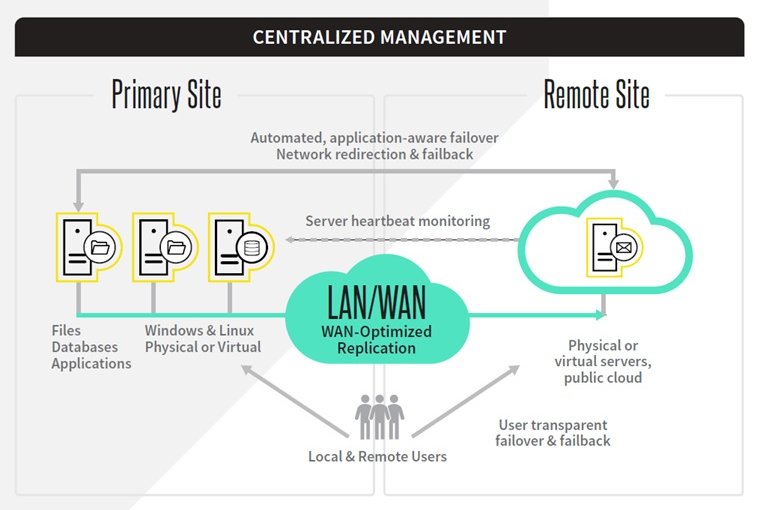
Data protection specialist Arcserve has updated its Arcserve Replication and High Availability platform with full high availability support for Linux, plus protection of Windows and Linux workloads on Microsoft’s Azure public cloud.
Arcserve RHA was developed to provide organisations with true continuous application and system availability, according to the firm, and uses a journal-based replication method that operates at the level of files and folders, rather than relying on snapshot-based backups. A heartbeat monitors the server or application, with every change asynchronously duplicated to the replica.
With Arcserve RHA 18.0, the platform gains full system high availability for Linux as well as Windows, so that it provides automatic failover for systems running both platforms. This ensures workloads remain operational with minimal interruption if a vital server goes down.
This release also extends full system support for these platforms to Azure, which means that Windows systems can replicate to XenServer, VMware, Hyper-V, Amazon EC2 or Microsoft Azure, while Linux systems can replicate to VMware, Hyper-V, KVM, Amazon EC2 or Microsoft Azure.
Arcserve RHA: how it works
At the application level, organisations can now manage data replication for Exchange, SQL, IIS, SharePoint, Oracle, Hyper-V and custom applications.
This release of Arcserve RHA also offers the ability to rollback applications to a point in time before a system crash, data corruption, or ransomware event.
Also new is Hyper-V Cluster Share Volumes (CSV) support for Microsoft Hyper-V scenarios, Windows Server 2019 support, plus enhanced monitoring and alerting capabilities.
Arcserve
AHA is used by customers in industries such as manufacturing, banking and finance,
for whom the issue is not just about recovery but the delivery of always
available systems, according to Arcserve. Manufacturing especially cannot
afford to have onsite systems down due to application availability issues.
Arcserve RHA is licensed per server, per virtual machine or per host. Pricing remains the same as it was for RHA 16.5.
However, Arcserve told Blocks & Files that some licensing changes have been made in this version: it now requires minimum of two licenses (source and target) for initial purchase, per socket and per TB options are longer available, license keys for RHA 16.5 will not work with RHA 18.0, and operating a trial version will now require a license key.
A new report from research outfit Gigaom aims to help enterprises focus on the key factors in order to make the right decision when investing in storage systems.
Prospective buyers might be forgiven for being confused. Enterprise storage has changed radically in recent years thanks to developments such as flash memory, software-defined storage and new high-speed connectivity options.
The Gigaom report “Key Criteria for Evaluating Enterprise Block Storage” focuses on the vital metrics that should be considered for a modern block storage system aimed at serving primary workloads.
Technologies like flash memory and high-speed Ethernet networks have commoditised performance and reduced costs. Other needs such as better agility of the infrastructure and integration with cloud-based storage systems now play a bigger role, Enrico Signoretti, the report author, writes.
Many of the metrics familiar to storage managers still play an important part. They include performance, TCO, cost per IOPs and cost per GB.
What does the roadmap say?
However, Signoretti notes that many innovative technologies quickly become standard capabilities that are taken for granted, and so it is important to consider the features that vendors offer today and what they plan to release in the near future.
The meat of the report is the key criteria, including such capabilities as NVMe and NVMe-oF and analytics and notable vendor implementations.
There is also a lengthy discussion on how each feature might affect the metrics identified earlier in the report, plus a handy table that offers an at-glance guide with rough weightings.
Signoretti makes it clear that the impact of such features differs for every organisation, and so his goal is to enable end users to better understand the value of each feature or storage capability presented by vendors when making their own purchase decisions.
Gigaom’s report can be downloaded from the firm’s site here.
The latest SSD market figures from IDC show that Samsung continues to be the leading supplier, but that revenue is down sharply against last year while shipments have increased, showing that the market is still suffering from oversupply in the short term.
According to IDC, total SSD market revenue in 1Q19 hit $4.924bn, which is 30 per cent down o this time last year. It estimates that a total of 60.2m SSDs were shipped in the quarter, representing a 21 per cent increase on last year.
In terms of SSD capacity sold, IDC’s figures show 25.3 exabytes (EB) was shipped in 1Q19, which is a 33 per cent increase on last year.
Looking at the enterprise sector, SSD revenue (the black line in the chart) was $2.494bn in 1Q19, which is 35 per cent down on the same quarter last year.
Enterprise SSD revenue and capacity shipped
However, a total of 9.72EB of enterprise SSD capacity shipped in the quarter (the blue bars), an increase of 11 per cent year-on-year, which indicates that the price in terms of $/TB has fallen 41 per cent. IDC estimates this was made up by unit shipments of 6.8m SSDs, which is just 1 per cent up on this period last year.
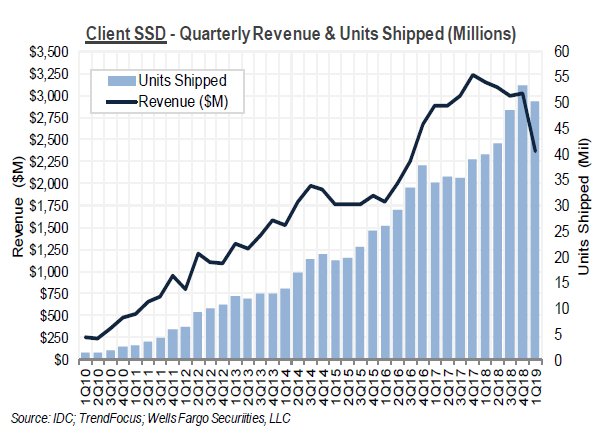
For client SSDs going into laptops and the like there is a similar picture, with revenue hitting $2.371bn for this quarter, 25 per cent down year-on-year.
Client SSD revenue and millions of SSDs shipped
This revenue was made up through the delivery of 15.6EB of SSD capacity, up 51 per cent year-on-year, and implies a fall in price per TB of 50 per cent. In terms of actual unit shipments, IDC estimates this represents 50.4m drives, an increase on this time last year of 26 per cent.
So what is causing this decline in revenue? Well, The Register reported last week that oversupply in the Nand flash component market has seen revenues slump there, which is good news for buyers, but not so good for the manufacturers.
Weakening demand in 4Q18 has pushed OEMs to begin adjusting their inventories, meaning that the system builders are likely to be buying in fewer SSDs while they use up supplies they have already ordered. Demand is expected to pick up again, however.
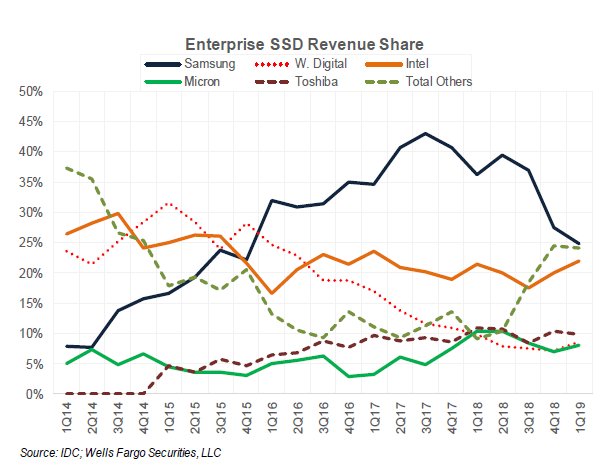
Enterprise SSD revenue by vendor
Meanwhile, IDC’s figures show that Samsung keeps its position as the top SSD vendor, followed by Intel and Western Digital, although Samsung’s share of the enterprise SSD market appears to be declining while Intel’s has held relatively steady over the past year.
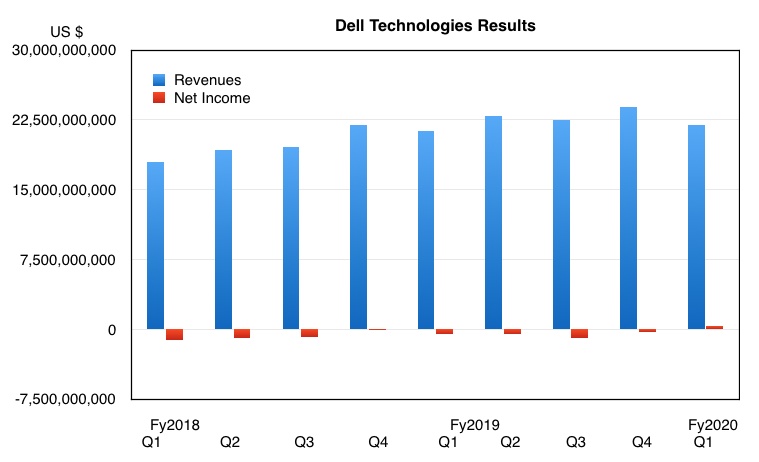
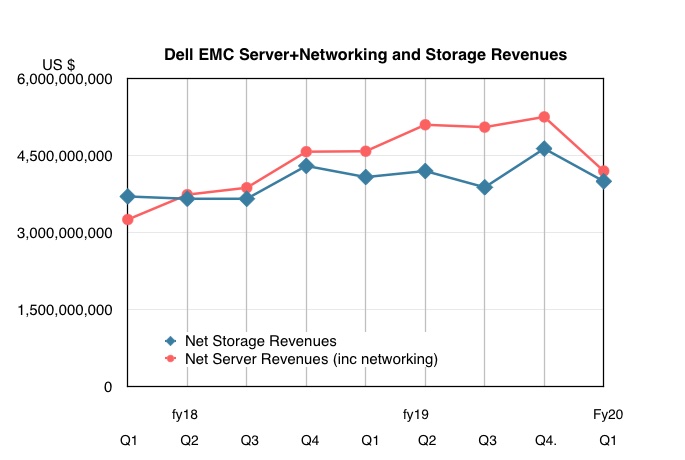
Dell posted $21.9bn revenues for the first fiscal 2020 quarter up three per cent on last year, and net income $329m (-$538m). However storage revenues fell a little and server revenues fell a lot.
Revenue falls were in Dell’s Infrastructure Solutions Group (ISG) where revenue for the first quarter was $8.2bn, 5 per cent down year-over-year. The company reported a 9 per cent decline in server and networking revenue to $4.2bn. There was also a 1 per cent decline in storage revenue to $4.bn.
These results brought Dell’s servers and storage revenues closer together:
The other parts of Dell’s empire did much better:
Client Solutions Group revenue for the first quarter was $10.9bn, up 6 per cent
Commercial revenue grew 13 per cent to $8.3bn
Consumer revenue was down 10 per cent to $2.6bn
VMware revenue was $2.3bn for the first quarter, up 13 per cent, with profits of $505m, down 46.4 per cent from last year’s $942m.
Dell attributed the ISG performance to lower-than-anticipated industry demand, principally in China, and certain large enterprise opportunities. In both, Dell walked away from deals that required heavy discounting to win the bids .
Storage focus
Storage demand remained solid but revenue was down due to an order backlog.
Dell said it has had four consecutive quarters of storage share gains. It said it is the leader in storage software with 14.9 per cent share, the number one all-flash array provider with 27.9 per cent share, and number one HCI provider with a 28.6 per cent share. VxRail revenues grew by triple digits.
It doesn’t yet know if it grew server share in the quarter, waiting on IDC numbers, but it was leader in units and revenue, and thinks it grew market share.
The company anticipated storage sales will rise still further when the new unified mid-range products arrive by the end of the year.
Storage supplier comparison
We can compare Dell’s quarterly storage revenue history with other suppliers’ storage-only revenues.
Supplier quarters normalised to HPE’s.
Dell EMC is the clear top storage supplier, followed by Western Digital, then Seagate. The top three are trailed by NetApp and ten HPE. Below them in our chart are a pack of other suppliers such as IBM (storage hardware only), Nutanix, Commvault and Pure Storage.
Sunil Potti, Nutanix chief product and development officer, has resigned to go somewhere else.
On top of disappointing Q3 fy19 results due to customers taking up subscriptions faster than anticipated, and such subscriptions having an unexpectedly deeper effect on revenues, Nutanix has lost its product guiding light.
Sunil Potti.
CEO and founder Dheeraj Pandey commented on this in the earnings call: “Sunil Potti, our chief product officer, has decided to leave the company to pursue another opportunity. Sunil joined Nutanix at a critical moment over four years ago, and has shepherded our product organisation through a period of significant growth.
“The last four years have been memorable, and I will miss a leader in him who was fun, collaborative and deeply empathetic. We are grateful to have benefited from his leadership as we’ve grown over the years and we wish him the very best in his future endeavours.”
Potti will leave Nutanix in June. He joined the company from Citrix in January 2015. His destination is unknown but may involve a SaaS company and. Blocks & Files guesses, a CEO position.
Brian Stephens, until recently the CTO of Google Cloud, has joined the Nutanix board.
Gigabyte has announced an Aorus PCIe v4 SSD that streams data at 5GB/sec, faster than an Optane gumstick drive.
The gumstick card M.2 2280 drive uses 96-layer 3D NAND from Toshiba organised into TLC (3bits/cell) format. The drive has 500GB, 1TB and 2TB capacities and a PCIe gen 4 x4 lane interface with NVMe v1.3.
Intels latest Optane memory M15 M.2 drive runs at 450,000/220,000 random read-write IOPS and has 2GB/sec and 900MB/sec sequential read/write bandwidth. The Aorus drive blows it away.
Aorus PCIe gen 4 SSD
Aorus is Gigabyte’s gaming brand and this is a gamer’s workstation drive. The card supports TRIM and SMART, and has a full body copper heat spreader. It requires an external 2GB DDR4 cache.
Gigabyte supplies a five-year warranty but does not reveal the Aorus drive’s endurance. There is no lifetime terabytes written rating.
This is the first PCIe 4 drive we have seen and we are eager to see a data centre drive using PCIe 4.0. But, with PCIe v5.0 systems likely to appear ion a year’s time vendors may skip the 4.0 standard.
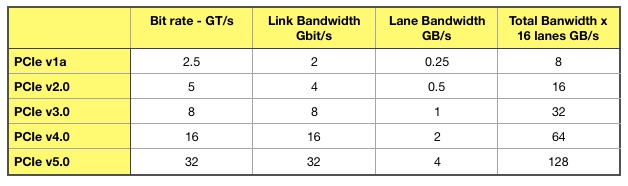
The PCI-SIG has released PCIe 5.0, a specification that quadruples PCIe speed, with 16 lanes running at 128GB/sec.
Servers using the PCIe 5.0 bus should run applications faster as their IO transfers complete in less time.
PCIe speeds are represented as the raw bit rate and also gigatransfers/second (GT/s) as the bits transferred across the bus include overhead bits as well as data bits. The actual data rate can be approximated though, and our table shows this as a per lane rate and aggregated across 16 lanes.
PCIe speed table.
PCIe 4.0 standards were announced some two years ago. The update has taken 18 months to produce and is backwards-compatible, as with previous versions of the specification.
Indeed the PCI-SIG has produced the updates so quickly that hardware system builders may skip PCIe 4.0 entirely to go straight to v5.0.
PCI-SIG Astera Labs has announced PCIe v5.0 retimer technology to help hyperscalers to tie processors, GPU accelerators and storage nodes together across PCIe. Retimers are needed to ensure PCIe signal integrity across links.
Applications in the artificial intelligence, machine learning, gaming, visual computing, storage and networking areas are identified by the PCI SIG as potential for v5.0 systems.
PCIe members can get the v5.0 specifications here.
NetApp bought Cognigo, a small Israeli data compliance and security supplier, for $70m last month, according to local reports.
Cognigo’s 35 staff will join NetApp at its development centre in Israel.
Cognigo was founded in 2016 as D.Day Labs by CEO Guy Leibovitz and raised $11m in two funding rounds.
Guy Leibovitz
Leibovitz published a letter about the NetApp acquisition on LinkedIn. “Cognigo’s technology will extend NetApp’s Cloud Volume ONTAP portfolio with an AI-driven compliance solution,” he wrote.
Cognigo’s intriguingly empty website shows data flooding in.
On a personal note he said: “The decision to be acquired was a bittersweet one, but I am certain it was the right one.
” In a short amount of time, we reached the escape velocity that every startup craves for. Revenue was tripling almost every quarter. We had a fast-growing number of clients including top banks, insurance and media companies worldwide.
“Our partnership with NetApp started early on, and I always saw a clear alignment of culture, values and vision. Joining forces with NetApp today, will allow us to reach a larger audience, and realise our mission at a faster pace.”
HPE’s upcoming purchase of Cray and its ClusterStor high-performance computing arrays could affect its supplier Qumulo.
HPE will have four scale-out filesystem products to sell: its own Scalable Storage for Lustre, two partnership-supplied offerings from Qumulo and WekaIO Matrix, and Cray ClusterStor.
Blocks & Files asked Qumulo how it saw the scale-out file system situation with HPE buying Cray, and we received a reply from Molly Presley, Qumulo’s director of product marketing, shrugged off our suggestion that ClusterStor was a cuckoo in HPE’s storage nest.
No ClusterStor cuckoo here
Molly Presley
She saw three trends affecting file system storage:
Customers want the freedom of software defined storage (aka, they want to avoid vendor lock-in on hardware and the associated uncontrolled support price increases that occurs on proprietary hardware from some vendors beyond year 3)
High-performance applications are designed today and over the past several decades to write to file systems. File counts and size of unstructured data has accelerated far beyond the limits of many legacy file, NAS, scale-out and scale-up architectures.
The cloud is an important part of infrastructure today, or in the near term planning for most data driven organisations.
In her view, ClusterStor, Weka and Qumulo all are driven by these trends. But similarities pretty much stop there. Presley explained Qumulo’s thinking on its differentiation from ClusterStor and WekaIO below.
ClusterStor and Lustre
ClusterStor is a branch of the Lustre open source code. It has its own features and code branches that are only merged with the main tree of Lustre code on a very infrequent basis. ClusterStor is essentially an appliance made and supported by Cray to simplify Lustre deployment, and for users who want support for the open source Lustre code and who already have a relationship with Cray for their supercomputing technology.
The use case for Lustre is for extremely high performance, supercomputing users that have a very high number of users. It is a workhorse file system that requires deep administrative expertise, requires client software be loaded on all client machines, and has very few enterprise high availability or data protection features built in.
Presley pointed out that Robinhood tiering has proven to not be robust; typically third party applications are needed for data protection; there are no snapshots, very limited NAS integration work with directory services, NAS security and cross protocol locking for mixed SMB and NFS environments.
It is really designed for in-data centre deployment on Fibre Channel or InfiniBand networks to connect to super computers.
With the purchase of Cray by HPE, perhaps ClusterStor in the future will be sold elsewhere, but today, it is sold as part of a larger supercomputing deployment in large HPC data centres. Time will also show if the Lustre-based ClusterStor file system gets significant traction with Cray compute in Azure.
WekaIO
Weka is a new file system, written cloud-native, that appears to have been purpose designed to compete against Lustre in these extreme performance, HPC environments. They are in a spec war showing who has the fastest benchmarked performance numbers.
Weka is high performance but [it’s] very expensive to build that performance. Weka is focused on extreme IO acceleration and low latency. It is a model targeted toward supercomputing scratch space primarily, and, secondarily, applications which need a burst buffer.
In a panel discussion with Weka, DDN, Qumulo and WD’s object storage division in Texas this spring, Weka was focused on their focus on being a burst buffer as an alternative to IME.
It requires NVMe storage and substantial amounts of memory to achieve the posted performance numbers. It then has an offload to [an] object storage function for long term retention.
Weka has snapshots but lacks replication, quotas and many of the NAS protocol deeper capabilities mentioned above. Weka typically is displacing GPFS, Lustre or competing against BeeGFS and DDN.
Qumulo
Blowing her own trumpet, so to speak, Presley said Qumulo is designed to meet the demands of the much larger scale-out NAS and distributed file system market. It offers very simple to deploy and manage offerings both on-prem and in the cloud.
Qumulo typically is displacing NetApp and Isilon, competing against Pure and Nutanix. Qumulo is designed to integrate into enterprise environments that have both Macs and PCs with their strong SMB and NFS support. Extensive work has been done to integrated into directory services, maintain enterprise access permissions, assign usage quotas.
[It] is built for both business units with large unstructured data (automotive, life sciences) and bumps into Weka and Lustre in these environments competitively. Qumulo has a much larger TAM as it also is very successful in video surveillance (which doesn’t need the extreme performance), M&E (which has extensive Mac users), Healthcare and Enterprise environments (which require deep enterprise NAS integration, high availability and complete enterprise data protection services).
Blocks & Files net:net
So there you have it. Qumulo argues that there is substantial differentiation from Lustre-based systems like ClusterStor, which is not enterprise-capable. It also differs from newcomer WekaIO which focuses purely on high-performance, unlike Qumulo, which competes with mainstream NetApp ONTAP and Dell EMC Isilon systems.
Our take is that Qumulo believes HPE will still need to partner with Qumulo in these sales opportunities because both Weka and Lustre systems have insufficient functionality in this mainstream scale-out filer space.
Analysis:LucidLink announced its Filespaces cloud file service product provides on-premises applications with instant access to large data sets over long distances, without consuming local storage.
That got Blocks & Files attention; instant access to TBs and PBs of data over long distances? No local storage? How?
The announcement release said Filespaces works with any OS, and any cloud or on-premises object storage. Its cloud-native product sits on top of S3 object storage and reduces the traffic between applications and its remote storage.
George Dochev, LuciudLink co-founder and CTO, said: “By seamlessly transforming any S3 storage into just another tier of local storage, LucidLink allows organisations to leverage the cloud economics for high-capacity data workloads.”
LucidLink says there is no need to download all the data and synchronise it as file sync-and-sharing applications do. Because it streams data on demand to a requesting site applications can read or write portions of large files without the need to download or upload them in their entirety.
LucidLink claim concerns
On-premises applications mount the remote storage as if it were a local disk and only the portion of the data currently being used is streamed across the network. Filespaces “mitigates the effects of latency when using cloud storage as primary storage.”
Mitigating the effect of latency could mean something different from “instant access.”
The point about not “consuming local storage” is not quite true as Filespaces utilises the local storage on each device to cache the most frequently accessed data. Why bother doing this unless there is a time penalty when accessing remote data in the cloud?
Blocks & Files checked out how this technology works.
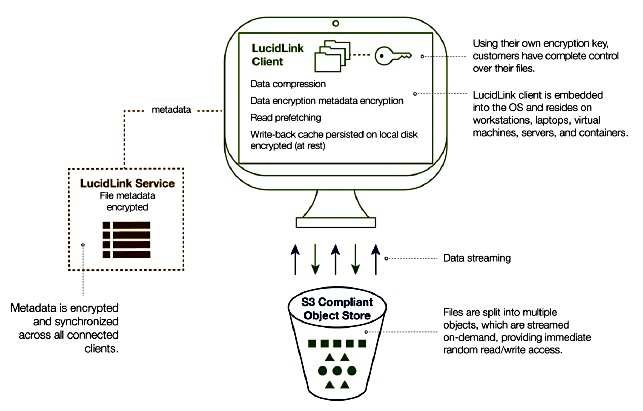
LucidLink Technology
There are three Filespaces technology components;
Client SW,
Metadata service, known as the hub,
Object store.
LucidLink Filespaces diagram.
SW on each client device is integrated with the local OS to present a file system mount point that seems to be a local device. This software talks to the metadata service and the object store back-end via a LucidLink protocol. It does not use the standard NFS or SMB protocols.
The metadata service is replicated across all nodes so that access is local and not remote. LucidLink says: “overall system responsiveness increases significantly when all metadata related operations are serviced locally.“
This means that Filespaces accelerates access to metadata to achieve the same end as InfinteIO; save the network links for data traffic and don’t fill them up with chatty metadata traffic.
The metadata service is a distributed key:value store, stored separately from the object store, and delivers file system metadata – (file system hierarchy, file, and folder names, attributes, permissions etc.,) to all client nodes. Metadata is continuously synced between client devices.
The object store contains file data which is compressed and encrypted on client devices before being uplinked to the object repository. This inline compression reduces the amount of data sent up the links to the object store. There is no deduplication.
As a file is written to the object store it is split up into equal-size pieces which are each written as separate objects and manipulated as atomic entities. The segment size is a configurable parameter at file system initialisation time.
When a client device requests file access, data is streamed down to it, first being decrypted and verified.
LucidLink says performance is enhanced through the metadata synchronisation, local on-disk caching, intelligent pre-fetching and multiple, parallel IO streams.
Multiple parallel streaming
Dochev told us: “When the user reads from a file, for instance, we prefetch simultaneously multiple parts of the file by performing GETs on multiple segments using the already opened connections. When writing, we again upload multiple objects simultaneously across these multiple connections.”
“Multiple parallel IO streams mean that we open multiple HTTPs connections (64 by default) to the object store and then perform GET/PUT requests in parallel across these multiple connections. Conceptually we talk about one object store, but in reality, these multiple connections likely end up connecting to different servers/load balancers comprising the cloud provider infrastructure. In the case of a local on-premise object store, they might be different nodes forming a cluster.”
Prefetching
Prefetching involves fetching more blocks than requested by the application so that future reads can hopefully be satisfied immediately from the cache without waiting for data to come from the remote object store.
LucidLink’s software checks for two types of IO; reads within the same file and within the same directory. It identifies and analyses multiple streams to improve the prefetch accuracy. When an application issues multiple streams of sequential or semi-sequential reads within the same file or multiple files in the same directory, each stream will trigger prefetching.
The aim is to eliminates cache misses, and LucidLink will incorporate machine learning in the future to improve prefetching accuracy.
Write-back caching
Filespaces also uses persistent write-back caching as well as prefetching, to improve write performance.
Application write requests are acknowledged as soon as the data is written to the local disk cache. These cached writes are pushed asynchronously and in parallel to the object store. As each block is uploaded, the metadata is updated so all other Filespaces clients can see the file store state as soon as the data is available to them.
Multiple writes to the same file might be cached before being uploaded, reducing network traffic.
Cache size can vary from a few GBs on smaller devices like laptops all the way to multiple TBs on servers. It expands on demand up to a predefined and configurable limit. Once the cache fills up with data to be written, the system can slow down, as all new writes get processed at the speed at which old ones are flushed to the cloud.
On top of this
Filespaces is based on a log-structured design. A filespace can be snapshotted and preserved at any point in time. Using the snapshot, individual files or the entire file space can be recovered to an earlier point in time. A snapshot copies incremental changes since a previous snapshot was taken and not the full data set.
Admin staff can control which parts of a filespace are accessible by individual users and the design supports global file locking and zero-copy file clones.
Future advancements will deliver multi-cloud capabilities in the form of striping, tiering, and replication across multiple S3 buckets. Replication to multiple regions or providers offers a higher degree of durability, and reduces the distance (time) to data by allowing each node to access its closest location.
Net:net
Can LucdLink’s Filespaces product deliver cloud economics, object store scalability and local file store performance?
The proof of its usability will be defend upon the caching size, the prefetch ability, the multiple parallel IO streaming, the write back caching flush speed, and the metadata synchronisation. As a Filespaces systems grows in size all these things will be tested.
The basic design looks comprehensive and a proof of concept would seem to be a good idea for interested potential customers.
Interview DDN bought software-defined storage player Nexenta this month. We conducted a short email interview with Kurt Kuckein, DDN senior director, to find out more.
Blocks & Files: Will Tarkan Maner stay on as Chairman and CEO of Nexenta?
Kurt Kuckein: Tarkan is staying on as CEO of the Nexenta by DDN business.
Blocks & Files: What is DDN’s strategy for Nexenta?
Kurt Kuckein: Short-term, we will continue to have each of the three businesses follow their swim lanes and they are tasked with being the best in their respective markets.
DDN Storage delivers the world’s most powerful and comprehensive AI, big data and data management at scale product portfolio.
Tintri by DDN offers the ultimate in simplicity and control for virtualized environments and enterprise applications.
Nexenta by DDN provides the most cost and performance-optimal software-defined data services for enterprises, telcos and SPs with 5G and IoT requirement.
We are currently defining the longer-term vision and product roadmap. We certainly see opportunities in the convergence of AI and Analytics processing at scale (DDN’s strength through our history in HPC) with the promise of next-generation networks like 5G creating new opportunities at the edge (IoT deployments and such) all the way back the core – whether that final resting place be in the data centre or on public cloud.
Layer on top of that the Tintri analytics capabilities and tight integration with VMs (and potentially containers) and applications and you can start to see a possible direction. Again, none of this is set in stone yet, and the product direction is still being discussed.
Blocks & Files: Will there be a convergence of Nexenta’s back-office functionality with that of DDN?
Kurt Kuckein: Much like the Tintri acquisition, we do see opportunities to lower operating costs through pooling of back office resources. That is definitely in the plan.
Blocks & Files: Will Nexenta remain in its current San Jose offices or move to DDN’s Chatsworth facility?
Kurt Kuckein: The Nexenta folks will be moving to the Santa Clara DDN/Tintri offices at some point.
Blocks & Files: On a separate topic, how does DDN view the HPE-Cray combination in terms of competition for its own storage line? (Cray has its Lustre-based ClusterStor scale-out parallel access filesystem arrays and DataWarp accelerator.)
Kurt Kuckein: This is probably a longer conversation.
Blocks & Files: And one we intend to have. Thank you.
Net:net
DDN is heading towards an endpoint where data generated by IOT edge devices is transmitted across 5G networks and combines with other enterprise generated data. This is processed by virtual machines and containers, and AI and analytics may have roles to play. Data is stored and archived on-premises or transmitted to a final resting place in the cloud.
NVMesh provides NVMe-over-Fabrics access to all-flash storage, configured as an all-flash array or as hyperconverged storage. It provides the storage for the open source BeeGFS, which is maintained by ThinkParQ.
BeeGFS clients have direct parallel access to storage servers with file access informed by separate metadata servers. Files are separated into chunks and striped over the storage servers. Metadata can also be spread across several metadata servers for scalability.
AI applications that use GPU compute clusters experience an IO bottleneck because data reaches the GPUs too slowly from external storage. NVMesh software can speed up external storage access by GPU cluster, according to Excelero and ThinkParQ.
The two companies tested their setup on a 2U 4-server chassis with 24 NVMe SSDs, running NVMesh and connected via a 100Gbit RDMA network to 8 BeeGFS client compute nodes. This system delivered 75GB/sec sequential bandwidth and 1.25 million random write IOPS. The IOPS number dropped to 251,000 when NVMesh was not used.
Excelero and ThinkParQ will show BeeGFS running with NVMesh at the ISC High Performance Event 2019, June 16-20 in Frankfurt, in ThinkParQ’s booth J-640 and Excelero’s booth E-1039. Read a blog about Excelero and AI data access here.