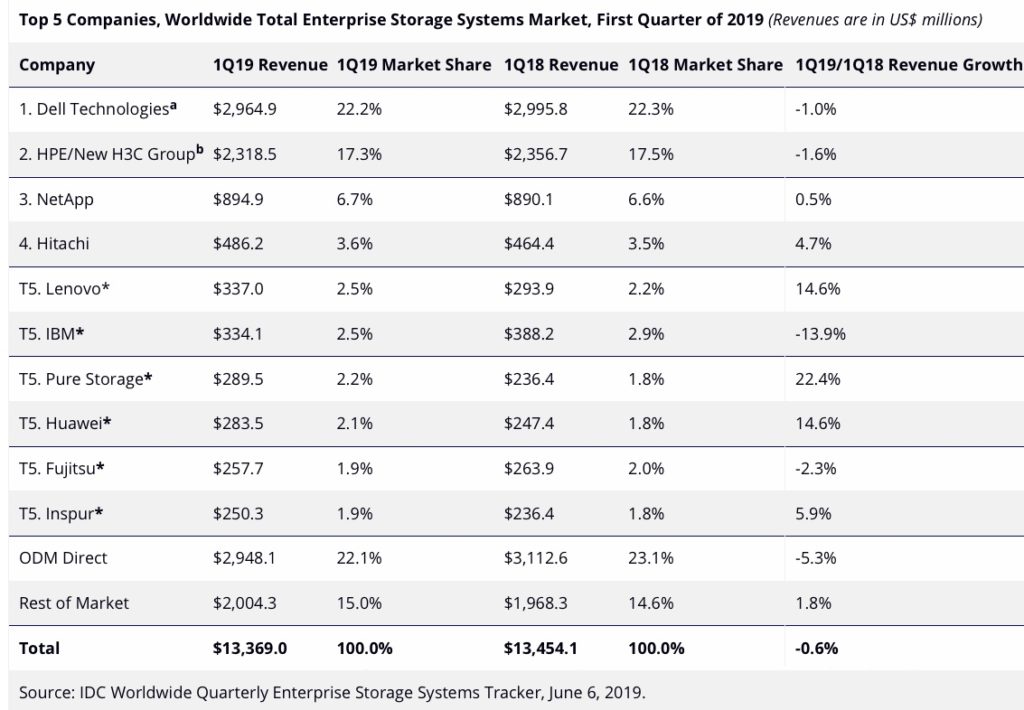
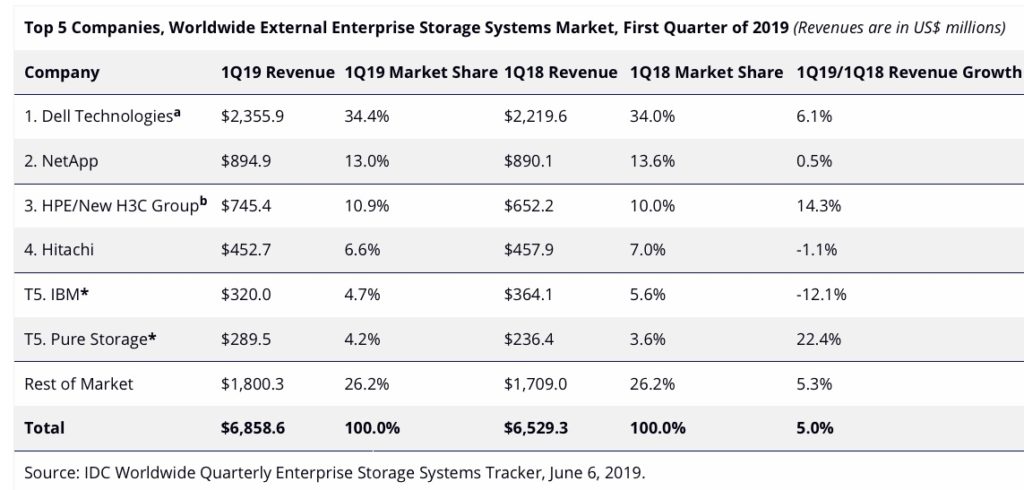
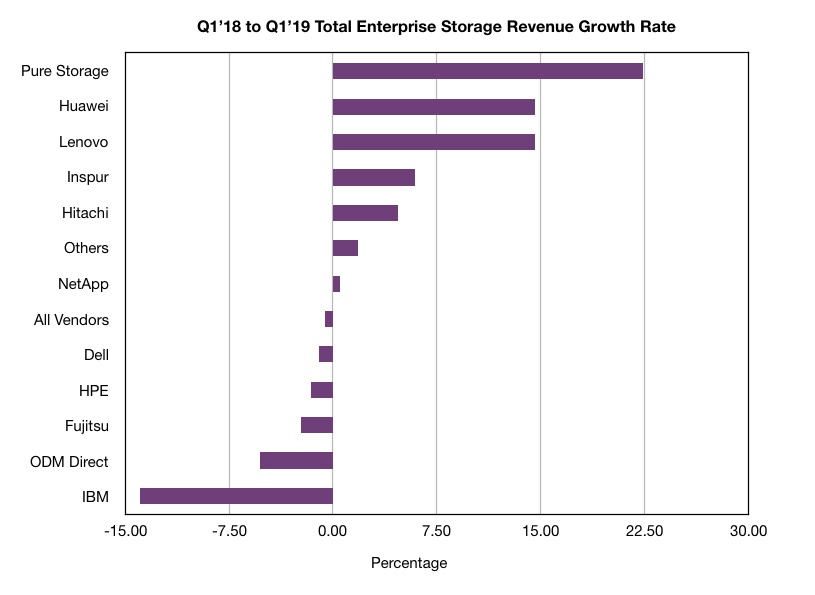
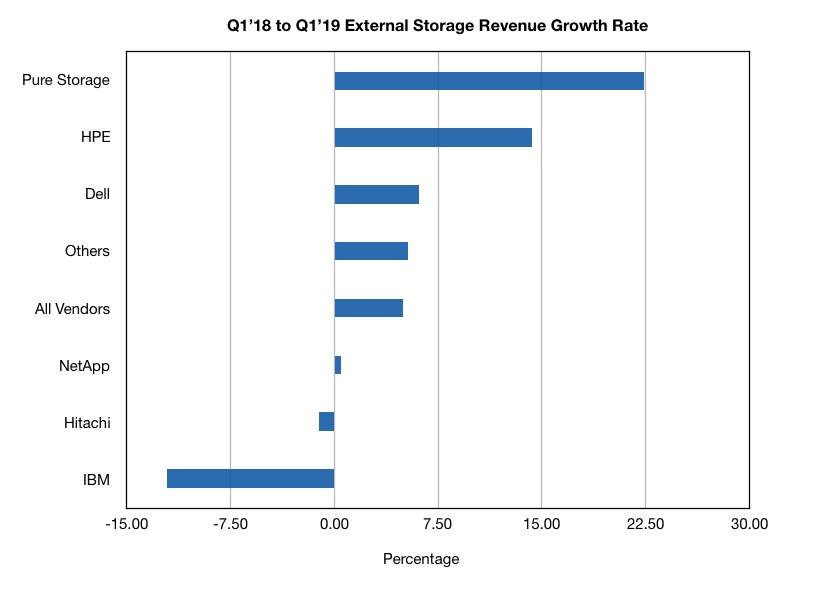
HPE’s Primera array, launched today, is an evolutionary upgrade of its 3PAR platform, with expanded InfoSight management and claimed Nimble array ease-of-use.
Our sister publication The Register carries the announcement story here. On this page Blocks & Files tries to figure out the speeds and feeds. This is a bit of a headscratcher as HPE has released next to no pertinent information – a glaring oversight for such a big launch.
Rant over. We have gleaned what we can and inferred the information from an HPE release, presentation deck, and HPE sponsored IDC white paper(registration required) as HPE has declined to supply data sheets.
3PAR for the course
Primera can be considered a next-generation 3PAR design as 3PAR’s ASIC-based architecture is still used.
According to HPE, Primera uses a new scale-out system architecture to support massive parallelism. This is highly optimised for solid state storage.
Steve McDowell of Moor Insights Strategy, said in an email interview: “Primera is absolutely an evolution of 3PAR. It was built by 3PAR engineers. It’s based around an update to 3PAR’s ASIC. The Primera OS is based on 3PAR’s operating environment. At the same time, HPE is being very careful to distinguish that it’s a new product. I think that says less about what Primera is today, and more about how it will be basis for HPE’s high-end storage moving forward. This is HPE’s “highend.next”.
We cannot compare Primera to the obvious competitive array candidates: Dell EMC PowerMax, Infinidat InfiniBox, NetAPP AFF and Pure Storage FlashArray, as we lack enough speeds and feeds information.
Primera will also compete with NVMe-oF startup products such as Apeiron, E8, Excelero and Pavilion.
McDowell said: “From a speeds/feeds perspective, I have no doubt that Primera will be competitive with PowerMax, AFF, FlashArray//X, and Infinidat. It’s less about technology in that space today, with all players being more or less equal depending on workload and day-of-the-week, and more about positioning and filling out the portfolio.” x
He thinks Primera will do well against Dell EMC: “The HPE sales teams have cracked the nut and figured out how to sell storage against Dell and Pure – those are the players who HPE is running into most as it closes business. Primera gives them great ammunition in that fight.”
Blocks & Files believes HP will focus on streamlined management through InfoSight and the 100 per cent availability guarantee as its main competitive differentiators, with performance once SCM and NVMe/NVMe-oF technologies are supported inside the array.
The hardware
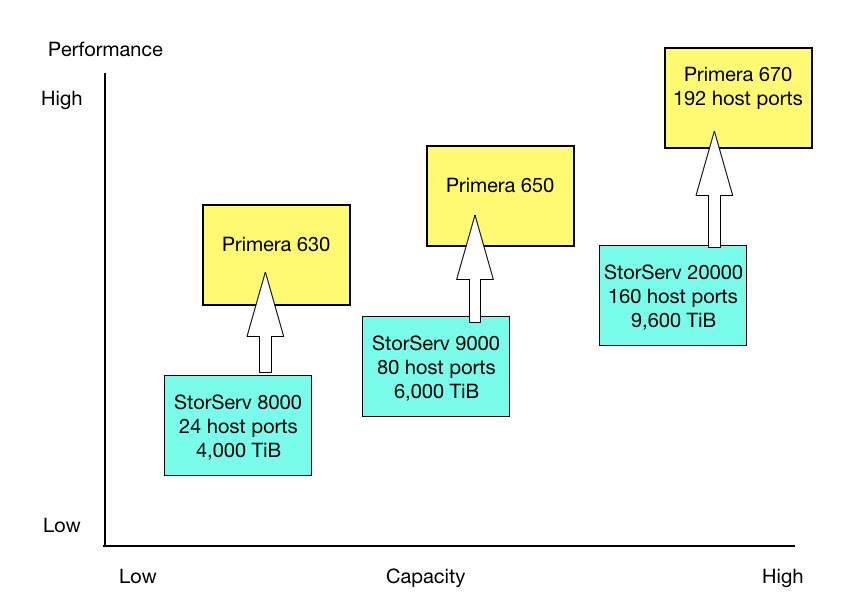
There are three Primera models, the 630, 650 and 670. HPE has not provided comparison information and, yes, we have asked.
These are built from nodes or controllers, the terms are synonymous, and up to four nodes can be combined in a single system. Each node plugs into a passive backplane; avoiding cabling complexity. The system comes in two sizes:
- 2U24 with two controllers
- 4U48 with four controllers
Each controller has two Intel Skylake CPUs and up to four ASICs. HPE says this is a massively parallel system ad we might have expected more nodes/controllers to justify that term. An HPE source said: “It’s massively parallelized inside the 4-node architecture, that’s true. But it’s not some gigantic scale-out box. It’s a high end box with all fancy data services that’s easy to consume.”

We have asked HPE if the 2U24 building block has 24 drive slots, and the 4U48 one has 48 slots. A source tells us there are 12 drives per rack unit, which implies that there are 24 slots in the 2U controller and 48 in the 4U one.
Node à la mode
There are eight dual-purpose (SAS/NVMe) disk slots per controller pair. At time of writing HPE has not published raw capacity numbers per drive or revealed the available drive types.
An HPE source told us: “System is primarily all flash but there will be options to get it with spinning drives for archival type needs.”
A node can have up to 1PB of effective capacity in 2U (or 2PB in 4U), with additional external storage capacity expansion available in both form factors. HPE is not providing data reduction ratios nor does it detail expansion cabinet capacity details or numbers.
In this absence, we rely on our completely scientific speculative back of the envelope calculation and note a 2U x 24 slot system with 1PB of effective capacity would have 1PB/24 capacity per drive; 42.66TB/drive. If we assume a 1PB = 1,000TB and a 2.5:1 data reduction ratio then that gives us 16.66TB/drives. Possibly coincidentally, this is is pretty close to the 16TB drives Seagate has just announced.
A 4-node system can have up to eight Skylake CPUs and up to 16 ASICs. That’s the maximum system today.
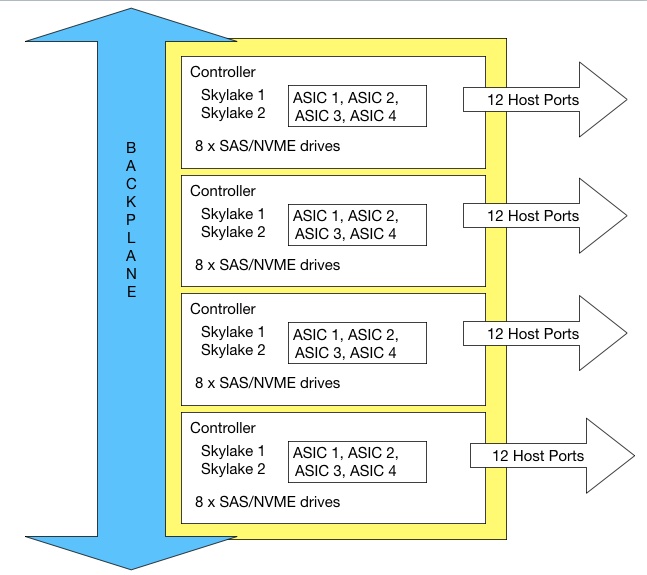
There can be up to 12 host ports per node, hence 48 in total across the 4 nodes, These ports have 25GbitE or 32Gbit/s FC connectivity. NVMe-over Fabrics is not mentioned by HPE.
The nodes have redundant, hot-pluggable controllers, disk devices, and power and cooling modules.
Primera has a so-called “all-active architecture,” with all controllers and cache active all the time, to provide low latency and high throughput. HPE has not released performance numbers for latency or throughput.
Gen 6 ASIC
The sixth generation ASIC provides zero detect, SHA-256, X/OR, cluster communications, and data movement functions. Its design is said to optimise internode concurrency and feature a “lockless” data integrity mechanism.
Data reduction (Inline compression) runs in either a QAT (Intel Quick Assist Technology] chip or a controller CPU, depending on maximum real-time efficiency. This is determined by the system’s AI/ML-driven self-optimisation.
The data reduction is built-in and always-on but can be turned off.
One HPE source said Primera has dedicated hardware, the ASICS, to help with ultra fast media that would otherwise overwhelm the fastest CPUs.
Moor Insights’ McDowell thinks this ASIC may be used in the future to upgrade 3PAR systems.
Storage class memory
HPE said Primera is built for storage class memory, without specifying if any SCM media is actually used. We have asked and are waiting a reply.
In November 2018 HPE said it would add Optane caching to the 3PAR arrays, calling the scheme Memory-driven flash.
Services-centric OS
The Primera system features:
- RAID, multi-pathing with transparent failover
- Thin provisioning
- Snapshots
- QoS
- Online replacement of failed components,
- Non-disruptive upgrades
- Replication options including stretch clusters
- On-disk data protection
- Self-healing erasure-coded data layout which varies based on the size of the system and is adjusted in real time for optimum performance and availability.
Features associated with high-end HPE storage – RAID, thin provisioning, snapshots, quality of service, replication, etc. – are implemented as independent services for the Primera storage OS.
Feature cans be added or modified without requiring a recompile of the entire OS. Such service upgrades take five minutes or less. HPE claims this approach enables Primera to be upgraded faster, easily, more frequently, and with less risk than other high-end storage systems. Blocks & Files understands that this may not be the case for the base OS code.
McDowell, told us: “The new OS uses containers to provide isolation for data services – this is different from 3PAR’s traditional approach. It’s also (interestingly) the approach that Dell has said is core to its forthcoming Midrange.next.”
According to the IDC white paper, “System updates are all pre-validated prior to installation by looking at configurations across the entire installed base (using HPE InfoSight) to identify predictive signatures for that particular update to minimise deployment risk.”
There is no mention of any file storage capability, although 3PAR has this with its File Persona.
Primera management
HPE stresses that its cloud-based InfoSight is AI-driven and manages servers, storage, networking and virtualization layers. It can predict and prevent issues, and accelerate application performance.
The IDC whitepaper states: ‘The system generally follows an ‘API first’ management strategy, with prebuilt automation for VMware vCenter, Virtual Volumes, and the vRealize Suite.”
HPE’s pitch here is that data centre systems and storage arrays such as Primera are becoming too complex for people to manage effectively, and AI software is needed to augment or replace human efforts.
The IDC white paper notes: “Fewer and fewer organizations will be able to rely entirely on humans to ensure that IT infrastructure meets service-level agreements (SLAs) most efficiently and cost effectively.”
Performance
InfoSight AI models trained in the cloud are embedded in the array for real-time analytics to ensure consistent performance for application workloads, according to HPE.
The system predicts application performance with new workloads using an on-board AI workload fingerprinting and headroom analysis engine
We are told Primera has consistent, but unspecified, low latency. An HPE source said: “Latencies even with large configurations under pressure are in the low hundreds of microseconds.”
This is maintained at scale. Our source said: “It’s easy for most systems to maintain low latency for small capacities and specific simple types of workloads (like doing single block size benchmarks across a small working set), but doing so across a maxed-out system subjected to very mixed real workloads is far harder.”
Primera is 122 per cent faster running Oracle, according to HPE, without revealing what the base system is or specifying the Oracle software used.
Data protection
Data protection is provided through Recovery Manager Central (RMC), which provides application-managed snapshots and data movement from 3PAR to secondary StoreOnceSystems, Nimble hybrid arrays, and onwards to HPE Cloud Bank Storage or Scality object storage for longer-term retention. Pumping out data to AWS, Azure and Google clouds is supported.
RMC provides application-aware data protection for Oracle, SAP, SQL Server, and virtual machines.
How Primera stacks up with the rest of HPE’s storage lines
Our HPE sources say that Primera replaces no existing storage product. However, Blocks & Files thinks Primera will ultimately replace the 3PAR line as HPE’s mission-critical storage array. For now 3PAR is mission-critical and Primera is high-end mission-critical.
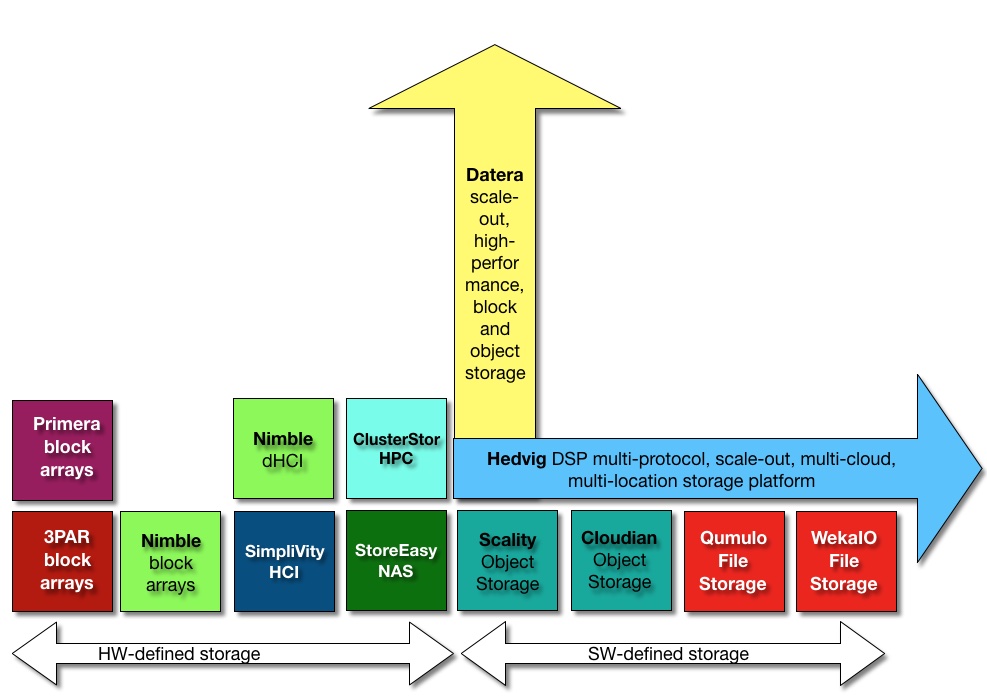
Nimble arrays remain as HPE’s business-critical arrays for enterprises and small and medium-business. The XP arrays continue to have a role as mainframe-connected systems.
Primera will have data mobility from both 3PAR and Nimble arrays.
The overall HPE storage portfolio, including the to-be-acquired Cray ClusterStor arrays and new Nimble dHCI product, looks like this;
Net:net
Primera promises to be a powerful and highly-reliable storage array for hybrid cloud use, with potentially the best management in the industry. But until performance data is released we can’t judge how powerful. It appears to lack current NVMe-oF and SCM support and also lacks file capability. We expect these features to be added in due course.