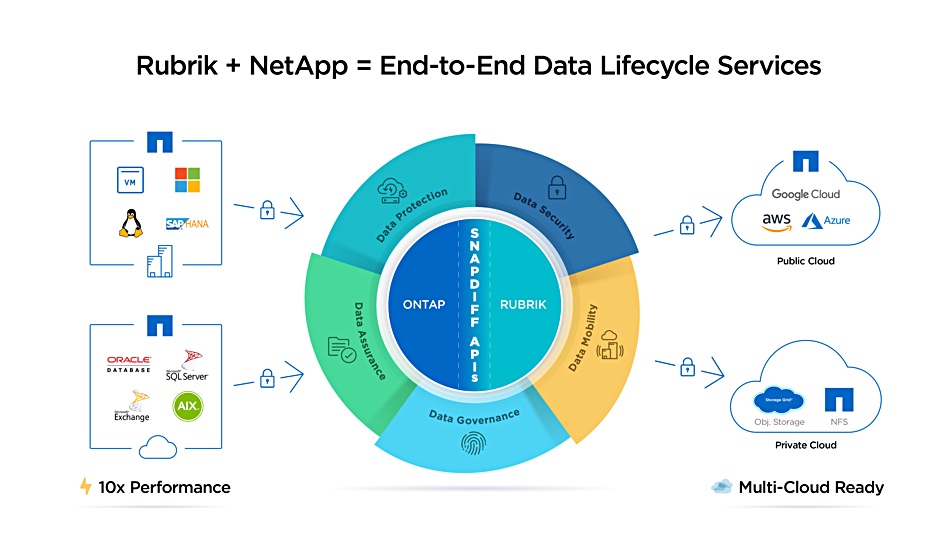
Rubrik Cloud Data Management (CDM) will integrate with NetApp’s SnapDiff APIs to enable faster ONTAP backups, the companies announced yesterday.
Backups are normally done incrementally after an initial full system backup, backing up only the files that have changed. This saves time compared to the original full backup. However, this changed file information collection process takes take longer and longer as the filesystem population of directories, sub-directories and files grows into the tens of millions.
Usually external backup software accesses a NAS filesystem and does a so-called tree walk; inspecting every directory, sub-directory and file to collect a record of the filesystems’ state. This is compared to a previous record and a list of changed files which need backing up is created.
With this NetApp deal, Rubrik’s CDM no longer has to do a tree walk and can get its list of changed files to backup quicker and with far less CPU resources. As ONTAP runs on-premises in NetApp arrays and also in the public cloud, Rubrik CDM runs faster ONTAP backups in both environments.
Spot the difference
NetApp’s Data ONTAP OS takes snapshots of its filesystem. SnapDiff, a proprietary crawler or indexer in the array, compares two snapshots, listing the files which have been added, deleted, modified and renamed. Internal NetApp APIs give access to the SnapDiff engine.
Rubrik SnapDiff API integration with NetApp ONTAP.
Third-party software vendors with SnapDiff API licenses include Catalogic, Commvault, IBM (TSM) and Veritas (NetBackup).
But Rubrik is the first backup vendor to gain NetApp access to SnapDiff APIs to find and send backed up data to the public cloud.
SnapDiff enhanced functions for Rubrik include data compliance, governance and hybrid cloud application failover/failback of ONTAP systems.
SnapDiff API integration will be released with v5.2 of Rubrik’s CDM in early 2020.
Teradata is rushing to cloudify its data warehouse software in the face of SnowFlake and Yellowbrick and public cloud competitors.
The company has already simplified its product set by combining them into Vantage. The next steps are to broaden its public cloud scope and extend self-service capabilities to reduce the need for expensive data scientists.
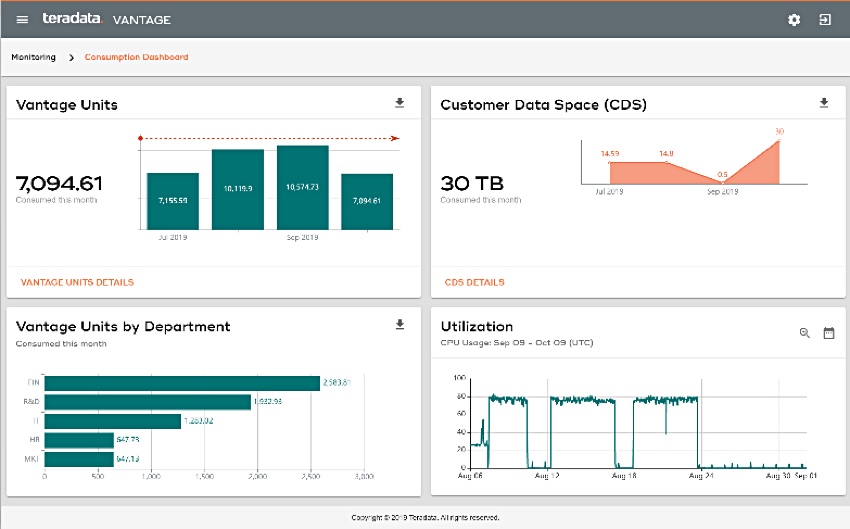
Teradata today announced it will make Vantage available on the Google Cloud Platform, adding to AWS and Azure coverage. It is also adding support for lower-cost cloud storage options: AWS S3, Azure Blob and GCP storage.
Consumption-based pricing for Vantage in the cloud is coming, with per-millisecond level billing.
The company has also introduced a collection of tools, processes and services to help Hadoop users to migrate to Vantage integrated with public cloud storage.
Vantage pay-as-you-go pricing monitor
And it has assembled two offerings to help customer staff run self-service analysis without direct data scientist help. Vantage CX as-a-service is targeted at marketers who need to analyse customer buying behaviour better so as to tailor offers for them.
Vantage CX on a notebook
Vantage Analyst is a way for business users to get the benefit of machine learning and deep analytic routines, again without the need for direct data scientist involvement.
With these moves Teradata will be more able to compete with Snowflake and Yellowbrick Data on their own public cloud and as-a-service grounds.
Teradata is the traditional front-runner in the data warehouse market and historically sold a mix of expensive on-premises software atop super-expensive hardware. This successful formula has been under strain in recent years with revenues falling from $2.7bn six years ago to £2.16bn in 2018,
The prime cause for the fall has been the switch of data warehouse market to the cloud. New cloud competitors include Snowflake, Yellowbrick, AWS Redshift and Microsoft Azure SQL Data Warehouse pose an existential threat to Teradata.
But the company remains financially robust and seems to have the internal resources to make that cloud pivot. The company will hope today’s moves will stop on-premises customers getting seduced off the reservation and return Teradata to growth.
Availability
Consumption pricing for Teradata Vantage has limited availability now, with general availability planned in the first half of 2020. Hadoop migration services are available now. Teradata Vantage on GCP is planned to be available in 2020.
Native access to low-cost object stores is in private preview now, with general availability planned in the first half of 2020. There is no price uplift as native object store is included with Vantage.
Vantage Customer Experience is in limited availability, with general commercial availability in Q1 2020. Vantage Analyst is available now with additional features by year end, 2019.
Western Digital has uprated the Red line of NAS drives to 14TB capacity, included a 1TB 2.5-inch mini Red and added a Red SSD as a NAS flash cache.
The mainstream RED disk drive line is split into the Red Pro for NAS enclosures with up to 24 bays and the ordinary Red, which supports up to 8 bays. The Red spins at 5,400rpm and has a 3-year warranty, while the Red Pro spins at 7,200rpm and carries a 5-year warranty.
Red line capacity options are 1, 2, 3, 4, 6, 8, 10, 12 and 14TB, and the workload rating is 180TB/year. There is also a 2.5in drive variant with one single 1TB capacity point.
The Red Pro is slightly different, offering 2, 4, 6, 8, 10, 12, and 14TB and has a 300B/year workload rating.
WD Red 3.5-inch and 2.5-inch disk drives.
All the Red disk drives use a 6Gbit/s SATA interface and are rated one million hours MTBF. The 10TB and higher variants are helium-filled drives and the the others are air-filled.
WD Red SA500
The WD Red SA500 is the company’s first NAS-focused SSD, is supplied in 500GB, 1TB, 2TB and 4TB versions. They are also available in U.2 and gumstick formats with capacities of 500GB, 1 and 2TB.
WD Red U.2 and M.2 SSDs
So what makes these SSDS more suitable for NAS work than any other SATA SSD? Here is WD’s answer: “Unlike standard SSDs, WD Red NAS SATA SSDs are specifically designed and tested for 24/7 usage. Their endurance and efficient caching makes them ideal for demanding applications.”
That sounds a tad thin to this cynical hack. The SA500’s endurance numbers are:
500GB – 350TBW (Terabytes written)
1TB – 600 TBW
2TB – 1,300TBW
4TB – 2,500 TBW
The 1TB version, when writing 1TB /day, would need a 1,800TBW rating over 5 years. Instead it gets 600TBW, meaning 0.33 drive writes per day (DWPD). This implies the drives have limited over-provisioning.
Seagate’s IronWolf 110 NAS SSD offers 1DWPD, with the 384TB version supporting 7,000TBW. This far outstrips WD’s 4TB Red SSD and its 2,500TBW rating. Check your drive endurance needs carefully.
Prices start from $72.00 for the M.2 500GB Red SSD and $75 for the U.2 500GB Red SSD. The 14TB red disk drive costs $450 with the equivalent Red Pro priced at $525.
The 14TB drives and Red SSDs will be available in November from WD’s various channels.
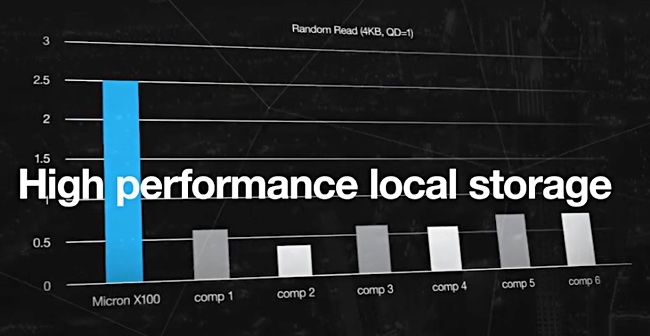
Micron today introduced the X100 – the world’s fastest SSD, it claims. Oh and it’s the company’s first 3D XPoint product, which makes the X100 the world’s first direct competitor to Intel Optane.
The X100 offers up to 2.5 million IOPS – “more than three times faster than today’s competitive SSD offerings,” Micron said today. But in reality there is only one competitor out there – Intel’s DC D4800X, which also uses 3D XPoint media.
Micron X100 video capture. Queue depth of 1 and comp 5 or 6 is probably Intel’s D4800X at 550,000 IOPS.
The X100 has an NVMe interface running across a PCIe Gen 3 x16 lane bus.
Micron X100 3D XPoint drive.
It provides 550,000 random read or write IOPS so Micron’s 3x faster claim is no exaggeration. Micron quotes eight microseconds for X100’s latency. This is two microseconds faster than Intel’s D4800X SSD.
That implies it is using second generation XPoint; the media Intel revealed in its Barlow Pass technology in September.
According to Micron the X100 has more than 9GB/sec bandwidth in read, write and mixed modes. The D4800X does up to 2.7GB/sec when reading and 2.2GB/sec when writing. By this measure the X100 looks eye-wateringly fast.
The nearest SSD is Samsung’s PM1733, which delivers 8GB/sec in AIC format using PCIe gen 4 and TLC 9x layer NAND; 9x meaning 90 to 99 layers. A PCIe Gen 4 X100 should go even faster than 9GB/sec.
Micron doesn’t reveal the X100’s capacity. However, gen 1 XPoint uses a 128Gbit die. Gen 2 XPoint doubles the layer count from gen 1’s 2 to 4. Images of the X100 card show 16 die placements. Assuming a gen 2 die has twice gen 1’s capacity that means the X100 will be a 512GB capacity product (16 x 256Gbit).
In a statement Sumit Sadana, chief business officer, said the X100 delivered “breakthrough performance improvements for applications and enabling entirely new use cases.”
Micron claims the X100 enables two to four times the improvements in end-user experience for various applications in data centres.
Micron has broadened its data centre SSD range, moving the 9300 NVMe SSD technology down market, and adding a gumstick form factor. It has also replaced the 5200 SATA SSD with the 5300. The new lines all use the latest 96-layer TLC (3bits/cell) NAND.
The 7300 complements rather than replaces the 9300, according to Micron, which likens the 9300 to a Porsche GT3 and the 7300 to a Tesla Model 3.
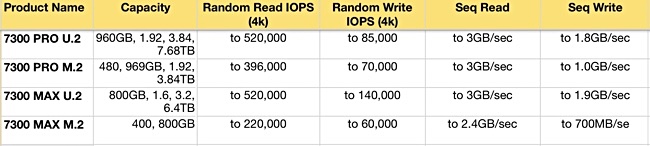
Like the 9300 NVME SSD, the 7300 comes in capacity-optimised PRO and endurance-optimised MAX versions. The PRO supports a single drive write per day and the MAX version lifts this to three DWPD.
The 7300 is hot-pluggable and supports Flex capacity. This means admins can tune the SSD to get the right capacity and endurance balance.
The 9300 comes in the U.2 form factor. Both the PRO and MAX 7300s are available in U.2 and lower capacity gumstick formats.
Their latencies are 90μs/25μs read/write; slower than 9300’s 86μs/11μs. Mean time to failure is two million hours and they have a five-year warranty. They use a PCIe Gen 3.1 x 4, 2×2 NVMe interface. The capacities and speeds are:
The 7300 has half the maximum capacity of the 9300 PRO despite using denser 96-layer TLC NAND than the 9300’s 64-layer TLC. The 9300 PRO capacity reaches 15.36TB, the 7300 PRO has7.68TB, while the 7300 MAX’ 6.4TB is eclipsed by the 9300 MAX’s 12.8TB. You get less capacity for less money.
The 7300s will get a dual-port capability in the fourth quarter.
5300 line
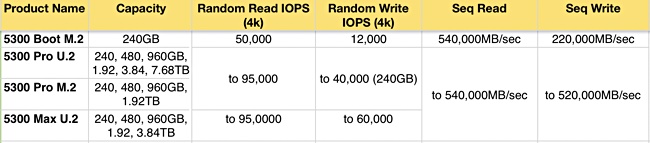
The 5300 replaces the prior 5200. The 5200 SATA SSD line used 64-layer TLC NAND packaged into U.2 2.5-inch drives and came in Eco and Pro variants. There was also a 5210 ION using QLC flash. Micron’s 5300 drives use the denser 96 layer flash and are provided in Boot M.2 gumstick, Pro M.2 and U.2 formats, and a Max in U.2 form only. Micron has not pushed out a 5310 ION in QLC guise – perhaps one will come out in a few months..
All three 5300s use the SATA 6Gbit/s interface, have 3 million hours MTTF rating, like the 5200, and a five-year warranty. They support encryption, incorporate various data protection features and are hot-pluggable.
The Boot drive comes in a single 240GB capacity and is in the 1 drive write per day (DWPD) endurance category at 438 total terabytes written (TTBW).
The Pro is a capacity-optimised 1DWPD-class drive whereas the 5300 Max is an endurance-focused 3DWPD-class drive. The 5210s have random read latencies from 175μs to 200μs, and random writes in the 100μs to 650μs range.
The capacity and speed numbers are:
The 5300 Pro extends its capacity up to 7.68GB, a big jump on the the 5200 Pro, which topped out at 1.92GB.
5300 speeds are approximately the same as the 5210s.
Micron thinks demand for SATA SSDs will continue for some time despite the growing popularity of faster NVMe SSDs. The latter are taking over from SAS drives. It also thinks that TLC and QLC flash products will co-exist, with QLC products expanding the market rather than replacing TLC flash.
Twice a year IBM blitzes out a bunch of storage hardware releases. Today was once of the twice.
The information overload is overwhelming but IBM’s main messages for today’s announcements are storage for artificial intelligence and big data applications, with various upgrades, refreshed with a sprinkling of NVMe.
The ESS3000 looks like the latest member of the Elastic Storage Server line, a scale-out set of storage products for AI and Big Data analytics. This product line is based on IBM Power processors and uses Spectrum Scale parallel access file system software.
CPU change
IBM confirmed the ES3000 system is compatible with other ESS models. Blocks & Files was told by an IBMer that the ESS 3000 is based on Intel CPUs Skylake (14cores) running RedHat v8. Also the name – look closely – has changed from ESS (Elastic Storage Server) to ESS (Elastic Storage System).
IBM ESS 3000 configuration details
The ESS 3000 is an all-flash NVMe system in a single 2U box, preconfigured with Red Hat Enterprise Linux v8.x and containerised Spectrum Scale. At launch IBM used different descriptors for bandwidth and usable capacity for ESS 3000 and its older cousins. This makes meaningful comparison impossible.
The ESS can be deployed as a standalone system or scale out with additional ESS 3000 systems or with gen 3 Elastic Storage Server systems, the gen 3 GS flash, GH hybrid and GL disk-based products. It starts from 23TB capacity (12 x 1.92TB drives) and scales up and out to an exabyte and beyond.
The 3000 uses a 24-slot, 2U box, fitted with 1.92 TB, 3.84 TB, 7.68 TB or 15.36 TB SSDs. It provides up to 3m IOPS and has up to 42GB/sec read bandwidth number (32GB/sec read), using 12 x EDR Infiniband or 100G Ethernet ports.
ES3000
The Spectrum Scale Erasure Code Edition uses, as you would expect, erasure coding for data integrity. This is more space-efficient than RAID schemes. Spectrum scale also supports the Container Storage Interface.
And now for some more IBM storage news
Next up. Spectrum Discover file cataloguing and indexing now supports Spectrum Protect backup. Discover can harvest and extend metadata for records stored in Spectrum Protect backups. Spectrum Discover supports unstructured data in IBM’s Cloud Object Storage and Spectrum Scale. IBM intends to add support for Dell EMC Isilon later this year.
Storwize V7000
IBM’s top-end mid-range array the gen 3 Storwize V7000, gets FlashCore Modules, IBM’s proprietary SSDs, with compression. The less powerful V5100s got them in April.
The souped up V7000 delivers up to 2.7x more throughput than the gen 2+ V7000 product with its non-compressing FlashCore Modules.
The V7000 has end-to-end NVME capability.
NVMe-oF
Updated Spectrum Virtualize enables NVMe over Fabrics (NVMe-oF) support for Fibre Channel through a non-disruptive software upgrade for FlashSystem 9100, many installed FlashSystem V9000s, Storwize V7000F/V7000, SAN Volume Controller and VersaStack systems.
A new 16Gbit/s adapter adds Fibre Channel NVMe-oF support for FlashSystem 900, which already supports InfiniBand-based NVMe-oF. It gets a new high-capacity 18TB flash module supporting up to 44TB effective capacity after compression, compared with 22TB for the previous module.
The FlashSystem A9000R gets a lower-capacity entry-level configuration with a 40 per cent lower list price. It gets IBMs HyperSwap high-availability feature and disaster recovery.
Later this year the A9000R (R for rack) should get AI-enhanced capacity management of its deduplicated storage.
The mainframe-focused DS8880F arrays also gets a bigger flash module increasing capacity by up to 2X. The DS8882F tops out at 737.3TB compared to its previous 368.6TB.
IBM plans to add NVMe capability to Cloud Object Storage software in software-defined storage configurations later this year.
Veritas has made a small version of its SME Flex 5240 appliance for remote and branch offices and other edge computing sites. Both versions of the new 5150 run a containerised version of NetBackup as does as the data centre Flex 5340 appliance,
The company cities a Gartner forecast that 50 per cent of data will be created and processed away from public clouds and on-premises data centres by 2022. That data should be protected and so Veritas is stepping up with a ROBO appliance that needs no local IT manager.
The 5150 holds up to14.55TB of usable capacity, a long way short of the 5240’s 294TB and 5340’s 1.9PB usable capacity. It runs at 5TB/hour doing server-side deduplication and 10TB/hour with client side dedupe. The equivalent 5240 numbers are 13TB/hour and 53TB/hour, while the 5340 numbers are 37TB/hour and 196TB/hour.
The appliance protects and restores data at the edge site, and integrates with NetBackup in the data centre and the cloud. Backup data can be sent to the cloud by creating a CloudCatalyst container from the menu on the Flex console. Deduplicated data can then be transferred.
Phil Brace, Veritas EVP for storage solutions, said in a press release that the 5150 is an exciting first step. This implies there will be more appliances or instantiations of NetBackup for ROBO sites – perhaps as a SaaS offering. Veritas already offers SaaS backup for Office 365.
Veeam today released some headline figures for Q3 and it isn’t showing any signs of slowing down.
The privately-owned company self-reported a double-digit revenue growth quarter, without revealing any actual numbers. Annual recurring revenue increase 24 per cent year-over-year, with an 108 per cent rise in bookings for the same period attributed to its Veeam Universal License subscription deal.
Veeam’s Enterprise business grew 20 per cent and the company counts 81 per cent of the Fortune 500 and 66 per cent of the Global 2000 as customers. It said it has more than 375,000 customers, up from a claimed 350,000 customers in May 2019.
Veeam reported 113 per cent growth in Veeam Backup for Microsoft Office 365, which hasbeen downloaded by more than 84,000 organisations that support over nine million user mailboxes.
Veeam technology alliance reseller agreements with Hewlett Packard Enterprise (HPE), Cisco, NetApp, and Lenovo reported 92 per cent YoY growth, and a 28 per cent quarter over quarter increase
Veeam is now calling itself a leader in Backup solutions that deliver Cloud Data Management.
Can Veeam parlay its virtual server business into a cloud data management business? It’s a big ask and it faces competition from startup Clumio, Cohesity, Commvault, Druva, Igneous, Rubrik, and others.
If Veeam can upsell its 375,000 customers to use its cloud data management products that will give it a formidable start.
Spot the odd ones out: Carrera, Cayman, Boxster, Macan, Cayenne, Synergy, GreenLake. Easy; Synergy and GreenLake aren’t Porsche cars – but they are being used by Porsche’s in-house IT operation.
Porsche Informatik is using HPE’s composable Synergy infrastructure through a GreenLake pay-for-what-you-use deal as its goes all-in on HPE for its data centre kit. These Synergy systems deliver IT services to 30,000 Porsche employees in 29 countries. They give Porsche a software‑defined infrastructure that assembles pools of physical and virtual computing, storage and networking fabric into configurations for specific workloads. And this is in a hybrid cloud environment.
Porsche Informatik took six months to compare market offerings, do its planning and run a test phase before going ahead with the HPE set-up
Initially this involved eight Synergy 12000 frames fitted with 38 x 480 Gen10 computer modules, using Xeon SP processors, which were installed and operational since January this year.
Another eight 12000 frames with 36 x 480 Gen10 and 16 dedicated NVIDIA graphic processors for virtual desktop infrastructure were added in July.
There are 32 Synergy all-flash DS3940 modules for storage, with more than 2.2 PB capacity presented through VMware’s vSAN. A single DS3940 has 40 drive bays with 12Gbit/s SAS connectivity for SSDs.
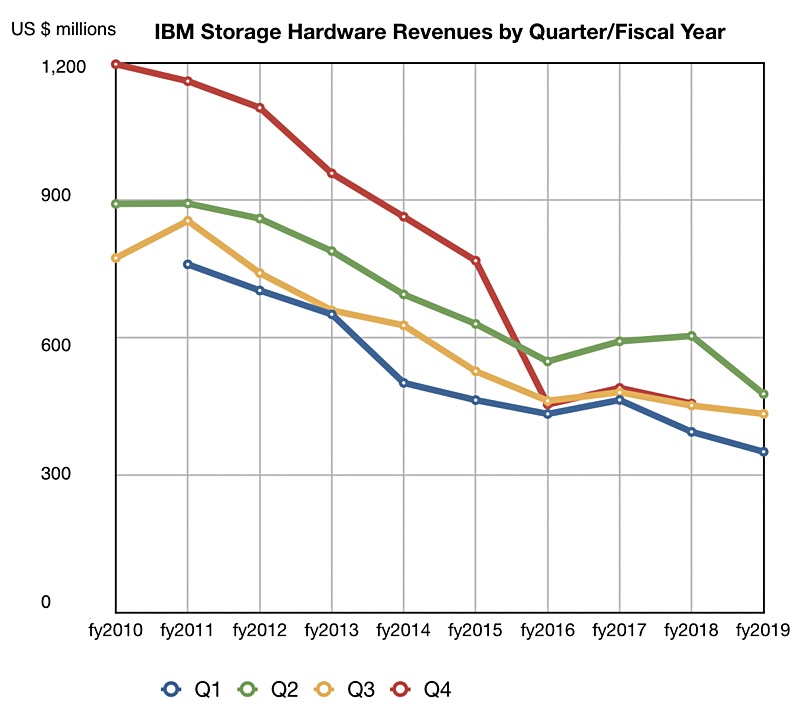
A look at storage systems’ progress in IBM’s third quarter shows continuing long-term decline but expect a mainframe-led pickup next quarter.
IBM’s overall results were examined by our sister publication The Register. We look at the storage side in more detail here.
Storage is part of IBM’s Systems segment which produced revenues of $1.5bn. Hardware revenues fell 16 per cent to $1.1bn, as the z14 sales cycle ended and the new generation z15 cycle starts. IBM Z revenue was down 20 per cent and. Power server system revenues fell 27 per cent, while storage revenues declined 4 per cent to $433.7m.
IBM CFO Jim Kavanaugh said in prepared remarks: “This is an improvement in the year-to-year performance compared to recent quarters, driven by our high-end and growth in all-flash arrays.”
We have charted IBM’s storage quarterly hardware revenues by fiscal year to show a pronounced pattern of declining revenues;
Each quarter has its own line and colour so we can see how the results have trended since fiscal 2010. Fiscal 2017 was a growth year, and fiscal 2018’s first quarter showed y-on-y growth, but all other fiscal years show consistent quarterly revenue declines.
For comparison:
Dell EMC net storage revenues were $4.2bn in its latest quarter
NetApp recorded $1.2bn in its latest quarter
HPE reported $844m
Pure’s last quarter saw $396.3 revenues and is guiding $440m for the current quarter.
Big Blue is not so big now.
NetApp and, to an extent, HPE, saw an enterprise buying slowdown in their latest results. They attributed the fall to concerns about trade wars and the macroeconomic situation. And IBM’s revenue decline? Kavanaugh answered this question in the earnings call, saying: “I would not say per se this is a macro related thing.”
The high-end DS8900 was announced in the quarter and sales should be boosted next quarter as z15 sales attract attached DS8900 storage in their wake.
Kavanaugh more or less said outright that new storage arrays were coming: “Pre-tax profit was down, reflecting mix headwinds and the investments we’re making to bring new [sic] hardware innovation to market.”
With the high-end already refreshed Blocks & Files expects new mid-range arrays in the Storwize and FlashSystem 900 lines.
IBM’s fourth quarter is traditionally its strongest, and this one will coincide with the first full quarter of z15 and DS8900 availability. Expect a bumper close to the year and an uplift in storage revenues as the DS8900 orders roll in.
Containerised applications are heading for production environments. And this is a big problem for storage admins. Unlike current production environments there are no backup data reference frameworks to call on for containerised applications. This means that administrators face a world of pain as they tackle orphan data and inadequate protection.
Containerisation is a boon for DevOps work but the lack of backup reference frameworks is a serious problem when protecting production-class containerised systems.
Chris Evans.
Chris Evans, a prominent storage consultant and author of the Architecting IT blog, takes us through the how and why of this. He concludes that filesystem-supplied data for containers is better than block storage because it can supply the necessary metadata hooks to make the backups usable.
Blocks & Files: Can you explain in principle why backup data need some sort of reference framework for it to be useful?
Chris Evans: Quite simply, application packages (servers, virtual servers, containers) have a finite lifetime and will live longer than the data they contain. We need an external way of showing where application data existed over its lifetime.
Blocks & Files: What is the situation if backup data has no reference framework? Is it basically useless because it can’t be restored? Why is that?
Chris Evans: Imagine sites with hundreds or thousands of virtual servers. Each server is unlikely to be given a meaningful name. Instead, generic names will be used that include references like location, virtual environment, platform etc. The application in some form may possibly be visible, but with limited characters, it’s impossible to be fully descriptive.
Virtual Machines are like swarms of bees.
One solution here is to use tagging of VMs in the virtual environment (although tags are freeform and that again is a problem). If any virtual server is deleted from the virtual environment, it no longer exists and is not visible in searches. The only record of its existence is then in the backup environment.
If the backup environment doesn’t preserve the tags, then the only piece of information on the application is the server name. Finding that name six-12 months later could be a real challenge.
Blocks & Files: How has this notion of a reference framework persisted as computing has passed through its stages of mainframe, mini-computer, server and virtualized servers?
Chris Evans: Over the years, we’ve moved from mainframe to dedicated client-server hardware, to server virtualization. At each stage, the ‘source’ application has been relatively easy to identify. Because:
Mainframe – permanent deployment, lasting years. Data typically backed up via volumes (LUNs) that have sensible names or are in application pools. Easy to map applications/data due to the static nature of the environment.
Server hardware – effectively permanent application hosts. Servers are deployed 3-5+years with standard naming and applications/data are only moved elsewhere when the server is refreshed. The only risky time is when applications are refreshed or moved to another server. Support teams need to know where the application was previously.
Virtual Server – typically up to 3-year lifetime, generally static names. Relatively easy to know where an application lives, although refreshes may occur more frequently to new VMs as it is sometimes easier to build from scratch than upgrade in place. IT organisations are increasingly rebuilding VMs from templates or ‘code’ and injecting data once rebuilt, rather than recovering the entire VM. This is starting to separate application data from the application code and “wrapper” (e.g. VM and operating system).
In all of the above examples, the inventory of metadata that tracks the application can be aligned with the physical or virtual server.
Data protection systems need to provide some form of inventory/metadata that allows the easy mapping of application name to the application package. With long-running systems, this is much easier as even with poor inventory practices, local site knowledge tends to help (developers know the names of the applications/servers they are supporting).
However, IT organisations should not rely on the backup system as that system of record, because servers get deleted/refreshed and in the case of a disaster, the staff performing the recovery may not have site knowledge.
Blocks & Files: Is it better to use file or blocks (LUNs) for backups?
Chris Evans: If we look back at the backup environments over time, all backup systems have backed up at either the file or application level. This is because the data itself has metadata associated with it.
File backups have file name, date, time etc. Database backups have the database name, table name, etc.
A raw LUN has no metadata associated with it. We can’t see the contents and unless there’s some way to assign metadata to the LUN, we can’t identify where it came from, security protocols or anything valuable.
The backup system can’t (easily) index a LUN image copy and we can only do basic deduplication of blocks to save on backup space. We can’t, for example, do partial recovers from a LUN image copy, unless we can see the contents.
It’s worth noting that of course, backup systems could mount the volume and attempt to read it. This was a process done years ago to index/backup data from snapshots or clones, but it is tedious. LUN snapshots will be “crash consistent” unless we have some host agent to quiesce the application before taking a copy. There is no guarantee that a crash consistent volume can be successfully recovered.
Blocks & Files: Does containerisation change things at all?
Chris Evans: Containers extend the longevity paradigm and can exist for hours or days, or even a few minutes.
A busy container environment could create and destroy millions of containers per day. This could be for a variety of reasons:
Scale up/down processing to meet demand (think of web server processes increasing to manage daytime traffic and reducing at night)
Due to errors – a container application crashes and gets restarted.
Code gets upgraded. An application is changed with a new feature added. The container image is simply restarted from the new code to implement the change.
Containers, much smaller than VMS, resemble a swarm of locusts.
Now we have separated the data from the application package. Both operate independently. This is of great benefit for developers because the separation allows them to test against test/dev images in parallel to each other, rather than having to share one or two test/dev environments. Pushing code to production is easier as the production image simply needs to be pointed to the production data.
The second challenge with containers is the way in which persistent data has been mapped to them. The original laughable assumption was that all containers would be ephemeral and be temporary data sources.
Applications would be protected by application-based replication, so if any single container died, the remaining containers running the application would keep things running while a new container was respawned and the data re-protected (a bit like recovering a failed drive in RAID).
This of course, was nonsense and would never have got past any auditors in a decent enterprise, because the risk of data loss was so great.
Also, it makes no sense to assume the only copy of data is in running applications, when data is copied/replicated for a wide variety of reasons (like ransomware). Quickly the industry realised that persistent storage was needed, but decided to go down the route of LUNs mapped to a host running a container and then formatting a file system onto it. The LUN would then be presented into the container as a file system (e.g. /DATA).
This process works, but has issues. If the container host dies, the LUN has to be mapped to a new container host (a new physical or virtual server).This could be a big problem if there are dozens or hundreds of LUNs attached to a single server.
Second, some operating systems have limits on the number of LUNs mapped to a single OS instance. This immediately limits the number of containers that host can run.
Third, the security model means we have to permit the LUNs to be accessible by ANY container that might run on that host – it’s security to the whole host or nothing. So we need a secondary security mechanism to ensure the LUN is only mapped to our application container. This never existed in the initial implementations of platforms like Docker.
Containers therefore introduce many issues with persistent data because the LUN was originally meant to be a pseudo physical disk, not a location for data.
Blocks & Files: Is it the case that a VM, which is a file, can be backed up, with the app being the VM, whereas there is no such VM-like framework with containers, so that an app cannot be referenced as some sort of VM-like containerised system construct?
Chris Evans: Comparing VMs to containers; typically a VM will contain both the data and the application. The data might be on a separate volume, which would be a separate VMDK file. With the container ecosystem there is no logical connection we can use, because the container and the data are not tightly coupled as they are in a VM.
Bunches of containers, like facets of a Rubik cube, are orchestrated to form an application. You can’t backup just at container level as you don’t know how containers fit together without a reference framework.
Blocks & Files: Doesn’t Kubernetes provide the required framework reference?
Chris Evans: To a degree Kubernetes (K8S) helps. The environment uses volumes, which have the lifetime of a Pod. A Pod is essentially the group of containers that make up part or all of an application. If a single container dies, the Pod allows it to be restarted without losing the data.
Equally, a volume can be shared between containers in a pod. The logical implementation of a volume is dependent on the backing storage on which it is stored. On AWS this is an EC2 EBS (created ahead of time). Solutions like Portworx, StorageOS, ScaleIO, Ceph etc, implement their own driver to emulate a volume to the Pod/containers, while storing the data in their platform.
These implementations are mostly LUNs that are formatted with a file system and presented to the container. Persistent Volumes in K8S outlive a single container and could be used for ongoing data storage. CSI (container storage interface) provides some abstraction to allow any vendor to program to it, so legacy vendors can implement mapping of traditional LUNs to container environments.
The problem with the Persistent Volume abstraction in K8S is that there is no backup interface built into the platform. VMware eventually introduced the Backup API into vSphere that provided a stream of changed data per VM. There is no equivalent in K8S. So you have to back data up from the underlying backing storage platform. As soon as you do this, you risk breaking the relationship between the application and the data.
Blocks & Files: If a server runs containerised apps with backups being restored to that server then is that okay, in that backups can be restored?
Chris Evans: Potentially that works, but of course containers were designed to be portable. Restricting a container application to a single server means you can’t scale and redistribute workloads across multiple physical servers.
Blocks & Files: If the containerised apps are run in the public cloud does that cause problems?
Chris Evans: Public cloud represents another challenge. This is because the underlying data platform could be obfuscated from the user or incompatible with on-premises or other cloud providers. This is great if you want to run in a single cloud but not good for data portability.
AWS Fargate (to my knowledge) is a container service that has no persistent volume data ability. AWS ECS (elastic container service) is effectively a scripted process for automating container environments, so you have to map persistent volumes to the hosts that get built on your behalf. These either have a lifetime of the container, or can be associated with the server running ECS. Therefore you’d have to build data protection around that server.
Blocks & Files: Will backups of containerise apps have to be of the data only, with that data having metadata to make it restorable?
Chris Evans: It makes sense to back up data and container information separately. Container (and K8S) definitions are basically YAML code so you’d back that up as an item and backup data separately as the application.
Blocks & Files: Does there need to be some kind of industry agreement about what need to be done? Is this an issue for the SNIA?
Chris Evans: We need people who have an understanding of the data challenges at both the storage level and data management. This seems to have been sadly lacking in the Docker and K8S communities. The SNIA could be one organisation to work on this, but I think they’re too focused at the infrastructure level.
If we used file shares mapped to containers (e.g. an NFS/SMB or solution with client presentation to the hosts running the containers) then data would be abstracted from both the platform and OS and could be backed up by traditional backup systems. We could use logical structures to represent the data – e.g. like those in Microsoft’s DFS – also we could assign permissions at the file system level which the container environment could then honour via some kind of token system.
So data management, access, security, audit would all be done at the file server level, whether the data was on-prem or in the cloud. This is why I think we’d be better off using a (distributed) file system for container data.
We have news on backup systems, NVMe-oF bundles and benchmarks, NVMe/TCP, Commvault data management, disk ships and fast access object store migration. Read on.
Acronis and Exagrid
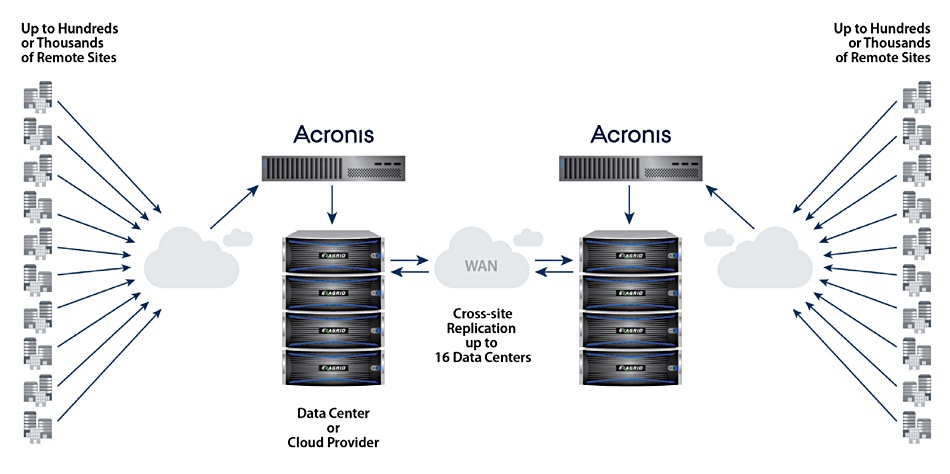
Acronis Cyber Backup software can squirt backup data to a deduping Exagrid storage box. The two companies say the combo is suitable for remote and branch offices. Remote sites use Acronis agent software to pump their data to a central Exagrid store.
Data can be replicated to a second-site ExaGrid system for disaster recovery.
Acronis-Exagrid cross-replication DR setup.
The remote sites can be split into two groups with each backing up to a single Exagrid system. The two Exagrids cross-replicate to each other to provide Disaster Recovery for the whole system.
Commvault augments Activate
Commvault has upgraded its Activate data management insights and governance software. Activate works as standalone product or in tandem with Commvault’s backup software. It gives customers visibility into their data, and helps them locate areas for storage efficiencies.
The upgrade includes Entitlement Management, which gives customers better control of critical or sensitive data.
File Storage Optimization dashboards are now consolidated into Commvault Command Center for easier management and reporting. Users can access the various views when reviewing storage distribution and identify duplicated or orphan files for clients or client-groups.
Sensitive Data Governance ets Redaction when exporting files. For those who respond to GDPR Right-to-Access and other similar requirements, the export function will optionally redact sensitive data entities found within the files or emails.
Commvault Activate remains available on a per user basis, but customers can now flexibly purchase Commvault Activate’s capabilities. This is either on a per terabyte (for use with file and VM data) or a per user(for use with email or Microsoft Office 365 data).
The new pricing options are available via Commvault resellers in early Novemeber.
Excelero love-in with Quanta Cloud Technology
Quanta Cloud Technology (QCT) NVMe storage servers are being combined with Excelero’s NVMesh NVMe-oF software for sale to HPC, cloud service providers and hyperscale customers.
QuantaGrid D52B-1U server.
QxStor Excelero NVMesh is a pre-validated and pre-configured software-defined storage product. The technology has been tested in disaggregated and converged architectures.
The two companies say it fulfils an unmet and growing demand for storage architectures with high throughput and/or ultra-low latency at terabyte-to-petabyte scale.
Mellanox supports NVMe/TCP
Mellanox has announced acceleration of NVMe/TCP at speeds up to 200Gbit/s.
Its ConnectX adapters supports NVMe-oF over both TCP and RoCE. The ConnectX-6 Dx and BlueField-2 products also secure NVMe-oF connections over IPsec and TLS, using HW-accelerated encryption and decryption for both RoCE and TCP. Mellanox claims they are the fastest and most secure NVMe-oF SmartNICs.
This NVMe/TCP storage acceleration enables customers to deploy NVMe storage in existing TCP/IP network environments. There’s no need to buy costly datacentre-class Ethernet, which you would need for NVMe-oF RoCE, which is faster though.
Pavilion Data Systems performance STACs up
NVMe-oF startup Pavilion Data Systems’ array has produced world-record performance in four STAC-M3 analytical benchmarks against all other publicly disclosed systems, including systems with direct-attached SSD storage and Intel Optane drives.
STAC (Securities Technology Analysis Center) runs benchmarks on financial trading systems for financial trading firms. These benchmarks are not publicly available. If you are a STAC member, you can see details here.
In eight records versus all-flash arrays Pavilion beat E8 with Optane, Dell/EMC with DSSD, Vexata and the IBM Flash System 900.
There were four more STAC records versus all systems, which includes filers, with Pavilion beating WekaIO and Dell/EMCIsilon.
Beating E8 with an Optane-enhanced system must have been satisfying. Pavilion said it used a mix of Toshiba and Western Digital SSDs with older servers; meaning ones not using Xeon SP processors we think. Read a Pavilion blog about its STAC wins here.
SwiftStack and InfiniteIO
SwiftStack is teaming up with InfiniteIO to migrate older inactive files off NAS storage and move them to on-premises or in-cloud SwiftStack object store – but still accessible as files.
InfiniteIO software can present them, wherever they are, as if they are local files. Customers can continuously tier and migrate files based on policy and/or metadata attributes to SwiftStack to optimise local storage.
There is an ingenious blog about a disk drive’s life by Backblazehere.
Analytics firm Databricks is donating its Delta Lake platform to the Linux Foundation, a non-profit that wants to help innovation through open source software.
Tarun Thakur, GM for Rubrik Database Products, and the CEO of Rubrik-acquired DatosIO, has left Rubrik. He co-founded distributed database protector DatosIO in June 2014 and was its CEO when Rubrik bought it in February 2018. He became the database products GM at Rubrik but now wants to take time out and perhaps look around for another startup opportunity.
Object storage service supplier Scaleway has a get-started offer with 75GB of free storage. Beyond the free 75 GB, additional gigabytes are priced at €0.01/month for storage and €0.01/month for the outgoing data transfer. The network transit infrastructure is free of charge within Scaleway regions, allowing inter-regional exchanges in Scaleway data centres in Amsterdam, Paris and very soon Warsaw.
StorMagic’s SvSAN is compared, to its advantage, with VMware’s vSAN in a DCIG report available here.