MinIO has developed an Enterprise Object Store to create and manage exabyte-scale data infrastructure for commercial customers’ AI workloads.
The data infrastructure specialist provides the most popular open source object storage available, with more than 1.2 billion Docker pulls, and is very widely deployed. However, the Enterprise Object Store (EOS) product carries a commercial license.
AB Periasamy.
AB Periasamy, co-founder and CEO at MinIO, issued a statement: “The data infrastructure demands for AI are requiring enterprises to architect their systems for tens of exabytes while delivering consistently high performance and operational simplicity.
“The MinIO Enterprise Object Store adds significant value for our commercial customers and enables them to more easily address the challenges associated with billions of objects, hundreds of thousands of cryptographic operations per node per second or encryption keys or querying an exabyte scale namespace. This scale is a defining feature of AI workloads and delivering performance at that scale is beyond the capability of most existing applications.”
EOS features include:
Catalog Enables indexing, organizing and searching a vast number of objects using the familiar GraphQL interface, facilitating metadata search in an object storage namespace.
Firewall Aware of the AWS S3 API and facilitating object-level rule creation from TLS termination, load balancing, access control and QOS capabilities at object-level granularity. It is not IP-based or application-oriented.
Key Management Server MinIO-specific, highly available, KMS implementation optimized for massive data infrastructure. It deals with the specific performance, availability, fault-tolerance and security challenges associated with billions of cryptographic keys, and supports multi-tenancy.
Cache a caching service that uses server DRAM memory to create a distributed shared cache for ultra-high performance AI workloads.
Observability Data infrastructure-centric collection of metrics, audit logs, error logs and traces.
Enterprise Console A single pane of glass for all the organization’s instances of MinIO – including public clouds, private clouds, edge and colo instances.
As we understand it, ultra-high performance AI applications run in massive GPU server farms. MinIO’s cache pooled DRAM does not operate in the GPU servers in these server farms and the GPUs there cannot directly access the MiniO pooled x86 server DRAM cache.
On that basis, we suggested to MinIO CMO Jonathan Symons that MinIO’s cache, although designed for ultra-high performance AI applications, does not support direct supply of data by cache-sharing to the GPU processors used for these ultra-high performance AI applications.
Symons told us GPUDirect-supporting filers use networking links – like MinIO – to send data to GPU server farms. “GPUs accessing the DRAM on SAN and NAS systems using GPUDirect RDMA are also limited by the same 100/200 GbE network HTTP-based object storage systems use. RDMA does not make it magically better when the network between the GPUs and the storage system is maxed out.
“Nvidia confirmed that object storage systems do not need certification because they are entirely in the user space. Do you see Amazon, Azure or GCP talking about GPUDirect for their object stores? No. Is there any documentation for Swiftstack (the object store Nvidia purchased) on GPUDirect? No. SAN and NAS vendors need low level kernel support and they need to be certified.
“GPUDirect is challenged in the same way RDMA was in the enterprise. It is too complex and offers no performance benefits for large block transfers.
“Basically we are as fast as the network. So are the SAN and NAS solutions taking advantage of GPUDirect. Since neither of us can be faster than the network, we are both at the same speed. To qualify for your definition of ultra-high performance, do you have to max the network or do you simply have to have GPUDirect?”
Point taken, Jonathan.
MinIO’s Enterprise Object Store is available to MinIO’s existing commercial customers immediately, with SLAs defined by their capacity.
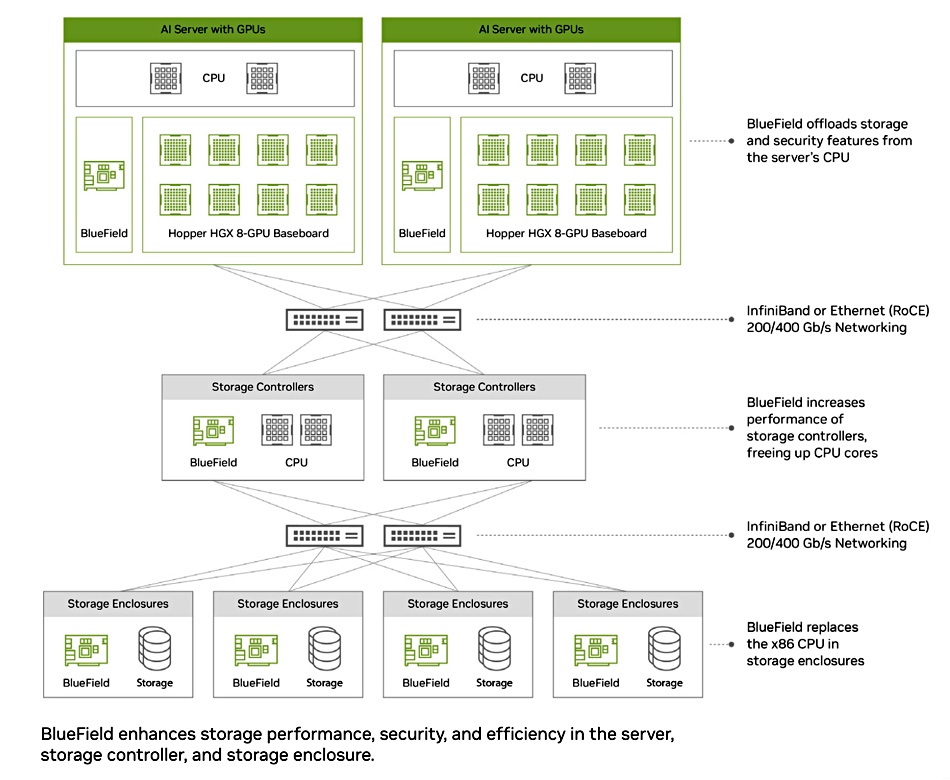
All-flash storage array supplier VAST Data has ported its storage controller software into Nvidia’s BlueField-3 DPUs to get its stored data into the heart of Nvidia GPU servers, transforming them, VAST says, into AI data engines.
Update: Supermicro and EBox section updated 13 March 2024.
The BlueField-3 is a networking platform with integrated software-defined hardware accelerators for networking, storage, and security. Nvidia’s BlueField-3 portfolio includes DPUs and SuperNICs, providing RDMA over ROCE, with both operating at up to 400Gbps and a PCIe gen 5 interface. VAST Data supplies a disaggregated single QLC flash tier, parallel, scale-out, file-based storage system and has built up layers of software sitting on top of this: data catalog, global namespace, database, and coming data engine, all with an AI focus.
Jeff Denworth, co-founder at VAST Data, talked about the news in AI factory architecture terms, saying in a statement: “This new architecture is the perfect showcase to express the parallelism of the VAST Data Platform. With NVIDIA BlueField-3 DPUs, we can now realize the full potential of our vision for disaggregated data centers that we’ve been working toward since the company was founded.”
The existing VAST storage controller nodes (C-nodes) are x86 servers. The controller software has been ported to the 16 Armv8.2+ A78 Hercules cores on the BlueField-3 card, and this new VAST architecture is being tested and deployed first at CoreWeave, the GPU-as-a-service cloud farm supplier.
Nvidia BlueField-3 DPU and SuperNIC deployment diagram
VAST highlights four aspects of its BlueField-3 (BF3) controller adoption:
Fewer independent compute and networking resources, reducing the power usage and data center footprint for VAST infrastructure by 70 percent and a net energy consumption saving of over 5 percent compared to deploying NVIDIA-powered supercomputers (GPU servers) with the previous VAST distributed data services infrastructure.
Eliminating contention for data services infrastructure by giving each GPU server a dedicated and parallel storage and database container. Each BlueField-3 can read and write into the shared namespaces of the VAST Data system without coordinating IO across containers.
Enhanced security as data and data management remain protected and isolated from host operating systems.
Providing block storage services natively to host operating systems – combining with VAST’s file, object, and database services.
This fourth point is a BlueField-3 SNAP feature, providing elastic block storage via NVMe and VirtIO-blk. Neeloy Bhattacharyya, Director, AI/HPC Solutions Engineering at VAST Data, told us this is not a VAST-only feature: ” It is on any GPU server with BF3 in it, with no OS limitation or limitation of the platform that the BF3 is connected to. The block device is presented from the BF3, so it can be used to make the GPU server stateless.”
We asked is VAST now delivering block storage services generally to host systems? Bhattacharyya replied: ”Not yet, that will be available later this year.”
VAST has Ceres storage nodes (D-nodes) with BF1 and we asked if the block protocol will include them: “Yes, the block device is presented on the BF3, so the hardware the CNode function is talking to on the backend does not matter.”
We also asked if this is effectively an update on the original Ceres-BlueField 1 announcement in March 2022. He said: “No, this announcement is the logic function (aka CNode) running on a BF3 hosted in a GPU-based server. This means VAST now has an end-to-end BlueField solution (between the BF3 in the GPU server and currently BF1 in the DBox). By hosting the CNode on the BF3, each GPU server has dedicated resources to access storage which provides security, removes contention between GPU servers and simplifies scaling.”
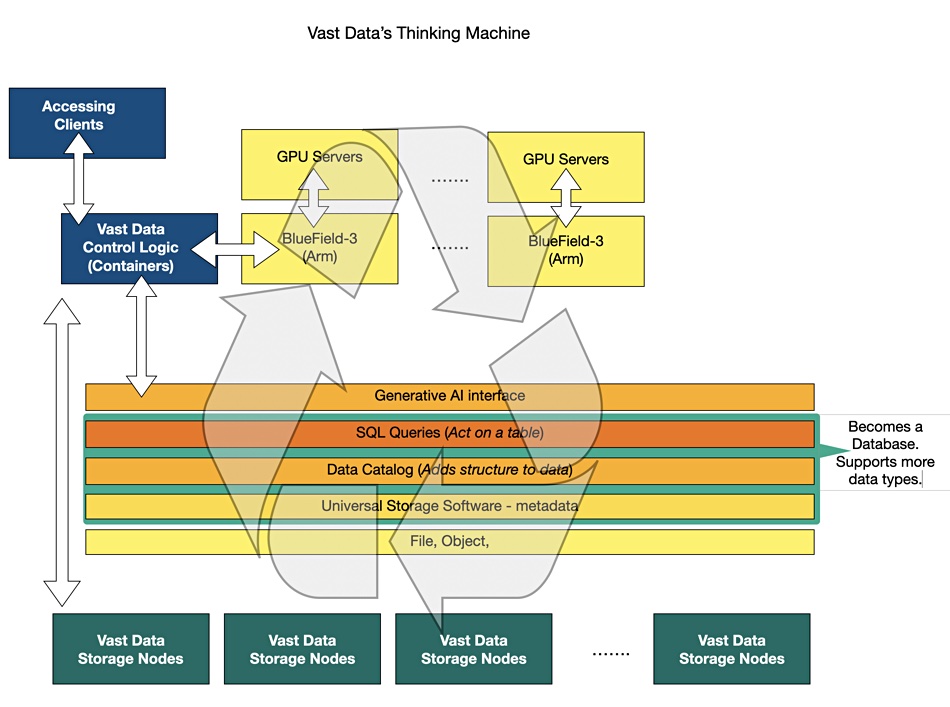
Back in May last year we interpreted VAST’s Thinking Machine’s vision in a diagram (see above), and Bhattacharyya told us us: “this is the realization of that vision.”
Peter Salanki, VP of Engineering at CoreWeave, said: “VAST’s revolutionary architecture is a game-changer for CoreWeave, enabling us to fully disaggregate our data centers. We’re seamlessly integrating VAST’s advanced software directly into our GPU clusters.”
The performance angle is interesting. As no x86 servers are involved in the data path on the VAST side there is no need for the x86 server host CPU-bypassing GPUDirect. Denworth told B&F: “Performance-wise, the introduction of VAST’s SW on BlueField processors does not change our DBox numbers, these are orthogonal. We currently get 6.5 GBps of bandwidth from a BlueField-3 running in a host. The aggregate is what matters… some hosts have one BF-3, others have 2 for this purpose – which results in up to 13 GBps per host. Large clusters have 1,000 of machines with GPUs in them. So, we’re essentially talking about being able to deliver up to 13 TBps per every 1,000 clients.”
Supermicro and EBox
VAST Data is also partnering Supermicro to deliver a full-stack, hyperscale, end-to-end AI system, certified by Nvidia, for service providers, hyperscale tech companies and large, data-centric enterprises. Customers can now buy a fully-optimized VAST Data Platform AI system stack built on industry-standard servers directly from Supermicro or select distribution channels.
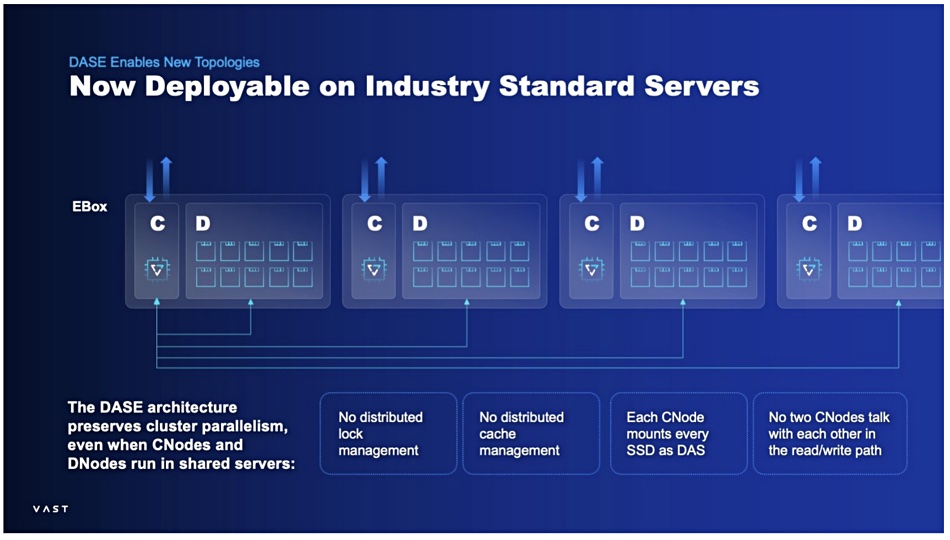
There is a second VAST-Supermicro offering which is an alternative to the BlueField-3 configuration and aimed at exabyte scale deployments. A LinkedIn post by VAST staffer John Mao, VP Global Business Development, said the company has developed an ” ‘EBox’, whereby a single standard (non-HA) server node is qualified to run both VAST “CNode” software containers and VAST “DNode” containers as microservices installed on the same machine.”
“While from a physical appearance this offering may look like many other software-defined storage solutions in the market, it’s critically important to understand that the DASE software architecture remains 100 percent intact, to preserve true cluster wide data and performance parallelism (ie. no distributed lock or cache management required, every CNode container still mounts every SSD to appear as local disks, and CNode containers never communicate with each other in the read/write data path.)”
The term EBox refers to an exabyte-scale system. Mao says that, at this scale, “failure domains shift from server-level to rack-level, homogeneity of systems become critical in order to optimize their hardware supply chain, and better overall utilization of data center rack space and power.”
Write speed increase
Denworth has written a blog, “We’ve Got The Write Stuff… Baby”, about VAST increasing its system’s write speed as the increasing scale of AI training processing means a greater need for checkpointing at intervals during a job. The idea is it would safeguard against re-running the whole job if an infrastructure component fails. We saw a copy of the blog before it went live, and Denworth says: “Large AI supercomputers are starting to shift the balance of read/write I/O and we at VAST want to evolve with these evolutions. Today, we’re announcing two new software advancements that will serve to make every VAST cluster even faster for write-intensive operations.”
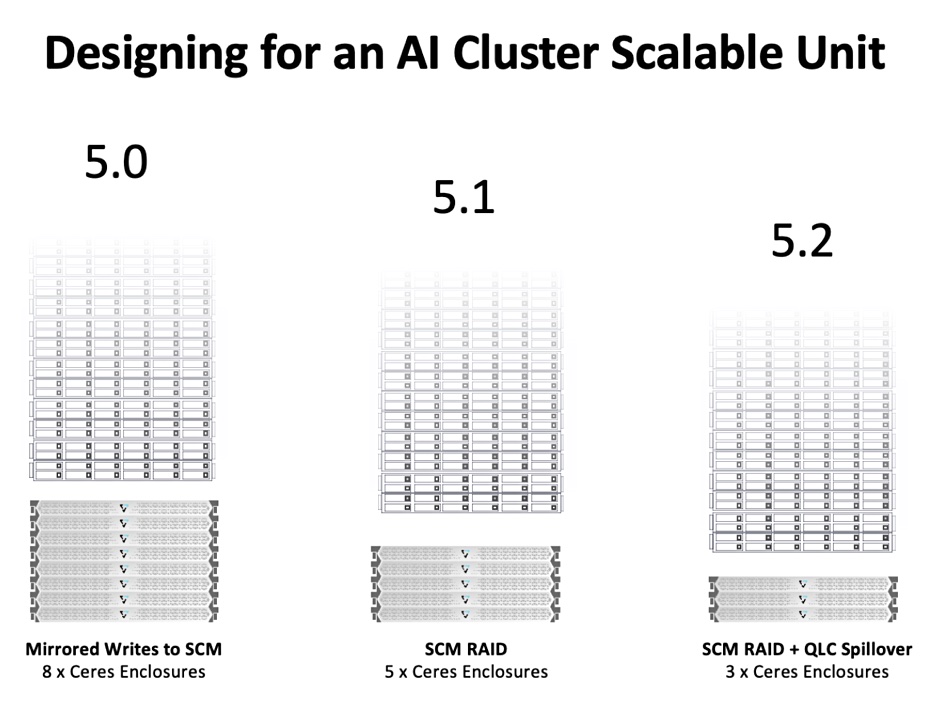
They are SCM RAID and Spillover. Regarding Storage-Class Memory (SCM) RAID, Denworth writes: “To date, all writes into a VAST system have been mirrored into storage class memory devices (SCM). Mirroring data is not as performance-efficient as using erasure codes. … Starting in 5.1 (available in April, 2024), we’re proud to announce that the write path will now be accelerated by RAIDing data as it flows into the system’s write buffer. This simple software update will introduce a performance increase of 50 performance.”
Currently write buffers in a VAST system are the SCM drives with their fixed capacity, which can be less than the capacity needed for a checkpointed AI job. So: “Later this summer (2024), version 5.2 of VAST OS will support a new mode where large checkpoint writes will spillover to also write directly into QLC flash. This method intelligently detects when the system is frequently being written to and allows large, transient writes to spillover into QLC flash.”
All-in-all these two changes will help reduce the VAST hardware needed for AI training: “When considering how we configure these systems for large AI computers, write-intensive configurations will see a 62 percent reduction in required hardware within 6 months time. … If we take our performance sizing for NVIDIA DGX SuperPOD as a benchmark, our write flow optimizations dramatically reduce the amount of hardware needed for a single Scalable Unit (SU).”
VAST Data will be exhibiting at NVIDIA GTC at Booth #1424.
Listening to Cohesity’s Gaia guy, Greg Statton, talking to an IT Press Tour audience about having a conversation with your data, and CEO Sanjay Poonen saying Gaia, with RAG, will provide insight into your private data, prompted a thought about how the data will be made ready.
Gaia (Generative AI Application) provides data in vector embedding form to large language models (LLMs) so they can use it to generate answers to questions and requests. Being Cohesity, the source data is backups (secondary data) and also primary data. An enterprise could have a petabyte or more of backup data in a Cohesity repository.
Greg Statton, Office of the CTO – Data and AI at Cohesity.
Statton told us companies adopting Gaia will need to vectorize their data – all or part of it. Think of this as a quasi-ETL (Extract, Transform, Load) with raw structured or unstructured data being fed to a vector embedding process which calculates vector embeddings and stores them in a Gaia database.
This is all very well but how does the raw data get transformed into a format usable by LLMs? It could take a long time to vectorize a whole data set. This is a non-trivial process.
Suppose the customer has Veritas backup data on tape. If customers want to use Gaia and AI bots to query tape-based data then they have to vectorize it first. That means restoring the backup and identfying words, sentences, mails, spreadsheets, VMs, etc. It will take a while – maybe weeks or months. But this will need to be done if a customer wants to query the entirety of their info.
How is it done? The raw data is fed to a pre-trained model – such as BERT, Word2Vec, and ELMo – which vectorizes text data. There are other pre-trained models for audio and image data.
A Datastax document explains: “Managing and processing high-dimensional vector spaces can be computationally intensive. This can pose challenges in terms of both computational resources and processing time, particularly for very large datasets.”
It gets worse, as we are assuming that restored backup and other raw data can be fed straight into a vector embedding model. Actually the data may need preparing first – removing noise, normalizing text, resizing images, converting formats, etc. – all depending on the type of data you are working with.
Barnacle.ai founder John-David Wuarin has worked out a tentative timescale to have a million documents transformed into vector embeddings using openAI. He starts with a price: $0.0001 per 1000 tokens, where a token is a chunk is formed from a part of a word, a whole word or a group of words.
For one document of 44 chunks of 1000 tokens each, it’ll be 44 x $0.0001 = $0.0044. For 1,000,000 documents with an average of 44 chunks of 1000 tokens each: 1,000,000 x 44 x $0.0001 = $4,400. There are rate limits for a paid user: 3,500 requests per minute and 350,000 tokens per minute. He reckons embedding all the tokens would take 1,000,000 x 44 x 1000 ÷ 350,000 = 125,714.285 minutes – or 87 days. It is a non-trivial process.
Statton believes that enterprises wanting to make use of Gaia will probably run a vector embedding ETL process on subsets of their data and proceed in stages, rather than attempting a big bang approach. He noted: “We vectorize small logical subsets of data in the background.”
Customers will use Gaia, meaning Azure OpenAI from the get-go to generate answers to users’ input. “But,” he said, “we can use other LLMs. Customers can bring their own language model,” in a BYOLLM fashion.
Statton also reckons the models don’t matter – they’re useless without data. The models are effectively commodity items. The suppliers who own the keys to the data will win – not the model owners. But the data has to be vectorized, and incoming fresh data will need to be vectorized as well. It will be a continuing process once the initial document/backup stores have been processed.
Gaia promises to provide fast and easy conversational access to vectorized data, but getting the whole initial data set vectorized will likely be neither fast nor easy. Nor particularly cheap.
Object storage supplier Scality released the results of a survey of US and European decision-makers about immutable storage, saying that not all immutability is created equal – some forms still leave a window of exposure. Chief marketing officer Paul Speciale blogged about true immutability and this sparked our curiosity. We asked him some questions abut this via email.
Blocks & Files: Are there degrees of immutability? If so, what are they and how do they matter?
Paul Speciale.
Paul Speciale: Yes, there are degrees. To first provide some context, we view immutability as a cornerstone of an organization’s data cyber resiliency strategy, especially for backup storage in the face of today’s rising ransomware threats. Cyber criminals understand that as long as you can recover (restore), you are less likely to pay their ransom, so attacks on backups are much more common now. Immutability puts up significant barriers to common attack threats that modify (encrypt) or delete backup data.
That said, there are indeed different forms of immutability offered in different storage solutions that offer varying degrees of protection. The key factors to consider here include:
Does the underlying storage have true immutable properties, or can data essentially be edited/modified-in-place and is the underlying storage, therefore, effectively “mutable”?
Is the data immutable at the moment it is stored, or is there a delay that creates a window of exposure to ransomware? How long is that delay in practice?
How tightly integrated is the immutability capability with the writing application (is there an API that can be used to enable and configure immutability directly in the backup storage system)?
Are immutable backups online for fast restore in the event it is needed?
True immutability provides a critical last line of defence against ransomware attacks and data loss, by preventing any alteration or deletion of data. Other forms of immutability are more focused on preserving data states at certain points in time, which doesn’t provide the same cyber resilience benefits as those preventing the alteration or deletion of the actual data.
Blocks & Files: How much do the degrees of immutability cost?
Paul Speciale: Ransomware protection is really what imposes longer retention periods and higher costs – immutability by itself does not. By increasing the retention period of the backups, organizations are giving themselves more time to detect that an attack has occurred, and they’re also increasing the probability that a “clean” (non-infected) backup will be available to restore in case of an attack.
Regarding cost, the impact is dependent on the specific immutability mechanism in the backup solution implementing it. For example, data reduction mechanisms such as deduplication or incremental forever backups will reuse unique data blocks (S3 objects) at different restore points.
To manage different immutability periods from restore points using the same unique S3 objects in an object store, backup software vendors may implement different strategies with different cost implications. One strategy can be to have multiple copies of these unique S3 objects, each retaining a different immutability period. In that case, the cost of immutability translates directly into additional capacity requirements.
Another strategy is to extend the immutability period of these unique S3 objects using put-object-retention operations. In that case, the cost of immutability translates into additional S3 operations. This approach incurs more costs on public clouds charging for S3 operations, but it comes at no cost for on-premises object storage such as Scality provides in RING and ARTESCA.
Blocks & Files: Are there different restoration regimes for immutable data stores? How should we categorize them?
Paul Speciale: Yes, restoration regimes will depend on the type of immutable storage that is employed – this can range from backups on tape, on cloud storage such as in AWS S3 or Glacier, backup appliances, NAS/file system snapshots and modern object storage. Each one of these options presents their own tradeoffs in how data is restored and, moreover, how quickly it can be restored.
Corporate backup strategies should always include multiple copies of backup data. The famous 3-2-1 rule dictates at least three copies, but we often see organizations maintain more. In the case of on-premises application data, a multi-tiered backup policy that places strong emphasis on true immutability and rapid (online/disk-based) restore for performance and capacity tiers, and uses tape or cloud storage for longer-term retention can be an effective strategy.
Scality supports all-flash and hybrid RING and ARTESCA configuration to protect the most restore-time-sensitive workloads. Both of these solutions combine the main virtues of true immutability, high restore performance and low TCO for long-term backup retention, making them an optimal choice for multiple tiers of a backup strategy.
Blocks & Files: Can you tell me about the immutability exposure window?
Paul Speciale: Many traditional immutable solutions leave gaps in between writes. Some solutions may stage backups on standard storage before moving them to immutable media. File systems typically make data immutable via scheduled and periodic snapshots. Hours or more may pass between the last snapshot taken, with frequent intervals becoming increasingly costly in terms of capacity overhead and storage performance (especially when there are extensive snapshot histories maintained).
In addition, perhaps the most important issue with exposure windows is that when they exist, backups may get deleted and corrupted, requiring additional operations and complexity to restore from the snapshots. This can result in data retention gaps, leaving exposures for data loss from malicious internal or external actors.
Blocks & Files: How can it be reduced?
Paul Speciale: The only way to eliminate this exposure window is by saving and storing data instantly each and every time it is written. Doing so enables data to be restored from any point in time. The emergence of an immutability API in the popular AWS S3 API (S3 object locking) has created a de facto standard interface for data protection applications to directly enable, configure, and manage immutability in an optimal manner. Veeam Data Platform, for example, can enable object locking, set retention policies, and also set compliance mode enforcement directly in the object store through the APIs.
Blocks & Files: Should organizations have a formal and known immutability exposure time objective, set like a policy and variable across files, folders and objects?
Paul Speciale: Organizations should define and track their recovery point objective (RPO) and schedule their backups accordingly. Most workloads will tolerate a one-day RPO, and traditional daily backups are typically scheduled for that purpose.
As discussed, backups remain exposed before they are made immutable, so those backups can be deleted or altered. If the most recent backups are deleted, the organization can only restore older immutable backups, thus increasing the RPO.
But immutability exposure time has the most impact on the recovery time objective (RTO). Exposure means you cannot trust your latest backups, and you will potentially need to perform additional operations (e.g. rollback a snapshot) before you can restore. Having to connect to multiple administrative interfaces to perform manual actions will impose additional delays in recovery.
To restore at a higher throughput, having a very high-performance storage system for backups is certainly ideal. But are you really going to restore faster if you first need to spend your time on manual rollback operations before you can start the actual restore process? Admins must carefully consider the impact of these manual operations, plus the “immutability exposure time” when setting their organization’s RPO and RTO objectives.
Blocks & Files: What can you tell me about flaws in an organization’s immutability armor?
Paul Speciale: Immutability as it is normally implemented by most storage solutions protects against attacks that go through the data path – for example, from malware instructing the storage to delete its data. But ransomware actors have become increasingly sophisticated in their attack methods to increase their chances of forcing ransom payments – and a newer breed of AI-powered cyber attacks is raising the stakes even higher.
It’s important that organizations are aware of (and address) advanced attack vectors that can make storage systems vulnerable:
The first attack vector is the operating system, which needs to be hardened to prevent any root access.
Server consoles, such as the IPMI and the iDRAC, are also subject to vulnerability and can provide full access to underlying storage. They should either be configured on a dedicated secure network or disconnected entirely.
External protocols such as NTP and DNS also need to be protected to avoid timeshifting attacks or DNS hijacking.
Immutable object storage solutions are now available that provide the strongest form of data immutability plus end-to-end cyber resilience capabilities to protect against the threat vectors described above.
Blocks & Files: How can they be detected and fixed?
Paul Speciale: We can refer back to our principles to find solutions that combine true immutability at the storage layer, API-based control to allow applications to enable and configure immutability directly in the storage system, and fast/online restore capabilities.
Moreover, we should mention that the latest data protection solutions from vendors like Veeam are able to leverage object storage directly for backups (direct-to-object over S3), high-performance (multi-bucket SOBR), instant restore (VM Instant Recovery), and backup integrity validation (VM SureBackup) and more.
There are several elements that we recommend organizations ensure are integrated into their immutable storage:
Instantaneous data lock The second you store object-locked data, it is immutable with zero time delay.
No deletes or overwrites Make sure your data is never deleted or overwritten. This blocks ransomware attackers from encrypting or deleting data to prevent you from restoring. If any changes are made, a new version of the object is created, leaving the original data intact.
Support for AWS-compatible S3 Object Locking APIs Enabling immutability at the API level prevents user or application attempts to overwrite data when issuing S3 commands against a data set.
Configurable retention policies These are important because organizations are required to keep data for varying time periods. The ability to customize such retention policies means they can keep their data protected and fully immutable during this time.
Compliance mode This capability prevents anyone (including the system superadmin) from changing immutability configurations.
Blocks & Files: Is there a way to scan an organization’s data environment for immutability weaknesses?
Paul Speciale: Yes. First, the organization needs to understand the capabilities and potential limitations of immutable storage. Start by ensuring that immutable backups can be swiftly restored in case of an attack. Periodic and regular restore testing in disaster-like scenarios is strongly encouraged. Backup vendors have implemented tools to make these types of real-world restore validations more practical, and having a fast and reliable backup storage solution is mandatory to cope with this additional workload.
Vendor capabilities and immutability implementations can also be validated by third-party agencies. Scality, for example, has worked with the independent validation firm Cohasset Associates, and has published SEC 17a4(f) and FINRA 4511(c) Compliance assessments.
And look for storage solutions that offer multiple internal layers of security to avoid the novel threat vectors mentioned above. To address the need for end-to-end security, Scality is setting a new standard of cyber resilient ransomware protection with its comprehensive CORE5 approach.
Huawei is developing an archival storage system using magneto-electrical disks (MED), claiming its power draw is similar to a spin-down disk archive.
This OceanStor Arctic device first emerged in a presentation at MWC 24 by Dr Peter Zhou, president of Huawei’s data storage product lines. What we know so far is that it is slated to lower total connection cost by 20 percent compared to tape and reduce power consumption by 90 percent compared to hard drives. The first MED generation’s capacity will be like a big capacity disk: around 24TB. A rack system is said to have more than 10PB capacity, and its power consumption to be less than 2KW. The overseas (outside China) release will take place in the second 2025 half.
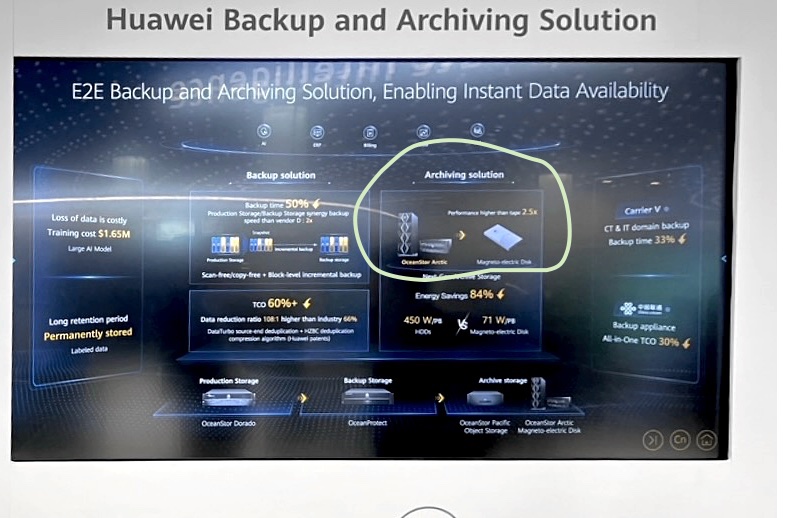
Analyst Tom Coughlin contributed a smartphone photo of a backup and archiving slide presented by Huawei at another event, and this has a section devoted to the OceanStor Arctic device.
We tried to enhance this to bring out the OceanStor Arctic section, and circled it in the next image:
The Archiving solution section of the slide has three visual elements: a rack, a 4 or 6RU chassis, and a disk. You can read this as the drive fits in the chassis which fits in the rack. We’re checking with Huawei to get this confirmed and will update this story if we hear back.
The text reads, as far as we can see:
Performance higher than tape – 2.5x
Energy Savings – 84 percent
450 W/PB HDDs vs 71 W/PB Magneto-electric Disk
We have been pondering what the term magneto-electric disk might mean. Dictionary-wise the magneto-electric effect refers to any linkage between the magnetic and the electric properties of a material. That could conceivably describe a hard disk drive’s technology, which involves using electricity to change the polarity of a magnetic region on a disk platter’s surface.
Huawei claims its MED has 90 percent lower power consumption than a hard disk drive. How can it spin a disk and consume so little power?
Supplier Disk Archive sells a spun-down disk archive. That has a far lower power consumption than permanently spinning HDDs – it quotes 210 watts/PB with 22–24 TB disks. A 10PB DiskArchive system would then need 10 x 210 watts, meaning 2.1KW. That’s not too far way from a 10PB Huawei MED rack needing <2KW.
We are asking Huawei if the OceanStor Arctic device uses spun-down disks and its initial response – through a spokesperson – was “My understanding is that the product line may not be in a position to disclose more information about the product as it’s not yet available in overseas market.” We live in hope.
Western Digital is being split into separate disk drive and NAND/SSD businesses, and CEO David Goeckeler will head up the latter.
Western Digital, under activist investor engagement from Elliott Management, has decided to separate its constituent HDD and NAND flash and SSD supply units. Elliott believes this will increase shareholder value as the NAND side of the business is undervalued. The company has issued a split progress report release saying Goeckeler is the CEO designate for the HDD business, and Irving Tan, EVP Global Ops, will step into the CEO role for the standalone HDD company, which will continue operating as Western Digital.
David Goeckeler
Goeckeler said: “Today’s announcement highlights the important steps we’re making towards the completion of an extremely complex transaction that incorporates over a dozen countries and spans data storage technology brands for consumers to professional content creators to the world’s leading device OEMs and the largest cloud providers.”
He added: “The flash business offers exciting possibilities with market growth potential and the emerging development of disruptive, new memory technologies. I am definitely looking forward to what’s next for the spinoff team.”
Industry analyst Jim Handy blogs: “I had been expecting for Goeckeler to follow the HDD side of the business, which remains quite healthy despite almost two decades of flash manufacturer predictions for HDDs to vanish as they were replaced by SSDs, a position that I never embraced.”
There are two execs currently leading the HDD and NAND/SSD business units – Ashley Gorakhpurwalla, who is EVP and GM for the HDD business, and Robert Soderbery, EVP and GM of the flash business. Their roles in the split businesses may need redefining.
Tan wasn’t quoted in the release, but Goeckeler commented: “Since joining Western Digital two years ago, Irving has made a tremendous impact on the transformation of our global operations organization and plays an integral role in running our HDD business. He leads with global perspectives, diverse insights and deep industry expertise and I have full confidence in him as Western Digital’s chief executive when the separation is completed.”
The announcement notes that Western Digital’s separation teams are establishing legal entities in the 18 countries where operations are located, preparing independent company financial models, finishing final preparations for SEC and IRS filings, conducting a contract assignment process for global customers and suppliers, and designing company-wide organizational structures for both companies.
Business IT modernization supplier BMC bought Model9 in April last year, and has rebranded its software as the AMI Cloud.
BMC is a private equity-owned $2 billion a year revenue company supplying enterprise IT operations and service management with a focus on automation and digital transformation and, latterly, the application of AI. Its customers are mid-size to Fortune 500 enterprises. AMI stands for Automated Mainframe Intelligence and it is a suite of mainframe data management products encompassing AMI Storage Management, Storage Migration and Storage Performance focussed on the z/OS environment.
John McKenny, SVP and GM of Intelligent Z Optimization and Transformation at BMC, said in a statement: ”Organizations rely on their mainframes to run their always-on, digital world. By launching BMC AMI Cloud, we’re helping them modernize their mainframe by eliminating the need for specialized skills and unlock their mainframe data to gain the benefits of cloud computing, so they can secure the most value for their organizations.”
Model9 supplied mainframe VTL (Virtual Tape Library) and data export services so that mainframe customers could avoid using slow and costly mainframe tape on the one hand, and move mainframe data to open system servers and the public cloud for application processing that is not available in the mainframe world.
BMC has evolved the Model9 software assets into a trio of AMI Cloud offerings alongside the AMI Storage threesome:
AMI Cloud Data—Migrate mainframe backup and archive data to cloud object storage; part of the classic Model9 VTL tech.
BMC AMI Cloud Vault—Create an immutable data copy of the mainframe environment in the cloud with end-to-end compression and encryption for protection against cyber-threats and ransomware. This uses Model9’s data export capability.
BMC AMI Cloud Analytics—Transfer and transform mainframe data for use in any AI/ML analytics cloud applications which simply may not be available in the mainframe environment.
Simon Youssef, head of Mainframe at Israel Postal Bank, was on message with his statement: “I am thrilled with the exceptional results we have achieved by implementing BMC’s data protection and storage management solutions for our mainframe data. With BMC AMI Cloud, we were able to modernize our legacy infrastructure and unlock new levels of efficiency and cost savings. BMC’s solution seamlessly integrated with our mainframe systems, eliminating the need for costly tape backups and streamlining our data management processes.”
BMC told an IT Press Tour in Silicon Valley that is investing heavily in integrating AI throughout its portfolio. CTO Ram Chakravarti said: “Operationalising innovation is the key to competitive advantage … AI is data’s best friend.” He talked about BMC building a set of interconnected DigitalOps products.
After talking with the BMC staffers it seems likely that customers will have several AI bots (GenAI Large Language Model Assistants) and they will interact. A CEO at an enterprise customer could, for example, ask Microsoft Copilot a question and Co-pilot then use sub-bots to get domain-specific information, such as the BMC bot. There could be a contest between BOT suppliers to get the CxO-facing bot, the top-level one, in place and then expand their Bot’s applicability in a land-and-expand strategy.
With Cohesity and Veritas having announced their impending merger, data protection and cyber resilience rivals Commvault and Rubrik are trying to promote themselves as safe havens for customers that they think may be overcome by fear, uncertainty and doubt.
Cohesity, the main company in this merger, has been putting out the message that the deal will benefit customers and that no Veritas NetBackup customer will be left behind. The software will not go end-of-life. There will be no forced migration to Cohesity’s backup and Cohesity customers could well benefit from Veritas’ cloud capabilities. By bringing Cohesity’s GenAI Gaia offering to the more than 300 EB of Veritas backup data then NetBackup users will be able to turn this dead data into an asset and mine it for insights.
That’s not the view of Commvault VP of Portfolio Marketing Tim Zonca, as outlined a blog entitled: “Avoid Veritas + Cohesity Chaos.” He writes: “Uncertainty and chaos should not come from vendors who [purport] to help maintain resilience.”
“The integration process between any two companies is a complex and time-consuming endeavor, likely taking several years to complete. At a time when data has never been more vulnerable to attacks, the transition can be quite chaotic for impacted customers and partners. But it doesn’t have to be.” Of course not. Come to Commvault: “When it comes to cyber resilience, there is no time for chaos. Commvault Cloud is the cure for chaos.”
Rubrik’s Chief Business Officer Mike Tornincasa blogs: “while the merger may make sense for Veritas and Cohesity, it will have a negative impact on their customers who are facing exploding volumes of data across Data Centers, Cloud, and SaaS with unrelenting threats of cyber attack, ransomware, and data exfiltration.”
Tornincasa says both Cohesity and Veritas are coming from positions of weakness: “Veritas has been struggling for relevance for the last ten years,” while “Cohesity has not been growing fast enough to raise another round of capital at an acceptable valuation.”
He chisels away at the financial background: “This is not a deal done in happy times. Cohesity’s valuation in 2021 was $3.7 billion. It should have increased considerably in the past three years if they had been healthy. Veritas was acquired by Carlyle Group (a Private Equity firm) for $7.4 billion in 2016. This would be a minimum $11 billion+ business if these businesses were growing. Instead, the combined valuation is presented as $7 billion.”
In his view: “Cohesity is now legacy,” and “We can anticipate Carlyle to bring the same playbook to the combined entity – no improved quality, higher prices and less choice.” So come to Rubrik instead.
While both Commvault and Rubrik cast FUD on the Cohesity-Veritas merger their FUD-elimination strategy is to suggest Cohesity and Veritas customers come to Commvault or Rubrik. This would mean Veritas or Cohesity customers then having to move to or adopt a separate backup regime. But that move to a separate backup regime is also what they are using to criticize Cohesity and Veritas. It’s nice to have a cake and eat it.
Sanjay Poonen
Cohesity CEO Sanjay Poonen told an IT Press Tour party in San Jose: “I don’t expect a single Veritas customer to defect. … Trust me. It’s not my first rodeo. … This is not Broadcom taking over VMware.”
He told us: “We’ll not talk about our roadmap until we meet regulatory approval,” and: “I want to keep our competitors guessing. … Let (them) spread the word it’s conflict and chaos. … I predict the FUD will fall flat.”
Cohesity and Veritas together will have around 10,000 customers; Rubrik has 6,000, and more than 300 EB under management. Poonen said the merged entity would count 96 percent of the Fortune 100 as customers; just four are missing.
Eric Brown
Cohesity CFO Eric Brown said Cohesity is working on an AI-enabled file translation facility to get Veritas backup files accessible by Cohesity’s Gaia AI. There was no mention at all of migrating Veritas backup files to Cohesity’s format.
Cohesity plus Veritas revenue in 2024 will be circa $1.6 billion, which is comparable to Veeam. Rubrik has about about $600 million revenues today. The merged Cohesity-Veritas business will be very profitable in GAAP net Income sense, Brown said. “We fully intend to go public in due course,” and “our value when we go public will likely be $10 billion.”
B&F thinks the merger will spark interest in other backup supplier combinations. For example, IBM has a legacy backup customer base, which has just received an indirect valuation. Rubrilk may look to an acquisition to bolster its customer count and data under management. Veeam too may look to an acquisition to enlarge its business and regain a clear separation between itself and the other players. The backup business is a-changin.
Azure Native Qumulo Cold (ANQ Cold) is the new cloud-native cold file data storage service from Qumulo.
Qumulo provides scalable and parallel access file system software and services for datacenters, edge sites, and the cloud with a scale anywhere philosophy. The aim is to make its file services available anywhere in a customer’s IT environment – that means on-premises, public cloud, and from any business location via clusters that are globally managed through a single namespace. It ported the Core file system software to run natively in the Azure public cloud in November last year and has now extended its Azure coverage.
Ryan Farris, VP of Product at Qumulo, said in a statement: “ANQ Cold is an industry game changer for economically storing and retrieving cold file data.”
ANQ Cold is positioned as an on-premises tape storage alternative and is fully POSIX-compliant. It can be used as a standalone file service, as a backup target for any file store, including on-premises scale-out NAS, and integrated into a hybrid storage infrastructure using Qumulo Global NameSpace – a way to access remote data as if it were local.
Kiran Bhageshpur
Qumulo CTO Kiran Bhageshpur said: “With ANQ Cold, we offer enterprises a compelling solution to protect against ransomware. In combination with our cryptographically signed snapshots, customers can create an instantly accessible ‘daily golden’ copy of their on-premises NAS data, Qumulo or legacy scale-out NAS storage.”
He claims there is no other system that is as affordable on an ongoing basis, while also allowing customers to recover to a known good state and resume operations as quickly as ANQ Cold.
In another use case, ANQ Cold provides picture archiving and communication system (PACS) customers with the ability to instantly retrieve cold images from a live file system, and has seamless file compatibility with PACS applications.
J D Whitlock, CIO of Dayton Children’s Hospital, said: “In pediatrics, we have to keep imaging files until the child turns 21. After a few years, it’s unlikely we will need to look at the image. But we have to keep it around for medical-legal purposes. Keeping this massive store of imaging data on secure, scalable, reliable, and cost-effective cloud storage is a perfect solution for us.”
Farris said: “Hospital IT administrators in charge of PACS archival data can use ANQ Cold for the long-term retention of DICOM images at a fraction of their current on-premises legacy NAS costs, while still being able to instantly retrieve over 200,000 DICOM images per month without extra data retrieval charges common to native cloud services.”
ANQ Cold has a pay-as-you-go pricing model, with customers paying for the capacity consumed. It costs $0.009/GB/month and is said to be up to 90 percent less expensive than other cloud file storage services. Its $/TB/month cost is $9.95 in the anchor Azure regions of westus2 and eastus2. Prices may be higher in other regions due to variability in regional Azure costs.
Customers have 5 TB of data retrieval included each month. After 5 TB, they’ll be charged at the rate of $0.03/GB until the first of the following month, when another 5 TB will be allowed. There is a minimum 120-day retention period. Data deleted before 120 days will be billed as if it were left on the system for 120 days.
We can expect Qumulo’s public cloud coverage to extend further as it develops its ability to provide file services in a multi-hybrid cloud environment.
Profile.Solix, the enterprise information archiving survivor, says it’s working on privately trained AI assistants to help customers converse with their active and archived enterprise app data.
The company was founded 22 years ago by CEO Sai Gundavelli to connect with enterprise applications such as ERP, CRM, and mainframes. It is application-aware and ingests, creates, and stores metadata about their information documents in a Common Data Platform. A set of applications are built on this platform.
Sai Gundavelli
The Solix software ingests older documents and data from these applications’ primary storage and archives it to lower-cost stores such as public cloud object instances. Its hundreds of customers are typically global Fortune 2000 companies and include Wells Fargo Bank, Elevance Health, Sterling Pharmaceutical, LG Electronics, Helen of Troy, and Korea Telecom, with a preponderance for the banking, insurance, and pharmaceutical markets.
Solix customers
We met Solix on an IT Press Tour in Santa Clara and Gundavelli said revenue had grown 50 percent from 2022 to 2023 to the $20-30 million region, and that the privately-owned company is profitable. It is developing LLMs it says are capable of being trained on a customer’s private data to improve accuracy.
B&F has been writing about the overall storage market for 20 years or more and has not come across Solix before, which prompts us to take a look at the reasons for this.
We think Solix does its info archiving top down, from the enterprise app viewpoint, not bottom-up from the storage arrays level. B&F looks at the storage market from the storage angle and that means we have had a blindspot for higher-level suppliers such as Solix. We categorize suppliers such as Komprise and Datadobi, also latterly Hammerspace and Arcitecta, as information lifecycle management operators. They are, we can say, storage array and filer-aware, and ingest data and metadata from storage, both hardware-defined and software-defined.
They do not ingest data directly from JD Edwards or SAP HANA or enterprise applications like that. Solix does, and operates at a higher level, as it were, in the enterprise information and storage stack than the more storage-focused operators such as Komprise, Datadobi, Hammerspace, and Arcitecta.
We checked this point of view with Sai Gundavelli, and he said: “I agree on your assessment why B&F never encountered us. Take for example:
Komprise – Unstructured Data Only
Datadobi – Unstructured Data Only
Hammerspace – Unstructured Data Only
MediaFlux – Never encountered them, but they claim all types of data
“Yes, we are working with application folks, not the storage folks. We work across structured, unstructured, and semi-structured, we have 186 connectors, starting from mainframe, DB2, Sybase, Informix, VAX/VMS. The most complex thing we manage for enterprises is structured data, which is key for SAP HANA, Snowflake, Databricks, and data warehousing and AI.
“Let’s take Cohesity or Druva, they are clearly in a category of backup and recovery. You clearly have an argument for online backup and making the data available for AI. You are correct on that, but we haven’t seen that yet. Most enterprises operate with each division making their own decision for either traditional tape backup or online, they are disparate. First, globally all backups in an enterprise need to be online. Secondly, all data to be enriched with metadata. Thirdly, it also has to provide governance and compliance globally. Further, it has to connect to machine learning algorithms, and one needs to train the algorithms as well. All these things are possible, but it is all about execution.
“Take Citibank, AIG, Kaiser Permanente, Pepsi – not that they are not doing backup and not that they may have Cohesity. We have not seen them to improve application performance nor manage compliance from a data retention or data sovereignty perspective etc.
“Irrespective, enterprises want to embrace AI. Whoever can help them achieve faster are the winners. We believe having access and understanding of all enterprise data is key, provides competitive advantage to bring AI to enterprises. For example, just imagine an AI algorithm which can predict cancer. How do you knit the data, with compliance and governance considerations, an element of structured data querying from Epicor or Cerner or AllScripts, and also bringing in unstructured medical imaging provide as an API and ensure Canada data is processed in Canada only and US data in US only? See which of the companies can enable it. Solix can do that.”
NetApp is using AI/ML in ONTAP arrays to provide real-time file ransomware attack detection. Its AIPOD has also been certified by Nvidia so customers can use NetApp storage for AI processing with DGX H100 GPU servers.
The sales pitch is that NetApp is adding Autonomous Ransomware Protection with Artificial Intelligence (ARP/AI) to its ONTAP storage array software, with adaptive AI/ML models looking at file-level signals in real time to detect – we’re told – even the newest ransomware attacks with planned 99 percent-plus precision and recall.
NetApp CSO Mignona Cote claimed in a statement: “We [were] the first storage vendor to explicitly and financially guarantee our data storage offerings against ransomware. Today, we are furthering that leadership with updates that make defending data comprehensive, continuous, and simple for our customers.”
There are four more allied anti-ransomware initiatives from NetApp:
BlueXP Ransomware Protection’s single control plane, now in public preview, coordinates and executes an end-to-end, workload-centric ransomware defense. Customers can identify and protect critical workload data with a single click, accurately and automatically detect and respond to a potential attack, and recover workloads within minutes.
Application-aware ransomware protection via SnapCenter 5.0offers immutable ransomware protection, applying NetApp’s ransomware protection technologies, previously used with unstructured data, to application-consistent backup. It supports tamper-proof Snapshot copy locking, SnapLock protected volumes, and SnapMirror Business Continuity to protect applications and virtual machines on-premises with NetApp AFF, ASA, and FAS, as well as in the cloud.
BlueXP Disaster Recovery, now generally available, offers seamless integration with VMware infrastructure and provides storage options for both on-premises and major public cloud environments, eliminating the need for separate standby disaster recovery (DR) infrastructure and reducing costs. It allows smooth transitions from on-premises VMware infrastructure to the public cloud or to an on-premises datacenter.
Keystone Ransomware Recovery Guaranteeextends NetApp’s current Ransomware Recovery Guarantee to the Keystone storage-as-a-service offering. NetApp will warrant snapshot data recovery in the event of a ransomware attack and, if snapshot data copies can’t be recovered through NetApp, the customer will be offered compensation.
AIPOD
AIPOD is NetApp’s new name for its current ONTAP AI offering, which is based on Nvidia’s BasePOD. The company says it’s an AI-optimized converged infrastructure for organizations’ highest priority AI projects, including training and inferencing.
Arunkumar Gururajan, VP of Data Science & Research at NetApp, said: “Our unique approach to AI gives customers complete access and control over their data throughout the data pipeline, moving seamlessly between their public cloud and on-premises environments. By tiering object storage for each phase of the AI process, our customers can optimize both performance and costs exactly where they need them.”
NetApp announced the following:
AIPOD with Nvidia is now a certified Nvidia BasePOD system, using Nvidia’s DGX H100 platform attached to NetApp’s AFF C-Series capacity flash systems. It is claimed to drive a new level of cost/performance while optimizing rack space and sustainability. It continues to support Nvidia’s DGX A100 and SuperPOD architecture.
New FlexPod for AI reference architecturesextend the NetApp-Cisco FlexPod converged infrastructure bundle to support Nvidia’s AI Enterprise software platform. FlexPod for AI can be extended to use RedHat OpenShift and SUSE Rancher, and new scaling and benchmarking have been added to support increasingly GPU-intensive applications.
NetApp is the first enterprise storage vendor to formally partner with Nvidia on its OVX systems. These provide a validated architecture for selected server vendors to use Nvidia L40S GPUs along with ConnectX-7 network adapters and Bluefield-3 DPUs.
We think all primary file storage vendors will add integrated AI-based real-time ransomware detection and it will become a standard checkbox item. Learn more about the NetApp offerings to support Gen AI here, and find out more about its cyber-resiliency offerings here. NetApp will be offering the first technology preview of the ONTAP ARP/AI within the next quarter.
Myriad, the new all-flash storage software from Quantum, will support Nvidia’s GPUDirect protocol to feed data faster to GPU servers.
Myriad was initially devised by technical director Ben Jarvis, who has filed several Myriad-related patents and came up with the core transactional key-value metadata database idea. He’s a long-term Quantum staffer, saying that back in 2006 he “joined ADIC and found out that Quantum was buying it the next day.”
Ben Jarvis.
Quantum bought ADIC for its backup target deduplication technology, which is used in the present day DXi backup target appliances.
Jarvis became involved with the StorNext hierarchical file manager, which initially was based on disk storage with tiering off to tape. As soon as the first all-flash arrays started appearing, he thought that Quantum and StorNext would need to support SSDs and that a disk-oriented operating system was inappropriate for this, however much it could be modified. A flash storage OS needed to be written from first principles so that it would be fast enough for NVMe drives and could scale up and out sufficiently.
Myriad was announced last year. Nick Elvester, Quantum’s VP for Product Operations, told an IT Press Tour in Denver that there has been high interest in Myriad, and CEO Jamie Lerner added: “Myriad has had million-dollar rollouts.” John Leonardini, a principal storage engineer for customer Eikon Therapeutics, is evaluating Myriad. “It’s one of the very fastest things on my floor. Myriad is the first Quantum product we cut a PO for,” he said.
Eikon currently uses Qumulo scale-out storage and indicated that Myriad outperformed it, with a five-node setup providing more data IO than racks of Qumulo gear. He also said that Myriad features were more usable than aspects of Qumulo’s data services such as snapshots. Leonardini likes Myriad’s automated load balancing and new node adoption as well. “We can click a button, come back in a day, and everything is rebalanced. That’s a win in my book.”
Jamie Lerner.
Elvester said the main Myriad customer interest lies in using its high performance for AI applications. It currently supports NFS v3/4 and SMB, and has a client providing parallel access. Myriad services include encryption, replication, distributed and dynamic erasure coding, data cataloging, and analytics. S3 access, a POSIX client, and GPUDirect support are roadmap items.
Jarvis said Myriad has a client access system that is dedicated like Lustre, and doesn’t use parallel NFS. One vendor does use pNFS, although a formal standard has not been adopted generally by the industry.
He said the suppliers that defined pNFS did so in a way that suited them and not others. For these others, adopting pNFS means bending their NFS software uncomfortably. “By using our client we avoid all that.”
Jarvis’s enthusiasm for writing from scratch extended to Myriad’s internal ROCE RDMA fabric. “It’s not NVMe-OF but our own protocol similar to NVMe-OF.”
Myriad is containerized and a cloud-resident version is being produced but not yet available.
Asked about GPUDirect, Jarvis said: “Storage for AI does not begin and end with GPUDirect. We’re going to check the box. We’re going to do innovation. Not all GPUDirect implementations are good.”
Lerner said: ”GPUDirect and SuperPOD support in Myriad is coming out imminently.”
He was asked about Quantum’s tape business and said tape is declining faster than before. New architectures don’t use tape. Tape cartridge capacities are larger than before and tapes are filled up rather than being part-filled and shipped off to Iron Mountain. So fewer cartridges are needed and they tend to stay in the libraries.
We have heard from sources that the hyperscalers over-bought tape a year or so ago and are now continuing to digest the purchases, slowing down their buy rate.
Looking at Quantum overall, Lerner said: “Quantum is inventing again. We’re generating patents again. Our innovation engine is running again. In the future I imagine everything we have is flash and then there will be tape. We have to let the legacy go.”