


VAST Data is enabling customers to tackle bigger AI and HPC workloads courtesy of a new storage architecture that works hand in glove with Nvidia GPU Direct.
Unusually the technology – called LightSpeed – employs the NFS storage protocol rather than the parallel access file system that most HPC competitors use. VAST claims the LightSpeed NVMe drive enclosure overall delivers twice the AI workload performance of the prior chassis.
VAST says a legacy NFS client system typically deliver around 2GB/s and that’s why HPC systems have used parallel access file systems for many years to get higher speeds. LightSpeed nodes can each deliver 40GB/s to Nvidia GPUs, with the GPU Direct interface using the NFS protocol.
The company has demonstrated 92GB/s data delivery speed using plain NFS – nearly 3X the performance of VAST’s NFS-over-RDMA and nearly 50X the performance of standard TCP-based NFS.
LightSpeed customer Bruce Rosen, the exec director at the Martinos Center for Biomedical Imaging, provided a supporting quote: “VAST delivered an all-flash solution at a cost that not only allowed us to upgrade to all-flash and eliminate our storage tiers, but also saved us enough to pay for more GPUs to accelerate our research.”
Jeff Denworth, VAST Data’s VP Product, proclaimed: “Let data scientists dance with their data by always feeding their AI systems with training and inference data in real-time. The LightSpeed concept is simple: no HPC storage muss, no budgetary fuss, and performance that is only limited by your ambition.”
LightSpeed clusters
There are three branded LightSpeed cluster configurations, using nodes with a 2U x 500TB NVMe SSD chassis, VAST server and Ethernet or InfiniBand connectivity;
- The Line – 2 x Lightspeed nodes putting out 80GB/sec supporting 32 x Nvidia GPUs
- The Pentagon – 5 x Lightspeed nodes providing 200GB/sec for 80 x Nvidia GPUs
- The Decagon – 10 x Lightspeed nodes delivering 400GB/sec to 160 x Nvidia GPUs
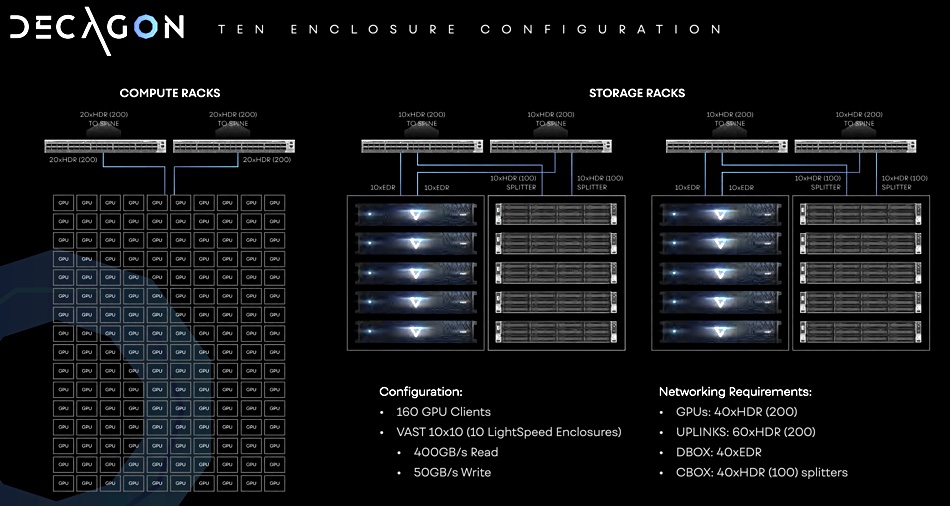
VAST says it provides 2:1 data reduction and so a LightSpeed enclosure provides 1PB of effective capacity.
LightSpeed boxes are heavily skewed towards read performance; the Line cluster achieves 10GB/s when writing data – just 12.5 per cent of the read speed. The same relative read write performance difference applies to the Pentagon and Decagon clusters.
AI is characterised by read-heavy, random I/O workloads, according to VAST, which cites deep learning frameworks such as computer vision (PyTorch, Tensorflow), natural language processing (BERT), big data (Apache Spark) and genomics (Parabricks).
Read more in a LightSpeed eBook.





