Watch out Commvault, Rubrik, Unitrends and Veritas; Arcserve is coming right at you.
It has updated its UDP appliance with 9000 series models that integrate backup, disaster recovery and backend cloud storage, enabling it to compete more strongly with other unified data protection vendors.
They replace the previous, second generation UDP 8000 series, which were purpose-built backup appliances similar to those of Data Domain.
Arcserve claims this is the market’s first appliance purpose-built for DR and backup. Compared to the UDP 8000s this all-in-one option for onsite and offsite backup and DR boasts:
- Cloud services that enable companies to spin up copies of physical and virtual systems directly on the appliance, and in private or public clouds
- Twice the effective capacity as previous models (In-field expansion up to 504TBs of data per appliance and up to 6PBs of managed backups through a single interface)
- A new hardware vendor that enables Arcserve to deliver onsite hardware support in as fast as four hours, and high redundancy with dual CPUs, SSDs, power supplies, HDDs and RAM.
Who is the HW supplier? Arcserve says it cannot say but it is the #1 hardware vendor in the world and is U.S. based. [Who said Dell?]
Arcserve schematically shows the 9000 appliance’s deployment;
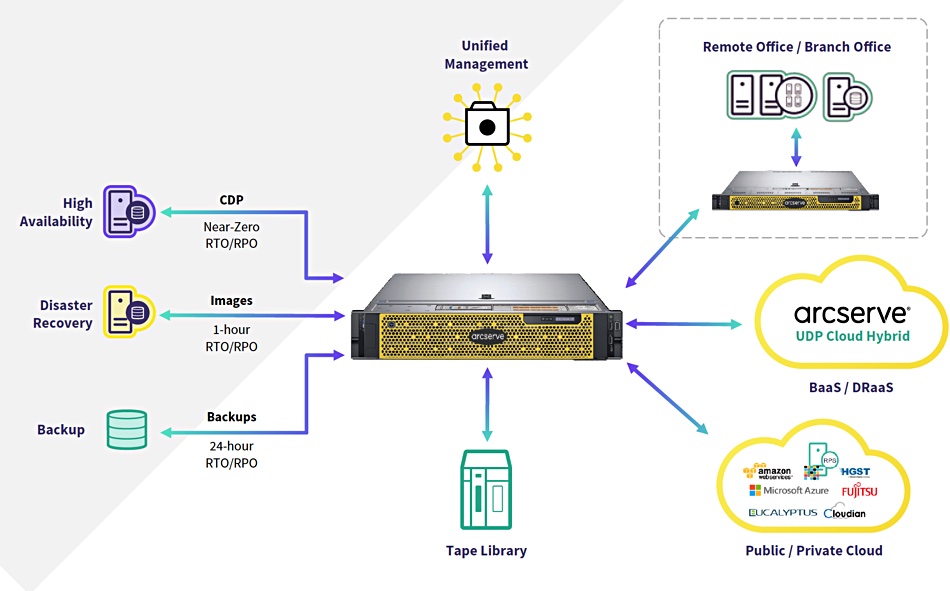
The A9000 series features;
- Up to
- 20 x86 cores,
- 768GB DDR4-2400MHzRAM
- 504TB effective capacity
- 6PB backups managed
- 20:1 dedupe ratio with global dedupe
- SAS disk drives and SSDs
- 12Gbit/s RAID cards with 2GB non-volatile cache
- Expansion kits to bulk up base capacity up to 4x
- High-availability add-on
- Cloud DRaaS add-on
- Real-time replication with failover and failback
- Pump data offsite to tape libraries
There are 11 models;
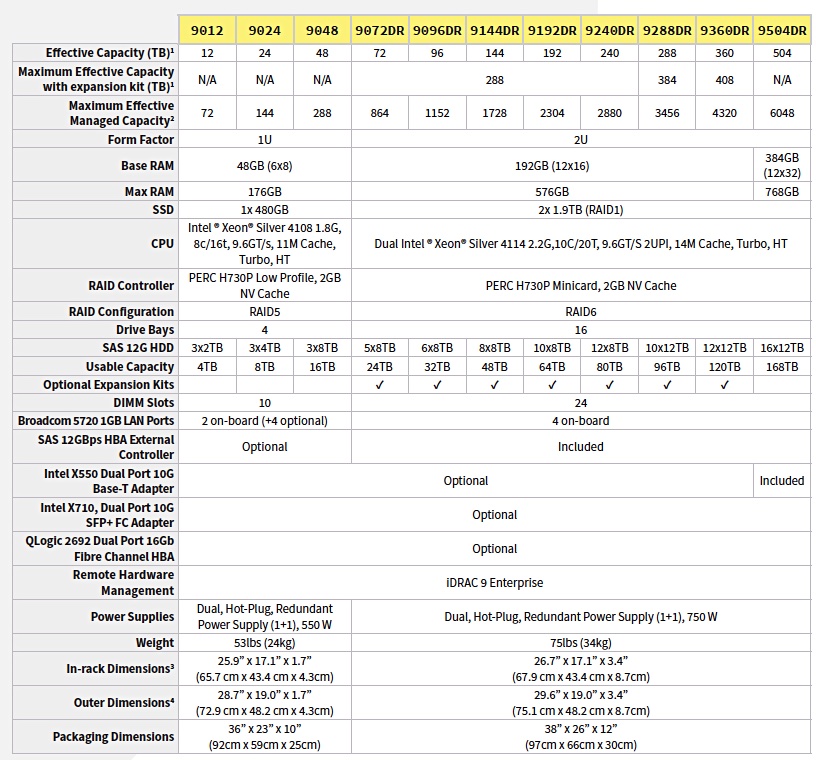
Arcserve 9012, 9024 and 9048 appliances deliver up to 20 TB/hour throughput based on global source-side deduplication with a 98 per cent deduplication ratio. The 9072DR, 9096DR, 9144DR, 9192DR, 9240DR, 9288DR, 9360DR and 9504DR deliver up to 76 TB/hour throughput based on global source-side deduplication with a 98 per cent deduplication ratio.
The appliances can protect VMware, Hyper-V, RHEV, KVM, Nutanix AHV, Citrix and Xen VMs with agentless and agent-based backup. They can back up and recover Office 365, UNIX, FreeBSD, AIX, HP-UX, Solaris, Oracle Database, SAP HANA and more.
Supported back-end clouds include the Arcserve Cloud, AWS, Azure, Eucalyptus and Rackspace.
A dozen appliances and 6PB of backups can be managed through one interface.
Arcserve says it can take as little as 15 minutes to install and configure the appliance, and it comes with 4-hours and next-business-day on-site support options.
Competition
Arcserve says its biggest competitors with this announcement are Unitrends, Rubrik and Veritas [US] and Veritas, Commvault and Rubrik [outside of US]. Unitrends, Rubrik and Veritas use a different, less preferred hardware vendor outside of the U.S.
It makes the following competitive claims;
Unitrends
- Unitrends disaster recovery is very limited and there are no expansion capabilities
- On-appliance recovery is only supported for Windows, and only if backup is done with Windows-based imaging
- You can’t backup VMware/Hyper-V VM host-based and use on-appliance recovery
- Any of their Instant Recovery rehydrates the entire VM, and that’s why it’s very slow (at least 20 minutes per TB).
- You must allocate 100 per cent of Windows machine used storage for IR, removing it from backup storage.’
- No support for hardware snapshots – Arcserve supports NetApp, HPE 3Par and Nimble
- No UEFI on-appliance
Veritas:
- No on-appliance DR or HA – appliances do not include storage and require storage shelves, driving costs and complexity
- Veritas does not claim dedupe ratios.
- Very high cost of units, software, maintenance, expansion
- Complex NetBackup software at the core, consuming IT pro time, lowering IT productivity
Rubrik:
- 80TB is capacity of Rubrik model r6410.
- 400TB is based on an advertised dedupe efficiency of 5:1.
- High list price, and targeted primarily at enterprise
- No on-appliance DR or HA – separate infrastructure required, driving up cost and complexity
- No 4-hour, or even NBD support commitment – best effort only
Commvault
- HyperScale cluster can scale infinitely. 262TB is for 3x Commvault HyperScale
- 3300 appliances with 8TB drives. Commvault does not claim deduplication ratios.
- Requires a minimum of three appliances to operate.
- Very high cost of units, software, maintenance, expansion
- Complex Simpana software consumes IT pro time, lowering IT productivity
- No on-appliance DR or HA – separate infrastructure required, driving up cost and complexity
Development plans
New focus areas for the next generation of Arcserve Appliances will centre on expansion enhancements.
Arcserve will launch a new version of its UDP software featuring Nutanix and OneDrive support, as well as a next-gen of our RHA which will include a host of new support for Linux HA to AWS, Azure, VMware and Hyper-V, Windows Server 2019, and more.
Arcserve Appliance customers will get a free upgrade to the new versions with all these features as part of their maintenance benefits. Currently general availability for these new products is targeted at late spring / early summer 2019.
Availability and pricing
All new trial and licensed customers of Arcserve UDP Appliances are using the new Arcserve 9000. New Arcserve UDP Appliance customers will be able to use the new series within the next month.
The new Arcserve Appliance series is available now worldwide through Arcserve Accelerate partners and direct.
The starting list price for the backup only (DR not included) Appliance is $11,995. The starting list price with DR included is $59,995.