German IT services company Bechtle replaced a faulty HPE Primera array in its data centre with an Infinidat equivalent when HPE support could not resolve a firmware problem expeditiously.
Bechtle, headquartered in Neckarsulm, north of Stuttgart, is a $6 billion turnover multinational IT products and services supplier with 80 offices, 12,700 employees and more than 70,000 customers. It used a Primera array as part of its hosting environment for managed services.
The firm said it first encountered a problem with its Primera storage array in 2021 which prevented it from performing properly as the workload scaled up. Talking at an IT press tour event in Israel this month, Eckhard Meissinger, Bechtle’s head of Datacenters, said there were “massive performance issues with the existing storage system” – the Primera system.
He added that the “frequency of the faults led to a loss of trust among our customers” and “we had to pay a lot of contractual penalties.”
Meissinger said he was told by Primera Level 3 support that the problem affected 1 percent of HPE’s Primera customers. HPE offered a 3PAR replacement array as a solution to the issue, but then – according to Bechtle – subsequently withdrew the offer as it suffered the same firmware glitch.
Both the Primera and 3PAR arrays rely on a proprietary ASIC to carry out functions such as zero detect, RAID parity calculation, checksums and some deduplication tasks, accelerating them far beyond the speed of software carrying out the same functions.
As the location of the fault was in firmware, it seems the Bechtle workload encountered an issue in the Primera and 3PAR ASIC subsystem.
HPE was unable to fix the problem over a number of weeks, because it was a major bug fix issue, according to Bechtle. As a result, Bechtle went out to tender for a replacement system, eventually choosing one from Infinidat. It bought a 1PB InfiniBox array.

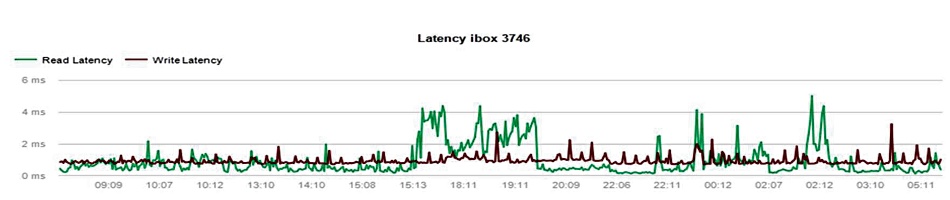
The array became operational in January this year after three weeks of testing. Thousands of Bechtle clients use the system and – to date – it has exhibited 100 percent availability, and performance close to or equal to an all-flash system. Bechtle said that with a capacity utilization of 70 percent, the savings compared to competitors such as NetApp and Pure are about €35 per TB. When utilization is higher than 70 percent, the claimed savings are about €40-45 per TB.
Bechtle is now in the process of becoming a public Infinidat reference customer.
That’s quite a turnaround as Bechtle was honoured as Hewlett Packard Enterprise’s Global Solution Provider of the Year for Germany, Austria, Switzerland, and Russia in June 2019, with HPE CEO Antonio Neri present at the ceremony. Bechtle was also HPE’s DACH Solution Provider of the Year 2020.
We have asked HPE what was the nature of the problem and why it could not be fixed in a timescale that met Bechtle’s requirements. An HPE spokesperson replied: “HPE as a policy does not comment on our customers.”