


Profile. StorageX is a computational storage company with a difference, supplying AI processing and models to cut data-heavy workloads down to size.

We met StorageX founder and CEO Stephen Yuan on an IT Press Tour to find out more about its Lake Ti processing card and its functionality. StorageX believes that for data-heavy workloads, compute should move closer to the data. Moving mass data to distant compute – be it x86 or GPUs – takes a long time and needs a lot of electricity.
But placing compute near to the storage invites the question “what kind of compute?” Is it x86, GPU, Arm, Risc-V or something else? Is StorageX a ScaleFlux-type computational storage company?
StorageX says its Lake Ti P100/P150 series add-in card features a dedicated AI engine that has higher performance per watt and per dollar than mainstream GPUs, plus 32GB of DRAM. It also brings high-performance data acceleration and low latency IO acceleration for storage and the network – meaning high-performance AI, network, and storage acceleration in one package.
It supports PCIe 4 and is RDMA ready. Yuan said “We can support RDMA. We have the protocols for it right now.” The current product’s 2x 100 GbitE ports are there for that and also for memory expansion. There is a direct SCM/SSD bridge for memory/storage extension. The Lake Ti card can pre-process data before it goes to GPUs and process incoming data before it is stored on a drive.
The card is ready for real-time analytics work. Yuan asserted that Lake Ti can carry out vector processing tasks more efficiently than CPUs and GPUs. There are predefined and optimized AI models for a user application and the Lake Ti system has data-awareness applications for a smart data lake which can be used for recommendation processing.
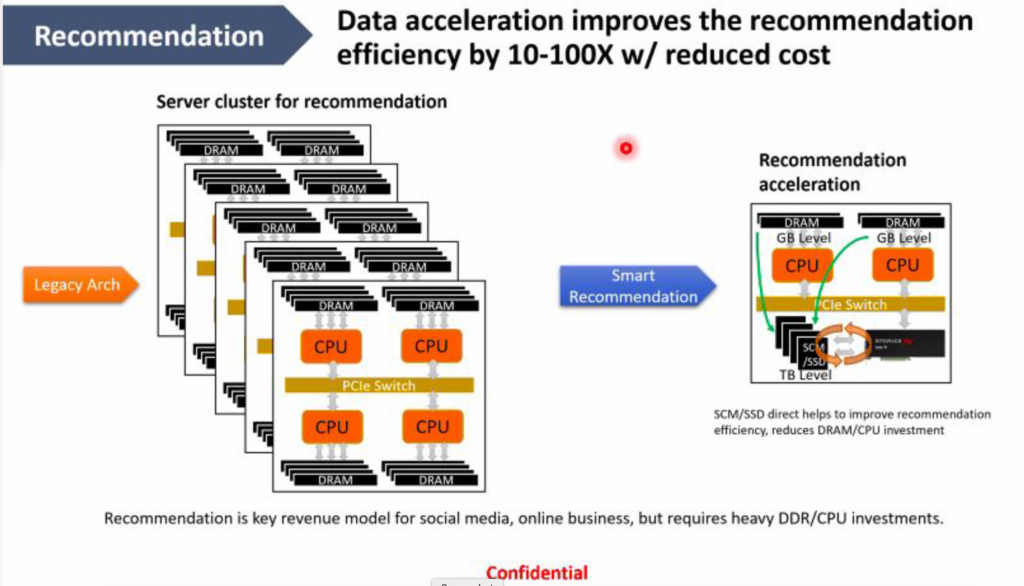
The diagram above compares a legacy server recommendation cluster on the left with a StorageX-enabled recommendation system on the right, which is more efficient. It shows a Lake Ti card connected to a TB-level set of SSDs communicating at the GB level via PCIe switch to a CPU and a GPU. They are still needed – the card does not replace them.
Yuan explained: “If we can process closer to the storage nodes, that will make it a lot easier … you can reduce a lot of the data size, making it more efficient when doing the compute.” In other words, StorageX processes the data and reduces its size, reducing network transmission time. He added: “We can process the data close to the storage nodes, and pre-process it, and we really streamline the throughput.”
“We’re optimizing … data intensive workloads. We’re not competing with CPUs for those very complex computer tasks or GPUs for the graphical stuff or things like that. But we’re good at … data heavy workloads.”

In summary, this Lake Ti card, which is FPGA-based, has three compute functions: an AI engine and AI models, a storage data processor, and a network I/O processor. StorageX is bringing some dedicated compute functions to the storage along with storage and network I/O acceleration so that customers can carry out AI analytics work without needing access to massive x86 or GPU server farms for all of it.
Compared to Nvidia’s Bluefield SmartNIC/DPU product, the Lake Ti card has more capabilities such as AI and pseudo-TPU features. But Lake Ti does not support virtualization, which BlueField does. Nvidia’s card shares network acceleration with Lake Ti, but does not have data acceleration. Lake Ti supports memory expansion, via its 2x 100Gbit ports, and BlueField does not.
The Lake Ti card is not a DPU in the Fungible sense – a routing or gateway chip able to connect to many hosts, each of which have a corresponding front-end card.
StorageX claims it has users in the digital or smart factory market, and is working with SK hynix’s Solidigm unit in that area. It is partnering with AMD and working with some of the memory vendors – SSD vendors as well – to create a smart data lake system. StorageX is working in autonomous driving with an on-vehicle storage and compute platform, also in streaming media. With Tencent, for example, there are more than 100 million videos uploaded each day. Yuan said that means around 5PB of video data needs to be mined, analyzed, and recommended, which involves 360 billion frames per day. TikTok is showing up to 167 million videos per minute and needs fast recommendations to its users.
Yuan says StorageX Lake Ti computational storage processors in a smart data lake can provide video understanding, natural language processing, extraction, user profiling, and recommendations.
There is a next-generation product in development that may use an ASIC instead of an FPGA, and could support PCIe 5. It should arrive later this year. Direct CXL support is planned, as is card clustering. The clustering would not necessarily use a PCIe connection.
Some kind of fast data transport to GPUs is being developed, with Yuan hinting: “We’re planning to connect to the GPUs using certain … protocols, and pre-process the data before feeding it to the GPU itself.”
This should be independent of the specific GPU manufacturer, as “the only thing that matters is how we connect to them.”
The Lake Ti product is not sold as a card on its own – StorageX provides a rounded package. “We provide hardware, software and services for … customers,” Yuan explained.
From a competitive view, StorageX considers itself to be an AI plus data company. “Databricks or … SaaS software service companies really are software-based companies. We are providing our dedicated hardware to accelerate these workloads, making it more efficient to process very data-heavy workloads.”
If potential customers are spending a lot of money on GPU or x86 server clusters and suffering long latency data movement between them and the storage, Yuan suggests: “Our hardware helps us to reduce the TCO and make the [CPUs and GPUs] more efficient. So we’re a kind of hybrid hardware and algorithms and data company.”
It is not a drive-level computational storage company like ScaleFlux. It is a system-level near-storage compute company with AI capabilities running on its own specialized FPGA hardware, and we’re going to hear a lot more about it in the future.





