Enterprise backup is a huge and overcrowded market. But HYCU, a new arrival on the block, thinks it has found a couple of lucrative backwaters that are underserved by competitors.
The company has set out its backup software stall for Nutanix and Google Cloud Platform.
HYCU was spun out of Comtrade, a Boston, Mass. technology holding group, in April 2018. There are some 300 HYCU employees, including 200 engineers, and a 700-strong customer base.
HYCU’s go-to market challenge is to grow without engaging in bruising full-frontal warfare with well-established and rich competitors.
The chosen strategy, CEO Simon Taylor reveals, is to find under-served areas with backup growth potential, get close and stay close with a purpose-built offering. The company thinks two technologies fit these criteria: Nutanix and Google Cloud Platform (see my 2017 HYCU-Nutanix article).
Even in its chosen markets, HYCU has plenty of competition. For instance, for Nutanix backup, competitor Arcserve has integrated its UDP protection product with Nutanix’s AHV hypervisor. Rubrik’s Alta software release last year also features AHV support.
How to cover a LOB
HYCU thinks a single backup product to cover all use cases won’t work and isn’t working.
For instances lines of business (LOBs) within companies are gaining more purchasing power and are buying their own data protection products. And trend for LOBs is to embrace a hybrid and multi-cloud strategy,
That means data protection has become less sticky and LOBs are increasingly willing to switch to best of breed backup products that suit them, according to HYCU.
Market research appears to support HYCU’s thesis. A survey published in November 2018 reveals enterprises are using several backup vendors.
So. no one-size fits all backup vendor exists. What instead? HYCU’s Taylor says you need workload products purpose-built for individual on-premises and cloud applications, unified under a single management layer.
HYCU management dashboard
HYCU has unified management of its purpose-built backup products under a single, central pane of glass management.
V3.5 release
A v3.5 update of HYCU’s Nutanix software adds support for systems running SAP HANA. HYCU says it’s the first supplier to provide storage-level snapshots for SAP HANA workloads on Nutanix. Customers can also get clones of their SAP HANA environments with a button click.
The latest version supports Volume Groups (block) as well as files (AFS), objects and virtual machines. Volume Groups are used by Nutanix performance-sensitive applications.
Blueprints provide 1-click provisioning of an entire backup infrastructure on a Nutanix storage node.
HYCU has added backup support for Microsoft SQL Failover Cluster, without the need for any agents.
Samsung has started shipping the 860 QVO, a 4TB QLC consumer SSD.
QLC means quad-level cell flash and 4bits per cell – one more than the typical TLC (3bit/ cell) flash used in many SSDs today.
The downsides of higher capacity are slower read/write speeds and lower endurance than TLC. But drive controller and over-provisioning.can mitigate this.
The 2.5-inch form factor 860 QVO uses 32 x 1Tbit (128GB) 64-layer V-NAND dice and comes in 1, 2 and 4TB versions. It has a 6Gbit/s SATA interface.
The drive incorporates a Samsung MJX controller and employs a secondary SLC (1bit/cell – the fastest flash) cache (TurboWrite technology) to speed write performance; with the 1TB drive getting 42GB and the others 78GB of cache. Random read/write IOPS are up to 97,000 and 89,000 respectively, which is unexpectedly balanced. Typically, results skew to reads.
Sequential bandwidth is up to 550MB/sec for reads and 520MB/sec for writes.Random and sequential numbers are similar to Samsung’s TLC 860 EVO SSD but write speeds will drop if the stream of incoming data overwhelms the SLC cache.
There is a three-year warranty and the 4TB drive supports 1,440TB written (TBW), with the 2TB one supporting 720TBW and the 1TB version 360TBW. That means the 4TB drive supports roughly 1.3 drive writes per day (DWPD).
Samsung vs. Intel
Intel has dropped a pair of QLC SSDs on the market, the SSD 660p M.2 format consumer drive and the D5-P4320 data centre drive.
How does the Intel 660p, with its 512GB, 1TB and 2TB capacities, compare on speed with Samsung’s 860 QVO ? The short answer is – very well indeed.
That said, the drives are aimed at different markets. For instance, the 860 QVO can be used to replace a 2.5-inch disk drive: Intel’s 660p cannot. Intel’s 660p can accelerate a consumer desktop or laptop much better than the 860 QVO.
The Intel drive has an NVMe v1.3 PCIe 3 x 4 interface, which is much faster than the 860 QVO’s 6Gbit/s SATA. This enables it handle to up to 220,000 random read and write IOPS and 1,800 sequential read and write bandwidth.
The drive is warranted for five years and supports 0.1 DWPD.
The 860 QVO is available this month and costs $149 for 1TB, $299 for 2TB and $499 for 4TB. At time of writing, a 2TB Intel 660p costs $436.99 on Newegg.
NetApp is bulking out its public cloud offering with three new services for Azure, Google Cloud Platform and Salesforce.
The company aims to deliver a single, consistent IT environment in which workloads and applications can move between and use mainstream public clouds and customer on-premises data centres.
Today’s announcements are not significant per se but they show NetApp’s progress in building that overarching data fabric.
Now for a summary of the NetApp cloud news. The company will reveal more details this week at NetApp Insight 2018 in Barcelona.
Azure NetApp Files
Azure NetApp Files provides ONTAP storage and data management capabilities for storing, moving and deploying file-based workloads in Azure.
Microsoft will sell and support the service which is in preview in certain Azure regions. NetApp says it will add more capabilities in coming months.
Cloud Volumes for GCP
NetApp is offering more coverage of Cloud Volumes for Google Cloud Platform with a European Union West3 region.
NetApp says Cloud Volumes for GCP can move analytics to the Google cloud and clone hundreds of database environments in minutes inside automated test and dev environments.
Users can revert to the original database if anything goes wrong.
NetApp SaaS Backup for Salesforce
SaaS Backup for Salesforce provides automated backups, choice of backup targets, unlimited retention, and the ability to go back to a point in time and restore at different granularities.
It accompanies NetApp’s SaaS Backup for Office 365 and in both cases NetApp says it provides better data protection than native Office 365 and Salesforce facilities.
Users can manage both SaaS offerings from a single console.
Delphix virtualizes Amazon’s Relational Database Service in new ways beyond logical replication, and farms out test and dev copies in minutes.
Delphix virtualizes on-premises production databases, such as Oracle and SAP, and pumps out copies quickly to test and dev and other users needing access to production-class data.
AWS’s Relational Database Service (RDS) supports Oracle, SQL Server and PostgreSQL, MySQL and Aurora, AWS’s own MySQL-compatible database.
Data has inertia and friction and can’t move easily, even in the cloud. Delphix’s automated RDS environment provisioning counters this obstacle for the testers and developers using AWS RDS.
Delphix claims to handle EC2 provisioning of RDS production database copies to development and test teams faster than any alternative method.
It moved into AWS in December last year, supporting Oracle DB on Amazon’s RDS. The Delphix Dynamic Data Platform (DDP) works with the AWS Database Migration Service (DMS), using logical replication to continuously replicate data to and from RDS and EC2 instances.
Delphix’ VP for marketing, Alex Plant, told us that: “While successful, this solution presents many edge conditions and challenges when it comes to creating like-for-like copies of data outside of the RDS environment.”
The AWS RDS and Delphix engineering teams worked together to improve things and this latest announcement details new RDS-DDP integrations.
Plant said: “For Oracle, they developed the capability to automate the creation of Oracle backup files in S3, and we developed a plugin that could ingest from those backups (S3 or not) into the Delphix platform.
“For MySQL, this was already available as a replication offering that we could integrate with.”
With this update, customers are able to support “true like-for-like database copies in Delphix, without the additional complexity and fragility of logical replication…Today we support Oracle and MySQL ingestion and are working with the RDS team and key customers to expand to PostgreSQL, Aurora, and SQLServer.”
Anurag Gupta, VP Analytics, Aurora, and RDS for AWS said the Delphix relationship means the companies can improve database management and deliver performance enhancements for enterprise customers.
Delphix has integrated data masking to redact sensitive data and extensible plugins support Oracle, PostgreSQL, and MySQL, and more to come. Users get self-service controls to refresh, branch, bookmark, and share data, integrated via APIs with DevOps tools and the Delphix Automation Framework.
Here is a snapshot of press and conference announcements to go with your morning’s coffee, tea, smoothie or some other beverage.
Cohesity goes up the Amazon
Cohesity, a converger of secondary data storage, has its software running inside AWS and using Elastic Block Store (EBS) snapshot APIs to protect cloud-native virtual machines (VMs).
The DataProtect software has auto-discovery and auto-protect capabilities so backups scale automatically as cloud-based workloads are added or deleted. Admins can set backup policies for different virtual machines (VMs) that automatically match different service level agreement (SLA) requirements.
On-premises Cohesity deployments can use AWS for disaster recovery, with fail-over and fail-back capabilities. If there is a data center outage then automated policies activate backup VMs on AWS and then bring the workloads back to the original location when the incident is over.
The on-premises Cohesity can also pump data, via policy-based protection tasks, into Amazon’s Snowball data collection device, used to transfer large amounts of data into AWS.
E8 and SPEC SFS 2014
We received this note from Julie Herd, Director of Technical Marketing for E8: “We were looking at your [NetApp SPEC SFS 2014] article and the latest SPEC results, and agree that having a $ metric as part of the results would be interesting.
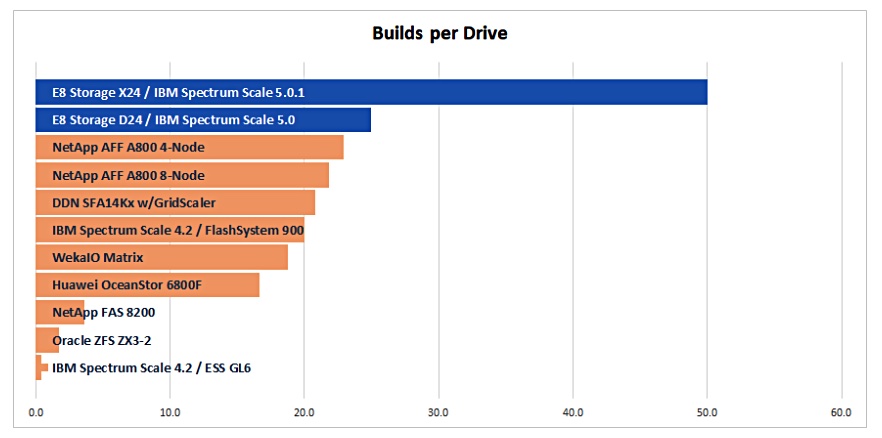
“One derived metric that we thought might be interesting to look at is builds / drive as a (very) rough indicator to show the usage efficiency of the media.
E8′ chart of SW Builds per drive
“Just a thought, not sure if you think it would be useful, but wanted to provide it to you. The graph includes all of the results (HDD+SSD) except for the Weka IO AWS results since that doesn’t report the drives attached on the AWS instance.”
Interesting idea. As a reminder here is the chart of recent supplier SW Build scores from the SPEC SFS 2914 benchmark.
Perhaps we’ll see E8 have another run at the benchmark using more media and getting a higher result.
HPE OEMs Cohesity
HPE is OEMing Cohesity’s data management software. This converges secondary data onto master copies which can be used to furnish data sets for analytics, test and dev and other purposes.
Cohesity has been certified for use on HPE Apollo and ProLiant server offerings. Mohit Aron, CEO of Cohesity, said HPE has “committed sales, marketing, and technical support resources,” to bring the joint offering to market.
HPE and Cohesity quote Vanson Bourne research that shows over a third of organizations use six or more products for secondary data operations and 10 per cent use 11 or more products. Cohesity claims its single product can replace multiple alternatives, saving customers time, money and management expense.
The joint HPE-Cohesity products are available from HPE and channel partners in Spring 2019. Until then Cohesity software is available through the HPE Complete program.
Red Hat buys NooBaa
Red Hat has bought object storage and inter-cloud transfer startup NooBaa, founded by ex-Exanet and former Dell Fluid File System people in Israel in 2013. It received seed round funding of $2m in 2014, another $2 million in bridge funding in early 2015, and there were two funding events in 2017; the amounts were not revealed.
NooBaa developed object storage software that uses under-utilized compute cores and storage capacity on x86 servers and desktops in a customer’s data centres and makes it accessible as an S3-like cloud service. In late 2016 it announced a bridge between this and Microsoft Azure’s blob store, using an S3 interface to move data to and from Azure,
This technology was developed as an abstraction layer across multiple public clouds and the on-premises world so users could move and manage data in a hybrid environment. It will be used by Red Hat alongside its OpenShift Container Platform, Open Shift Container Storage and Ceph Storage.
The acquisition cost was not disclosed.
Where did the somewhat odd company name of NooBaa come from? The founders wanted to register a web domain of noob.com, as they were noobs, newcomers. It was already taken so they went with NooBaa as an alternative from GoDaddy. Now you know.
One thought: IBM”s investigations when it bought Red Hat for $34bn must have revealed this pending NooBaa acquisition and it was, presumably, approved by IBM.
People on the move
Cloudian has appointed Lenovo executive John Majeski as an observer of its board of directors to provide expert perspective and strategy. He heads the Software and Solutions Defined Infrastructure business at Lenovo, focusing on setting overall product strategy and growing market share.
Jeremy Burton, ex-marketing head at Dell, is now the CEO of a stealthy startup called Observe, Inc. It was founded in 2017, and he joined it in October.
Observe’s founder is Antonov Vadim, who was a founding engineer at Snowflake Software, the data warehouse in the cloud company. He calls himself the Crazy Russian on LinkedIn.
The company is based in San Mateo and offers application performance management tools based on a versatile observability platform. Observe will take on competitors such as Dynatrace and Virtual Instruments.
Crunchbase has no listing for it and we have no funding information. LinkedIn lists under a dozen employees.
Mark Long has resigned as Western Digital’s CFO, effective June 1, 2019, to pursue private equity opportunities. Long has been CFO since 2016, and as its chief strategy officer and an EVP from February 2013. He is also the president of Western Digital Capital, an investment fund, and was involved with both the HGST and SanDisk acquisitions.
HCI vendor Scale Computing has announced the appointment of Mark Sproson, as country manager for UK and Ireland. He’ll be responsible for identifying new business, significantly boosting sales, and continuing to grow the company’s channel business, through both new and existing partnerships. Prior to joining Scale Computing, Sproson held sales and partnership roles at Nexsan, Quantum Storage and CA Technologies.
Shorts
Arcserve UDP has been integrated with HCI Market leading Nutanix’ AHV hypervisor. UDP provides agentless backup of Windows and Linux workloads running on Nutanix AHV, and recovery to virtualised and cloud environments such as VMware, AWS, Azure, Hyper-V or AHV itself. Users get protection of physical servers, virtual machines and cloud instances with disaster recovery to AHV using UDP’s Instant VM and Virtual Standby. UDP On AHV will be available in early 2019.
Clifton College, an independent school in the UK with some 2,000 students, is using Arcserve’s UDP for data protection. It has scalable storage for the estimated 5 to 6 TB of data growth every six months and its Recovery Point Objective has shortened from 24 hours to 15 minutes.
Data protector Asigra says its customers are using its Cloud Backup V14 software to prevent ransomware attacks which use attack loops to infiltrate backup data sets. Cloud Backup V14 detects ransomware infections in the backup stream, isolates the infected files, prevents them from being backed up, and notifies the administrator(s). Admin staff can then identify the infected files and remove them before they detonate. Watch a video discussion about this here.
Cobalt Iron, a provider of enterprise data protection SaaS, has been issued a patent (U.S. Patent No. 10133642) for its techniques for presenting views of a backup environment for an organisation on a sub-organisational basis. The new Cobalt Iron patent discloses unique ways to manage and track IT resource usage in complex, multi-tenant environments.
DataDirect Networks (DDN) is collaborating with India’s Council of Scientific Industrial Research – Central Electronics Engineering Research Institute (CSIR-CEERI) to develop systems for AI, machine learning and deep learning. CSIR-CEERI’s customers should get AI as a service from January 2019.
The two will look at producing joint research, solution blueprints, and AI and DL intellectual property related to accelerating performance through data accessibility to computation clusters. CSIR-CEERI’s Naraina Center has a 5 petaFLOP Cluster which uses NVIDIA DGX-1 servers and DDN storage, which will be used to develop and test the the DDN-CSIR-CEERI research, bluepprints and so forth.
Rubrik’s data protection and management software supports Amazon’s S3 Intelligent-Tiering storage class. With this extension low-access rate archive data can be stored more cheaply.
Seagate has sponsored an IDC white paper; TheDigitization of the World – From Edge to Core, which says that, while Healthcare currently has the smallest share of the global enterprise datasphere among key industries examined in the study, it is primed to grow the fastest, far surpassing the Media and Entertainment sector and matching the Financial Services sector by 2025. Download the paper here.
Storage Made Easy has integrated Microsoft Office Online with its File Fabric product so that hosted File Fabric users can edit files stored in Amazon S3, Cloudian, Microsoft Azure, Google Cloud Storage or any of the 60+ storage and data clouds supported, directly in the SME File Fabric using Microsoft Office Online.
The SNIA has an “Emerging Memory Poised To Explode” webcast on Dec 11 at 10am PT and afterwards available on demand. The moderator is Alex McDonald and the two presenters are Tom Coughlin of Coughlin Associates and Jim Handy from Objective Analysis; both know what they are talking about and we expect SCM content. Register here.
Veeam’s N2WS business unit introduced Amazon Elastic Block Store (Amazon EBS) snapshot decoupling and and N2WS-enabled Amazon Simple Storage Service (Amazon S3) repository with N2WS Backup & Recovery v2.4 software, claiming customers using it can reduce storage costs by up to 40 per cent. Users, including managed service providers, can choose different storage tiers and reduce costs for data being retained for longer terms.
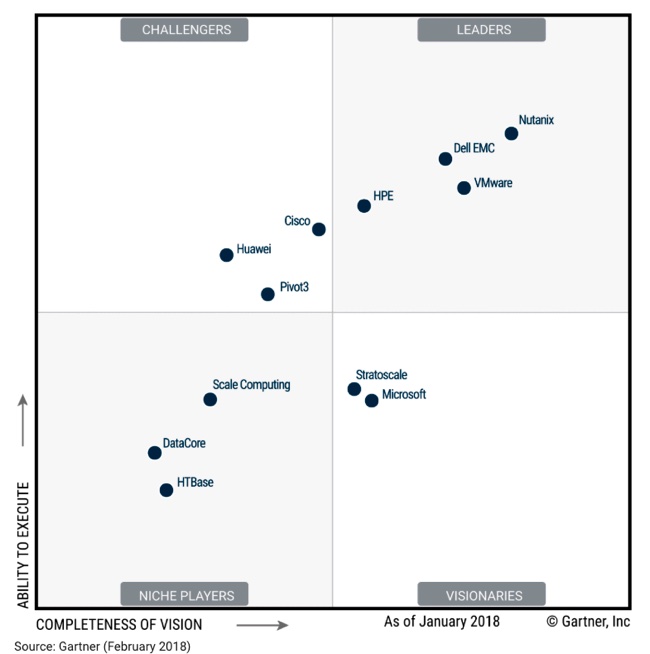
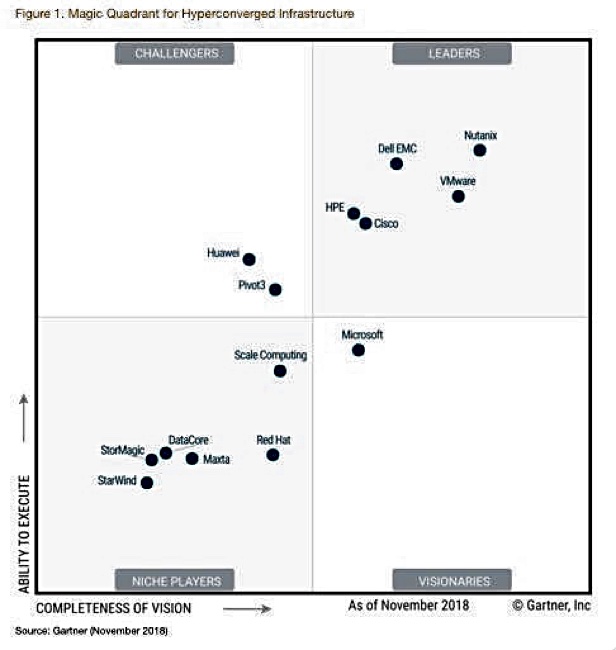
Cisco’s HyperFlex hyper-converged system has joined the leaders’ squad, getting promoted from from the challenger’s square and overtaking HPE – just, in the latest HCI Magic Quadrant from Gartner.
Here’s a standard MQ explainer: the “magic quadrant” is defined by axes labelled “ability to execute” and “completeness of vision”, and split into four squares tagged “visionaries”, “niche players”, “challengers” and “leaders”.
Gartner put out a hyper-converged infrastructure (HCI) systems MQ in February, defining HCI systems strictly as virtualisation + compute + storage in one enclosure with one order number (SKU). It did not include semi-HCI systems from the likes of Datrium and NetApp in its definition and they were absent from the February HCI MQ, and are absent from this updated one.
Here are the two MQs;
February 2018 edition
November 2018 edition, enlarged from small Twitter tweet image.
Instantly we can see Cisco’s move rightwards from the Challenger’s square to the Leader’s box. The overtake of HPE is extra pleasure for Cisco, who is mightily pleased overall, saying the Leaders’ box entry has happened after just 2.5 years shipping the acquired Springpath product to its more than 3,500 customers.
Nutanix leads the leaders, followed by Dell EMC and VMware, then Cisco, with HPE close behind
Absent Cisco, Huawei and Pivot3 have roughly unchanged positions in the Challengers’ square.
In the Visionaries’ box we see Microsoft on its own; Stratoscale having been ejected, and that company now has a focus on cloud-native products and services.
Next door the niche players squad has increased from three players in February to six today, with the additions of Maxta, Red Hat, StarWind and StorMagic, and the elimination of HTBase. Scale Computing has moved up and right to continue leading the niche players.
Gartner gives honourable mentions in its HCI MQ report to Datrium, Fujitsu, Hitachi Vantara, Lenovo, NetApp, the New H3C Group, Riverbed, Robin Systems, Sangfor Technologies and ZeroStack.
We can only begin to imagine the intensity of the discussions there must have been between suppliers such as Datrium and NetApp and the Gartner analysts about inclusion in the MQ. What fun!
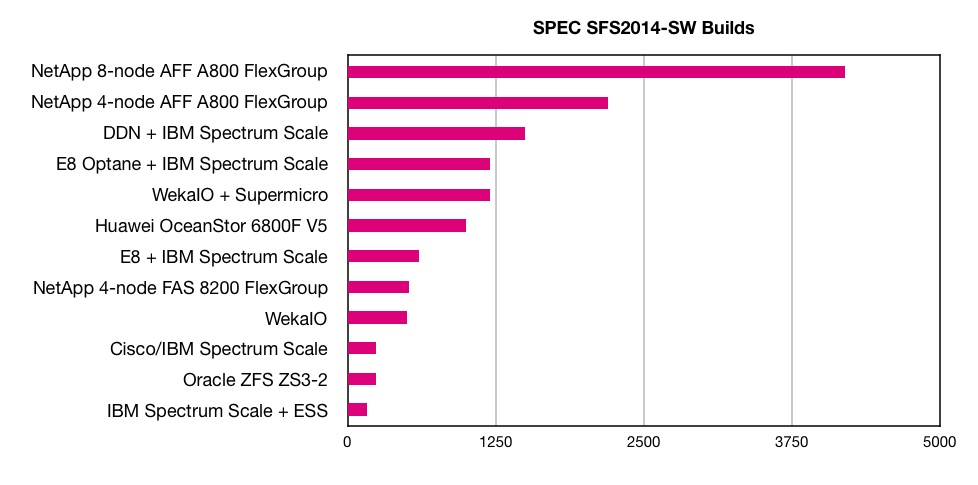
All-flash NetApp filers have blown the SPEC SFS 2014 SW Build benchmark record to hell and gone.
A 4-node system scored 2,200 and an 8-node one 4,200 – 2.8 times faster than the previous DDN record score of 1,500, which is only two months old.
That was set by all-flash SFA 14KX array, fitted with 72 x MLC (2bits/cell) SSDs, 400GB SS200 SAS drives, and running IBM’s Spectrum Scale parallel file system.
The SPEC SFS 2014 benchmark was introduced in January 2015 and tests five separate aspects of a filer’s workload performance:
Number of simultaneous builds that can be done (software builds)
Number of video streams that can be captured (VDA)
Number of simultaneous databases that can be sustained
Number of virtual desktops that can be maintained (VDI)
Electronic Design Automation workload (EDA)
NetApp just ran the SWBuild workload, which is the most popular benchmark. It used an all-flash AFF A800 array, running its ONTAP software, and fitted with NVMe SSDs, and in 4-node and 8-node configurations.
In detail, the 4-node setup consisted of a cluster of 2 AFF A800 high availability (HA) pairs (4 controller nodes total). The two controllers in each HA pair were connected in a SFO (storage failover) configuration. Each storage controller was connected to its own and partner’s NVMe drives in a multi-path HA configuration.
A previous NetApp filer scored a much lower 520 on this benchmark in September 2017. That was a 4-node FAS8200 array, configured as two HA pairs, with 144 x 7,200rpm disk drives and 8 x NVMe 1TB flash modules set up as a Flash Cache.
We asked NetApp’s Octavian Tanase, SVP of the Data ONTAP Software and Systems Group, what made the A800 so fast. He said: “ONTAP has been optimised over the years to deliver consistent high-performance for NAS workloads.”
NetApp has “focused on reducing latency and increase IOPs on AFF. We have also overhauled our processor scheduling and dramatically improved our parallelism for our high-core count platforms. … In addition, our NVMe backend software stack on A800 provides further reduction of latency.”
He pointed out that compression and deduplication were switched on during the benchmark run. And: “We were also able to deliver this result without any change to client attribute cache settings – our goal was to stress the storage controllers and use minimal memory on clients.”
In our view this benchmark is lacking as it does not reveal price/performance information. Knowing a $/SW Build cost would enable more meaningful system comparisons.
The storage industry can be bewildering, with so many hardware and software technologies and overlapping products. How to make sense of it all?
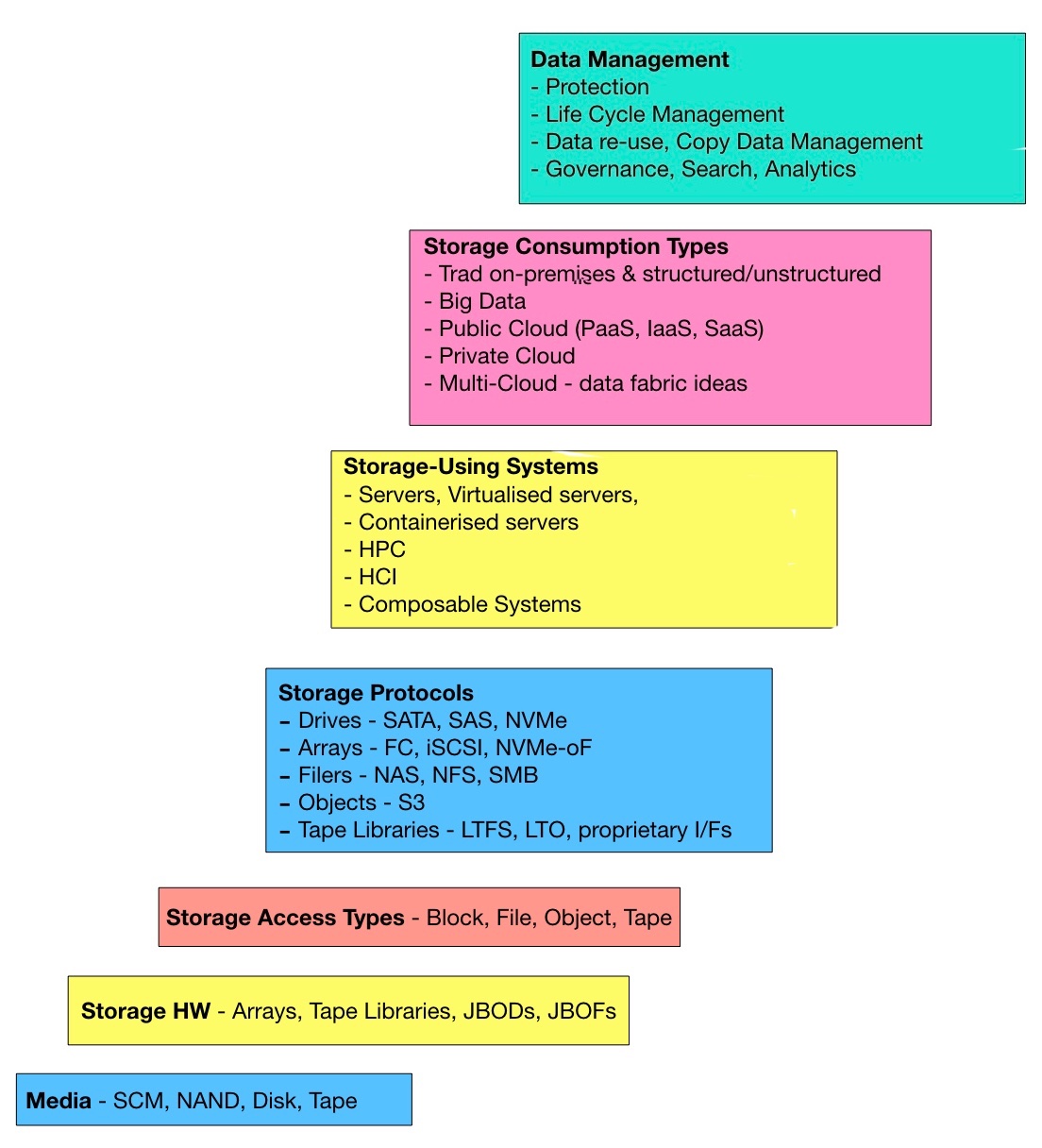
Let’s think of computer storage as a layered stack with media hardware at the bottom and data management at the top. In my mental landscape this stack has seven layers:
Media
Storage hardware
Storage access types
Storage protocols
Storage-using systems
Storage consumption types
Data management
These layers can be sub-divided into different technologies or product classes. For example, storage-using systems can be partitioned into servers, high performance computing (HPC) systems, hyperconverged infrastructure (HCI) systems and composable systems.
Servers can be further categorised as bare metal, virtualized or containerised.
Blocks and Files Storage Layer Cake
The storage hierarchy landscape chart is my own mental map and is neither exhaustive nor definitive.
I use this framework to generally place a storage technology or product and as an aid to map supplier activities. This helps me better contextualise the storage industry and to assess the import of technology trends and deals. For instance, what is one to make of the Cohesity and HPE partnership, the Red Hat NooBaa acquisition, Vexata’s kick-ass storage arrays, and rival multi-cloud data fabric ideas.
I hope you find this Blocks and Files storage stack layer cake useful too.
In this article we explore Storage-Class-Memory (SCM) and explain why it is ready for enterprise IT big time in 2019.
Setting the scene
DRAM is the gold standard for storing data and code in terms of access speed where it is used by CPUs and caches. Everything else – NAND, disk and tape – is slower but much cheaper.
Artificial intelligence, graph-processing, bio-informatics and in-memory database systems all suffer from memory limitations. They have large working data sets and their run time is much faster if these data sets are all in memory.
Working data sets are getting larger and need more memory space yet memory DIMM sockets per CPU are limited to 12 slots on 2-socket X86 systems and 24 on larger systems.
Memory-constrained applications are throttled by a DRAM price and DIMM socket trap: the more you need the more expensive it gets. You also need more CPUs to workaround the 12 DIMM slots per CPU limitation.
A 2016 ScaleMP white paper sums this up nicely. “A dual-socket server with 768GB of DRAM could cost less than $10,000, a quad-socket E7 system with double the capacity (double the cores and 1.5TB memory) could cost more than $25,000. It would also require 4U of rack space, as well as much more power and cooling.”
Storage Class Memory tackles price-performance more elegantly than throwing expensive socketed CPUs and thus more DRAM at the problem.
SCM, or persistent memory (P-MEM) as it is sometime called, treats fast non-volatile memory as DRAM and includes it in the memory space of the server. Access to data in that space, using the memory bus, is radically faster than access to data in local, PCI-connected SSDs, direct-attach disks or an external array.
Bulking and cutting
It is faster to use the entire memory space for DRAM only. But this is impractical and unaffordable for the vast majority of target applications, which are limited by memory and not by compute capacity. SCM is a way to bulk out server memory space without the expense of an all-DRAM system.
In the latter part of 2018, mainstream enterprise hardware vendors have adopted NVMe solid state drives and Optane DIMMs. This month Intel released its Cascade Lake Xeon CPUs with hardware support for Optane. These NVMe drives and Optane DIMMs can be used as storage class memory, and this indicates to us that 2019 will be the year that SCM enters enterprise IT in a serious way.
Background
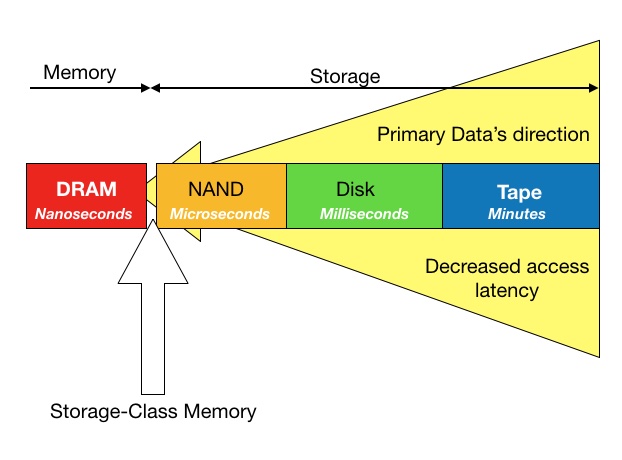
IT system architects have always sought to get primary data access latencies as low as possible while recognising server DRAM capacity and cost constraints. A schematic diagram sets the scene:
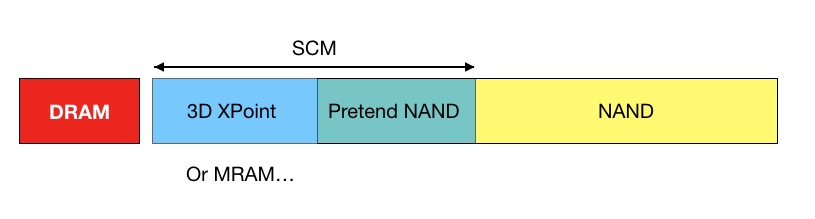
Where SCM fits in the memory-storage spectrum
A spectrum of data access latency is largely defined by the media used. Coincidentally, the slower the media the older the technology. So, access latency decreases drastically as we move from right to left in the above diagram.
Access type also changes as we move in the same direction: storage media is block-addressable, and memory is byte-addressable. A controller software/hardware stack is typically required to convert the block data to the bytes that are stored in the media. This processing takes time – time that is not needed when reading and writing data to and from memory with Load and Store instructions.
From tape to flash
Once upon a time, before disk drives were invented, tape was an online media. Now it is offline and it can take several minutes to access archival backup data.
Disks, with latencies measured in milliseconds, took over the online data storage role and kept it for decades.
Then along came NAND and solid state drives (SSDs). The interface changed from the SATA and SAS protocols of the disk drive eras as SSD capacities rose from GBs to TBs. Now the go-to interface is NVMe (Non-Volatile Memory express) which uses the PCIe bus in servers as its transport. SSDs using NVMe have access latencies as low as 100 microseconds.
In 2018, the network protocols used for SSDs in all-flash arrays are starting to change from Fibre Channel and iSCSI to NVMe using Ethernet (ROCE, NVME TCP), Fibre Channel (NVMe FC) and InfiniBand (iWARP), with access latencies of 120 – 200 microseconds.
But this is still slower than DRAM, where access latency is measured in nanoseconds.
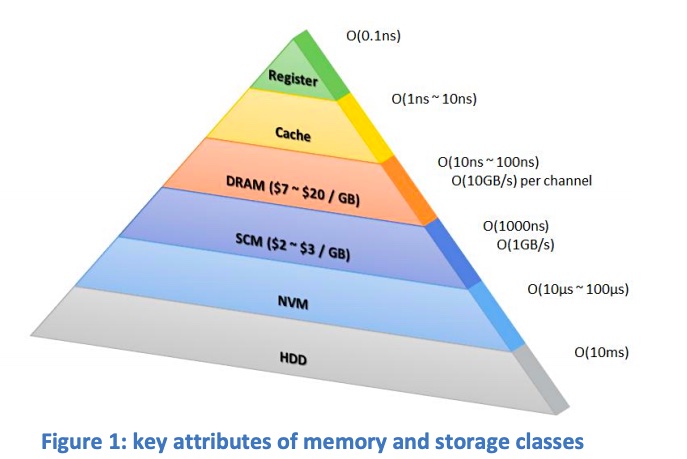
We can illustrate this hierarchy with a chart from ScaleMP (it’s from 2016, so the example costs are out of date).
ScaleMP chart
The NVMe section refers to NVMe SSDs. DRAM is shown with 10 – 100 nanosecond access latency, an order of magnitude faster than NAND.
Two types of SCM media
To occupy the same memory space as DRAM, slower media must be presented, somehow, as fast media. Also the media if block-addressable – such as NAND – needs to be presented with a byte-addressable interface. Hardware and/or software is required to mask the speed and media access pattern differences. If NAND is used for SCM it becomes, in effect pretend NAND, and presents as quasi-DRAM.
ME 200 NAND SSD + ScaleMP SW MMU (Western Digital)
Z-SSD (Samsung)
MRAM, PCM, NRAM and STT-RAM.
3D XPoint and Optane
Intel’s 3D XPoint is a 2-layer implementation of a Phase Change Memory (PCM) technology. It is built at an Intel Micron Flash Technologies foundry and the chips are used in Intel Optane SSDs and are soon to feature in DIMMs.
Optane has a 7-10μs latency. Intel’s DC P4800X Optane SSD has capacities of 375GB, 750GB and 1.5TB, runs at up to 550,000/500,00 random read/write IOPS, sequential read/write bandwidth of up to 2.4/2.0GB/sec, and can sustain 30 drive writes per day. This is significantly more than a NAND SSD.
Intel introduced the DC P4800X in March 2017, along with Memory Drive technology to turn it into SCM. It announced Optane DC Persistent Memory DIMMs in August 2018, with 128, 256 and 512GB capacities and a latency at the 7μs level.
Intel has announced Cascade Lake AP (Advanced Processor) Xeon CPUs that support these Optane DIMMs. Cascade Lake AP will be available with up to 48 cores, support for 12 x DDR4 DRAM channels and come in either a 1- or 2-socket multi-chip package.
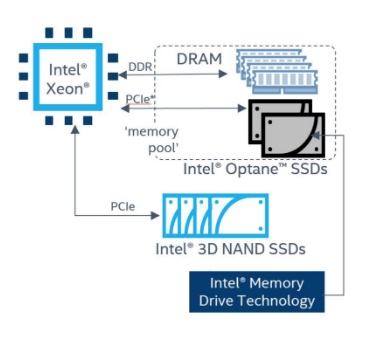
Intel Memory Drive Technology
Intel Memory Drive Technology (IMDT) is a software-defined memory (SDM) product – actually vSMP MemoryONE licensed from ScaleMP.
Intel Memory Drive Technology diagram
According to Intel, IMDT is optimized for up to 8x system memory expansion over installed DRAM capacity and provides ultra-low latencies and close-to DRAM performance for SDM operations. It is designed for high-concurrency and in-memory analytics workloads.
A section of the host server’s DRAM is used as a cache and IMDT brings data into this DRAM cache from the Optane SSDs when there is a cache miss. Data is pre-fetched and loaded into the cache using machine learning algorithms. This is similar to a traditional virtual memory paging swap scheme – but better, according to Intel and ScaleMP.
IMDT will not support Optane DIMMs, Stephen Gabriel, Intel’s data centre communications manager said: “It doesn’t make sense for Optane DC persistent memory to use IMDT, because it’s already memory.”
Intel’s Optane DIMMs have a memory bus interface instead of an NVMe drive’s PCIe interface. This means that SCM software has to be upgraded to handle byte addressable instead of block-addressable media.
ScaleMP’s MemoryONE can’t do that at the moment but the company told us that the software will be fully compatible and support Optane DIMM “when it will become available”.
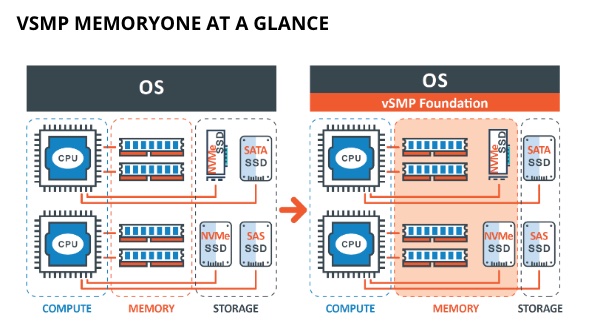
ScaleMP Memory ONE
ScaleMP combines X86 servers into a near-supercomputer by aggregating their separate memories into a single pool with its vSMP software. This is available in ServerONE and ClusterONE forms.
ServerONE aggregates multiple, industry-standard, x86 servers into a single virtual high-end system. ClusterONE turns a physical cluster of servers into a single large system combining the computing-power, memory and I/O capabilities of the underlying hardware and running a single instance of an operating system.
ScaleMP MemoryONE diagram
With MemoryONE two separate pools of ‘memory’ in a single server are combined. We say ‘memory’ because one pool is DRAM and the other is a solid state store that is made to look like DRAM by the MemoryONE software.
A bare metal hypervisor functions as a software memory management unit and tells the guest Linux variant operating systems that the available memory is the sum of actual DRAM and the alternate solid state media, either NAND or 3D XPoint.
Intel and Western Digital use ScaleMP’s software, and other partnerships may be in development.
MemoryONE SCM cost versus all-DRAM cost
Let us suppose you need a system with 12TB of memory and two Xeon SP CPUs. For an all-DRAM system you require an 8-socket Xeon SP configuration, with each CPU fitted with 12 DIMM slots populated with 128GB DIMMs. This adds up to 1.5TB per socket.
ScaleMP tells us that 128GB DIMMs cost, on average, around $25/GB. These DIMMs require a high-end processor – with an ‘M’ part number – which has a price premium of $3,000.
The math says the DRAM for a 1.5TB socket costs $41,400 inclusive of the CPU premium (1,536GB x $25/GB + $3,000) and the entire 8 sockets’ worth will cost $331,200.
The cost is much lower if you use MemoryONE and a 1:8 ratio of DRAM to NAND or Optane. For a 12TB system, the Intel memory Drive Technology (IMDT) manual says you need 1.5TB of DRAM plus 10 units of the 1.5TB Optane SSDs. (ScaleMP explains that the larger total has to do with decimal to base of 2 conversion, and some caching techniques).
If you don’t need the computing horsepower of 8-socket system, you could have a 2-socket Xeon SP system, with each CPU supporting 768GB of DRAM (12 x 64GB) – and reach 12TB of system memory with IMDT, using 15TB of Optane capacity (10 x 1500GB P4800X). Also you avoid the $3,000 ‘M’ part premium.
You save the price of six Xeon SP processors, the ‘M’ tax on the two Xeons you do buy, along with sundry software licenses, and the cost difference between 12TB of high-cost DRAM ($307,200 using 128GB DIMMs) vs. 1.5TB of commodity DRAM ($15,360 using 64GB DIMMs) and 10 x P4800X 1.5TB SSDs with the IMDT SKU, which cost $6,580 each.
In total you would pay $81,160 for 12TB of memory (DRAM+IMDT), a saving of $250,040 compared to 12TB of DRAM on an 8 socket Xeon SP machine. Also, if you opt to do this with a dual-socket platform you pay less for the system itself. So you are looking at even greater savings.
ScaleMP and Netlist HybriDIMMs
In July 2018 Netlist, an NV-DIMM developer, announced an agreement with ScaleMP to develop software-defined memory (SDM) offerings using Netlist’s HybriDIMM.
Netlist HybriDIMM
HybriDIMM combines DRAM and existing NVM technologies (NAND or other NVMe-connected media) with “on-DIMM” co-processing to deliver a significantly lower cost of memory. It is recognised as a standard LRDIMM, by host servers, without BIOS modifications. Netlist is gunning for product launch for 2019.
Netlist states: “PreSight technology is the breakthrough that allows for data that lives on a slower media such as NAND to coexist on the memory channel without breaking the deterministic nature of the memory channel. It achieves [this] by prefetching data into DRAM before an application needs it. If for some reason it can’t do this before the applications starts to read the data, it ensures the memory channels integrity is maintained while moving the data [onto] DIMM.”
As noted above, ScaleMP’s MemoryONE will be fully supportive of non-volatile Optane and NAND DIMMs.
Western Digital Memory Expansion drive
Western Digital’s SCM product is the ME200 Memory Expansion drive. This is an optimised Ultrastar SN200 MLC (2bits/cell) SSD, plus MemoryONE software.
Western Digital Ultrastar DC ME200 SSD
This is like the Intel MDT product but uses cheaper NAND rather than Optane.
Western Digital says a server with DRAM + ME200 + MemoryONE performs at 75 – 95 per cent of an all-DRAM system and is less expensive.
Memcached has 85-91 per cent of DRAM performance with a 4-8x memory expansion from the ME200
Redis has 86-94 per cent DRAM performance with 4x memory expansion
MySQL has 74-80 per cent DRAM performance with 4-8x memory expansion
SGEMM has 93 per cent DRAM performance with 8x memory expansion
We have not seen any Optane configuration performance numbers, but it is logical to infer that the alternative using Optane SSDs instead of NAND will perform better and cost more.
However, Western Digital claims the ME200 route gets customers up to “three times more capacity than the Optane configuration”.
Eddy Ramirez, Western Digital director of product management, says there is “not enough compelling performance gain with Optane to justify the cost difference.”
Samsung Z-SSD
Z-NAND is, basically, fast flash. Samsung has not positioned this as storage-class memory but we think it is a good SCM candidate, given Intel and Western Digital initiatives with Optane and fast flash.
Samsung’s SZ985 Z-NAND drive has a latency range of 12-20μs for reads and 16μs for writes. It has an 800GB capacity and runs at 750,000/170,000 random read/write IOPS. Intel’s Optane P4800X runs at 550,000/500,000 so its write performance is much faster but the Samsung drive has up to 50 per cent more read performance.
Samsung SZ985 Z-NAND drive
The SZ985’s sequential bandwidth is up to 3.1 GB/sec for reads and writes, with the P4800X offering 2.4/2.0 GB/sec. Again Samsung beats Intel.
The endurance of the 750GB P4800X is 30 drive writes per day (41 PB written during its warranted life) – the same as Optane.
With this performance it is a mystery why Samsung is not making more marketing noise about its Z-SSD. And it is a puzzle why ScaleMP and Samsung are not working together. It seems a natural fit.
Samsung provided a comment, saying: “Samsung is working with various software and hardware partners to bring Z-SSD technology to the market, including some partners that are considering Z-SSD for system memory expansion. We can’t discuss engagements with specific partners at the moment.”
Watch this space.
MRAM, PCM, NRAM and STT-RAM
Magnetic RAM and STT-RAM (Spin Transfer Torque RAM) are the same thing: non-volatile and byte-addressable memory using spin-polarised currents to change the magnetic orientation, and hence bit value, of a cell.
Crocus, Everspin and STT are the main developers here and they claim their technology has DRAM speed and can replace DRAM and NAND, plus SRAM and NIR, and function as a universal memory.
But no semiconductor foundry has adopted the chip design for mass production and consequently the technology is unproven as practical SCM.
PCM is Phase-Change Memory and it is made from a Chalcogenide glass material whose state changes from crystalline to amorphous and back again by using electric current. The two states have differing resistance values, which are detected by a different electric current and provide the two binary values needed: 0 and 1.
This is another prove-it technology with various startups and semi-conductor foundries expressing interest. Micron, for example, demonstrated PCM tech ten years ago. But no real technology is available yet.
NRAM (Nanotube RAM) uses carbo nanotubes and is the brainchild of Nantero. Fujitsu has licensed the technology, which is said to be nonvolatile, DRAM-like in speed, and possess huge endurance. This is another yet-to-be-proven technology.
Summary
For NAND to succeed as SCM, software is required to mask the speed difference between it and DRAM and provide byte addressability. ScaleMP MemoryONE software provides thus functionality and is OEMed by Intel and Western Digital.
Samsung’s exceptional Z-SSD should be an SCM contender – but we discount this option until the company gives it explicit backing.
For now, Optane is the only practical and deliverable SCM-only media available. It has faster-than-NAND characteristics, is available in SSD and DIMM formats and is supported by MemoryONE.
Cascade Lake AP processors will be generally available in 2019, along with Optane DIMM. This combination provides the most realistic SCM componentry available thus far. We can expect server vendors to produce SCM-capable product configurations using this CPU and Optane DIMMs.
The software, hardware and supplier commitment elements are all in place for SCM systems to be adopted by enterprises for memory-constrained applications in 2019 and escape the DRAM price and DIMM slot limitation traps.
Vexata has plugged into a big enterprise sales channel in the USA and Canada via a deal with Fujitsu to resell its bleeding edge NVMe storage arrays.
The companies will jointly develop reference architectures for customer proof of concept projects in a new Fujitsu Solutions Lab in Silicon Valley. Fujitsu will pitch Vexata arrays into the financial services, bio-medical, retail and manufacturing sectors.
Vexata must surely be pleased with this prospect while Fujitsu gets some tech glamour in its Solutions Lab. If it works out Fujitsu may extend the deal worldwide.
Unboxing Vexata
Vexata storage is scale-up and scale-out and is available as an appliance, as an array with IBM’s Spectrum Scale (PDF), or as software running on commodity servers and switches.
The company claims 10x performance and efficiency improvements at a fraction of the cost of existing all-flash storage products.
Vexata arrays are not your average run-of-the-mill all-flash storage arrays. They use a 3-stage accelerated internal architecture that’s a long way from traditional dual-controller design.
Vexata array architecture
Vexata’s VX-100 box is a 6U enclosure with two active:active controllers using either up to 64 NVMe SSDs or Optane SSDs. It connects to accessing servers, using up to 16 x 32Gbit/s Fibre Channel ports or 16 x 40GitbE NVMe over Fabric ports.
Effective capacity is 432TB usable for the VX-100F and 19TB-38TB for the Optane-based VX-100M.
Performance numbers are 7 million IOPs (8KB 70 per cent read/30 per cent write) with a 35-90μs latency (flash) or 40μs (Optane). Bandwidth is 70GB/sec (50GB/sec read; 20GB/sec write).
These are hot array boxes compared to Fujitsu’s ETERNUS dual-controller arrays. Their performance is comparable to Fujitsu’s top-end multi-controller ETERNUS DX8900 S4 with its 10 million IOPS (8KB Random Read Miss).
HPE has announced Optane caching for its 3PAR arrays and this makes them chew through Oracle database workloads faster.
According to HPE, “92% of all 3PAR install base reads and writes are met below 1 millisecond”. Some 72 per cent are dealt with in 0.25ms (250μs).
HPE is using Intel NVMe-accessed Intel Optane drives, which form a persistent memory pool and are addressed with Load/Store memory semantics instead of the slower storage stack Reads and Writes used in storage drive accesses.
HPE calls this Memory-Driven Flash (MDF), with caches filled with transient hot data, metadata, or used as a storage tier for hot data.
Intel’s Optane drives use 3D XPoint media which has a 7-10μs latency – faster than flash SSDs’ 75-120μs. With a 3PAR 3D XPoint, cache average latency is reduced by 50 per cent and 95 per cent of IOs are serviced within 300μs.
Memory eccentric
HPE says this is an example of a memory-centric compute fabric design, with multiple CPUs accessing a central memory pool, thereby bringing storage closer to compute and increasing the workload capability of a set of servers.
You may think that’s a bit of a stretch from adding Optane caches to a shared external array with dual controllers. To be truly memory-centric, HPE should surely add Optane SCM to HPE servers, and then aggregate the Optane SCM between the servers.
In the meantime the company uses Optane as storage class memory (SCM) in 3PAR array controllers to deliver more data accesses faster in response to requests coming in across iSCSI or Fibre Channel networks.
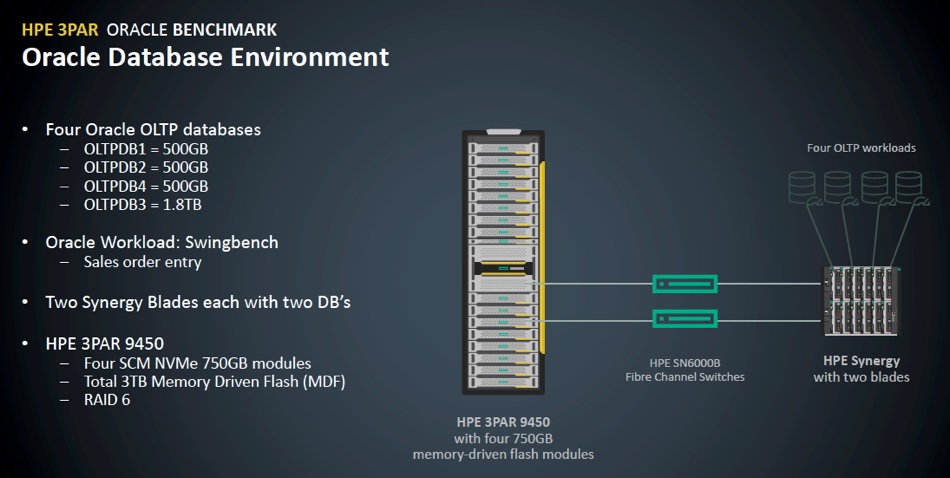
HPE has benchmarked the set-up in an Oracle environment, using a 3PAR 9450 array equipped with 3TB of Optane capacity and 4 x 750GB XPoint drives. The workload was Oracle Swingbench (sales order entry) and the 3PAR box linked across 16Gbit/s Fibre Channel (FC) to a 2-blade HP Synergy composable system servicing four OLTP workloads.
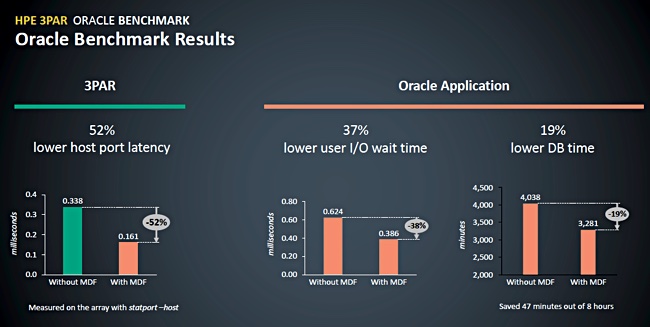
HPE recorded a 52 per cent lower port latency on the array, plus a 37 per cent lower user I/O wait time and 19 per cent lower database time. There was a 27 per cent increase in SQL select execution per second – meaning more database queries were run.
HPE says the lower user I/O wait time means a lower read transaction latency and reduced database time means more workloads are completed. The company suggests you could lower Oracle licensing costs or increase your Oracle workloads.
This is good but ….
A Broadcom document states that you could reduce Oracle 12c data warehouse workload query time by half with 32Gbit/s FC compared to 16Gbit/s FC. This suggests that upgrading the 3PAR 9450 to 32Gbit/s FC, and so cutting network transit time, would be more effective than using SCM.
A Lenovo document says you can get a 2.1x increase in IOPS by moving from Fibre Channel to NVMe over Fibre Channel; again getting a bigger performance boost than by using Optane SCM caching in the array.
in August 2016 an anonymous HPE blogger said NVMe-over-Fabrics with RDMA and FC was on the 3PAR roadmap. It isn’t here yet and surely it must be coming soon.
ProfileLightbits Labs claims to have invented NVMe/TCP. This is a big claim but the early-stage startup has demonstrable product technology for running fast access NVMe-over-fabrics (NVMe-oF) across standard data centre LANs using TCP/IP.
Lightbits Labs was founded in 2015 by six Israeli engineers. The company is 50-strong and runs two offices in Israel and a third in Silicon Valley. The company has revealed no funding details – it is possibly owner-financed and/or has angel investment.
It does not yet have a deliverable product but we anticipate it will come to market in 2019 with a hardware accelerator using proprietary VLSI or FPGA technology. These will work with commodity servers, Lightbits says, but we must wait for the product reveal to see how that pans out in practice. It seems reasonable to infer that a funding round is on the cards to cover the costs of the initial business infrastructure build-out.
Lightbits Labs has considerable competition for an early-stage startup. The company is in competition with other attempts to run NVMe-oF across standard Ethernet, e.g. SolarFlare with kernel bypass technology and Toshiba with its Kumoscale offering.
These companies are, in turn, up against NetApp, IBM and Pure Storage, which are developing competing technology that enables NVMe over standard Fibre Channel.
Lightbit’s rivals are established and well-capitalised. For example, Solarflare, the smallest direct competitor, is 17 years-old and has taken in $305m in an improbable 24 funding rounds.
Lightbits, with a startup’s nimbleness and single-minded focus, may be able to develop its tech faster. And of course we have yet to see what product or price differentiation the company may have to offer.
NVMe over TCP
Let’s explore in some more detail the problem that Lightbits is trying to solve.
NVMe-oF radically reduces access latency to block data in shared array. But to date, expensive data centre-class Ethernet or InfiniBand has been required for network transport.
By running NVMe-oF over a standard Ethernet LAN using TCP/IP its deployment and acquisition costs would be reduced.
NVMe is the protocol used to connect direct-attached storage, typically SSDs, to a host server’s PCIe bus. This is much faster, at say 120-150µs, than using a drive access protocol such as SATA or SAS. An NVMe explainer can be found here.
NVMe over Fabrics (NVME-oF) extends the NVMe protocol to shared, external arrays using a network transport such as lossless Ethernet, with ROCE, and InfiniBand, with iWARP.
Both are expensive and fast, with remote direct memory access speeds; think 100-120µs latency. Running NVMe-oF across a TCP/IP transport adds 80 – 100 microseconds of latency compared to ROCE and iWARP, but the net result is much faster than iSCSI or Fibre Channel access to an external array; think <200µs compared to >100,000µs.
Lightbits Labs system
Lightbits maps the many parallel NVMe I/O queues to many parallel TCP/IP connections. It envisages NVMe-over TCP as the NVMe migration path for iSCSI.
The Lightbits pitch is that you don’t need a separate Fibre Channel SAN access infrastructure. Instead, consolidate storage networking with everyday data centre Ethernet LAN infrastructure, and gain the cost and manageability benefits. Carry on using your everyday Ethernet NICs, for example.
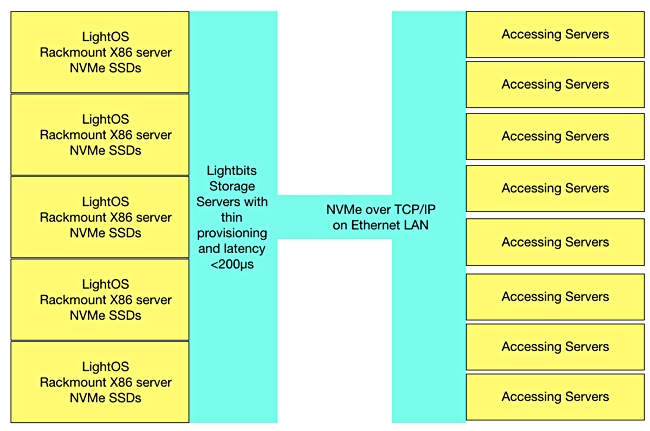
Our diagram of the Lightbits Labs system
In its scheme, storage accessing servers direct their requests to an external array of commodity rack servers which run the LightOS and are fitted with NVMe SSDs. The SSD capacity is thinly provisioned and managed as an entity, with garbage collection, for example, run as a system-level task and not at drive-level. Random write accesses are managed to minimally affect SSD endurance.
Lightbits says the NVMe/TCP Linux drivers are a natural match for the Linux kernel and use the standard Linux networking stack and NICs without modification. The technology can scale to tens of thousands of nodes and is suitable for hyperscale data centres, the company says.
Lightbits pushes access consistency with its technology, claiming reduced tail latency of up to 50 per cent compared to direct-attached storage. It uses unspecified hardware acceleration and system-level management to double SSD utilisation.
The white paper notes: “The LightOS architecture tightly couples many algorithms together in order to optimise performance and flash utilisation. This includes tightly coupling the data protection algorithms with a hardware-accelerated solution for data services.”
And it summarises: “Lightbits incorporates high-performance data protection schemes that work together with the hardware-accelerated solution for data services ad read and write algorithms.”
It adds: “a hardware-accelerated solution for data services that operates at full wire-speed with no performance impact.”
Hardware acceleration in the data path seems important here, and we note co-founder Ziv Tishel is director of VLSI/FPGA activities at Lightbits. This suggests that LightOS servers are fitted with Lightbits’ proprietary VLSI or FPGA technology.