Arcitecta CEO and founder Jason Lohrey presented his thoughts on the company’s progress and future at an IT Press Tour event in New York this month.
Australia-based Arcitecta’s Mediaflux distributed data management software supports file and object data storage with a single namespace and tiering capability covering the on-prem, public cloud, and hybrid environments, with SSD, disk, and tape storage tiers. There is a Livewire data mover and metadata database. Mediaflux Multi-Site, Edge, and Burst offerings help geo-distributed workers get fast access to shared data – text, images, video, time-series, etc. – with Mediaflux Real-Time offering virtually instant access to content data. Arcitecta competes with Datadobi, Hammerspace, and Komprise. Recent customer wins include Princeton University, Dana-Farber Cancer Institute, the National Film and Sound Archive of Australia, Technische Universität Dresden, and the UK’s Imperial War Museum.
Jason Lohrey
As organizations store more and more data, heading toward hundreds of billions or even more than a trillion files, Lohrey said: “Pretty much everyone needs data management, and that’s good for us. That’s the space we’re in, including those that are doing geo-distributed.” This needs more than a distributed file system as it’s “a flow of data with a single pane of glass to see where all of these things are at any point in the time and where they’ve been and controlled to create these super holdings of data and orchestration of flow.”
“That’s not your normal file system kind of thing, but it will actually involve file systems and general distributed data.”
“During the last year, we figured out how to double, or better than double, the information density of the database. This, to me, is the Holy Grail; how to increase the density of information in the database with a given footprint, and it is the thing that we’ve spent years and years and years and years of R&D on.”
“And this year, I think we’ve cracked the nut open in terms of vastly improving the density of information storage that will be, those algorithms will be rolled out in the coming year, I think, to increase the amount of information we can store in the system, it’ll improve the performance and allow us to have more indices and sets of things within a given unit of storage space in the database.”
He said that Arcitecta is unlike other data management suppliers: “What differentiates us from others is that we’re in the data path. And I really think real data management must entirely be in the data path. It’s the only way you can do things like understanding where things are in real time, and be able to find things in tens of milliseconds.
“We have a customer where we’re exporting 70 million ordered events per month, and that is enabling us to tell exactly what was created in the file system, by whom and from what vector, what was deleted by whom, and from what vector, what was accessed, every single access to those files at any point in time, every rename, every operation, every metadata operation, every data operation. And then we produce analytics outside of this to determine what the shape of access is in these systems, and how much of that data is being used or not.”
One of Arcitecta’s customers has used this. “They’ve realized that 12 out of their 18 petabytes is not active data at any point. Because we’ve got access records back to 2012, we can tell that those are not active. So they might actually move a lot of that data to tape as well, and just keep a much smaller high-performance storage system than they would normally keep.”
He said that datacenters need to be built in places where there is energy for compute and water for cooling. This alters system design assumptions. “It used to be that we took compute to the data, and we’re still very interested in that, but, in fact, we might need to really take our data to the compute, where the energy and water is actually.”
This means high-performance networking becomes more important. “To me, that is part of the overall vision that’s driving what we’re doing as a platform, general orchestration. Not just concentrated on a single file system here, high performance parallel file system there, or local enterprise storage, but the ability to move data wherever it wherever it’s needed, and have very distributed systems.”
Arcitecta has added more tape library support in the last year, including SpectraLogic, Grau Data, and IBM Diamondback. Lohrey said: “Mediaflux managers will keep track of all the barcodes on tapes in the system, so that if you have an issue where something is corrupted, we can go back and recover it.”
Looking ahead, Lohrey said: “Where are we going to go to from here?”
Specifically, Arcitecta will add a Python module to Mediaflux, and upgrade the DAMS (Digital Media Asset Management System). It will expand the vector database, and streamline Mediaflux’s deployment.
Lohrey discussed Arcitecta’s general direction for the future, and mentioned two aspects.
First: “We’re going to go further up the stack, which means we’re going to build more applications and things like our digital asset management application. You’ll see more of those that are integrated with the platform. I’ve got a decade’s worth of things that we could build up our sleeve. I’ll probably keep them up my sleeve for the while.”
We wouldn’t be surprised to see AI data pipeline-related applications coming.
Second: “We’re still going to go further down. So that means we’re going to do more storage management underneath, so integrating. … It’ll become less clear where the boundaries are between us and the storage. Because most people are interested in the protocols at the top and the management of their data, and we can hide away a lot of the storage underneath those layers, so we can actually simplify the entire stack just by having us drive the hardware underneath.”
This suggests Arcitecta could be developing a software-defined storage layer.
There will be some sort of action on the HPC front: “I once said that we would not do HPC file systems. And in fact, actually, if you look at something like Dell’s Project Lightning, that’s pretty impressive. When that comes to pass, we’re not going to compete with that. But I think there’s a very good chance that we can do a lot, a very significant number of HPC work. So we’re going to start doing more on that front. So you’ll end up with your grand unified file system.”
Traditionally, HPC data storage has meant parallel file systems, like Storage Scale and Lustre. Arcitecta competitor Hammerspace has used parallel NFS (pNFS) technology to build is data orchestration/data management product. We think Arcitrecta might be looking to use pNFS to add parallelism to Mediaflux and so have a foundation for HPC features.
The latest, v6.0, major release of IBM’s Storage Scale has a Data Acceleration Tier (DAT), a high-performance NVMeoF-based storage layer designed to deliver extreme IOPS and ultra-low latency for real-time AI inferencing workloads.
Storage Scale, originally called GPFS, is IBM’s parallel file system software and is popular in supercomputing and high-performance computing circles as well as in enterprise computing shops adopting HPC-style IT for workloads needing fast file IO, such as GenAI. It is adapting to the GenAI era by speeding data delivery to GPU servers with a new tier of storage for low-latency and high-speed access; the DAT layer, which uses Asymmetric Data Replication. This provides a ‘performance’ data replica for fast reads and a ‘reliable’ data replica for data safety, protected by erasure coding.
The performance copy of data is a persistent, non-redundant cache. It is maintained with lazy consistency, meaning that missed updates (eg, performance drive offline) will be corrected on the next read after the drive is back online.
There are two deployment options for the performance replica or pool, both maintaining the reliable pool on the Storage Scale System 6000 (ESS 6000) appliance;
Centralized DAT: This configuration is optimized for ease of use and meets general AI workload IOPS requirements, with the performance pool deployed on Storage Scale System 6000 using NVMeoF for client access. It’s achieved 29 million IOPS with 32 nodes.
Distributed DAT: This configuration is optimized for higher, indeed extreme, AI workload IOPS needs, with the performance pool deployed on client-local storage (GPU Server DAS), and performance determined by the drive configuration and compute capabilities of the client nodes. It’s achieved 16 million IOPS with 16 nodes.
An ESS 6000 supports a single DATA filesystem and a DAT filesystem may not use more than one ESS 6000 and that should be the all NVMe flash configuration, not a hybrid config.
IBM Slide.
IBM slide.
All-in-all, IBM says, Storage Scale v6.0 has these AI-relevant features:
Content Aware Storage (CAS): introduces async notifications, enabling faster, event-driven data ingesting into AI inferencing workflows
Expanded Nvidia integration with CNSA (Container Native Storage Access) support for GPUDirect Storage, enhanced Base Command Manager support, and Nvidia Nsight integration.
Aligned with NvidiaA BasePOD/SuperPOD and Grace Blackwell platforms, Nvidia cloud platform and Nvidia-certified storage certifications, ensuring performance and compatibility.
It also has 1-button GUI upgrades, enhanced prechecks, and unified protocol deployment simplify operations. API-driven control plane enhancements help enable automation of features like quotas. There are improved problem determination diagnostics for expels and snapshots to streamline root cause analysis and remediation.
IBM says there should be added support for NFS nconnect for Storage Scale 6.0.0 which enables high-throughput AI workloads over standard Ethernet. It intends to add support for SMB Multichannel for future releases of Storage Scale which would enable high-speed data acquisition from Windows-based instruments and faster subsequent data processing by Windows-based applications.
IBM intends to remove a DAT restriction saying it cannot support a remote cluster in a future release of the software.
Bootnote
From a Microosoft website: The nconnect mount option allows you to specify the number of connections (network flows) that should be established between the NFS client and NFS endpoint up to a limit of 16. Traditionally, an NFS client uses a single connection between itself and the endpoint. Increasing the number of network flows increases the upper limits of I/O and throughput significantly.
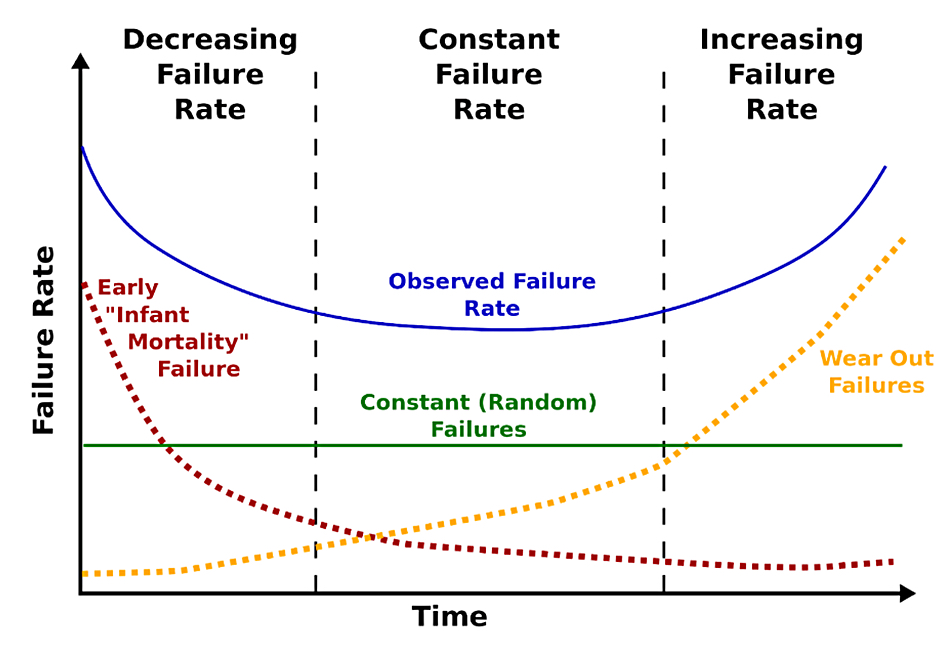
Backblaze disk drive failure stats suggest the “bathtub curve” effect may be imaginary.
The idea is that disk drives fail either early on in their life or after many years, and a plot of failure rate over time shows a U-shaped curve with higher rates at the start and end of working life and few or no failures between these points. However, a Backblaze blog shows that the bathtub curve effect is absent as the company builds up more lifetime failure data.
The bathtub curve concept looks like this:
Backblaze chart.
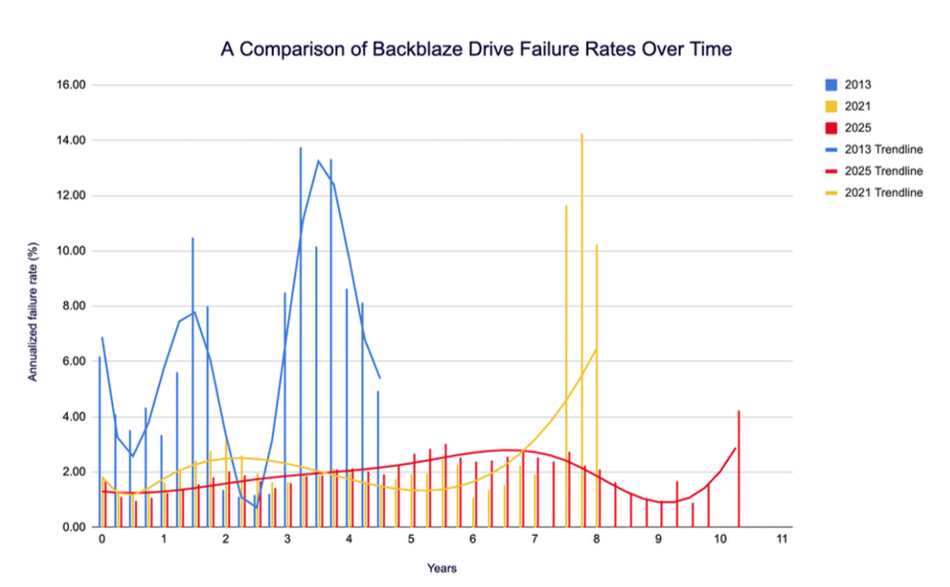
Backblaze published three sets of HDD lifetime failure rate charts in 2013, 2021, and 2025. It has combined these in a single bar chart with trend lines added for each year:
There was a partial bathtub effect in 2013 (blue bars and curve), with a midlife failure rate peak as well as start and end-of-life peaks. The 2021 numbers (yellow bars and curve) differ, showing a mild early years rise and a pronounced end-of-life increase in failure rates.
The 2025 numbers (red bars and curve) are different again, showing a gradually rising failure rate curve until year seven, after which there is a drop and then a much less-pronounced uplift.
What is going on?
First of all, the number of drives involved has risen over the years, so the failure rates are more statistically reliable. In 2013, there were 35,000 drives, 207,000 in 2021, and as of June 30, 2025, Backblaze had 321,201 drives under management. Secondly, Backblaze could be managing its drives better. Thirdly, as these stats cover 15 years or more, the disk drive manufacturers are making more reliable drives.
The Backblaze bloggers say that “drives are getting better and lasting longer.” In effect, the bathtub disk drive failure rate concept looks to be wrong.
They add: “Our numbers have always and will always reflect both good planning and the unforeseen aspects of reality. Understanding whether drives are ‘good’ or ‘bad’ is always a conversation between what you theorize (in this case, the bathtub curve) and what happens (the Drive Stats dataset).”
The first part of this interview looked at Quantum CEO Hugues Meyrath’s career and how it came about that he joined Quantum as its CEO. This next part looks at his views on the products and their prospects, quantum’s debt and the difference he can make.
B&F: You’ve got the product lines, you’re in place, you’ve brought in new sales leadership, Tony Craythorne. There’s a CFO slot I guess you have to fill still. So Tony will help with go-to-market for the existing product sets. How do you look at things like video surveillance and Myriad? Do they have a role in the future you see for Quantum.
Hugues Meyrath
Hugues Meyrath: Yeah, so it’s a good question. So let’s talk about video surveillance first. I’ve learned a lot more. So I went with Tony to see in person something like 58 customers and partners the last three weeks. So we went on the road and I did a west coast trip. I did a Dallas and Oklahoma trip and I did an east coast trip. And then I went as you know to Europe for 10 days and I’m going to tell you about video surveillance. What’s interesting in video surveillance is underneath it, you have actually a converged architecture, converged like compute and storage architecture, which is a scale-out architecture based on open-source. I think it’s an interesting platform. So there’s something that maybe can be done with that, but it’s not priority number one. But number two, which is after I reboot the team, finished the rebooting of the team, and [then] we have more to talk about that that’s not been disclosed.
When the sales guy goes to video surveillance customers, they meet the video surveillance team. When I go meet with the video surveillance customer, they introduce me to corporate IT. Now we went to see a big casino; they have 10,000 security cameras. And I went to other customers like the Washington Metro Transit area, like the buses, the subways, they’re all Quantum surveillance in there. But when I go see the customer as a CEO, they introduce me to corporate IT, which are different buyers. And when we go to the casino corporate it, they tell us: “Hey, we’re a casino and we have issues with the insurance and privacy of leaving data in the cloud. What can you do for us?” And we have an ActiveScale cold storage conversation with them, right?
And that’s the motion that never worked at Quantum, right? This was the vision, like I can go into this segment and then go back to corporate IT. But I think what it takes is for the CEO, and maybe Tony; we need to train the salesforce, and I need to get my ass on the road to create that conversation on behalf of my salesforce. But assuming that a salesperson can actually do it on their own when they’re six levels down is not a reasonable assumption. Now, I’m not saying that I’m going to double down on video surveillance, but it’s actually a very stable product. Not a lot of engineering effort and really, really good customer names that you can potentially sell more to.
But you have to actually help the field sell more. And I think that a lot of the issues in the past is when you get a CRO that’s coming from a big large company and they’re waiting for the jet to show up. That’s not going to work. Like Quantum’s the salt mines. We’ve lost the right of an automatic meeting except with a lot of distorting customers. You have to be willing to go down the salt mines and put the effort in. But if you put the effort in, I think it yields with return. But you need the right people for those jobs.
B&F: Would you be possibly thinking that AI could possibly have a role here in helping to mine the video surveillance data?
Hugues Meyrath: Oh, absolutely. I think in general AI you have to look at it a couple different ways. I have a fundamental assumption for AI. If you look at what Gardner said, they said the 60 percent of the AI companies’ [AI projects] that fail is because they don’t have enough data in a data lake. The fundamental of a data lake for AI, [is] to make it affordable when you’re a startup; there’s different models where you have the startup model and then you have the mature company model.
In the startup model, they have to do everything in the cloud because they don’t have time to create infrastructure, they don’t have time to buy, or money to buy, a data centre and all that stuff. So they do everything in the cloud, which creates a huge hurdle for them. The failure rate is high, but for a mature company you can say, if I have this huge data lake in the cloud, and I have to recall that all that data, put it in a fast environment, you run into the egress fees and you can’t keep all that compute and a fast storage app in the cloud.
They can’t just keep growing that, and never retiring it to cold storage, because you can’t afford that. So my fundamental thing about Quantum is; our playbook should be the fastest primary storage and the cheapest store and everything in between to track all that data and move it from very fast to very cheap and start building IP around how we do that. How do we give visibility to the data? How do we index it, how do we track it? How do we put policies so that you can retire from expensive tier to a less expensive tier to a very cheap tier?
I just don’t think there are a lot of companies that have that. And it’s about leveraging the portfolio and changing the product strategy. And that’s the AI use case we can do and it resonates with the customer. I go to a customer, no one’s kicked me out, and in fact everybody’s there. We need ActiveScale cold storage and change our purchase behaviour so we can build our AI infrastructure.
I was at a big M&E customer, that has worldwide workflow, they’ve StorNext, they have ActiveScale cold storage. We talked about that. They want this AI environment which is in a private cloud so they can distribute assets and make them searchable, reusable across press, video, website, movies and all that stuff. That’s the AI strategy we play perfectly in, because we can be the core infrastructure under their AI. And once machines start generating data; I mean you’ve seen this, disk drives are having a second life, tape’s going to have to have a second life if you have an object interface in front of it.
Because the reality is people are going to run out of money. We’re just barely starting scratching the surface. So tape’s not just hyperscaler. It’s going to be you have to think about tape as, like in one rack, I have 20 petabytes , and you never have to open the darn thing.
… It’s huge and just one rack. So when you think about it, tape’s not about moving the cartridges anymore (off to Iron Mountain’s vault). It’s about how you can create a couple racks of tape and, there you go, 40 petabytes, 60, 80, it goes quickly, and it’s a pool of storage.
Now we’re putting disk and flash in front of it, in ActiveScale cold storage. So you have all the metadata in front of it, outside. So now it’s becoming this huge object store. If you can put policies around: “Hey, we’re doing this on the AI.” So precondition everything to disk or flash, put policies in front of it, [then] this becomes a huge powerful private cloud that has both flash and disk and tape, and then you can put super fast storage in front of it.
So I think for us, there are just so many things to do that we could do, just with the amount of technology we have.
B&F: And StorNext will be the natural piece of software to manage all this, provide policies and have your developments done on it later. How about Myriad? Is that still going to be a key part of Quantum going forward?
Hugues Meyrath: I think we’ve learned a lot from Myriad. I do have a plan. It’s not a public plan yet.
B&F: It has a future.
Hugues Meyrath: I’m not saying it has a future as is. … Myriad’s going to have to change one way or another. I think Myriad’s deployment model is very particular and it’s not lending itself to a quick insertion into a storage environment. You really need to have a different networking kind of environment. So I think there’s stuff we’ve learned from Myriad I’d like to apply, but I think in the end my vision for Quantum is to have one primary storage platform, not five that are finished.
B&F: You’ve managed to clean up the debt situation a lot as well.
Hugues Meyrath: Part of me coming on board is John (Fichthorn) and I bought the debt from Blue Torch Capital. … It was toxic and, frankly, there was a massive boat anchor for Jamie and the prior team. But we did that. We raised money on the public market, … [and] will convert the Dialectic debt into equity dilution. But, frankly, it is great because it’s kind of like the debt we have at Quantum is like bad credit card debt and how’d you get out of that credit card debt without restructuring it? You have to at some point. And I think we’re taking care of that and we’ve made difficult decisions in terms of reducing headcount mainly in non-product areas. And the point of reducing headcount was to match expenses to the revenue so we can actually generate cash and be EBITDA-positive. And that’s been the focus of me trying to figure out, okay, how do we get to be EBITDA -positive and generate cash for the business so it can be self-sustaining.
B&F:So you come on board and you clearly think Quantum has a good solid and profitable future ahead of it or you wouldn’t be talking to me at the moment.
Hugues Meyrath: I don’t need to work, Chris, I live at the beach and I have enough money. I’m not trying to be arrogant. I’m doing this because I have a connection. I have a 30 year connection. I came from Belgium with a black Samsung suitcase in 1994 on the six month, thousand dollars a month salary. And [one of my] first jobs was to work on Quantum heads for disk drives and tape drives, and get my little H1B and slog through it. And then I made my way through and I’m staring back at Quantum and I really genuinely do want to help. I mean, how do you not want to help a company that was your first customer and then where you worked? … I just really want to help and I think I can, I really do.
****
And we too hope that he succeeds at rebuilding amd re-energizing Quantum.
AI-powered data trust company Ataccama announced a native integration with Atlan, bringing Ataccama’s automated data quality intelligence directly into experiences powered by Atlan’s metadata lakehouse, including search, lineage, and glossary. Stewards define the rules in Ataccama, and data consumers see trust signals instantly in Atlan, reducing risk, accelerating decision-making, and building confidence in AI.
…
The CTERA Intelligent Data Platform is now available in the AWS Marketplace. It, CTERA says, “delivers a secure, compliant, and scalable data fabric across on-premises, cloud, and hybrid environments, offering centralized control, automated protection, and intelligent insights so enterprises can operate with agility, reduce risk, and unlock the full value of their data estate. … AWS customers can now access the CTERA Intelligent Data Platform and suite of Enterprise Data Services directly within AWS Marketplace, streamlining purchase, deployment, and management within their existing AWS accounts.”
…
Databricks plans to train 100k professionals in data and AI in the UK and Ireland by 2028 in generative AI, data engineering, machine learning, and analytics through Databricks’ in-person and self-paced programmes. As part of Databricks Free Edition, a global data and AI education programme aimed at closing the industry-wide talent gap, more than $10 million will be invested in the UK and Europe to provide free access to the Databricks Data Intelligence Platform. Databricks is involved in the UK’s Department for Science, Innovation and Technology’s (DSIT) “Get Tech Certified this Autumn” programme, and has partnered with UK & Irish universities including London School of Economics (LSE) and University College Dublin to equip students with in-demand data and AI skills.
…
dbt Labs announced it is open-sourcing MetricFlow with an Apache 2.0 licence. “This marks a significant step towards advancing trustworthy AI across enterprises and comes as the company has committed to the Open Semantic Interchange (OSI), a joint initiative led by industry leaders aimed at creating vendor-neutral standards for semantic data exchange across analytics platforms and AI tools. … MetricFlow is the core engine that compiles metric definitions into the code that computes them, and, unlike text-to-SQL methods, that computation is explainable and reliable every time. … uses information from semantic model and metric YAML configurations to construct and run SQL in a user’s data platform, providing governed metrics.”
…
EnterpriseDB has added new capabilities to EDB Postgres AI giving enterprises faster, simplified paths to achieve hybrid data sovereignty.
EDB is expanding Agent Studio’s tool functionality with native Model Context Protocol (MCP) support, giving instant access to hundreds of pre-built MCP servers
Enhancements to the migration experience help enterprises leave limited legacy and cloud systems behind for open solutions that accelerate sovereign AI goals. There is an AI copilot for Oracle modernizations, support for AWS Aurora migrations and improved migration guidance and monitoring.
EDB PG AI now delivers secure, flexible deployment across cloud, on-premises, and hybrid environments – achieving sovereign control.
…
Target backup device supplier ExaGrid announced its v7.4.0 release includes new features optimal for Managed Service Providers (MSPs) who use ExaGrid Tiered Backup Storage to protect their customers’ data. MSPs can store multiple customers in a single ExaGrid system can use ExaGrid with over 25 backup applications including Veeam, Rubrik, Commvault, NetBackup, HYCU, Cohesity (in 2026), Oracle RMAN Direct, SQL Dumps Direct and many others.. The new features will help MSPs track their customers’ data usage and separately provide the ability to restore an individual customer’s data in the case of a ransomware attack.
…
Data orchestrator Hammerspace demonstrated its Tier 0 architecture at Oracle AI World 2025, Las Vegas. With Tier 0, Oracle Cloud Infrastructure (OCI) Supercluster – a bare metal GPU server cluster – operates with ultra-high-performance shared storage, helping to reduce bottlenecks and minimize GPU idle time. By transforming existing local NVMe storage in OCI GPU shapes into a persistent, ultra-fast shared storage tier, Hammerspace eliminates data silos and unifies storage, unlocking a new level of efficiency and performance for AI workloads.
Benchmark testing in OCI showed:
Up to 7x improvement in latency vs. traditional cloud file storage.
Up to 6x improvement in storage performance vs. traditional cloud file storage.
Checkpointing at extreme speeds, crushing idle time.
Throughput so fast it keeps GPUs fed 24/7, not waiting on data.
Policy-driven flexibility to move cold data to lower-cost tiers without touching the hot path.
…
IBM and Nvidia are working together to bring Nvidia cuDF to the Velox execution engine, enabling GPU-native query execution for widely used platforms like Presto and Apache Spark. This is an open project. Get info here. IBM Fusion HCI announced support for the Lenovo SR675V3 3U rack-mount server with support for the Nvidia RTX PRO 6000 Blackwell Server Edition GPUs and H200 NVL PCIe GPUs. Get more detail here.
…
Index Engines released findings from an independent study that reveals a gap between cyber resilience awareness and actual preparedness to respond and recover from cyberattacks. Conducted by theCUBE Research and based on insights from 600 IT and cybersecurity professionals across North America, Europe, and APAC, the research in this eBook highlights a troubling reality: while most organizations recognize cyber resilience as a business imperative, few are equipped to recover when—not if—a cyberattack occurs.
…
InfluxData announced that InfluxDB 3, its time series database, is available as a fully-managed service on Amazon Timestream for InfluxDB, now the default time series database in the AWS Console. Developers can run InfluxDB 3 Core (open source) and InfluxDB 3 Enterprise directly on AWS. Users of AWS’ time series offering, LiveAnalytics (now closed to new customers), can migrate to InfluxDB 3 immediately.
…
Informatica announced an expanded partnership with Oracle to help customers unify and govern trusted master records to accelerate agentic development. §Some details:
Blueprint for Agentic AI on Oracle Cloud Infrastructure (OCI) – A framework that runs on Oracle Cloud, with no-code, pre-built connectors, recipes and an API layer to speed agent development.
IDMC MCP Server Support – A dedicated server within Informatica’s Intelligent Data Management Cloud (IDMC) platform that lets enterprise agentic AI projects access IDMC’s data management capabilities, via the industry-standard MCP protocol.
Master Data Management (MDM) Capability on OCI – Native availability of Informatica MDM SaaS on OCI providing trusted data from any business domain with enterprise-grade security, performance and cloud-native efficiency.
Informatica’s IDMC on Oracle Dedicated Region Cloud@Customer (DRCC) – This enables customers to run the entire IDMC platform, including MDM, data governance, and other IDMC services in a private environment that meets regulatory and data-residency requirements.
…
MemVerge and XConn Technologies unveiled a 100 TiB CXL memory pool for KV Cache, integrated with Nvidia Dynamo at the OCP Global Summit,, demonstrating how CXL-based memory pooling boosts AI inference performance by more than 5x compared to SSDs. The duo showed how scalable CXL memory architecture—powered by XConn’s hybrid CXL/PCIe Apollo switch and MemVerge’s GISMO software—offers a commercially available, high-performance system for the next generation of AI workloads. The joint demo illustrated how MemVerge’s Global IO-free Shared Memory Objects (GISMO) technology enables Nvidia’s Dynamo and NIXL to tap into huge CXL memory pool (up to 100TiB in 2025) and serve as the KV Cache store for AI inference workloads, where prefill GPUs and Decode GPUs work in synchrony to take advantage of the low latency and high bandwidth memory access to complete the computing.
…
Reuters reports Micron is stopping selling its DRAM chips for data center servers inside China. It will continue to sell chips to auto and mobile phone sector customers China. The Chinese government forbade the use of Micron’s chips in critical infrastructure in 2023. Micron will continue selling chips to China’s Lenovo and one other Chinese customer (Huawei?) that have data center businesses outside China. Some 12% of Micron’s revenues came from sales inside China in its last financial year.
…
Mirantis announced the release of Pelagia, an open source Kubernetes controller for lifecycle management of Ceph software-defined storage. It works alongside Rook to add needed lifecycle automation and a simplified control plane for large-scale environments. Pelagia comes from the Mirantis OpenStack for Kubernetes (MOSK) product, which for more than five years, was used to deploy and manage large production Ceph clusters where reliability was critical. Pelagia is available now under an open source license. Quick start instructions are availablehere. For more information, join the user community discussion group on GitHub.
…
Kristine Sedum.
NetApp announced a multi-year partnership with The San Francisco 49ers to provide data science education to high school students in the Bay Area. This will essentially allow the 49ers and NetApp to use Levi’s Stadium as a classroom and is part of the 49ers EDU Data Analytics Lessons Series that’s already reached 500K students. 49ers EDU educators will teach data storage, cloud integration, data security, and performance optimization, with NetApp volunteers mentoring on tech careers (fostering the pipeline from classroom to real-world scenarios). The 49ers Foundation received a NetApp Customer Social Impact Award due to this partnership at NetApp INSIGHT 2025.
…
NetApp appointed Kristine Wedum as VP, US Partner Organization. Wedum previously held related roles at Pure Storage (8 years), Proofpoint, Tufin, and Brocade.
Alex Dunfey.
M&E industry storage software supplier OpenDrives has promoted Alex Dunfey to CTO from his former position as SVP of Engineering. This coincides with the soft launch of Astraeus, OpenDrives’ new cloud-native data services platform announced in September. Dunfey said: “Future updates to Astraeus will add new data services, simplify workflow management, and leverage AI for insights and automation, which means we have to evolve the way we operate to do that. Download an Astraeus white paper here.
…
William Blair analysts Sebastian Naji and Jason Ader noted: “This week we attended Oracle’s 2025 AI World conference and financial analyst session. The focus this year was not only on the sea-change impact of AI across the technology landscape, but also on Oracle’s advantage in monetizing the AI platform shift through its vertical integration of infrastructure, database, and apps. While OCI is the primary driver of growth over the next five years (growing at a 75% compound annual rate), the ability for customers to leverage vectorized data inside the Oracle database and the integration of AI agents across all of Oracle’s applications (from Fusion to vertical apps) should also serve as key levers of growth.”
…
Oracle is vectorizing everything in its database so that its customers can use Oracle database records in their RAG AI workloads. The Oracle AI database can take data in the database, OCI object store, or AWS or google cloud storage, and vectorize it for AI models such as Grok, ChatGPT, Llama, or Gemini. Watch Oracle chairman and CEO Larry Ellison’s keynote presentation from OracleAI World here.
Video grab from Larry Ellison’s keynote presentation from OracleAI World.
…
PingCAP unveiled TiDB X, a new architecture for its distributed SQL database, and announced a suite of Generative and Agentic AI innovations:
TiDB X: A new distributed SQL architecture that makes object storage the backbone of TiDB. By truly decoupling compute and storage, TiDB X enables TiDB to scale intelligently, adapting in real time to workload patterns, business cycles, and data characteristics.
Smarter Retrieval & Reasoning: A unified query engine that fuses vectors, knowledge graphs, JSON, and SQL for richer, multi-hop queries and deeper insights. Enables long-term memory with versioned, branchable storage.
AI Developer Toolkit: New building blocks for GenAI, including the TiDB AI SDK, TiDB Reasoning Engine, and TiDB MCP Server, empowering developers to quickly build and scale agentic workflows.
LLM Integrations: Out-of-the-box support for OpenAI, Hugging Face, Cohere, Gemini, Jina, Nvidia, and more, making TiDB the most open and flexible distributed SQL platform for AI builders.
TiDB X and the new GenAI capabilities will be available across all TiDB Cloud tiers in late 2025, including Starter, Essential, and Premium, with BYOC (Bring Your Own Cloud) coming soon. To learn more or request early access, visit https://www.pingcap.com/product/cloud.
…
Red Hat announced Red Hat AI 3, with the latest versions of Red Hat AI Inference Server, Red Hat Enterprise Linux AI (RHEL AI) and Red Hat OpenShift AI. It makes it possible to rapidly scale and distribute AI workloads across hybrid, multi-vendor environments while simultaneously improving cross-team collaboration on next-generation AI workloads like agents, all on the same common platform.
It introduces the general availability of llm-d, which reimagines how LLMs run natively on Kubernetes. llm-d enables intelligent distributed inference, tapping the proven value of Kubernetes orchestration and the performance of vLLM, combined with key open source technologies like Kubernetes Gateway API Inference Extension, the Nvidia Dynamo low latency data transfer library (NIXL), and the DeepEP Mixture of Experts (MoE) communication library. Learn more here.
…
Riverbed, which supplies AIOps for observability and data acceleration, introduced its SaaS-based Data Express Service built on Oracle Cloud Infrastructure (OCI) and designed to move petabyte-scale datasets up to 10x faster than traditional offerings. Petabyte-scale datasets can now be moved in days instead of months, dramatically accelerating AI model training and deployment. The service uses post-quantum cryptography (PQC) to move petabyte-scale datasets through secure VPN tunnels to ensure that customer data remains protected during the transfer process. The service includes enterprise-grade controls for secure access to data as well as the option to deploy data mover agents in customer tenants to enable additional security controls. Get a Solution Brief here.
…
The Sandisk PCIe Gen 5 SN861 NVMe SSD is now featured on the OCP Marketplace.
…
Object storage supplier Scality announced an exceptional Net Promoter Score (NPS) of 85 across its RING and ARTESCA products. It says that, iIn the standardised NPS model, any score above 30 is considered strong, above 70 is excellent, and above 80 is exceptional. With an industry average NPS for data storage solution vendors typically ranging between 40 and 50, Scality’s 85 score places it among the top-performing technology vendors worldwide. The score is based on ratings collected directly from customers following interactions with Scality’s support and customer-success teams.
…
SK hynix revealed a PS1101 SSD wih 245 TB capacity and a PCIe gen 5 connection in the E3.L format at a Dell Technologies forum event in Seoul, Korea. It uses QLC NAND and a 321-layer 3D NAND chip. The drive could ship in 2026. SK hynix says it’s continuing its journey to becoming a full-stack AI memory provider.
SK Hynix display panel showing PS1101.
…
SK hynix is offering some scary good deals on select SSDs during a limited-time promotion available on Amazon, now through October 26:
SK hynix Platinum P41 1TB – Now $71.99 (was $79.99) → 10% off
SK hynix Tube T31 2TB – Now $118.98 (was $159.99) → 26% off
…
Open data lakehouse Starburst has a new set of capabilities designed to operationalize the Agentic Workforce. It says that, with new, built-in support for model-to-data architectures, multi-agent interoperability, and an open vector store on Iceberg, Starburst delivers the first lakehouse platform that empowers AI agents, with unified enterprise data, governed data products, and metadata, empowering humans and AI to reason, act, and decide faster while ensuring trust and control.
Starburst gives AI agents secure, governed access to data wherever it resides, on-premises or in the cloud, at enterprise scale. This federated, model-to-data approach helps organizations maintain sovereignty, reduce costs, and avoid compliance pitfalls, especially in highly regulated industries or cross-border environments. Read a blog here. The enhancements:-
Multi-Agent Ready Infrastructure: A new MCP server and agent API allows enterprises to create, manage, and orchestrate multiple AI agents along-side the Starburst agent. This enables customers to develop multi-agent and AI application solutions that are geared to complete tasks of growing complexity.
Open & Interoperable Vector Access: Starburst unifies access to vector stores, enabling retrieval augmented generation (RAG) and search tasks across Iceberg, PostgreSQL + PGVector, Elasticsearch and more. Enterprises gain flexibility to choose the right vector solution for each workload without lock-in or fragmentation.
Model Usage Monitoring & Control: Starburst offers enterprise-grade AI model monitoring and governance. Teams can track, audit, and control AI usage across agents and workloads with dashboards, preventing cost overruns and ensuring compliance for confident, scalable AI adoption.
Deeper Insights & Visualization: An extension of Starburst’s conversational analytics agent enables users to ask questions across different data product domains and provide back a natural language response in natural language, a visualization, or combination of the two. The agent is able to understand the user intent and question to do data discovery to find the right data before query processing to answer the question.
…
Synology announced DSM 7.3, which includes significant updates to our third-party hard drive support policy. This new release restores support for third-party drives across the 2025 DiskStation Plus, Value, and J Series models, allowing installation and storage pool creation without the previous restrictions.
DSM 7.3 introduces Synology Tiering, automatically moving files between high-speed and cost-effective storage based on actual use, maximising storage value and performance.
Security enhancements include adoption of industry-recognised risk indicators — KEV, EPSS, and LEV — for smarter threat prioritisation and stronger protection against emerging vulnerabilities.
The Synology Office Suite has been upgraded to improve team workflows. With Synology Drive, users can now add shared labels and create smarter file requests.
MailPlus now enables email moderation and domain sharing for unified identities.
The AI Console introduces custom data masking and filtering, allowing users to safeguard sensitive information locally before transmitting data to third-party AI providers, enhancing both security and workflow reliability.
Storage flexibility has been expanded, with 2025 DiskStation Plus, Value, and J Series models permitting installation and storage pool creation using third-party drives (M.2 pools still require validated models).
…
VDURA CEO Ken Claffey has written a blog about NetApp’s AFX, using it as an example to support his point that the general purpose AI storage era is ending. Hesays NetApp positions AFX as highly capable for AI, with claims of up to 4 TB/s throughput and strong enterprise integration. AFX inherits ONTAP’s strengths in enterprise controls but also its constraints in areas like scaling mechanics, data protection, performance, and hardware efficiency.
AFX achieves up to 4 TB/s cluster throughput (reads) and scales to over 1 EB, which is respectable for feeding GPU clusters via standard protocols like NFS/pNFS. This peak requires up to 128 2 RU AFX 1K controller nodes, equating to about 31 GB/s reads per controller node (4 TB/s ÷ 128), plus 2 RU NX224 NVMe HA enclosures and 100GbE switches. He reckons the total rack space needed would be 512RU.
VDURA delivers over 60 GB/s reads and 40 GB/s writes per 1 RU standard server node in comparable configs, with its shared-nothing design that avoids legacy controller bottlenecks. A 67 node (67 RU) VDURA config would deliver 4 TB/s. Read much more in his blog.
…
SW RAID supplier Xinnor with MEGWARE, Celestica, and Phison, enabled Germany’s most powerful university-owned AI supercomputer at NHR@FAU to achieve the #3 position in the global IO500 benchmark rankings and #1 among Lustre-based solutions. The Helma supercomputer at Friedrich-Alexander-Universität Erlangen-Nürnberg’s National High-Performance Computing Center (NHR@FAU) combines 192 dual-socket AMD EPYC 9554 “Genoa” compute nodes with 768 Nvidia H100/H200 GPUs, ranking #51 on the June 2025 TOP500 list. The storage infrastructure, designed and built by MEGWARE using Celestica SC6100 systems with Phison Pascari drives and protected by Xinnor’s xiRAID Classic 4.2, delivered breakthrough performance metrics that established new benchmarks for high-availability NVMe storage in academic HPC environments. Read the case study here.
Seagate and ZeroPoint Technologies demonstrated hardware-accelerated compression within a CXL memory tier at the OCP Global Summit in San Jose, CA.
How could disk drive supplier Seagate utilise ZeroPoint’s HW-accelerated memory compression technology within Compute Express Link (CXL) memory tiers? Is it envisaging a JBOD chassis, full of Exos disk drives, with a CXL memory tier in its controller?
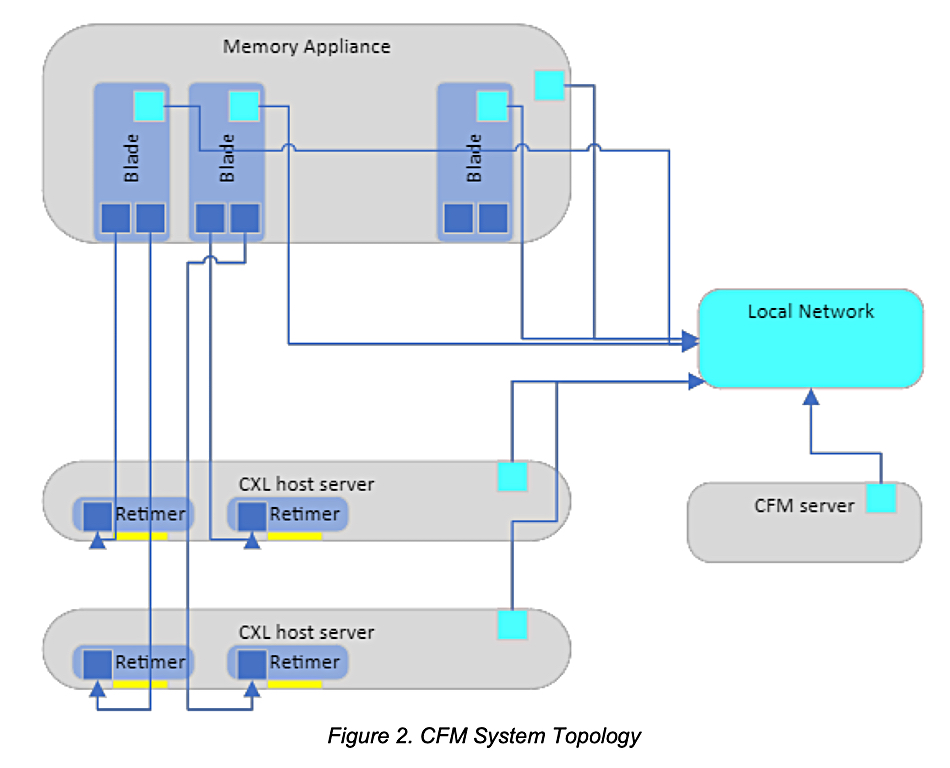
It turns out that Seagate is developing a Composable Memory Appliance (CME) and it ran a Multi-Headed Composable Memory Appliance Next-Gen session at the OCP summit. We understand that this refers to a rack-mounted CMA appliance connected to and supporting multiple accessing end-points simultaneously and using CXL memory technology.
Seagate has developed a Composable Fabric Manager (CFM) for its CMA device, with code available on Github. This “provides a client interface for interacting with a Composable Memory Appliance. It provides a north-side (frontend) OpenAPI interface for client(s) and a south-side (backend) Redfish interface to manage available Composable Memory Appliances (CMAs) and CXL Hosts.”
Seagate CFM document.
A Composable Memory Fabric Management Software and APIs Architecture document, authored by Seagate staff, is available on the OCP website. This “defines the minimum APIs used for managing composable memory fabric system backed by OCP-compliant composable memory appliance[s].” The CMA is “a scalable memory device based on CXL technology.”
The document says: “A memory appliance contains multiple memory blades, and each blade can individually connect to multiple CXL host servers.”We understand the CMA acts as a CXL Type 3 memory expander, allowing connected servers to access the shared, scalable memory resources over a CXL fabric rather than relying solely on local DRAM.
The ZeroPoint DenseMem technology is used to create compressed memory tiers, boosting capacity by 1.85x to 2.25x and so cutting DRAM costs.
The document does not specify the persistent storage devices to which the memory blades are attached, be they Seagate Nytro SSDs or Exos HDDs. We have asked Seagate and it replied: “As this is not a product release but more of a research effort exploring the possibilities around Memory disaggregation there is nothing much we can add at this time on the top of what was issued in Zeropoint press release”.
ZeroPoint says its DenseMem technology “increases effective CXL Type 3 Device memory capacity by a factor of 2-3x through transparent, in-line memory compression/decompression with minimal impact to latency and bandwidth. DenseMem is available as an area and power efficient drag and drop IP block portable across the latest process nodes.”
In other words, it gets incorporated into a CMA device controller chip.
DenseMem can be integrated into the CXL Type 3 device SoC, between the CXL controller and memory controller logic blocks. It provides a compressed memory tier instantiated automatically inside a CXL Type 3 device, featuring real-time compression/decompression coupled with compaction, and transparent memory management. Operations take place at main memory speed and throughput.
As we understand it, an external JBOF would currently send data to a GPU server via NVMe and RDMA. By using this CMA tech, a Seagate JBOF, or JBOD, could communicate with it by using CXL memory pooling and sharing, which would have a lower latency. Bandwidth would be raised by having multiple CMA devices.
The loading of data from the CMA’s persistent storage into its CXL memory would effectively be caching, we assume, with large items sharded across drives to increase bandwidth at this level
Long-lived and near-silent malware lurking in systems for months can be detected by looking for signs of their presence in a historical stream of immutable backups.
Rubrik found evidence of long-lived Chinese nation-state level malware code in its immutable backups using updated threat intelligence
The company was alerted by Google Threat Intelligence (with Mandiant) to the details of BRICKSTORM, a stealth backdoor used by the UNC5221 China-nexus threat cluster. The Rubrik Zero Labs organization then tested Rubrik’s backup system against UNC5221.
It noted that traditional EDR (End-point Detection and Response) systems often do not or cannot run on hardened appliances like VMware vCenter Server Appliances (VCSA), firewalls, VPNs, and other Linux/BSD-based network devices. A Zero Labs team blog says: “Sophisticated threat actors are deploying silent, elusive malware that bypasses EDR tools and hides dormant in backups or embedded deep within critical infrastructure.”
UNC5221 uses a BRICKSTORM backdoor, and this evades such EDR systems by, for example, changing its filename to match a legitimate VCSA process (e.g., vami-httpd) and runs from a trusted directory, allowing it to execute undetected where EDR is set to trust system binaries implicitly. It uses SOCKS proxying and minimal network noise, generating network activity that blends structurally with normal VCSA traffic.
Once inside a system, BRICKSTORM can linger undetected for months, even longer than a year.
Rubrik’s cyber-resilience software carries out daily scans of “over 2.3 million snapshots, looking for active and dormant threats—not only within active environments, but also within immutable backup data.” Its secured backups are immutable and the backup data repository is a reliable, historical record of the system state.
The scans are updated with new malware information and, Rubrik says, they can “confirm a compromise within EDR-blind appliances, isolate the malicious code, and establish the definitive breach timeline.”
We’re told that: “when BRICKSTORM indicators (like specific file hashes, YARA signatures, or suspicious file paths on a vCenter server) were found in a customer’s backups, customer data analysis allowed for:
Early Detection: Catching threats missed by conventional EDR.
Contextual Intelligence: Detailing the threat actor’s modus operandi, including their initial perimeter breach and lateral movement tactics to vCenter.
Actionable Guidance: Equipping customers with the precise steps for containment, threat eradication, and crucially, ensuring a clean recovery from their backups.
Rubrik says a 3-stage approach is needed:
Threat Confirmation: Use targeted IOC scanning (YARA signatures, specific file hashes—see Appendix) against historical snapshots to validate the threat and determine the precise moment of compromise.
Clean Recovery: The compromised appliance must not be restored. A new VCSA instance must be built from a trusted source, with the configuration selectively restored only from the latest known-clean snapshot.
Proactive Defense: Enhance logging and monitoring on all appliance blind spots, and enforce strict administrative controls (MFA, network segmentation) to prevent credential-based lateral movement.
It states: ”This integration of active threat intelligence with immutable data defense represents a required evolution in cyber resiliency architecture.”
Security professionals should use immutable backup scans to detect this kind of persistent, EDR-evading malware threat and then help customers recover from it and clean their systems.
Bloomberg has just reported that US cyber-security provider F5 was breached by state-backed hackers from China who used BRICKSTORM malware to infiltrate its network for 12+ months and steal source code.
Bootnote
SOCKS is an Internet protocol that exchanges network packets between a client and server through a proxy server. A SOCKS proxy is an SSH tunnel down which specific applications forward their traffic to the server, and then on the server end, the proxy forwards the traffic out to the general Internet.
CoreWeave’s AI Object Storage service shifts object data around the world at high speed, using Local Object Transport Accelerator (LOTA) technology, with no egress or request/transaction/tiering fees.
It says high-performance AI training relies on large datasets located near GPU compute clusters, like the ones in its GPU server farms. CoreWeave reckons conventional cloud storage isn’t engineered for the level of throughput or flexibility needed, leaving developers constrained by latency, complexity, and cost. Its LOTA tech makes a single dataset instantly accessible, anywhere in the world.
Peter Salanki.
Co-Founder and CTO at CoreWeave Peter Salanki says: “We are rethinking storage from the ground up. We’ve built a system where data is no longer confined by geography or cloud boundaries, giving developers the freedom to innovate without friction or hidden costs. This is a truly game-changing shift in how AI workloads operate.”
Game-changing? Probably yes for CoreWeave customers.
CoreWeave says its AI Object Storage performance scales as AI workloads grow, “and maintains superior throughput across distributed GPU nodes from any region, on any cloud, or on-premises.” It has a multi-cloud networking backbone with private interconnects, direct cloud peering, and 400 Gbps-capable ports to provide this throughput. The throughput is up to 7 GBps per GPU and it can scale to hundreds of thousands of GPUs.
The AI Object Storage service has three automatic, usage-based pricing tiers that “provide more than 75 percent lower storage costs for our existing customers’ typical AI workloads” which makes it “one of the most cost-efficient, developer-friendly storage options in the industry.”
Hot: Accessed in the last 7 days
Warm: Accessed in the last 7-30 days
Cold: Not accessed in 30+ days
Holger Mueller, VP and Principal Analyst at Constellation Research, said; “Leveraging technologies like LOTA caching and InfiniBand networking, CoreWeave AI Object Storage ensures GPUs remain efficiently utilized across distributed environments, a critical capability for scaling next-generation AI workloads.”
LOTA details
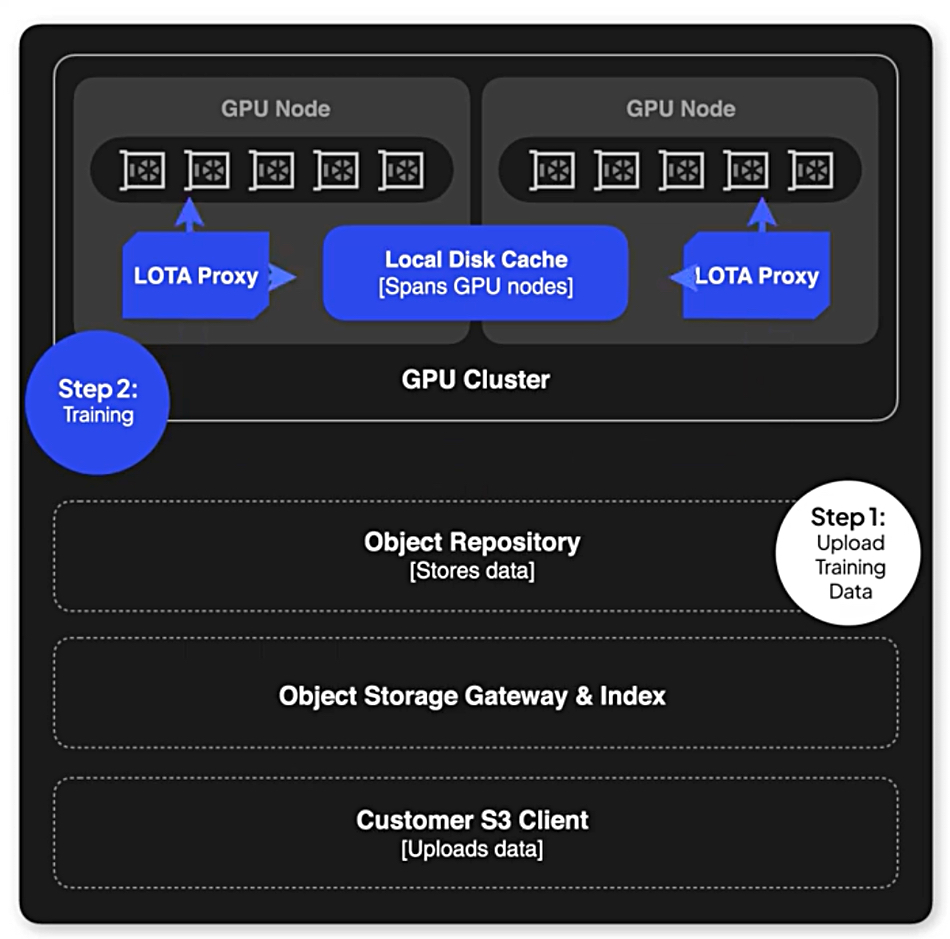
CoreWeave’s Local Object Transport Accelerator (LOTA) is an intelligent proxy installed on every GPU Node in a CKS (CoreWeave Kubernetes Service) cluster to accelerate data transfer. LOTA provides a highly efficient, local gateway to CoreWeave AI Object Storage on each node in the cluster for faster data transfer rates and decreased latency.
From the user point of view; “with LOTA, software clients can easily interact with CoreWeave AI Object Storage through a new API endpoint. Clients only need to point their requests to the LOTA endpoint [http://cwlota.com] instead of the primary endpoint [https://cwobject.com], with no other changes required to S3-compatible clients.”
We’re told by CoreWeave that “LOTA proxies all object storage requests to the Object Storage Gateway and storage backend. First, LOTA authenticates each request with the gateway and verifies proper authorization. Then, when possible, LOTA bypasses the gateway and directly accesses the storage backend to fetch objects with the greatest possible throughput. LOTA stores the fetched objects in a distributed cache to significantly boost data transfer rates, especially for repeated data requests.”
When LOTA uses the direct path to bypass the Gateway and access the object directly, data transfer rates improve significantly. By storing the data in a distributed cache, LOTA ensures that frequently accessed objects are readily available for quick retrieval.
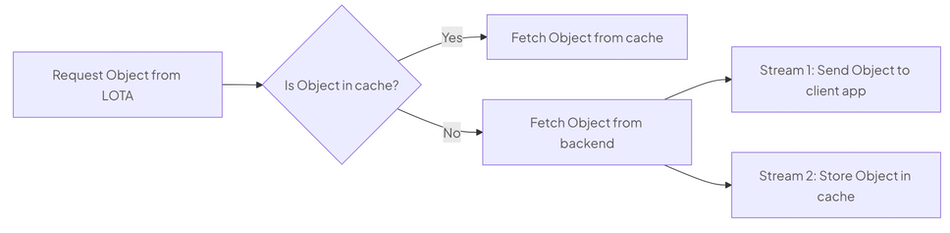
LOTA actively caches recently accessed objects on the local disks of GPU Nodes – tier 0 as Hammerspace would say, significantly reducing latency and boosting read speeds for CoreWeave AI Object Storage. The following diagram illustrates the process flow when fetching an object using LOTA;
When a request is made to LOTA, it first checks if the object is available in the cache. If the object is found, it’s fetched directly from the cache, ensuring minimal latency.
If the object is not in the cache, LOTA fetches it from the backend storage (whether or not the backend resides in the same Availability Zone as LOTA) and forks it into two pathways:
Stream 1 sends the object to the client application.
Stream 2 stores the object in the cache, using local storage on one or more GPU nodes.
This dual-pathway approach—implemented as two concurrent data streams—ensures that future requests for the same data are served quickly from the cache, enhancing overall performance. LOTA distributes the cache across all GPU Nodes in a CKS cluster, ensuring efficient data retrieval and management.
CoreWeave has 28 operational regions spread across the USA, two in the UK, and three in mainland Europe – Norway, Sweden and Spain. Regions are interconnected with high-speed dark fiber. LOTA acceleration will expand to other clouds and on-premises environments in early 2026.
There’s an Object Storage service blog here. See here for more information about LOTA. For a deeper detailed look go here. Basic info on CoreWeave storage can be found here.
CoreWeave recently announced ServerlessRL, the first publicly available, fully managed reinforcement learning capability. And it has a deal with Poolside, a foundation model company, to deliver AI cloud services that support Poolside’s mission to build artificial general intelligence and power the deployment of agents across the enterprise.
Under the agreement, CoreWeave will provide a state-of-the-art cluster of Nvidia GB300 NVL72 systems, including more than 40,000 GPUs. Separately, CoreWeave plans to provide Poolside with its market-leading cloud solutions for Project Horizon, Poolside’s 2GW AI campus in West Texas. As part of the initiative, CoreWeave plans to serve as the anchor tenant and operational partner for the first phase of the project, which comprises 250MW of gross power and includes an option to further expand capacity by an additional 500MW.
HPE storage is doing so well that HPE is publicly reporting its numbers again as part of an AI-focussed financial reporting revamp, with Alletra Storage MP taking the lead role.
This was revealed at a Securities Analyst Meeting it held in New York on October 15, to convince the analysts to recommend HPE shares to their clients. CEO and President Antonio Neri said the company has five strategic priorities: build a new networking industry leader – with acquired Juniper helping; capture profitable growth in the AI infrastructure market with a focus on sovereign and enterprise customers; accelerate high-margin software and services growth through GreenLake; capitalize on unstructured data market growth with its own IP through Alletra MP; and transition customers to next-generation server platforms.
The drivers here include, of course AI, and that is boosting networking and the cloud business model. HPE used to have its own storage IP; remember acquired 3PAR and Nimble and SimpliVity? The 3PAR line became Primera and this then evolved to the Alletra brand which included the old Nimble arrays. But HPE sold a lot of its ProLiant servers running other supplier’s software-defined storage; think Nutanix for example.
Neri had HPE’s financial reporting drop public exposure of its storage revenues at the end of its fy2023 year, with that number subsumed into its Hybrid cloud business. Then along came VAST Data, with its disaggregated and separately scalable compute and storage based on all-flash NVMe storage enclosures and fast internal networking.
HPE responded and introduced its Alletra Storage MP system in April 2023 with block and file storage supported. There were ProLiant-based controllers (compute) and separate storage nodes. It actually OEM’d the file storage SW from VAST. HPE introduced its own object storage SW in November 2024.
The Alletra Storage MP system prompted a renaissance in HPE storage sales, with it recording triple-digit year-over-year growth for the third consecutive quarter in September this year. HPE claimed it has the second largest share of the primary block all-flash array (AFA) market, based on IDC numbers. HPE’s the third overall AFA supplier, behind Dell and NetApp.
Neri and his execs are seeing AI driving an enormous change in the IT system supplier business, boosting demand for GPU servers and pulling along networking and storage behind it. As a consequence, it’s revising its public financial reporting which has had, up until now, been structured as Server, including HPC and AI, Networking, Hybrid Cloud, Financial Services and Other.
Now we have Cloud and AI as the top segment, with Campus & Branch, DataCenter Networking, Security, and Routing as the sub-segments. Analysts were provided with backdated numbers to Q1 fy2024 and that’s allowed us to chart HPE’s recent revenue history with a separate storage line;
We can readily see the boost to its revenues from the AI-led server boom with storage paralleling at a lower revenue number and less pronounced rises. HPE’s customers are buying servers for AI processing but storage sales are lagging behind. The customers are not yet storing significantly more unstructured data (file and object) for AI inferencing or training.
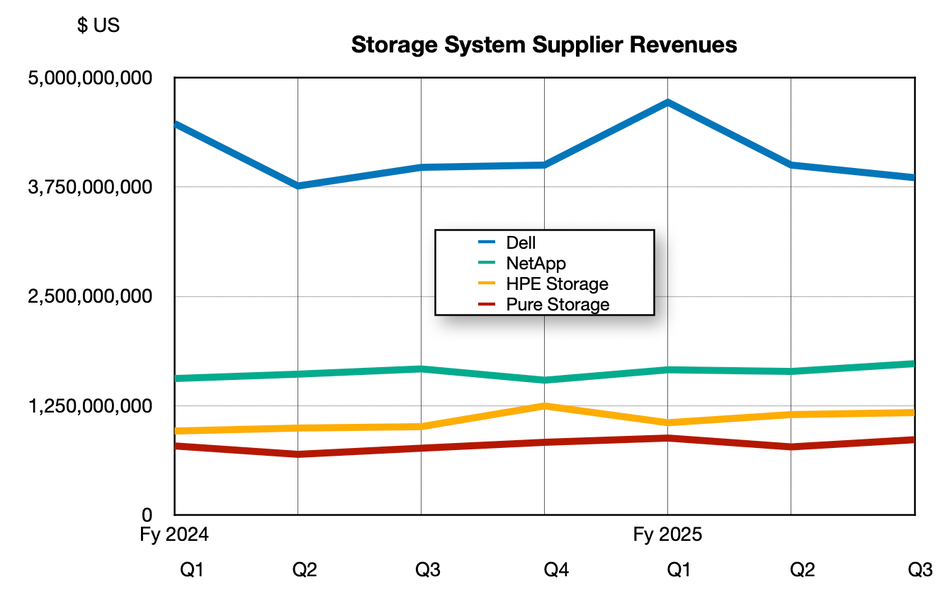
However HPE Alletra storage sales are rising and Neri and his team want to capture more storage sales using HPE’s own intellectual property. We charted Dell storage, HPE storage, NetApp and PureStorage revenues, using HPE’s newly-revealed numbers;
We can see that Dell sales are trending down, NetApp and HPE and Pure – look closely – are rising.
Our understanding is that HPE will be selling storage as part of an overall AI system sale, led by servers and networking. NetApp and Pure don’t have the advantage of a server- and/or networking-led sales motion. We would think that their storage has to stand out, with clear advantageous differentiation, to overcome an inherent coupling of storage as an ancillary to server/networking AI system sales. Building their own disaggregated architecture along with an AI data pipeline SW stack on their storage software base is one way to do it.
NetApp (AFX) and Pure (FlashBlade//EXA) have both introduced their own disaggregated compute and storage node architectures, and AI pipeline software stacks. We think Dell will do something as well.
A final question; can HPE storage grow fast enough to withstand Pure’s growth and overtake NetApp? We’ll see. These are interesting times.
DAOS is the now-unwanted parallel file system offspring of Intel, back in its Optane era, and now, with its high performance is being resuscitated by Enakta Labs and other members of the DAOS Foundation.
We wrote about DAOS, the Distributed Asynchronous Object Store software, back in April, noting that DAOS Foundation was set up in late 2023 by DAOS user Argonne National Lab, Enakta Labs, Google, HPE (the Cray part), and Intel, with VDURA joining last year. We mentioned that the Aurora DAOS system in Optane mode won the top IO500 Production Overall Score slot in 2023, putting out 1.3 TBps bandwidth. Clearly DAOS has exceptional performance. Also that, as a result of Optane’s demise, DAOS had been re-architected to use fast SSDs for its metadata store and its performance was more or less the same.
Open-source DAOS, as a parallel file system, has to fight for attention amongst other parallel file system products, meaning heavyweights like Storage Scale (IBM’s much developed GFS) and Lustre, along with BeeGFS, Quobyte, and VDURA’s PanFS. These are all HPC-focussed and have quite widespread adoption, especially Storage Scale and Lustre, whereas DAOS, as we understand it, has limited adoption, with institutions that valued its high-performance and open-source-ness, as exemplified by its use in the Aurora supercomputer system.
These competing systems are also all responding to the enterprise need for AI workloads, with high-bandwidth file and object data feeds to GPU server systems. This brings them into contention with other Nvidia-validated storage suppliers, such as NetApp, Pure Storage, WEKA and VAST Data, not forgetting Dell and HPE. All of these HPC and enterprise fast storage suppliers are well-established and have substantial development and support teams, and marketing/PR budgets. DAOS has none of that, it being an orphan child.
What it does have is its exceptional performance, tech credibility, and its open-source nature.
Denis Nuja.
Denis Nuja is the founder of UK-based Enakta Labs and has an extensive Linux-related CV. We met him to discuss the state of DAOS and where it’s going. He said Enakta wants to commercialize DAOS; it has its Enakta Data Platform product based on it. Enakta has added support for S3, SMB, NFS, and, for AI workloads, PyTorch. As it supports block as well as file and object, we could look at DAOS as the new Ceph. A reference architecture has been opblished with collaboration from Kioxia and Supermicro.
Nuja thinks that potential DAOS adoptees include the neo-clouds and emerging sovereign clouds. Because DAOS is open-source there is no lock-in and, arguably, it has better bandwidth and latency numbers than competing software, meaning it can keep their vastly expensive GPU clusters busier than alternative storage software. Enakta can also offer direct, engineer-level support.
It can also save them money on their high-performance storage SW but, he ruefully said, their GPUs and their memory, their power and cooling costs were so extraordinarily high that savings of storage SW could be in the rounding error category. Performance, meaning latency and bandwidth is their key storage SW need, along with reliability, followed by responsive and expert support. Cost is a tail-end item.
We understand Enakta is benchmarking the latest version of its DAOS-based software on a half-billion dollar GPU cluster owned by a large cloud operator and that the preliminary results are impressive. We wonder if another IO500 run could be a possibility.
Nuja puts forward a view that a commercial, enterprise-ready version of DAOS could be built to run on commodity hardware and it could outperform even the world’s most powerful supercomputer storage systems. We’re talking about a bunch of Supermicro-class GPU servers with NVMe SSDs and running Linux. We think DAOS needs to demonstrate a substantial performance advantage to persuade potential customers to look away from the well-funded and smoothly-marketed operations characteristic of DDN, Pure, WEKA, VAST and so forth.
This makes us look forward to the upcoming Supercomputing 2025 conference (November 16-21 in St. Louis, MO ) where official IO500 benchmark results would be announced. The orphan could shine.
Parallel NFS-based data manager/orchestrator Hammerspace has selected the Xsight Labs E1 800G DPU to eliminate legacy storage servers from AI data storage.
Hammerspace claims this collaboration advances the Open Flash Platform (OFP) vision of a democratized, efficient, and radically simplified data storage infrastructure offering more than 10x storage density and 90 percent lower total cost of ownership. Its OFP concept replaces all-flash arrays with directly accessed SSDs in JBOFs that have a controller DPU, Linux, its parallel NFS (pNFS) software, and a network connection. Israel-based fabless semiconductor business Xsight Labs provides end-to-end networking technologies to support exponential bandwidth growth (e.g., up to 800G and 12.8T speeds) for cloud infrastructure, 5G, machine learning, and compute-intensive workloads.
David Flynn
David Flynn, Hammerspace CEO, says: “Legacy storage is collapsing under the weight of AI. By fusing our orchestration software with Xsight’s 800G DPU, we flatten the data path and turn every Linux device into shared storage. The result is an open architecture that scales linearly with performance, slashes cost, and feeds GPUs at the speed AI demands.”
The company says its OFP architecture redefines the data center by removing the traditional storage server, “the expensive middleman,” from the storage path. Instead, flash storage connects directly to the network using open standards such as Network File System (NFS) and Linux, creating a dramatically simpler and more enduring architecture.
Xsight E1 800G DPU chip
Hammerspace has selected Xsight’s E1 800G DPU to realize the OFP vision for the next generation of warm storage AI infrastructure. This required a DPU with the Arm core density, memory bandwidth, and 800Gbps Ethernet connectivity necessary for high-performance environments.
Xsight’s E1 800G DPU is an edge server for AI data center infrastructure and comes in the form of a PCIe Gen 5 add-in card or 1 RU edge server. It features:
800G DPU with 100 percent fast-path all-layer processing (no slow-path architecture – see bootnote)
64C x Arm N2s, TDP 90W, TSMC n5
8 x 112G SerDes allowing 2x400GE, 4x200GE, 8x100GE
Networking, security, storage, and compute (SDN model with hardware acceleration)
Arm System Level 6 Ready workload compatibility on all Linux distros
Xsight says there is no traditional slow-path and fast-path misalignment in the E1 – it has no slow path. This allows full line rate at 800G with no use of accelerators.
Ted Weatherford
Ted Weatherford, VP Business Development at Xsight Labs, said: “Hammerspace’s orchestration software allows every network element, regardless of memory size, to function as a flat layer zero storage node. The scalability and performance story here will set the pace for the entire AI industry. Hammerspace’s stack coupled with our E1 DPU – which is silently a full-blown Edge server – offers the performance leading warm-storage solution.
“The magic is we are fast-piping warm storage directly to the GPU clusters eliminating all the legacy x86 CPUs. The solution offers an exabyte per rack, connected directly with hundreds of giant Ethernet pipes, thus simplifying the AI infrastructure profoundly.”
What Hammerspace and Xsight are saying is that AI datacenters no longer need external storage arrays to hold training and inference data. They can use basic Linux-controlled JBOFs (just a box of flash) with component SSDs directly connected to GPU servers to save costs and power. It’s somewhat similar to messaging from Western Digital with its OpenFlex JBOFs, and Kioxia with its now abandoned Kumoscale product technology.
Early access deployments of the Xsight Labs E1 DPU, integrated with Hammerspace’s orchestration software, are underway with strategic partners. Limited volume shipments are planned to begin in Q4 2025 with production systems available early Q1 2026.
Bootnote
We understand that Hammerspace’s flattened AI warm storage architecture is optimized for AI workloads, particularly in hyperscale datacenters. There is a direct data path between GPUs and SSDs holding so-called warm data – frequently accessed, but not as often as active training (hot) datasets.
Xsight’s fast path and slow path concepts relate to the fast path being the high-speed, hardware-accelerated data plane optimized for line-rate processing of the data traffic. The slow path is the exception-handling or control plane path, managed by embedded software running on Arm cores (or similar) within the DPU. Misalignment occurs when the fast-path and slow-path are not synchronized in their configuration, state, or behavior.
Broadcom announced its third-generation Tomahawk 6 Davisson (TH6-Davisson) product, the industry’s first 102.4 Tbps co-packaged optics (CPO) Ethernet switch – double the bandwidth of any CPO switch available today. Broadcom claims Davisson is changing the game for AI infrastructure. By reducing link flaps and power consumption, it not only cuts costs, but enables faster, more reliable AI model training. This allows Broadcom customers to achieve higher MFU, fewer job failures, and greater cluster uptime, unlocking unprecedented value for both scale-up and scale-out AI deployments.
…
Broadcom announced Thor Ultra for AI Scale-Out networking, the industry’s first 800G AI Ethernet network interface card (NIC) engineered to deliver advanced RDMA for large-scale AI datacenters with over 100,000 XPUs. Compliant with the new Ultra Ethernet Consortium (UEC) capabilities, Thor Ultra delivers the performance, scalability and openness required for tomorrow’s scale-out AI clusters – without lock-in and with true interoperability.
RDMA is key to accelerating job completion in AI datacenters. However, traditional RDMA cannot keep pace with the demands of future AI workloads. It lacks Multipathing Support, cannot handle Out-of-Order Packet Delivery, and relies on slow retransmission methods like Go-Back-N, and uses Congestion Control mechanisms that are difficult to tune.
Thor Ultra introduces a suite of advanced RDMA features designed to meet the demands of next-generation AI workloads:
Packet-level multipathing for efficient load balancing.
Out-of-order data placement to XPU memory, maximizing PCIe link utilization.
Reliable packet delivery with hardware-based selective acknowledgment (SACK) and retransmissions.
Programmable congestion control to seamlessly adapt to future congestion management algorithms.
…
Ceramic-coated glass tablet archival storage startup Cerabyte showed early access media samples containing copies of the U.S. Constitution at the 2025 Open Compute Project (OCP) Global Summit, October 13-16 in San Jose, California. Watch this video to learn about Cerabyte’s progress in 2025.
…
Reuters reports that data streaming software supplier Confluent is looking for a buyer: “The software provider is working with an investment bank on the sale process, which is in its early stages and was instigated after both private equity firms and other technology companies expressed their interest to the company in buying it, the sources said… Some of the sources had told Reuters while Confluent’s technology is highly sought-after, it became vulnerable to takeover approaches when its stock price dived in July, when it reported losing business from a large customer.”
…
Data protector CrashPlan announced a strategic partnership with cloud storage supplier Wasabi Technologies to store its backups. This partnership eliminates the costly egress and API fees charged by hyperscalers by offering a flat-rate, predictable pricing model, enabling CrashPlan customers to store more data for longer at a fraction of the cost. This partnership covers Microsoft 365, Google Workspace, endpoint devices, and file servers.
…
DeepTempo announced an integration with Cribl, bringing its deep-learning behavioral detection engine directly into Cribl’s telemetry pipeline. It says this is the first time enterprises can run purpose-built deep learning models within their data orchestration workflow, detecting polymorphic and AI-driven threats like agentic attacks and zero-click exploits before data even reaches the SIEM. It says that, as legacy rule-based tools continue to miss behavior-driven threats, this partnership gives SOC teams a new intelligent layer of preprocessing, powered by DeepTempo’s LogLM foundation model that “understands the language of logs.”
…
Generative AI inference pioneer d-Matrix, in collaboration with Arista, Broadcom and Supermicro, announced SquadRack, the industry’s first blueprint for disaggregated, standards-based, rack-scale systems for ultra-low latency batched inference. Showcased at the Open Compute Project Global Summit, SquadRack provides a reference architecture to build turnkey solutions enabling blazing fast agentic AI, reasoning and video generation. It delivers up to 3x better cost-performance, 3x higher energy efficiency, and up to 10x faster token generation speeds compared to traditional accelerators.
SquadRack configured with eight nodes in a single rack enables customers to run Gen AI models up to 100 billion parameters. For larger models or large-scale deployments, it uses industry standards-based Ethernet to scale out to hundreds of nodes across multiple racks.
d-Matrix JetStream IO Accelerators enabling ultra-low latency device-initiated, accelerator-to-accelerator communication using standard Ethernet.
Supermicro X14 AI Server Platform integrated with Corsair accelerators and JetStream NICs.
Broadcom Atlas PCIe switches for scaling up within a single node.
Arista Leaf Ethernet Switches connected to JetStream NICs enabling high performance, scalable, standards-based multi-node communication.
d-Matrix Aviator software stack that makes it easy for customers to deploy Corsair and JetStream at scale and speed up time to inference.
SquadRack configurations will be available for purchase through Supermicro in Q1 2026. Learn more here.
…
Industrial AI supplier Cognite announced a partnership with Databricks, and plans for a bidirectional, zero-copy data sharing integration between the Cognite Industrial AI and Data Platform, which includes Cognite Atlas AI and Cognite Data Fusion, and the Databricks Data Intelligence Platform, including Databricks’ flagship AI product, Agent Bricks. This collaboration leverages the open ecosystem approach of both platforms to provide a unified, domain-specific intelligent data foundation for Industrial AI, driving operational efficiency and measurable business value across the enterprise.
…
Channel-led DataCore launched its Freedom360 Partner Program. The software-defined DataCore offering includes SANsymphony for block storage, Nexus for file (via the ArcaStream acquisition in February 2025), Swarm for object, Puls8 for containers, and StarWind for hyperconverged infrastructure (acquired in May 2025). Pixitmedia solutions (acquired in Feb 2025) further extend opportunities in media and entertainment, supporting end-to-end workflows in broadcast, live events, post-production, and creative pipelines. Freedom360 has a progressive certification framework – Base, Specialist, and Excellence – that recognizes partner commitment and rewards contribution. This system gives every partner, whether newly onboarded or long established, a clear path to higher rewards, greater visibility, and stronger collaboration with DataCore. The framework is designed to accelerate cross-sell opportunities across the portfolio. DataCore is modernizing partner training and certification
…
DDN Infinia is available in Oracle Cloud Marketplace and can be deployed on Oracle Cloud Infrastructure (OCI). Oracle Cloud Marketplace is a centralized repository of enterprise applications offered by Oracle and Oracle partners. DDN Infinia delivers cloud-native, GPU-optimized, software-defined object storage designed to mitigate the complexity, performance bottlenecks, and costs that stall modern AI pipelines. Infinia is optimized for OCI bare metal instances, providing improved performance for AI, analytics, and data-intensive workloads while supporting OCI’s native governance, spend management, and compliance frameworks.
…
Automated data mover Fivetran signed a definitive agreement to merge in an all-stock deal with dbt Labs. Fivetran CEO George Fraser will serve as CEO of the unified company, and dbt Labs CEO Tristan Handy will serve as co-founder and President. Following close of the transaction, the combined company will be approaching nearly $600 million in ARR. As part of this transaction, the company is committed to keeping dbt Core open under its current license and maintaining it with and for the community, ensuring its development remains vibrant.
The unification of Fivetran and dbt sets the standard for open data infrastructure, a new approach that reduces engineering complexity by automating data management end to end. It works across any compute engine, catalog, BI tool, or AI model, is built on open standards like SQL and Iceberg, and remains flexible so organizations avoid lock-in and can scale with future workloads.
Finalisation of the merger remains subject to customary closing conditions, including regulatory approvals.
…
Data security supplier Forcepoint announced the expansion of its Self-Aware Data Security platform to protect enterprise databases and structured data sources. With this launch, Forcepoint is the first to extend AI Mesh Data Classification technology across both structured and unstructured data throughout the hybrid enterprise, delivering unified Data Security Posture Management (DSPM) and adaptive data loss prevention in a single platform.
Most DSPM tools stop at cloud visibility without remediation, widening the gap between visibility and control. Forcepoint extends its AI Mesh-powered discovery and classification into enterprise databases and business applications, while unifying visibility with enforcement across SaaS apps, endpoints, networks and AI workflows. This closes that gap by giving enterprises and governments a single, AI-native platform to secure both structured and unstructured data consistently. Read a blog to learn more.
…
According to an HPEblog: “The HPE Alletra Storage MP X10000, supporting unstructured, data-intensive workloads, will soon introduce native support for the Model Context Protocol (MCP) – enabling seamless integration between storage, compute, and AI frameworks. Together, they create a modular, software-defined platform that grows with the business.”
…
Anti-ransomware backup startup HyperBunker has closed an €800,000 seed round from Fil Rouge Capital and Sunfish Venture Capital.
…
GPU-based NVMe RAID supplier Graid Technology has entered a strategic license agreement with Intel to take the lead in developing, marketing, selling, and supporting Intel VROC (Virtual RAID on CPU) worldwide. Together, CPU- and GPU-based RAID architectures will deliver unparalleled speed, scalability, and resilience for AI, HPC, and data-intensive workloads.
As we understand it, Intel VROC is a blend of hardware and software RAID storage, designed to maximize the performance of NVMe SSDs in high-end computing environments like servers and workstations. It enables RAID configurations (such as RAID 0, 1, 5, 10, and matrix RAID) directly through the CPU, eliminating the need for separate hardware RAID controllers or host bus adapter (HBA) cards, which reduces complexity, cost, power consumption, and frees up PCIe slots.
At close, which is expected by the end of the year, Graid Technology will assume responsibility for all Intel VROC customer support and future development. Both Intel and Graid Technology say they are committed to ensuring a seamless transition with regular updates and transparent communication throughout the process.
Graid told us: “[Our] SupremeRAID is a software-defined RAID solution that runs on the GPU, not a hardware card. Under the new agreement, we’ll lead global sales, development and support for Intel VROC, which remains a CPU-based RAID product. Together they offer complementary, software-defined RAID architectures for different performance needs.’
…
JEDEC Solid State Technology Association announced it is nearing completion of the next version of its Universal Flash Storage (UFS) standard: UFS 5.0. Designed for mobile applications and computing systems that demand high performance with low power consumption, UFS 5.0 should deliver:
Increased sequential performance up to 10.8 GB/s to meet AI demands.
Integrated link equalization for more reliable signal integrity.
Distinct power supply rail to provide noise isolation between PHY and memory subsystem, easing system integration.
Inline Hashing for greater security.
…
Lightbits Labs, which supplies software-defined, disaggregated, NVMe over TCP storage, and CYBERTEC, the largest PostgreSQL consultancy and services delivery company in Europe, announced a strategic technical alliance that offers optimized next-gen infrastructure for high-performance PostgreSQL workload needs. The collaboration combines CYBERTEC’s PostgreSQL expertise with Lightbits’ high-performance block storage to help organizations overcome the storage bottlenecks that limit the growth and performance of PostgreSQL databases at scale.
…
Ingo Wiegand
Mainframe software modernizer Mechanical Orchard has hired Ingo Wiegand as VP of Product, reporting directly to CEO Rob Mee. His most recent position was GM & VP of Product Management at Samsara, where he led the video-based safety product through a phase of hyper-growth to several hundreds of millions in ARR over the course of five years. Wiegand will scale the Imogen product, including managing the roadmap, driving smooth collaboration between teams, and ensuring the successful translation from vision to delivery.
Imogen “rewrites mainframe applications safely and quickly by focusing on the behavior of the system as represented by data flows, rather than on just translating code. This approach, encapsulated in the platform, signals the end of opaque, risky and uncertain mainframe transformation projects, resets the technical debt meter and restores control to IT teams through rewriting systems into clean, modern code. Customers span the global banking, retail, healthcare, manufacturing, and logistics sectors.”
…
Wedbush analyst Matt Bryson told subscribers that Samsung announced its Q3 operating profit is expected to grow around 32 percent year-over-year to ₩12.1 trillion ($8.5 billion), marking its highest levels since Q2 2022 and far exceeding consensus of ₩10 trillion. Although detailed figures weren’t disclosed, the Chosun Daily estimates Samsung’s semiconductor division (DS) drove the majority of the upside earning around ₩5 trillion, more than ten times its Q2 profit of ₩400 billion. A number of reports attributed the earnings beat to stronger-than-expected prices of commodity DRAM and NAND, stemming from demand for AI datacenter servers, and overall tighter chip inventory levels.
Pfeiffer University, a private nonprofit liberal arts institution in North Carolina, is using VergeIO to replace VMware, reducing Pfeiffer’s infrastructure costs by approximately 85 percent. “VMware wasn’t calling us back,” said CIO Ryan Conte. “VergeOS was the only product I looked at that didn’t need hardware. Others told me to buy new, but I had good servers with life left in them. VergeOS let me use them.” VMware’s move to per-core subscriptions increased Pfeiffer’s projected costs to $35,000-$45,000 annually, compounded by the elimination of discounts offered to higher education institutions. In addition, MSPs pushed for hardware refreshes or cloud migrations that would have cost Pfeiffer $100,000 to $200,000 – a significant capital expense for most private nonprofit institutions.
VergeIO stood out because it:
Supported reuse of HP Gen9/10/11 and Dell servers, allowing the university to repurpose existing equipment.
Combined virtualization, storage, networking, and data protection into a single platform.
Enabled in-house migration of 30–40 VMs without professional services.
Delivered built-in disaster recovery, replication, and ransomware protection, eliminating the need for a separate $20,000–$30,000 backup project.
Western Digital announced the opening of its expanded System Integration and Test (SIT) Lab, a state-of-the-art 25,600 sq ft facility in Rochester, Minn. and called it a strategic investment to provide research, development and global operations and enable real-world testing and validation with a mini datacenter environment. The SIT Lab serves as a massive, dedicated collaboration hub where the company’s engineers work alongside key customers throughout every stage of the product lifecycle, including development, qualification, production ramp and end-of-life. WD’s global SIT lab network has multiple sites close to its customers in the United States and across Asia. A blog says more.