


VAST Data and Nvidia today published a reference architecture for jointly configured systems built to handle heavy duty workloads such as conversational AI models, petabyte-scale data analytics and 3D volumetric modelling.
The validated reference set-up shows VAST’s all-QLC-flash array can pump data over plain old vanilla NFS at more than 140GB/sec to Nvidia’s DGX A100 GPU servers.”There’s no need for parallel file system complexity,” Jeff Denworth, VAST Data CMO told us. All-flash HPC parallel file systems are prohibitively expensive, he argues.

“We’ve worked with Nvidia on this new reference architecture, built on our LightSpeed platform, to provide customers a flexible, turnkey, petabyte-scale AI infrastructure solution and to remove the variables that have introduced compromise into storage environments for decades,” Denworth said.
Tony Paikeday, senior director of AI Systems at Nvidia, said: “AI workloads require specialised infrastructure, which is why we’ve worked with VAST Data, a new member of the Nvidia DGX POD ecosystem, to combine their storage expertise with our deep background in optimising platforms for AI excellence.”
Reference checking
For the reference architecture setup, VAST Data uses LightSpeed technology, NFS over RDMA, NFS multi-path across a converged InfiniBand fabric, to hit 140GB/sec-plus data delivery to a DGX A100. This is about 50 per cent fast than delivery to Nvidia’s prior DGX-2’s Tesla V100 GPUs.
The DGX A100 has eight Tesla A100 Tensor Core GPUs. These are 20x faster than the Teslas V100s.
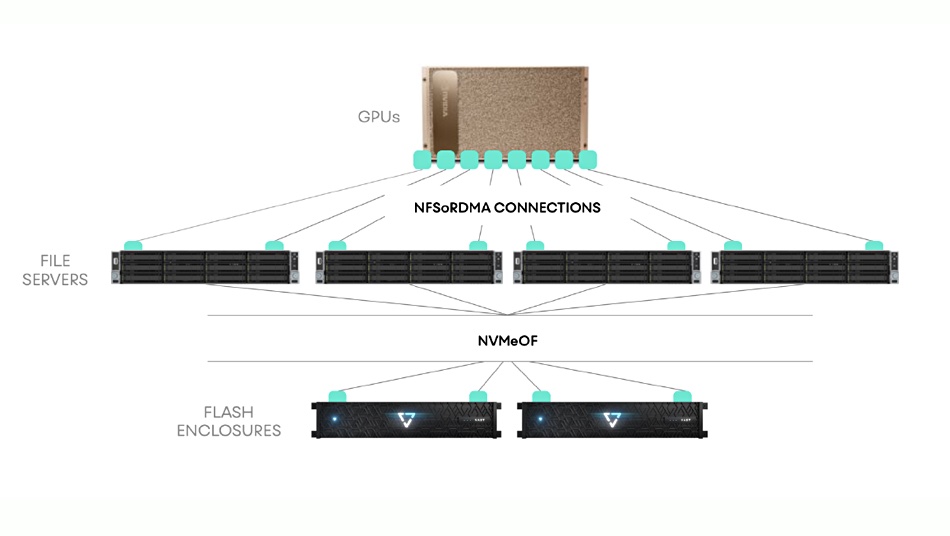
For the test results quoted in the reference architectures, scaling was linear from one to four A100 systems. VAST is working on scaling further to eight A100s.
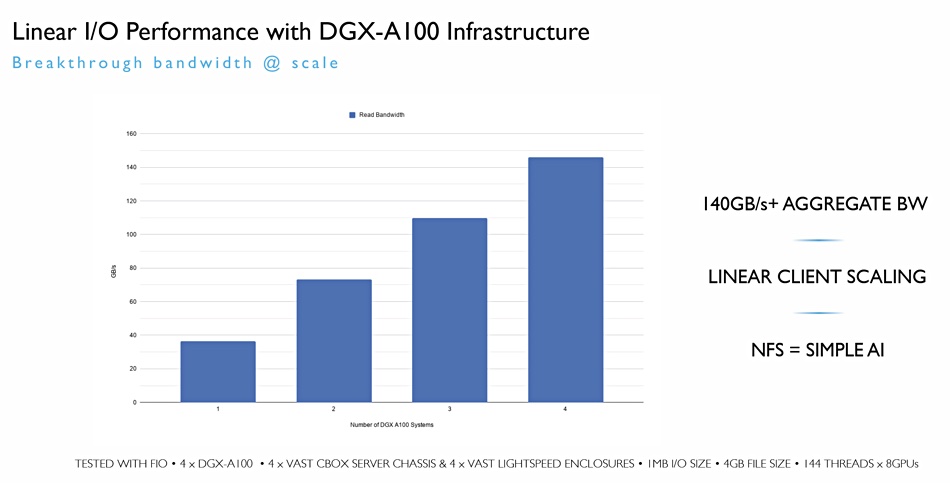
Are Weka and DDN faster?
The 140GB/sec speed is fast but not a record-breaker. A Nvidia presentation in November 2020 shows a WekaIO/Nvidia DGX-A100 system delivered 152GiB/sec (163.2GB/sec) to a single DGX-A100 across eight InfiniBand HDR links with 12 HPE ProLiant DL325 servers.
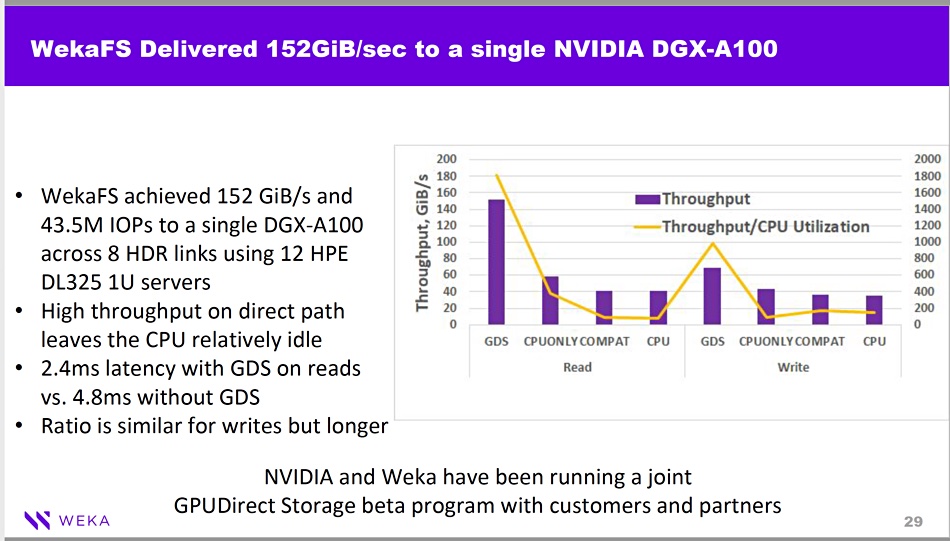
The same deck shows a DDN A1400X all-NVMe SSD system, running the Lustre parallel file system, delivering 162GiB/sec (173.9GB/sec) read to a DGX A100. The DDN slide’s text included this comment about its 162GiB/sec throughput; “That’s nearly 1.6X more throughput than with traditional CPU IO path and 60X more than NFS.”
Also this Weka/DDN comparison with VAST is not an apples-for-apples one as both use NVidia’s GPUDirect CPU IO path sidestep scheme. The VAST-Nvidia reference architecture does not. But Nvidia and VAST have actually demonstrated 162GiB/sec (173.9GB/sec) when using GPUDirect to link VAST’s systems to the DGX A100; the same as DDN.
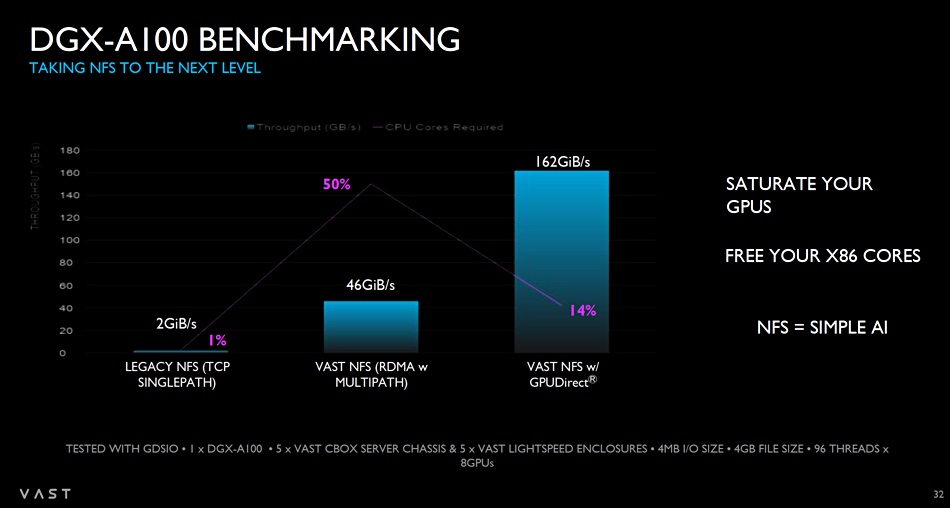
I guess we can expect an updated reference scheme in due course,
VAST-Nvidia reference architecture systems will be sold through VAST’s channel partners – Cambridge Computer, Trace3 and Mark III in the USA, Xenon in Australia, and Uclick in South Korea. No news yet on European coverage.





