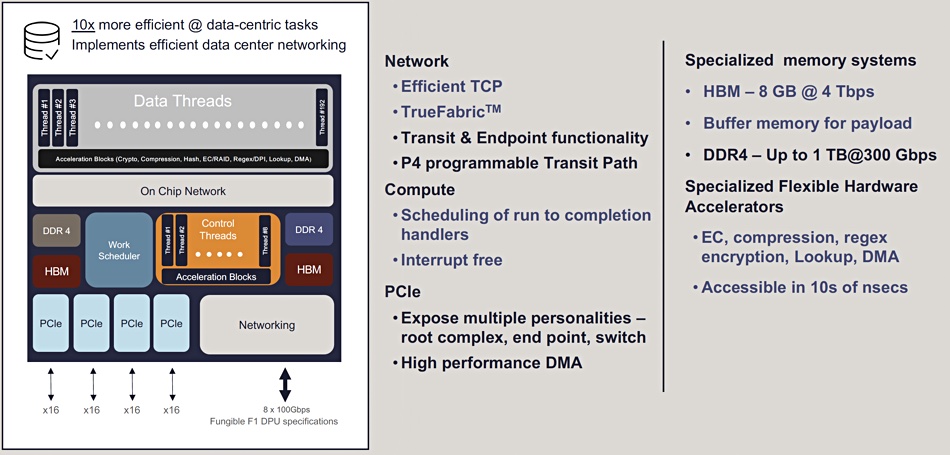
DPU – Data Processing Unit – dedicated processors to accelerate storage and networking functions carried out by industry standard x86 servers. These DPUs can be based on different kinds of processing hardware – for example, ASICs, FPGAs and SoCS with customised Arm CPUs.
Fungible DPU diagram.
A DPU is a system on a chip (SoC), typically containing three elements;
Multi-core CPU, e.g. Arm
Network interface capable of parsing, processing and transferring data at line rate – or at the speed of the rest of the network – to GPUs and CPUs,
Set of acceleration engines that offload and improve applications performance for AI and machine learning, security, telecommunications, and storage, among others.
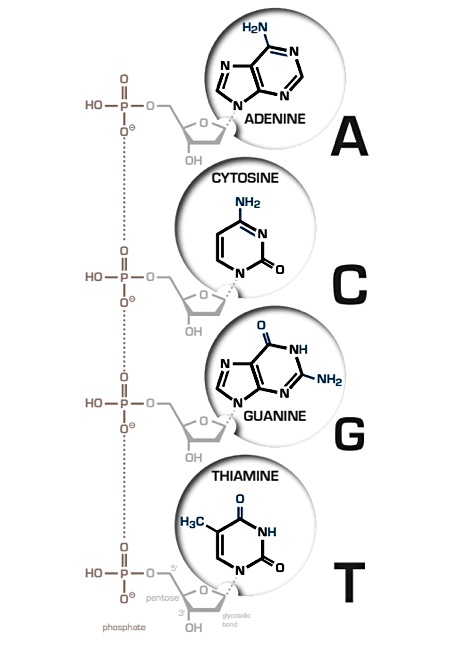
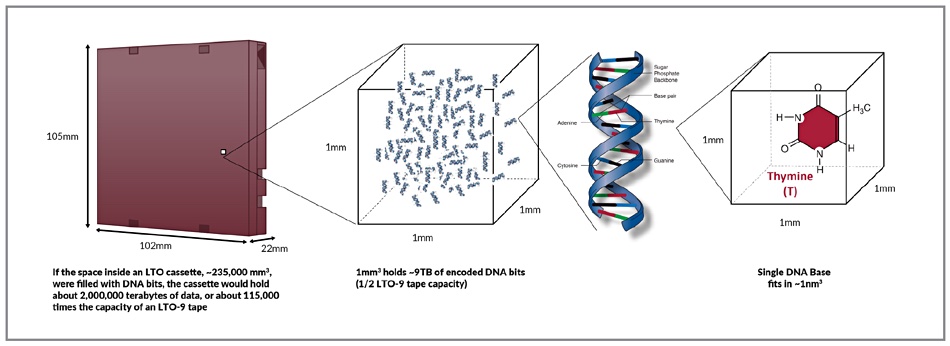
DNA Storage – DNA (Deoxyribonucleic acid) is a biopolymer molecule composed of two chains in a double helix formation, and carrying genetic information. The chains are made up from nucleotides containing one of four nucleobases; cytosine (C), guanine (G), adenine (A) and thymine (T). DNA data storage encodes binary data (base 2 numbering scheme) into a 4-element coding scheme using the four DNA nucleic acid bases. For example, 00 = A, 01 = C, 10 = G and 11 = T. This transformed data is encoded into short DNA fragments and packed inside some kind of container, such as a glass bead, for preservation. One gram of DNA can theoretically store almost a zettabyte of digital data – one trillion gigabytes. Such fragments can be read in a DNA sequencing operation. They are tiny and can theoretically last for thousands of years or more.
DIMM – Dual Inline Memory Module. A double-sided hardware card loaded with DRAM chips that plugs into a socket on a computer motherboard and so connects to a CPU across a 64-bit bus. A prior SIMM (Single InLine Memory Module) used a 32-bit bus and the DIMM is therefore significantly faster. There are various types of DIMMs such as UDIMMs (unbuffered DIMMs), FB-DIMMs (fully-buffered DIMMs), RDIMMs (registered DIMMs), LRDIMMs (load-reduced DIMMs), SO-DIMMs (small outline DIMMs), MicroDIMMs, and UniDIMMs.
Deduplication – A method for removing repeated items or groups of items in a file to make it take up less space. It is often used in backup software and also in purpose-built back up appliances, such as those from Dell. Eg, PowerProtect and previous DataDomain products. Inline deduplication is carried out as backup data lands on the device, and not afterwards in a post-process deduplication exercise. Global deduplication is carried out across a group of appliances. Otherwise the deduplication scope is limited to the appliance or system within which it is executing. Some storage arrays also use it, such as file-based VAST Data’s Universal Storage.
Deduplication is lossless. It is a form of data reduction and compression is another. Compression reduces the size of a file by finding and replacing redundant data within the file by pointers to the original data string. Eg; a 100 text file might be compressed by replacing repeated sequences of space characters our text strings replacing them with shorter pointers.
Deduplication works at the block-level within files and gives blocks a calaculated hash value. If a subsequent block has the same hash value then it is replaced with a pointer to the original block, thus saving space. The deduplication algorithm can work with a fixed block size or variable sized blocks.
As a quick differentiation, compression and deduplication are both forms of data reduction with compression scanning for similar characters or character strings in short sections of a file, whereas deduplication calculates hash values for lager strings of characters (blocks) and then looks for repeated hash values to identify similar blocks. It is a hash value level check whereas compression is a character string level check.
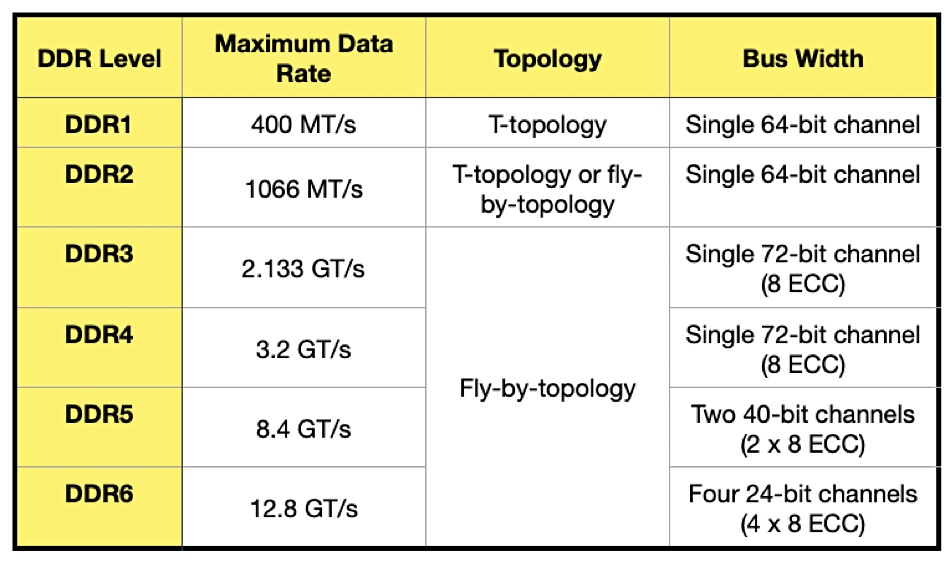
DDR5 – Double Data Rate memory with double the bandwidth and capacity of DDR4 memory. DDR5 3200 will deliver 182.5 GB/sec effective bandwidth from its 3200 MT/s data rate, which is is 1.36 x faster than DDR4 3200. DDR5 4800 will provide 250.9 GB/sec and is 1.87 x faster than DDR4 4800. DDR5 6400 is expected to deliver 298.2 GB/sec bandwidth.
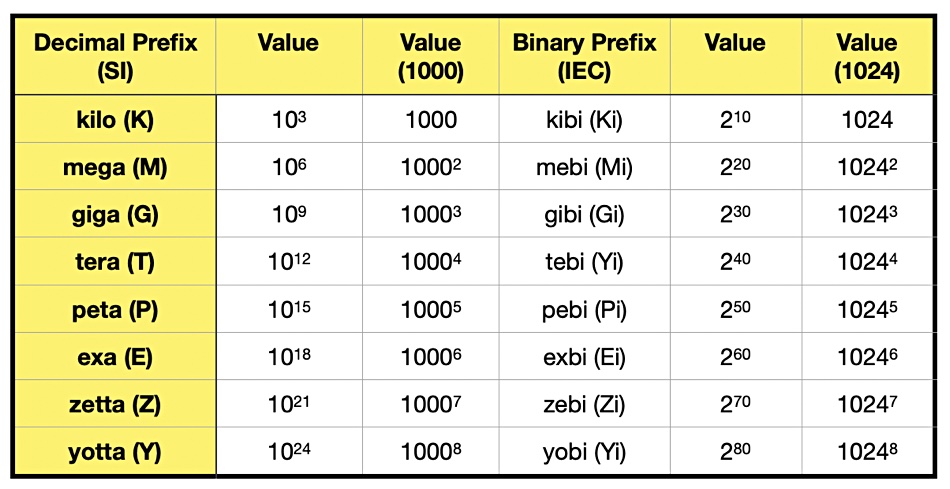
Decimal and Binary Prefixes – The SI system, a decimal system, measures units in powers of 10. The binary numeric system measure units in powers of 2. Numeric prefixes, such as kilo, mega, and tera, represent thousandfold increases from the preceding number or base number. If the base number is 1 then a kilo is 1,000 times that and a mega is 1,000 times a kilo. A decimal kilo is 10 to the power 3 (103) or 1,000. But a binary kilo is 2 to the power 10 (210) or 1024. Since it has a different value from the decimal kilo the prefix is changed to kibi. The following table lists the various decimal and binary prefix terms and their values;
When dealing with the capacity of computer memory or storage the binary prefix is more accurate, although the less accurate decimal prefixes are in common use.
DDR – Double Data Rate memory. Originally data was transferred from memory to the CPU every clock signal. The more DRAM capacity and the higher the speed the better, as server and PC CPUs can get through more work with less waiting for memory contents to be read or written. As a way of increasing the rate DDR transfers data at the start of the clock signal and also at its end, doubling the data rate per clock signal.
There are five generations of DDR technology, as at November 2022, with a sixth generation in prospect. Standards are set by JEDEC and data rates can be exceeded
V-Tree – a tree-like structure used for storing metadata in VAST Data’s universal file system. This has a DASE (Disaggregated Shared Everything) datastore which is a byte-granular, thin-provisioned, sharded, and has an infinitely-scalable global namespace. It involves the compute nodes being responsible for so-called element stores.
These element stores use V-tree metadata structures, 7-layers deep with each layer 512 times larger than the one above it. This V-tree structure is capable of supporting 100 trillion objects. The data structures are self-describing with regard to lock and snaps states and directories.
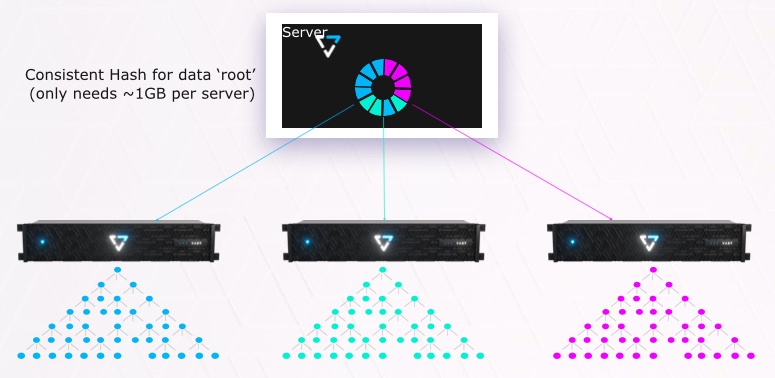
There is a consistent hash in each compute node which tells that compute node which V-tree to use to locate a data object.
The colour wheel in the server is the consistent hash table in the compute-node that provides the first set of pointers to the blue, cyan and magenta V-trees in the data-nodes.
Since the V-trees are shallow finding a specific metadata item is 7 or fewer redirection steps through the V-Tree. That means no persistent state in the compute-node (small hash table built at boot) and adding capacity adds V-Trees for scale.
More conventional B-Tree systems and others need tens or hundreds of redirections to find an object. That means the B-Tree has to be in memory, not across an NVMe-oF fabric, for fast traversal, and the controllers have to maintain coherent state across the cluster. VAST Data keeps state in persistent (Storage-class) memory and can afford the network hop to keep state there.
V-trees are shared-everything and there is no need for cross-talk between the compute nodes. Global access to the trees and transactional data structures enable a global namespace without the need of cache coherence in the servers or cross talk. There is no need for a lock manager as lock state is read from storage-class memory.
DASE – Disaggregated Shared Everything – the system architecture devised and used by VAST Data. This employs a Universal Storage filesystem with a DASE (Disaggregated Shared Everything) datastore which is a byte-granular, thin-provisioned, sharded, and has an infinitely-scalable global namespace.
It involves the compute nodes being responsible for so-called element stores. These element stores use V-tree metadata structures, 7-layers deep with each layer 512 times larger than the one above it. This V-tree structure is capable of supporting 100 trillion objects. The data structures are self-describing with regard to lock and snaps states and directories.
There is a consistent hash in each compute node which tells that compute node which V-tree to use to locate a data object. The 7-layer depth means V-trees are broad and shallow. V-trees are shared-everything and there is no need for cross-talk between the compute nodes.