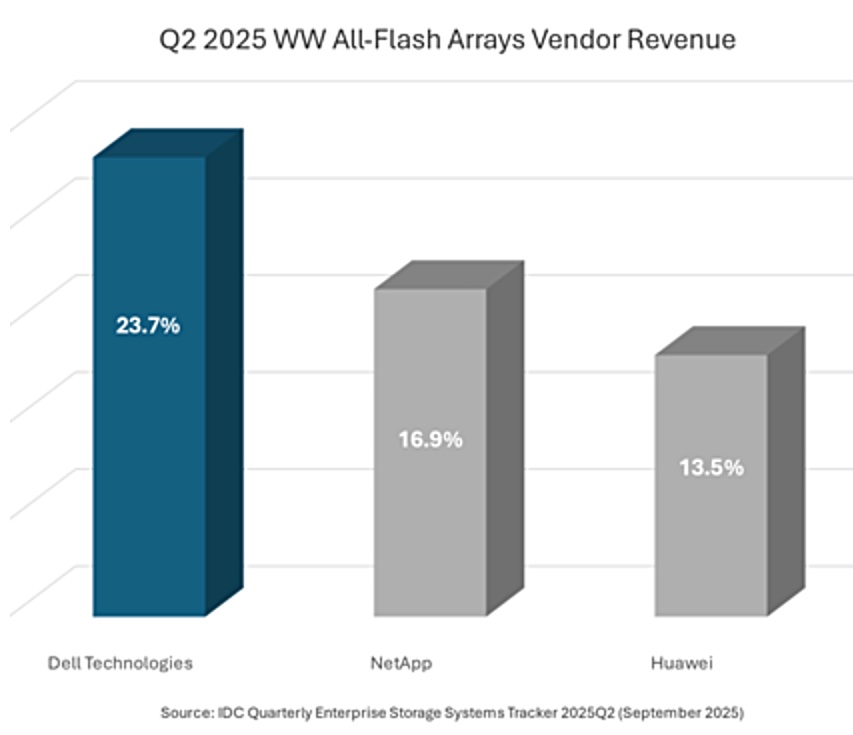
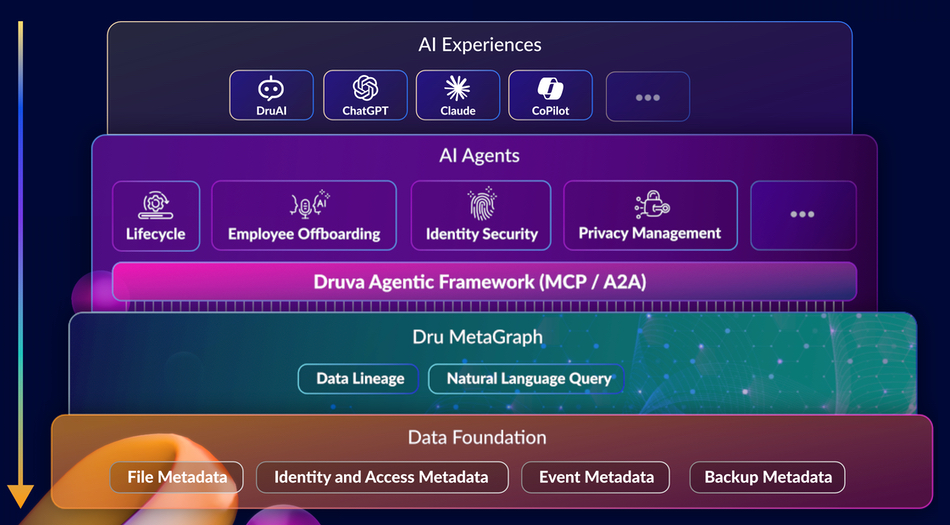
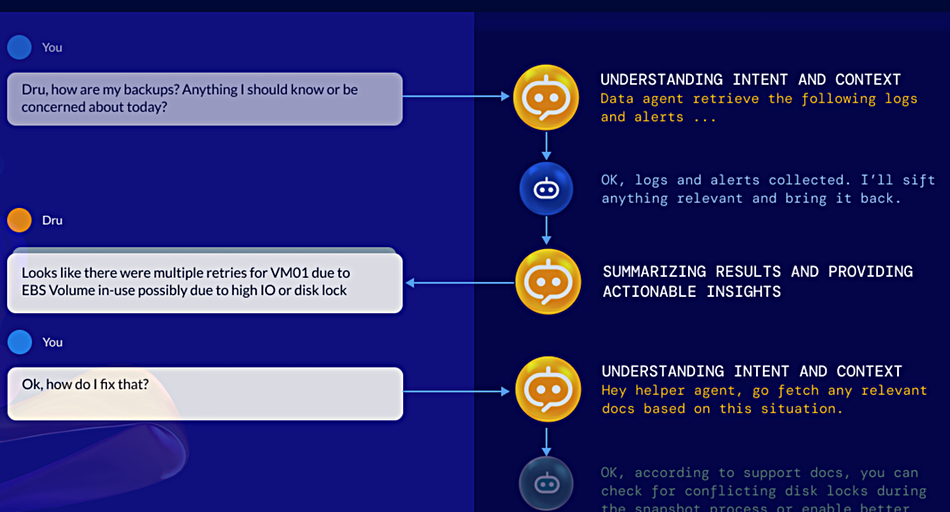
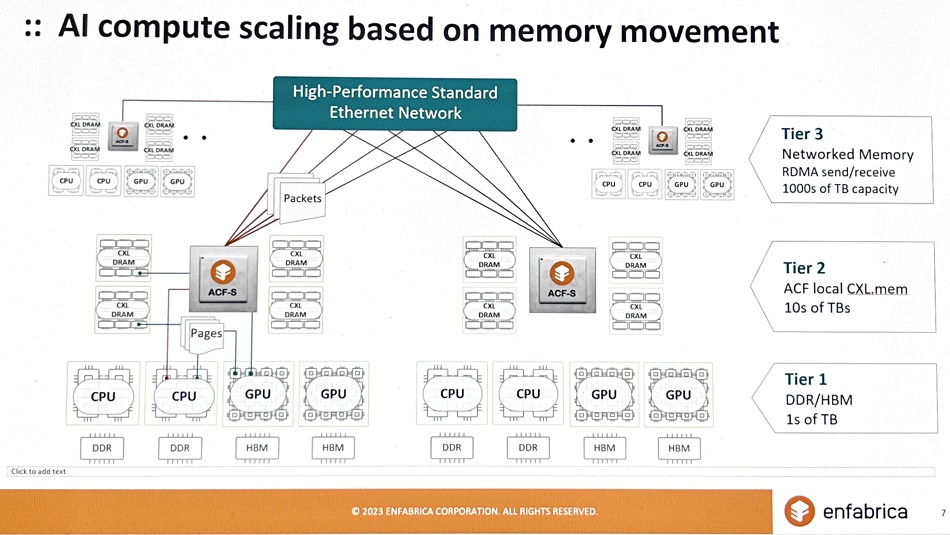
Acronis will incorporate Seagate’s S3-compatible Lyve Cloud Object Storage into its Acronos Archival Storage offering to help enable MSPs to deliver services with more cost-effective, and compliant storage. Learn more here.
…
China’s Biwin has introduced a prorietary MicroSSD card-like Mini SSD product, 15.0 mm × 17.0 mm × 1.4 mm in size, supporting PCIe gen 4, and delivering pp to 3700 MB/s sequewntrial read, 3400 MB/s write speeds. It uses TLC 3D-MAND, Land Grid Array (LGA) packaging and has 512 GB, 1 TB, and 2 TB capacities. It has a modular slot design, enabling plug-and-play functionality and wide compatibility with diverse devices, including laptops, tablets, smartphones, handheld gaming consoles, cameras, NAS systems, smart albums, and portable SSDs.
…
BlackFog, a global cybersecurity company providing on-device anti-data exfiltration (ADX) technology, announced a distribution partnership with Exertis Enterprise to expand BlackFog’s presence across the UK and European markets and equip resellers and service providers to deliver advanced prevention against unauthorised data exfiltration and evolving AI-enabled threats.
…
Data protector Commvault announced the findings of its latest report with ESG which assesses the real-world impact that its Cleanroom Recovery and Cloud Rewind offerings are having on customers worldwide. It found that customers:
- Reduced recovery times by 99 percent
- Rebuilt cloud infrastructure 94 percent faster
- Improved testing frequency by 30 times
- Reduced testing time by 99 percent
…
Cristie Software, which supplies system recovery, replication, and migration technologies, announced GA of Cristie System Recovery PBMR (PowerProtect Bare Machine Recovery) for Dell Technologies PowerProtect Data Manager. This new integration extends PowerProtect Data Manager environments with full system recovery capabilities, enabling bare machine recovery (BMR) to physical, virtual, or cloud-based targets. PBMR also features powerful automated recovery tools, including Continuous Recovery Assurance, which automatically performs a full system recovery within a clean room environment whenever a new backup is detected on a protected system. PBMR enhances Cristie’s system recovery portfolio, joining existing solutions for Dell Technologies Avamar and NetWorker platforms.
…
Databricks is partnering with London based AI startup Applied Computing to tackle emissions from heavy industry in India. Applied Computing is one of only three British AI startups to develop their own foundational model (others being Synthesia and Wayve). It’s developed Orbital, the first foundation model designed specifically for complex energy environments, including refining, upstream operations, LNG, and renewables. Orbital is built on physics-inspired, domain-specific AI that delivers accuracy, explainability and real-time optimisation at scale. It can cut energy operations emissions by 10 percent. By embedding Orbital into the Databricks Data Intelligence Platform, customers in energy and utilities can access industry-specific AI models directly within it.
…
Dell has updated its PowerProtect (deduping backup target) product set:
- PowerProtect Data Domain All-Flash appliance is now available, enhancing cyber resiliency with up to four times faster data restores and two times faster replication performance.
- PowerProtect Data Manager now features new ecosystem, security and virtualization enhancements.
- PowerProtect Cyber Recovery now supports Data Domain All-Flash and CyberSense Analytics support for Commvault client-direct backups of Oracle databases.
- PowerProtect Backup Services can now leverage Microsoft Azure Storage as a backup target.
…
The EU’s General Court has rejected a challenge to the European Commission’s approval of the EU-US Data Privacy Framework, the system that allows certified US companies to receive personal data from Europe under strict privacy rules. The challenge, brought by a French MEP, argued that US surveillance powers remain too broad and that the new US redress body lacks independence. The Court disagreed, finding that although the US has wide surveillance powers, they are subject to checks and remedies that are sufficient under EU law.
…

Postgres-compatible SQL and real-time data analytics and AI platform supplier Firebolt has promoted its president, industry veteran Hemanth Vedabargha, to CEO. He succeeds co-founder Eldad Farkash, who will now serve as Firebolt’s chairman of the board. Firebolt’s decoupled metadata, storage, and compute architecture gives organizations the flexibility to run in the cloud or self-host, while maintaining the same efficiency, Iceberg support, and Postgres compatibility.
…
UK-based Firevault has launched its three Firevault products:
- Vault: A secured offline digital vault for directors, shareholders, HNWIs, family offices, and professionals. Protects board papers, contracts, financial records, identity documents, investments, IP, and personal archives. Identity-locked to one verified owner, available in 2 TB, 4 TB, and 8 TB models from £360/month, with Backup Vault and Vault Buddy for continuity.
- Storage: A scalable secured offline data storage system for enterprises and industries. Keeps crown-jewel, commercial, critical, and customer data physically disconnected and unreachable. Acts as the “0” in the 3-2-1-0 model, delivering risk reduction and 30-plus percent OPEX savings versus connected systems.
- Platform (FV-PaaS): An offline-first platform with nine offline modules, designed to help organisations take control of their data and protect critical assets. Supports secure, multi-site, sovereign-grade deployments for governments, enterprises, and critical infrastructure, ensuring sensitive information remains disconnected and beyond attacker reach.
…
Gartner produced a new Enterprise Storage Platform Magic Quadrant with Pure Storage topping the charts, followed by NetApp, HPE, Huawei, IBM, and Dell in the top right Leaders’ box. Hitachi Vantara is the sole Visionary with DDN and IEIT Systems Niche Players. There are no Challengers. How long will it be before VAST Data and Infinidat appear in this chart? They are definitely enterprise storage platform suppliers but can’t pass Gartner’s stiff exclusion criteria barriers – which will be a source of satisfaction, if not relief, to the suppliers that do.
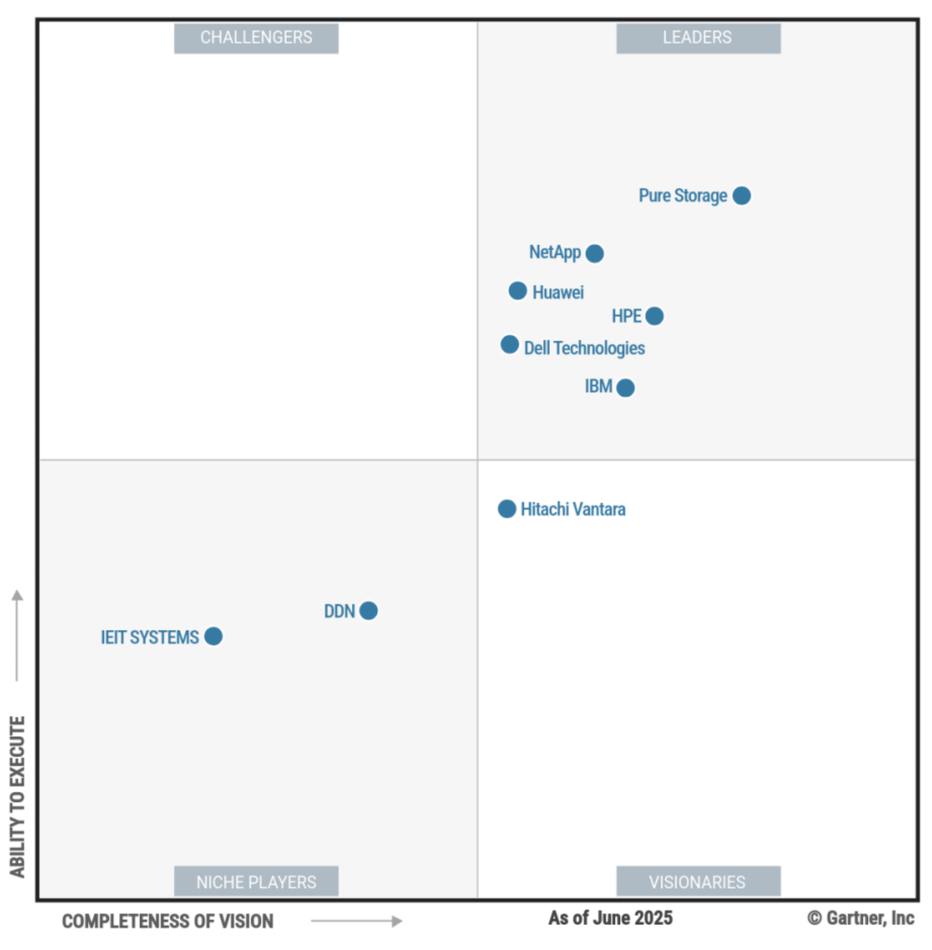
HPE said: “This marks the 16th consecutive year of recognition as a Leader for HPE’s Ability to Execute and Completeness of Vision.” Get the full report from HPE here, from NetApp here, and Pure Storage here.
Gartner says this is a new MQ, so no vendors have been added or dropped. It says: “Vendors must have a minimum total product and services revenue of $325 million (excluding support and maintenance), with at least 25 percent of total revenue coming from unstructured data product revenue. In addition, unstructured data product revenue must have a minimum year-over-year growth of 15 percent, as reported through 31 May 2025.” This and other restrictions exclude VAST Data and Infinidat.
A look at Gartner’s 2024 Primary Storage Platform MQ shows notable differences. As this 2025 Enterprise Storage Platform MQ is a new report, we shouldn’t make any comparisons. HPE’s comment certainly implies it’s comparing its status with previous such Gartner MQs though. As, obliquely, does a statement from Pure: “For the previous five years, Pure Storage was positioned highest and furthest in the Gartner Magic Quadrant for Primary Storage Platforms.” Here, therefore, we show the 2024 Primary Storage Platform MQ so that, like HPE and Pure, you won’t make any comparisons 🙂
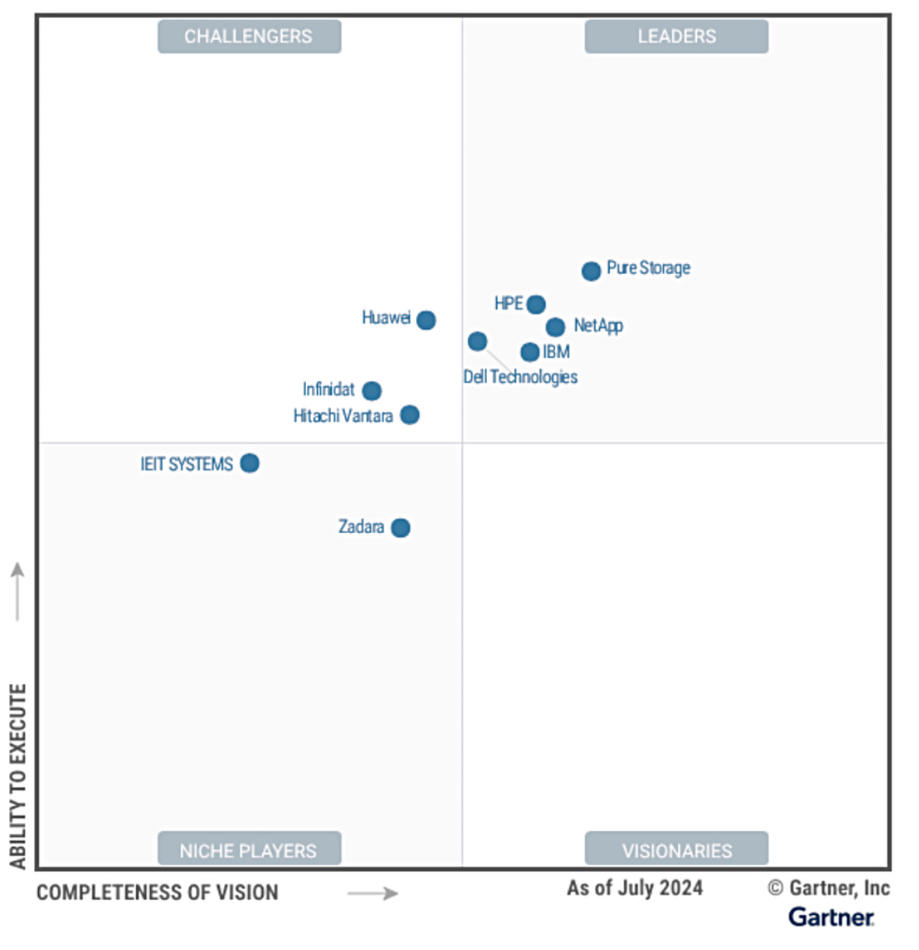
A March 2025 Voice of the Customer research report from Gartner found that primary storage customers prefer Huawei, Infinidat, and NetApp over Dell, HPE, Hitachi Vantara, Pure Storage, and other suppliers.
…
Hardware RAID supplier Graid Technology, Giga Computing, and Miruware signed a Memorandum of Understanding focused on South Korea. The trio will ensure seamless integration of Graid’s GPU-accelerated storage solutions into Giga Computing’s server platforms, pursue technology integration initiatives, co-developing optimized solutions tailored to the needs of South Korean enterprises. They will engage in joint marketing and outreach, amplifying awareness of next-generation server and storage innovations, and collaborate on customer development, including lead generation, solution demos, and after-sales services.
…
A Forrester Total Economic Impact (TEI) study found that customers using Hitachi Vantara’s Virtual Storage Platform One (VSP One) storage product have achieved a 285 percent return on investment (ROI), $1.1 million in net present value (NPV) and payback in just seven months. The TEI study evaluated the VSP One experiences of six decision-makers across North America, Europe and Asia Pacific. Download the study here.
…
Earth Sciences New Zealand (formally NIWA) of Aotearoa selected HPE’s Cray XD2000, purpose-built for AI and simulation workloads, to accelerate the organization’s environmental science and precision of meteorological forecasting. The new system, named Cascade, replaces an aging Earth Sciences New Zealand’s HPC system, delivering 3x more computing power to run multiple AI-powered simulations simultaneously for more accurate weather predictions. It supports Earth Sciences New Zealand’s mission to strengthen the country’s resilience against weather and climate-related hazards, such as wildfires and flooding from heavy rainfall. Cascade is powered by AMD 4th Gen EPYC processors and tightly coupled with HPE GreenLake for File Storage to deliver a highly performant, simplified storage environment and enable 19 petabytes of data to accelerate local research, supporting faster decision-making and more informed crisis management.
…
Global AI and data consultancy Indicium has new funding from Databricks Ventures, the strategic investment arm of Databricks. Indicium and Databricks have been partners since 2017, working to modernize data platforms and deliver AI systems to some of the world’s biggest companies, including Burger King, PepsiCo and Volvo. Going forward, Indicium will be more tightly integrated with Databricks’ product roadmap, including Agent Bricks and Lakebase, engineering resources, go-to-market efforts and training. Indicium will work more closely with Databricks on features such as advanced AI capabilities, Unity Catalog enhancements and Lakehouse upgrades. And Indicium and Databricks will work to co-develop AI and data solutions.
…

Cloud-based SaaS data protector Keepit appointed Jan Ursi as VP of Global Channel. He has led partner and alliance initiatives at Rubrik, UiPath, Nutanix, and Infoblox, and earlier helped expand NetScreen and Juniper in Europe.
…
Japan’s Nikkei reports Japan will provide Micron Technology a ¥536 billion ($3.63 billion) subsidy for R&D and capital spending at its fab in Hiroshima, Nikkei Asia reports. Micron plans to invest ¥1.5 trillion to expand the fab to a maximum capacity of 40,000 wafers per month and make advanced memory chips there by end of fiscal 2029, so ¥500 billion of the subsidy will cover a third of that cost, while the other ¥36 billion is for R&D over five years.
….
During the week of Sep 18, RDIMM demand has increased unexpectedly. Wedbush analysts say eSSD demand has lifted significantly, in line with greater RDIMM demands, driving NAND ASPs higher. A large portion of this increase appears tied to greater CSP requirements for compute SSDs. However, a shortage of HDDs (and the need to find other storage) also appears to be creating incremental demand for QLC. It thinks Micron’s revenues will be karger as a result of this unexpected shift.
…
MSP-focused data protector N-able has launched Anomaly Detection as a Service (ADaaS), to strengthen Cove Data Protection’s defense against cyberthreats, with no additional management or cost impact. The first available ADaaS capability, Honeypots,is an always-on defense mechanism designed to detect brute-force attacks on infrastructure. Honeypots will be able to identify access attempts by unauthorized parties, ensuring that infrastructure and data remain fully protected. N-able plans to expand Cove’s Anomaly Detection functionality with capabilities including critical configuration changes, which will alert users to suspicious backup policy modifications.
…
A NAKIVO Backup & Replication release will enable customers (enterprises, SMBs and MSPs) to store backups anywhere: local, cloud, deduplication appliances, file shares and even tape with immutability, encryption, air gapping and other cybersecurity features supported. The new features/enhancements are designed to deliver disaster resilience, near-zero downtime and data loss across diverse IT environments – while also simplifying accessibility and MSP-tenant management. Should there be any incident or disruption to an organisation’s digital assets, data can be seamlessly restored.
…
The PCI-SIG announced the PCI Express 8.0 specification is well underway, with revision 0.3 now available to members. Check out a blog post below to learn more. PCIe 8.0 spec feature objectives:
- Delivering 256.0 GT/s raw bit rate and up to 1.0 TB/s bi-directionally via x16 configuration
- Reviewing new connector technology
- Confirming latency and FEC targets will be achieved
- Ensuring reliability targets are met
- Maintaining backwards compatibility with previous generations of PCIe technology
- Developing protocol enhancements to improve bandwidth
- Continuing to emphasize techniques to reduce power
…
Pinecone has just become the first and only vector database integrated into Mistral AI’s Le Chat platform, as part of that company’s major enterprise expansion. The integration is part of Mistral’s broader push to become the enterprise AI assistant of choice, featuring 20+ connectors across data, productivity, and development tools from Notion, Asana, PayPal and others. This makes Pinecone the sole vector database available to Le Chat’s growing user base across free and enterprise tiers, enabling users to search and analyze vector data directly within their AI workflows.
…
Aquant, an Agentic AI platform for service organizations that maintain complex equipment, chose Pinecone’s vector database to replace its previous previous vector search infrastructure, built on PostgreSQL extensions, which was too slow. The results:
- 98 percent retrieval accuracy
- Cut full response time from ~24s to ~13.7s
- Initiated responses 2x faster at 2.89s
- Reduced no-response queries by 53 percent
…
UK-based mainframe to-cloud connectivity supplier Precisely is expanding the Precisely Data Integrity Suite with a new generation of AI agents and a context-aware Copilot – designed to bring autonomous, yet fully governed, data integrity to enterprises worldwide. Built to operate across complex hybrid and multi-cloud environments, these innovations will empower organisations to keep data accurate, consistent, and contextual by automating and optimizing data management processes without constant human intervention.
…
Progress Software launched Progress Agentic RAG, a SaaS Retrieval-Augmented Generation (RAG) platform designed to make trustworthy and verifiable generative AI accessible across organizations and teams of all sizes. The new platform expands Progress’ portfolio of end-to-end data management, retrieval and contextualization solutions that empower businesses to leverage all their data to gain a competitive edge. Progress Agentic RAG platform is available now as a self-service offering on AWS Marketplace, as well as at Progress.com. Pricing starts at $700/month, providing small businesses, departmental teams and individuals the immediate power to transform unstructured data into actionable intelligence at an affordable price. For more information or to start a free trial, click here.
…

Object storage supplier Scality has appointed Tom Leyden as VP of Product Marketing. Leyden brings over two decades of experience in SaaS, storage, backup, and AI. His background includes leadership roles at Amplidata (acquired by HGST), DDN, Excelero (acquired by Nvidia), and Kasten by Veeam.
…
Here are some recent Scality blogs:
- From warehouses to lakehouses, each evolutionary step in data architecture has solved one problem while creating another.
- Enterprise AI in action: 5 real-world use cases powered by object storage
- From data swamps to AI-ready data warehouses
- AI can’t wait for your data – How Hammerspace and Scality keep GPUs fed
…
Research house TrendForce says its latest findings indicate that over the next two years, AI infrastructure will mainly focus on high-performance inference services. As traditional high-capacity HDDs face significant shortages, CSPs are increasingly sourcing from NAND Flash suppliers, boosting demand for nearline SSDs designed specifically for inference AI and catering to urgent market requirements. NAND Flash vendors are quickly validating and adopting nearline QLC NAND Flash products to address the supply gap. QLC technology offers higher storage density at lower costs, making it essential for meeting large-capacity demand. Suppliers are also increasing QLC SSD production, with capacity utilization expected to steadily grow through 2026. The demand is likely to persist into 2027 as inference AI workloads expand, leading to tight supply conditions for enterprise SSDs by 2026.
To enhance the competitiveness of nearline SSDs in AI storage and better replace HDDs, future products will focus on increasing capacities and lowering prices. Manufacturers are working on new nearline SSDs that surpass mainstream HDDs in capacity, offer better cost efficiency, and significantly cut power consumption.
Beyond inference AI, NAND Flash suppliers are also focusing on AI training applications by introducing High Bandwidth Flash (HBF) products, dividing the industry into two main technology groups. The first is led by SanDisk, which is developing a hybrid design that integrates HBM with HBF. This approach seeks to balance large capacity and high performance to fulfill the dual needs of data throughput and storage in AI model training. The other group is led by Samsung and Kioxia, focusing on storage-class memory technologies like XL-Flash and Z-NAND. These offer a more affordable alternative to HBM, aiming to attract a wider range of customers.
…
VAST Data has been ranked 24th in the 2025 Forbes Cloud 100, the definitive ranking of the top 100 private cloud companies in the world, published by Forbes in partnership with Bessemer Venture Partners. VAST recently experienced 5x year-on-year sales growth in FY25, on top of a 2023 valuation of $9.1 billion. It has achieved a verified Net Promoter Score (NPS) of 84 – the highest in the industry. Earlier this year, Forbes also recognized VAST on the 2025 Forbes AI 50 List, which honors the top privately-held companies developing the most promising business use cases of artificial intelligence. Databricks is at no. 4 on the Forbes Cloud 100. Cohesity is at no. 21 with a $9 billion valuation. Cyera is no. 82.
…
Parallel file system supplier VDURA has launched its first scalable AMD Instinct GPU reference architecture in collaboration with AMD. The validated blueprint defines how compute, storage and networking should be configured for efficient, repeatable large-scale GPU implementations. The design combines the VDURA V5000 storage platform with AMD Instinct MI300 Series Accelerators to eliminate performance bottlenecks and simplify deployment for the most demanding AI and high-performance computing (HPC) environments. It supports 256 AMD Instinct GPUs per scalable unit, achieves throughput of up to 1.4 TB/s and 45 million IOPS in an all-flash layout, and delivers around 5 PB of usable capacity in a 3 Director and 6 V5000 node configuration. Data durability is assured through multi-level erasure coding, while networking options include dual-plane 400 GbE and optional NDR/NDR200 InfiniBand. The full 20-page architecture reference guide is available for download here.
…
ZDNet Korea reported that China’s YMTC is interested in entering the HBM market, possibly via a collaboration with CXMT.
…
IBM, Supermicro, and software RAID supplier Xinnor have produced an “IBM Storage Scale with Supermicro and Xinnor XiRAID” reference architecture. Check it out here.
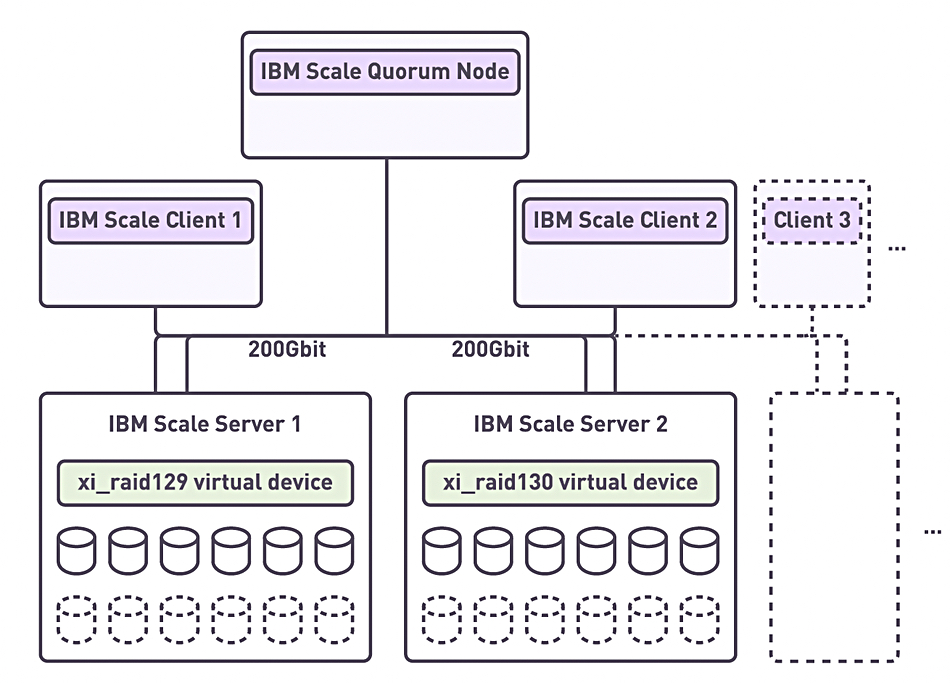
…
Xinnor has produced xiRAID Opus 1.2, an NVMe Composer in Lunux user space, which is GA. It features more NVMe over Fabrics capabilities and Virtualized access protocol (VirtIO-BLK) performance and scalability. It ‘unifies local and network-attached NVMe drives into a single, high-performance storage platform that maximizes speed and reliability while minimizing hardware overhead and power consumption. The solution’s breakthrough architecture delivers an impressive 1 million IOPS and 100 GB/s throughput per CPU core with ultra-low latency, providing linear scaling across cores and nodes. xiRAID Opus 1.2 native NVMe-oF initiator and target as well as VirtIO-BLK implementation allow it to seamlessly integrate network storage capabilities across drives, drive-namespaces, and RAID arrays and volumes. This integrated approach enables organizations to simplify NVMe deployments by removing the complexity of integrating various Linux components.”