Cloud storage provider Backblaze is developing drive type profiling models to optimize its drive replacement and migration strategies.
The work is detailed in the latest edition of its quarterly disk drive annual failure rate (AFR) statistics blog. Author and principal cloud storage storyteller Andy Klein says: “One of the truisms in our business is that different drive models fail at different rates. Our goal is to develop a failure profile for a given drive model over time.”
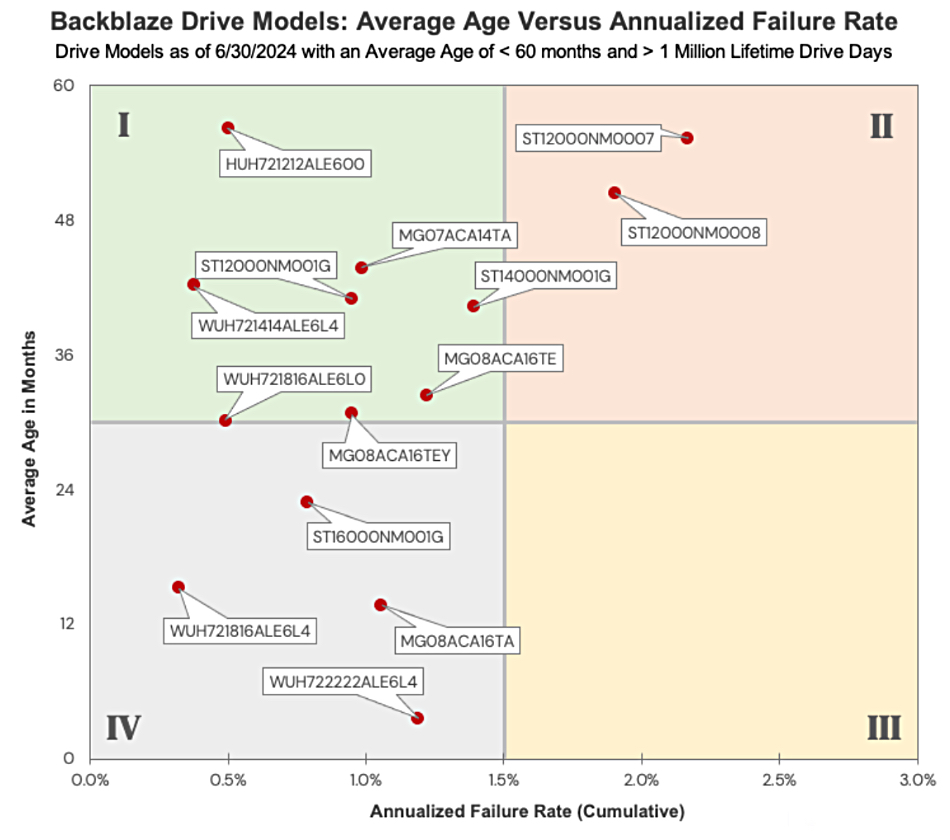
He started by “plotting the current lifetime AFR for the 14 drives models that have an average age of 60 months or less” drawing a chart of drive average age versus cumulative AFR and dividing it into four quadrants:
We can instantly see that the left hand two quadrants have most drives in them, and the top right quadrant – for older drives with higher cumulative AFRs – has only two drive models in it.
Klein characterizes the quadrants as:
1. Older drives doing well – with ones to the right having higher AFRs;
2. Drives with >1.5 percent and around 2 percent AFRs – “What is important is that AFR does not increase significantly over time”;
3. The empty quadrant – it would be populated if any of Backblaze’s drives exhibited a bathtub curve failure rate; pattern with failures in their early days, a reliable mid-period and subsequent failures as they age
4. Younger drives – with low failure rates.
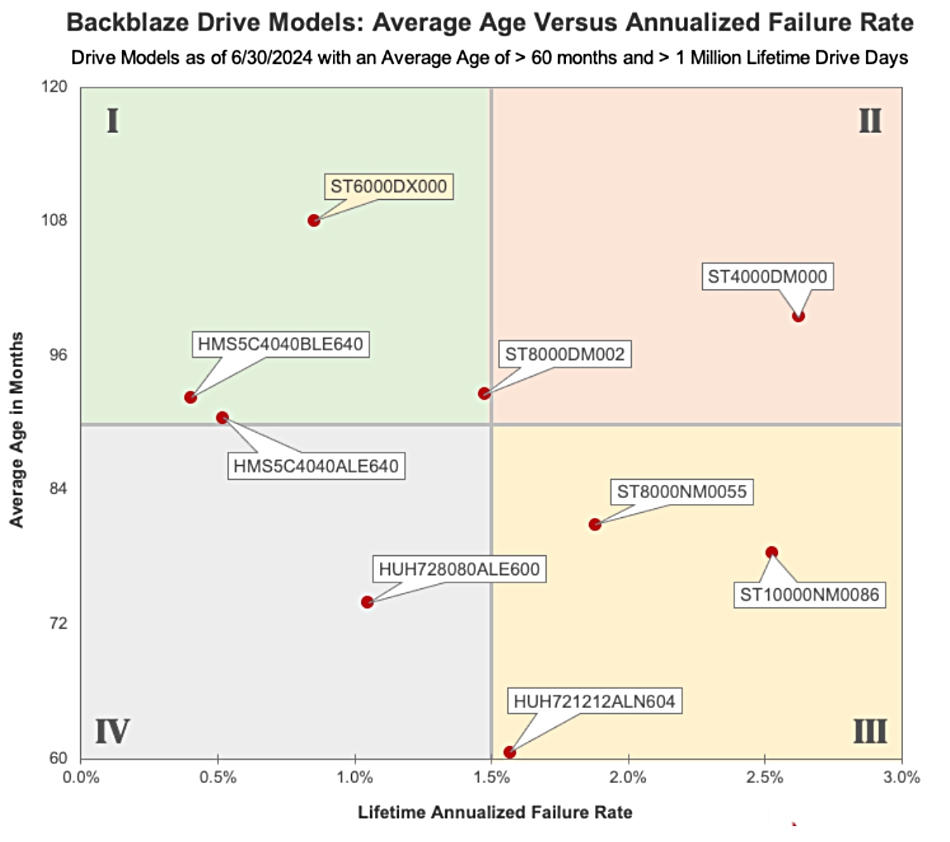
Next Klein drew a similar chart for drives older than 60 months:
Now there is a more equable distribution of drives across the four quadrants. He says: “As before, Quadrant I contains good drives, Quadrants II and III are drives we need to worry about, and Quadrant IV models look good so far.” The 4TB Seagate drive (ST4000DM000) in quadrant 2 looks “first in line for the CVT migration process.” CVT stands for Backblaze’s internal Cluster, Vault, Tome migration process. [See bootnote.]
Klein next looked at the change in failure rates for these drives over time in a so-called snake chart:
This chart starts at the 24-month age point and it shows that “the drive models sort themselves out into either Quadrant I or II once their average age passes 60 months,” except for the black line – Seagate’s ST4000DM000 4TB model.
Five drives are in quadrant number 1. “The two 4TB HGST drives (brown and purple lines) as well as the 6TB Seagate (red line) have nearly vertical lines “indicating their failure rates have been consistent over time, especially after 60 months of service.”
Two drives exhibit increasing failure rates with age – 8TB Seagate (blue line) and the 8TB HGST (gray line) – but both are now levelling out.
Four drives are in quadrant 2. Three of them – the 8TB Seagate (yellow line), the 10TB Seagate (green line), and the 12TB HGST (teal line) – show accelerated failure rates over time. Klein writes: “All three models will be closely watched and replaced if this trend continues.”
The 4TB Seagate drive (ST4000DM000 and black line) “is aggressively being migrated and is being replaced by 16TB and larger drives via the CVT process.”
Looking at all these curves, Klein believes that the 8TB Seagate (ST8000DM002) is normal as it started out with a 1 percent AFR to the 60 month point and then, as expected, its AFR increased towards 1.5 percent.
He says the two 4TB HGST drive models (brown and purple lines) have “failure rates … well below any published AFR by any drive manufacturer. While that’s great for us, their annualized failure rates over time are sadly not normal.”
Klein believes that using Gen AI large language models (LLMs) to predict drive failure rates is a no-go area for now. Training a model on one drive type’s failure profile doesn’t mean the model can predict another drive type’s failure profile. He observes: “One look at the snake chart above visualizes the issue as the failure profile for each drive model is different, sometimes radically different.”
Backblaze’s drive set data is freely available here. He points out anyone can use it but: “All we ask are three things: 1) you cite Backblaze as the source if you use the data, 2) you accept that you are solely responsible for how you use the data, 3) you may sell derivative works based on the data, but 4) you can not sell this data to anyone; it is free.”
Bootnote
A Tome is a logical collection of 20 drives, “with each drive being in one of the 20 storage servers in a given Vault.” A storage server could possess 60 HDDs and hence 60 unique tomes in the vault. A Cluster is a logical collection of Vaults, which can have any combination of vault sizes.
Virtualized datacenter supplier VergeIO reckons it can migrate hundreds of VMware virtual machines in seconds, providing a quicker and better tested exit for Broadcom VMware migrants.
Since Broadcom bought VMware and changed its business terms and conditions and forced reselling partner to re-apply to be resellers, VMware customers have been considering options – such as moving their virtual machine (VM) applications to other environments. Several suppliers of alternative hypervisor systems, including VergeIO, have been positioning themselves as VM migration targets.
Jason Yaeger.
VergeIO SVP of Engineering Jason Yaeger put out a statement saying: “At VergeIO, we understand the critical importance of minimizing operational disruption during migration. Our ability to migrate over 100 VMs in less than five seconds showcases our commitment to delivering seamless and efficient solutions for our customers.”
VergeIO claims this “significantly outpaces other alternative solutions, which average 3 to 7 minutes per VM, translating to a lengthy 5 to 12 hours for migrating 100 VMs.”
CMO George Crump tells us: “Recently, I watched a webinar by Veeam demonstrating the migration of a VMware VM to another hypervisor (Hyper-V). It took about 1 minute and 45 seconds to migrate one VM. When asked how long it would take to migrate 100 VMs, the SE estimated it would take nearly three hours, raising concerns about the server’s ability to handle that many migrations in a single pass.”
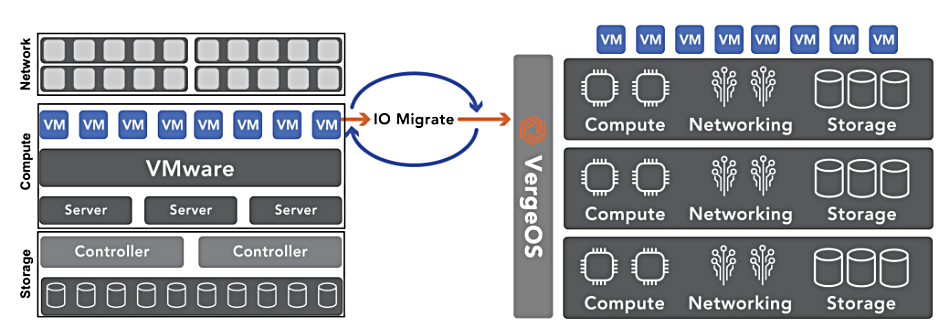
VergeIO has its VergeOS software which provides a virtual datacenter built from hyperconverged infrastructure servers. It emphasizes that storage and networking are included directly in VergeOS and do not run as VMs.
VMs are migrated from VMware to VergeOS with the IOmigrate feature, which uses VMware’s change block tracking technology to make a real-time copy of virtual machines. Verge claims it allows IT admins to log into the VMware ecosystem, view available VMs, select desired ones for migration, and within moments – near real time – these VMs are able to operate under VergeOS.
VergeIO IOmigrate diagram.
According to Broadcom, VMware’s Changed Block Tracking (CBT) is a VMkernel feature that keeps track of the storage blocks of virtual machines as they change over time. The VMkernel keeps track of block changes on virtual machines, which enhances the backup process for applications that have been developed to take advantage of VMware’s vStorage APIs.
A backup or other appliance uses the VMware API calls to request that a snapshot is created. VMware then takes the snapshot and presents it back so that a backup can be made.
Changed Block Tracking (CBT) is a feature that identifies blocks of data that have changed or are in use. It enables incremental backups to identify changes from the last previous backup, writing only changed or in-use blocks, so helping to reduce transferred data size and time.
VergeIO claims the speed and convenience of its VM transfer technology minimizes downtime and enables the quick creation of test environments, “facilitating thorough compatibility and performance testing.” Its “migration processes ensure optimal use of existing hardware and resources,” and it claims its “optimized infrastructure enhances overall system performance post-migration.” Its boot times are 3x faster than VMware.
The company has already “successfully converted customers with thousands of VMware VMs to VergeOS.”
It will host a live demo of its VMware VM migration technology on August 15 at 1:00 pm ET. Register here.
COMMISSIONED: Enterprises adopting AI to stay competitive must tailor AI models to their needs. This means defining use cases, choosing workflows, investing in the right infrastructure, and partnering for success.
Amidst today’s intense market competition, enterprises seek to leverage AI to gain a strategic advantage. Developing proprietary AI models enables companies to tailor solutions to their unique needs, ensuring optimal performance and differentiation. Starting a project to develop AI models involves navigating a complex landscape of technological challenges and requires careful planning, problem-solving skills, and a strategic approach to AI integration.
In AI development, defining a clear use case is the initial critical step, followed by selecting an AI workflow that ensures efficiency and effectiveness, with tools that are simple, integrated, customizable, scalable, and secure. Performance sizing is key, involving benchmarking and optimizing AI models for speed and accuracy, while balancing other performance metrics. The infrastructure to support AI is extensive, requiring robust data storage, compute resources, data processing, machine learning frameworks, and MLOps platforms. And with investments in AI predicted to reach nearly $200 billion by 2025 according to Goldman Sachs reports, the economic potential is significant and necessitates substantial capital investment. Not to mention, the specialized knowledge required for AI projects often necessitates enlisting external expertise.
Each of these challenges must be carefully considered and addressed to ensure the successful development and deployment of AI models. The following step-by-step approach can help organizations address these challenges.
Step 1: Define your use case
Deploying a Generative AI (GenAI) system successfully involves a series of strategic steps, the first and most crucial being defining a clear use case. This foundational step is about understanding the specific needs and objectives of the business, which will guide the selection of the appropriate GenAI workflow. It’s essential to consider the parts of the organization that will be impacted, identify the end-users, and locate where the necessary data is stored.
Aligning GenAI’s capabilities with business goals, whether it’s generating marketing content, providing digital assistance on a website, creating synthetic data or images, or facilitating natural language code development, helps to ensure that the technology is applied in a way that adds value and drives innovation. The success of GenAI deployment hinges on this alignment, resulting in technology that serves as a powerful tool to enhance business processes, engage customers, and foster growth.
Step 2: Choose your AI workflow
Choosing the right AI workflow is crucial for the success of any AI-driven project. Starting with a clear understanding of the objective and the specific use case will guide selection of the appropriate workflow pattern.
Pre-trained models offer a quick start, as they are ready-made solutions that work out-of-the-box for a variety of tasks. Model augmentation, such as retrieval augmented generation (RAG), involves adding new knowledge to an existing model, allowing it to make informed decisions based on additional data. Fine-tuning is a more in-depth process, where the model’s existing knowledge is refined to improve its performance on specific tasks. Finally, model training from scratch is the most comprehensive approach, involving the creation of a new neural network tailored to the unique requirements of the task at hand. This step-by-step escalation in AI workflow complexity, while requiring additional time and effort to complete, allows for a tailored approach that aligns with the project’s goals and technical needs.
Step 3: Size performance requirements
When planning for AI deployment, sizing performance requirements is critical. The type of model you choose, whether it is a language model like GPT4 or an image-based model like DALL-E and Stable Diffusion, influences your compute and storage needs. Language models, while having a high number of parameters, are more compact, which means they require less storage space but more computational power to process a large number of parameters.
On the other hand, image-based models may have fewer parameters but require more storage due to the larger size of the model itself. This distinction is important because it affects how you architect your system’s infrastructure. For instance, a system designed for language models should prioritize processing power, while one for image-based models should focus on storage capabilities. Compute and storage requirements will vary depending on a model’s architecture and the task it is designed to perform so this needs to be factored into how you architect your entire AI project. Understanding these nuances can lead to more efficient resource allocation and a smoother AI workflow.
Common storage solutions for AI models include many options, each with unique benefits and best use cases. Local file storage is often used for smaller, individual projects due to its simplicity and ease of access. Network-attached storage provides more robust solutions for larger datasets, offering better performance and scalability. Distributed file systems (DFS) are ideal for large datasets that require high availability and fault tolerance, as they distribute the data across multiple machines. Object storage is another choice, especially for cloud-native applications, due to its scalability and performance with substantial amounts of unstructured data. It is important to consider the specific needs of your AI model, such as the size of the model and the number of parameters, to choose the most suitable storage solution.
Step 4: Right size your infrastructure investments
Right-sizing infrastructure investments is a critical step in developing efficient AI systems. It involves selecting the appropriate hardware that aligns with the computational demands of the AI models. For instance, smaller AI models may be able to run on optimized laptops such as Dell Precision workstations, while more complex algorithms require powerful setups, such as those with multiple GPUs like Dell’s XE9640 and XE9680 servers. Dell PowerScale offers a versatile storage solution that caters to various needs, from all-flash arrays designed for high performance to tiered storage that balances cost and scalability.
The main advantages of PowerScale for GenAI applications include its scalability, which allows starting with a small and economical setup that can grow exponentially across different environments. It also offers universal data access which allows data to be ingested, read, and written through multiple protocols. Additionally, PowerScale supports GPUDirect, allowing for high-speed and efficient data access, crucial for intensive tasks like AI training. With high-performance Ethernet and NFS over RDMA, it provides for rapid data collection and preprocessing. Lastly, its multicloud deployment capability is essential for running AI workloads in various settings, whether on-premises, at the edge, or in the cloud, providing flexibility and efficiency in AI infrastructure.
Step 5: Engage Dell resources for help
Engaging Dell resources can significantly streamline the process of integrating advanced technologies into your business operations. With step-by-step guidance, your teams can concentrate on strategic growth and innovation rather than the intricacies of implementation. Dell’s Validated Designs and Reference Architectures provide a solid foundation for building efficient IT solutions and assurance that your infrastructure is optimized for performance and reliability. Additionally, we work with our Dell partners to offer specialized AI Workshops which are designed to bring your team up to speed on the latest in AI developments and applications. For a more tailored approach, Dell Professional Services for GenAI offer expertise in deploying generative AI, helping you to quickly establish a robust AI platform and align high-value use cases to drive tangible business value.
In order to be successful with AI model implementation, you need clear guidance on defining use cases, ensuring that your AI initiatives are aligned with strategic business goals. Our Dell AI solutions are designed for efficiency and effectiveness, featuring tools that are not only simple and integrated but also customizable and scalable to meet the evolving demands of AI projects. Performance sizing resources and best practices available through Dell are streamlined with our advanced benchmarking and optimization capabilities, enhancing the speed and accuracy of AI models. The infrastructure required for AI is robust and extensive, and our solutions encompass high-performance data storage, powerful compute resources, and sophisticated data processing capabilities. Recognizing the need for specialized knowledge, we connect you with industry experts to bridge any gaps in expertise, ensuring that your AI projects are not only successful, but also cutting-edge.
To learn more about how Dell storage can support your AI journey visit us online at www.dell.com/powerscale.
Samsung has crafted ultra-thin LPDDR5X memory chips built to support mobile devices with AI workloads.
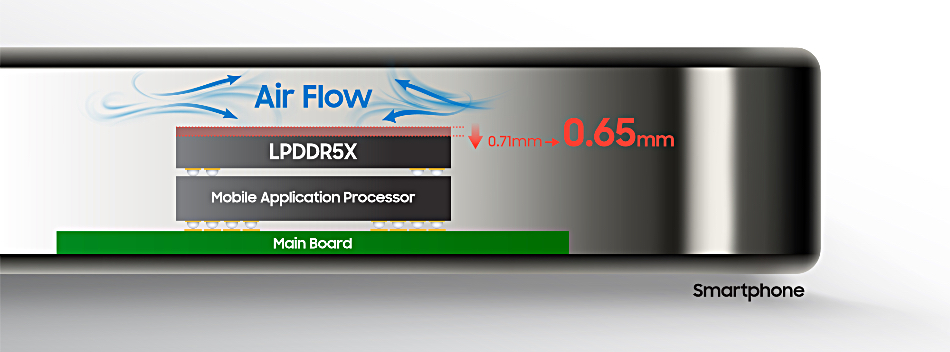
LPDDR5X is low power double data rate DRAM, and Samsung has made it using 12nm-class process technology with a 0.65mm package height, likened to fingernail thickness. It is producing 12GB and 16GB capacity versions of the chip, with 4 DRAM die layers, each layer having two LPDDR DRAMs. It is nine percent (0.06mm) thinner than previous generation product, and also has 21.2 percent more heat resistance, says Samsung.
It says it has optimized printed circuit board (PCB) and epoxy molding compound (EMC) techniques and back-lapping to make the chip package thinner. The EMC material protects semiconductor circuits from various external risk, such as heat, impacts, and moisture.
Samsung reckons its memory chip will be good for AI-enhanced mobile devices. YongCheol Bae, EVP for Memory Planning, claimed: “Samsung’s LPDDR5X DRAM sets a new standard for high-performance on-device AI solutions, offering not only superior LPDDR performance but also advanced thermal management in an ultra-compact package.”
Samsung’s diagram showing airflow benefits of its 12GB LPDDR5X chip.
High capacity memory chips contribute to the heat load inside a mobile device and enabling better airflow may in some ways enable better thermal management. That said, there are no fans inside mobile devices and so the airflow is passive, convective, and not that effective as a cooling agent. Generally mobile devices use heat spreading from the warmest components, like the processor and wireless chips, within the device, transferring heat via conduction to the sealed case. This functions as a heat sink and natural convection from the case expunges unwanted heat.
Samsung’s thinner LPDDR5X package could help enable thinner mobile devices and that, in some users’ minds, could trump the thermal management capability.
The company aims to supply its new chip to both mobile processor makers as well as mobile device manufacturers. Samsung does, of course, make its own Exynos mobile processor and Galaxy smartphones, so will also be using the new chip.
The roadmap for the device has planned 6-layer 24GB and 8-layer 32GB chips. They will probably be thicker.
Bootnote
Back-lapping involves grinding a chip’s surface using abrasive slurry, a mixture of abrasive material (e.g. silicon carbide and boron carbide) suspended in water or oil, instead of fixed-abrasive wheels for a less stressful thinning process.
The merger talks between DPU accelerator card builder Pliops and massively parallel DPU supplier Kalray have ended.
Israel-based Pliops is adding an AI feature set to its XDP (Extreme Data Processor) card. This product’s functionality provides key:value store technology whigh is designed to offload and accelerate low-level storage stack processing from a host x86 server for applications like RocksDB and RAID.
Ido Bukspan
Pliops CEO Ido Bukspan said in a statement: “You are likely aware that we explored the possibility of joining forces with Kalray in a merger. Kalray’s impressive technology and mature products in systems and advanced computing would have greatly enhanced our GenAI system-level offerings.
“However, economic conditions – especially financial market trends – did not favor a capital-intensive merger that would align with our targets. Moving forward, the management teams of both companies will continue discussions to explore areas of cooperation and leverage synergies.”
What now? Bukspan claimed Pliops has a “bright future” because it can enable “organizations to achieve unprecedented levels of performance and efficiency in their AI-driven operations.”
The company is developing an XDP LightningAI product, “a Key-Value distributed smart storage node for the GPU Compute Domain.” It claims this can provide an up to 50 percent TCO reduction for large language model (LLM) inference workloads. It can also “maximize performance per power budget and enhance VectorDB,” Pliops said.
On X post, Pliops claimed: “Our Extreme Data Processor uses GPU key-value I/O to cut power usage & emissions.”
The hardware is not ready yet, however. Bukspan added: “Pliops LightningAI has gained significant traction with major customers and partners eagerly awaiting our demo based on our first silicon, which will be available soon.”
Pliops AI Inferencing acceleration graphic
There will be a demo of XDP LightningAI at this week’s FMS 2024 event in Santa Clara, California.
Bukspan is still on the lookout for more partners, saying: “Partnerships that bring value to our customers and support our mission to enhance GenAI application efficiencies are integral to our business model. Kalray remains a valued partner, joining our other collaborators to deliver essential solutions that will yield amazing results in the coming months.”
Startup Lucidity claims its Autoscaler can automatically scale public cloud block storage up or down dynamically – depending on workload – without downtime, saving up to 70 percent of cost and with virtually no DevOps involvement.
Vatsal Rastogi (Left) and Nitin Singh Bhadauri (right)(.
Lucidity was founded in 2021 in Bangalore, India, by CEO Nitin Singh Bhadauria and Vatsal Rastogi who drives the technical vision and manages engineering and development. Rastogi was previously a software developer involved in creating Microsoft Azure.
It has taken in $5.6 million in angel and VC pre-seed and seed funding. The investors were responding to a proposal that Lucidity develop auto-scaling software to manage the operations involved in scaling up and shrinking public cloud persistent block storage. Its autoscaler would have agents in each virtual machine running in AWS, Azure or GCP, monitor the metrics produced, and then automatically grow or shrink storage capacity as required with no downtime and no need for DevOps involvement.
Lucidity explains that there is a common storage management cycle for AWS, Azure and GCP. This cycle has four basic processes: plan capacity, monitor disks, set up and respond to alerts. Lucidity says it’s built an autonomous orchestration layer to manage this and reduce storage costs, and reduce DevOps involvement by using auto-scaling.
Its GCP and Azure autoscaler documentation claims that “Shrinking a disk without downtime especially has not been possible so far. Lucidity makes all of it possible with no impact on performance.”
The autoscalers rely on a concept of providing logical disks, made up from several smaller disks, which can be added to the logical disk pool or removed from it. A ‘disk’ here means a drive – which can be SSD or HDD-based.
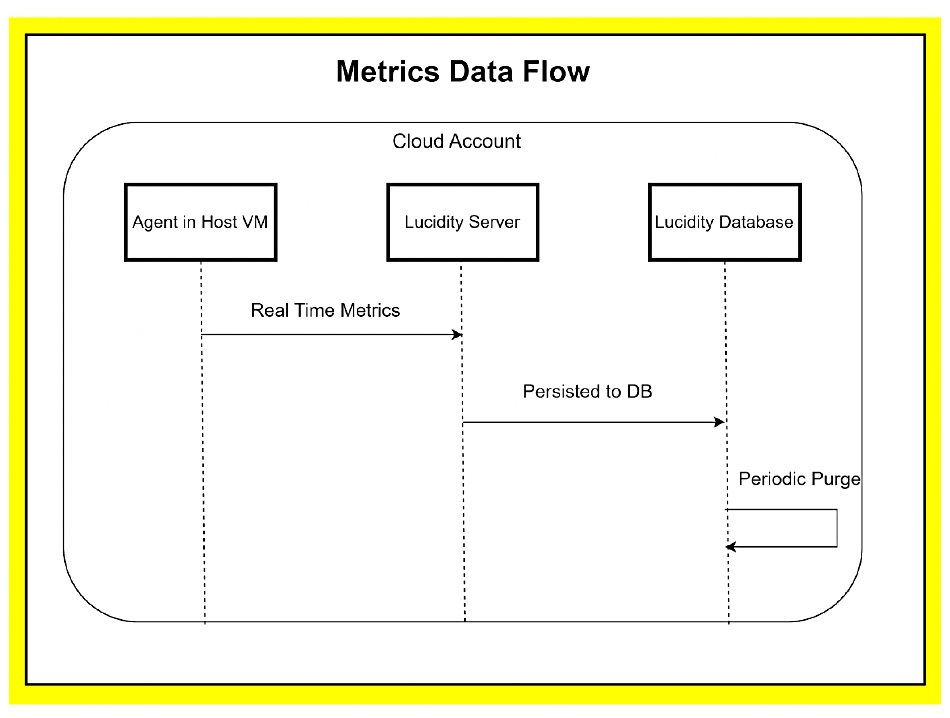
A Lucidity agent runs inside each VM and sends metrics to a Lucidity server which “analyzes the usage metrics for each VM instance to figure out the right storage configuration and keeps tuning it continuously to ensure that the workload always gets the resources it needs.”
Lucidity metrics data flow diagram.
This is an out-of-band process. The Lucidity server calculates when to scale capacity up or down. Lucidity GCP autoscaling documentation states: “The Lucidity Scaler is able to perform expand and shrink operations at a moment’s notice by using a group of disks attached to an VM instance as opposed to a single disk. The group of disks is composed together to form a single disk (or a logical disk).”
When a volume is shrunk, Lucidity’s server software works out which disk to remove, copies its data to other drives to rebalance the system, and then removes the empty disk. There is no performance impact on a running application.
Lucidity Autoscaler decision tree.
This storage orchestration “is powered by Windows Storage Spaces behind the scenes.” Lucidity software runs on top of this and uses the BTRFS filesystem in Linux “to group disks and create a logical disk for the operating system. The operating system would be presented with one single disk and mount point which the applications would continue to use without any impact.”
The AWS autoscaler handles cost optimization by navigating the many and varied AWS EBS storage instances. There are, for example, four SSD-backed EBS volume types and two HDD-backed ones. Lucidity states: “As a result of various performance benchmarks and uses of the various types of EBS volumes, the pricing of these can become challenging to grasp. This makes picking the right EBS type extremely crucial, and can cause 3x inflated costs than required, if not done correctly.”
Luvidity’s table of AWS EBS volume types and costs.
There are also two types of idle volume and AWS charges on provisioned – not used – capacity. A Lucidity ROI calculator facility can provide more information about this.
Lucidity Community Edition – providing a centrally managed Autoscaler hosted by Lucidity – is available now. A Business Edition – enabling users to “access the Autoscaler via a Private Service Connect that ensures no data is transferred over the internet” – is coming soon. An Enterprise Edition wherein the Autoscaler “is hosted within the cloud account and network of the user for exclusive access” is also coming soon.
A Cisco end-of-life notice confirmed it is going to stop selling certain Cisco Select Cohesity Solutions, initially with no replacement option specified but now with alternatives.
Update: Cisco and Cohesity provided explanatory statement, 6 August 2024.
Cohesity entered Cisco’s Solutions Plus program in March 2019, enabling its internal sales teams to sell Cohesity software products running on UCS servers. There was joint sales, marketing, service and support, and product roadmap alignment between Cohesity and Cisco, which is a strategic investor in Cohesity.
Cisco’s end-of-life notice, emitted at the weekend, announced that November 4, 2024 is the end-of-sale date, and identified Cohesity SiteContinuity Delivered as a Service, DataProtect and Flexible DataProtect Delivered as a Service, and Replica or Retention Delivered as a Service as the affected Cohesity offerings.
An event that may be related to this EOL notice is that Cisco made a strategic investment in anti-ransomware startup Halycyon at the start of this month. Janey Hoe, VP at Cisco Investments, stated, “Ransomware has been a perpetual Cybersecurity pain-point for enterprises across the world.
“Halcyon’s deployment of bespoke artificial intelligence models to proactively identify ransomware strains, as well as instantaneous recovery of hijacked data, represents a robust AI enabled response to an endemic problem. We are proud to have Halcyon become a part of our $1B global AI-investment fund, announced earlier this year.”
Only last month, Cisco blogger Jeremy Foster wrote that since formulation of their agreement in 2019: “Cisco and Cohesity have produced five Cisco Validated Designs (CVDs) and multiple open-source contributions in GitHub repositories. These prebuilt integrations, reference architectures, and solution guides cover a number of use cases for simplifying data management and strengthening data security, including backup, archiving, disaster recovery, ransomware protection and recovery, file and object services, dev/test, and analytics.”
Cisco and Cohesity had more than 460 joint customers and their alliance expanded to include Cohesity Cloud Services, described by the pair as “a portfolio of fully managed, cloud-native, as-a-service (aaS) offerings that provide backup and recovery, threat detection and data classification, and cyber vaulting services.”
Foster wrote: “With more apps and workloads generating more data than ever before, there is a historic demand to derive value from this data. But that also means there are more points of complexity and vulnerability than ever before for companies who need to manage and secure all that data across multiple environments.
“As long as this is the reality, Cisco will continue to work closely with strategic partners like Cohesity to ensure that our customers can protect and manage their data better so that they can unlock real value from what is likely to be their most important asset.”
Furhter back in August 2023, Cisco integrated Cohesity DataProtect data protection and DataHawk ransomware protection capabilities into its extended detection and response (XDR) offering.
We have asked both Cisco and Cohesity for an explanation of why this EOL notice is being issued and what it means for their relationship. A joint Cisco-Cohesity statement said: “Cisco and Cohesity’s strategic relationship remains unchanged. This EOL notice simply pertains to SKU’s being deprecated as part of a price list update and retirement of certain offers by Cohesity.
“Four of the offers have been replaced with new SKU’s; the EOL notice is updated to reflect that. The remainder are offers being EOL’d by Cohesity have been rolled into new offers. There are currently 38 Cohesity “as-a-Service” SKUs on the Cisco price list. Additionally, the Cisco price list includes Cohesity Service and Support SKUs including Cohesity data replication and management software, such as Cohesity DataProtect, Replica, SmartFiles and Archive, as well as Cohesity’s catalog of professional services, training and data platform SKUs.
“Our hundreds of joint customers can expect Cisco and Cohesity to continue their strong relationship, and we’re committed to working closely together to continue to offer innovative solutions. The small number of customers impacted by the EOL announcement will be provided, where appropriate, migration paths to newer offerings.”
An IEEE report sees no mass takeover of the disk drive market by SSDs because HDD cost/bit is decreasing fast enough to prevent SSDs catching up.
The International Roadmap for Devices and Systems 2023 Update (IRDS) is discussed in Tom Coughlin’s August Digital Storage Technology Newsletter (subscription details here.) It covers many mass storage technologies: SCM, NAND/SSDs, HDDS, tape and emerging memories including DNA.
We’re focusing on SSDs and disk drives here and the IEEE report notes that HDDs have ceded the fast data access market to SSDs: “As flash-based SSD costs have fallen, HDDs have been displaced: first in consumer PCs, and increasingly in data centers, as SSDs have come to occupy the tier of frequently, and randomly, accessed data.”
Nowadays: “HDDs are used for bulk mass storage and SSDs are used for speed. Frequently requested and typically randomly accessed data resides in the SSDs, while less-frequently used and typically sequentially accessed data is kept in high-capacity HDDs. “
However: “SSDs and HDDs continue to coexist because HDDs (and tape) will continue to offer the lowest cost per bit for the foreseeable future.”
As a consequence: “Today the HDD market continues its decline in unit volume primarily due to displacement by solid state drives.” The IEEE report sees total HDD unit ships increasing from 2023 to 2028 as the nearline mass storage market increases in size:
The mobile, branded, consumer electronics and retail HDD markets continue to decline over this period, or so the forecast states.
SSD capacity is increasing as layer counts in 3D NAND increase and drive down the cost/bit, but the rate of increase is slowing. This is because adding layers also adds cost. The alternative way of increasing capacity, adding bits to cells, has reached a possibly temporary wall with QLC (4bits/cell) as the next 5bits/cell; level – penta-level cell or PLC – has such short endurance as to make infeasible, for now.
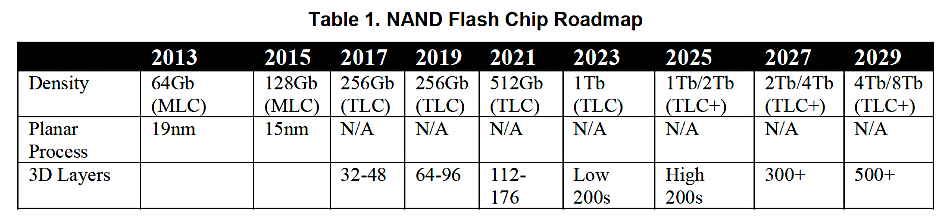
The IEEE report has a table from its IRDS (International Roadmap for Devices and Systems) community showing NAND chip density progression out to 2029:
IRDS does not commit itself to saying QLC will displace TLC from 2025 onwards, instead using the term TLC+. We are currently just entering the high 200s layer count area with Micron’s 276-layer technology with a 1Tb die.
The table shows 300+ layers in the 2027 period and 500+ in the 2029 timeframe, leading to a doubling in maximum die capacity from 2TB in 2025, to 4Tb in 2027 and 8Tb in 2029.
Despite this capacity increase, SSD cost/bit will not become equal to or go below HDD cost/bit, the report states: “The ultra-high capacity HDD market will remain unavailable to flash for the foreseeable future due to its lower cost per bit.”
No alternative semiconductor-based memory technologies, either volatile or non-volatile, will replace NAND or DRAM. Keeping the fate of Intel’s Optane mind, this is because their performance and other characteristics do not justify a supplier bearing the cost of ramping production to a volume level where the cost/bit, performance, endurance and power consumption means customers will switch from either DRAM or NAND.
Technologies like ReRAM, MRAM, etc. will remain niche embedded market alternatives because of this restriction.
HDDs will increase their capacity, and therefore lower their cost/bit as a table indicates:
All the suppliers – Seagate, Toshiba and Western Digital – will move to HAMR technology, and use patterned heated dot media in the 2037 period:
The report states: “Patterned media has discrete elements of the magnetic material distributed in an orderly fashion across the disk surface. These patterned dots become the magnetic bits when the head writes on them. Patterned media will be combined with HAMR recording to create 10 Tb/in2 magnetic recording areal density within the next 15 years.”
One enduring HDD issue is access density; IO operations per second per byte. The report says: “As the storage capacity on a surface increases, the time it takes to access a given piece of data increases and the time to read or write all the data on the disk increases as well. Although the average performance of disk drives to access data is increasing by about 10 percent per year … the disk access density (Access density = I/Os per second per gigabyte) of disk drives is continually decreasing as disk drive capacity increases faster than disk drive performance.”
Despite advances such as multi-actuator technology, access density will continue to decline as HDD capacity increases. NAND caching, as with WD’s OptiNAND technology, can help mitigate this.
Altogether the IEEE report makes for fascinating reading and there is much more information in its 117 pages than we can cover here. It is a terrific primer and introduction into current and future mass data storage technologies.
IBM’s Vela AI supercomputer, described here, was not powerful enough for IBM Research’s AI training needs. In 2023, it began the Blue Vela development to supply the major expansion of GPU compute capacity required to support AI model training needs. To date, Blue Vela is actively being used to run Granite model training jobs.
Update. Performance comparison between Vela and Blue Vela added. 12 Aug 2024.
IBM Blue Vela graphic
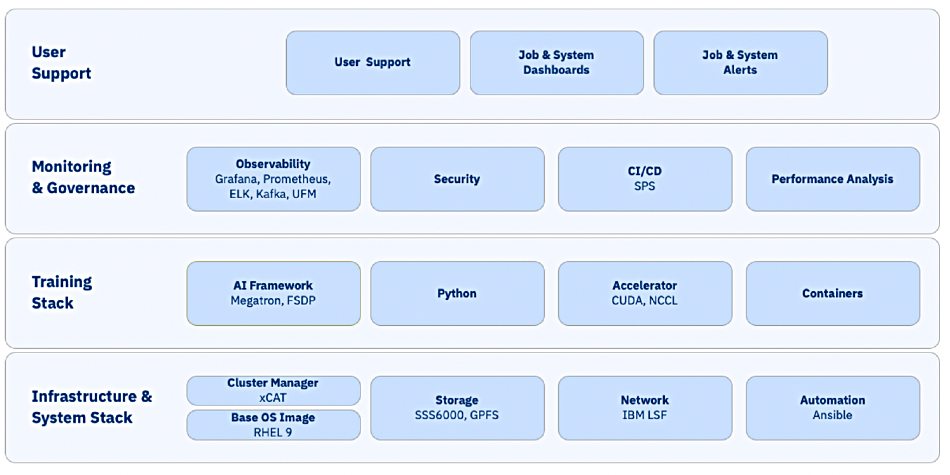
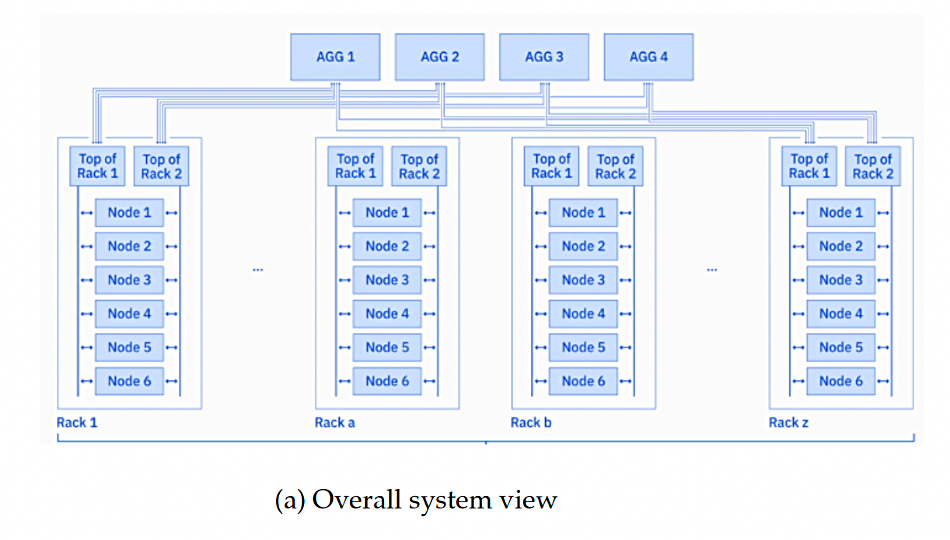
Blue Vela is based around Nvidia’s SuperPod concept and uses IBM Storage Scale appliances as we shall see.
Vela is hosted on the IBM Cloud but the Blue Vela cluster is hosted in an IBM Research on-premises datacenter. This means that IBM Research has ownership and responsibility for all system components, from the infrastructure layer to the software stack.
Blue Vela system layers
As the number of GPUs needed to train larger and more connected models increases, communication latency becomes a critical bottleneck. Therefore, the design of Blue Vela originated with the network and Blue Vela is designed around four distinct purpose-built networks.
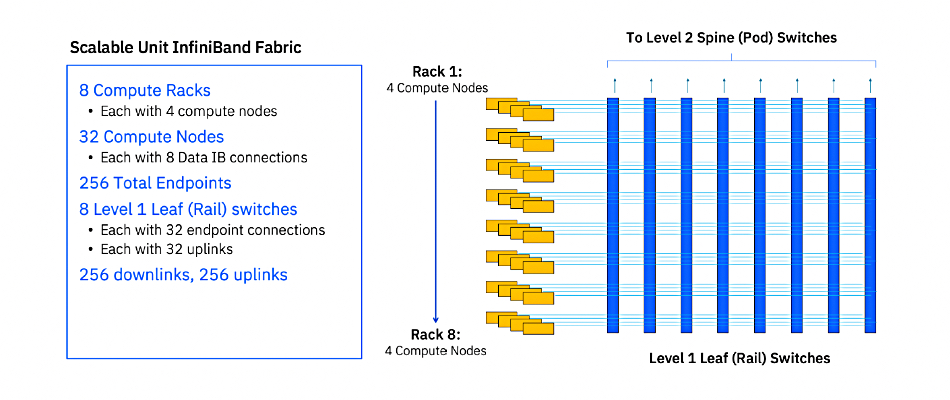
A compute InfiniBand fabric, which facilitates GPU-to-GPU communication, as shown below
A storage InfiniBand fabric, which provides access to the storage subsystem, as shown below
An in-band Ethernet host network is used for inter-node communication outside the compute fabric
An out-of-band network, also called the management network, which provides access to the management interfaces on the servers and switches
Blue Vela is based on Nvidia’s SuperPod reference architecture. It uses 128-node Compute Pods. These contain 4 x Scalable Units, each of which contain 32 nodes. The nodes contain Nvidia H100 GPUs. Nvidia’s Unified Fabric Manager is used to manage the InfiniBand networks comprising the compute and storage fabrics. UFM can help recognize and resolve single GPU throttling or non-availability, and it is not available for Ethernet networks.
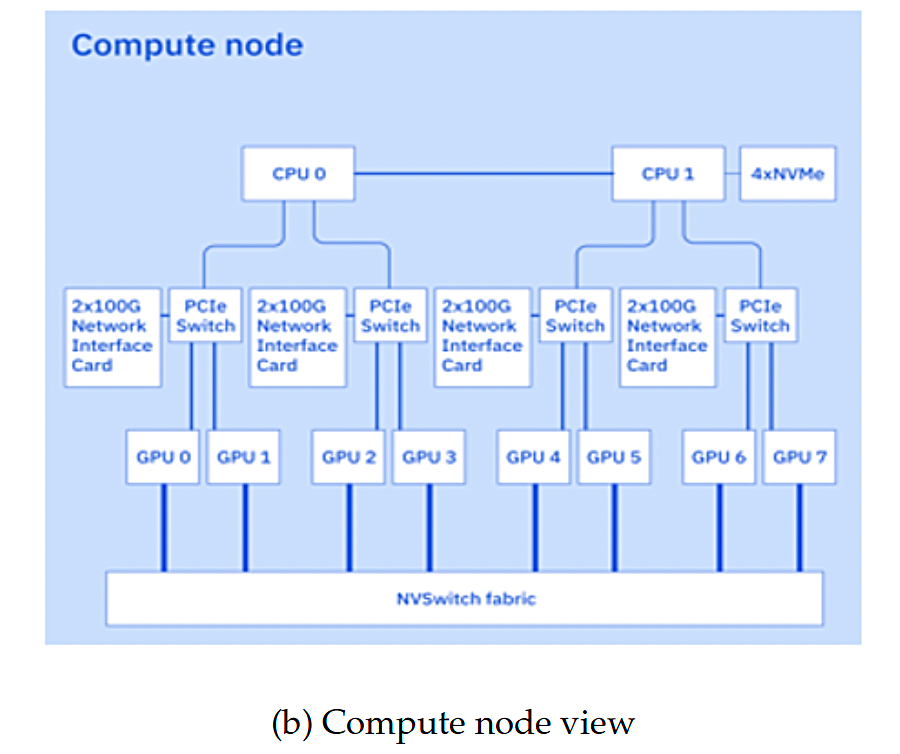
A compute node is based on Dell’s PowerEdge XE9680 server and consists of:
Dual 48-core 4th Gen Intel Xeon Scalable Processors
8 Nvidia H100 GPUs with 80GB High Bandwidth Memory (HBM)
IBM “modified the standard storage fabric configuration to integrate IBM’s new Storage Scale System (SSS) 6000, which we were the first to deploy.”
These SSS appliances are integrated scale-up/scale-out – to 1,000 appliances – storage systems with Storage Scale installed. They support automatic, transparent data caching to accelerate queries.
Each SSS 6000 appliance can deliver upwards of 310 GBps throughput for reads and 155 GBps for writes across their InfiniBand and PCIe Gen 5 interconnects. Blue Vela started with two fully populated SSS 6000 chassis, each with 48 x 30 TB U.2 G4 NVMe drives, which provides almost 3 PB of raw storage. Each SSS appliance can accommodate up to seven additional external JBOD enclosures, each with up to 22 TB, to expand capacity. Also, Blue Vela’s fabric allows for up to 32 x SSS 6000 appliances in total.
IBM says the maximum effective capacity is up to 5.4 PB based on FCM drives and 3:1 compression, which will depend upon the characteristics of the data stored in the FCM
Blue Vela has separate management nodes using Dell PowerEdge R760XS servers, and utilized to run services such as authentication and authorization, workload scheduling, observability, and security.
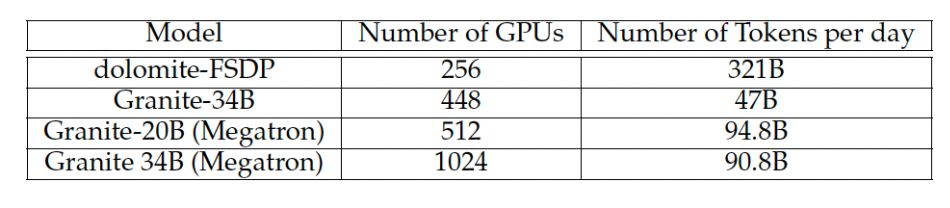
On the performance front, the paper authors say: “From the onset, the infrastructure has demonstrated good potential in throughput and has already shown a 5 percent higher performance out-of-the-box compared to other environments of the same configuration.”
“The current performance of the cluster shows high throughputs (90-321B per day depending on the training setting and the model being trained).”
Blue Vela performance
Vela vs Blue Vela
A comparison between the Vela and Blue Vela systems would use this formula: # Training Days = 8 * #tokens * #parameters/(#gpus * flops per GPU). On this basis;
IBM Vela – 1100 x A100 GPUs for training and theoretical performance = 300 teraFLOPs/GPU (bf16)
IBM Blue Vela – 5000 x H100 GPUs for training and theoretical performance = 1,000 teraFLOPs/GPU (bf16)
This makes Blue Vela more than three times faster than Vela.
There is much more detailed information about the Blue Vela datacenter design, management features and software stack in the IBM Research paper.
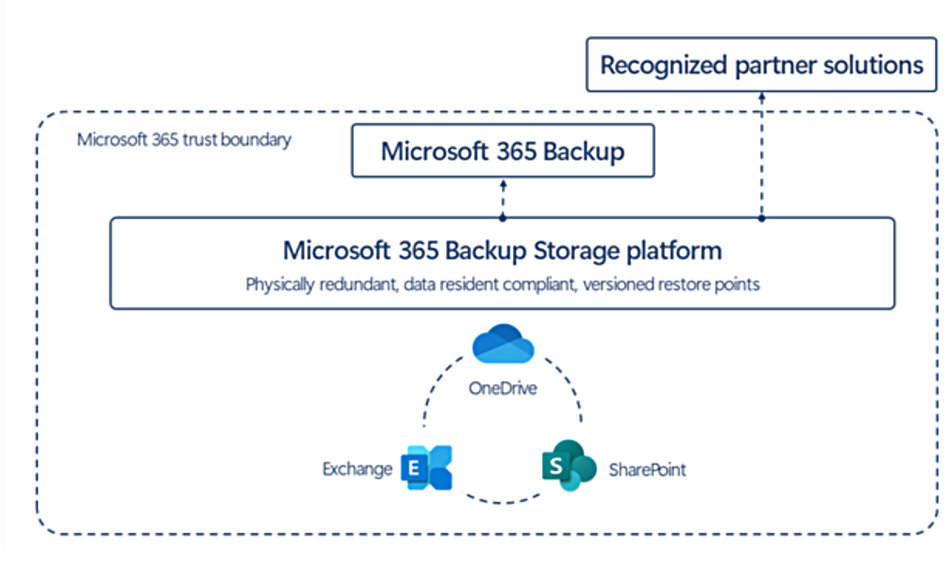
Microsoft has launched Microsoft 365 Backup and Microsoft 365 Backup Storage, introducing cloud data backup directly on its platform, which is also accessible for third-party use.
Several have jumped aboard at once – AvePoint, Cohesity, Commvault, Keepit, Rubrik, Veeam, and Veritas – and will be keeping all or some of their Microsoft 365 customer backup data in Azure. Microsoft software engineers have probably done clever things with snapshots and metadata to speed things up.
Microsoft diagram
Microsoft 365 Backup provides backup and recovery for active data to maintain business continuity “at speeds orders of magnitude faster than with traditional migration-based backup methodologies.” It has “ultra-high-speed recovery of your OneDrive, SharePoint, and Exchange data.” Microsoft says: “Many customers will see average speeds for mass restores that are 20 times faster than traditional means of backing up and restoring large volumes of Microsoft 365 data.”
We haven’t seen any benchmark test numbers and Microsoft bases its claim on internal research. However, if a service like Exchange Online or Teams is based in Azure, then backing it up within Azure is intuitively going to be faster than copying the data outside Azure.
Microsoft 365 Backup Storage powers the Microsoft 365 Backup offering. It gives third-party backup developers, using the Microsoft 365 Backup Storage APIs, a way to provide the same features of Microsoft 365 Backup through their own integrated application.
Commvault
Commvault Cloud is built on Azure, and Commvault has announced Microsoft 365 Backup Storage as an integrated component of Commvault Cloud Backup and Recovery for Microsoft 365. It delivers cyber resilience and recovery across Microsoft 365 workloads. Native integration provides unified control with single-pane-of-glass monitoring and administration via Commvault Cloud.
Commvault’s Microsoft 365 protection capabilities across Exchange Online, Teams, OneDrive, and SharePoint include selectable and configurable extended retention, granular recovery, and self-restore options.
Tirthankar Chatterjee
Tirthankar Chatterjee, CTO Hyperscalers at Commvault, stated: “We are building on our 27-plus years of co-development and co-engineering with this integrated solution that helps customers achieve the highest level of cyber resilience and threat readiness, along with the ability to greatly improve recovery time to specific Microsoft 365 workloads.”
Zach Rosenfield, Microsoft’s Partner Director of PM, Collaborative Apps and Platforms, stated: “With this integration, Commvault has taken a major step in helping our joint customers keep their business running with fast operational recovery from cyberattacks.”
Commvault Cloud Backup and Recovery for Microsoft 365 will be available through the Microsoft Azure Marketplace later this quarter.
Keepit
SaaS backup provider Keepit is, on the face of it, an unlikely Microsoft Backup Storage partner. The Keepit service offers fast, immutable, independent, always-online storage that protects Microsoft 365, Entra ID, Google Workspace, Salesforce, and more. It stores the backup data in its own privately operated datacenters in the USA, Canada, UK, Germany, Denmark, and Australia.
Paul Robichaux
Keepit’s Paul Robichaux, Senior Director of Product Management, writes in a blog: “We are adding support for Microsoft 365 Backup Storage so that you can flexibly choose to add rapid-restore protection for your most critical Microsoft 365 assets.”
“Microsoft has invested decades of engineering experience and knowledge into the Microsoft 365, Entra ID, Power Platform, and Dynamics 365 platforms. Because they have complete control over and visibility into every aspect of those platforms, their first-party backup solution delivers some great technical capabilities, including high restore speeds at large scale and great data fidelity. The combination of database level backup for SharePoint and OneDrive and copy-on-write backup for Exchange Online gives customers a powerful new tool for large-scale recovery. No other vendor can provide the same direct capabilities because none of us are “inside the blue curtain.” We just do not have the same access to the platform that Microsoft does.”
While Microsoft has unique access to their platform, what Keepit says it contributes is unique separation of environments and guaranteed access to data: “With data stored in the independent Keepit cloud, customers retain access even if they lose access to Microsoft.”
He says that the SaaS backup discussion is changing with the increased recognition that the customer is responsible for ensuring the security and availability of their own SaaS control plane and application data in a world that is increasingly insecure. The SaaS vendor can do a lot to help, but ultimately it’s the customer’s responsibility: “They ignore that at their peril.”
“Keepit protects the full range of critical objects, including conditional access policies, application registrations, users, mailboxes, SharePoint sites, Teams channels, Microsoft 365 Groups, CRM data, and more; Microsoft 365 Backup Storage adds rapid-restore protection for the object types they protect.”
“For customers, the perfect backup setup for Microsoft 365 will be this: A full, immutable, logically and physically separate backup of all of Microsoft 365 and Entra ID in Keepit, with extra restore capabilities of critical data sets in Microsoft 365 Backup Storage. In this setup, customers can keep costs under control, and have guaranteed access to all data, in the event of losing access to Microsoft tenants or administrator credentials.”
Keepit’s integration with Microsoft 365 Backup Storage is currently in private preview and it’s rolling this feature out to eligible customers soon. The Keepit Microsoft 365 roadmap includes:
Keepit will suggest which data items might benefit from rapid restore protection, using data about activity and cost to intelligently balance recovery time, coverage, and cost
When a user requests a restore, Keepit will know exactly where to retrieve the data from to get it back both completely and quickly
Seamless integrated restore across both storage platforms, allowing one-click restore of Entra ID alongside Microsoft 365 data
Automatic migration of data between platforms to provide cost-effective long-term data preservation giving you the right protection for the different types of data you have at the right cost
Integrated auditing and management to help define, monitor, and enforce backup and compliance policie
Veeam
Veeam Data Cloud is built on Azure and provides backup-as-a-service (BaaS) for Microsoft 365, with more than 21 million users protected. The company says it’s a launch partner for Microsoft 365 Backup Storage and Veeam Data Cloud for Microsoft 365 uses Microsoft’s 365 Backup Storage offering. This new Microsoft backup technology is embedded inside Veeam’s backup service for Microsoft 365.
Veeam Data Cloud for Microsoft 365 protect and restore hundreds of TBs of data or 10,000-plus objects. It “offers bulk restores at scale, ensuring increased resilience to ransomware or malware attacks and minimizing downtime.”
John Jester
John Jester, Chief Revenue Officer (CRO) at Veeam, said in a statement: “This new release combines the benefits of Veeam’s industry-leading technology – in both data protection and ransomware recovery – with the latest Microsoft 365 data resilience capabilities introduced by Microsoft, and extends them to even more customers using Microsoft 365. In addition, we’re making great progress in our joint innovation bringing the power and insights of Microsoft Copilot to the Veeam product family.”
Veeam has a new five-year strategic partnership with Microsoft and is developing future services integrating Microsoft Copilot and Azure AI services to enhance data protection for Microsoft 365 and Azure. These “will simplify operations [and] automate administrative tasks.”
Veeam Data Cloud for Microsoft 365 with Microsoft 365 Backup Storage will be available in early August. Three packaging options (Express, Flex, and Premium) are available to accommodate Veeam and Microsoft customers. Get more information here.
***
Microsoft 365 Backup is offered through the Microsoft 365 admin center and is sold as a standalone pay-as-you-go (PAYGO) solution with no additional license requirements. There is more information available in a Microsoft blog.
The Cohesity, Rubrik, and Veritas offerings with integrated Microsoft 365 Backup Storage will be coming soon.
Data protector Acronis has shared research from the first half of 2024 in its biannual cyberthreats report, “Acronis Cyberthreats Report H1 2024” The report found that email attacks have seen a 293 percent increase when compared to the same period in 2023. The number of ransomware detections was also on the rise, increasing 32 percent from Q4 2023 to Q1 2024. In Q1 2024, Acronis observed 10 new ransomware groups who together claimed 84 cyberattacks globally. Among the top 10 most active ransomware families detected during this time, three highly active groups stand out as the primary contributors, collectively responsible for 35 percent of the attacks: LockBit, Black Basta, and PLAY.
Bahrain, Egypt, and South Korea were the top countries targeted by malware attacks in Q1 2024
28 million URLs were blocked at the endpoint in Q1 2024
27.6 percent of all received emails were spam and 1.5 percent contained malware or phishing links
The average lifespan of a malware sample in the wild is 2.3 days
1,048 cases of ransomware were publicly reported in Q1 2024, a 23 percent increase over Q1 2023
Top barriers to adopting AI were worries about the security and compliance risks that AI presents (74 percent), not having the proper training or talent to manage AI tools (38 percent), and AI tools being too expensive (26 percent).
While 94 percent of respondents said that they trust their data, 55 percent also said they would rather get a root canal than try to access all of their company’s data.
The top use cases for AI included improving customer experiences (60 percent), increasing operational efficiency (57 percent), and expediting analytics (51 percent).
…
Data lake service provider Cribl has launched its inaugural Navigating the Data Current Report, which provides insights into how IT and Security teams are modernizing their data management practices. Cribl says it holds the largest amount of data on how IT and Security teams use their telemetry data and how the trends are shifting. A sampling of the key findings:
Increase in Data Sources: The number of data sources ingested by IT and Security teams grew by 32 percent year over year, with nearly 20 percent of users consuming from ten or more data sources.
Preference for Single Cloud: Contrary to the multi-cloud trend, only 11 percent of IT and Security teams are sending data to more than one CSP-native destination.
Growth in Multi-SIEM Deployments: The number of companies sending data to multiple SIEM products increased by 45 percent over the last year. Usage of multiple SIEMs grew from 11 percent to 16 percent, with significant gains for Google SecOps and Microsoft Sentinel.
You can download the full report at the link here and the accompanying blog post here.
…
SSD supplier DapuStor says it is expanding its collaboration with Marvell to deliver breakthrough Flexible Data Placement (FDP) technology optimized for Quad-Level Cell (QLC) and Triple-Level Cell (TLC) SSDs. QLC SSDs face challenges such as lower endurance and slower write speeds. TheFDP technology supported in the Marvell Bravera SC5 SSD controller with firmware developed by DapuStor directly addresses these issues. The FDP algorithms dynamically adjust data placement based on workload and usage patterns, ensuring that the most frequently accessed data is stored in the fastest and most durable regions of the SSD. Testing has demonstrated that this can achieve a write amplification (WA) close to 1.0. Marvell and DapuStor will showcase the DapuStor QLC SSD H5000 series with FDP solutions at the 2024 FMS: Future of Memory and Storage conference in Santa Clara this month.
…
According to Datacenter Dynamics Google has launched an air-gapped version of Google Distributed Cloud (GDC) hardware for artificial intelligence (AI) edge computing.It’s an appliance that runs Google’s cloud infrastructure stack including Kubernetes clusters, data security services, and Vertex AI platform when access to the Internet is not possible. It was in preview mode last year and is now GA. This Azure Stack-like offering has hardware components supplied by Cisco, HPE, Dell, and Nvidia (GPUs).
…
ExaGrid has begun a new strategic partnership with StorIT Distribution, a Value-Added Distributor in the Middle East and North Africa for Enterprise IT Products and Systems. StorIT in partnership with ExaGrid will help organizations to have a comprehensively secure data backup that enables fast ransomware recovery, through its Tiered Backup Storage offering.
…
Data pipeline supplier Fivetran announced the opening of its new EMEA headquarters in Dublin. Over the past three years, Fivetran has increased headcount in EMEA by almost 200 employees. Recruitment continues across Dublin, London, Amsterdam, Munich and its latest European location in the Serbian city of Novi Sad.
…
Harriet Coverston
FMS: The Future of Memory and Storage, the world’s conference highlighting advancements, trends, and industry figures in the memory, storage, and SSD markets, announced that Harriet Coverston, CTO and co-founder of Versity Software, has won the SuperWomen of FMS Leadership Award for 2024. Her work included developing the Quick File System (QFS), which laid the foundation for SAM-QFS. SAM-QFS was the first multi-node clustered file system combined with archiving, addressing the high-performance scaling needs of large real-time streaming data systems.
…
NVMe storage system provider HighPoint Technologies announced a strategic partnership with Phison. It says this collaboration promises to revolutionize compact PCIe storage systems for x86 server and workstation platforms. HighPoint’s NVMe Gen5 x16 Switch & RAID AIC Series, when equipped with Phison-powered M.2 NVMe SSDs, delivers the world’s fastest, densest, secure and field-proven PCIe Gen5 x16 NVMe storage in today’s marketplace, suitable for a wide range of applications and workflows including Data Centers, Professional Workstations, SMB platforms and personal computing.
…
HighPoint Technologies says it will unveil the Industry’s first PCIe Gen5 x16 NVMe SSD systems to deliver nearly 60GBps of real-world transfer performance and up to 2 Petabytes of storage capacity from a single PCIe slot at FMS 2024. It will be introducing its Real-time Advanced Environmental Sensor Logging & Analysis Suite,“which enables customers to take a proactive approach to NVMe storage management by closely monitoring the hardware environment in real-time.”
…
Cybersecurity company Index Engines announced new data integrity reporting within the CyberSense product to empower data protection and security teams to quickly understand and explain the health status of protected data. CyberSense indexes over 5 exabytes of customer data daily. The new data integrity homepage within the CyberSense 8.7 user interface displays insights into the data that CyberSense has analyzed, details on its integrity, and assurance that triggered alerts are addressed. This content is easily integrated into security platforms to collaborate on data protection and cybersecurity strategies.
…
Enterprise cloud data management company Informatica announced its Q2 FY 24 earnings, beating guidance across the board, and demonstrating “that Informatica continues to be the go-to cloud data management platform to help enterprises prepare their data for GenAI.” Highlights from the quarter include:
Total Revenue: Increased 6.6 percent to $400.6 million
Total ARR: Increased 7.8 percent to $1.67 billion
Subscription ARR: Increased 15 percent year-over-year to $1.20 billion
Cloud Subscription ARR:Increased 37 percent year-over-year to $703 million
These results follow the general availability of CLAIRE GPT – the first GenAI-powered data management assistant now available in North America – as well as expanded partnerships with Microsoft, Snowflake and Databricks.
…
Kioxia Kitakami plant with K2 on the left and K1 on the right
Kioxia announced that the building construction of Fab2 (K2) of its Kitakami Plant was completed in July. K2 is the second flash memory manufacturing facility at the Kitakami Plant in the Iwate Prefecture of Japan. As demand is recovering, the company will gradually make capital investments while closely monitoring flash memory market trends. Kioxia plans to start operation at K2 in the fall of 2025. Wedbush analyst Matt Bryson tells subscribers “Per the Nikkei, Kioxia’s plan of record now calls for production to commence in the second Iwate fab in 2025. We believe the ramp of the new fab likely will coincide with the more significant ramp of Kioxia and WD’s BICS8 products. And assuming the Nikkei is correct with its assertion around timing of the fab, it suggests to us that incremental NAND bits from the JV partners will remain at minimal levels until CQ4 of next year. With other vendors, in our view, adopting a similar stance regarding incremental production, we believe NAND fundamentals are set to remain favorable for producers for a prolonged period.”
…
Canadian cloud and IaaS provider Leaseweb announced an object storage service with “highly competitive pricing”, S3 compatibility, Canadian data sovereignty and 99 percent uptime by redundantly spanning data across three availability zones. More info here.
…
Dr Tolga Kurtoglu
Lenovo has appointed Dr Tolga Kurtoglu as the company’s new CTO, succeeding Dr. Yong Rui. Dr. Kurtoglu brings experience from his previous roles at HP, Xerox Palo Alto Research Center, and Dell. His expertise lies in AI, automation, and digital manufacturing. Dr. Kurtoglu will lead Lenovo’s Research team and innovation ecosystem, ensuring alignment with the Group’s technological vision and business objectives. He will also join Lenovo’s Executive Committee. Lenovo has established a new Emerging Technology Group, led by Dr. Yong Rui, which will focus on identifying and leveraging emerging tech trends to fuel future business growth.
…
Lenovo has joined forces with Databricks to drive AI adoption amongst its customers. As a Databricks Consulting & Systems Integration (C&SI) Select Tier Partner, Lenovo will work with businesses to help them take advantage of enhanced data management capabilities, streamlining access to data from multiple sources and removing barriers to successful AI usage.
…
MemVerge tells us that, during the last year, the CXL vendor community has piqued the interest of IT organizations with the promise of products offering more memory bandwidth and capacity for their memory-intensive apps. During the last year we’ve seen announcements for CXL memory modules and software support from MemVerge, Red Hat, and VMware. The last breakthrough needed get CXL technology into customer’s hands is the availability of servers. At FMS, August 6-8 in Santa Clara, you’ll see in booth MemVerge #1251 a server from MSI that’s integrated with memory peripherals and software, and available for Enterprise PoCs. In fact, the server on the show floor is being shipped to a multi-billion-dollar corporation immediately after the event.
…
Cloud file services supplier Nasuni announced a couple of award wins in recognition of their customer service. For the fourth year running, it’s received a NorthFace ScoreBoard Service Award. Nasuni achieved an “excellent” NPS score of 87. For its overall technical support, Nasuni achieved an SBI rating of 4.8 and a 9.5/10 CSAT rating. Nasuni has also achieved eight Badge Awards in G2’s 2024 Summer Reports in categories including Hybrid Cloud Storage Solutions and Disaster Recovery.
…
SSD and SSD controller supplier Phison will show an affordable, reliable, secure in-house AI training solution, aiDAPTIVE+, powered by its Pascari SSD, at FMS 2024 this month. It features:
An inhouse LLM system that can be trained and maintained on premises
A cost of $40K plus fees for electricity and power
Organizations fully own their data and can fine tune it
A turnkey solution: No additional IT or engineering staff is required to run it
Minimized security risks
Over 100 enterprises are using it with 12 distinct use cases in less than a year
Removal of universal pain points like onboarding new employees, ongoing professional development, keeping up with coding demands, and automation of tasks that can keep up with huge data volumes.
Trained data that reveals valuable inferences to deliver immediate business value
…
Wedbush analyst Matt Bryson gave subscribers his view of Samsung’s latest and solid memory results
View: Samsung’s memory results and outlook appeared in-line to slightly better than expected.
DRAM bits lifted mid single digits (in line with expectations) while ASPs lifted in the high teens.
NAND bits lifted mid single digits (slightly above the prior guide) with ASPs up in the low 20 percent range.
Samsung guided for low single digit bit growth in both categories in CQ3.
HBM revenue lifted 50 percent Q/Q with Samsung indicating sales will continue to lift through the 2H (with 2H sales expected to be 3.5X 1H results). Management also is looking at HBM capacity doubling into 2025, with some suggestion they might have to lift their capacity plan further to meet customer demand.
HBM3E sales roughly tripled Q/Q. Samsung shipped samples of HBM3E (8H) and expects mass production to start this quarter. HBM3E (12H) has sampled with Samsung noting supply will expand through the 2H. HBM3E sales are expected to represent a mid-teens percentage of HBM revenue in CQ3 and around 60 percent of HBM3E sales in CQ4.
Samsung noted industry capacity adds for standard products appear to remain limited given modest capex and the focus on HBM.
We believe Samsung’s results (in particular slightly better NAND volumes and strong pricing) will be seen as positive for US memory vendors, particularly post Hynix’s results and subsequent concerns NAND demand in particular might be slowing.
…
Leostream and Scale Computing today announced a joint integration delivering virtual desktop infrastructure (VDI) for distributed enterprise, SME/SMB, education, and others for whom VDI has been unrealistically complicated. As an alternative to VMware Horizon they have developed a streamlined, complete hardware/software architecture for hosting Windows and/or Linux desktops with greater ease of deployment, best-in-class support, and a competitive price point. Features include:
Robust tools for dynamic resource allocation to allow more efficient use of hardware and better handling of peak loads compared to more static allocation methods
Support for hybrid cloud environments with seamless management of both on-premises and cloud-based resources
Optimized performance for different workloads ensures that applications run smoothly, providing a better end-user experience
High availability features for minimal downtime and reliable access to mission-critical applications
Advanced security features such as multi-factor authentication, role-based access control, and end-to-end encryption, ensuring that virtual environments remain secure
Granular control over virtual environments that allows administrators to fine-tune settings according to specific needs
Support for custom configurations and automation to streamline operations and reduce administrative overhead
Support for the widest range of remote display protocols to meet the needs of even specialty applications
Highly intuitive and centralized management console that is easier to use than more fragmented approaches
Real-time analytics and monitoring tools for deep insights into the performance and usage of virtual resources
Streamlined installation and configuration for intuitive, fast setup – less than four hours from start to finish
Dedicated and responsive support
A more cost-effective licensing model to optimize IT budgets
…
SK hynix introduced what it claimed is the industry’s best GDDR7 memory with improvement of 60 percent in operating speed (32 Gbps) and 50 percent in power efficiency. The company increased the layer number of the heat-dissipating substrates from four to six, while applying the EMC (Epoxy Moulding Compound) for the packaging material in a bid to reduce thermal resistance by 74 percent, compared with the previous generation, while maintaining the size of the product unchanged. Speed can grow up to 40Gbps depending on the circumstances. When adopted for the high-end graphics cards, the product can also process data of more than 1.5TB per second. It will be mass produced in 3Q24.
…
Storage supplier Swissbit introduces its first PCIe Gen5 SSD; the D2200 series offering performance of up to 14 GBps for sequential read and 10 GBps for sequential write. It has a sequential read performance of up to 970 MB/s per watt.The series supports NVMe 2.0 and OCP 2.0, making it future-proof. Comprehensive data protection features, including TCG Opal 2.0, are standard. The Swissbit D2200 will be available in U.2 and E1.S form factors with storage capacities of 8 TB and 16 TB in late August, with a 32 TB version in U.2 format following at the end of 2024.
…
Enterprise application data management supplier Syniti announced Q2 2024 results:
Cloud ARR increased 26 percent year over year and was up five percent from Q1 2024.
Software bookings grew 28 percent over Q1 2024 and were up 23 percent from Q2 2023.
Total quarterly revenue was up 8 percent when compared to Q2 2023, with services revenue rising 11% from a year ago.
The company reported an EBITDA margin in the mid-teens.
More than 11 clients with over $1 million in bookings.
Strong software renewals at longstanding clients in aerospace and defence and manufacturing, life sciences, oil & gas.
Robust volume with its SAP business with more than 50 percent of software annual contract value coming from the partnership; Syniti’s software is sold as a SAP Solution Extension and is available as an Endorsed App on SAP Store.
The company expanded its client base with 15 significant new logos in the quarter, adding five more Global2000 organizations to its customer roster including major players in retail, food & beverage, manufacturing and life science.
…
Andre Carpenter
Cloud storage provider Wasabi has appointed Andre Carpenter as the managing director of its Australia and New Zealand business as the company continues to rapidly expand in the region. Cloud storage adoption is growing in Australia, with 89 percent of Australian organizations expecting to increase the amount of data they store in the public cloud in 2024, according to the APAC Wasabi Cloud Storage Index. Most recently, Andre was the APAC director of cloud solutions at Crayon, a global technology and digital transformation service company. In addition, Andre has also held leadership roles across sales and consulting for global technology companies including Dell EMC, Hewlett Packard Enterprise, NetApp, Oracle and Veeam.
…
AI-native vector database company Weaviate is releasing a developer “workbench” of tools and apps along with flexible tiered storage for organizations putting AI into production. They include:
Recommender app: Provides a fully managed, low-code solution for rapid development of scalable, personalized recommendation systems. Recommender offers configurable endpoints for item-to-item, item-to-user, and user-to-user recommendation scenarios and supports images, text, audio and other forms of multimodal data. Sign up to be part of the private beta.
Query tool: Enables developers to query data in Weaviate Cloud using a GraphQL interface. Available now through Weaviate Cloud Console.
Collections tool: Allows users to create and manage collections in Weaviate Cloud without writing any code. Available now through the Weaviate Cloud Console.
Explorer tool: Lets users search and validate object data through a graphical user interface (GUI). Coming soon to Weaviate Cloud Console.
…
ReRAM developer Weebit Nano has taped out its first chip in DB HiTek’s 130nm BCD process. It’s targeting completion of qual/production readiness in the 2nd calendar quarter of 2025. DB HiTek customers can get started now. On Aug. 7, during FMS: The Future of Memory and Storage, Weebit’s VP of Quality & Reliability Amir Regev will share the latest Weebit ReRAM technical data including results on GlobalFoundries 22FDX wafers – the first such ReRAM results.
Big Blue developed its own Vela cluster, using Storage Scale, to train its AI models.
IBM’s next generation AI studio, watsonx.ai, which became generally available in July of 2023, was trained on the Vela cluster. Storage Scales is a parallel filesystem and Vela uses it as a quasi-cache in front of object storage, speeding data IO to keep GPUs busy.
The Vela infrastructure powering IBM’s Gen AI model development is described in a freely available research paper.
It describes Vela as a cluster of CPU/GPU servers hosting virtual machines in the IBM Cloud. The server nodes are twin-socket systems with, originally, Cascade Lake Gen 2 Xeon Scalable processors plus 1.5TB of DRAM and 4 x 3.2TB NVMe SSDs, 8 x 80GB Nvidia A100 GPUs, using NVLink and NVSwitch. The Xeons were later upgraded to IceLake.
A 2-level spine-leaf Clos structure, (nonblocking, multistage switching network) based on 100Gbps network interfaces, links the nodes together. The storage drives are accessed over Remote Direct Memory Access (RDMA) over Converged Ethernet (RoCE) and GPU-direct RDMA (GDR). GDR with RoCE allows GPUs on one system to access the memory of GPUs in another system, using Ethernet network cards. Congestion management is built into the networking subsystem.
Vela is operated by IBM Cloud as IaaS (Infrastructure as a Service). Red Hat OpenShift clusters are used for tasks that span the entire AI lifecycle, from data preparation to model training, adaptation, and ultimately model serving.
The data needed for the AI training is held in object storage but this is too slow for both reading (needed for job loading) and writing (needed for job checkpointing). The IBMers decided to use Storage Scale: “a high-performance file system … inserted between the object storage and the GPUs to act as an intermediating caching mechanism. In doing so, the data can be loaded into the GPUs much faster to start (or re-start) a training job, and model weights can be checkpointed to the file system at a much faster rate than when checkpointing directly to object storage. Thanks to unique technology in the file system we use, the checkpointed data can then be asynchronously sent to object storage but in a way that does not gate progress of the training job.”
A Scale client cluster runs across Vela’s GPU nodes in container-native mode leveraging the CNSA edition of Scale. The paper states Vela: “uses Kubernetes operators to deploy and manage Scale in a cloud-native fashion as well as a CSI Plugin for provisioning and attaching persistent volumes based on Scale. The client cluster does not contain any locally attached storage devices and instead performs remote mount of the file system in the storage cluster. Such an architecture allows compute and storage clusters to grow and shrink independently as workload requirements change.”
It says: “We configure Active File Management(AFM) technology to transparently connect filesets to object storage buckets. File system namespaces represent objects in buckets as files and brings data from the object storage into the file system on demand. When a file is written to the file system, AFM eventually moves it to object storage.”
The total capacity of this Scale parallel file system, using all attached devices, is hundreds of TBs.
The research paper says: “Scale is deployed in Vela using a disaggregated storage model. The dedicated Scale storage cluster consists of tens of IBM Cloud Virtual Server Instances (VSIs) with two 1TB virtual block volumes attached to each instance. The virtual block volumes are hosted on a next-generation cloud-native and highly performant block storage service in IBM Cloud that can meet the high throughput requirements of model training workloads.”
We’re told by a source close to IBM that before it deployed this storage solution based on Scale, “AI researchers using Vela could either use IBM COS directly or an NFS file system that was deployed for Vela.
“Compared to NFS performance, our Scale file system achieves a near 40x read bandwidth speedup (1 GBps vs 40 GBps with Scale), which directly helps with input data read operations. Also compared to IBM COS bandwidth, the Scale file system achieves a near 3x write bandwidth speedup (5 GBps vs 15 GBps with Scale), which accelerates the checkpoint and other data write operations.”
This was based on data from iteration times for a Granite-13B AI training job using NFS and another Granite-8B job using the Scale file system.
Training jobs can take a month or more to run, as a table in the paper indicates:
Vela was overhauled in 2023 with the larger and more powerful Blue Vela cluster, which came online in April this year and was built with Dell and Nvidia. We’ll describe this in a second article.