Wikipedia public domain image: https://commons.wikimedia.org/wiki/File:C_Merculiano_-_Cephalopoda_1.jpg
IBM has updated Ceph with object lock immutability for ransomware protection and previews of NVMe-oF and NFS to object ingest.
Storage Ceph is what IBM now calls Red Hat Ceph, the massively scalable open-source object, file and block storage software it inherited when it acquired Red Hat. The object storage part of Ceph is called RADOS (Reliable Autonomous Distributed Object Store). A Ceph Object Gateway, also known as RADOS Gateway (RGW), is an object storage interface built on top of the librados library to provide applications with a RESTful gateway to Ceph storage clusters.
Ex-Red Hat and now IBM Product Manager Marcel Hergaarden says in a LinkedIn post that Storage Ceph v7.0 is now generally available. It includes certification of Object Lock functionality by Cohasset, enabling SEC and FINRA WORM compliance for object storage and meeting the requirements of CFTC Rule 1.31(c)-(d).
There is NFS support for the Ceph filesystem, meaning customers can now create, edit, and delete NFS exports from within the Ceph dashboard after configuring the Ceph filesystem. Hergaarden said: “CephFS namespaces can be exported over the NFS protocol, using the NFS Ganesha service. Storage Ceph Linux clients can mount CephFS natively because the driver for CephFS is integrated in the Linux kernel by default. With this new functionality, non-Linux clients can now also access CephFS, by using the NFS 4.1 protocol, [via the] NFS Ganesha service.”
RGW, the RADOS gateway, can now be set up and configured in multi-site mode from the dashboard. The dashboard supports object bucket level interaction, provides multi-site synchronization status details and can be used for CephFS volume management and monitoring.
He said Storage Ceph provides improved performance for Presto and Trino applications, by pushing down S3select queries onto the RADOS Gateway (RGW). V7.0 supports CSV, JSON and Parquet defined S3select data formats.
It also has RGW policy-based data archive and migration to the public cloud. Users can: “create policies and move data that meets policy criteria to an AWS-compatible S3 bucket for archive, for cost, and manageability reasons.” Targets could be AWS S3 or Azure Blob buckets. RGW gets better multi-site performance with object storage geo-replication. There is “improved performance of data replication and metadata operations “ plus “Increased operational parallelism by optimizing and increasing the RadosGW daemon count, allowing for improved horizontal scalability.” But no performance numbers are supplied.
The minimum node count for erasure coding has dropped to 4 with C2+2 erasure-coded pools.
Preview additions
Three Ceph additions are provided in technical preview mode with v7.0, meaning don’t use them yet in production applications:
NVMe for Fabrics over block storage. Clients interact with an NVMe-oF initiator and connect against an IBM Storage Ceph NVMe-OF gateway, which accepts initiator connections on its north end and connect into RADOS on the South end. The performance equals RBD (RADOS Block Device) native block storage usage.
An object archive zone that keeps every version of every object, providing the user with an object catalogue that contains the full history of the object. It provides immutable objects that cannot be deleted nor modified from RADOS gateway (RGW) endpoints and enables the recovery of any version of any object that existed on production sites. This is good for ransomware and disaster recovery.
To limit what goes into the archive, there is archive zone bucket granularity which can be used to enable or disable replication to the archive zone on a per0object bucket case.
A third preview is of an NFS to RADOS Gateway back-end which allows for data ingest via NFS into the Ceph object store. Hergaarden says: “This can be useful for easy ingests of object data from legacy applications which do not natively support the S3 object API.”
Analysis. VAST Data is set on building a transformative data computing platform it hopes could be the foundation of AI-assisted discovery.
A blog by Global Systems Engineering Lead Subramanian Kartik, The quest to build thinking machines, starts by saying: “The idea behind VAST has always been a seemingly simple one: What if we could give computers the ability to think and discover for themselves?”
His next paragraph builds on the idea: “If computers were capable of original thought the process of discovery, which has catalyzed all human progress since the earliest moments of civilization, could be accelerated significantly. We could build revolutionary artificial intelligence capabilities that wildly surpass our own potential, solving the world’s biggest challenges and moving humanity forward.”
He seems to be aiming his pitch at future models, adding: “ChatGPT and AI [large] language models do not discover things or generate new ideas.”
Kartik notes: “AI-driven discovery and deep learning goes far beyond processing unstructured data like documents, images, or text … It’s processing real-world, analog data from sensors or genome sequencers or video feeds or autonomous vehicles, interpreting it in the context of the body of human knowledge, and making connections with ideas that we haven’t imagined yet.”
Kartik envisages self-discovering computers: “We think a data platform that provides neural networks with broad access to such natural data at tremendous speed and scale will deliver much more sophisticated AI than what we’ve seen to date. And as datasets grow larger, as algorithms get smarter, and as processors get stronger, self-discovering computers – thinking machines – will no longer be science fiction.”
In September, VAST Data co-founder Jeff Denworth wrote: “CoreWeave, like VAST, is focused on a future where deep learning will improve humanity by accelerating the pace of discovery.” A VAST announcement said in August: “The true promise of AI will be realized when machines can recreate the process of discovery by capturing, synthesizing and learning from data – achieving a level of specialization that used to take decades in a matter of days.”
It went on to say: “The era of AI-driven discovery will accelerate humanity’s quest to solve its biggest challenges. AI can help industries find treatments for disease and cancers, forge new paths to tackle climate change, pioneer revolutionary approaches to agriculture, and uncover new fields of science and mathematics that the world has not yet even considered.
That last point, about uncovering “new fields of science and mathematics that the world has not yet even considered” certainly seems like eureka-style discovery. But an organization may not like what has been discovered. Consider Galileo and his discovery that the Earth orbited the Sun. This infuriated the Catholic Church hierarchy who believed the Sun orbited the Earth, and told Galileo to abandon his heliocentric theory and not teach it.
I think that VAST has a more constrained idea of discovery; that its system will help customers improve their operations and not disrupt or damage them. The idea of discovery, of an AGI discovering new things, of a VAST Data system discovering new things, seems tremendously impressive but, unless the things discovered help an organisation they will not be wanted.
Imagine Kodak back in 1975 being told by an AI that digital cameras were the future and not film amd chemistry-based cameras; would this have made any difference to Kodak’s future business failure? Probably not.
Bootnote
The first digital camera was invented by Kodak engineer Steve Sasson in 1975. His management told him not to talk about it. Kodak stayed in denial for more than 25 years, working to get film good enough to compete with digital. It obviously failed. The point is that discovery, on its own, is not enough. The impact and relevance of the discovery has to be understood by the humans overseeing the system that produced the discovery.
The Storage Newsletter reports that Atempo SAS has requested the opening of a judicial recovery procedure to finalize the restructuring of its activities and accelerate its business development. Atempo intended to raise funds to move forward, but the investor exit dispute with a long-time financial partner has hindered this effort so Atempo asked for the protection of the Commercial Court. In recent years Atempo has built resale and distribution agreements with suppliers such as DDN, Quantum, Huawei, Panasas, and Eviden, and cloud service providers like OVH, Oustcale, and Scaleway. It also has a network of national and regional system integrators.
…
AWS has announced Redshift MySQL integrations with Aurora PostgreSQL, DynamoDB, and Relational Database Service (RDS) to connect and analyze data without building and managing complex extract, transform, and load (ETL) data pipelines. Customers can also now use Amazon OpenSearch Service to perform full-text and vector search on DynamoDB data in near real time.
…
What is the status of Velero container backup business CloudCasa? It has ambitions for funding and a spin off from Catalogic. Ken Barth, Catalogic CEO, told us: “Catalogic Software is very bullish on the future of CloudCasa. As you know, we were seeking funding partners for a spin out earlier in the year but with the slowdown in VC funding and exits, we haven’t seen anything that has excited us yet.
“CloudCasa has seen good market traction from the April recent release of CloudCasa for Velero. In November, based on customer demand, we added the option for organizations to self-host CloudCasa on-premises or in a cloud, or stay with our original BaaS architecture. We are in a great position to take advantage of the increasing adoption of Kubernetes in production environments, and CloudCasa placed well in the recent IDC MarketScape: Worldwide Container Data Management 2023 Vendor Assessment.
“We are looking forward to the opportunities that 2024 will bring for Catalogic and CloudCasa, both in terms of growth and strategic partnerships.”
…
Data observability supplier Cribl says it has surpassed $100 million in ARR, becoming the fourth-fastest infrastructure company to reach centaur status (behind Wiz, Hashicorp, and Snowflake). It also just launched its international cloud region, making its full suite of products available to customers in Europe. Cribl has closed its Series D of $150 million, bringing its total funding to date over $400 million from investors including Tiger Global, IVP, CRV, Redpoint Ventures, Sequoia, and Greylock Partners.
…
Cancer Research UK Cambridge Institute is using storage supplied by Zstor GmbH for its Lustre Object Storage Servers (OSS). The CIB224NVG4 2-Node Server, designed by Zstor, is a 2-node server configuration in a 2U format with 24 DapuStor Roealsen5 NVMe Gen4 SSDs built with TLC 3D NAND.
…
Lakehouse supplier Databricks has launched a suite of Retrieval Augmented Generation (RAG) tools. These will support enterprise users with overcoming quality challenges by allowing them to build high-quality, production LLM apps using their data. RAG is also a powerful way of incorporating proprietary, real-time data into LLM applications. There is a public preview of:
A vector search service to power semantic search on existing tables in your lakehouse.
Online feature and function serving to make structured context available to RAG apps.
Fully managed foundation models providing pay-per-token base LLMs.
A flexible quality monitoring interface to observe production performance of RAG apps.
A set of LLM development tools to compare and evaluate various LLMs.
DataCore’s Swarm v16 object storage release has added a single-server deployment for edge workloads. Swarm has been containerized and streamlined onto a single server powered by Kubernetes for compact configurations suited for Edge and Remote Office/Branch Office (ROBO) locations. Swarm 16 includes integration with Veritas NetBackup via immutable S3 object locking, which complements similar joint developments with Veeam and Commvault.
…
Data integration supplier Dataddo has launched its Data Quality Firewall, which ensures the accuracy of any data the platform extracts to storages like BigQuery, Snowflake, and S3. It claims the firewall is the first of its kind to be fully embedded in an ETL platform at the pipeline level. Dataddo says it performs checks on null values, zero values, and anomalies, and can be configured individually for each column, enabling granular quality control. It offers multi-mode operation to accommodate various fault tolerance standards, and rules are easy to configure and test in the platform’s no-code interface.
…
Datadobi’s StorageMAP v6.6 release has object storage support. It can now analyze object data stored on any S3-compliant platform, offering users a complete view of their unstructured data, including both File (SMB and NFS) and Object (S3) data. v6.6 also enables users to search for files based on specific metadata criteria and copy those files to a file or object target. For instance, they can easily copy files from a file server to a data lake for normalization and aggregation prior to copying (or moving) training datasets to apps for analytics and/or AI processing.
…
Data lakehouse supplier Dremio announced the public preview of Dremio Cloud for Microsoft Azure. It offers companies self-service analytics coupled with data warehouse functionality and the flexibility of a data lake. It’s built on Apache Arrow’s columnar foundation, and offers organizations rapid and scalable query performance for analytical workloads. A native columnar cloud cache (C3) provides fast throughput and rapid response times on Azure Data Lake Storage (ADLS). The software delivers sub-second response times for BI workloads.
Dremio Cloud can combine data located in cloud data lakes, leveraging modern table formats like Iceberg and Delta Lake, with existing RDBMSes. By delivering a semantic layer across all data, it provides customers with a consistent and secure view of data and business metadata that can be understood and applied by all users.
…
Data integrator Fivetran announced support for Delta Lake on Amazon S3. Fivetran customers can land data in Amazon S3 and access their Delta Lake tables. In April Fivetran announced support for Amazon S3 with Apache Iceberg. Fivetran says its no-code platform offers enterprises a simple, flexible way to move data from nearly any data source to any destination.
…
Hitachi Vantara announced the launch of Hitachi Unified Compute Platform (UCP) for GKE Enterprise, a new, integrated hybrid solution, with long-time partner Google Cloud. Through Google Distributed Cloud Virtual (GDCV), Hitachi UCP for GKE Enterprise offers businesses a unified platform to manage hybrid cloud operations. GDCV on Hitachi UCP empowers enterprises to modernize applications, optimize infrastructure and enhance security across hybrid cloud environments by combining the flexible cloud infrastructure of Hitachi UCP with the versatility and scalability of GDCV. The system can deploy and manage workloads within on-premises data centers, cloud environments or edge locations. As part of its launch, GDVC on Hitachi UCP has also been included in Google’s Anthos Ready platform partners program, which validates hardware that works seamlessly with GDCV.
Angela Heindl-Schober.
…
HYCU appointed Angela Heindl-Schober as SVP Global Marketing. Her CV includes global technology companies such as Vectra AI (most recent amd 8-years in place), Riverbed Technology, Infor, and Electronic Data Systems (now part of HPE). HYCU says she has a proven track record spanning over 28 years in global marketing roles. She effectively replaces HYCU CMO Kelly Hopping who went part-time in August this year, and became fill-time CMO at DemandBase in September.
…
TD SYNNEX subsidiary Hyve Solutions recently earned a top annual rating in the Human Rights Campaign Foundation’s assessment of LGBTQ+ workplace equality in the 2023-2024 Corporate Equality Index and has been recognized as a leader of workplace inclusivity in the United States. Hyve sells storage hardware to hyperscaler customers.
…
Informatica has launched enhanced Databricks-validated Unity Catalog integrations. Informatica’s no-code data ingestion and transformation pipelines run natively on Databricks for use with Databricks and Databricks Unity Catalog. The integration gives joint customers a best-in-class offering for onboarding data from 300+ data sources and rapidly prepares data for consumption with an extensive library of out-of-the-box, no-code, proven, repeatable data transformation capabilities.
…
Kinetica announced the availability of Kinetica SQL-GPT for Telecom, the industry’s only real-time offering that leverages generative AI and vectorized processing to enable telco professionals to have an interactive conversation with their data using natural language, simplifying data exploration and analysis. The Large Language Model (LLM) utilized is native to Kinetica, ensuring robust security measures that address concerns often associated with public LLMs, like OpenAI.
…
Lenovo said its latest quarterly (Q2 2024) results made it the number three worldwide storage supplier, having been number four last quarter. Its storage products are sold by its ISG business unit, which recorded $2 billion in revenues. Our records of the latest supplier quarterly storage results are:
Dell – $3.84 billion
NetApp – $1.56 billion
HPE – $1.11 billion
Pure – $762.84 million
Lenovo’s storage revenues thus fall somewhere between $1.56 billion and $1.11 billion. The company said it is seeing clear signs of recovery across the technology sector and will “leverage the opportunities created by AI, where it is uniquely positioned to succeed given its hybrid AI model, pocket-to-cloud portfolio, strong ecosystem and partnerships, and growing portfolio of AI technologies and capabilities.”
…
File collaboration startup LucidLink is launching a film series called Unbound, profiling how creatives are unlocking new possibilities without needing to work from the same office. The first episode will kick off with the creative studio Versus. It will show how they are collaborating across eight time zones and producing their best work with the support of LucidLink.
The series will run throughout 2024, with each episode spotlighting a diverse group of creatives across creators, media, advertising, and gaming. LucidLink says it serves as an indispensable component of their workflow and process.
…
Object First has issued a downloadable case study of its customer Centerbase. This is a cloud-based platform that aids in managing law firms, and their data recovery plans that ensures its backups are protected with out-of-the-box immutability. Centerbase chose Object First’s Ootbi with the goal of reducing restore time from its cloud repository – and ended up decreasing its recovery point objective (RPO) by 50 percent, from eight hours to just four.
…
The SNIA is planning an open collaborative Plugfest colocated at SNIA Storage Developer Conference (SDC) scheduled for September 2024, aimed at improving cross-implementation compatibility for client and/or server implementations of private and public cloud object storage solutions. This endeavor is designed to be an independent, vendor-neutral effort with broad industry support, focused on a variety of solutions, including on-premises and in the cloud.
An SNIA source tells us: “There are many proprietary and open source implementations claiming compatibility, but in reality there are plenty of discrepancies which lead to customer surprises when they’re transitioning from one object storage solution to another.” Some examples were mentioned at SDC.
…
Data analytics supplier Starburst, which is based on open source Trino, announced new features in Starburst Galaxy to help customers simplify development on the data lake by unifying data ingestion, data governance, and data sharing on a single platform. It added support for:
● Near real-time analytics with streaming ingestion: Customers can leverage Kafka to hydrate their data lake in near real-time. Upcoming support for fully managed solutions, such as Confluent Cloud, is also planned.
● Automated data governance: As new data lands in the lake, machine learning models in Gravity – a universal discovery, governance, and sharing layer in Starburst Galaxy – will automatically apply classifications for certain categories. Depending on the class, Gravity will apply policies granting or restricting access. Now, as soon as PII (personally identifiable information ) lands in the lake, Gravity will be smart enough to identify and restrict access to that data.
● Automated data maintenance: abstracts away common management tasks like data compaction and data vacuuming.
● Universal data sharing with built-in observability: With Gravity, users can easily package data sets into shareable data products to power end-user applications, regardless of source, format, or cloud provider.New functionality will allow users to securely share these data products with third-parties, such as partners, suppliers, or customers.
● Self-service analytics powered by AI: New AI-powered experiences in Galaxy, like text-to-SQL processing, will enable data teams to offload basic exploratory analytics to business users, freeing up their time to build and scale data pipelines.
…
Distributed storage supplier Storj announced the launch of Storj Select, which delivers customizable distributed storage to meet specific security and compliance requirements of organizations with sensitive data, such as healthcare and financial institutions. Customer data is only stored on points of presence that meet customer specified qualifications, such as SOC2, GDPR, and HIPAA, with Storj Select. It is also announcing CloudWave, a provider of healthcare data security offerings, as a customer that chose Storj Select to provide compliant data storage.
…
UK IT services company StorTrec has announced a partnership with Taiwanese company QNAP to expand its services to global manufacturers. StorTrec is focused on delivering end-to-end support to data storage manufacturers and its resellers. Prior to the partnership, QNAP only offered warranties with its products. But this partnership will allow QNAP to offer customers a value-added option for full support for their storage solutions, with StorTrec managing all of the support services.
…
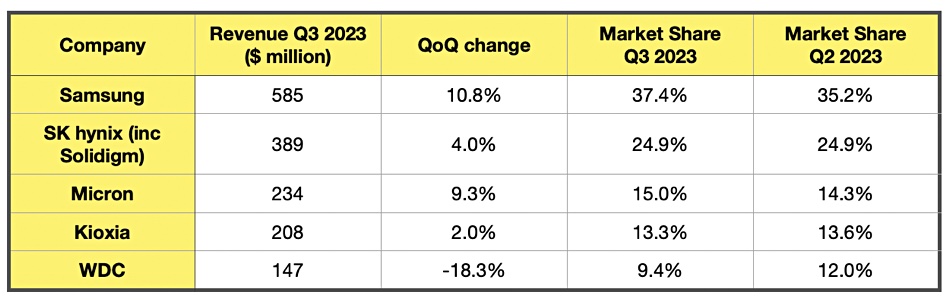
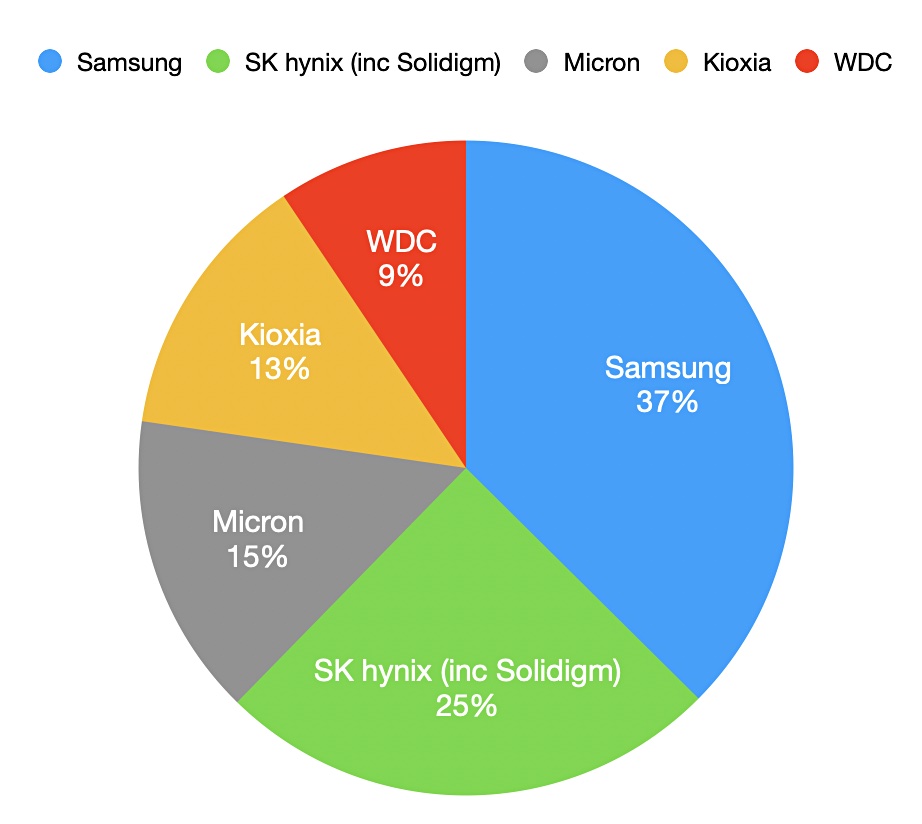
Analyst TrendForce released enterprise SSD supplier revenue shares for Q3 203. It said there has been an uptick in enterprise SSD purchases by server OEMs in 4Q23. TrendForce notes that Micron’s strategic focus on PCIe SSDs in recent years is now paying off, allowing the company to continue increasing its market share even amid subdued enterprise SSD demand. It notes that as other enterprise SSD suppliers shift to technologies above 176 layers, Kioxia’s continued use of 112-layer technology presents challenges in increasing supply flexibility and optimizing profitability. WDC’s enterprise SSD sales were primarily focused on North American CSP clients, who generally maintained conservative purchasing strategies, leading to a continued decline in overall purchases in Q3.
As WDC undergoes corporate restructuring, it is anticipated that the production timeline for PCIe 5.0 enterprise SSDs will be shortened. This constraint could result in WDC’s enterprise SSD revenue growth falling behind that of other suppliers in subsequent periods.
Samsung is anticipated to lead in revenue performance growth among suppliers as the first to mass-produce the PCIe 5.0 interface.
…
AI-enabled data observability and FinOps platform supplier Unravel Data has joined the Databricks Partner Program to deliver AI-powered data observability into Databricks for granular visibility, performance optimizations, and cost governance of data pipelines and applications. Unravel and Databricks will collaborate on go-to-market efforts to enable Databricks customers to leverage Unravel’s purpose-built AI for the Lakehouse for real-time, continuous insights and recommendations to speed time to value of data and AI products and ensure optimal ROI.
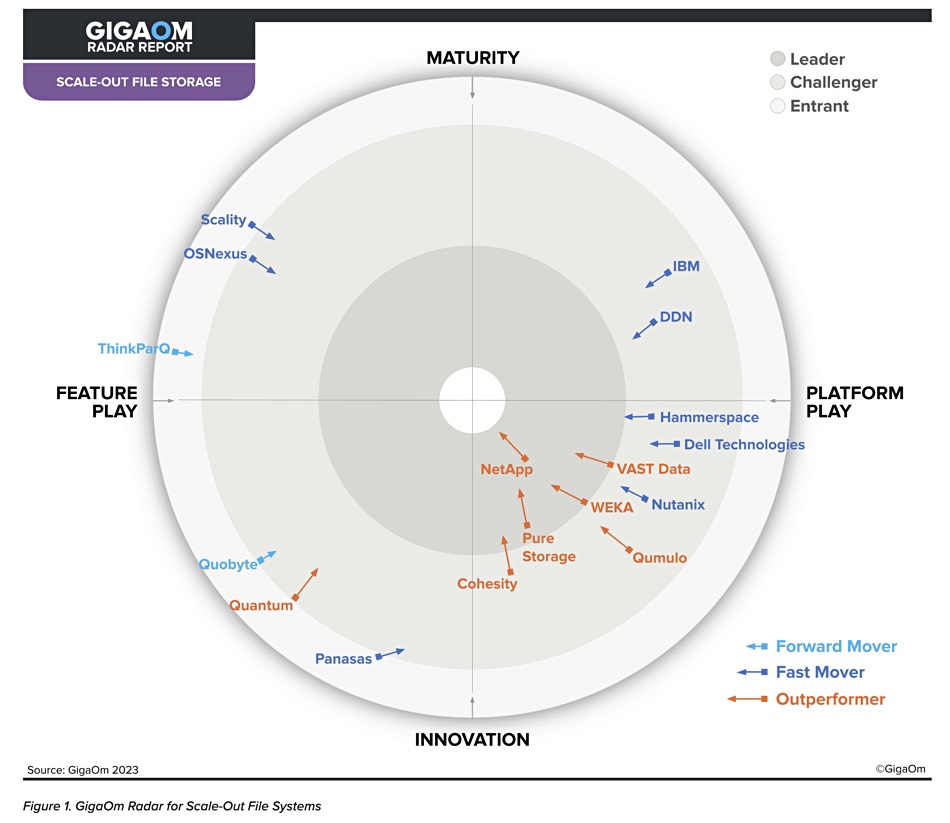
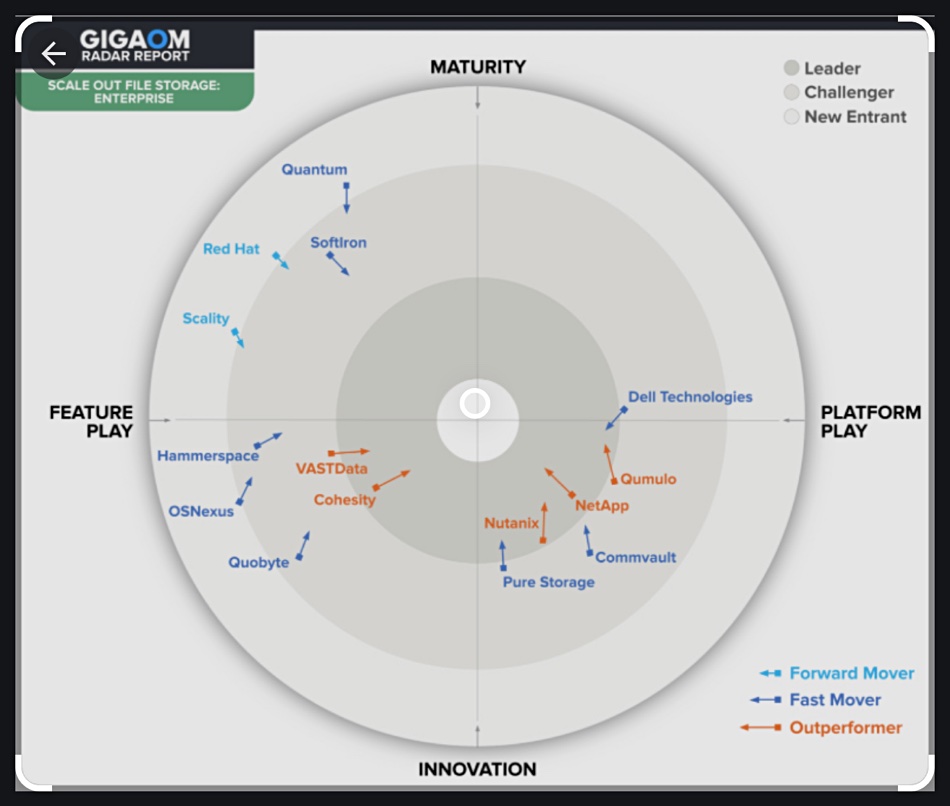
GigaOm has evaluated 17 suppliers of scaleout file storage systems and has placed NetApp out in front with a substantial lead.
The GigaOm Radar report evaluates products’ technical capabilities and feature sets against 14 criteria to produce a circular chart, divided into concentric inner Leader, mid-way Challenger, and outer New Entrant rings. These are separated into quarter circle segments by two opposed axes: Maturity vs Innovation, and Feature Play vs Platform Play. Suppliers are also rated on their forecast speed of development over the next year to 18 months as forward mover, fast mover, and outperformer.
GigaOm analysts Max Mortillaro and Arjan Timmerman said: “The scaleout file storage market is very active. Roadmaps show a general trend toward expanding hybrid-cloud use cases, implementing AI-based analytics, rolling out more data management capabilities, and strengthening ransomware protection.”
The hybrid cloud use cases include integrating file and object storage, and also integrating on-premises and public cloud file storage in a data fabric with the capability of storing files in specific cloud regions.
Here’s the scaleout file storage (SCOFS) Radar chart:
NetApp, Pure Storage, VAST Data, and Weka are the four leaders. The bulk of the suppliers are challengers with Scality, ThinkParQ (BeeGFS), and long-term supplier Panasas classed as entrants.
There are four main groups of the 17 suppliers on the chart:
Mature platform plays: DDN (Lustre) and IBM (Storage Scale)
Mature feature plays: Scality, OS Nexus, and ThinkParQ (BeeGFS)
Innovative feature plays: Quobyte, Quantum, and Panasas
The mainstreamers with innovative platform plays: NetApp, Pure Storage, Weka, VAST Data, Cohesity, Qumulo, Nutanix, Dell Technologies, and Hammerspace.
The analysts sub-divide the mainstream group into outperformers and challengers. They point out: “It’s important to keep in mind that there are no universal ‘best’ or ‘worst’ offerings; there are aspects of every solution that might make it a better or worse fit for specific customer requirements.”
They say NetApp is ahead because of its “broad portfolio options to implement and consume a modern scaleout file system solution based on ONTAP with a complete enterprise-grade feature set, flexible deployment models, and ubiquitous service availability across public clouds.”
The report includes a description of each supplier’s offering and technology situation and its scores out of three on a variety of different criteria.
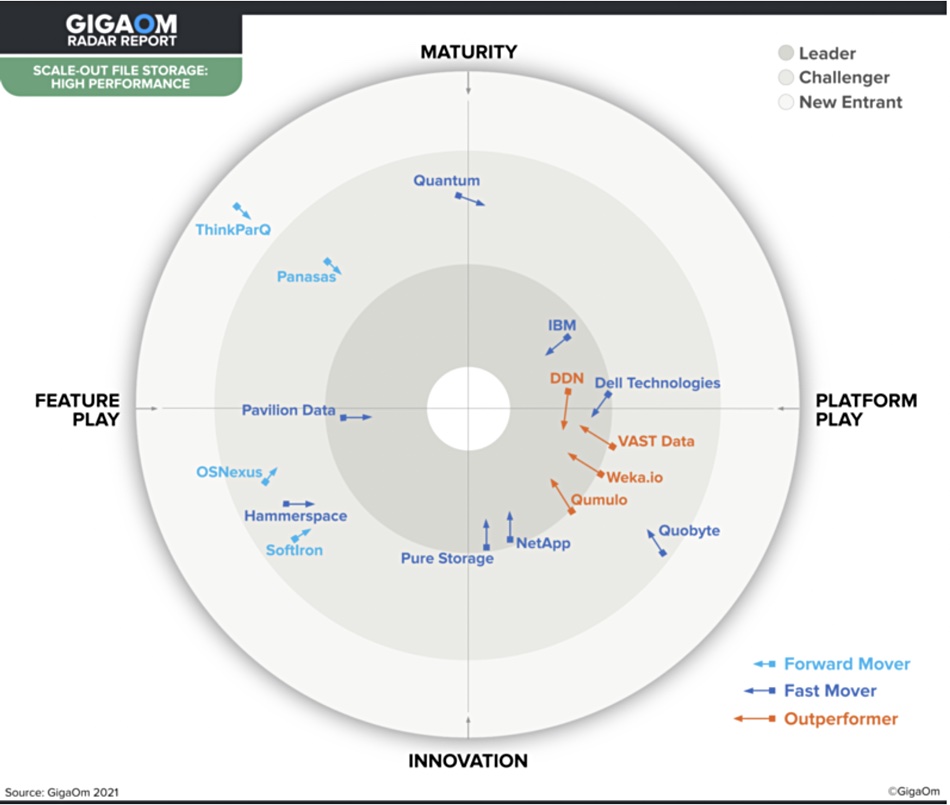
Changes from last year
This year’s scaleout file storage report recognizes that there are two market segments; enterprise and high-performance. Last year GigaOm produced a high-performance SCOFS radar plus a separate enterprise SCOFS report. The changes from a year ago are quite startling. Here’s last year’s high-performance SCOFS:
Last year’s leaders, DDN and IBM, have moved backwards and are now challengers. Pavilion and Softiron have gone away. Scality has entered the scene. Quantum, Hammerspace, Panasas, and Quobyte have all swapped hemispheres. Qumulo has gone backwards. NetApp, despite not being classed as an outperformer in 2022, has wildly outperformed every other supplier. Last year’s outperformer, VAST Data, has hardly moved its position at all, ditto Weka.
And here’s the enterprise SCOFS from last year:
Again, the changes are dramatic with VAST Data, Cohesity, and Hammerspace swapping east and west hemispheres, and Quantum swapping the north for the south hemisphere. Commvault goes away, as does Red Hat (with IBM’s acquisition).
UK-based Disk Archive Corporation, known for its spun-down disk archives, says it now has 350 broadcast and media company customers. Its pitch is that its performance can beat both tape and optical disk archives.
The company was founded in 2008 and developed and sells its ALTO appliance, ALTO standing for Alternative to LTO, a 60-disk drive 4RU chassis and embedded server, with up to 10x 60 HDD expansion chassis for a total raw capacity of 660 x 24 TB HDDs = 15.8 PB. The system can scale out to over 200 PB, and if 26 TB SMR drives are used, the capacity will be even higher.
Alan Hoggarth, CEO and co-founder, briefed an IT Press Tour in Madrid, and talked about the company’s beginnings. “We wanted to break the mold – transcending traditional data tape, video tape, optical disk, and cloud solutions. A large broadcaster could have a million video tapes. Bypass them and stick them on disk,” he said.
ALTO head unit and expansion chassis
His thinking was that Copan’s original MAID (Massive Array of Idle Disks) concept was flawed. This was a disk-based archive that delivered faster access to data than tape archives, and saved on energy costs by spinning down the drives until their content was needed. But it used RAID sets so several drives had to be spun up when data was required, and data could conceivably be lost, Hoggarth said. A v2 MAID based on slowed-down but not spun-down drives wouldn’t deliver the power savings and environmental benefits of fully spun-down drives. However, if you didn’t use RAID sets and fully spun down the disks, a disk archive could provide a lower TCO than a tape archive because there is no need for tape generation migrations or robotic libraries, saving energy and cooling costs.
A tape library needs robotics to bring cartridges to the read/write drives. But a disk archive has no need for robots because each disk is a drive as well.
An optical disk archive is subject to the whims and happenstance events of the restricted set of suppliers, such as Sony closing down optical disk product lines. Similarly, the tape market can be upset by disputes between the duopoly suppliers Sony and FujiFilm, as happened in 2019 with LTO-8 media supply seriously disrupted.
The ALTO active archive system was designed specifically for film production, TV broadcast, and legal evidence (court recording) markets where video and audio assets have to be kept for decades with faster-than-tape access to files when required. It relies on SATA disk drives, which do not suffer from generational media access problems that affect both tape and optical disk. The affordable SATA interface is used because faster SAS or even NVMe access is not needed in the archive access situation. When it takes 60 seconds to spin up a quiescent drive, having a faster interface in the milliseconds area is simply not relevant.
The disk drives in an ALTO system may only spin for 50 hours a year. This vastly reduced active period extends their usable life out to 15 years or longer. Hoggarth noted that helium-filled drives prevent disk motor and spindle lubricant evaporating, which did occur with some air-filled drives.
ALTO is sold as an unpopulated chassis, with customers buying their own disk drives. Hoggarth said: “Data reduction is not feasible with video and audio images. We talk raw data.”
It writes raw data files to a pair of disk drives, and drives can be removed for storage on a shelf on-premises or in an external vault. That means if Disk Archive Corporation goes bust, customers can still read the data from the disk drives. It also provides a physical air-gap, preventing ransomware access.
Hoggarth told B&F: “We write two copies to two identical disks. There is no RAID controller so they’re not mirrored. One disk stays on the appliance. The other is put on the shelf and the pair put in read-only mode.” A person takes out the second drive in a pair, puts a generated QR code on it, then moves it to a shelf location.
Every disk drive has a UUID, a Universal Unique Identifier, and the ALTO software knows and tracks this. The QR code label includes the UUID and the ALTO system tracks QR codes, UUIDs, and shelf locations to know which files/folders are on which disks and where. A management system has a GUI facilitating this.
Alternatively, both disks could stay in the appliance, providing a media-redundant archive. You could make it more resilient against failures with a media-redundant high-availability archive by putting the second disk drive in a pair in a separate chassis.
ALTO systems need active human admins because they have no robotics, unlike tape libraries. Hoggarth said robotics and tape suffer from humidity, needing air conditioning, and have difficulties in humid environments such as in Asia. Disk Archive Corporation’s first customers were in Asia and its no-robotics feature has proved a strong advantage when selling in tropical environments.
Virtually every country has a state or private TV broadcaster and film company, also a legal system, and they will all need video/audio archives. The no-robotics characteristic gave Hoggarth’s company a real edge when selling into tropical countries.
The system’s electricity consumption is low, even with a management system running in a server. Hoggarth said: “We keep a flat file record of everything stored in an server, which adds background power consumption.” The power consumption of an ALTO disk archive system is 210 watts/PB with 22-24 TB disks. As disk capacities rise, the watts/PB number goes down.
Active Archive Alliance members
According to Oracle documentation: “A ten module library with 20 tape drives and 20 power supplies has a total idle power of 338 W (1154 Btu/hr) and a steady state maximum of 751 W (2564 Btu/hr).” The ALTO spun-down disk archive library has lower power consumption than this.
The ALTO system can support a third copy of a disk stored in the cloud as a last resort. The Disk Archive Corporation website has various case studies illustrating different ALTO configurations. There is a reduced depth or short-rack alternative for space-restricted datacenters.
The Active Archive Alliance trade association was set up to advance the idea of an active archive, one with a higher than normal archive data access rate. It is a vendor-neutral forum with members such as FujiFilm, Quantum, SpectraLogic, and others. Curiously, Disk Archive Corporation is not a member, having never seen the need in its clearly defined market niche.
The company has just 15 employees in the UK, Italy, and India. The biggest worldwide market is India by a wide margin. It was Russia but then “bad things happened,” Hoggarth said.
Amazingly, the company owns no IP. Everything is open. The mainstream archive companies ignore this market for spun-down disks. Hoggarth says many of them sell tapes and tape systems and make a lot of money from them. “They have no incentive to change.”
There are around 450 Disk Archive customers and the company is involved in a 100 PB archive project. The rough price range for an ALTO head unit is $24,000-$40,000, depending on features.
In these steadily greening days, the idea of a cheaper and faster-than-tape archive with more longevity that better satisfies environmental, social, and corporate governance criteria could look an attractive proposition.
XenData is developing a media browser for faster location of video file segments to be integrated into its networked disk-based archive for media and entertainment (M&E) customers.
B&F learned about this at an IT Press Tour briefing. The company, known for its X series of tape archives front-ended with a RAID disk cache, also has an E-Series, which is fully disk-based and scales out from one to four nodes, each storing 280 TB in its usable capacity.
XenData E-Series four-node system
E-Series content can be accessed using the S3 object protocol from anywhere using HTTPS, or via the Windows File System locally, with Active Directory security, and NFS, CIFS/SMB protocol support. The system is compatible with many media asset management (MAM) applications so supports collaboration between media teams.
The system has various options to support mirroring files to a second E-Series appliance, to a connected LTO tape library or to public cloud object storage. The archiving to tape or the public cloud moves files there and leaves stubs behind so no changes in access are needed. Logically, the files are still in the E-Series system.
Being disk based, it is very much an active archive system and provides faster access to any file than XenData’s disk+tape X series products. If a file is in the RAID cache, access is as fast as with the E-Series. If it’s on tape, access will be slower, and if on external tape, much slower.
The spun-down disk-based Disk Archive system, with its ALTO product’s one-minute idle disk spin up time, will be faster than a tape library but not as fast as the E-Series. So in an access speed hierarchy, it sits between XenData’s X series products and the E-Series.
CEO Dr Philip Storey said: “Disk Archive has features we don’t have and we have features they don’t. We’re open to working with them.”
Asked about E-Series cost, he said: “Over five years, disk is 2.5x more expensive than tape.”
What about storing archived video data in the cloud rather than on the E-Series? He said that, in general, “at the petabyte level the cloud costs $1.2-1.5 million over five years, and the E-Series is much cheaper.”
There is a break point. “Below 100 TB of capacity use in the cloud, if you have more than 100 to 400 TB then choose on-premises tape or the E-Series. It costs less.”
Media Browser
CTO and co-founder Dr Mark Broadbent told briefing attendees that XenData was developing a media browser in response to customer wishes to find a desired segment in a large video faster than by playing the video and waiting until it appears.
Dr Mark Broadbent presenting to IT Press Tour (photo: Celine Coustaut)
In theory, you could do this with time-stamped metadata tags, with, for example, a tag timed at 10.5 seconds in a football video labelled “Penalty taken.” But it will take a massive effort to manually add such tags to archived videos and AI can’t do it yet. It is simpler to take advantage of the human eye’s scanning ability and display a set of low resolution images, or previews, showing different parts of the video.
The human eye can check these quickly, zoom in on the right one, click it, and then XenData’s system will locate and display the corresponding high-resolution video segment. A 4K video could have proxies displayed with 2 percent resolution.
Broadbent said: “We write a video file twice – once at high depth and once again in at low depth (resolution). You navigate by sight looking at low-density images (previews), which can also play at low depth. Then you can go right to the high-res image.”
He said these low-res previews “are not proxies which are frame-accurate. Our previews are not frame-accurate and quick to write. Proxies can take a long time to produce.”
This Media Browser will be an add-on to the E-Series in 2024. The company will also introduce a XenData Media Cloud in 2024.
Bootnote
Dr Philip Storey
XenData was founded in September 2001 by two ex-Plasmon people, Dr Philip Storey and Dr Mark Broadbent. They were involved with UK-based Plasmon’s UDO, Ultra Density Optical disk storage, which failed to become a viable product.
They self-funded XenData, using money they made in the dot-com era, not wanting to become slaves to investing VCs and product direction demands. Storey and Broadbent did not believe in optical data technology and started XenData to combine disk and tape in an archive.
XenData produced its first product in 2003 and has grown organically since then. It won a TV station installation customer in 2005 which persuaded Storey and Broadbent that their technology had a great fit with entertainment industry needs.
Storey said: “We’re in oil and gas and other markets but M&E is our main market.”
It has more than 1,500 installations in 97 countries with 90 percent being in the media and entertainment category. Customers include broadcasters, TV and film studios, video production companies, post-production, corporate marketing departments, pro sports teams, and churches. Competitors include Quantum and SpectraLogic.
Dell is making a supercharged GenAI data delivery pump with the introduction of a second-gen all-flash PowerScale with smart scaleout capabilities, OneFS enhancements, and ongoing PowerScale SuperPOD validation.
The intent is to make PowerScale an optimized storage offering for both general AI and generative AI workloads.
Arthur Lewis, Infrastructure Solutions Group president, stated: “Storage performance is a critical factor for successful AI and generative AI outcomes,” adding that customers want Dell to remove “data access bottlenecks that limit the throughput and scalability of compute-intensive applications. We are addressing these needs by delivering fast, efficient and secure access to data and turning [PowerScale] into a proverbial goldmine of AI and GenAI possibilities.”
The company claims new PowerScale all-flash storage systems, based on latest generation Dell PowerEdge servers, will enable an up to 2x performance increase for streaming reads and writes.
PowerScale will have new smart scaleout capabilities to improve single compute node performance making for enhanced GPU utilization, and leading to faster storage throughput for AI training, checkpointing, and inferencing.
There are forthcoming OneFS software enhancements so customers can prepare, train, fine-tune, and inference AI models quicker.
Dell is validating PowerScale with Nvidia’s DGX SuperPOD and it is expected to be the first Ethernet storage system validated on the platform.
The company says its APEX File Storage for Microsoft Azure will deliver enterprise-class file performance and management capabilities in Azure, and is suited to the needs of performance-intensive AI and machine learning applications like Azure OpenAI Service and Azure AI Vision.
A Databricks collaboration means customers can choose from a variety of large language models (LLMs) and use libraries from Databricks’ MosaicML to retrain a foundational model with their proprietary data stored in Dell APEX File Storage. This offers flexibility across multi-cloud environments as Dell also has its APEX File Storage in AWS.
18-rack SuperPOD
A SuperPOD-validated PowerScale means customers can ship data to and from SuperPOD GPU factories via Nvidia’s Quantum-2 InfiniBand and Spectrum Ethernet networking, according to Dell. It will also give SuperPOD-loving VAST Data and DDN some competition.
There are no details available on the new PowerScale all-flash system, the OneFS enhancements or the smart scale-out addition. We have asked Dell for further comment.
Availability
PowerScale OneFS software enhancements will be globally available this month.
Next-gen all-flash PowerScale systems and smart scale-out features will be globally available in the first half of 2024, as will Dell APEX for File Storage for Microsoft Azure. PowerScale’s Nvidia DGX SuperPOD validation is expected to complete in the first quarter of 2024.
Dell APEX for File Storage integration with Databricks and MosaicML is available in AWS today and in Microsoft Azure in the first half of 2024. Dell’s open, modern data lakehouse offering will be globally available in the first half of 2024.
MSP 11:11 Systems is launching 11:11 DRaaS for Azure, a new disaster recovery as a service (DRaaS) offering for the Azure cloud. This globally available recovery offering gives organizations customized and fully managed disaster recovery (DR) for their on-premises, Azure cloud and/or multi-cloud environments.
…
Data intelligence supplier Alation released The State of Data Culture Maturity: Research Report. Alation says that building a strong data culture is a strategic imperative for leaders. According to Alation, data culture maturity has four pillars – data leadership, data search & discovery, data literacy, and data governance. The report emphasizes the need for all four, e.g. 89 percent of respondents with strong data leadership say their organizations met or exceeded revenue goals in the past year.
….
CloudFabrix, which describes itself as the inventor of Robotic Data Automation Fabric (RDAF), launched its “Data Fabric for Observability” with dynamic Data Ingestion and Automation service (DIA) for the Cisco Observability Platform. CloudFabrix also demonstrated the use of this service for multiple application modules on the Cisco Observability Platform.
…
Wells Fargo analyst Aaron Rakers talked to Commvault CFO Garry Merrill and tells subscribers Merrill separated Commvault’s total addressable market (TAM) into two sectors: “1. Traditional on-premises data management/recovery as representing a $9-$10 billion TAM growing at an est. 0-2 percent CAGR, and 2. Cloud-based recovery market currently at a ~$2 billion addressable market growing at a 12-13 percent CAGR going forward. CVLT’s portfolio/capability breadth (including integration w/ security) and scale were key highlighted differentiators.” Rakers says: “We model CVLT’s F2024, F2025, and F2026 (FYE = March) revenue growth at +4, +5, and +7 percent y/y, respectively. With CVLT’s Subscription + SaaS momentum (now 74 percent of total ARR, which was +32 percent y/y in 2024; including $131 million in SaaS ARR vs $74 million a year ago), coupled with lessening declining/normalization in traditional perpetual + support revenue, we see increasing potential for CVLT to drive toward double-digit y/y revenue growth looking into F2025-F2026.”
…
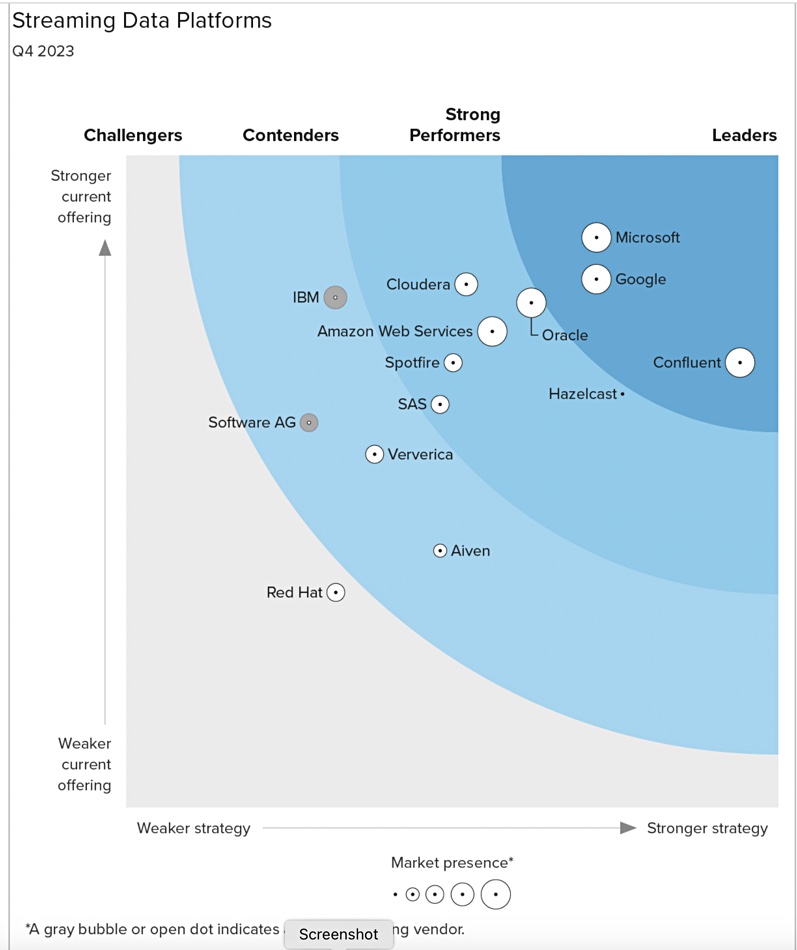
Kafka-using Confluent was named a Leader by Forrester Research in The Forrester Wave: Streaming Data Platforms, Q4 2023. Jay Kreps, co-founder and CEO, said: “We founded Confluent in response to a critical need for reliable, scalable data streams, and we believe our placement as a leader in this category validates our approach to delivering a complete, enterprise-ready data streaming platform.” Get a copy of the report here.
…
Couchbase announced financial results for its third quarter fiscal 2024. Q3 highlights include:
Total revenue was $45.8 million, an increase of 19 percent year-over-year. Subscription revenue for the quarter was $44.0 million, an increase of 23 percent year-over-year.
Total annual recurring revenue (ARR) was $188.7 million, an increase of 24 percent year-over-year, or 23 percent on a constant currency basis.
Gross margin was 88.8 percent, compared to 87.4 percent for the third quarter of fiscal 2023. Non-GAAP gross margin for the quarter was 89.5 percent, compared to 88.0 percent for the third quarter of fiscal 2023.
…
Business continuity and DRaaS supplier Databarracks launched Jump-Start, a cloud-based recovery landing zone. By using Infrastructure as Code (IaC), resources, networking, security, and governance are activated within minutes, ready for a complete recovery. It says Jump-Start delivers the quickest recovery time in a low-cost and secure solution in a disaster invocation.
…
Datadobi announced StorageMAP 6.6 with enhancements including support object storage. It can analyze object data stored on any S3-compliant platform, offering users a complete view of their unstructured data, including both file (SMB and NFS) and object (S3) data. v6.6 also provides richer file copy and movement functionality. Users can search for files based on specific metadata criteria and copy those files to a file or object target. They can easily copy files from a file server to a data lake for normalization and aggregation prior to copying (or moving) training datasets to apps for analytics and/or AI processing.
…
Recovery instructions for lost files in Google Drive were posted yesterday. They start by saying: “How to restore files in Drive for desktop (v84.0.0.0-84.0.4.0). If you’re among the small subset of Drive for desktop users on version 84 who experienced issues accessing local files that had yet to be synced to Drive, please follow the instructions for one of the following solutions below to recover your files.” The process is based on recovering files from a backup.
…
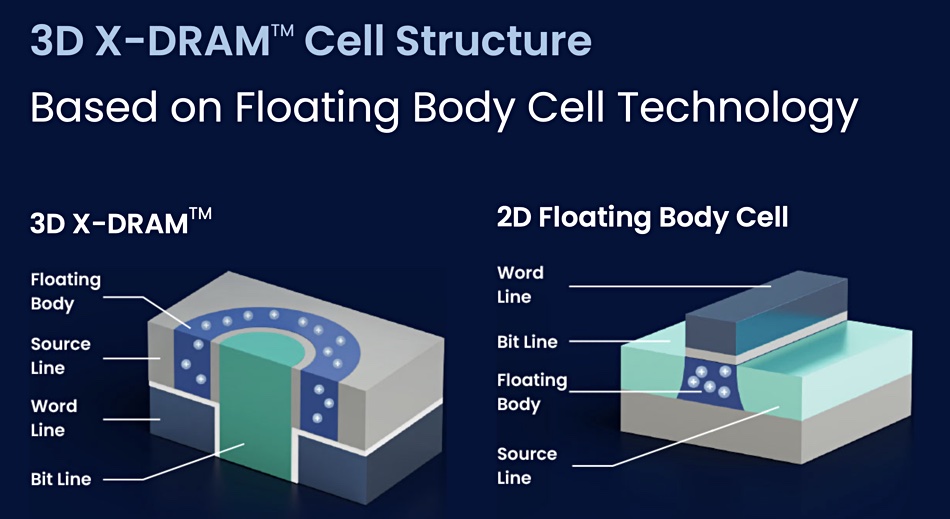
NEO Semiconductor released Technology CAD (TCAD) Simulation Data for its 3D X-DRAM. Semiconductor manufacturers and engineers use TCAD to simulate emerging technologies and optimize new products. Explorations of TCAD models and simulations reveal that 3D X-DRAM supports high sensing margins, retention times, and endurance cycles:
< 1 V (volt) operation voltage
< 3 ns (nanosecond) write time (cell level)
> 20 uA (microampere) sensing margin
> 100 ms (millisecond) data retention time
> 10ˆ16 (10 quadrillion) endurance cycles
Conventional DRAM connects one Sense Amplifier (SA) to a Bit Line (BL) directly. X-DRAM connects one Sense Amplifier (SA) to four Bit Lines (BL) through four Bit Line Select Gates (BLSG). Conventional DRAM performs read and write operations using one word line at a time. X-DRAM allows four word lines (WL) to perform read and write operations in parallel, increasing data throughout by 400 percent during refresh operation. More info here.
“A new memory architecture with 3D DRAM technology will represent the future of memory in order to accelerate and scale DRAM to new levels,” said Jay Kramer President of Network Storage Advisors Inc. The next logical step for Neo would be to build a test chip/
…
Some succinct Pliops predictions for 2024:
There will be a rapid adoption of Retrieval Augmented Generation (RAG) in enterprises using Vector Databases to complement the LLM foundation model.
As inference workloads and costs grow significantly, there will be a rise in startups developing lower-cost performance silicon chips while hyperscalers pursue their custom silicon for inference and startups.
The race to build larger, smarter, comprehensive large language models (LLMs) will continue, resulting in large organizations spending a fortune in the range of $100 million to $0.5 billion.
Sustainability will take center stage – and the IT industry as a whole will experience momentum in higher-density computing and storage options to store and process large datasets in smaller footprints.
There will be increased adoption of key-value stores from traditional applications to Generative AI applications for caching in the Prompt and Token phase of LLMs.
AI-generated media content will become the norm, from basic website designs to generating songs and making Hollywood movies.
…
Pure Storage announced the appointment of Lynn Lucas as its CMO, reporting to COO Matt Burr. She was CMO at Cohesity, from where she was laid off in June. It has a CMO vacancy. She previously worked at Cisco and Veritas, and is the successor to Pure’s previous CMO, Jason Rose, who left in March.
…
Quantum announced that its Myriad all-flash, scale-out file and object storage software platform for the enterprise is now generally available for purchase.
…
Scality CTO Giorgio Regni provided 2024 predictions. He said HDDs will live on, despite predictions of a premature death, notably from Pure Storage. End users will discover the value of unstructured data for AI. Ransomware detection will be the next advancement in data protection solutions. Managed services will become key to resolving the complexity of hybrid cloud. More info here.
…
We asked VAST Data, which uses Storage Class Memory in its storage systems, how VAST works in AWS. Does it run on special hardware that includes Storage Class Memory? Or does VAST have a version that can run without SCM? VAST told us: “The VAST Data Platform on AWS leverages the local EC2 SSD (instance store) to serve both Metadata/Write Buffer (normally on SCM), and capacity (normally on QLC) layers. All I/Os are served from the local instance SSD, making it very fast compared to competing solutions. Persistency is achieved with minimal overhead, using write-only mirroring to EBS for the Write Buffer and Metadata layer, and asynchronous migration to S3 for the data layer. This works very well, thanks to the relatively large Write Buffer. Using Multi-Cluster Manager, the customer can choose burst-only mode (no persistence in AWS), and then the EBS and S3 are not used, allowing for an even lower cost scratch/burst solution.”
…
Veeam announced GA of the Veeam Data Platform 23H2 update including Veeam Backup & Replication v12.1, Veeam ONE v12.1 and Veeam Recovery Orchestrator v7. This latest release includes hundreds of new features and enhancements designed to not only protect enterprise data, but to enable customers to better recover from ransomware and cyber-attacks. New features and enhancements include:
AI-powered built-in Malware Detection Engine performs low-impact inline entropy and file system analysis during backup for immediate detection of ransomware and malicious file management activity.
New Veeam Threat Center highlights threats, identifies risks and measures the security score of an environment.
YARA content analysis helps pinpoint identified ransomware strains to prevent reinfection of malware into an environment; detects the presence of sensitive data in backups (like PII, PHI and PCI data).
Enhanced backup protection prevents accidental or malicious deletion or encryption of backups, including using additional immutability capabilities and the new four-eyes principle to prevent accidental backup or repository deletion.
Greater security for cloud backup ensures least privilege access to backup and recovery tasks with more granular IAM permissions, as well as immutable backups for Amazon RDS PostgreSQL databases.
Security & Compliance Analyzer continuously verifies your backup infrastructure hardening and data protection approaches against best practices to ensure recovery success.
Backup enhancements include:
AI-powered assistant driven by large language models and using product documentation as a context provides real-time access to Veeam’s knowledge, improving efficiency.
Object storage backup strengthens recovery with powerful granular restore capabilities for on-premises or cloud object storage data, secured by an ultra-resilient immutable backup.
Expanded workloads in the cloud to protect Amazon S3, DynamoDB, Azure Blob, Azure virtual networks, and Google Cloud Spanner.
Automated cloud recovery validation saves time by automating the manual post recovery tasks required when recovering an on-premises workload into Microsoft Azure.
Veeam App for ServiceNow offers open integration leveraging ServiceNow workflows to monitor backup jobs, sessions and restore points in a pre-built dashboard with automatic incident creation.
New plug-in for IBM DB2 and support for Linux and SAP HANA running on IBM Power eliminates the need for multiple backup solutions in an IBM datacenter.
IBM 3592 “Jaguar” tape support reduces costs without compromising security by combining Veeam’s air gapped data protection with low-cost storage at enterprise scale.
Expanded Enterprise Capability with support for large volumes on NetApp ONTAP FlexGroups, instant recovery for PostgreSQL, and integration with native backup immutability on EMC Data Domain and HPE StoreOnce Catalyst Copy storage
.…
Veeam announced the promotion of Tim Pfaelzer to GM and SVP of EMEA. He is responsible for Veeam’s business operations across all segments and markets across the region.
…
VergeIO announced the immediate availability of VergeOS Small Data Center (SDC) Edition. It is more than a competitive swap out of VMware Essentials, being a significant capability upgrade and lowering costs. VergeOS SDC includes everything included in VMware Essentials plus advanced storage services, live virtual machine migration, advanced layer two and layer three networking capabilities, and ransomware protection. Also, unlike VMware Essentials, the VergeOS SDC Edition isn’t limited to three servers.
VergeOS is priced per physical server, regardless of resources. With the launch of VergeOS, SDC organizations have the opportunity to improve cost savings even further. Any customer who participates in a demonstration of the VergeOS before December 15th will receive an offer to buy one node license and get the second free, or buy two node licenses and get two node licenses free (matching the term of their subscriptions).
…
Veritas is scaring us with research revealing that one in ten business execs fear their business will not survive the next 12 months, while half of executives and IT teams say data security is one of the biggest threats facing their business. It says the study shows the extent to which there is fear that cybersecurity presents a very real threat to businesses’ survival, and in turn how many businesses are fearful of their survival over the next 12 months. For more survey findings on the global picture, download the report: Data Risk Management: The State of the Market—Cyber to Compliance.
…
BMC-acquired Model9 has competition. VirtualZ Computing, which provides the Lozen out-of-the-box product to connect mainframes to hybrid cloud for bi-directional data access, has raised $2.2 million in seed financing led by Next Frontier Capital. Additional investors include 2M Investment Partners, Innosphere Ventures, and Next Coast Ventures. Including prior funding, VirtualZ has raised $4.9 million to date. The Lozen product, available now, enables hybrid cloud, SaaS, distributed and custom applications to gain real-time, read-write access to mainframe data. Data isn’t moved; instead, all apps share the data equally as a peer with mainframe applications. The software installs in minutes and runs on the zIIP engine, consuming a fraction of the capacity of a general processor. Minneapolis-based VirtualZ says it’s the only woman-founded mainframe company in history – but it was actually co-founded by a woman, CEO Jeanne Glass, and two men, CTO Vince Re and SVP GLobal Alliances Dustin Forum.
DataCore is updating its SANsymphony software with block-level tiering to move cold data to less costly secondary storage.
In an IT Press Tour briefing, Alexander Best, DataCore senior director for product management, said that 90 percent of data in SANsymphony deployments is cold. When users access a LUN, a logical chunk of storage, the cold and hot data blocks are mixed. He noted that traditionally, a LUN could be optimized for either performance or capacity, but not both. SANsymphony v10, currently in preview, will include Adaptive Data Placement to fix this.
Best said: “We’ll compress stale data at the block level. It’s continuous real-time, auto-tiering with inline dedupe and/or compression.” This “overcomes the all-or-nothing dilemma of LUNs.”
The adaptive data placement software splits a virtual disk container into small chunks that can go anywhere. SANsymphony has various storage tiers and a background capacity-optimized tier contains deduplicated and compressed data. There are policies setting block access frequency cut-off points for deduplication and compression, with overall aggressive, normal, and lazy policies.
SANsymphony continuously tracks data access frequencies (temperatures) and moves colder data from any tier to the capacity-optimized tier as per chosen policy. Based on ongoing access frequency, it can dynamically relocate data to the appropriate tier in real time, including tiering to/from the capacity-optimized tier.
Best claimed the approach is unique and allows for the optimization of both performance and cost (capacity). It may be unique now, but it wasn’t a decade ago.
Back in 2010, Dell-acquired Compellent had FluidData storage which used block-level tiering. Compellent’s data progression technology tracked disk block activity and moved a block of data up and down storage tiers, from SSD through Fibre Channel, SAS, and SATA drive tiers. Each block had metadata associated with it. Dell acquired Compellent and in 2013 its FluidFS technology could run on demand, and move relatively inactive SLC flash data to MLC, then to and through disk tiers.
By 2017, the Compellent branding had been replaced by SC, and that brand and separate product line disappeared after 2018 when Dell unified its branding with a “Power” prefix and consolidated products. The FluidFS technology then faded from view.
VAST Data has raised $118 million in new funding for a $9.1 billion valuation, with total cash raised hitting $381 million.
The company provides parallel, scale-out access to file and object data with disaggregated controllers and storage nodes using a single tier of QLC (4 bits/cell) flash and metadata access accelerated by storage-class memory SSDs. This platform, certified for Nvidia GPUDirect access, has a data catalog and database built on it with a data engine coming that promises to enable AI processes to discover new insights about the data it analyzes. With the ongoing supercharged generative AI hype, it’s a great time to raise VC money.
Renen Hallak
VAST said the funding will advance its mission to deliver a new category of infrastructure that puts data at the center of how systems work. There are no details on how the cash will actually be spent. In fact, co-founder Jeff Denworth said: “This funding is simply being used to raise awareness of VAST and our mission … VAST operates its business on a cash-flow positive basis. We’ve managed to build a company which can triple its business annually while not burning through mountains of venture capital … This new Series E funding will sit in the bank and collect interest alongside the funding we received from Series B, Series C, and Series D.”
Renen Hallak, CEO and co-founder, added: “To be truly impactful in this era of AI and deep learning, you not only want to have a lot of data, but also high-quality data that is correctly organized and available at the right place, at the right time. The VAST Data Platform delivers AI infrastructure that opens the door to automated discovery that can solve some of humanity’s most complex challenges.”
Denworth elaborated in a blog: “As machines become more capable, they will also be able to reason about the natural world and create new discoveries in the areas of math, science, and even the arts. AI-discovered advancements for clean energy, food abundance, and human health are on the immediate horizon.”
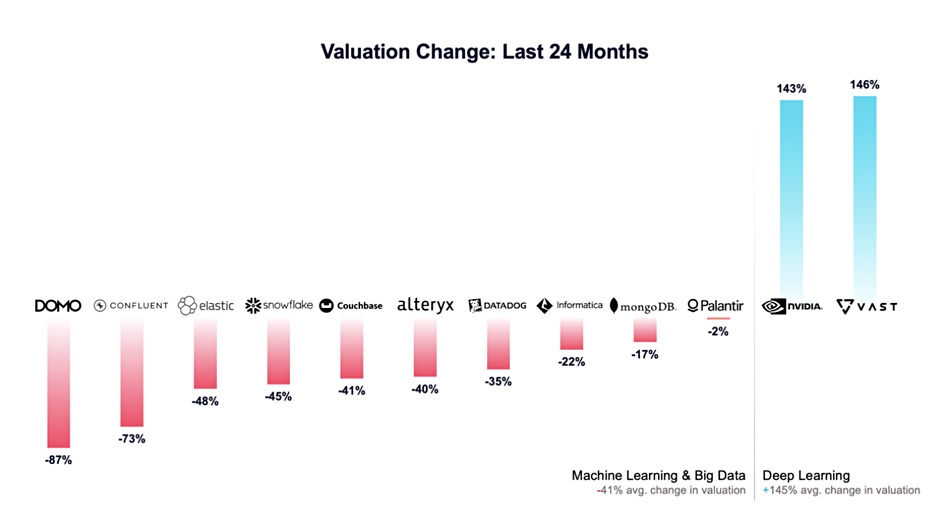
It says its valuation increase parallels that of Nvidia, as a chart indicates:
The company claimed its growth rate means that it will surpass $1 billion in cumulative software bookings. It says it has achieved 3.3x year-over-year growth and maintained positive cash flow for the last 12 quarters with a gross margin of nearly 90 percent.
VAST now has more than 700 employees worldwide, and is actively broadening its business footprint, penetrating new regions in Asia-Pacific, the Middle East, and Europe. That involves a lot of spending.
The valuation of $9.1 billion is a more than 2x raise on the $3.7 billion valuation at the time of VAST’s last funding round for $83 million in 2021. Since then the company has pulled in partnership deals with GPU-as-a-Service cloud providers CoreWeave and Lambda Labs, secured the Texas Advanced Computing Center (TACC) as a customer, and landed an OEM deal with HPE for its GreenLake File Services software. With this growth, VAST Data is a prime VC funding target, even though it doesn’t need the cash.
The new round was led by Fidelity Management & Research Company accompanied by New Enterprise Associates (NEA), BOND Capital, and Drive Capital. Even though VAST is not a public company, it’s thought that VAST may use some of the cash for share buybacks so employee stock options could be turned into cash.
Looking ahead, Denworth said: “Over the next 12 months you’ll see a lot more focus on cloud, zero-trust, [and] the AI computational layer.”
Micron has updated its 176-layer 3400 workstation SSD to the 3500, which uses 232-layer NAND Technology, claiming best-in-class SPECwpc performance.
The raw performance numbers of this M.2 2280 with TLC flash are significantly better than the 3400, with both using an NVMe PCIe 4 x 4 interface and having 512 GB, 1 TB, and 2 TB capacity points. It delivers up to 1,150,000 for both read and write IOPS compared to the 3400’s 720,000 random read and 700,000 random write numbers. The sequential bandwidth is up to 7 GBps for both read and write with the 3400 pumping out up to 66 GBps when reading and 5 GBps when writing. Latency numbers of 50μs read/12μs write also improve on the 3400’s 55μs read/14μs write. The endurance numbers are the same with up to 1,200 TB written in its working life and a 2 million hours MTBF rating.
Prasad Alluri, Micron VP and GM of Client Storage, stated: “With impressive specs like a remarkable 132 percent improvement in scientific computing benchmark scores, the 3500 SSD will turn your next PC or workstation into a powerhouse to enable insights and empower creativity.”
However, Micron’s 3500 SPECwpc benchmark result has not been published as of December 6, meaning it is based on its internal testing with no workstation configuration details published either (see bootnote below).
Micron claims it loads the biggest, newest games like Valorant up to 38 percent faster than the top four competitive suppliers of client OEM SSDs by revenue as of November 2023. Again, this is internal testing with no numbers exposed. The drive also supports Microsoft’s DirectStorage.
It says content creators who work with native 4K and 8K video can load and edit files faster with the 3500 SSD.
The Micron 3500 is now shipping to select PC OEMs.
Bootnote
The SPECwpc benchmark measures aspects of workstation performance based on more than 30 professional workloads to test CPU, graphics, I/O, and memory bandwidth. The PCs involved obviously have storage, such as M.2 SSDs, and the benchmark results publicize the workstation configurations.
SPECwpc can be used by vendors to present benchmark results for different vertical market segments like energy, life sciences, media and entertainment, and more. Larger scores indicate greater speed. SPECwpc 2.1 runs under the 64-bit versions of Microsoft Windows 7 SP1, Windows 8.1 SP1, and Windows 10.
Kioxia believes SATA SSDs disappearing and has launched an updated value-SAS SSD, saying it’s available in HPE’s Gen 7 ProLiant servers and being used in HPE’s Spaceborne Computer-2 (SBC-2).
The RM5 line was first announced by Toshiba in 2018, shipping in 2019, and positioned as better than SATA with more IOPS and bandwidth through its single 12Gbps port. The drive used 64-layer 3D NAND in TLC (3bits/cell) format, and came in 960 GB, 1.92 TB, 3.84 TB and 7.68 TB capacities. It was priced, Kioxia claimed, at SATA SSD levels. The RM6 gen 2 version, with the same capacities and 96-layer TLC NAND, was announced in 2022, with the Toshiba Memory business having been sold off and renamed Kioxia. Now we have the RM7, with the same 960 GB, 1.92 TB, 3.84 TB and 7.68 TB capacity points.
Faraz Velani, senior director and head of Go-to-Market for the Kioxia SSD Business Unit, provided a debut statement for the drive: “We are now proud to launch the 3rd generation of our Value SAS product line on HPE servers. With outer space being the most rugged and the furthest edge environment there is, we are very excited to have Value SAS as the core storage technology supporting HPE SBC-2 over the next several years, targeted for the International Space Station.”
The RM7 is the RM6 upgraded, we understand, to 112-layer TLC 3D NAND technology, but with the same capacity points as the RM5 and RM6. Like the RM6 it comes in 1 Drive Write per Day (DWPD) RM7-R read-optimized and 3DWPD RM7-V mixed use versions. The mixed use version (3DWPD) has a lower maximum capacity, with only 960 GB, 1.92 TB and 3.84 TB capacity points available.
Kioxia has a flagship HPE customer story with the RM7 and its use in HPE Spaceborne Computer-2. Norm Follett, Senior Director of Space Technologies & Solutions, HPE, had something flattering to say about this: “To further accelerate exploration with our Spaceborne project, HPE needed a storage technology that could handle the rigorous and harsh environments of space. Value SAS technology delivered on all the requirements and we’re pleased to collaborate with KIOXIA for our next mission to the ISS scheduled in January.”
We learnt about this from Kioxia in February this year, with the actual SSD product details withheld. Now we know. It’s the RM7 drive enjoying an HPE-assisted launch into orbit.