


UltiHash, a German startup that’s devised a byte-level deduplication algorithm, claiming it dedupes better than existing alternatives, with faster data access as well, has raised a $2.5 million pre-seed funding round.
Its deduplication software is deployed in an S3-compatible object storage cluster that can run on-premises or in AWS. The cluster has a head node and data nodes. Clusters can scale horizontally with variable sized data nodes supporting petabyte-scale volumes,
Incoming data is scanned and repetitious variable sized byte-level combinations replaced by markers. UltiHash says its dedupe operates both within and across datasets and is independent of structured, semi-structured and unstructured data data types such as text, images, videos, audio files, database records and so forth.
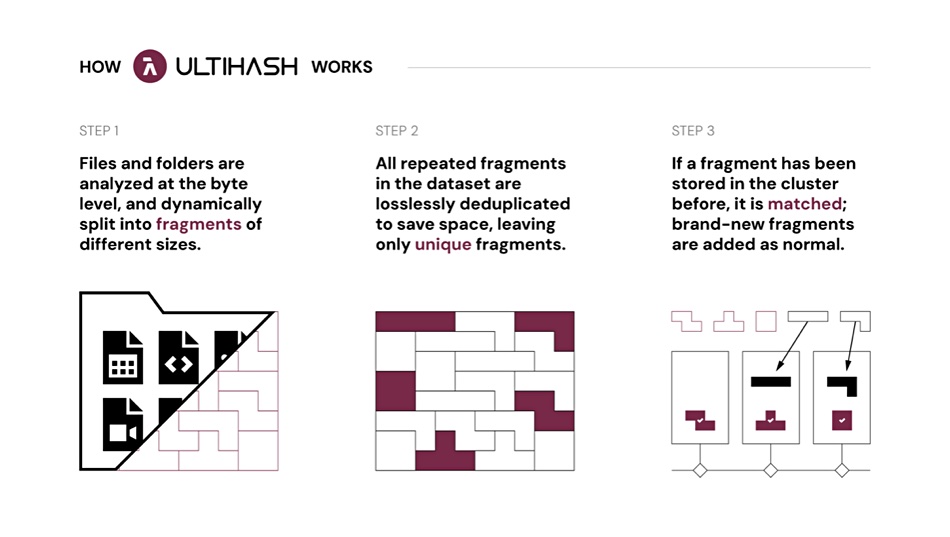
An UltiHash diagram (above) explaining its dedupe says “Files and folders are analyzed at the byte level.” However the UltiHash storage repository is an S3-compatible object storage construct, as a second diagram indicates;
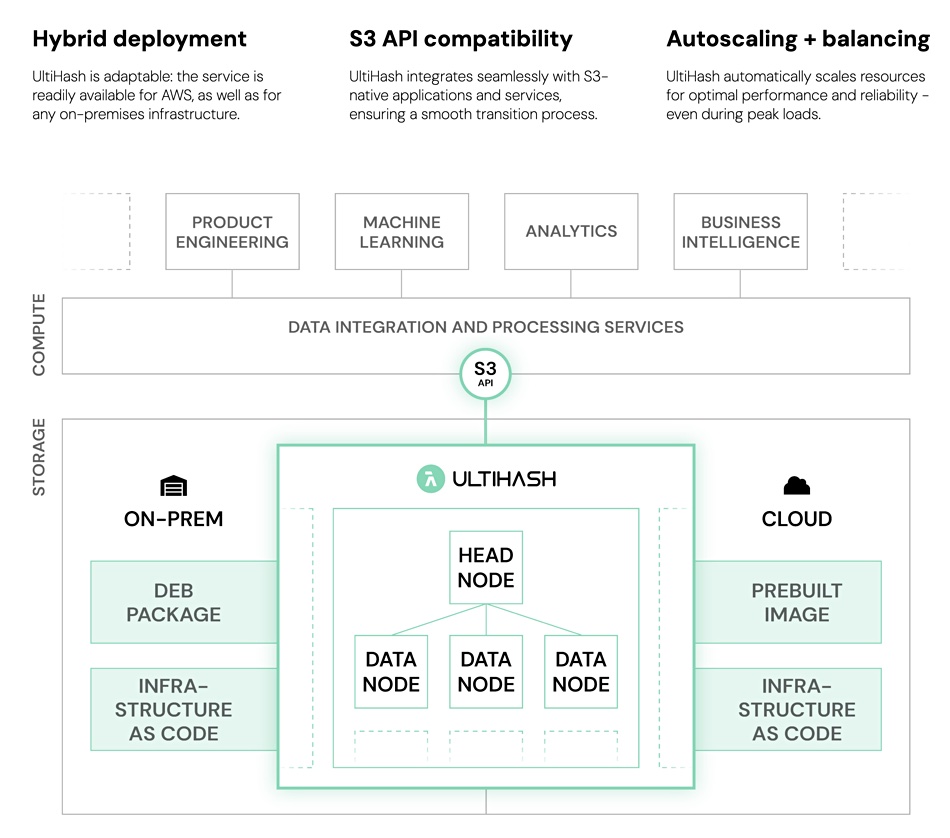
This means that the files and folder ingestion is carried out by some kind of input routine and, we understand, sent to the UltiHash SW using its API.
UltiHash integrates with S3-native applications and services, helping with its adoption. It says it has “built-in features for data backup and recovery, ensuring high availability and business continuity.” The software supports “multi-tenant environments with robust access control, ensuring secure segmentation and user management” and has “monitoring for real-time insights into storage usage, performance, and operational trends.”
The company’s lossless dedupe is claimed to cut storage costs by up to 50 percent, an overall 2:1 dedupe ratio. It’s website has details of storage capacity savings vs AWS S3 for several file types;
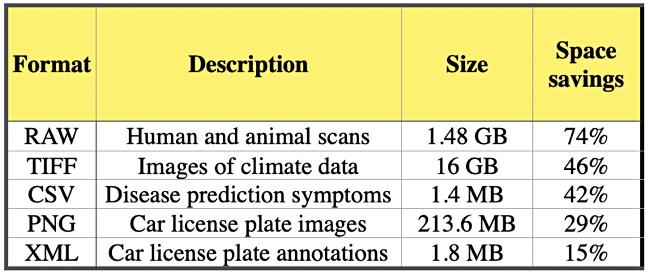
Customers’ overall dedupe ratios with UltiHash will vary with the data types used. UltiHash also claims speed advantages, saying its software is up to 50 percent faster on reads (GETs) than Amazon S3 when benchmarked on TIFF files;
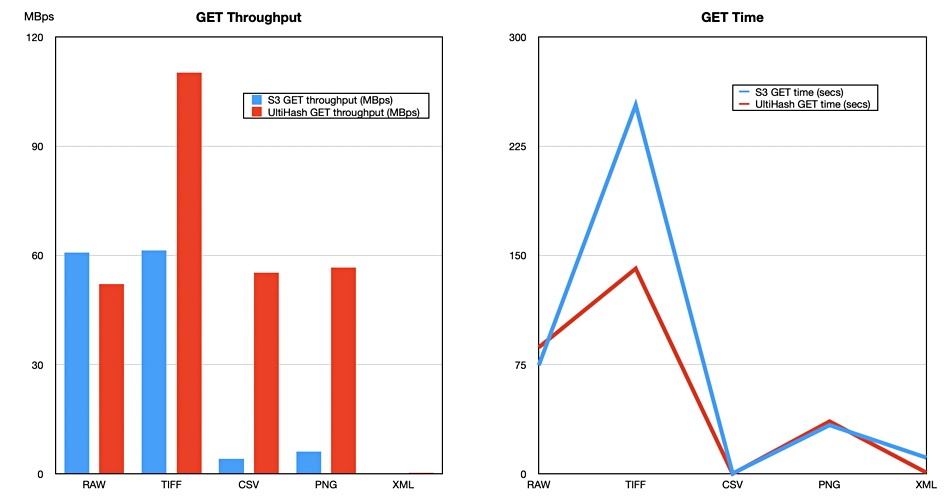
The company’s read throughput and time numbers show UltiHash is slightly slower than S3 when reading RAW files and very much faster than S3 when reading CSV and PNG files, and also XML files.
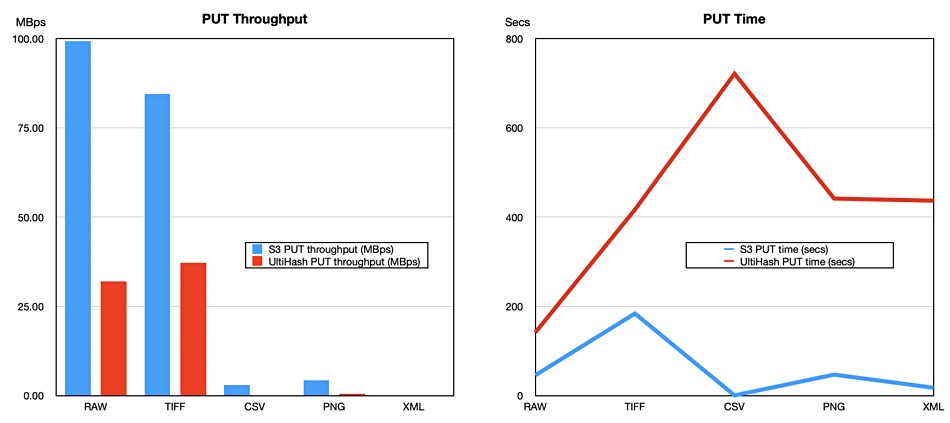
But the performance picture versus S3 places UltiHash at a disadvantage with writes (PUTs) for RAW, TIFF, CSV, PNG and XML files as its own AWS performance benchmark numbers show;
We asked the company about the dedupe load on CPUs and were told: “Some CPU is used only during the “write” phase. Since UltiHash, in general, divides between “write” and “read” activities and can provide separate nodes for them (standard practice for any high-load IO solution). For on-premise it would mean that you need one CPU heavier machine only, and the rest can be more general-purpose nodes.”
The software is available in a public beta and in the AWS Marketplace. It is setup in a VPC with the UltiHash-AMI and a cloud formation template.
Pricing is straightforward, with customers being charged $6/TB/month. A 30-day free trial is available. Request a demo here.
UltiHash was co-founded in 2022 by CEO Tom Lüdersdorf, a Berlin-based entrepreneur, and original CTO Benjamin-Elias Probst. The current CTO, Katja Belova, was recruited in December 2023. UltiHash has a development office in Berlin, some remote workers in the Berlin timezone, and a head office in San Francisco. Overall it has a team of around 10 people.
The pre-seed round was led by Inventure, with participation from PreSeedVentures, Tiny VC, Futuristic VC, The Nordic Web, Antti Karjalainen, founder, and angel scout for Sequoia Capital, and other private investors.
Bootnote
Startup StorReduce developed variable-length deduplication technology for data stored in Amazon S3 buckets. It was founded in 2014 and the technology seemed so promising that Pure Storage snapped up StorReduce in 2018. It ran the software in an ObjectEngine appliance and stored the deduped data in an underlying FlashBlade array. But the system was not a success and Pure closed it down in 2020, saying it would work with backup vendors, who each had their own dedupe technology, to have them use FlashBlade as a target.
Nowadays Cohesity, ExaGrid, Quantum, Veritas and other suppliers use variable-length deduplication. It is not clear how UltiHash’s dedupe ratio compares in efficiency to other variable-length dedupe suppliers’ technology. Its use case is different with a focus on workloads needing fast access to S3 data. Lüdersdorf stated: “The exponential increase in data storage resources is not sustainable from either a business or environmental perspective. Resource optimization is the only way forward to manage data growth and continuously use data as the lever to solve challenges. In this industry, speed is a must, and we’re here to make hot storage resource-efficient.”





