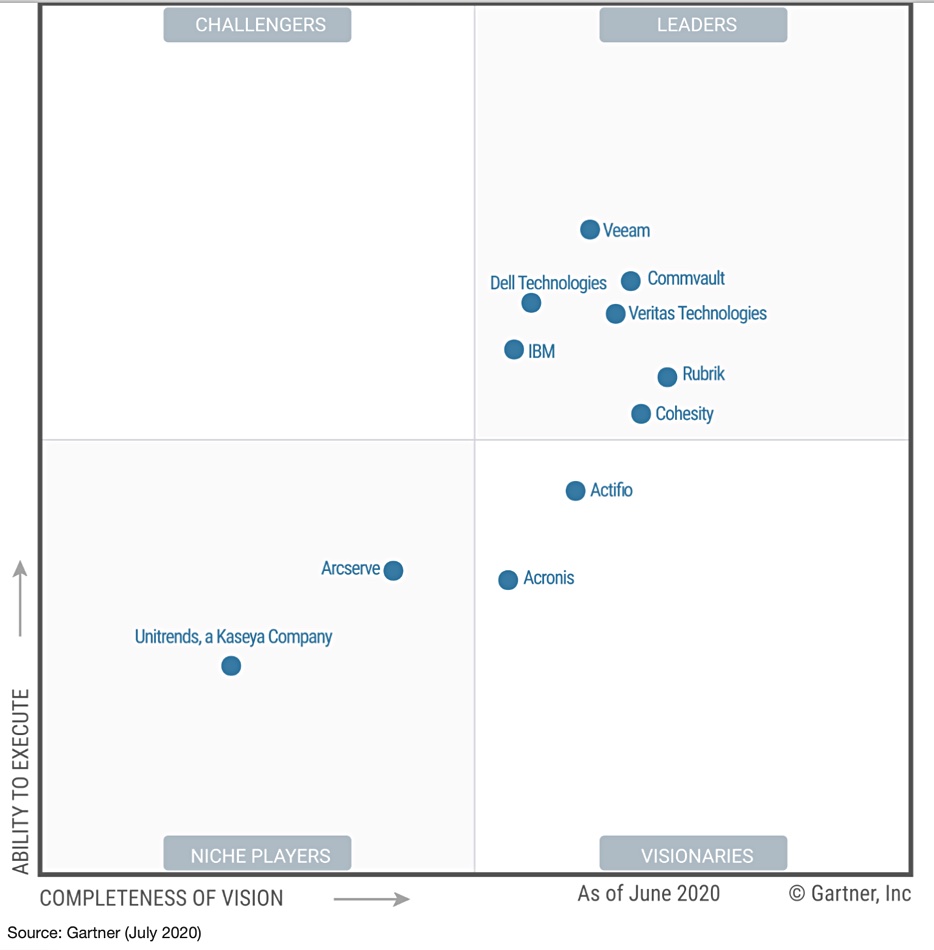
The Gartner gurus have updated their Backup and Recovery Magic Quadrant, moving two of 2019’s ‘visionaries’, Cohesity and Rubrik, into the leaders’ quadrant.
Update: 2020 MQ for backup and recovery diagram added.
We have seen a copy of the report and Magic Quadrant (MQ) chart. The authors write: “The move toward public cloud, heightened concerns over ransomware, and complexities associated with backup and data management are forcing I&O leaders to rearchitect their backup infrastructure and explore alternative solutions.”
That is fast progress for both companies, but faster for Cohesity than Rubrik, which made its first appearance in 2019. That year Rubrik and Arcserve complained publicly that their position in the visionary and niche player’s quadrants respectively were unfair.
This year Rubrik has made it to the leaders’ quadrant but Arcserve remains boxed in with the niche players. Arcserve did not respond to requests for supplemental information,” Gartner says. “Gartner’s analysis is therefore based on other credible sources, including Gartner client inquiries, Gartner Peer Insights, press releases from Arcserve and technical documentation available on Arcserve’s website.”
Dell and IBM are in the Leader’s quadrant as before but in other changes:
Commvault and Veeam are the top two in the leaders quadrant but Veeam has overtaken Commvault with a higher ability to execute.
Veritas is a leader for the fifteenth time in a row, and Commvault for nine years in a row
Acronis moves from niche player to visionary. The MQ report says Acronis has a widening capability gap and “trails competition in its ability to provide comprehensive data protection capabilities for public cloud, hyperconverged infrastructure (HCI) and network- attached storage (NAS) environments.”
MicroFocus, a niche player in 2019, no longer in the MQ.
Actifio moves higher up the visionaries’ quadrant with Gartner noting limited presence outside North America, lack of tape support, and its “list price for software licenses and annual maintenance is higher than most vendors evaluated in this research”.
In response, an Actifio spokesperson told us: “Gartner relies on revenue and growth for its Ability to Execute axis. Companies that sell hardware, be they appliances or “bricks,” get what one might call an unfair advantage (in this case a spot in the Leaders quadrant) compared with vendors with pure software or SaaS models.”
Like Arcserve, niche player Unitrends did not respond to Gartner requests for supplemental information.
Gartner awards so-called Honourable Mentions to certain other backup suppliers; Clumio, Druva, HYCU, and Zerto.
Clumio, HYCU and Zerto were not included in the MQ because they did not meet Gartner’s revenue criteria. Druva was not included as it did not meet the criteria for minimum number of enterprise backup customers that deployed the solution at the scale.
As a reminder, Gartner’s Magic Quadrant is a 2-axis chart plotting Ability to Execute” along the vertical axis and Completeness of Vision along the horizontal axis. There are four subsidiary quadrants or squares; Challengers and Leaders along the top, and Niche Players and Visionaries along the bottom.
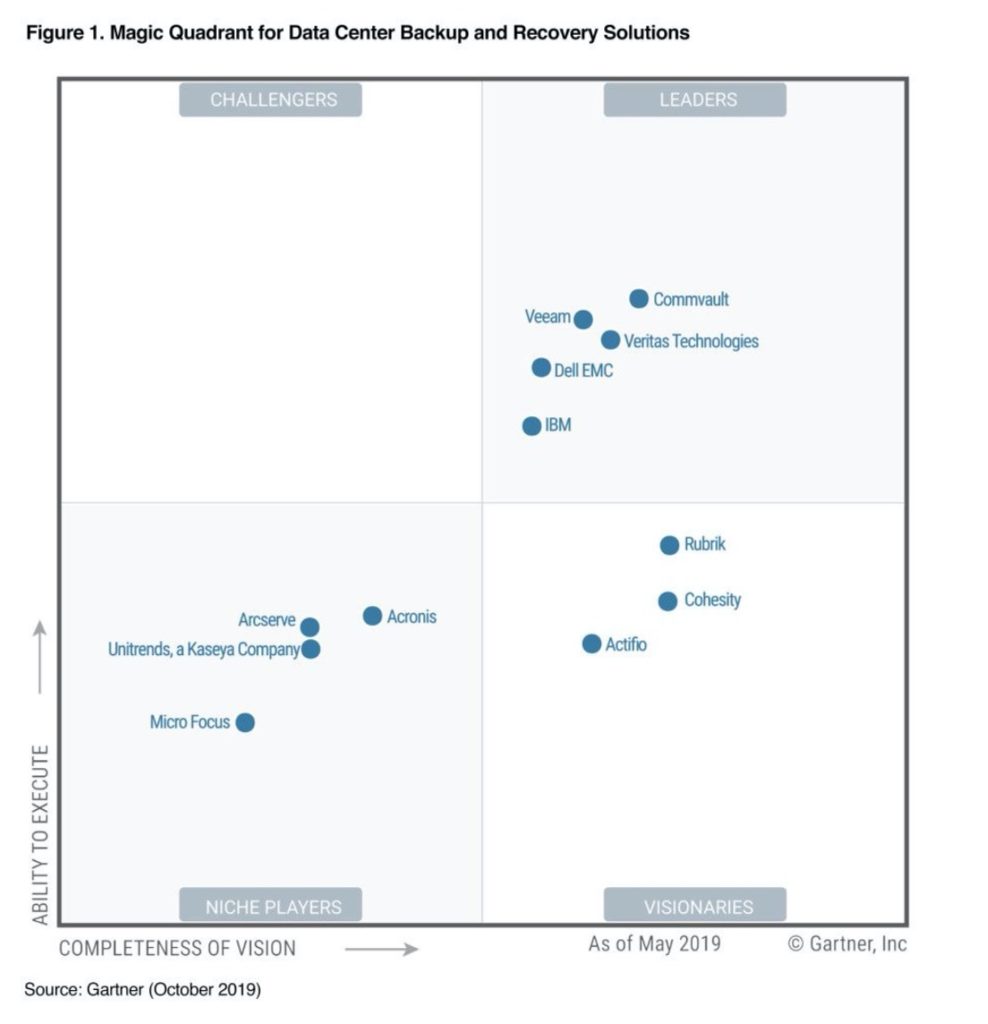
Here’s last year’s backup and recovery MQ for comparison;
Kubernetes is “four to five years away” from being a stable distribution capable of running stateful apps, according to Redis Labs chief product officer Alvin Richards.
Enterprise IT applications typically need to access recorded data, process it, and write fresh data. This data is its state. Can Kubernetes run stateful applications out of the box? “No, absolutely not,” Richards told us in a phone interview. That’s where Kubernetes’ myriad extensions come in.
More on that later, But first, let’s remind ourselves of ‘stateful’ and ‘stateless’.
Stateful and stateless containers
Alvin Richards
Kubernetes began its life orchestrating stateless containers and these provided a way to scale applications relatively easily. But they don’t record data, having no memory of previous sessions when they are instantiated. Like a simple calculator application they have no state. Whenever a calculator is started up it sets itself at zero and waits for input. That input is lost when the calculation app is closed.
A spreadsheet, on the other hand, has state. In other words, you don’t need to enter information each time Excel is started up. The values in its cells are recorded, stored and loaded into memory when the spreadsheet app opens the filed spreadsheet data.
CSI (Container Storage Interface) is the starting point for adding state to containers orchestrated by Kubernetes. CSI enables third-party storage providers to create plugins adding a block or file storage system to a Kubernetes deployment without affecting the core Kubernetes code. Multiple data storage vendors have set up CSI plugins linking their external storage systems to containers or they set up actual storage containers. Each one is unique.
Kubernetes Operators
So is CSI job-done for Kubernetes and storage? Not according to Richards, who says the software needs an operator.
Redis Labs software talks to an operator, a piece of interface code that automates Kubernetes operations. An operator uses the Kubernetes API to tell Kubernetes what to do. Effectively, Richards says, “Kubernetes is an API … to provision and automate infrastructure.” Redis operator has been extended so it can use the API to create a database inside a cluster. It provides high availability with automated disaster recovery.
A question for Redis, as a supplier of an open source, distributed, memory-cached NoSQL database, is what should Kubernetes do about such stateful services?
These, like the Redis NoSQL database, could run in the local Kubernetes cluster or in a managed cloud service accessed through a gateway. The operator needs to know this and there has to be secure node-to-node communication for software like Redis. Raw storage functionality is not enough for enterprise storage needs.
Multiplying distributions
According to Richards, there are many Kubernetes distributions, with each adding its own bit of uniqueness to the pot, that could lead to customer confusion. How will these disparate distributions get combined? Richards contrasts Linux and Docker: “Linux got to a point with a guiding light (Linus Torvalds) and powered ahead…. Docker did not.”
He thinks there are two very different Kubernetes communities: stateless and stateful. My impression is that he wants it to take the Linus/Linux route to power ahead, and adopt stateful container functionality.
Incentives dichotomy
In our view, the baseline Kubernetes distribution expands functionality over time, absorbing the good additions from the various forks. Suppliers providing added paid-for services on top of the raw Kubernetes distribution have to accept this, and move their services up the stack or add new services. They don’t contribute their paid-for code to the Kubernetes open source project; that would destroy their ability to monetise their code.
Other more altruistic coders develop similar or equivalent functionality and contribute it to the project, eroding the basis for the paid-for code. Richards describes this as a dichotomy of incentives. For instance, he thinks that stateful app management, like encryption, should be just a basic part of the raw Kubernetes distribution, i.e, a feature and not a product.
Richards cites MongoDB as now having core and good enough database functionality. In other words mucho of the functionality in originally, paid-for extensions has been assimilated into the core database.
Stating the not-so-obvious
So will a vibrant Kubernetes open source community follow suit? Progress has been made and you can run stateful services in Kubernetes. But, Richards says: “Can a wider audience/community be successful? Well the jury is out on that.”
He thinks we’re maybe four to five years away from having a stable Kubernetes distribution capable of running stateful apps. But “the timeline will shorten as it becomes a major focus.”
Until then we have to endure the messy altruistic and artisanal coding creativity that is the open source movement, and hope it collectively takes us to the right destination where raw Kubernetes can run stateful containers out of the box.