

Blockchain – A blockchain is a decentralized ledger of transactions across a peer-to-peer network. Each transaction is recorded in an immutable and date/timestamped way and cannot be overwritten. All new transactions to the entity, such as a cryptocurrency, that the blockchain is associated with cause a new block to be appended to the chain. Each node in the peer-to-peer network has access to the blockchain, thus ensuring that the transaction history is open and transparent.
Block
Block – Data is stored in bit areas on storage media. The bits are grouped into blocks and the blocks numbered sequentially from the start of the disk, thus providing a block addressing scheme; “Put this data in the series of blacks starting at block number 5,623,782,566.” The storage media device controller or an accessing application has to keep track of which blocks are used and which empty. An application, such as a database can use block addressing to go straight to a location in a storage device to read or write data with no intervening steps such as transiting a file and folder structure.
Virtually all storage devices group bit areas into blocks, and data organising schemes such as files and objects are overlaid on the basic block system. The storage device controller translates an object or file and folder address into a block-level address.
Bit Line
Bit Line – Cells in a memory array, such as DRAM, are laid out in rows and a row is called a bit line (as in line of bits). Each cell can carry a binary bit value, logically zero or one. The array has set of wires, perpendicular to the bit lines, which are called word lines. The intersection between a bit line and a word line is the cell’s effective address. Electrical currents sent or received along the word and bit lines can be used to set or read the electrical resistance value of a cell and so provide binary values.
MR-MUF
MR-MUF – Mass Reflow Molded Underfill – A method used by SK hynix in its HBM semiconductor manufacturing process. It involves the placing of multiple chips on the lower substrate and bonding them at once through reflow, and then simultaneously filling the gap between the chips or between the chip and the substrate with a mold material.
Bit
Bit – The smallest element of data in an IT system. It has a value of 1 or 0 and eight of them make up a byte. The letter A in capital form for example, is written as 01000001 using eight bits. This binary number represents the binary equivalent of the decimal number 65, which in the ASCII text encoding system, is a capital A.
Log-Structured Merge Tree
Log-Structured Merge Tree – The Log-Structured Merge Tree (LSM Tee) concept is used for ingesting and indexing data and persisting it to storage by application storage engines. It has ordered key:value pairs which are held in two or more places such as an in-memory structure and a storage structure. We can envisage three such structures: (1) an in-memory container to hold incoming data requests as a hash table or K:V pair table, (2) when full the in-memory container contents are written to one or more sorted and indexed in-memory delta container, freeing up the in-memory container, (3) a base storage structure into which the delta container contents are batch written or merged in a way that is consistent with the disk structure.
The merging or compaction is a background operation. Once deltas are merged into the base they are deleted. A search is then a three-step process, looking into each data structure in turn until the item is found.
The code for an LSM-Tree does not have to be written from scratch as developers can link to libraries of such code. There are three popular open source libraries for this – LevelDB, RocksDB and Speedb. Speedb is a rewritten RocksDB implementation that, the company claims, is significantly faster than RocksDB.
Thousands of enterprise apps use LSM-Tree-based storage engines and here are some prominent LSM-Tree app users:
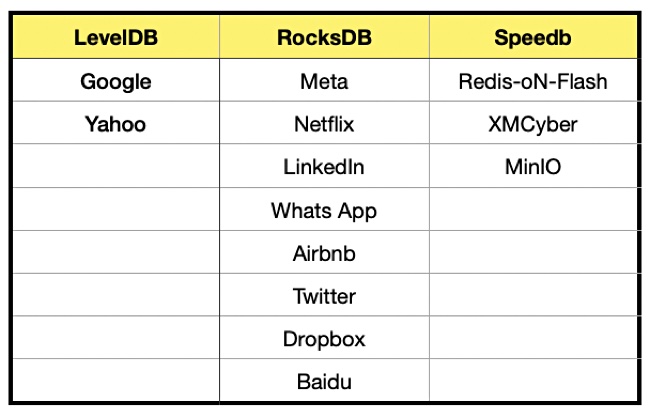
It is claimed that these embedded LSM-Tree storage engines offer the highest-performance data storage capabilities, enabling massive scale and stability under pressures. This approach is highly efficient for massive ingest of data because it allows new data to be quickly written from sorted arrays in memory, aligning aggregated bytes (in memory) to fill complete blocks (on disk), while allowing for efficient retrieval of new data from memory, and old data from disk.
Binary Search Tree
Binary Search Tree – see B-Tree.
B-Tree & B+ Tree
B-Tree – A method used by application storage engines for writing, reading and indexing data optimised for reading. One way of writing data is just to append it to existing data. Then you search for it by reading each piece of data, checking if it’s the right one, and reading the next item if it is not. This can, however, take a very long time if your database or file has a million entries. The longer the file, the worse the average search and read time. We need to index the file or database so we can find entries faster.
A binary search tree and a B-Tree both store index or key:values for data items. A binary tree has a starting point or root, with a few layers of nodes. Each layer is laid out from left to right and a node has a key:value that is greater than nodes to the left and smaller than nodes to the right. To find a particular key, you progress down through the layers in the tree util you arrive at the node with the desired value. The deeper the tree and the more nodes, the longer this takes.
A B-Tree fixes this problem. It has a starting point or root with a small number of node layers called leaves and children. We’ve drawn a simplified diagram to show this. Note that there are different definitions of what is a leaf node and what is not. We have kept things simple and may be oversimplifying.
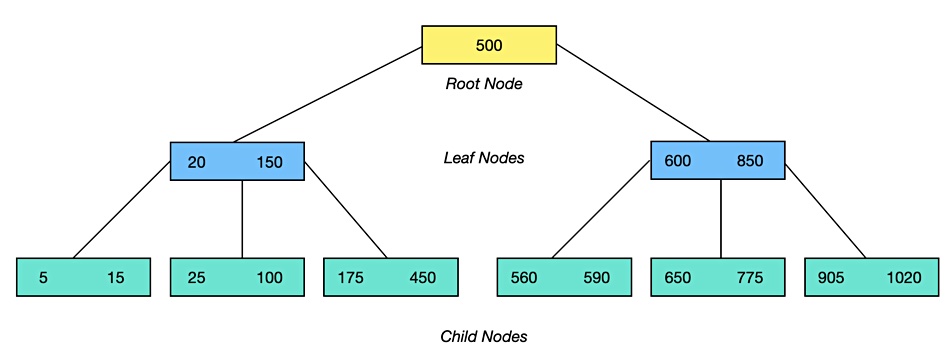
A node can hold one or more keys, up to a limit, which are sorted in ascending order. The numbers in each node in our diagram are range limits. The left-most child node, for example, has a range of keys between 5 and 15. If we have a leaf node with a range of 20 to 150 then we know all key:values below 20 will be in its left-most child, key:values between 20 and 150 will be in the middle child, and keys valued at more than 150, but less than 500, will be in in its rightmost child.
As you add more data, a B-tree gets more index values which have to be added. This can lead to more leaf nodes and child nodes, with nodes being split in two, and reorganization going on in the background.
B+ Tree
A B+ tree stores data pointers only at the leaf nodes of the tree. The B-Tree has far fewer layers than a binary tree which reduces the number of disk access needed to search it. This makes a B-Tree scheme good for read-intensive workloads. A Log-Structured Merge Tree is better for write-intensive workloads.
A B+ Tree differs from a B-tree in that both are self-balancing tree data structures that maintain sorted data and allow searches, sequential access, insertions, and deletions in logarithmic time. However, there are several key differences between them:
Structure:
- B-tree:
- Nodes: Both internal and leaf nodes can store key-value pairs or pointers to records.
- Data Storage: Data can be stored in both leaf nodes and internal nodes. Each node contains a number of keys and pointers, where the keys act as separators for the pointers. For example, if a node has keys K1, K2, …, Kn, then pointers P1, P2, …, P(n+1) direct to subtrees where keys less than K1 go to P1, keys between K1 and K2 go to P2, and so on.
- Internal Nodes: Have both keys and pointers to child nodes.
- B+ tree:
- Nodes: Only leaf nodes store actual data or key-value pairs. Internal nodes only contain keys and pointers to child nodes.
- Leaf Nodes:
- All data is stored in the leaf nodes, which are linked together in a linked list (or sometimes a doubly linked list) for sequential access. This means you can traverse from one leaf to another without going back up the tree.
- Each leaf node contains all the keys within its range in sorted order.
- Internal Nodes: Only contain keys for routing, not the data itself. Each key in an internal node acts as a guide to where further search should go.
Key Differences:
- Data Storage:
- B-tree: Data can be stored in any node.
- B+ tree: Data is only stored in leaf nodes.
- Sequential Access:
- B-tree: Requires recursive or iterative traversal back up the tree to move to the next or previous key, making sequential access less efficient for operations like range queries.
- B+ tree: Provides efficient sequential access through the linked list of leaf nodes, which is advantageous for range queries or full scans.
- Redundancy and Space Efficiency:
- B-tree: Keys might be repeated in internal nodes leading to higher space usage.
- B+ tree: Keys in internal nodes are not duplicated in leaf nodes, potentially saving space, although this depends on the size of the keys and the data they reference.
- Search Path:
- B-tree: A search might end at an internal node if the key is found there.
- B+ tree: All searches must traverse down to a leaf node since only leaves hold data.
- Performance for Different Operations:
- Insertions and Deletions: Both can be complex but handled similarly in terms of maintaining balance. B+ trees might involve more pointer updates due to the linked list in leaf nodes.
- Range Queries: B+ trees are generally more efficient due to the direct connection between leaf nodes.
Use Cases:
- B-trees are often used in database systems where random access to data is needed, and where the data size might not justify the overhead of B+ trees.
- B+ trees are preferred in file systems, databases for range queries, and any scenario where sequential access is common or beneficial due to their efficiency in scanning large portions of data.
In summary, while both B-trees and B+ trees are used for similar purposes in managing sorted data, B+ trees offer advantages in terms of sequential access and potentially better space utilization for certain types of data, at the cost of slightly more complex insertion and deletion operations due to the maintenance of the linked list in leaf nodes.
Binary Number
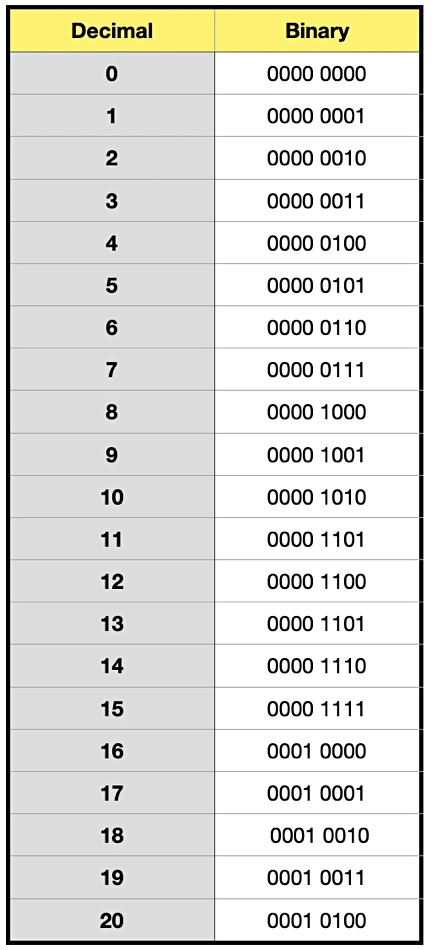
Binary number – a number written in base 2 notation which uses only the numerals 0 and 1. The binary numbers are written as 8-bit bytes and here is a conversion table for the first 21 decimal numbers;
Binary
Binary – (1) refers to computer code, (2) refers to a choice between two alternatives. Binary computer code replaces decimal numbers and alphabetic characters and symbols with streams of binary numbers. It is composed of bits – single binary numbers, organised into 8-bit bytes. Capital C is written as 01000011 in binary code.
Backup
Backup – A copy of data, a file or database, used for data protection against loss, damage or deletion. It is stored separately from the original data and used to restore that data to its original state. There are three main types of backup;
- Full backup – A total copy of a data set which takes the most time to create.
- Incremental backup – a copy of the dataset changes made since the last backup. This takes a shorter time to complete than a full backup.
- Differential backup – this is a copy of all the data changed since the last full backup.
- Synthetic full backup – A full backup copy at a certain date created from the prior full backup and all the intervening incremental backups.
Azure
Azure – This is Microsoft’s public cloud offering and provides application, compute, storage and system application services. It is the second largest public cloud after AWS and the second largest hyperscaler.