


All-flash NetApp filers have blown the SPEC SFS 2014 SW Build benchmark record to hell and gone.
A 4-node system scored 2,200 and an 8-node one 4,200 – 2.8 times faster than the previous DDN record score of 1,500, which is only two months old.
That was set by all-flash SFA 14KX array, fitted with 72 x MLC (2bits/cell) SSDs, 400GB SS200 SAS drives, and running IBM’s Spectrum Scale parallel file system.
The SPEC SFS 2014 benchmark was introduced in January 2015 and tests five separate aspects of a filer’s workload performance:
- Number of simultaneous builds that can be done (software builds)
- Number of video streams that can be captured (VDA)
- Number of simultaneous databases that can be sustained
- Number of virtual desktops that can be maintained (VDI)
- Electronic Design Automation workload (EDA)
NetApp just ran the SWBuild workload, which is the most popular benchmark. It used an all-flash AFF A800 array, running its ONTAP software, and fitted with NVMe SSDs, and in 4-node and 8-node configurations.
In detail, the 4-node setup consisted of a cluster of 2 AFF A800 high availability (HA) pairs (4 controller nodes total). The two controllers in each HA pair were connected in a SFO (storage failover) configuration. Each storage controller was connected to its own and partner’s NVMe drives in a multi-path HA configuration.
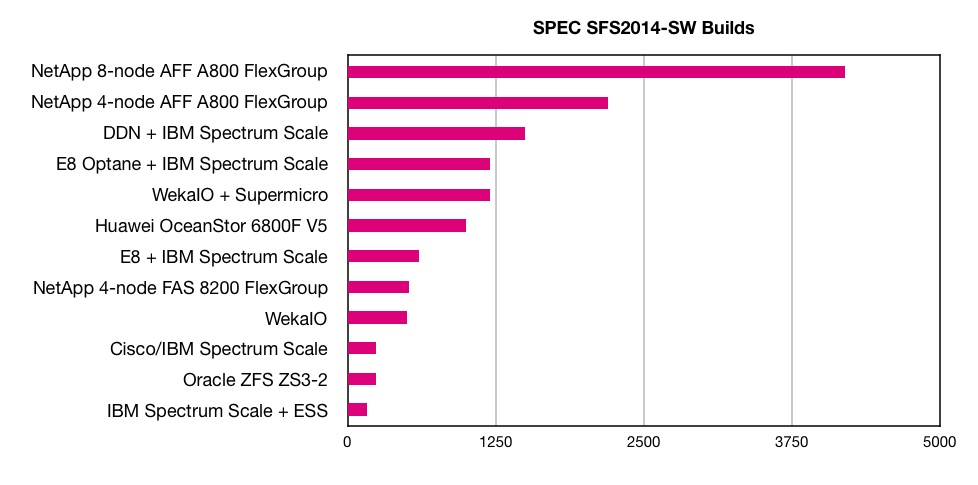
A previous NetApp filer scored a much lower 520 on this benchmark in September 2017. That was a 4-node FAS8200 array, configured as two HA pairs, with 144 x 7,200rpm disk drives and 8 x NVMe 1TB flash modules set up as a Flash Cache.
We asked NetApp’s Octavian Tanase, SVP of the Data ONTAP Software and Systems Group, what made the A800 so fast. He said: “ONTAP has been optimised over the years to deliver consistent high-performance for NAS workloads.”
NetApp has “focused on reducing latency and increase IOPs on AFF. We have also overhauled our processor scheduling and dramatically improved our parallelism for our high-core count platforms. … In addition, our NVMe backend software stack on A800 provides further reduction of latency.”
He pointed out that compression and deduplication were switched on during the benchmark run. And: “We were also able to deliver this result without any change to client attribute cache settings – our goal was to stress the storage controllers and use minimal memory on clients.”
In our view this benchmark is lacking as it does not reveal price/performance information. Knowing a $/SW Build cost would enable more meaningful system comparisons.





