


Israeli startup Unifabrix demonstrated its Smart Memory Node at SC22 and we wrote an initial account of its technology here. The intent was to demonstrate remote memory pooling across a CXL 3.0 link from two Smart Memory Nodes to a group of Sapphire Rapids servers, using the MAX HBM-enhanced version, each with its own local and socket-connected DRAM.
Our assumption was that memory capacity expansion was the point, but that wasn’t the whole story. The demo was also showing off memory bandwidth expansion.
Ronen Hyatt, Unifabrix co-founder and CEO, told us in a briefing: “This was one of our key messages here in supercomputing because people, when they talk about CXL memory, they always talk about capacity. How do I expand capacity, memory expansion, memory pooling? It’s all about capacity and TCO. We came from a completely different angle – we came from performance.”
He says that, over time, memory channel bandwidth per core has gone down as processors’ core counts have gone up.
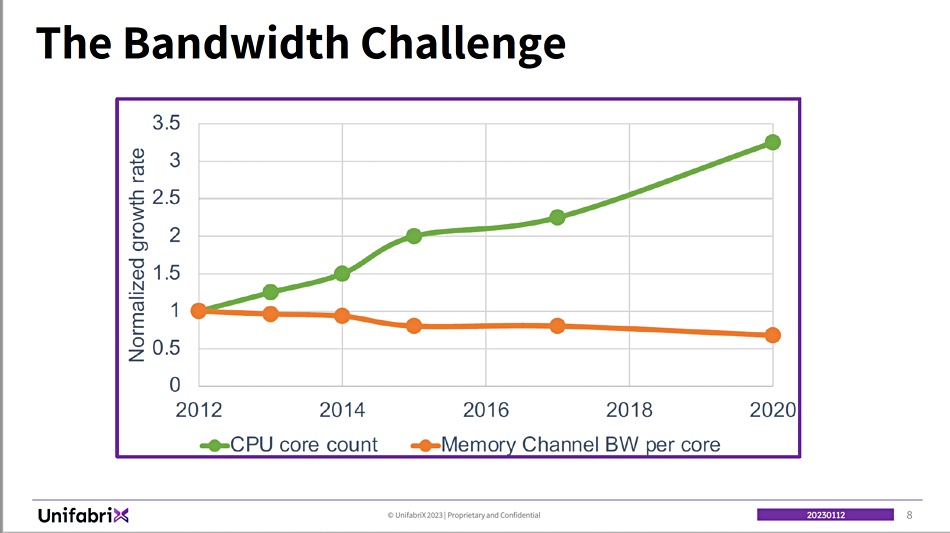
This means that there comes a point when adding more memory to a server has no effect on performance, because the cores can’t use it all. It’s stranded.
Unifabrix ran an HPCG (High Performance Conjugate Gradient) benchmark on the servers in its SC22 demo. This runs an application entirely in the computer’s DRAM and explores the limitations of the memory subsystem and internal interconnect limitations of the supercomputer. In other words, memory socket bandwidth.
The biz produced a demo run chart showing how server CPU core utilization increased by 26 percent once its Smart Memory Node added both more memory and more memory bandwidth to the servers.
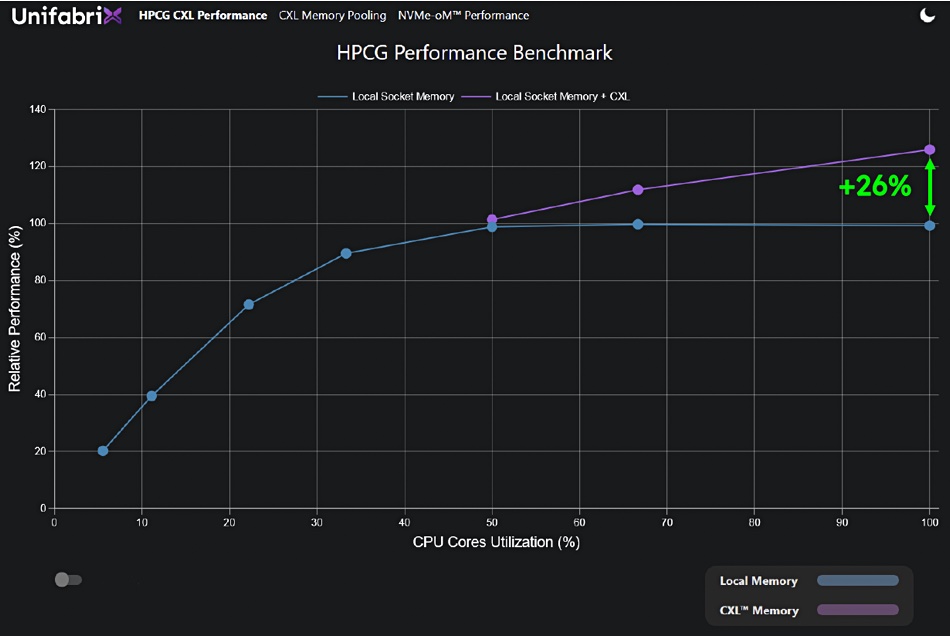
The SC22 show took place before Sapphire Rapids was publicly announced, so the actual number of cores was hidden and the graph has been normalized with a relative performance vertical axis. Also the horizontal axis shows core utilization and not core numbers. That’s Intel for you.
Anyway, we can see the blue line shows core utilization in a server when only its own DDR5 DRAM was available to it. When 50 percent of the cores are busy, the HPCG performance plateaus and additional cores cannot do any work. There is no more memory available for them because the socket channels are maxed out. It’s not a memory capacity limitation, but a memory bandwidth bottleneck.
Hyatt said: “What happens at this point is that you exhaust all your sockets, memory bandwidth, the local DDR bandwidth.”
Stepping outside the Intel arena, he added: “What you see with AMD processors that have, like, 96 cores and 128 cores, you will get the plateau here at the 20-something percent level. So the problem becomes even more significant when you have more cores.”
When the Smart Memory Node became active in the SC22 demo, it interleaved its CXL memory with the server’s local memory. As a result, HPCG performance went up 26 percent, with all the cores utilized – the purple line on the chart. This occurred even though CXL memory access, at 256GB/sec, is slower than DDR5’s DRAM access speed of 300GB/sec.
Hyatt explained: “Our Smart Memory node measures the memory bandwidth. And once it detects that there is an issue with the local DRAM memory bandwidth, it starts provisioning more bandwidth to the socket. And this is how we can scale to almost 30 percent more performance.”
Also: “Our Smart Memory Node can provision capacity and bandwidth independently. [It] actually monitors the system and monitors how the workload performs. And it creates an interleaving ratio between local DDR and external CXL memory that maximizes and optimizes the performance.”
We should note that, as Hyatt explained, “you cannot get this performance scaling with memory expansion.” That’s because simple CXL memory expansion doesn’t do anything for bandwidth.
High Bandwidth Memory, as used in the demo Sapphire Rapids system, provides some help – but its capacity, 64GB, is too small to make a difference.

Unifabrix’s pitch is that there is a mismatch between local DRAM capacity and bandwidth and high-performance compute needs, and this is derailing performance and TCO. HPC users buy more servers to get more memory capacity and bandwidth. By using Unifabrix Smart Memory Node, they can sidestep this trap.
Intel is producing a white paper that discusses all these points and it should be out in a few weeks’ time. Hopefully it will contain application run time details, comparing run times with and without Smart Memory Node contributions. At the least, with 26 percent more core utilization we should see an equivalent drop in application run times – but it could be even greater.
The Smart Memory Node works for storage as well. Hyatt said: “One of our HPC customers said they have bottlenecks with memory but they have also bottlenecks on the I/O side. And they will be very happy also for the storage. Because they have very large datasets that we can help them bring to the table.”
Unfabrix gave us a chart showing its SSDc-oM (SSD CXL over memory) performance at SC22, looking at an SSD storage system’s IOPS over time for a PCIe 4 reference NVMe drive.
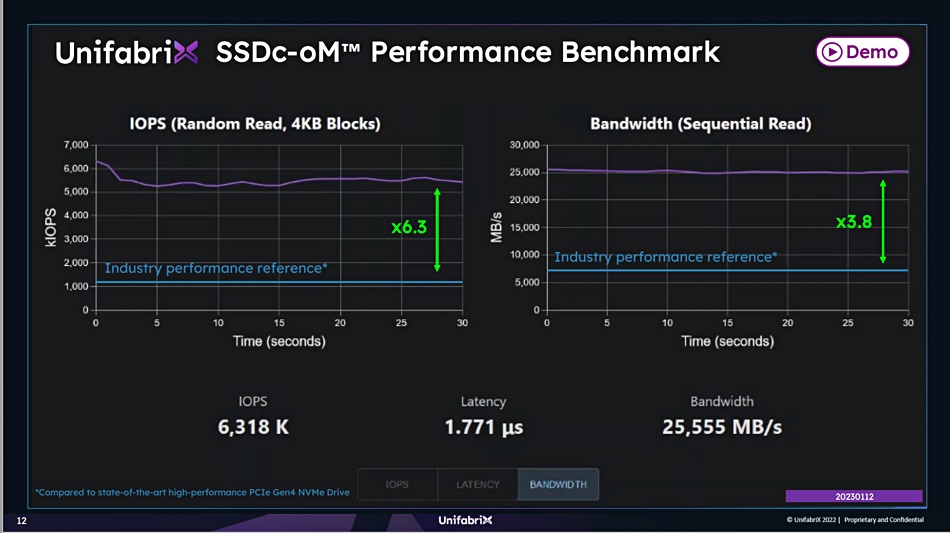
There was a 6.3x IOPS increase to around 5.5 million sustained IOPS and a 3.8x jump to 25.5GB/sec bandwidth.
It occurs to us that AI/ML and complex analytics applications are probably subject to the same core count limitations as HPC applications. Unifabrix’s technology could help here, but the company is focusing on the HPC market first. That has attractions for a startup: a relatively small number of customers and good OEM and MSP opportunities.
Unifabrix has pilot projects under way with several customers already and Hyatt says it is also earning revenue at this point.
Comment
This is the only such technology we have seen and it is firmly anchored in the CXL space. Unifabrix is CPU-agnostic and, in theory, can work with AMD processors, Arm and RISC-V. Once, and if, it gets OEMs selling on its behalf into the HPC market, and once PCIe 5 and then 6 are adopted, those same OEMs can take it into the enterprise AI/ML/analytics market.
We’re thinking intuitively here of Dell, which has a big HPC market presence. But DDN could see an interest from the storage point of view. We could also envisage memory expansion software suppliers such as MemVerge seeing potential benefits here as well. Ditto Liqid with server element composability across CXL.
Watch what happens with Unifabrix and its technology. There’s a good thing going here.





