


Profile: Little-known Chinese startup StorageX has developed a Lake Ti computational storage processor it says enables compute to move to the data, allowing for fast processing of big data for Generative AI-class work.
This company is nothing to do with Data Dynamics and its StorageX unstructured data migration product. We have gleaned the information in this profile from the company’s website and other resources. As a Chinese startup information about it is less available than it would be for a Silicon Valley startup.
StorageX is based in Shanghai, China, and was founded in 2020 as Shenzhen Technology by CEO Yuan Jingfeng, who also goes by Stephen Yuan. StorageX has a second China office in Wuxi, and a third office in San Jose. It says its team has an average of more than 20 years of storage industry experience, encompassing memory and controller chips, data acceleration, GPU and datacenter architectures. Core team members come from Western Digital, Micron, HPE, Intel, Microsoft Azure, Nvidia, Tencent and other industry big hitters.
Yuan is said to have worked on Micron’s first NAND memory chip and holds a dozen or so patents in the areas of memory, storage and system architecture. He has two decades of industry experience in memory, enterprise storage and data center architecture. He has an R&D and product development background, and holds more than a dozen patents in the field of memory, storage as well as system architecture.
The CEO says: “Moving compute is easier and more efficient than moving data, which will generate huge benefit [for] future data heavy applications. … Back to the first principal, the key to improve computing efficiency is to improve the efficiency of data movements, moving compute will be more effective than moving data.”
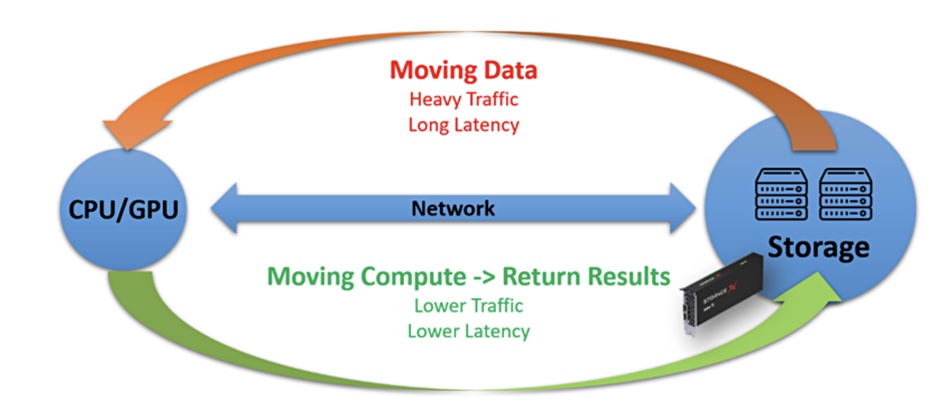
Market areas include datacenters, streaming media services, autonomous driving and others. StorageX says its computational storage processing (CSP) chips and systems can enable the deployment of high-performance near-data computing, provide powerful AI computing power, data acceleration capabilities, I/O acceleration capabilities and software platforms. They are claimed to be more suitable for the high performance of current data centers focussing on massive data sets than traditional separated compute and storage systems.
StorageX has joined the SNIA’s Computing, Memory and Storage Initiative (CMSI) group, and has become a voting member. Yuan is a member of the CMSI’s governing board, along with Nicolas Maigne (Micron), Scott Shadley (Solidigm), and James Borden (Kioxia). Bill Martin (Samsung) is the chair person, Leah Schoeb (AMD) the vice chair; and Willie Nelson (Intel), the treasurer.
Computational Storage background
The SNIA defines three computing storage standards:
- Computational Storage Drive (CSD) – i.e. a computational SSD including persistent storage and computing modules),
- Computational Storage Processor (CSP) – which does not include persistent storage, but deploys computing power on the data side for processing,
- Computational Storage Array (CSA) – a complete hybrid or converged system that integrates application compute and storage.
So far we have seen computational storage drives, from companies like Eideticom and ScaleFlux, and some computational arrays from startups like Coho Data.
In general, computational storage has underwhelmed the market for two main reasons. First, although it says it moves compute to the data, it only moves a lightweight portion of compute to the data to do trivial stuff like compression or video transcoding. When we think of moving compute to the data we intuitively think of moving x86 class processing to the data. But we don’t get that with computational storage drives. We only get restricted, limited compute based on a few Arm cores, ASICs and so forth.
Secondly, moving compute to the data has been done at a drive level, not an array level. That limits the amount of physical space available for the compute hardware; drives don’t have much empty space inside their shells and also don’t have excess electrical power waiting to be used. Any processor mounted inside a drive can only see the data on that drive.
If an application needs its compute resource to access 500TB of data and a disk drive can only hold 24TB and an SSD 30TB, then you would need 17 of the SSDs to hold the data. The processors in each one would need to communicate with the others to enable full dataset processing visibility. It’s a nonsense of added networking complexity to move data results between these drive level processors to regain what you lose by not moving the dataset to the X86-class compute in the first place.
Doing compute at the array level, with the array controller processing power boosted to run app processing as well as storage array operation processing, has been tried and failed.
Remember Coho Data back in 2015? It developed DataStream MicroArrays, which combine Xeon-based server processing, PCIe NVMe flash cards, and disk storage, for closely-coupled storage tasks such as video stream transcoding and Splunk-style data analysis. The compute was not for general application execution and the DataStream system was not positioned as a hyper-converged appliance.
The firm closed down in 2017. In general, compute inside storage arrays has failed to take off because large data sets need processing by multiple processors and their cores. The processing required to simply operate a large storage array is quite enough without then adding in a whole hardware layer of application processors and their memory and IO paths into the storage stack mix as well.
This is the background context to what StorageX is trying to achieve.
StorageX technology
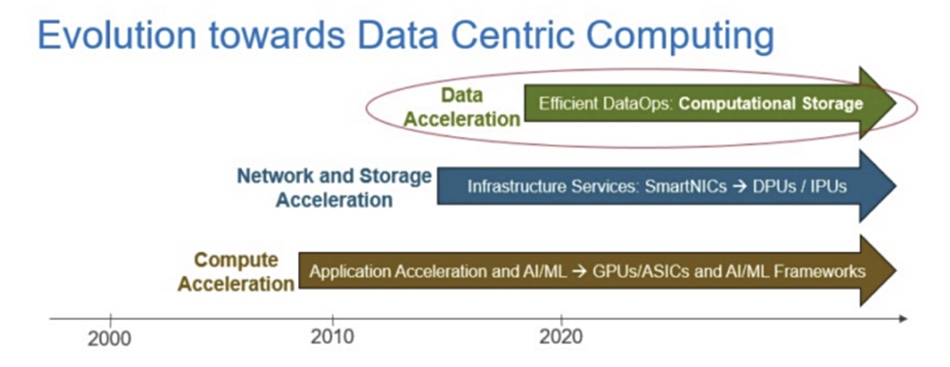
StorageX defines the computational storage array as a system combining computational storage processors, control software and other devices. Yuan believes that AI workloads require new processor designs to solve systemic problems faced by X86 and GPU processors when dealing with large amounts of data. Data-centric computing (storage nodes plus CSPs) will follow on from GPU-based processing acceleration and CPUs buttressed by DPUs and network acceleration.

Its Lake Ti (Titanium lake) P100 product incorporates an AI engine (CSP/XPU), data [flow] acceleration and I/O acceleration in one package, which is closely integrated with a storage system and data node. It has dual 100Gbps networking and is designed for data-centric computing, however that is defined.
In other words Lake TI is an ancillary near-data processor attached to a storage system. It is said to empower data-aware applications, with the storage array plus Lake Ti functioning, as we understand it, as a smart data lake. StorageX wants to lower the entry barrier for large language model AI computing by reducing costs and increasing efficiency at the computing hardware level.
Yuan said: “Our biggest difference is that we have taken computing power to the extreme, integrating acceleration and high performance AI in the CSP near the storage node to achieve the goal of data-centric computing and acceleration.”
We understand that StorageX (Shenzhen Technology) has applied for almost 50 patents, focused on AI, large models, near-data computing, SoC chips, data acceleration, IO acceleration and high-speed interconnect technology. It has customers who are trying out its product and we expect to hear more from the company in 2024.





