Disk drive maker Seagate has announced flat revenues and lower profits in its second fiscal 2020 quarter ended 3 January 2020, but as a bright spot, 3.5-inch drives accounted for about half of its revenues.
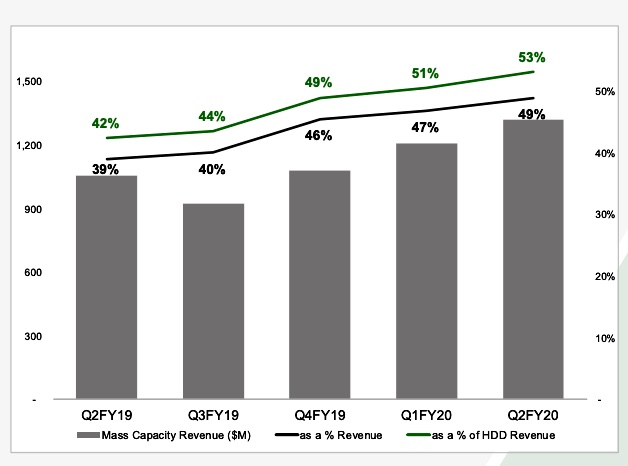
CFO Gianluca Romano told an earnings call: “Mass capacity storage which include nearline, video and image application and NAS drives represented 49 per cent of total December quarter revenue, up from 47 per cent in the prior quarter and 39 per cent in the prior year.”
Competitor Western Digital also reported anaemic revenues for the quarter.
Seagate’s revenues of $2.696bn were a sliver down on the year-ago $2.715bn while $318m net income fell 17.2 per cent. The company did not quite meet consensus analyst estimates of $2.72bn revenues but adjusted profit was $1.35 a share, beating the consensus $1.31 estimate.
It posted $480m cash flow from operations; it was $288m a year ago. Free cash flow a year ago was $161m; it’s now $286m.
CEO Dave Mosley said in a canned quote: “Seagate expanded non-GAAP operating margin by nearly 300 basis points and delivered non-GAAP EOS growth of more than 30 per cent Q-on-Q while driving strong operational cash flow in an improving demand environment.” He said Seagate had executed the company’s fastest-ever product ramp with its 16TB drive.
Western Digital is poised to deliver 18 and 20TB drives. Both companies will soon discover where the market’s sweet spot lies – either at the 16TB point (in Seagate’s favour) or higher capacity (with WD winning).
Seagate shipped 106.9EB of capacity overall, averaging 3.3TB/drive. A year ago it delivered 87.4EB with a 2.4TB/drive average.
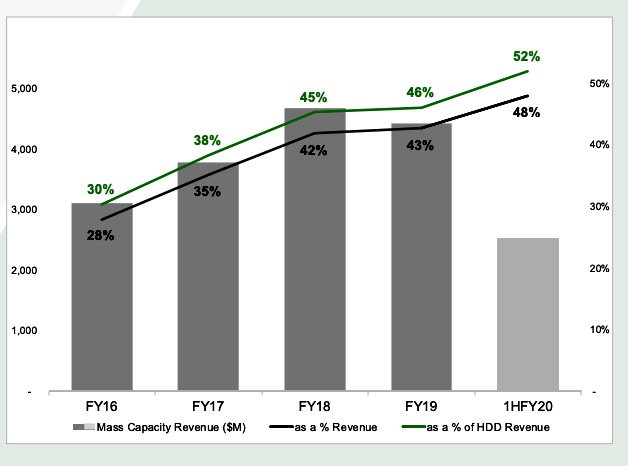
The company has changed its reporting to focus on mass capacity 3.5-inch and legacy 2.5-inch drives. It no longer providing segment revenue numbers for enterprise mission-critical, nearline, edge non-compute, edge compute, edge/client CE, consumer and desktop notebook category drives. So comparison on these counts with prior quarters comes to an end.
It is instead providing mass capacity drive growth trends by quarter and by year:
Seagate mass capacity drive numbers by quarterSeagate mass capacity drive number on an annual basis.
This way all the lines go up, whereas with the previous segmentation, many lines went down, as 2.5-inch drives were cannibalised by SSDs.
Seagate’s next quarter outlook is for revenues of $2.7bn plus or minus 7 per cent. At the mid-point that represents 16.7 per cent growth y-o-y.
Mosley said the company is “poised to benefit from ongoing demand for mass capacity storage which we expect to offset typical seasonal declines in the legacy (2.5-inch) markets in the first half of the calendar year.”
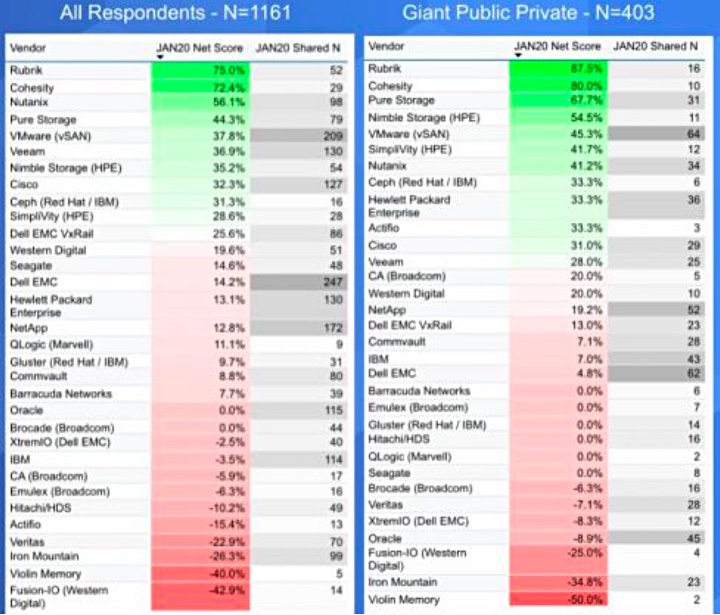
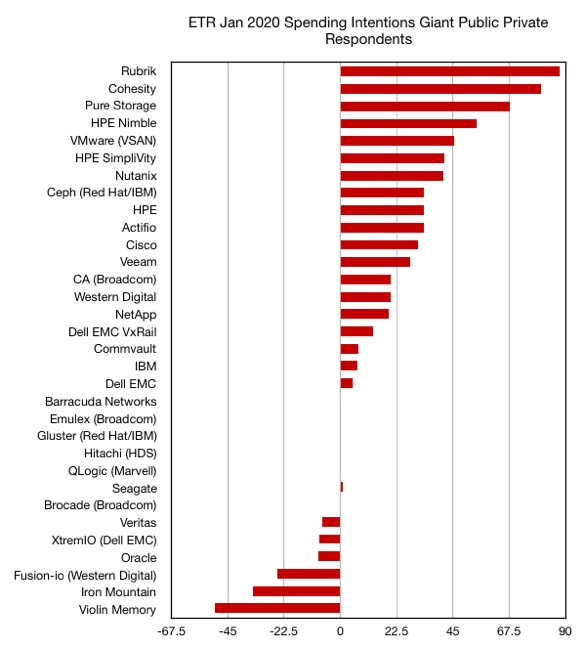
Wikibon’s Cube Insights has looked at large customer spending pattern forecasts in a Data Storage 2020: Icebergs Ahead report. Rubrik and Cohesity are looking good with Nutanix and Pure Storage not far behind. But Commvault, IBM, Hitachi (HDS), Veritas and Oracle are trailing.
ETR is a research and analyst agency looking at enterprise tech spending patterns on a monthly basis and producing net scores for vendors. Wikibon has pulled out scores for storage vendors for January, and also past months to check the trends.
Its chart below covers general ETR survey respondents on the left while the right-hand column is for larger organisations, what ETR calls Giant Public Private ones. ETR adds green and red colouring to indicate the most positive and least positive numbers, which are a measure of spending velocity, according to Wikibon. It says the GPP responses are a good indicator of real world spending patterns.
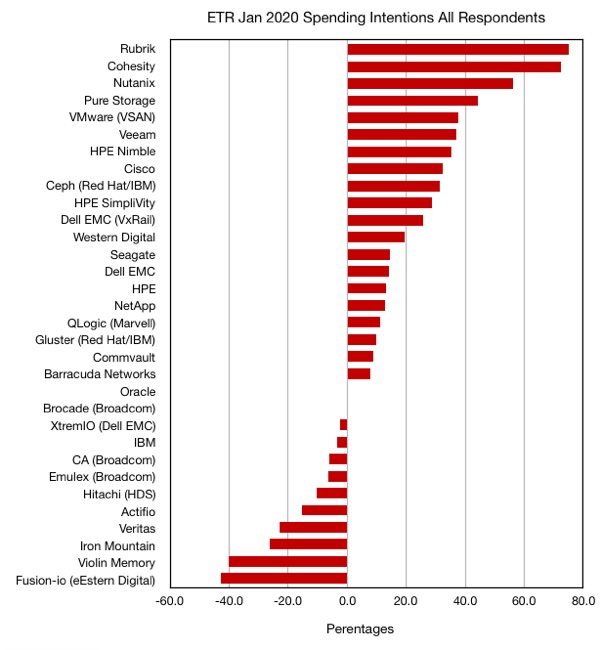
Looking at all IT buying respondents, 1,161 of them, Rubrik and Cohesity lead the chart with 75 and 72.4 per cent scores respectively. They are followed by Nutanix (56.1 per cent), Pure Storage at 44.3 per cent and VMware (VSAN) at 37.8 per cent. Veeam, Nimble, and Cisco follow behind.
Veritas, XtremIO, Oracle and others are in increasingly negative territory. The table above, screen-grabbed from the Wikibon report, is hard to read. We pored over it and charted the numbers to make it easier and faster to understand – the all respondents table first:
Next is the chart of Giant Public Private respondents:
One thing that jumps out is how much improved Actifio’s rating is, with a -15.1 per cent score for all respondents, but a 33.3 per cent rating on the GPP chart. Actifio does have a large enterprise focus. Oddly, Delphix is not listed by ETR and we would expect it to have a rating similar to that of Actifio. HPE has a similar pattern to Actifio, but not as extreme, being 13.1 per cent in the general chart and 33.3 per cent in the GPP chart.
Another realisation is that the spending force is with secondary storage management and then HCI. Classic primary storage arrays don’t feature well at all, particularly Dell EMC’s XtremIO. IBM is not doing so well either although NetApp is doing better.
Two backup/data protection suppliers have lowly ratings in both charts; Commvault and Veritas.
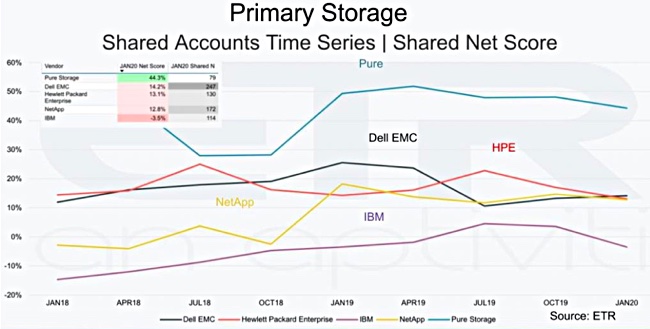
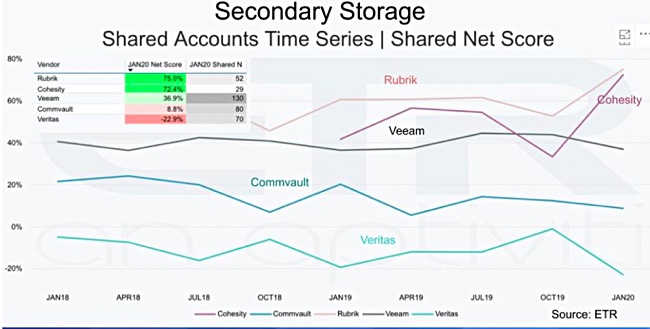
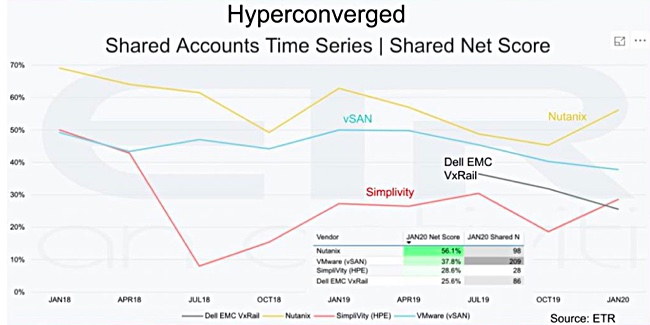
The Wikibon report then looked at the trends for selected primary, secondary and hyperconverged storage vendors.
In primary storage, Pure has maintained a stand-out lead over Dell EMC, HPE and NetApp, who are all ahead of lowly IBM. A secondary storage trends chart confirms Cohesity and Rubrik’s lead, with Veeam third and Commvault languishing, but ahead of poor, and downward-bound, Veritas.
The hyperconverged vendor trends chart shows Nutanix as a clear spending focus favourite, with vSAN second. Dell EMC VxRail was in third place but has dropped down to be overtaken by a resurgent HPE SimpliVity.
We’ll have to keep an eye on coming IDC and Gartner vendor market share numbers to see if these spending intention numbers are reflected accurately.
There’s more information in the Wikibon – Data Storage 2020: Icebergs Ahead – article. For example, it suggests that Rubrik and Cohesity could be gaining escape velocity and becoming self-sustaining (almost) companies like Nutanix and Pure Storage.
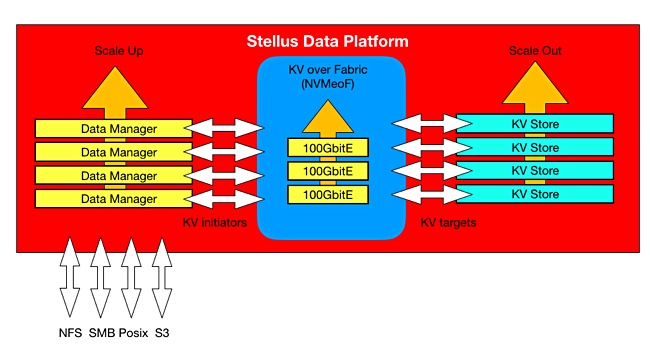
Newly emerged Stellus Technologies has developed a new and different high-performance data storage and processing system involving arrays of compute-in-storage SSDs providing real-time access across a key:value over NVMe fabric to hundreds of terabytes of unstructured data.
The firm said its Data Platform is a scale-up and out system. Scaling up can increase capacity while scaling out adds additional storage server devices, meaning more throughput. Scaling both at the same time is called scaling through by Stellus.
A Stellus system, a software-defined, commodity off-the-shelf hardware storage system, can reach a guaranteed 80GB/sec on both reads and writes with near parity of read and write performance, and a latency not exceeding 500μs.
The company’s plan is to address those parts of the market that need such a high-performance file-based storage and processing system, because there is a data-generating explosion happening and legacy file systems can’t keep up. They were developed when files were stored on disk, not flash, and file populations much smaller.
Stellus technology framework
Stellus said its memory-native file system uses SSDs to hold key:value stores. Its technology includes:
M.2 SSDs,
Memory-Native File System built on many key:value stores,
Global namespace,
NVMe-over Fabrics is used to provide key:value over fabrics (KVoF) access
Algorithmic data locality with Stellus claiming its memory-native architecture removes performance limitations of global maps at scale,
Stellus File system runs on-premises or in the cloud with no reliance on custom hardware and kernels,
Multi-tenancy,
Cloud connectivity,
Security features,
Erasure coding.
KV stores
A key is number or string. In the Stellus product it is converted to a hash value which maps to a storage address where the value is stored.
The value can be a string or a structured object; a list, a JSON object, an XML description, or something else, even keys to other values,
Key-value stores use get, put, and delete IO operations; object storage operations. Stellus SVP and chief revenue officer Ken Grohe writes that a KV store is a database containing KV pairs. The key identifies the value and the value is stored as a Binary Large Object (BLOB).
Any existing filer basically takes in files, breaks them up into chunks (if they’re big), and stores the chunks across a range of blocks in SSDs or disks. The fast ones all use flash for fast access now. The filer controller keeps a map that indexes logical file data to physical SSD block data.
Stellus inserts a KV store layer between the logical file data and the SSD blocks. It is betting its scale-out farm that this results in faster access to hundreds of terabytes of file data than the traditional filer controller-drive shelf method. ESG testing and pre-release customer evaluations have shown that it is faster than legacy filer systems.
Data locality is worked out using algorithms rather than having a global map across the cluster. This removes the need to keep the clustered nodes consistently synchronised with such a map, saving CPU and DRAM resources. Such synchronisation becomes more and more difficult as the number of nodes increases.
The Stellus software runs in user space and needs no Linux kernel hacking/customisation or customised hardware.
Accelerated performance
The firm’s proposition is that key-value stores replace traditional block storage for unstructured data. They remove the need for complex global maps and caching and deliver consistently fast performance. Stellus is betting its scale-out farm that this results in faster access to hundreds of terabytes of file data than the traditional filer controller-drive shelf method. ESG testing and pre-release customer evaluations have shown that it is faster Han legacy filer systems.
A Stellus spokesperson said: “We can provide really great performance with variable size objects with no need for things like multi-level caches.” The company talks of an up to 800 per cent performance boost compared to existing systems, which we understand to mean Isilon systems using capacity nodes.
Hardware
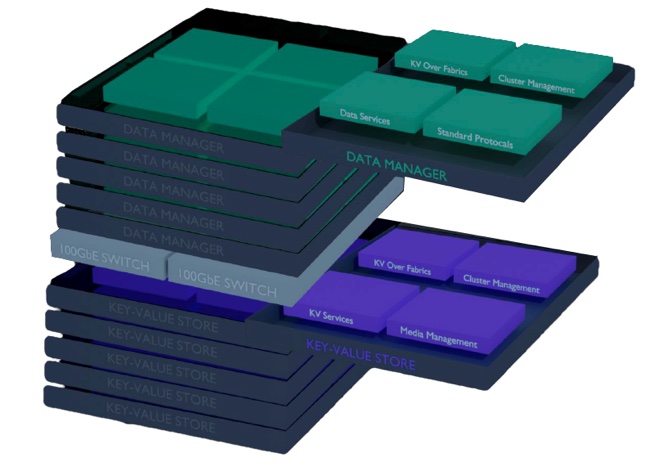
The first Stellus Data Platform systems, the 220, 420, 440, and 880, are distributed, share-everything clusters, with two types of node; Data Managers and KV Stores, plus 100Gbit/s Ethernet switching interconnecting them.
Stellus lab kit. The lower 4 x 2U shelves are servers that simulate workflows to access the upper 6 x 1U Stellus nodes
Data Manager nodes are 1U in size, stateless and form a protocol layer. They are rack enclosures, each with four components:
Data Services,
Standard Protocols,
KV over Fabrics (KVoF),
Cluster Manager.
Key Value Store (KV stores) nodes, also 1U rack enclosure with M.2 format SSDs inside, again have four functional components;
KV services,
Media Management,
Cluster Management,
KVoF.
Each Data Manager can see each KV store. There can be up to 4 KV stores per SSD and up to 32 x M.2 8TB hot-swap SSDs in a node, which provides, Stellus says, massive parallelism, taking advantage of NVMe queues.
Blocks & Files-created Stellus system diagram.
The base 220 system is 5U in size with 2 x Data Managers and 2 x KV stores 924 x 8TB M.2 drives) plus Ethernet switch. It has 184TB of raw capacity. The 420 has 4 x Data Managers and offers184TB raw. A 440 has 4 x Data Managers and 4 x KV Stores (369TB). An 880 has eight of each node type and 1.475PB of raw capacity in its 17U of rack space.
The largest 420 is 17U in size with 8 x Data Manager nodes and 8 x KV Store nodes plus a 100GbitE 1U switching shelf. It has 1.475PB of capacity.
Stellus provides a cloud-based management facility and its SW can run in the cloud, providing a hybrid on-premises-public cloud workspace.
This is a software-defined system and it is not tied to any branded hardware instantiation. Over time Stellus will provide a hardware compatibility list (HCL). It also supports U2 format drives.
Stellus Data Platform diagram.
We can relate this set-up to a standard dual-controller array by likening the Stellus Data Platform to a multi-controller (scale-up Data Managers) array with scale-out capacity shelves (nodes – KV stores) accessed across an internal NVMe fabric.
The data services include data placement, protection (snapshotting), erasure coding and the initiator side of the KVoF. The standard external access protocols are POSIX, NFS 3 and 4, SMB, S3 and streaming protocols.
This standard protocol support should make it straightforward for Stellus kit to fit into customers’ existing workflows.
Drive development
Stellus said the data path uses standard hot-swap M.2 SSDs today, and is ready for new drive types, meaning key:value SSDs and then Ethernet-connected KV-SSDs
A Grohe blog states: “Samsung … has developed an open standard prototype key-value SSD and is working to help productize it. A key-value SSD implements an object-like storage scheme on the drive instead of reading and writing data blocks as requested by a host server or storage array controller. In effect, the drive has an Object Translation Layer, which converts between object key-value pairs and the native blocks of the SS
What this means is the KV Stores will be able to move intelligence down to the component drives. It is our understanding that Samsung, and possibly other SDD suppliers, are sampling or about to sample KV SSDs.
We could envisage a future iteration of the Stellus product with tiers of solid state drives. For example, storage-class memory, fast SSD, medium speed SSD, capacity SSD. Particular virtual KV stores could be optimised for, and placed on, specific types of drive to use them optimally.
ESG performance validation
ESG has validated the Stellus system’s performance, with a report stating: “We started up 32 simultaneous uncompressed 4K video streams. … the video was playing smoothly on all clients without stutter, jitter, or dropped frames. The playback rate was 34.6GB/sec from a 420 system comprising 4 x Data Managers and 2 x KV Stores plus Ethernet switch.
A 420 system supported 45GB/sec reads to a single client with multiple threads running (FIO benchmark.) A 440 system (4 x Data Managers + 4 x KV Stores) supported 41.3GB/sec writes to the same client with a 100 per cent write workload. ESG said: “Both the read and write performance in this test exceeded Stellus’ guidance for performance of the SDP-420 and 440 which is 40GB/sec.”
ESG said: “Response time across all tests never exceeded 500μs,” and: “Delivering 41.3GB/sec write and 45.1GB/sec read throughput [is] the fastest we have ever seen for a file storage system.”
Application examples
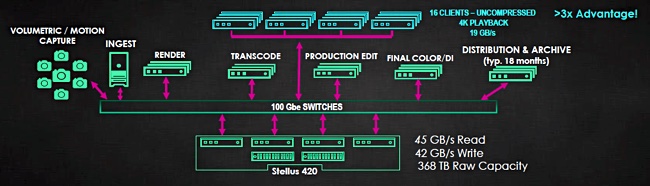
A Stellus diagram shows a 420 system supporting an entertainment and media environment, covering all stages from initial motion-capture and camera ingest through to distribution and archive:
A customer could be working on multiple projects at once, with the Stellus system receiving IO requests from each stage in the workflow across the projects at the same time.
A Stellus spokesperson said Isilon can support typically 4 x concurrent 4k streams. Grohe said: “We aim to do to Isilon what Isilon did to NetApp.”
Stellus CEO Jeff Treuhaft.
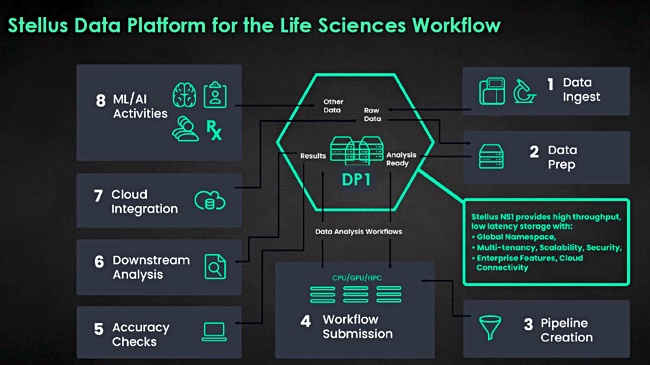
A life sciences environment and workflow uses a Stellus system covering workflow stages from data ingest, data preparation, pipeline creation, workflow submission, accuracy checks, downstream analysis, cloud integration and AI/ML activities.
Stellus said its system can sequence 150 to 500 genomes/day. It said Isilon-based systems can sequence up to150 genomes a day, giving it a claimed better than 3x advantage over the Dell EMC system.
Stellus factfile
Stellus is a Samsung arm’s-length subsidiary based in San Jose. It was initiated in 2015 with Samsung viewing it as an internal startup, and providing funding; we don’t know how much. Its CEO is Jeff Treuhaft, ex-Fusion-io where he was an EVP for products. The thinking was that Samsung couldn’t develop such a HW/SW flash array system inside itself; a fabrication business focused on manufacturing millions of smallish devices/month, meaning DRAM and NAND chips and SSDs.
So it funded Stellus Technologies as a separate company with its own board. There are some 90 employees, mostly in California, and it has been careful to stay in stealth mode since 2015. Some 17 patent applications have been made. Technology eco-system partners include Nvidia (GPUs) and Arista (network switches). Several very large companies have been looking at and evaluating the product: Apple, Disney, DreamWorks, the Federal Government, Optum, and Technicolor.
Ex-Sun boss Scott McNealy is on the board as is ex-NetApp CTO Jay Kidd.
Blocks & Files view
As one NAND chip and SSD manufacturer Western Digital exits the data storage array business having failed to achieve a successful outcome, Samsung, via Stellus, is trying to enter it. And instead of building a general-purpose fast-action filer, it’s building one specifically for use in the complex unstructured data workflows that are found in entertainment and media, life sciences and the like.
It is not looking at Big Data analytics nor at general high-performance computing (HPC).
Stellus is taking on the usual fast filer suspects – Isilon, NetApp, Quantum (StorNext), Qumulo and WekaIO, and also Excelero plus IBM GPFS systems, and ones using Intel DAOS to the extent that they are used in the target markets. It is clearly going to need a channel of vertical market-aware partners and all of the potential partners will already be selling the competing suppliers’ kit. Channel recruitment will be an important activity.
To make progress, the Stellus hot box product has to be significantly faster and more cost-efficient than the competition, which all use flash too, and as reliable. The performance and efficiency of the KV stores will be … key.
Chief Revenue Officer Ken Grohe and his team have a real job of work to do now, in establishing a new product, new technology and new vendor in a hotly-contested market. Turning Stellus into a sales star is a big ask.
Developer of container-attached storage for Kubernetes MayaData has been given access to DataCore technology while DataCore gets a piece of MayaData’s action, in a funding-related dance valued at $26m.
Evan Powell, co-founder of MayaData and CEO, said: “We are very excited to be working with DataCore and Insight Partners to deliver data agility to users worldwide. In addition to further investments in OpenEBS and the broader CNCF ecosystem, this transaction allows us to take a huge leap forward in serving enterprises, service providers and governments world-wide.”
The $26m comes from AME Cloud Ventures, DataCore Software, and venture capital and private equity firm Insight Partners.
MayaData funding background
The startup gets a $26m boost almost 7 years after its former incarnation, Cloudbyte, took in a $4m B-round. There was a CEO change in 2017 as ex-Nexenta CEO Evan Powell came in and relaunched the company as open source software-focused MayaData in 2018. He also announced a deal with IBM for MayaData’s OpenEBS product.
This made OpenEBS storage available to IBM Cloud Private users. OpenEBS (Open Elastic Block Storage) is open-source, container-attached native storage software delivering block storage to containers. It uses Kubernetes as its underlying framework for scheduling and storing configuration data.
MayaData says its software and services turn Kubernetes itself into a data layer. It claims this boosts the productivity of small teams building data centric applications and frees them from the risks and costs of data and cloud lock-in.
Another piece of the background it’s necessary to appreciate is that VC and private equity business Insight Partners has an existing investment in DataCore – $30m dating from 2008.
Deal details
The $26m is part of a package which contains:
Insight Partners and AME Cloud Venture investing in MayaData,
DataCore:
Investing in MayaData and owning a piece of it,
Joining forces with MayaData to go after the container-native storage market.
Transferring some IP and couple of engineers who were working on container storage to MayaData,
Cross-licensing technology agreement:
MayaData will have access to DataCore’s CDP (continuous data protection) to implement it in the container space, plus advanced mirroring and performance optimizations,
DataCore has access to technology MayaData produces for future product development.
DataCore will continue to pursue the IT Ops container market, as both its SANSymphony and vFilO offerings have CSI plug-ins. Gerardo Dada, DataCore’s CMO, said: “We want to focus on the ITOps market and let MayaData focus on the Kubernetes/DevOps market, which is very different.”
For MayaData this means it gets funding, technology, and expertise. The OpenEBS product will strengthen its position as, MayaData claims, the most widely used and most powerful container storage platform with the addition of these additional resources. It says weekly OpenEBS downloads as measured by container pulls increased by more than 500 per cent during 2019. Customers include companies such as Bloomberg.
A side piece of news is that Don Duet, former CIO of Goldman Sachs and Jay Kidd, former CTO of NetApp and Brocade Communications, have joined the company’s advisory board that also includes Frank Slootman, CEO of Snowflake and former CEO of ServiceNow and DataDomain.
Net:net
Evan Powell told us that MayaData: “will be emphasizing that DataCore has a built out 100 per cent channel approach that would have taken us years to build; conversely, we have a self adoption model, where OpenEBS is downloaded by Kubernetes teams and then some of them become customers. We at MayaData focus on the open source and self-adoption model and DataCore focuses on their reach via the channel.”
Ah, now we get it. MayaData gets DataCore as a reseller through its channel plus a technology contributor. DataCore gets to resell OpenEBS-based container storage alongside its other products, which have CSI plug-ins. And Insight Partners should see these two of its portfolio companies increase in value as the Kubernetes and containerisation waves flood across the enterprise IT development environment.
What a week for Quantum. It made its first quarterly profit in more than four years. It qualified to get listed on Nasdaq and now it is buying Western Digital’s unwanted ActiveScale archiving business.
Jamie Lerner, Quantum president and CEO, said of the acquisition: “Object storage software is an obvious fit with our strategy… and within our technology portfolio.”
He also said: “As Quantum returns to a growth path, we will be evaluating strategic acquisitions that bolster our technology portfolio.”
ActiveScale history lesson
ActiveScale was put on the For Sale block in September 2019 when WD sold its IntelliFlash business to DDN and said it was getting out of the data centre systems business.
WD acquired fellow disk drive manufacturer HGST in 2012. HGST then bought object storage supplier Amplidata in 2015 and started selling its ActiveArchive product. This evolved into ActiveScale in late 2016.
It was the second of two product pillars in WD’s Data Centre systems business.
For its part Quantum introduced its Lattus object storage products in 2015, and they were based on Amplidata technology. It also introduced Arkivio archiving software in 2015 and that could send files to Lattus as an archive store target.
Quantum, through Lattus, has sold and supported the ActiveScale product line for over five years. Now it has acquired the source technology behind Lattus.
WD’s Phil Bullinger, the SVP and GM of its now smaller Data Center business, said: “With Quantum’s resources, technical expertise and focus on solving customers’ challenges with managing video and other unstructured data, we believe ActiveScale will enable new value for customers.”
We might imagine he gave a sigh of relief at the conclusion of this sale and completion of WD’s data centre systems’ business exit. Time to move on.
Lerner said: “With the addition of the engineers and scientists that developed the [ActiveScale] erasure-coded object store software, we can deliver on a robust technical roadmap, including new solutions like an object store built on a combination of disk and tape.”
Quantum will provide post-closing continued support for ActiveScale products and a strong commitment to invest in – and enhance – the ActiveScale product line. That should reassure ActiveScale customers.
The transaction is expected to close by March 31, 2020, subject to customary closing conditions. Financial terms were not disclosed.
You thought you understood Cohesity well enough. It supplies hyperconverged secondary storage. It is basically ‘doing a Nutanix’ on the secondary storage market and converging the file use cases for test and dev, compliance and other copy data users. The San Jose firm makes a golden master copy of a file and farms out virtual copies of it for temporary use, saving storage space.
Only it doesn’t just do this. It provides a backup appliance. It tiers to the cloud. It provides file storage. It archives data. It can do disaster recovery. It can migrate data as well. So what is Cohesity in product positioning terms?
Sectarian
That’s a tough question to answer, in that it doesn’t fit in the standard product boxes. There are three main boxes to consider here: file storage, backup, and data management. We can easily populate these boxes with suppliers because that’s mostly how they define themselves; by product fit to a market sector. A diagram shows what we mean:
Blocks & Files created Cohesity positioning graphic.
Certain companies and products are known for file storage – Isilon, NetApp and Qumulo, for example.
Certain companies are known for backup, masses of them in fact, starting with Acronis and Asigra and running through the alphabet to Veeam and Veritas.
Other companies are known for copy data management, such as Actifio, Cohesity itself, and Delphix.
Some suppliers are known for file life cycle management, such as Komprise and file access acceleration, such as InfiniteIO.
Scale-out
Where Cohesity fits, according to Michael Letschin, its director for Technology Advocacy, who briefed us, is in all three boxes. As we understand it, Cohesity’s technology is based on a Span File System, which is a highly scale-out filesystem with some unique properties. For example, it can receive and present files using NFS, SMB and S3 protocols at the same time.
Cohesity’s software runs in scale-out clusters which are managed, in single or multiple geos, by the Helios SaaS facility.
Its generalised file data processing platform receives data from a variety of sources, does things with them, and makes them available to a variety of target use cases.
As a file store, Letschin said, it cannot do tier 0 file access work; it’s not equipped for that low latency, high speed access activity. NetApp and Isilon and Qumulo can rest easy in that use case. But Cohesity can do the tier 1, tier 2, and 3 work – what we can call the secondary file data or unstructured data world. And here, because of the breadth of its coverage, the firm could potentially reign supreme.
Data sources and targets
Backup is a way to get data onto its platform, an on-ramp, an ingest method. It built an appliance to do that, but is now switching to a software-only product available through subscription. This can run on-premises or in the public cloud. Cohesity can back up applications in physical servers and in virtual servers (vSphere, Hyper-V Acropolis). It can back up relational and distributed databases via its Imanis acquisition. It can back up Kubernetes-orchestrated containerised systems.
The product can be a target system for backup products, such as Veeam. It can write backup data out to archives in the public cloud (AWS, Azure, GCP) and also to tape via a Qstar gateway. The archive data can be written in an immutable form (Write once: read many or WORM).
It can tier file data to the cloud, leaving a reference access stub behind, and so save space on primary (tier 0-class) filers. And it can supply data to Test and Dev, with personally identifiable information detected and masked out. It can move backed-up VMs to the cloud ready to spin up if a disaster happens (CloudSpin) and even run them on the Cohesity cluster as a stop-gap.
Third-parties have built applications that use Cohesity’s software to do extra things, such as the Clam AV anti-virus product and the firm’s own Splunk facility for small log file populations.
Customers can download these from the Cohesity Marketplace, running on Cohesity’s distributed infrastructure and using the Cohesity App SDK to access the data managed by the Cohesity DataPlatform. They have to buy the licence from the vendor or partner directly.
Mostly all its functions are policy-driven and set up through a clean UI.
It seems that a lot of what a customer might want to do with secondary file and unstructured data can be done with Cohesity’s software. (We’re using secondary data to mean non-tier 0 data.)
This is why trying to position Cohesity in a single standard file storage activity-related box is like nailing jelly to a wall. All of which, its execs must be hoping, makes for remarkably sticky software.
In Internet of Things terms, an autonomous or near-autonomous vehicle (AV, NAV) is a mobile edge computing device that generates data needing to be processed for it to make its way across a network of roads. How much data? No one knows.
It’s the wild west in development terms and experts differ over how much data will be generated and stored each day, with up 450TB mentioned.
Blocks & Files has previously discussed the autonomous and near-autonomous vehicle (AV, NAV) storage topic, and also asked John Hayes, the CEO of Ghost Automotive, about it in order to get a broad look at the subject. Now we’re going to take a deeper dive, via an email interview with three industry aces.
B&F talked to Christian Renaud, an analyst at 451 Research; Robert Bielby, senior director of Automotive System Architecture at memory-maker Micron; and Thaddeus Fortenberry, who spent four years at Tesla working on Autopilot architecture. He left in September 2019 and is talking to a number of AV companies.
Left to right: Christian Renaud, Robert Bielby, Thaddeus Fortenberry.
We’ll note quickly that the test phase of AV development will generate more data than the operational phase. We’re concerned here with the operational phase unless specifically saying otherwise.
Also we point out there is going to be a difference in data generation between consumer-owned AVs and robo-taxi/ride-share. With the latter they will be operational for more hours each day and the operator will want more and different data from the vehicle than the average consumer who owns one.
Blocks & Files: How much data will near-autonomous and autonomous vehicles (AV) generate per day?
Christian Renaud, 451: This depends on a number of factors and there is no one (accurate) answer. If you assume all systems (DCUs, ECUs, multiple LIDARs, multiple long and short range radar, multiple ultrasonics, multiple cameras), operating for a typical consumer two hour duty cycle per day (so, excluding ride share drivers that may drive 10-12 hours a day), then you’re in the neighbourhood of 12-15TB/day generated by all the sensors, and then by the ISP/VSPs, V2X (Vehicle to Everything network links) systems, and the cellular vehicle connectivity gateway. Seventy-eight per cent of OEMs plan to have between 50-70 per cent of all that data analysed locally (on car) versus being sent off vehicle.
Robert Bielby, Micron: Let’s just start by saying it’s a lot! Though there is going to be quite a bit of variability to that number. First, it depends if you’re looking at a robo-taxi or a passenger car that has self-driving capabilities. The use profile of a robo-taxi is expected to be as close to 24 hours use as possible, where, if you were to look at the average use of a vehicle in the US, it’s estimated to be around 17,600 minutes a year, or on average about 48 minutes per day.
The next variable to consider is the sensors’ types and the number of those sensors that are employed to realize self-driving capabilities. High resolution cameras typically produce very large amounts of data 500 – 11,500 Mbit/s whereas LIDAR produces data streams ranging from 20 – 100 Mbit/s. Today’s autonomous vehicles have a wide range of mix and number of sensor types and associated resolutions of those sensors. It’s not impractical to see a self-driving car employing 6 – 21 cameras – which means lots of data! When you do the math, you find data rates that range from 3 Gbit/s (~1.4TB/h) to 40 Gbit/s (~18 TB/h). Implying that for the average self-driving car you are looking at about 1 – 15 TB data per day (for US) whereas for robo-taxi this number can get as high as 450 TB data per day.
Thaddeus Fortenberry, ex-Tesla: My near-term estimate is ~1.6TB per car per day – without Lidar. Intel did a good analysis and project 3-4TB per car per day. We will likely see this wildly change in the next few years. Innovation is required in data optimization and connectivity choices.
Sending data to the cloud
Blocks & Files; Will this data be transmitted to the cloud for decision-making and analysis? Will the AV be completely self-sufficient and make its own decisions , or will there be a balance between the two approaches?
Christian Renaud, 451: There are control-loop decisions (Advanced Emergency Braking) that are local functions using radar. There are other functions, such as model training (like Tesla does with Autopilot) and V2X that are, by nature, multi-body problems and therefore have to go off-vehicle. If this is ‘cloud’ per se, or network operator infrastructure like multi-access edge computing for V2X (which has a 4ms response time requirement, so it’s not going to any clouds), depends on the specific workload. Navigation data is less latency sensitive, V2X being the other extreme.
Short answer, it will be a mix, but cars already (with active ADAS) have to function independent of any connectivity for liability reasons. They’ll just function better when they do have connectivity just like your Waze or Google Nav does today. An implementation of this that is not critical to the driving function is the BMW on-street parking information where they use the ultrasonic sensors on BMWs to tell other BMW owners where there are open parking places. Distributed sensors, cloud function, not super latency sensitive.
Robert Bielby, Micron: There are two distinct phases to realize self-driving capabilities – there is the training phase and the inference phase. During the training phase, the vehicle is concerned with collecting as much data about the surroundings and the road as possible to be used to ultimately train the deep neural network algorithms to accurately detect objects such as pedestrians, street signs, lane markers and the overall operating environment of the vehicle.
During this phase, typically all sensor data is recorded and stored on large arrays of hard drives or SSDs for data capture. Based on the earlier discussion of data generation, the quantity of storage that is required can be significant. During this part of the training phase, training data is typically stored directly to [flash] memory – not sent to the cloud.
When the self-driving car is operating in the inference mode – once it has been successfully trained – the algorithms will continuously be monitoring the performance of the system for accuracy. As AI algorithms are ultimately non-deterministic, if the system encounters a situation or object that is has never seen before or doesn’t recognize, the results can be very unpredictable.
A well-designed system will deliberately introduce disparity into the system such that when a “new” situation or object has been encountered or detected, the system will recognize this, and the data associated with this disparity will typically be sent to the cloud for future algorithm improvements. Similarly, other details such as real time map updates – very low rate data sets on the order of Kbit/s are regularly transmitted to the cloud to ensure a map with the most up to date information is maintained and available to all self-driving vehicles.
Thaddeus Fortenberry, ex-Tesla: Definitely a combination. The vehicle must be able to function without requiring connectivity, but the vision of ‘fleet learning’ to rapidly assimilate and publish information for more accurate driving requires effective ingest, back-end collaboration and processing and effective publishing. It all requires a managed environment respecting policy and optimizations.
Blocks & Files: Will the AV IT system be a centralised one with sensors and component systems networked to a single central compute/storage and networking resource or will it be a distributed one with a set of separate systems each with their own processor, memory, etc? Ie. navigation, braking, suspension, engine management, etc.
Christian Renaud, 451: There are ECUs and DCUs, and then GPUs (as well as a variety of embedded compute in sensors, a number of image and video signal processors, etc.). Each perform different functions. The ECU that controls, say, your electric window system on the driver door isn’t a target for consolidation into a GPU that is also doing sensor fusion for ADAS/AV.
Now the AV-specific function, which is a combination of inputs (LIDAR, radar, ultrasonics, cameras, accelerometers, GPS), sensor fusion, path planning, and outputs (robotic actuation) will be a combination of GPUs and ECUs. Some people think a single GPU will do the job (NVIDIA Jetson) and others think it’s a combo of xPUs (Intel Mobileye).
Robert Bielby, Micron: There is no one right school of thought on the approach – each has their own pros and cons and I expect you will see both architectures co-exist in the market. While there have been arguments made that fully centralized architectures, where all processing occurs at a centralized location leads to a robust architecture that can deliver self-driving capabilities at the most competitive price, these architectures can typically be challenged in the area of thermal management.
Arguments have also been made that this architecture may not be as robust as a distributed architecture – where smart sensors with edge-based processing offer greater resiliency by virtue of the fact that the computation is indeed distributed.
While distributing the computing across the system can provide some relief in thermal management vs. a centralized architecture, close attention needs to be paid to local thermal management associated with close proximity processing in smart cameras due to detrimental effects on image sensor linearity and response associated with heat.
Again, no one “best” solution – each represents a different set of tradeoffs and the choice is typically dependent upon the overall objectives of the platform.
Thaddeus Fortenberry, ex-Tesla: The direction I see most automotive companies going is to have components systems with volatile memory/storage where the data is moved and processed on the central ADAS computer. A key point is the level of RAW-ness of the data coming from the micro-controllers and/or sensors. Companies like Tesla want direct sensor data, whereas more traditional companies ask the ODM to give them processed data.
Again, I think we will see a lot of innovation here. Nvidia and Intel are creating solutions for Tier-2 car companies. They will be interested in creating whole vehicle systems incorporating all aspects of relevant data. The Tier-1 vehicle companies must decide where they will directly innovate and who (and how) they will partner with for sensors.
Blocks & Files summary
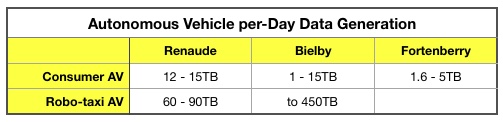
We can already see that there are great differences between our three experts in terms of data generation amounts per day. A table illustrates this:
Renaude and Bielby can see a consumer-owned AV generating up to 15TB/day while Fortenberry reckons 5TB a day as an upper limit. The robo-taxi data generation shoots up though, to a maximum of 450TB, half a petabyte near enough.
They are unanimous in thinking that only long reaction time reference data will be sent to the cloud for processing and storage by a car fleet operator or manufacturer. How much data this amounts to is unknown.
They also tend to favour a hybrid style of AV IT, with a central computer set-up allied to distributed subsystems. The degree of distribution will be limited in Bielby’s view by thermal management issues and by ODM/car manufacturer differences in Fortenberry’s view. Renaude thinks the centralised system could be GPU-centric or a mix of different processor types. A clear picture has not yet emerged.
We’ll soon be taking a look at how the AV data might be stored in the AV and transmitted to the cloud in a follow-up article. Stay tuned.
Western Digital reported flat results for its second fiscal quarter ended January 3, 2020 today, with a small uptick in data centre segment and a large dip in flash sales.
Revenues were $4.234bn, compared to $4.233bn 12 months previously, and it reported a loss of $139m, down from a $487m loss a year ago.
CEO Steve Milligan said: “The December quarter results reflect strong execution in our product roadmap, success in increasing our hard drive gross margin, and an improving flash market. We expect an accelerated recovery in our flash gross margins, which coupled with ongoing strength in demand for both hard drives and flash, positions us well for continued profitable growth in calendar year 2020.”
WD generated $257m cash from operations, and ended the quarter with $3.1bn of total cash and cash equivalents. Free cash flow was $97m, compared to the $21m reported a year ago.
Its three component businesses reported revenues of:
Data Centre Devices and Solutions – $1.49bn compared to $1.07bn a year ago,
Client Solutions – $948m compared to $945m a year ago,
Client Devices – $1.8bn compared to $2.2bn 12 months prior.
Disk
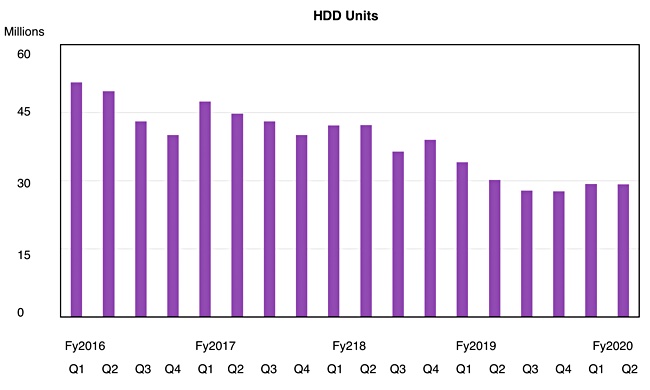
WD shipped 29.2 million disk drives, slightly less than the year-ago 30.2 million, but disk revenues of $2.4bn were higher than the $2.1bn recorded. That’s because HDD capacity shipped at about 119EB was up 56 per cent y/y.
A chart shows a levelling out after a prolonged disk drive unit ship reduction trend:
Enterprises and hyperscalers want more and more enterprise capacity drives; that’s where the unit ship growth is to be found.
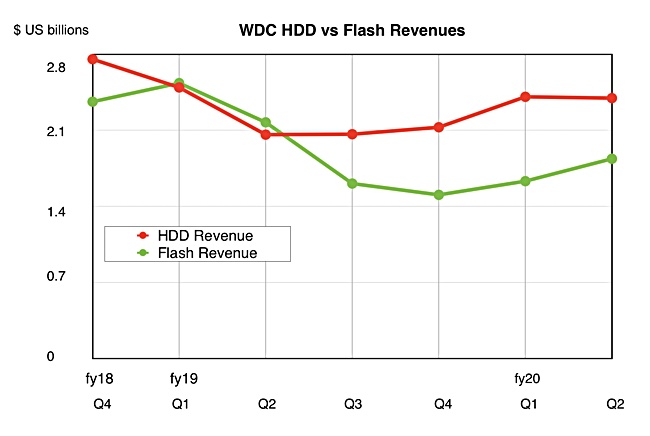
Flash
Flash revenues of $1.4bn were well down on last year’s $2.2bn; that’s due to lowered NAND prices from a supply glut which is now winding down. COO Mike Cordano said: “Inventory in the flash supply chain has returned to normal levels.”
Milligan said: “Demand is going to exceed supply this year. … Prices are improving. Right now that tightness is it’s kind of in pockets. It’s not necessarily across the board. So we’re seeing pockets of tightness in the market and as we move through the balance of the year, we expect that that tightness will increase.“
Both points indicate an end to the NAND glut.
Back to the flash revenue decline. CFO Bob Eulau pointed out: “On a sequential basis growth in enterprise SSD was offset by a decline in capacity enterprise drive and the impact of our exit from the storage-system business.”
NVMe SSD revenue rose more than 50 per cent quarter on quarter, as hyperscalers and OEMs adopted the products.
Aaron Rakers, a senior Wells Fargo analyst, told his subscribers that WD expects to see a 2x increase in its enterprise SSD revenue in calendar 2020, with a 20 per cent market share position target.
WD expects an accelerated recovery in its flash gross margins in the fist half of 2020 with more improvement in the second half.
Comparing HDD and SSD revenues in a chart shows a slight trend for flash to be catching up with spinning rust:
COO Mike Cordano said: “Starting in the June quarter, we expect to begin shipments into a new gaming platform. The gaming console market is expected to be a multi-exabyte opportunity this calendar year.”
We think this refers to Sony’s PlayStation 5 and WD could see a flash revenue bump if gamers take to Sony’s new console.
WD’s outlook for the next quarter is for revenues between $4.1bn and $4.3bn. At the $4.2bn mid-point that represents 14.3 per cent annual growth.
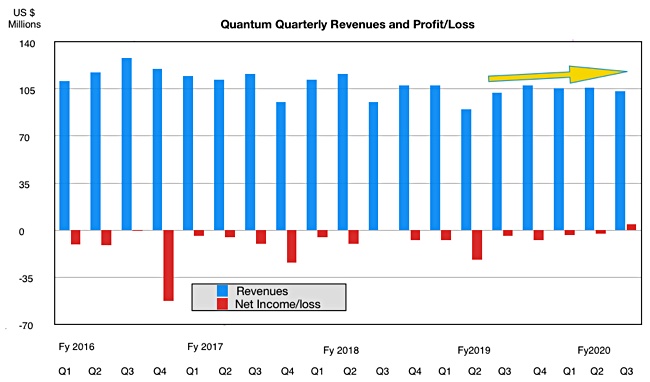
As well as becoming a listed company again, Quantum has made its first profit in 18 quarters; that’s four-and-a-half years.
Revenues in its third fiscal 2020 quarter were $103.3m, up just 1 per cent on a year ago. But profits were $4.7m, compared to a year-ago loss of $4.3m.
CEO Jamie Lerner emitted this quote: “This return to profitability validates the success of our transformation and provides us momentum as we uplist to the Nasdaq.”
The revenue was lower than expected, due to a tape library sales miss in its hyperscalar business, as a large order or orders were delayed.
Lerner said: “The long-term business opportunity in the archive tape storage market remains significant, so while we expect our hyperscaler business in the short term to continue to be volatile, longer term we anticipate adding new hyperscaler customers, which will help address non-linear purchasing patterns from a concentrated customer base.”
Because of this Quantum has lowered its full year guidance to $410m from around $430m. Lerner also said: “Our offerings in the video and video-like data portion of our business remained strong, and we continue to see growing demand … Our focus is to increase the contribution from these products, which maintain a better margin profile, which should mitigate the timing of hyperscaler revenue over time.”
Gross profit in the third quarter of fiscal 2020 was $47.1m or 45.6 per cent gross margin, compared to $43.1m, or 42.2 per cent gross margin, in the year ago quarter.
Selling, general and administrative expenses declined 15 per cent to $26.1m compared to $30.5m 12 months before. Research and development expenses were $9.3m, up 18 per cent compared to $7.9m a year ago.
There was cash and cash equivalents of $7.5m at quarter end compared to $10.8m as of March 31, 2019.
Quantum expects revenues of $95m plus or minus $5m in its fourth quarter. Can it squeeze a profit out of that? We’ll see.
Western Digital and Kioxia have crossed the 3-digit layer count barrier, announcing 112-layer 3D NAND, with early shipping dates pegged at Q4 2020.
Their BiCS5 generation and succeeds their 96-layer BiCS4 technology. BiCS stands for Bit Cost Scaling and refers to the lower cost/bit with each succeeding generation. BiCS5 technology will be used to build TLC (3bits/cell) and QLC (4bits/cell) NAND. Dies will be available in a range of capacities, including 512Gb (64GB and TLC), 1Tb (128GB and TLC) and 1.33Tb (1,000,000,000,000 bits and QLC).
The layer count increase, from 96 to 112, means 16 per cent more capacity on that count alone. But WD says second-generation multi-tier memory hole technology, improved engineering processes and other cell enhancements increase BiCS5’s cell array density horizontally across the wafer. That results in up to 40 per cent more bits of storage capacity per wafer than 96-layer BiCS4.
Kioxia says cell array density has risen by approximately 20 per cent over the 96-layer product.
Western Digital also claims design enhancements enable BiCS5 to offer up to 50 per cent faster I/O performance compared to BiCS4. This is in toggle mode for select applications. Kioxia says BiCS5 has lower read and write latencies than BiCS4. Great: we should get both fatter and faster SSDs.
BiCS5 chips.
Kioxia plans to start shipping 512Gbit TLC samples in the first quarter of 2020. Volume BiCS5 production should start in the second half of the year.
We might expect BiCS5-based SSDs to be announced then as well, with Q4 being the earliest ship date. Product will be manufactured at Kioxia and Western Digital’s Yokkaichi Plant and their newly built Kitakami plant, both in Japan.
Layered generations
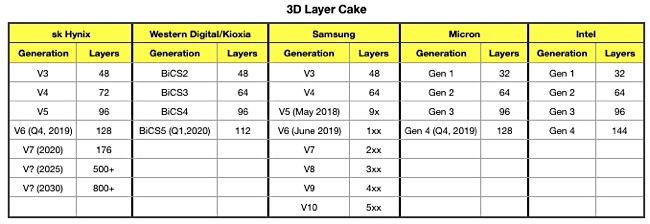
A table of 3D NAND suppliers and their layer generations shows that they have started diverging layer counts from 48 layers onwards, with SK Hynix introducing its 72-layer V4 generation whole the others settled on 64 layers. It rejoined the fold at 96 layers only for Samsung to say it had a 9x-layer count, not 96.
Now, at the 1xx level, sk Hynix has 128, WD/Kioxia have 112, Micron 128 while Intel has gone gangbusters and settled on 144. Blocks & Files expects more layer count divergence in the future.
This week in storage, we have an acquisition, three momentum releases, Cloudian going Splunk, Emmy awards for Isilon and Quantum, plus some funding news, people moves, two customer wins and books from NetApp and Intel.
Hitachi Vantara buys Waterline
Hitachi Vantara told the market it intends to buy Waterline Data and so gain a data cataloging capability for what it calls its “data ops” product.
Waterline Data’s catalog technology uses machine learning (ML) to automate metadata discovery. The firm calls this “fingerprinting” technology. It uses AI- and rule-based systems to automate the discovery, classification and analysis of distributed and diverse data assets to accurately and efficiently tag large volumes of data based on common characteristics.
Shown an example of a data field containing claim numbers in an insurance data set, the technology can then scan the data set for other examples and tag them. Hitachi V says this enables it to recognise and label all similar fields as “insurance claim numbers” across the entire data lake and beyond with extremely high precision – regardless of file formats, field names or data sources.
Hitachi V is getting technology that has been adopted by customers in the financial services, healthcare and pharmaceuticals industries to support analytics and data science projects, pinpoint compliance-sensitive data and improve data governance.
It can be applied on-premises or in the cloud to large volumes of data in Hadoop, SQL, Amazon Web Services (AWS), Microsoft Azure and Google Cloud environments.
Cloudian goes Splunk
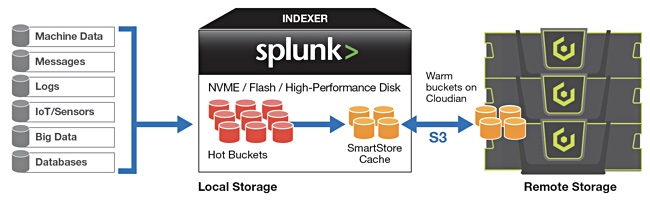
Cloudian has said its HyperStore object storage combined with Splunk’s SmartStore feature can provide an exabyte-scalable, on-premises storage pool separate from Splunk indexers.
The firm claims the growth of machine and unstructured data is breaking the distributed scale-out mode that combines compute and storage in the same devices. A Splunk SmartStore and Cloudian HyperStore combo lets you decouple the compute and storage layers, so you can independently scale both.
A SmartStore-enabled index minimizes its use of local storage, with the bulk of its data residing remotely on economic Cloudian HyperStore. As data transitions from hot to warm, the Splunk indexer uploads a copy of the warm bucket to Cloudian Hyperstore and retains the bucket locally on the indexer until it is evicted to make space for active datasets.
HyperStore becomes the location for master copies of warm buckets, while the indexer’s local storage is used for hot buckets and cache copies of warm buckets which contain recently rolled over data, data currently participating in a search or highly likely to participate in a future search. Searching for older datasets that are now remote results in a fetch of the master copy from the HyperStore.
Hyperconverged infrastructure appliance vendor Scale Computing claims to have achieved record sales in Q4, driven by its OEM partnerships and edge-based deal activity, exiting 2019 at a growth rate of over 90 per cent in total software revenue; its best year yet.
Scale says it added hundreds of new customers and announced an OEM partnership with Acronis, offering Acronis Cyber Backup to customers through Scale Computing’s channels. Via its Lenovo partnership, it says customer wins included Delhaize, Coca Cola Beverages Africa, the Zillertaler Gletscherbahn, National Bank of Kenya, beIN Sports, and De Forensische Zorgspecialisten.
Scale CEO Jeff Ready.
In 2019 NEC Corporation of America and NEC Enterprise Solutions (EMEA) announced a new hyperconverged infrastructure (HCI) solution powered by Scale Computing’s HC3 software.
Jef Ready, Scale’s CEO and co-founder, said: “In 2020, we anticipate even higher growth for Scale Computing as a leading player in the edge computing and hyper-converged space.”
Scality RINGs in changes
RING object storage software supplier Scality said it experienced record growth in 2019 from both customer expansions and “new logo” customers. Scality was founded 10 years ago and said it has recruited 50 new enterprise customers from around the world, across a broad range of industries and use-cases.
Scality’s largest customer stores more than 100PB of object data. Scality CEO and co-founder Jerome Lecat said: “Now in our 11th year, we’re really proud to be able to say that eight of our 10 first customer deployments are still in production and continue to invest in the Scality platform.”
He reckons: “It’s clear that Scality RING is a storage solution for the long-term; on a trajectory to average at least a 20-year lifespan after deployment. That’s a solid investment.”
Will Scality have IPO’d or been acquired by 2030 though? That’s an interesting question.
WekaIO we go
Scale-out, high-performance filesystem software startup WekaIO said it grew revenue by 600 per cent in its fiscal 2019 compared to 2018. The firm said its product was adopted by customers in AI, life sciences, and financial analysis.
WekaIO CEO Liran Zvibel.
Liran Zvibel, co-founder and CEO at WekaIO, claimed: “We are the only tier-1, enterprise-grade storage solution capable of delivering epic performance at any scale on premises and on the public cloud, and we will continue to fuel our momentum by hiring for key positions and identifying strategic partnerships.”
WekaIO said its WekaIO Innovation Network of channel partners grew to 67 partners in 2019, a 120 per cent growth rate. It is 100 per cent channel-focused and announced technology partnerships with Supermicro, Dell EMC, HPE, and NVIDIA in 2019. It said there was 300 per cent growth in AWS storage, topping 100PB in 2019.
Shorts
Datera has announced that its Datera Data Services Platform is now Veeam Ready in the Repository category. This enables Veeam customers to back up VMware primary data running on Datera primary storage to another Datera cluster, so providing continuous availability.
Dell EMC Isilon has been awarded a Technology & Engineering Emmy by the National Academy of Television Arts and Sciences for early development of hierarchical storage management systems. It will be awarded at the forthcoming NAB show, April 18-22, in Las Vegas.
HiveIO announced Hive Fabric 9.0 with protection for virtual machines (VMs) and user data with its Disaster Recovery (DR) capability, which integrates with cloud storage, such as Amazon S3 and Azure. Hive Fabric 8.0 also incorporates business intelligence (BI) tools into Hive Sense. This capability proactively notifies HiveIO of an issue within a customer environment.
HPE has added replication over Fibre Channel to its Primera arrays as an alternative to existing Remote Copy support over Internet Protocol (IP). It claims Primera is ready to protect any mission-critical applications, regardless of the existing network infrastructure. Remote Copy is, HPE says, a continuous-availability product and “set it and forget it” technology.
NVMe-Over-Fabrics array startup Pavilion is partnering with Ovation Data Services Inc. (OvationData) to bring Hyperparallel Flash Array (HFA) technology to OvationData’s Seismic Nexus and Technology Centers. OvationData is a data services provider for multiple industries in Europe and the United States, with a concentration on seismic data for oil and gas exploration.
Red Hat announced the general availability of Red Hat OpenShift Container Storage 4 to deliver an integrated, multi-cloud storage to Red Hat OpenShift Container Platform users. It uses the Multi-Cloud Object Gateway from Red Hat’s 2018 acquisition of NooBaa.
Quantum has also won a Technology & Engineering Emmy for its contributions to the development of Hierarchical Storage Management (HSM) systems, meaning StorNext, for the media and entertainment industries. This Emmy will also be awarded at the forthcoming NAB show, April 18-22, in Las Vegas.
SQream announced a new release of its flagship data analytics engine, SQream DB v2020.1. It includes native HDFS support which dramatically improves data offloading and ingest when deployed alongside Hadoop data lakes. SQream DB can now not only read, but also write data and intermediate results back to HDFS for other data consumers, to significantly improve analytics capabilities from a Hadoop data pipeline. It’s also added ORC Columnar Format and S3 support.
Container security startup Sysdig has announced a $70m E-round of VC funding, taking total funding to $206m. The round was led by Insight Partners with participation from previous investors, Bain Capital Ventures and Accel. Glynn Capital also joined this round, along with Goldman Sachs, who joined after being a customer for two years. Sysdig has also set up a Japanese subsidiary; Sysdig Japan GK.
People
Dell Technologies has promoted Adrian McDonald to its EMEA President position. He will continue his role as global lead for the Mosaic Employee Resource Group at Dell Technologies, which represents and promotes cultural inclusion and the benefits of cultural intelligence. In December last year Dell appointed Bill Scannell as its global sales organisation leader, with Aongus Hegarty taking the role of President of International Sales responsible for all markets outside of North America.
Cloud file services supplier Nasuni has appointed Joel Reich, former executive vice president at NetApp, and Peter McKay, CEO of Snyk and former Veeam co-CEO, to its board of directors.
Software-defined storage supplier Softiron announced the appointment of Paul Harris as Regional Director of Sales for the APAC region.
WekaIO has appointed Intekhab Nazeer as Chief Finance Officer (CFO). He comes to WekaIO from Unifi Software (acquired by Dell Boomi), a provider of self-service data discovery and preparation platforms, where he was CFO.
Customer wins
In the UK the Liverpool School of Tropical Medicine (LSTM) has chosen Cloudian’s HyperStore object storage to to manage and protect its growing data, Data will be offloaded onto the Cloudian system from what the firm says is an expensive NetApp NAS filer.
HPE has been selected by Zenuity, a developer of software for self-driving and assisted driving cars, to provide artificial intelligence (AI) and high-performance computing (HPC) infrastructure to be used for developing autonomous driving (AD) systems.
Books
Intel has published a 400+ page book on (Optane) Persistent Memory programming. The book introduces the persistent memory technology and provides answers to questions software developers an d system and cloud architects may have;
What is persistent memory?
How do I use it?
What APIs and libraries are available?
What benefits can it provide for my application?
What new programming methods do Ineed to learn?
How do I design applications to use persistent memory?
Where can I find information, documentation, and help?
NetApp has also published a book, an eBook; Migrating Enterprise Workloads to the Cloud. It provides hands-on guidelines, including how Cloud Volumes ONTAP supports enterprise workloads during and after migration. Unlike the Intel Persistent Memory brain dump, this is more of a marketing spiel – and is 16 pages in landscape format.
For anyone wanting to code a data protection app for containers, Kubernetes (K8s) is a great big help. Because it orchestrates container instantiation and operations, it knows everything about them that such an app needs to know.
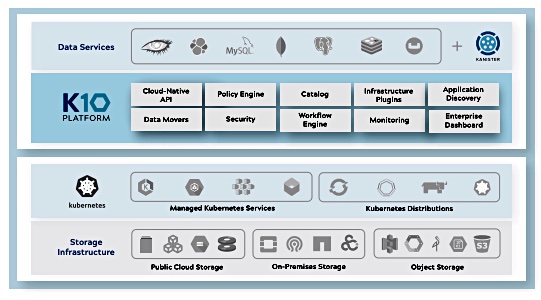
This theoretically puts three-year-old startup Kasten in a good position, as Kubernetes, a control plane for containers, is its gateway to container data protection. The firm uses Kubernetes to auto-discover containerised apps, and to list their components and their startup processes. K10, Kasten’s application, is a K8s data protection layer, using it and its interfaces to avoid having to have direct storage product system level integrations.
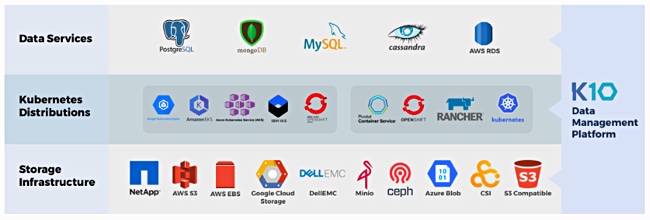
K10 datasheet diagram.
K10 doesn’t need to understand specific array interfaces, using K8s CSI (Container Storage Interface) abstractions instead, for block interface and object interface storage devices. It works with any CSI-supporting storage system.
Migration and disaster recovery are covered as well because Kubernetes enables K10 to snapshot a container’s entire state, not just the data it needs protecting. That means the K10-protected container can be moved to a different system and instantiated there; migration, and also sent to a disaster recovery site and kept there until needed.
Incremental changes can be snapshotted at intervals and sent to the remote site to keep it up to date. The remote sites can be in public clouds or on-premises, as can the source site. Wherever K8s runs then Kasten’s K10 can run; it is itself a containerised application.
Trad backup apps can’t cut it
Tolia told Blocks & Files in a briefing that in the containerised world, the app is the operational unit for backup and not, for example, the virtual machine. He said that, with K8s and containers: “The software application monolith is blown up.”
K10’s application and storage supplier eco system.
Mentioning a Fortune 1000 customer with 106 K8s pods and 538 app components, he said: “Traditional backup software can’t protect this. Recovery is very hard [and] scripting is too complex.”
Kasten backgrounder
The company was started up in the Bay Area in 2017 by CEO Niraj Tolia and Engineering VP Vaibhav Kamra. It raised $17m in a A-round of VC funding from Insight Partners in summer last year and has set up a second office in Salt Lake City.
Kasten co-founders: CEO Niraj Tolia (left) and VP Vaibhav Kamra.
Tolia and Kamra were previously involved with cloud storage gateway business Maginatics which was bought by EMC in 2014. Its IP included a distributed scale-out filesystem.
The CEO was Maginatic’s VP of engineering and Kamra its engineering director. Both stayed with EMC until leaving to found Kasten.
Tolia calls K10 a data management facility for containerised apps; preferring that term to data protection, since it provides migration and DR on top of backup. To find out more detail, check out a K10 data sheet.
B&F view
Kasten is fresh in the market and in a good place, with K8s orchestration set to become a standard feature of enterprise IT.
But two factors make the startup’s mid- and long-term position vulnerable to future attack. One is that it backs up entire containerised apps which can be re-instantiated. In other words it does not write them in a proprietary backup format, making it non-sticky in a backup application sense.
Secondly its gateway to the world of containerised app information is K8s, and that is open source, meaning anybody else can use it too.
Indeed Cohesity already does, and K8s-orchestrated container apps are just one of its backup source systems, which include multi-hypervisor VMs, physical server apps, such as relational and distributed databases, and the main public clouds, not available to Kasten. Cohesity can provide container app data protection, migration and disaster recovery too, like Kasten, but also file storage services, copy data management, archiving and more.
Other data protection suppliers could build their own K8s-based on-ramp to container backup as well, or buy the technology by buying a supplier, such as Kasten. It is easier for them to do that than for Kasten, with its limited resources, to expand into generalised backup or data management and take them on in their own product areas.
In B&F’s view, the ability to protect K8s-orchestrated apps will become table stakes for every data protection supplier in five or so years’ time. It will be a feature and not, as it is now for Kasten, a basis for a product. Time is short and Kasten has to move fast.
Footnote
For mountaineering wonks, K10 is a peak in the Karakoram range, otherwise known as Saltoro Kangri 1. It is the 31st highest mountain in the world.